
基于接替性领航机制的多机器人编队
2022-06-28 17:46孙延标黄润才
制造业自动化 2022年6期
孙延标,黄润才
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
人工智能的快速发展,促进机器人系统进入了一个崭新的研究领域,多机器人的编队控制受到越来越多的研究者关注。人们对机器人复杂任务的完成要求越来越高,诸如货物搬运、猎物捕捉以及环境探索等一些任务中,传统的单机器人已经满足不了需求,多机器人编队的引入成为了可行的途径。文献[1]提出了一种多移动机器人编队完成的分布式控制算法,该算法简单易行,适合大量的机器人。按照多机器人编队的体系结构,编队控制主要分为集中式、分布式和分层式三种[2]。集中式是由一个主控单元控制多机器人系统,该方法全局优化能力较高,通常应用在路径规划等方面[3],但灵活性较差。分布式则是各机器人的行为自主决定,该方法灵活可靠,在任务分配方面很广泛的应用[4],但全局目标优化能力较差。分层式是混合了集中式与分布式,机器人之间的协作性较强,文献[5]提出了一种自然启发性的方法用于多机器人的协调合作,平衡了任务的执行。
常用的编队控制方法有人工势场法[6]、虚拟结构法[7]、基于行为的方法[8]以及基于图论的方法[9]等。文献[6]采用人工势场法维持多机器人的队形并规划各机器人的路径,避免了各机器人之间的碰撞,实时性较强,但当势力场较多以及零势能点存在时,机器人会在小范围内往复运动。文献[7]将人工势场法与虚拟结构法相结合,可以有效的形成编队队形以及灵活的队形变换,并且在编队行进过程中很好的避免碰撞障碍物,但由于严格的队形约束会受到频繁的控制指令,通信过载,增加能耗。文献[8]将多机器人的编队任务分解成不同的行为,使用零空间的矩阵理论方法根据一定的优先级融合行为形成最终的队形,有着明确的队形反馈,系统的应变能力较强,但由于行为融合复杂,队形的基本行为无法明确定义,编队控制的稳定性难以得到保证。文献[9]将编队整体看作一个有向图,通过距离反馈控制率设计不同的控制策略形成编队的队形,队形结构稳定,拓扑结构简单明了,但对于稀疏的图,效率较低。这些方法在队形运行时对于领航者机器人本身考虑的较少,然而在一些关键的任务中,如货物搬运、环境探索等编队运行的过程中,当领航者出现通信堵塞时,跟随者接收不到下一步的有关信息,多机器人编队系统将面临崩溃的可能,对能量的损耗、任务的完成有着重大影响。因此合理有效的利用领航者,可以减少通信等待,快速平稳的完成相应的任务。文献[10]随机设置特定领航者模式的通信拓扑关系,根据一致性协议的约束来提高编队控制的稳定性。文献[11]改进非线性模型预测控制,根据树形结构动态分配领航者实现精确的编队控制。文献[12]采用卡尔曼滤波算法预测跟随者机器人的理想位置,有效的解决了领航者机器人的位姿突变问题。文献[13]针对参数不确定性以及输入扰动,采用分层控制—估计算法平衡稳定了具有两层领导者的多机器人编队控制。目前,各类编队的最优控制有着很多的局限性,与实际还有一定的差距,如领航者级别的增加导致控制繁琐满足不了实时的需求;长时间频繁的数据通信对系统的要求偏高以及动态环境下未知因素的欠考虑也会造成影响等。
针对上述研究的一些不足,本文在领航—跟随法的基础上,对多机器人编队领航者本身进行了研究,设计了一种接替性领航机制,当队形运行过程中由传统方法选定的领航者出现通信堵塞时,所有跟随者都有可能作为新的领航者组织队形继续运行。本文将新一轮领航者的选取作为编队性能的重要指标,以各机器人的综合优势作为选取的依据,最终以完整的队形到达指定的地点。
1 领航-跟随法编队的运动学模型
对于领航-跟随法多机器人编队,一般而言,作为领航者机器人的运动学模型可以依据自身的位姿信息来确定,而对于作为跟随者机器人的运动学模型则必须是依据领航者的位姿信息,通过与领航者的相对距离和相对角度来构建自身的运动学模型。因轮式移动机器人的无滑动滚动特征决定了多机器人系统满足非完整约束的条件[14],故在本文中主要以轮式的移动机器人为研究对象,采用与文献[14]相似的表示方式。
1.1 领航者运动学模型
设移动机器人在全局坐标系下的位姿信息为(x,y,θ),其中,(x,y)为机器人对应的位置坐标,θ为方向角,即机器人的线速度方向与坐标轴x轴正方向的夹角,如图1所示,v(t)与w(t)分别表示机器人在某一时刻t下的线速度与角速度。并且机器人的位姿信息可由向量p=(x,y,θ)T表示。
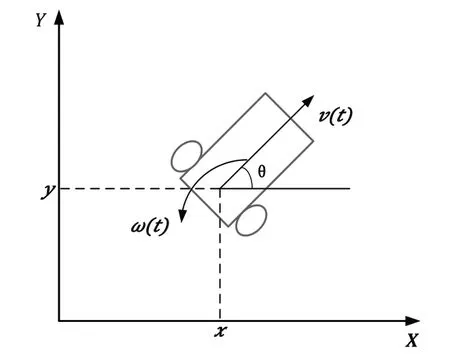
图1 领航者运动学模型
在图2中,领航者机器人的线速度表示为vL,角速度表示为wL,线速度方向与坐标x轴轴正方向的夹角表示为θL;跟随者机器人的线速度表示为vF,角速度表示为wF,线速度方向与坐标轴x轴正方向的夹角表示为θF[15]。将机器人两车轮的轴心线连接的中点作为对象研究的参考点,则领航者与跟随者这2个机器人参考点之间的距离表示为l(L-F),领航者机器人的前进方向即线速度方向与2个机器人参考点连线的夹角表示为φ(L-F)。
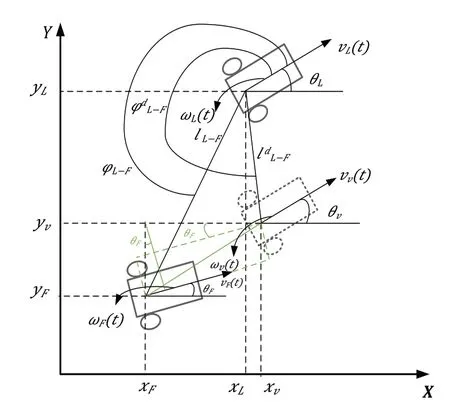
图2 领航—跟随者运动学模型
对于一个领航—跟随法的多机器人编队系统来说,整个团队的运动轨迹通常是由领航者进行决定的,而跟随者到达目标点的运动轨迹往往是由领航者期望的虚拟跟随机器人运动轨迹决定的。设跟随者与领航者形成最终需要达到的期望距离与角度分别为即虚拟跟随机器人与领航者机器人之间的距离与角度分别为虚拟跟随机器人的位置坐标表示为(xV,yV),线速度方向与坐标轴轴正方向的夹角即方向角表示为θV,虚拟跟随机器人的位置点由领航者机器人位置点可得:
由图1可知,可将领航者的运动学模型表示为:
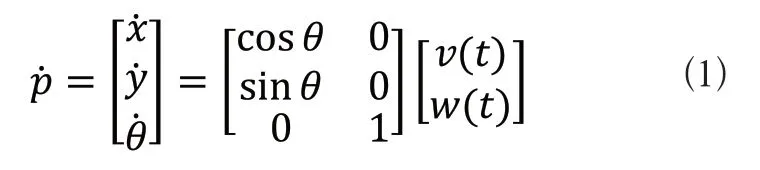
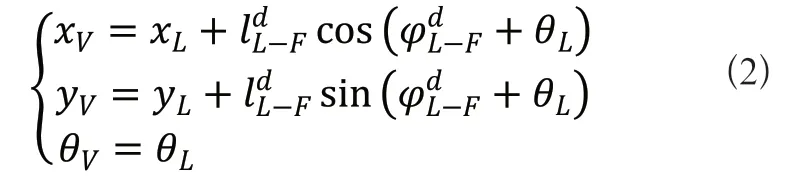
跟随者的位置点由领航者位置点可得:
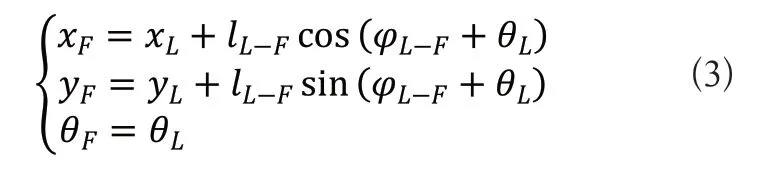
跟随者的位置点与虚拟跟随机器人RF位置点的误差可表示为xF-yF:
1.2 跟随者运动学模型
为了简单方便的描述各机器人在整个编队中的位置,将队形中的领航者机器人标记为RL,任意的跟随者机器人标记为RF,领航者期望跟随的虚拟机器人标记为RV,则领航—跟随法编队控制的运动学模型如图2所示。

通过旋转矩阵,可将其旋转变换到跟随者机器人RF自身的坐标系xF-yF下其误差可表示为:
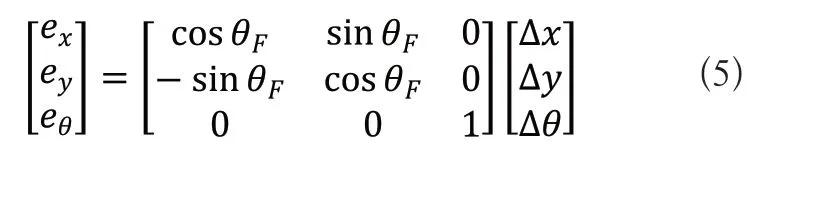
将式(3)和式(4)代入式(5)中可得:
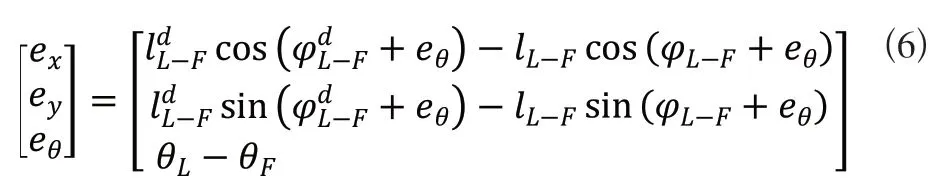
对式(6)的两边求导可得系统的动态误差方程为。
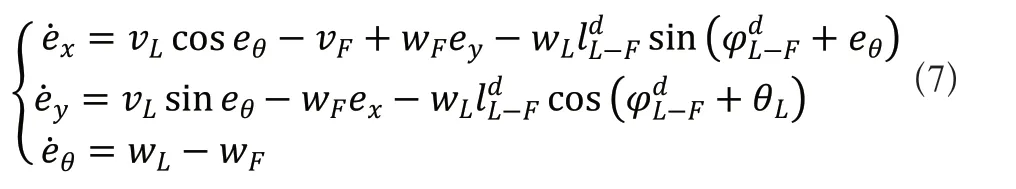
对于虚拟跟随机器人的引入,将多机器人编队的队形保持转换成了实际跟随机器人追踪虚拟跟随机器人的运动轨迹的控制,这种模型的建立可以描述任意多机器人编队的队形。
由上述可得跟随者的运动学模型为:
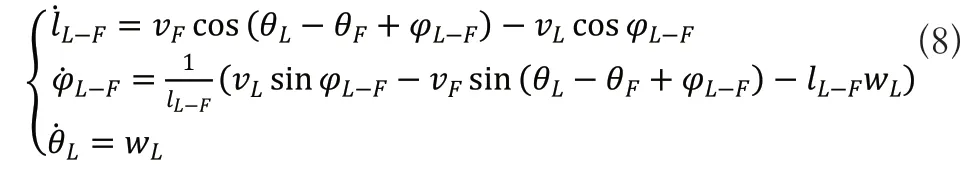
2 接替性领航机制
多机器人协作任务通常是由系统选定一个或多个领航者机器人带领跟随者机器人到达指定的地点,形成需要的编队队形以完成系统设定的任务。当领航者与跟随者出现通信堵塞时,为避免多机器人编队系统崩溃,本文提出一种接替性领航机制,根据各跟随者的综合优势选取新一轮的领航者组织队形继续前进,完成最终的任务。
机器人的综合优势包括距离优势、角度优势与能量优势[16],可用Rc表示综合优势,Rl表示距离优势,Rθ表示角度优势,Re表示能量优势:
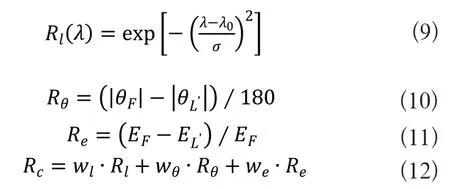
其中,λ0=(λmax+λmin)/2,若令Rl(λmax)=Rl(λmin)=0.05,可得σ=0.6(λmax-λmin),λ为跟随者与上一任领航者的距离;λmax、λmin分别为该跟随者与团队中其他跟随者的最远与最近距离;θF、θL分别为跟随者与上一任领航者的方位角;EF、EL分别为跟随者与上一任领航者的单位能量。根据专家的一些经验,wl,wθ,we的值可取为0.5,0.3,0.2。
根据各跟随者的综合优势,利用匈牙利算法的组合优化原则[17],在跟随者中选取新的领航者组织队形。系统对担任领航者的机器人的flag置为1,对担任跟随者的机器人的flag置为0。接替性领航机制主要步骤如下:
1)预先对团队中的所有机器人进行编号:i=1,2,…,n;
2)首先指定1号机器人担任领航者完成编队的队形,同时对1号机器人的flag置为1,其他机器人的flag置为0;
3)多机器人以设定的编队队形运动前进;
4)前进中每隔一段时间i,领航者与跟随者进行一次通信,若通信成功,则队伍继续前进;反之,在跟随者中根据各自的综合优势选取新的领航者接替上一任领航者组织队形继续前进,同时对该机器人的flag置为1,上一任领航者的flag置为0以及编号置为n+i;
5)上一任领航者清理缓存空间后作为跟随者回归到新的队形中。
6)重复步骤3)、4)、5)直到多机器人团队完成最终的任务。
初始的机器人综合优势矩阵为:

新领航者选取后的机器人综合优势矩阵为:

其中,Rc0,…,Rcn为各机器人的综合优势,Rc=-1的为领航者,剩余的为跟随者。
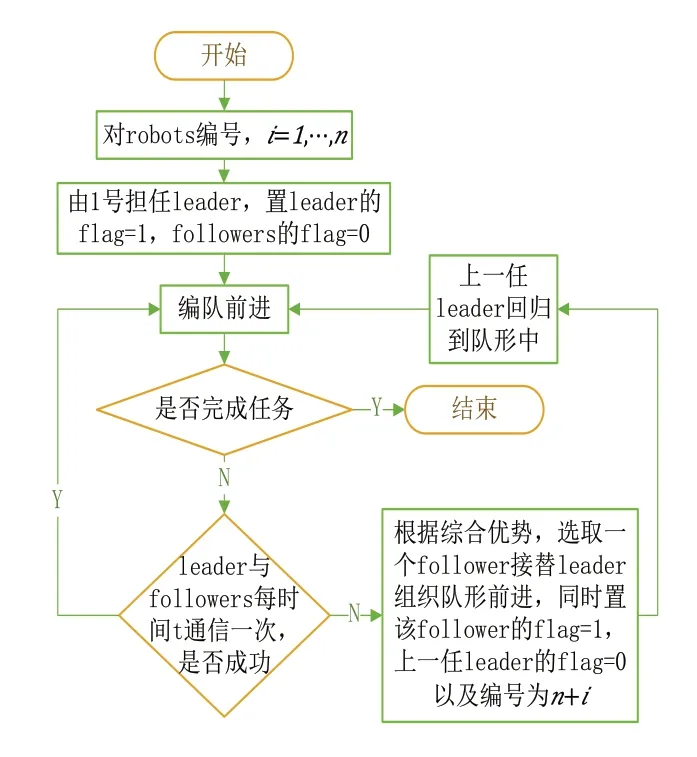
图3 接替性领航机制流程图
该机制简单且便于使用,当领航者与跟随者出现通信堵塞时,将对于由传统方法选定的领航者的依赖问题转变为从跟随者中选取新领航者的问题,以新一轮的领航者组织队形继续前进完成系统设定的任务。
3 仿真实验
为了验证本文提出的接替性领航机制可以有效的解决领航—跟随法多机器人编队对于领航者的依赖,使用MATLAB软件进行仿真实验。实验以6个机器人的三角形队形运动为例,各机器人的初始位姿任意,设领航者的初始位姿RL=[-3 0 0]T,跟随者的初始位姿RF1=[-4 1 0]T,RF2=[-4-1 0]T,RF3=[-5 2 0]T,RF4=[-5 0 0]T,RF5=[-5-2 0]T,仿真实验结果如下:
机器人的初始位姿以及目标点位置如图4所示。
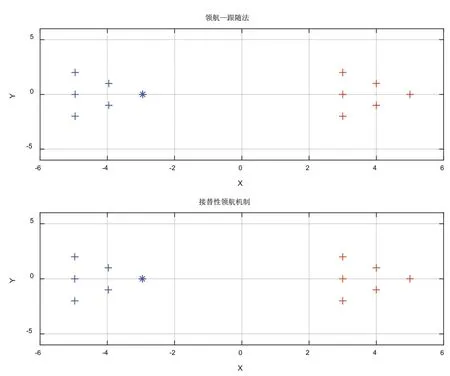
图4 机器人的初始位姿以及目标点位置
领航者通信堵塞时队形向目标点位置移动的运动过程如图5所示。
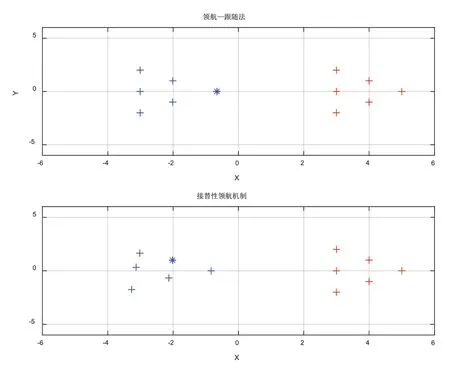
图5 领航者通信堵塞时队形向目标点位置移动的运动过程
新领航者组织队形向目标点位置移动的运动过程如图6所示。
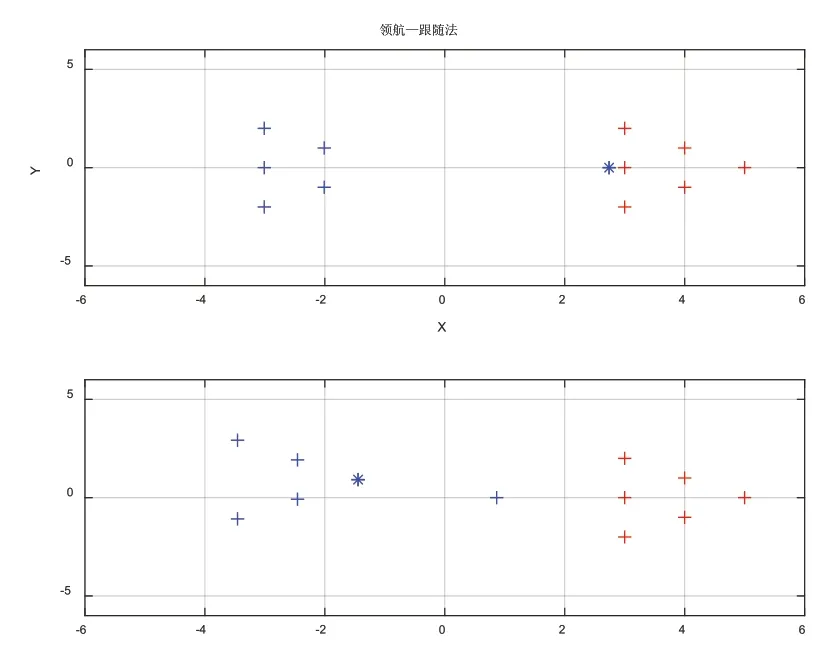
图6 新领航者组织队形向目标点位置移动的运动过程
上一任领航者清理缓存空间后作为跟随者回归到新队形中的运动过程如图7所示。
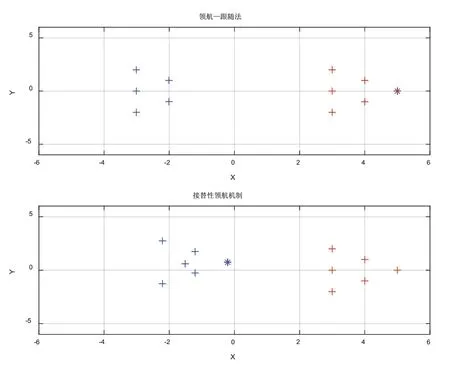
图7 上一任领航者清理缓存空间后作为跟随者回归到新队形中的运动过程
各机器人到达目标点位置如图8所示。
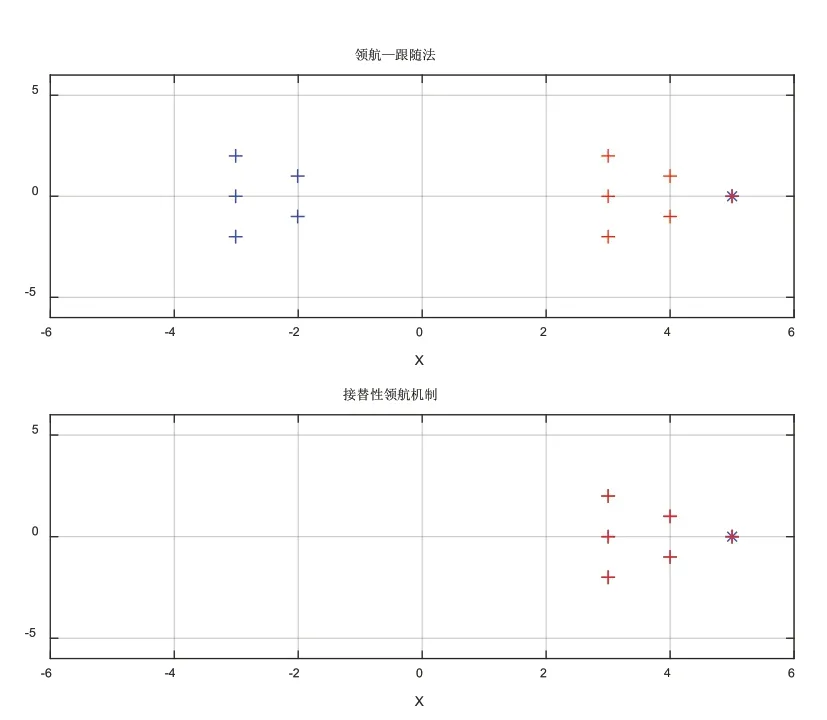
图8 各机器人到达目标点位置
各机器人向目标点位置移动的运动轨迹如图9所示。
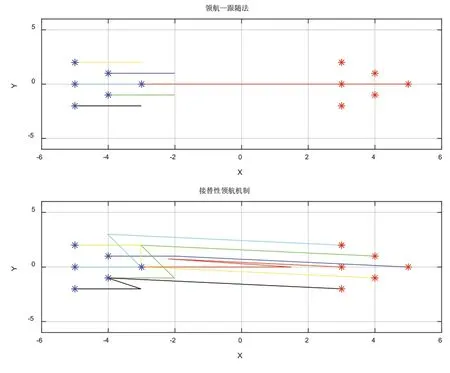
图9 各机器人向目标点位置移动的运动轨迹
由图5、图6可知,当领航者通信堵塞时,领航—跟随法编队下跟随者因接收不到领航者的下一步指示,只能在原地不动,而领航者继续前进;接替性领航机制下从跟随者中选取新的领航者组织队形继续向目标点出发,避免了因对领航者的依赖导致系统的崩溃。由图7、图8可知,接替性领航机制下上一任领航者清理缓存空间后作为跟随者回归到新的队形中继续前进,最终全部到达目标点,避免了机器人因故障而丢弃。
4 结语
本文在针对多机器人编队中领航者的情况下,将对于由传统方法选定的领航者的依赖问题转变为从跟随者中选取新领航者的问题来求解,主要为:当领航者通信堵塞时,根据跟随者的综合优势从中选取新的领航者组织队形继续前进,最终以完整的多机器人编队到达目标点。仿真结果表明在本文提出的编队控制方法下很好的解决了多机器人编队中对于领航者的依懒,队伍中每个机器人的“负担”较小,并且保证了队形的完整性,对于机器人的规模有很好的扩展性。
在本文的多机器人编队环境下新领航者组织队形的效率以及上一任领航者的回归消耗时间较长,因此如何缩短这两者消耗的时间是下一步的研究重点。
猜你喜欢
今日农业(2021年5期)2021-05-22
舰船电子工程(2018年12期)2019-01-03
考试周刊(2018年95期)2018-11-14
航空模型(2017年12期)2018-05-08
山东工业技术(2018年5期)2018-03-10
中国外汇(2017年8期)2017-08-16
—— 瓮福集团PPA项目成为搅动市场的“鲶鱼”
当代贵州(2017年24期)2017-06-15
诗潮(2017年5期)2017-06-01
留学(2017年5期)2017-03-29
科技创新与应用(2016年34期)2016-12-23
