
装备系统剩余使用寿命预测技术研究进展
2022-06-30 06:57郭忠义李永华李关辉彭志勇于振中
南京航空航天大学学报 2022年3期
郭忠义,李永华,,李关辉,彭志勇,张 宁,于振中
(1.合肥工业大学计算机与信息学院,合肥 230009;2.哈工大机器人(合肥)国际创新研究院,合肥 230601;3.天津津航技术物理研究所,天津 300192;4.北京机电工程研究所,北京 100074)
21 世纪作为技术创新的时代,国内和国际社会发展日新月异,科技信息量呈现指数式的高速增长。工业设备系统也日趋复杂多样化,航空航天、整车制造、武器装备、智能家电以及工业设计等各个领域的工程体系日趋精密、变得更加复杂和智能[1-3]。随之而来的便是故障风险的增加。设备突然宕机将造成巨大危害,各种因设备故障引发的事故也见诸报端,引发人们对财产以及生命安全威胁的担忧。因此,剩余使用寿命(Remaining useful life,RUL)预测成为设备系统健康管理领域研究的重点和热点。
早期工业设备的维护方式是故障之后维修,能够很快找到对应的故障,并实现完美的修复,但是会浪费大量的生产时间;随后,提出预防性维护。预防性维护从系统维护发展到基于状态的维护(Condition-based maintenance,CBM)[4]。在系统维护中,使用由部件构造者提供的与寿命相关的度量或可靠性信息来安排干预。在CBM 中,评估组件的状况,即其退化水平,并跟踪其演变,直到其越过某个阈值后及时进行维护,实现更加优化的维护方法。如今,预测性维护的提出对设备状态管理进一步细化,实现精确的故障预测,实现智能化的同时,进一步降低维护的成本。工业智能化不但能够提供安全高效的管理系统,而且能够实现成本的精确控制,减少不必要的消耗。精准的RUL 预测便是实现智能化的重中之重。
RUL 预测的实现方法在不同的文献中使用了不同的分类标准[5-7]。结合当前流行的分类方式,将预测模型分为两类:基于物理模型[8-23]和基于数据驱动模型。
物理模型是通过工业系统零部件的退化现象的数学或物理模型来构建的,能够用专业的模型对退化进行表征,从而能够将现有的观测数据代入模型求得RUL。例如,滚动轴承的L-P 公式[8]、Ioannides-Harris 模型[9]、裂纹扩展方程[10]和Forman 裂纹扩展规律[11],电池的指数模型[12],使用粒子滤波作为参数估计器[13],以及其他物理模型[14-23]。随着时代发展,工业系统日趋复杂化、集成化,基于物理模型的RUL 预测的相关研究呈现下降趋势。
数据驱动模型的建立依靠于先前观察到的数据来预测系统的未来状态,或通过匹配历史上类似的模式来推断RUL。数据驱动模型需要大量的数据进行训练,无需事先对系统的物理行为有专业认识,就能够很好地建模高度非线性、复杂和多维的系统。但是运行到故障的数据很难获得,因为获取系统故障数据可能是一个漫长而昂贵的过程。因此,通常使用公共数据库来验证所提出的模型,如FEMTO-ST研究所提供的PRONOSTIA-FEMTO轴承数据集[24],NASA 提供的电池数据集[25]和涡扇发动机退化仿真数据集[26]。支持向量机(Support vector machine,SVM)在RUL 预测领域有着广泛应用[27-42]。从单SVM 方法发展到与其他方法相结合,在对PRONOSTIA-FEMTO 轴承数据集的RUL 预测中将预测误差E由2%降至0.6%;结合神经网络的SVM 方法使均方根误差(Root mean square error,RMSE)降低了10%以上。维纳过程(Wiener process,WP)多用于构建可解释性的退化模型,在RUL 预测中准确率表现并不优异[43-53]。高斯过程回归(Gaussian process regression,GPR)利用高斯过程对函数从输入空间到目标空间的非线性映射进行建模,在RUL 预测中得到应用[54-62],对于电池数据集的RUL 预测中RMSE 随着GPR算法的开发有较大幅度的下降。另外神经网络也被引入到GPR 中以提高回归性能[63]。相似性方法是通过匹配退化轨迹实现RUL 预测[64-73],最早以PHM’08 竞赛冠军的姿态出现。随着此方法的改进将对涡扇发动机退化仿真数据集的RUL 预测中惩罚分数(Score)降低了72%以上,当前的研究也开始与神经网络进行结合,并将Score 由千位数量级降低至百位数量级。神经网络方法被广泛应用于RUL 预测[74-106]。在不考虑时间记忆性的情况下,从简单的人工神经网络(Artificial neural network,ANN)到卷积神经网络(Convolutional neural network,CNN),再到深度卷积神经网络(Deep convolutional network,DCNN),逐步降低了对涡扇发动机退化仿真数据集RUL 预测的RMSE 和Score,其中Score 都能保持在百位数量级。在后来的研究中时间记忆性也被引入,循环神经网络(Recurrent neural network,RNN)能够将预测准确性再提升,长短时记忆网络(Long short-term memory,LSTM)被用来解决RNN 存在的长期依赖问题,能够在RNN 的基础上将预测误差进一步降低。基于神经网络的RUL 预测优于其他方法的RUL预测,对抗学习与迁移学习[107-122]通过与神经网络结合,能够将RUL 预测结果进一步提升。神经网络在近些年来成为重点研究的对象,对抗学习与迁移学习也是神经网络相关研究的强大助推力量。
因此有必要对工业系统中的现有RUL 预测工作进行回顾,以此来掌握未来工业系统RUL预测的发展。本文介绍并总结了各种RUL 预测方法、相应的主要假设和应用领域,并着重于基于数据驱动的RUL 预测。接下来,指出并讨论当前和未来的挑战性问题,以期有助于未来的研究工作。
1 技术基本原理
1.1 RUL 预测
RUL 定义为从当前时间到有效寿命结束的长度[123]。RUL 预测就是通过设备的历史状态变化及其他条件信息来判断设备从当前时刻运行到失效的剩余时间。其中历史状态变化及其他条件信息多是对设备运行时的监控数据,包含但不限于监控数据的变化以及环境信息等,其基础定义公式如下[124]
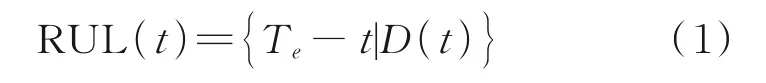
式中:RUL(t)为设备在时刻t的剩余使用寿命,Te为设备的失效时间,D(t)为当前时刻所拥有的所有状态信息。
1.2 RUL 预测方案
RUL 预测整体方案如图1 所示,需要完成从数据采集、数据处理、特征提取、模型构建、RUL 输出以及提供运维方案一系列工作。
数据是RUL 预测的基础,其中监控数据能够对设备的健康状态进行度量。监控数据的采集一般由传感器、数据传输设备和数据存储设备组成。采用多种传感器捕捉不同类型的监测数据,能够反映设备的健康状态变化。获取的数据通过数据传输设备传输到电脑或其他设备,并将其存储。随着传感器和通信技术的迅速发展,越来越多的先进数据采集设备被设计并应用到现代工业系统中。
有些数据可以直接作为设备性能或健康状态的表征。有些数据则不具有直接表征的能力,但是可以通过对数据进行更深层次的挖掘来对设备健康状况进行解读,实现间接表征。由此看来利用直接数据来进行RUL 预测是最好的选择,但是直接数据的获取具有很大的难度,有些数据通常是不可获取的或者需要付出高昂代价。直接数据难以获取,间接数据的获取更加方便。一般无需停机收集,且使用特定的传感器便可得以实现。间接数据虽然不能直接表征设备性能和健康状态,但是可以通过数据处理将其映射到相应的健康指标上来描述设备的性能。特征提取方法包括但不限于傅里叶变换、均值方差提取、小波变换和主成分分析(Principal component analysis,PCA)法等。
数据处理包含数据去噪、数据标准化/归一化、特征选择和特征提取等。数据去噪是由于原始数据被污染,会存在噪声,但是噪声不能反映设备的真实状态,会影响预测的结果。因此需要将原始数据中的噪声去除,以减少甚至消除噪声的不当干扰。

图1 RUL 预测整体方案Fig.1 RUL prediction scheme
数据标准化/归一化是由于采集到的原始数据会有多维变量,多维变量可能就会由于量纲的不一致导致数据的大小和方差有很大不同,因此需要消除数据中不同量纲尺度对设备健康状态估计的影响。一般会采用标准化和归一化的处理方法来消除量纲的影响。
特征选择主要针对包含多维变量的原始数据。多维变量中不相关或者冗余的变量可能会导致模型过拟合或者低灵敏度,因此变量选择是十分必要的。特征提取是为了消除数据中不同变量间具有明显或隐藏的相关性,将其变成线性不相关的新向量,新向量将具有更多的有效信息以及代表性。特征选择能够保持数据的原始特征,最终得到的降维数据其实是原数据集的一个子集;而特征提取会通过数据转换或数据映射得到一个新的特征空间,尽管新的特征空间是在原特征基础上得来的,但是新数据集与原始数据集之间的关联无法直接体现。
模型构建是考虑对应已有的数据,是采用物理模型还是数据驱动模型,或者是混合式的模型。针对不同的研究对象,需要分析不同模型的优缺点,再根据目标指导选择最合适的模型。对于单一设备的RUL 预测可以选择简单明了的物理模型,能够实现低成本且高效率的预测;而对于复杂的集成系统,构建物理模型是十分困难的,而数据驱动的方法能够取得更佳的效果。
RUL 输出以及运维方案是RUL 预测最后的步骤,将预测结果以需要的方式展现。运维方案是基于预测结果给予适当的处理方案,将预测结果变得更加立体化,展现出基于RUL 预测的智能一体化终端平台。
1.3 评价标准
RUL 预测结果一般可以由预测值和实际值进行直接差值对比,但是由于预测对象以及寿命计量单位的不同,会出现较大的差值。因此,对一些常用的评价标准进行简单介绍。常用的评价标准包括预测差值、RMSE、预测误差E、相对精度(Relative accuracy,RA)和惩罚分数(Score)等。
预测差值是真实RUL 值与预测RUL 值的差值,直观反映了预测的好坏。
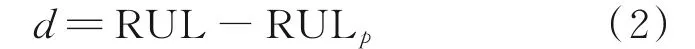
均方根误差是预测值与真实值偏差的平方和观测次数n比值的平方根,能够很好地反映出预测的精密度。
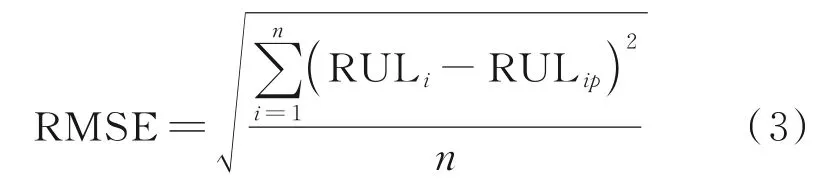
预测误差是预测值与真实值的差值除以真实值,反映了预测值与真实值的偏离程度。
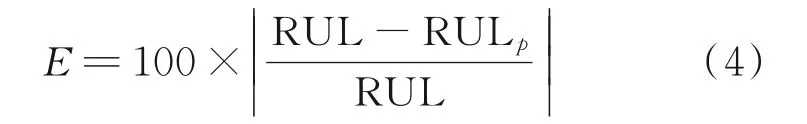
相对精度是相对于预测误差的另一种表现预测值与真实值的偏离程度的评价指标。
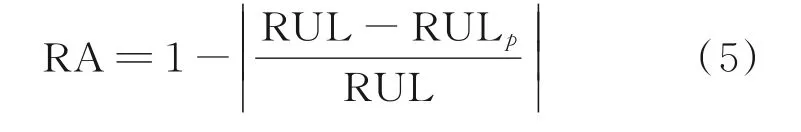
惩罚分数为航空发动机数据专用评价指标[26],是预测值和真实值之间的偏差带来的惩罚分数

式中:RUL 为真实的RUL 值,RULp为预测的RUL值,a1=13,a2=10。
2 研究进展
基于物理模型的RUL 预测方法能够在拥有少量数据样本的情况下实现工业设备系统RUL 的预测,其不需要考虑大规模大数量的采集数据,甚至无需数据分析就可以得到设备的故障或失效情况。在物理模型中,相应的专家知识是必不可少的,这里涉及到的模型构建将会花费大量的时间精力,模型一旦建立完成就具有了专用性,无法很好地适配到其他类似的系统中去,甚至在环境变化过大的情况下也不能很好地工作。故其在专业性上能够表现出可靠的预测效果,但是不具有迁移性,无法为其他类似或相近的工业系统服务。基于数据驱动模型的RUL 预测模型则完全不需要考虑系统的专业知识,能够对数据运用不同的数据分析方法进行分析和数据信息的深度挖掘,获取特征信息,再根据特征信息建立模型。基于数据驱动的RUL 预测模型的准确性依赖于数据的质量,只有足够且具有完整特征信息的数据才能实现模型的准确预测。数据的大量运用使其能够完成很复杂的物理模型无法完成的系统建模,但这既是其优点也是其缺点。设备运行的完整和准确的数据往往是不易获取的,其中完整的寿命周期数据更是难以获得,同时数据的采集也会受到噪声以及其他的干扰。本文将对近些年关于RUL 预测的研究进行归纳,重点将介绍数据驱动模型的RUL 预测,其中基于神经网络的RUL 预测研究由于其强大的特征提取能力以及计算机算力的大幅提升而出现了爆发式的增长。
2.1 物理模型
物理模型的正确建立是实现准确RUL 预测的基础,它涉及系统失效机制的专业知识,以建立系统退化过程的数学模型来估计RUL。模型参数的识别通常需要专门设计的实验和大量的经验数据。Lundberg 和Palmgren 在1949 年对滚动轴承疲劳失效进行研究[8],通过修正威布尔失效统计理论,分析了轴承疲劳失效的特征,并对应力材料体积的影响进行了评估,建立了各变量与承载力关系的L-P 理论公式。将滚动轴承的失效模型具现化,使得其寿命有了直观的描述

式中:L10为工作时间,Cr为额定动载荷,P为当量动载荷,ξ为轴承参数。
随着时代的发展,人们意识到L-P 理论存在一定的局限性。1985 年,Ioannides 和Harris 在引进了材料疲劳极限应力和考虑应力体积内各点应力及其深度的情况下,构建了滚动轴承及其他易疲劳机械元件疲劳寿命预测的一种新的数学模型[9],加入载荷、材料和操作条件等参数,能够对轴承的疲劳寿命描述得更加精准。
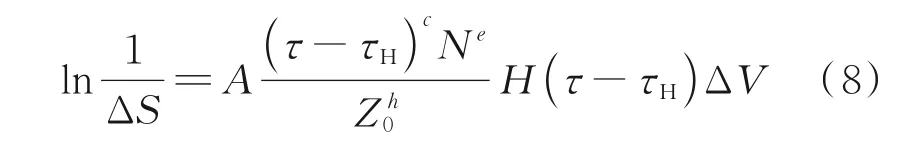
式中:S为存活率,τH为材料的疲劳极限应力,τ为产生疲劳裂纹的诱发应力,V为承受应力的体积,Z为应力所在的深度,H为海维赛阶跃函数,N为应力循环的次数,A为常数。
另一种轴承寿命预测模型是基于断裂力学,假定疲劳寿命取决于裂纹发展至断裂的过程。文献[10]基于混合模态Dugdale 模型、累积塑性位移准则和循环积分概念,建立了混合模态加载和小尺度屈服条件下的四次方应力强度因子裂纹扩展方程和二次方循环积分方程,使得各种加载条件下都能得到合理的大小。基于机器故障组合的物理模型的滤波器建立了基于线弹性断裂力学的Forman 裂纹扩展规律的寿命模型[11],将应用范围推广到机器系统,实现了发生灾难性故障前的剩余循环次数的预测。为了预测缺口镍基单晶高温合金的同相热机械疲劳(In-phase thermomechanical fatigue,IP TMF)寿命,基于连续损伤力学,建立了考虑疲劳损伤和蠕变损伤的镍基单晶高温合金光滑试样的IP TMF 寿命预测模型[14],再使用实验数据识别材料常数,最后通过在光滑试件上进行带停留时间的IP TMF 应力控制试验,验证了寿命模型的准确性。胡殿印等[15]建立了GH2036 合金的裂纹闭合模型,依据此模型研究GH2036 高温合金平板的低循环疲劳裂纹扩展寿命,取得了有效的RUL 预测。基于广义热力学框架的非线性连续介质损伤力学模型[12],在考虑不同载荷水平以及加载顺序的复杂条件下对某淬硬回火钢的疲劳实验数据建立模型,展现出对疲劳寿命的良好预测。随着新能源的大力发展,电池的寿命预测也有不少模型被建立起来。构建一个模型来反映电池健康状态(State of health,SOH)与其内外特性之间的联系,然后根据模型对SOH 或RUL 进行预测。文献[16]研究发现锂离子电池的面积比阻抗增加和功率衰减的速率遵循了基于时间功率和阿伦尼乌斯动力学的简单定律,以此根据功率衰减的电化学机理,建立了电池退化与温度和使用时间之间的联系。粒子滤波器(Particle filtering,PF)被用来估计和预测模型结构可用的时间序列数据[13],构建指数模型和改进指数模型,分别使用不同的状态方程来跟踪电池容量退化,对锂电池RUL 预测展现出了较强的优越性。考虑到PF 存在样本退化和贫瘠的问题,引入启发式卡尔曼算法(Heuristic Kalman algorithm,HKA),构建出HKA-PF 算法,在3 种不同情况下都能更准确地估计出RUL[17]。将PF 和无迹卡尔曼滤波(Unscented Kalman filter,UKF)融合构建了无迹粒子滤波(Untracked particle filter,UPF)[18],首先利用电池容量数据对电池退化趋势进行建模,再利用UPF 实现对锂离子电池RUL 的预测,相较于PF 算法降低了预测误差。在此基础上,进一步提出改进UPF 算法(Improve untracked particle filter,IUPF)[19],结合马尔可夫链蒙特卡罗算法解决了混合动力汽车中锂电池的退化现象,有效地实现锂电池RUL 的预测。另外通过对原始数据使用凸优化降噪处理,提升数据的可靠性,再求取锂电池退化机理模型的参数,构建了准确的表达式,进一步提高了对锂电池RUL 预测的准确率[20]。
电化学阻抗谱(Electrochemical impedance spectroscopy,EIS)被提出用作监测锂电池健康状况的指标[21],为了实时监测电池的健康状态,采用在线的EIS 估计方法非常有益。提出了一种基于可在线实现的分数阶等效电路模型的锂电池EIS估计方法,对电池的RUL 进行了较好的预测。文献[22]使用可循环锂的摩尔数和欧姆电阻作为SOH 指标的参数,开发了一种基于增强单粒子模型(Enhanced single particle model,eSPM)参数估计的RUL 预测算法。从实验数据中估计这些参数,并表明它们与从实验老化研究中测量的电池SOH 有关。最后利用估计的eSPM 参数导出的复合SOH 度量设计了基于PF 的RUL 预测器,该预测器可以利用SOH 度量的演化来预测RUL。文献[23]基于Dempster-Shafer 理论和贝叶斯蒙特卡罗方法建立了一个由两个指数函数组成的电池容量衰减模型,该模型在建模精度和复杂性之间有很好的平衡,能够准确捕捉电池容量衰减趋势的非线性。
以上基于物理模型的RUL 预测方法可以在相对稳定的外部条件下较好地提高预测的准确性。物理模型具有专用性,无法推广到其他设备中,而且其准确性很容易受到外界环境影响。随着工业设备系统高度集成化的发展,单个模型的建立已经不能满足整个工业设备系统寿命预测的需求。然而多模型的组合是困难的,无法通过简单叠加得到,需要基于设备的整体组合以及全面的专业知识去实现模型的建立,因此依靠物理模型来预测工业设备系统的RUL 十分困难。越来越多学者的研究集中于数据驱动模型的RUL 预测。
2.2 数据驱动模型
数据驱动模型的RUL 预测方法很多都是着眼于退化模型的构建,其基本原理如图2所示。使用离线数据库构建退化模型,再通过实时数据获取当前研究对象的退化模型,进行寿命预测。数据驱动模型可以总体概括为机器学习的方法,机器学习不需要专业的先验知识便能够从大量的数据中自主学习其中的规律,构建出高度非线性的复杂系统。机器学习能够适配工业设备系统的复杂性,使得其被广泛应用于RUL 预测中。数据驱动方法可以分为统计学习与机器学习两类。统计学习主要包括支持向量机、维纳过程和基于高斯过程回归等方法;机器学习方法包括相似性方法和神经网络模型等。
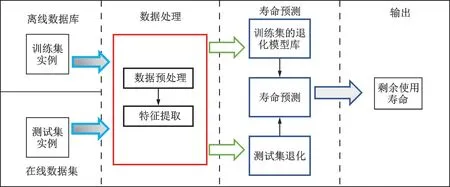
图2 基于退化模型的RUL 预测基本框架Fig.2 RUL prediction framework based on degradation model
2.2.1 支持向量机
支持向量机首先由Cortes 和Vapnik 提出[125],用于数据分析和模式识别。优点是灵活,当提供足够的数据时,可以模拟任意复杂的系统[126]。它通过搜索以最大间隔分隔感兴趣类别的超平面来执行分类。在SVM 中,核函数经常被用于通过将低维空间中的非线性问题转化为高维特征空间中的线性问题来促进非线性问题的解决。通常,预测基于在输入空间上定义的一些函数,而学习是推断该函数参数的过程。SVM 基于式(9)进行预测[127]
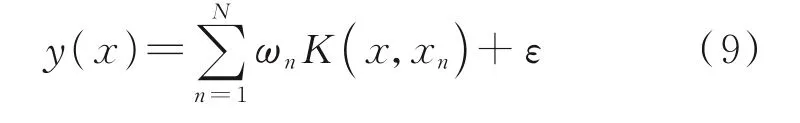
式中:ωn为连接特征空间到输出的模型权值,K( ·)为核函数,ε为独立噪声项。
该方法具有出色的小样本处理能力和避开维数灾难的能力,能够将高维空间中的非线性关系映射为线性关系。因此,许多学者尝试将该方法用于其他问题的解决。基于SVM 及其扩展的RUL 预测被应用到轴承、锂电池、航空发动机和机械部件等方面。文献[27]采用PCA 对滚动轴承运行故障试验的振动信号特征进行选择,并将粒子群算法应用于SVM 的参数优化,建立了基于SVM 回归的RUL 预测模型。如图3(a)所示,该模型主要有3个步骤,即敏感特征的选择、构建SVM 预测模型的输入输出和SVM 参数的优化。模型建立完成后将振动信号的特征作为输入,然后输出与轴承寿命相关的标量,相比于式(7)具有更高的预测精度。将机器退化过程中的离散健康状态概率与SVM 分类器结合,应用到健康状态估计中,能够有效地表征轴承故障的动态随机退化并有助于轴承RUL 的长期预测[28]。以上研究都是围绕单变量,考虑到仅关注单变量时间序列预后,不能很好地预测RUL,研究人员构建了基于相关特征和多变量SVM 的预测模型[29]。多变量SVM 考虑了变量间的影响,能够挖掘出小样本更多的潜在信息,并根据个体差异无效的相对均方根对轴承寿命阶段进行划分,对轴承RUL 实现有效的预测。不同于着眼于变量的多少,考虑到单个预测方式的不足,提出了一种结合Hilbert-Huang 变 换(Hilbert-Huang transform,HHT)、SVM 和支持向量回归(Support vector regression,SVR)的滚珠轴承监测新方法[30],该方法利用HHT 从平稳/非平稳振动信号中提取新的健康指标,然后通过SVM 的监督分类技术给出故障诊断,最后通过基于SVR 的时间序列预测获得RUL 的估计。三者的有效结合,提高了轴承退化检测、诊断和预测性能。另一种改进的灰色预测模型结合SVM 的灰色SVM 模型的RUL 预测方法也被提出[31],首先利用三角函数对原始数据序列进行平滑处理,然后利用SVM 和遗传算法建立最优预测模型,最后,通过回归生成操作恢复数据,得到电池寿命RUL 预测值。
2015 年以来,随着新能源汽车产业的蓬勃发展,SVM 的分类属性与回归属性结合被用来实现锂离子电池RUL 的实时预测[32]。首先由锂离子电池循环数据中提取关键特征,然后利用SVM 建立了基于关键特征的RUL 分类模型和回归模型,在电池接近寿命终点时,使用支持向量回归来预测准确的RUL。文献[33]构建了基于多健康状态评估的RUL 预测框架,该框架将轴承的整个寿命划分为多个健康状态,并分别建立局部回归模型,进行RUL 预测。RUL 预测框架如图3(b)所示,首先是数据采集,然后原始数据预处理,再使用SVM 进行轴承健康状态评估,将轴承的整个寿命划分为多个退化状态,最后构建出局部RUL 预测模型。文献[34]继续了多方式结合的探索,提出将最小二乘支持向量机(Least squares support vector machines,LS-SVM)与贝叶斯推理相结合,设计了一种预测微波元件RUL 的方法。如图3(c)所示,首先将训练数据和设置算法参数作为LS-SVM 框架的输入,然后对训练数据使用LS-SVM 学习算法进行建模,得到构成退化曲线的多个一步预测;同时利用贝叶斯推理找出最优模型参数,得到LS-SVM 回归模型的误差线;最后在给定失效阈值的情况下,得到RUL 点估计和区间估计。同样为了能实现点预测及一定置信水平的置信区间,于震梁等提出一种将SVM 和非线性卡尔曼滤波相结合的RUL 预测模型[35]。使用已有的具有全寿命周期的数据训练SVM 回归模型,引入非线性卡尔曼滤波构建出状态方程,再将机械零部件的退化特征构造出时间更新方程,最后通过逐步迭代计算出各时刻RUL 估计值及一定置信水平的置信区间。文献[36]提出了一种基于多传感器数据信息冗余的故障诊断与预测监测方法用于液压控制阀系统健康监测。如图3(d)所示,该故障诊断与预测系统采用模块化结构,包括一个故障检测与诊断(Fault detection and diagnostics,FDD)单元、一个故障参数估计(Parameter estimation,PE)单元和一个RUL 单元。将特征选择策略和SVM 技术结合在一起,以捕获多传感器数据信息中的冗余,并隔离FDD 单元中的故障。然后建立了3 种自适应神经模糊推理系统的分散网络来估计故障参数,最后使用自适应贝叶斯算法构造RUL 单元。自回归综合移动平均(Autoregressive integrated moving average,ARIMA)与SVM 结合的混合ARIMA-SVM 模型也被应用于RUL 预测中[37],首先通过ARIMA 模型对输入变量进行预测,然后将ARIMA 模型计算出的值作为输入值输入到使用线性核函数、多项式核函数、径向基核函数和S 形核函数训练得到的SVM 模型,最后得到RUL预测值。
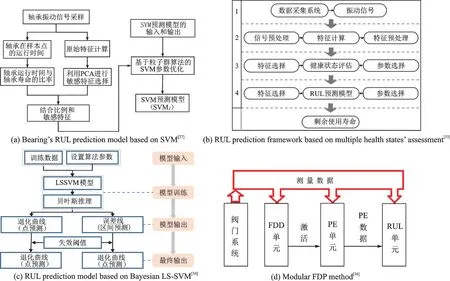
图3 基于支持向量机的RUL 预测方法Fig.3 RUL prediction methods based on SVM
2020 年以后,学者们不再只关注已被运用到RUL 预测方法的研究,有些未曾被应用的方法也被迁移到RUL 预测中,并取得了较好的预测效果。鸟群算法被引入到LS-SVM 参数进行寻优中[38],并在跟随者的位置更新中引入自适应学习因子,得到改进鸟群算法(Improved bird swarm algorithm,IBSA),然后结合LS-SVM 模型,建立了IBSA-LS-SVM 模型以解决锂离子电池RUL 预测问题。区别于其他学者的参数优化选择方式,粒子群算法(Particle swarm optimization,PSO)与LS-SVM 结合[39],其中LS-SVM 和核函数由PSO 进行优化选择,然后使用LS-SVM 进行故障预测,当故障症状的特征幅值超过特定阈值时,将RUL 预测模块激活,使用PSO-LS-SVM 进行RUL 预测。文献[40]采用了与文献[39]相同的PSO 算法,首先提取滚动轴承整个生命周期数据的特征值,利用单调性初步选择性能退化参数。然后利用本征矩阵的联合近似对角化(Joint approximative diagonalization of eigen-matrices,JADE)对提取的性能退化特征参数集进行降维,得到与设备性能退化一致的融合特征。最后构建基于PSO-SVM 的预测模型,预测性能退化趋势。2021 年,有学者将神经网络与SVM 结合,提出一种基于ANN 和SVM 的轴承RUL 预测方法[41]。考虑到神经网络的合理运用能够保证特征提取的准确性,使用ANN 模型将输入的多维时域和频域特征进行进一步的特征提取,然后将提取后的特征输入到SVM 模型中进行RUL预测。采用特征迁移的策略也被使用[42],使用同型号轴承在不同工况下的辅助数据,计算深度特征和退化轨迹间的相似度,提取出与退化轨迹走势相近的特征作为公共特征,实现退化信息的迁移。最后使用SVM 实现对轴承RUL 的预测。以上种种方法的结合及扩展使SVM 在RUL 预测的道路上有了更加广阔的前景。
如表1 所示,展示了SVM 在轴承RUL 预测上的应用,使用SVM 的方法能够在IEEE 2012 PHM数据集上分别取得RMSE 为34.5 和E为2%的结果。文献[30]和[42]由于结合了其他方法,使得在RMSE 和E结果上表现更加优异。文献[41]采用了不同于其他文献的RUL 统计方式,将整个寿命周期计为1,故而取得了远小于其他预测算法的RMSE。由于其他文献中使用了不同的数据集,且未有统一的评价标准,在这里没有进行相应的定量比较。
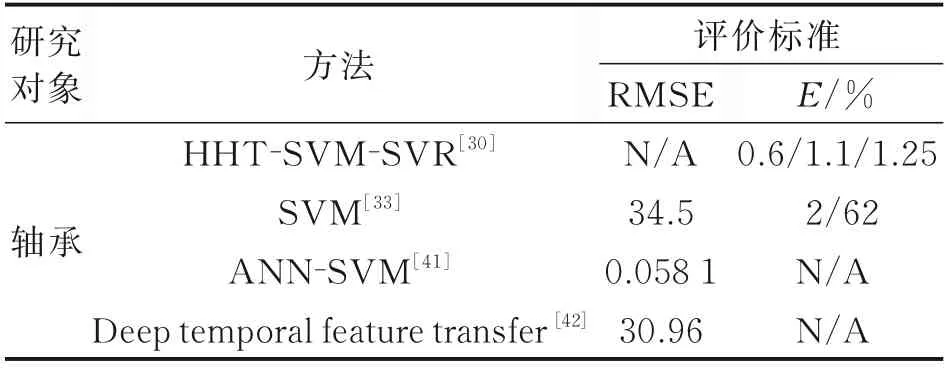
表1 基于SVM 方法的RUL 预测性能Table 1 Performances of RUL prediction based on SVM
2.2.2 维纳过程
维纳过程是布朗运动的数学模型。以X(t)表示运动中一微粒在时刻t在X轴的位置。X(t0)=x0,x0为微粒在时刻t0的位置,用p(x,t|x0)表示X(t0+t)=x的条件概率密度,则有

假定p(x,t|x0)与初始时刻t0无关,且当t趋于零时,有X(t0+t)的值无限趋近于初始时刻X(t0)的值,则有

根据中心极限定理,微粒的位移服从正态分布,即
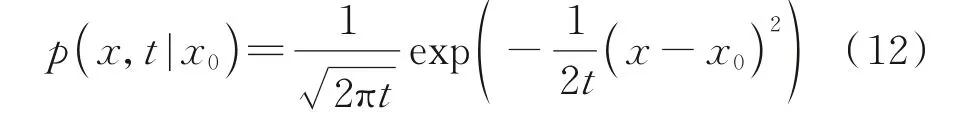
如果随机变量X(t)满足:(1)X(0)=0,且在t=0 连续;(2)具有独立增量;(3)对∀t>s≥0,有X(t)-X(s)~N(0,σ2(t-s)),σ>0;(4)对于任意两个互不相交的区间[t1,t2]和[t3,t4],随机变量X(t)的增量X(t2)-X(t1)和X(t4)-X(t3)相互独立。则称此随机变量X(t)服从维纳过程分布。维纳过程有许多种的变形,例如线性带漂移维纳过程、非线性带漂移的维纳过程以及集合布朗运动等。
学者们假设设备随时间的退化是一个维纳过程,提出了一种新的随机退化过程RUL 预测方法来更准确地预测退化早期阶段的RUL[43]。该方法以核函数加权和为漂移增量的维纳过程来建模退化过程,然后通过LSTM 预测未来退化增量,最后导出了一个数值近似的RUL 分布,并量化预测RUL。文献[44]提出了一类具有自适应漂移的维纳过程模型,该模型利用了布朗运动的自适应漂移和基于极大似然估计的模型估计方法,建立了锂离子电池的RUL 预测模型,展现了良好的预测效果。有学者假设产品随时间的退化是可以由Frank copula 函数来表征它们之间依赖性的维纳过程,于是提出了一种基于二维退化数据的自适应RUL 估计方法[45],该方法使用具有测量误差的二元维纳过程模型用于建模退化测量,结合基于群体的退化信息和被监测产品的退化信息,采用马尔可夫链蒙特卡罗(Markov chain Monte Carlo,MCMC)方法获得参数值,对未知参数进行序列估计得到RUL。为了描述表现出非线性、时间不确定性、项目间可变性和时变退化的退化行为,另一种具有自适应漂移的基于广义维纳过程的退化模型被提出[46],首先利用期望最大化算法来在线估计所有其他模型参数,而不需要来自同一批次中相同系统的基于群体的退化数据;然后结合隐藏漂移的不确定性,导出RUL 分布的解析近似的封闭形式;最后对实际铣削数据实现了良好的RUL 预测。
测量误差(Measurement error,ME)是测量数据的不确定性来源之一,对数据驱动寿命估计的性能影响很大。文献[47]提出一种基于维纳过程测量误差(Wiener process measurement error,WPME)的锂电池RUL 预测方法。该方法首先采用基于截断正态分布的估计退化状态建模方法,同时考虑测量不确定度和估计漂移参数分布,得到了精确的、封闭的RUL 分布;然后对基于总体的参数估计的最大似然估计方法进行改进,提高了RUL 预测效率。随后又提出一种具有测量误差的非线性维纳退化过程闭合形式的近似解析RUL 分布[48],采用极大似然估计方法对模型中未知的固定参数进行估计,再利用贝叶斯方法更新随机参数,最后仿真结果表明,在退化过程中考虑测量误差可以显著提高实时RUL 预测的精度。文献[49]提出了一种基于序贯贝叶斯更新的维纳过程模型用于RUL 预测,序贯方法采用上一次随机漂移参数的贝叶斯估计作为下一次随机漂移参数的先验;首先构建基于随机漂移效率的维纳过程的线性退化趋势模型;然后基于最大似然估计方法,确定初始模型参数;最后基于首次通过时间的概念,推导出了RUL 分布的解析表达式。文献[50]证明了用最大似然估计方法估计维纳过程的参数是有偏差的,于是构建了一种基于维纳过程一致性检验的RUL 预测模型;该模型在小样本的情况下,取得了高于经典的最大似然估计方法的估计精度。对于许多工业系统,由于外部操作条件和内部机制的变化,其退化轨迹往往呈现两相模式,在实际应用中,每一相的退化过程都表现出非线性特征,用线性维纳过程建立两相模型往往是不够的。Lin 等提出一种两相退化产物的新RUL 预测方法[51],首先采用非线性维纳过程的退化模型来描述两阶段退化轨迹,然后分别使用最大似然估计和贝叶斯方法求取模型的未知参数并更新参数,最后根据初始态跃迁到变化态的随机性和不同单元退化的可变性,导出首次穿越时间概念下RUL 的近似解。在另一项研究中,基于电荷剖面信息间接提取出两个健康指数,参考文献[45]建立了二维维纳过程模型来表征电池退化过程[52],利用最小二乘算法对参数进行估计后,得到了RUL 的概率密度函数,此外,维纳过程结合其他方法的应用也越来越多。文献[53]采用具有随机漂移、扩散系数和测量误差3 个状态变量的维纳过程来表征电池容量退化过程,并使用基于粒子滤波的状态与静态参数联合估计方法,迭代更新后验退化模型,同时估计单个电池的退化状态。
基于维纳过程的RUL 预测研究对象过于分散,且采用的判定标准不一致,故在此未列表展示近期研究成果的定量对比。基于维纳过程的RUL预测会伴随着大量的公式推导以及计算,虽然具有很好的可解释性,但是其准确率表现并不优异,且随着其他数据驱动方法的快速发展及高准确率的表现,基于维纳过程的RUL 预测研究呈现了一种下降的趋势。
2.2.3 高斯过程回归
GPR 是由Williams 等在1995 年提出[128],其原理是用历史样本对预测模型进行训练,然后用测试样本作为模型输入,得到具有概率显著性的预测结果。GPR 适合处理复杂的回归问题,如高维、小样本和非线性等。与神经网络和SVM 相比,该方法具有易于实现、超参数自适应获取和概率输出等优点。GPR 是一种贝叶斯回归技术,其联合分布是有限子集的多元正态分布。它由均值函数和协方差函数参数化。对于标量输入和输出,高斯过程定义为
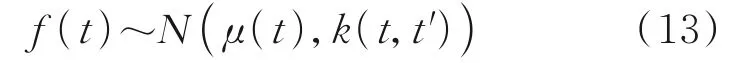
式中:μ(t)为均值函数,k(t,t′)为协方差函数。为了回归,假设先验均值μ(t)=E(f(t))为零。协方差由所选核指定,核函数有常数、线性、母函数、径向基函数和多核合成等多种选择。常用的指数平方函数用来表示协方差。它是一个平稳核,定义为

式中:σ为超参数方差,l为长度尺度。
在实际应用中,f(t)是难以获取的,实际上都是含有噪声的观测数据y=f(t)+ε,ε~N(0,σ2n)是服从独立同分布的高斯白噪声,σn是噪声的标准偏差。任意有限个观测值可以形成一个高斯过程,即
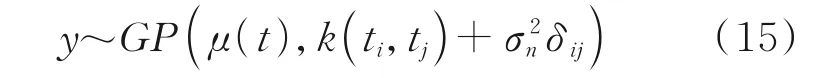
其中当且仅当i=j时δij=1,否则δij=0。
引入噪声项后,根据高斯过程的定义,观测值和新样本点处的函数值是有限数量的随机变量,服从联合高斯分布

式中:I为单位矩阵,K(T,T)为训练数据的协方差矩阵,K(t*,t*)为测试处的方差,K(T,t*)为N×1 协方差向量,且K(t*,T)=KT(T,t*)。
根据贝叶斯原理以及联合正态分布的条件概率特性有
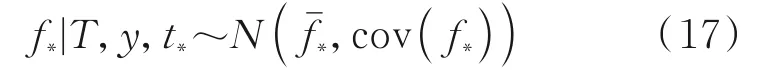
式中

因此,f*的后验分布可以用来对新样本点进行预测。是高斯过程模型在新的样本输入t*的预测值,置信区间由cov(f*)描述。
使用GPR 构建的通用健康模型被用于预测在各种使用场景下的电池容量退化[54],在这里GPR 以多种方式利用先验信息,多输出GPR 有效利用不同单元数据之间的相关性,能够实现对锂电池的容量和周期数据短期和长期RUL 预测。多输出GPR 也与代谢灰色模型结合[55],模拟电池复杂的退化行为;再利用PF 跟踪电池容量退化进行健康状态估计,并外推退化轨迹进行RUL 预测。为了实现多步预估,利用改进的GPR 方法结合高斯过程函数回归(Gaussian process functional regression,GPFR)来捕捉健康状态的实际趋势,包括全局容量退化和局部再生[56],可以有效地应用于锂电池的监测和预测。GPR 也适用于功率金 属 氧 化 物 场 效 应 晶 体 管 器 件(Metal-oxide-semiconductor field-effect transistor,MOSFET)RUL 预测[57],该方法以MOSFET 导通电阻为研究对象,分别以GPR 算法探讨数据驱动技术,以扩展卡尔曼滤波和粒子滤波探讨基于模型的技术,两种方法均能得到有效的RUL 预测结果。文献[58]将部分增量容量和GPR 结合的混合方法用于电池的短期健康状态估计和长期RUL 预测,利用混合方法的同时利用双高斯过程回归模型对电池健康状态进行了预测,根据电池健康状况值和以往输出的结果,建立了电池长期剩余有用寿命自回归模型。
深度高斯过程算法利用高斯过程对层间映射进行建模,再使用矩阵变量高斯分布对给定层间与节点间相关性进行建模[59],该算法利用局部充放电时间序列数据(电压、温度和电流)进行容量估计,并估计容量和运行时间之间的统计相关性,从而实现了RUL 预测。锂电池由于自充电和容量再生,退化轨迹具有多模态特性,高斯过程混合(Gaussian processes mixture,GPM)的RUL 预测方法被用来描述这种多模态[60],通过对不同退化模型的不同轨迹段进行拟合,可以揭示轨迹段之间的微小差异,从而实现多模态处理;此外,GPM 可以生成预测置信区间,使得预测比传统模型更加可靠。Kang 等提出一种基于模糊评价高斯过程回归(FE-GPR)的RUL 预测方法[61],首先对观测数据进行模糊评价预处理,然后利用重力搜索算法与历史数据有效结合,优化分类节点,最后利用该方法强大的数据提取能力,实现准确的RUL 预测。将状态空间模型和高斯过程相结合,Mohanty 等提出了一种适用于飞机变幅服役载荷的金属合金疲劳裂纹扩展混合模型[62],将FASTRAN-11 模型中的裂纹闭合状态变量公式与采用基于核的高斯过程回归模型相结合,构建了等效于无限神经元的神经网络模型的物,该模型能够更好地预测疲劳裂纹长度和扩展速率。
如表2 所示,展示了高斯过程回归在锂电池[25]RUL 预测上的应用。改进的高斯过程回归方法[56]将RUL 预测的RMSE 降低到2.69。双高斯过程回归模型[58]的使用将RMSE 进一步降低。具有多模态处理能力的高斯过程混合的方法[60]将RMSE 大幅度缩小。可以看出随着模型的改善,预测结果变得更加准确。FE-GPR 方法也展现出了较高的准确率[61]。

表2 基于GPR 的RUL 预测方法Table 2 RUL prediction method based on GPR
2.2.4 相似性方法
Wang 等在2008 年PHM 数据挑战竞赛中提出一种基于轨迹相似度(Trajectory similarity based prediction,TSBP)的RUL 预测方法[64]。使用大量的具有完整生命周期的传感器数据构建出同一系统下不同航空发动机的退化模型库,对于测试单元也构建出退化曲线,并将两者进行匹配以获取测试单元的RUL。如图4(a)所示,TSBP 方法包括3 个基本步骤[65]:(1)退化轨迹抽象——从训练实例的退化轨迹构建实例/局部模型;(2)相似度评价——根据退化轨迹评价一个测试实例与每个实例模型之间的相似度,将从每个实例模型中获得一个RUL 估计;(3)模型聚合——将所有实例模型得到的RUL 估计进行聚合,得到最终的RUL 预测。从那时起,各种方法被开发来扩展轨迹相似度预测。随后,一种广义相似度预测方法被提出来[66],在衡量系统与其他参考系统的相似性时,赋予系统最近的时间比以前的时间更多的权重,体现出系统退化过程中后面数据的重要性。2014 年,在TSBP 中使用基于皮尔逊相关性的相似线性回归和动态时间规整进行相似性预测方法被提出[67],使用该方法选择出最符合测试数据的退化模型,然后量化RUL 预测中的不确定性,在相同的数据及评判标准下取得了优于TSBP 的结果,提高了相似度预测的性能。提高相似度度量准确度也是改进的方向,分段式相似性度量方法被提出[68],使用一个固定长度的窗口,切割对比的两条曲线,形成两个线段集合,再将两个集合中的线段去做相似性对比,同时给予靠后位置的线段以更高的权重。该方法提高了相似性度量的准确性,在保持其他预测模块不变的情况下提高了RUL 预测的准确度。
在探究提高相似性方法的路上,文献[69]另辟蹊径,从多参数方面入手,使用相关性Spearman 系数从设备退化数据中选取关键参数,同时由系数大小进行权重分配。如图4(b)所示,不同于多参数共同构建一维退化曲线,每个关键参数都构建出对应的退化曲线,从而形成相应参数的退化模型库,测试数据便得到多个关键参数预测而来的RUL值,再通过相应参数的权重,加权融合实现装备系统的RUL 预测,关键参数的选取以及RUL 预测值的加权融合使得预测精度得到提升。类似方法也被应用于刀具的RUL 预测[70],充分利用历史数据,对海量复杂的原始监测数据进行挖掘与融合,构建出刀具的健康指数(Health index,HI)曲线,不同于TSBP,同时考虑距离相似性和空间相似性,提高了相似性的准确度,取得了更加准确的预测结果。针对TSBP 只能提供RUL 的点估计,不能适用于某些特定预测的问题,寻求一种能够提供RUL 预测置信区间的方法;Huang 等提出一种将自适应核密度估计技术与β准则相结合,扩展RUL 估计模块的框架的改进方法[71];改进后的TSBP 方法不仅能够提供准确、精确的RUL 点估计,而且能够在一定的置信水平下量化RUL 预测的不确定性,在增强TSBP 方法的不确定性管理能力的同时拓宽了TSBP 方法的应用场景。文献[72]从数据角度出发,考虑到之前提出的预测方法中对航空发动机原始数据的处理总是不太完美,由此将具有强大数据处理能力的神经网络引入到数据处理中去,如图4(c)所示,设计了一个神经网络拟合模型,用来构建原始数据输入和HI 输出的映射,再通过相似性算法实现测试实例的RUL 预测,该方法克服了短时测试数据的缺陷,并提高了关于预测指标的预测性能。2021 年提出结合自编码器神经网络的基于多时间尺度健康指标相似性的预测方法(AE MTS-HI)[73],如图4(d)所示,采用了类似于文献[72]的方法,引入非监督式神经网络的自编码器构建原始数据输入和HI 输出的映射,在相似性算法的实现上增加了多时间尺度的思想,根据测试轨迹长度选取不同时间长度的部分轨迹,与退化模型库中的退化轨迹进行相似性匹配,再以相似距离作为加权标准,求得不同时间长度轨迹对应的最优RUL 预测值,最后将所有时间长度下的RUL 预测值取平均,得到最终RUL 值。


图4 基于相似性的RUL 预测方法Fig.4 RUL prediction methods based on similarity
表3展示了相似性方法在航空发动机[26]RUL 预测的应用。TSBP 方法在2008 年PHM 数据挑战竞赛中以5 636.06的惩罚分数摘得桂冠[64],文献[72]通过神经网络滤波将惩罚分数进一步减小。增强的相似性方法大幅降低了惩罚分数,结合自编码器神经网络的基于多时间尺度健康指标相似性的预测方法将惩罚分数进一步缩小。随着研究的深入,相似性方法与神经网络结合将是未来发展的大方向。

表3 基于相似性的RUL 预测方法Table 3 RUL prediction method based on similarity
2.2.5 神经网络方法
ANN 是由大量的处理单元(神经元)互相连接而形成的复杂网络结构,是对人脑组织结构和运行机制的某种抽象、简化和模拟,图5(a)所示为简单的神经网络模型。ANN 可以实现仿真、二值图像识别和预测等功能,是处理非线性系统的有力工具。神经网络的短期趋势预测和基于多项式拟合相融合的RUL 预测方法被应用于风电齿轮箱[74],其预测流程如图5(b)所示,首先对采集到的振动数据进行频谱分析,得到轴承故障,接着计算并选择反映故障部件退化趋势的特征指标作为预测对象,同时设置各特征指标的阈值,然后再使用神经网络预测所选特征指标的短期趋势并拟合表征特征指标长期趋势的多项式曲线,通过观察历史和短期预测特征的形状确定拟合曲线的类型,最后通过计算拟合曲线与预先设定的阈值的交点来估计RUL。文献[75]应用ANN 和自适应神经模糊推理系统建立的预测水管鲁棒性的计算模型来训练和测试获得的现场数据,能够有效识别影响RUL预测的重要参数。随着神经网络的发展,深度神经网络(Deep neural networks,DNN)也被应用到RUL 预测中,文献[76]提出分层深度神经网络的RUL 预测方法。该方法为每个健康阶段构建RUL 模型,最后应用平滑算子得到更精确的RUL预测值。反向传播(Back propagation,BP)神经网络是一种通过迭代优化实现的有监督学习算法,用于解决分类或回归问题,一种改进的BP 神经网络被用来实现飞机发动机RUL 预测[77],该方法采取在损失函数中加入一个相邻差分项的方法来适当增加正则化,这种相邻差分BP 神经网络设计能够更好的学习退化过程中任意一点与对应RUL 之间的映射关系,有较好的预测精度。考虑到误差对BP 神经网络精度的影响,UKF 与BP 神经网络被结合起来,首先利用UKF 算法获得基于估计模型的预测,并建立原始误差序列,然后误差序列被BP神经网络用来预测UKF 未来残差,最后使用预测残差修正UKF 的预测结果,实现锂电池的RUL 预测[78]。文献[79]使用自组织映射(Self-organizing map,SOM)获取最小量化误差指标,训练聚焦于退化周期的BP 神经网络,建立了一种实用的滚珠轴承RUL 预测模型,相比于式(7)具有更高的预测精度。文献[80]构建了一个综合评价函数来选择优良的时域、频域和时频域退化特征,并使用SOM网络将特征融合成一维HI 曲线,构建出表征风力发电机组健康状态的HI 曲线。在此基础上采用果蝇优化算法优化的改进PF 对小风力涡轮机变速箱的剩余使用寿命进行预测[81]。
CNN 是典型的深度学习模型,基本结构由输入层、卷积层、池化层、全连接层和输出层组成。考虑到CNN 强大的特征提取能力,基于双CNN 模型结构的智能RUL 预测方法被提出[82]。如图5(c)所示,具体预测过程包括两个阶段:首先利用第1个CNN 模型和提出的“3/5”原则识别出初始故障点;然后构建第2 个CNN 模型进行RUL 预测。为了反映RUL 估计与健康状态检测过程的相关性,卷积神经网络与多任务学习(Multi task learning,MTL)方法结合[83],组织了一个共享网络和两个特定于任务的网络。如图5(d)所示,在MTL 模型中,利用卷积神经网络层作为共享层的基本结构,从复杂信号中提取全局特征,原始传感器数据直接输入到基于CNN 的MTL 结构中,利用多变量1~D 滤波器进行特征提取,反映了多传感器数据之间的时变关系。为了提高滚动轴承缺陷渐进状态下RUL 的预测精度,提高对个体差异和振动特征波动的鲁棒性,Kitai 等在2021 年提出了一种基于CNN 和层次贝叶斯回归的RUL 预测框架[84],通过考虑RUL 的退化条件和个体差异,可以生成具有概率分布的单调RUL 预测曲线,提高RUL 预测精度。文献[85]引入可以同时提取正向和反向特征的双向长短期记忆网络(Bi-directional long-short term memory,BiLSTM),提出了一种基于CNN 和BiLSTM 网络的双通道混合预测模型从原始传感器数据中提取深层特征。这种混合模型将从第1通道和第2 通道提取的特征数据矩阵串联起来,输入到全连接层中,并采用丢失输出(Dropout)技术来防止过拟合,然后利用包含神经元的回归层对目标RUL 进行预测。随着CNN 的发展,可转移卷积神经网络(Transferable convolutional neural network,TCNN)也被提出,并结合多核最大平均差异用于RUL 的预测[86]。该方案利用多层CNN 同时提取源域和目标域样本的退化特征,利用多核最大平均差异测量提取两个域之间的分布差异并与源域的预测误差相结合形成优化目标,再采用Adam 优化器对TCNN 进行训练,最后将测试数据输入训练好的TCNN,输出RUL 预测值。一种基于多层自关注和时间卷积网络的RUL 预测方法被提出用来改善CNN 网络过深时容易出现梯度消失的问题[87]。该方法首先利用多层自关注对不同通道和不同时间步自适应分配权重,然后通过采用了扩张卷积和剩余连接的TCN 得到数据的特征,最后有效预测了涡扇发动机的RUL。

图5 基于神经网络的RUL 预测方法Fig.5 RUL prediction methods based on neural network
DCNN 也被用于RUL 预测,使用新的特征提取方法在时域和频域上针对不同类型的数据在不同场景、不同预测模型相结合,得到适合于DCNN的特征,将所提取的特征输入到DCNN 中进行轴承的RUL 预测[88]。同样为了提高预测模型的自适应性,将自适应批量归一化(Adaptive batch normalization,AdaBN)与DCNN 相结合,将滑动时间窗和改进的分段线性RUL 函数也引入其中,提出一种自适应性RUL 预测模型[89]。该AdaBN-DCNN模型不仅可以提高预测的准确性,而且可以适应不同神经网络下的预测任务。Yang 等提出一种新型DCNN 使用多个卷积核组成的核模块用于特征提取,降低了时间维度上的参数,并能够利用任意时间间隔内连续时间样本的数据进行RUL 预测[90]。该网络所设计的新的预测内核模块,可以自动选择内核,进一步提高了网络的特征提取能力。随后采用贝叶斯优化方法自动选择网络结构和超参数改进AdaBN-DCNN 模型[91],能够对不同数据域具有自适应能力,并且能够在更短的时间内建立性能更好的RUL 预测模型。类似于文献[83]的多任务学习,多尺度也被应用到深度卷积神经网络中,提出了多尺度深度卷积神经网络(Multi-scale deep convolutional neural network,MS-DCNN)[92],MS-DCNN有3 个多尺度块,在每个块上并行地进行3 种不同大小的卷积运算。通过提取不同尺度的特征,提高了网络学习复杂特征的能力。Zhang 等提出了自适应时空图卷积神经网络[93],在空间领域以动态图神经网络来学习传感器的空间关系;在时域中利用堆叠的扩展1D-CNN 来捕获传感器输入信号的长距离依赖性。这两个部件组合在一起实现了涡扇发动机数据的性能预测。随后他们改变之前空间领域处理方式,提出ASTGNN-M 和ASTGNN-A 两个空间图卷积层,从时变信号中自适应学习空间结构,建立了高阶时空特征学习的自适应时空超图神经网络模型[94],该模型能够更有效地学习传感器信号的图和超图结构,并在测试中取得优于自适应时空图卷积神经网络的性能。
RNN 具有记忆性,在对序列数据的非线性特征的学习方面具有很大的优势,结构如图6(a)所示,因此,RNN 在RUL 预测方面同样体现出了巨大的潜力。Guo 等提出一种基于RNN 的轴承RUL 预测健康指标(Recurrent neural network based health indicator,RNN-HI)[95],首先将相关相似度特征与经典时频特征相结合,形成原始特征集;然后利用单调性和相关性度量,选取最敏感的特征;最后将选择的特征送入RNN 来构建RNN-HI,有利于承载RUL 预测。不同于前者使用RNN 来构建HI,一种新的循环卷积神经网络(Recurrent convolutional neural network,RCNN)框架被提出[96],首先构造递归卷积层来建模不同退化状态的时间依赖性,然后利用变分推理对RCNN 在RUL 预测中的不确定性进行量化。Dong 等提出将RNN 与LSTM 结合进行RUL 预测[97],首先利用LSTM 单元来捕获和记忆传感器信号的数据特征,再通过RNN 学习所有产品故障数据的特征,最后生成估计模型,映射RUL 的向量信息。回声状态网络(Echo state network,ESN)是RNN 的一个分支,经典RNN 中的梯度消失问题在ESN 中可以得到避免,这使得ESN 适合处理长期依赖关系时间序列。不同于文献[57],使用基于ESN 的预测方法来估计MOSFET 的RUL[98],该方法将导通电阻作为健康指标,通过输入历史运行到故障数据和粒子滤波方法来训练基于ESN 的预测模型,实现实时RUL 预测。基于相似度的方法与ESN 相结合,也可以实现RUL 预测[99],首先,采用PCA 对数据进行预处理,得到退化轨迹,然后采用欧氏距离计算不同退化轨迹之间的相似度,最后使用相似度最高的轨迹在ESN 中进行训练,有效地预测了航空发动机的退化轨迹。

图6 用于RUL 预测的网络结构Fig.6 Network architectures for RUL prediction
LSTM 是为了解决一般的RNN 存在的长期依赖问题而专门设计出来的,如图6(b)所示,由于它独特的设计结构,使得LSTM 更适合处理和预测时间序列中间隔和延迟非常长的事件。文献[100]提出了一种基于LSTM 的航空发动机故障诊断与RUL 预测,该方法能够在复杂运行模式和混合退化情况下提供准确的RUL 预测和故障发生概率。另一种基于混合长-短序列的发动机RUL 预测模型针对长序列和短序列分别利用LSTM 和梯度推进回归法实现[101],然后利用BP 神经网络对长序列与短序列的RUL 结果进行分析,得到混合序列预测结果。考虑到CNN 的强大特征提取能力,构建了基于卷积和长期短期记忆循环单元的端到端深度鲁棒估计框架[102]。如图6(c)所示,该神经网络首先利用卷积层直接从传感器数据中提取局部特征,然后引入LSTM 层捕捉退化过程,最后利用LSTM 输出和预测时间值估计RUL。同样结合了LSTM 和CNN 的有向无环图(Directed acyclic graph,DAG)网络被用来预测RUL[103]。这种DAG 网络有LSTM 和CNN 两条路径。这两条路径之间没有相关性,考虑到两条路径的输出会影响RUL 预测,采用了不同于文献[101]最后添加的BP 神经网络,构建的DAG 网络是一个整体模型,可以根据预测误差对网络中的各个参数进行校正,对涡扇发动机展现了优秀的RUL 预测能力。全卷积层一维卷积神经网络(1-FCLCNN)也与LSTM 相结合[104],对多场景、多时间点数据进行有效特征提取,以提高RUL 预测精度。使用LSTM 和1-FCLCNN 分别提取数据集的时空特征,然后将这两种特征进行融合,作为下一个CNN 的输入,从而获得目标RUL。为了减少训练时间,提高网络性能,提出了一种简化的改进于LSTM 结构网络的门控循环单元(Gated recurrent unit,GRU),如图6(d)所示,将LSTM中的门数从4 个减少至GRU 中的2 个,该网络一经提出很快得到了大量的应用,由此提出一种基于门控循环单元的循环神经网络预测非线性退化过程的RUL[105]。使用一种能通用的两步法预测非线性退化过程的RUL 方法来解决退化建模中的非线性问题,首先使用核主成分分析进行非线性特征提取,通过减小维数,有效地避免模型参数过多而引起的过拟合;最后,利用参数更少的LSTM 简化网络GRU,用于预测RUL。
也有其他新型神经网络方法也被提出用来进行RUL 的预测,文献[106]研究了退化过程如何受到单元特定操作条件的影响,提出了一种基于非线性自回归神经网络的预测建模方法,用于计算动态运行条件下退化系统的RUL。该方法包括两个过程:(1)基于数百个相同单元的运行到失效时间序列传感器数据集,建立离线训练过程,对退化规律和失效区域进行建模;(2)构建在线预测流程,对测试单元的RUL 进行预测。
表4 中研究对象为航空发动机[26]与轴承[24]。通过其与表1、3 的对比,可以看出神经网络在RUL 预测上的巨大优势。得益于神经网络强大的特征提取能力和非线性模型构建能力,神经网络的应用使得RMSE 有大幅度的降低。CNN 通过与其他方法的组合将RMSE 逐步降低,DCNN 在预测中展现了略优于CNN 的效果。各种方法的组合能够合理运用各方法的优势,并弥补其他方法的不足,使得RUL 预测更加倾向于多方法的组合运用,而不是单方法预测的小幅提升。因此RUL 预测的未来发展方向将更大可能向多方法的融合方向进行研究。
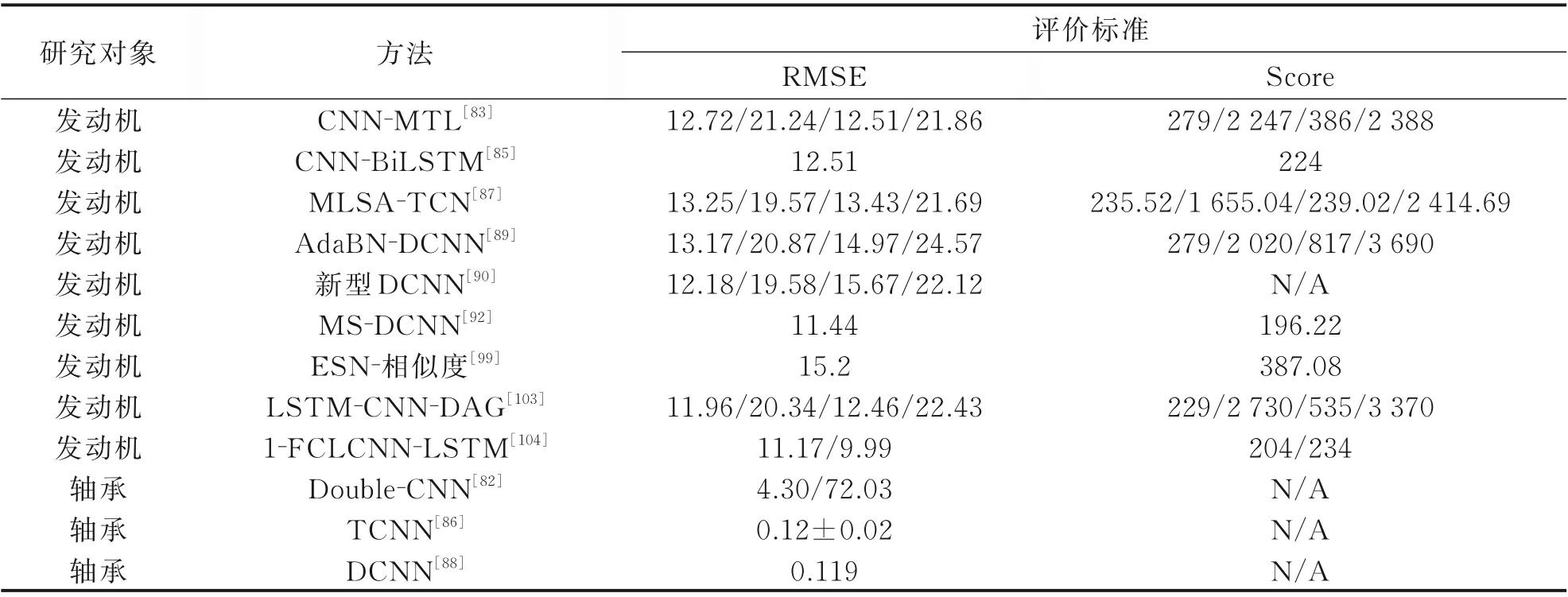
表4 基于神经网络的RUL 预测Table 4 RUL prediction based on neural networks
2.2.6 对抗学习与迁移学习
生成对抗网络(Generative adversarial network,GAN)是2014 年由Goodfellow 等[107]提出的一种网络训练框架,该框架仅有两个组成部分:生成器和判别器。GAN 的核心思想来源于博弈论中的零和博弈,其中生成器通过学习训练集数据的特征,在判别器的指导下,将随机噪声分布尽量拟合为训练数据的真实分布,从而生成具有训练集特征的相似数据。判别器用来判断数据是真实的还是生成器生成的假数据,并反馈给生成器。两个网络互相反馈训练,直到生成器生成的数据能够通过判别器的真实性判断。
GAN 多用于小样本数据的增强,以改善数据不足的困境。文献[108]为了解决行星齿轮箱故障诊断的故障样本数量较少的问题,使用GAN 进行数据扩充,再使用堆叠去噪自编码器方法实现故障诊断。基于信息最小二乘生成对抗网络[109],同样用于行星轮轴承数据的扩充,结合行动者-评论家算法实现滚动轴承剩余寿命预测。随后又将门控循环单元神经网络与条件生成对抗网络相结合,构建C-DRGAN,再结合动作探索方法同样实现滚动轴承剩余寿命预测[110],并将预测平均准确率由95.84%提升至96%以上。半监督生成对抗网络回归模型利用条件多任务目标函数从悬架历史中捕获有用的信息,将相似的故障与悬架历史之间的统计信息进行最大程度的匹配[111],通过对抗性训练,模型对噪声和多模态数据的泛化效果显著提高,由此提高了RUL 预测效果。对抗网络也被应用到DNN 模型训练中,文献[112]中构建了包含一对与单调性相关的和一对与范围相关的对抗神经网络,在每对网络在迭代中进行对抗比较,直到满足模型要求。
GAN 在无监督学习和迁移学习方面有着优异的性能,它可以利用有限的标记数据和丰富的非标记数据提供更高的分类精度。文献[113]在不平衡数据集上训练不同架构的CNN 模型与GAN 在交互模式下工作,训练多个CNN 的集合,然后对罕见类生成对抗样本,进一步细化集合模型,实验表明此方法能一定程度上提高某些类别的性能。一种新的基于GAN的主动半监督学习方法(Active semi-supervised learning with GANs,ASSL-GANs)[114],利用GAN进行主动半监督学习,在鉴别器、生成器和分类器之间进行对抗或合作学习,用来研究标记样本和未标记样本之间的潜在相关性,以充分获得数据分布的洞察力。精准的分类和数据打标有助于RUL 预测准确性的提升。
迁移学习和GAN 都是为了应对发生失效的数据难以收集或数据不足的情况。不同于GAN去生成数据,迁移学习是利用目前已有预测模型迁移到相关研究中去提高RUL 预测性能。文献[115]提出了一种基于双向长短时记忆(Bidirectional long short term memory,BLSTM)递归神经网络的迁移学习算法,该算法首先在不同但相关的数据集上训练模型,然后RUL 预测模型从源域迁移到目标域,再由目标数据集进行微调,取得了更好的效果。文献[116]使用自组织共识模型搜寻不同领域中的数据差异,并进行知识的迁移,取得不输于传统及其他方法的预测效果。稀疏自动编解码器的编码器部分也可以进行参数迁移[117],随后固定编码器部分参数,以目标域的数据更新解码器部分参数的形式进行模型的迁移,实现了在刀具数据上的有效迁移。迁移成分分析法被用来提取不同轴承的公共特征[118],然后以物理特征迁移的方式将特征输入到支持向量机,实现轴承RUL 预测。基于多层感知器(Multilayer perceptron,MLP)的迁移学习被用来解决分布差异问题,构建了RUL预测和域适应两个模块[119],RUL 预测模块负责找出提取的特征与相应的RUL 之间的关系;域自适应模块通过域分类器和域分布差异度量获得域不变特征。实现了一种工况下有标记数据训练的RUL 预测模型有效地预测另一种工况下无标记数据的RUL。在迁移学习的基础上提出由条件识别模块和域适应模块组成的深度卷积迁移学习网络[120],与非迁移学习方法相比,有着更高的轴承健康状态识别精度。
对抗性训练也是迁移学习常用的方法,通过建立源域与目标域之间的映射,将域分布差异调整到最小,便可将源域学习到的知识应用于目标域,实际上就是以博弈思想为核心的对抗式训练来实现迁移学习。文献[121]提出利用LSTM 进行预测的域适应方法,使用领域对抗神经网络的方法,以适应剩余有效寿命估计的目标领域传感器信息,该方法对于不同的运行条件和故障模式,能够提供更可靠的RUL 预测。另有学者同样使用LSTM 网络作为时间特征提取器,并进行类似于对抗判别域自适应的对抗学习,以学习领域中的不变特征[122],该方法在重载货车车轮的磨耗数据进行了有效的RUL 预测。
对抗学习与迁移学习是近年来兴起的深度学习方法,有助于解决基于数据驱动模型的RUL 预测中最关键的数据问题,因此相关研究有着爆发性增长的趋势。对抗网络扩充数据后,相关研究对象的RUL 预测效果随着数据量的增强都有一定的提升。迁移学习使得模型的建立变得简单,能够有效利用同类型数据,从而降低建模成本,提高数据有效利用率。对抗性训练为迁移学习提供了优化的参数迁移方式,通过无监督学习便可实现参数有效迁移。
3 总结与展望
本文对基于物理模型和数据驱动模型的RUL预测方法的优缺点进行比较,如表5 所示。物理模型直接从基本原理和对物理机制的理解中导出。当对系统拥有可用且足够完整的逻辑认知时,物理模型往往显著优于其他类型的模型。但是许多实际系统和组件的基础物理知识不确切或不可用,而且其中完整逻辑的获取十分困难。一般情况下,导致失效的底层物理过程并没有被完全理解,必须简化假设以促进模型开发。在物理模型开发中做出的假设可能不完全适用于现实世界的系统,从而限制了失效模型的适用性。而且对于大型、复杂的系统来说,失效模型的物理特性通常是不可用的、不精确的或不及时的。另外,因为开发的模型很少能够满足所需的灵活性,以匹配新场景下进行预测的条件,所以应用领域受到很大限制。基于数据驱动模型的RUL 预测就不需要专业知识,可以通过对已有数据的深度挖掘来获取其退化的特征,从而实现RUL 预测。

表5 各种RUL 预测方法优缺点对比Table 5 Comparison of advantages and disadvantages of various RUL prediction methods
支持向量机具有处理非线性映射问题的能力,在样本数量较少的情况下也有优异的表现,这使得支持向量机在RUL 预测中得到了广泛的应用。提高监测数据质量和从监测信息中提取有用特征是重要的研究方向。另外,如今主要研究对象仅包括轴承和电池,对支持向量机的应用进行更多的研究也是具有很大前景的。维纳过程具有良好的数学性质和物理解释能力,它可以很好地描述系统的非单调动态特性。未来需要在预测数据下进行更多的决策研究,增强模型参数的修正。高斯过程回归是一种灵活的非参数贝叶斯模型,允许在函数上直接定义先验概率分布,可以利用高斯过程对函数从输入空间到目标空间的非线性映射进行建模,对高维、小样本、非线性、复杂的分类和回归问题具有良好的适用性。对核函数的研究是一直以来研究的重点,未来的研究应该考虑结合其他方法来扩展其在不同领域的应用。相似性方法主要是基于退化模型的建立来实现基于实例的预测。需要退化模型的有效构建和完整生命周期数据的获取。可以考虑引入数据扩充算法,实现在原始有限数据基础上的扩充。
神经网络方法具有强大的特征提取和非线性映射构建能力,成为当今理论科研和应用研究的热点。但是神经网络存在建模训练成本高昂、模型复杂以及可解释性不强等缺点,导致它的使用受到诸多限制,但是强大的预测能力和提升的算力注定其将是未来RUL 预测研究的重点。结合对抗学习和迁移学习能够解决神经网络中存在的数据不足和模型建立困难的问题。神经网络训练需要大量经验数据的问题可以通过数据扩充的方式来解决,对于传感器数据一般可以采用复制、插值、加噪声和使用生成对抗网络生产数据等方法。另外对于小样本场景,可以考虑在神经网络中加入注意力机制以增加有效特征的权重。对于降低建模训练成本方面,可以使用轻型神经网络减少网络的参数量级。神经网络同样存在泛化性不强的问题,对于不同的预测对象往往需要重新训练模型,因此自适应方法也是学者研究的方向。深度神经网络通常过于复杂,一个神经网络往往涉及巨量计算,学者们很难对其内在工作机理进行解释,这也正是神经网络的痛点。未来学者应该考虑原理性解释与神经网络的结合,有着合理性解释的RUL 预测才是最合理的。
本文总结了近年来对RUL 预测的方法,对基于物理模型和基于数据驱动模型的RUL 预测方法进行综述,并分析其优缺点。最后根据当前RUL预测研究的热点,对未来研究方向提出了发展性建议。
猜你喜欢
黄河之声(2022年10期)2022-09-27
导航定位学报(2022年4期)2022-08-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
现代电力(2022年2期)2022-05-23
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
汽车导报(2017年5期)2017-08-03
