
增强特征金字塔结构的显著目标检测算法
2022-06-23 06:24刘剑峰
计算机工程与应用 2022年12期
刘剑峰,潘 晨
中国计量大学,杭州 310000
人类视觉具有注意力机制,能够高效处理场景中最重要信息,是当前计算机模拟人类视觉的重要研究方向。其中,显著目标检测(salient object detection,SOD)是一类自动感知场景中显著目标的方法,能广泛应用于图像检索[1]、机器人导航[2]、视觉跟踪[3]、目标检测[4]等众多领域。近年来,深度学习表现出超群性能,基于深度网络的显著目标检测(deep SOD)算法不断突破。特征金字塔技术(feature pyramid network,FPN)[5]往往能在显著目标检测中发挥作用。这是由于不同特征层级的信息可以表达不同的目标属性,充分利用这些层级信息,能形成更全面的目标检测结果,也更符合人类感知。但是在FPN框架中为了产生更好的显著图,需要选择合适的多层特征融合方式。如果不对模型中的信息进行准确的控制,则会引入一些冗余特征,如来自低层的噪声和来自高层的粗糙边界等,从而导致模型性能的下降。为了解决上述问题,文献[6]提出了一种在复杂结构中引入短连接的方法。文献[7]提出一种孪生网络结构和结构性损失函数进行清晰边界预测的方法。文献[8]提出了一种使用循环卷积神经网络的检测方法。文献[9]开发了一种循环显著性检测模型,该模型通过多路径周期性连接将全局信息从高层传输到浅层。文献[10]提出一种直接连接高级别和低级别的特征图来聚合多级特征的显著性方法。综上,现有深度学习模型中影响性能的因素较多,模型结构不同、损失函数不同、池化手段不同等都导致性能差异。如何基于整体框架,综合考虑这些因素来提升算法性能,是具有意义的研究方向。
本文利用FPN作为基本网络结构,针对显著目标检测算法中的关键问题做了一系列相应的改进,实验表明具有更好的检测结果。主要有以下几点贡献:
(1)在沿用特征金字塔的良好U型结构[11]基础上,改进特征融合机制,将特征融合相加操作改为特征融合相乘,使检测结果对显著性区域更加敏感。
(2)依靠结构性相似损失[12]模拟亮度、对比度和结构对图片进行相似性判别;使用交并比损失[13]判别图像感兴趣位置的相似性;沿用二值交叉熵损失[14]衡量像素差别。综合三者可以衡量“全局-局部”损失。
(3)增加残差特征图增强模块,借此强化最高层特征图语义信息。特征金字塔结构中顶层特征来源单一,通过该方法能增强最高层的信息构成,使得具有更准确的高层语义信息。
1 改进的特征金字塔结构方法
1.1 研究现状
近年来,由于泛化能力强大的深度学习方法的发展,大多数传统的显著性检测方法被逐渐取代。现有多种深度显著目标检测手段,比较流行的有:BASNET[15]、BMPM[16]、DSS[17]等,利用U型结构进行多尺度特征融合检测显著目标;PAGRN[18]、RAS[19]等采用注意力机制引导获取显著区域;BASNET[15]等利用改良的损失函数引导算法关注特定的信息;以及C2S[20]等利用分割网络改进显著性检测的方法。
上述SOD方法中,BASNET[15](boundary-aware salient object detection network)首先在编码解码结构中得到粗糙结果,然后串行添加细化方法进行修正,同时混合多种损失得到细粒度结果,使得网络关注边界信息。C2S[20](contour knowledge transfer for salient object detection)提出了一种由轮廓检测框架改良而来的显着性检测网络。通过多任务之间共享参数的方式来提高精度,介绍了一种标记误差掩膜的方法。PAGRN[18](progressive attention guided recurrent network for salient object detection)在不同卷积通道和不同空间位置像素中都赋予权重,通过该权重构造特征,实现注意力机制为导向的显著目标检测网络。BMPM[16](a bi-directional message passing model for salient object detection)使用不同扩张率的卷积层进行多尺度特征融合,并且引入门控双向信息传递模块,进行浅层和深层信息传递,使特征信息有选择地被处理。RAS[19](reverse attention for salient object detection)通过自上而下的途径来指导残差显著性学习,同时嵌入反向注意力块(RA)。反向注意力块通过更深层次的补充来强调非显著区域。DSS[17](deeply supervised salient object detection with short connections)提出了从较深侧输出到较浅侧输出的几个短连接。使得更高级别的特征可以定位显著区域,而较低级别的特征可以获得精细的细节。为了使研究更具有参考价值,以上方法均作为对比实验的参考算法,详细内容在第2章展示。
1.2 网络结构
本文提出了一个有效的显著性目标检测框架,见图1整体框架流程图。图中浅紫色C1~C5阶段为Resnet[21]编码层部分,经过了图中深蓝色残差特征图增强模块(residual feature augmentation,RFA)生成P6全局引导层。黄色全局融合模块在解码层逐渐解码,整体网络采用类似特征金字塔结构,使用淡蓝色背景表示。
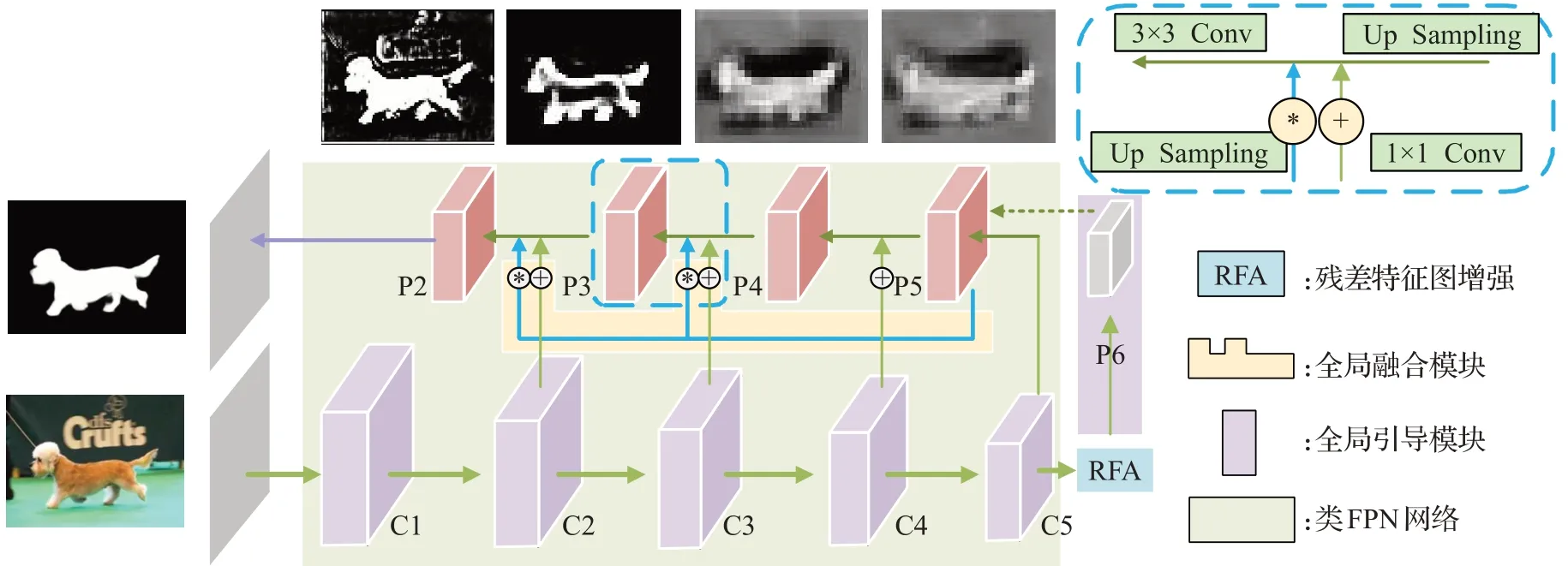
图1 整体框架流程图Fig.1 Whole framework flow chart
在此框架中,编码解码的U型结构有利于充分利用层次的特征信息;多尺度的融合机制有利于将高层语义信息和低层位置信息相融合,互补生成有效特征图,提高检测的能力;在此结构中多次使用了上采样和下采样的操作,目的是使层与层的特征图可以相互融合,完成多尺度特征的构建。
在图1的整体框架流程图中,右上方蓝色虚线代表全局融合模块的一分支,对应于图中P4到P3和P3到P2的淡蓝色虚线融合方式,将在1.3节详细介绍。
1.3 全局融合模块
特征金字塔利用多尺度融合方式,可将高层语义信息和低层位置信息相结合。众所周知,高层次特征图具有强语义,信息感受野[22]很大,但不具备细节边缘等信息。而低层次的特征图感受野区域较小,但边缘位置信息特别丰富。金字塔融合方式能有效提升最终输出特征图的感受野范围,并且保证了一定的细节内容,有效地结合了两者的优点。
通常特征图融合机制采用像素间相加的形式,而在实验中发现,利用像素点相乘操作可以更好地获得显著性目标检测区域。因此,本文方法在显著性目标检测中,通过对应像素相乘操作来突出位置信息,使图像对显著区域更加敏感,从而提升该区域的检测能力。
全局融合模块对应于整体框架图1中右上角的蓝色虚线操作。这里以P4、P5、C3输入,P3输出为例。
首先下方C3层经过1×1卷积至P4相同通道,P4经过上采样至相同尺寸,执行第一步特征层相加操作。如公式(1)所示。紧接着来自最高层的P5经过上采样操作与刚刚相加后的结果进行像素相乘处理,得到的结果进行3×3卷积为最后的P3特征层输出。如公式(2)所示:
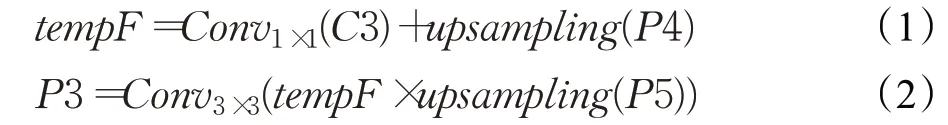
考虑到这里的两次操作可以有很多种替代方式,做了对比实验分别为使用相乘、相加以及无操作时的显著性特征图结果。图2融合机制对比图中三个红色特征图对应于图1解码层的P2、P3、P4层。其中(1)、(2)为不操作,(3)、(4)为两次相加操作,(5)、(6)为先相加再相乘操作。左上角蓝色虚线框为特征融合单元对应(5)、(6)图的蓝色虚线区域内操作。通过图2融合机制对比图可以发现不采用任何操作的(1)、(2)图效果最差,而依次采用相加和相乘处理的(5)、(6)图层次最明显,对细节最敏感。
图2 融合机制对比图Fig.2 Merge mechanism comparison diagram
1.4 残差特征图增强模块
FPN(feature pyramid network)特征融合机制从C5阶段自顶向下逐层融合,该方式可以获得图像上下文信息。低层次位置信息可以获得高层次语义信息的增强。但问题是,C5层(最高层)由于特征通道减少,只有单一尺度的上下文信息,不兼容于其他层次的特征图内容。
为了改进C5特征层的显示效果,本文引进残差特征图增强模块,利用残差分支向原始分支注入不同比率的上下文信息。期望全局上下文信息可以减少P5通道中的信息丢失,同时提高特征金字塔的性能。具体操作如下:
(1)以C5为原始特征,进行比率不变自适应池化:将C5原尺寸图按照一定比率进行上采样得到3个不同大小的子特征图。对应于图3(1)和(2)中紫蓝黄三种尺度特征图。比率不变自适应池化将最深的语义层进行采样,考虑了图像的比率,会使C5层包含更多的有效信息。
(2)再对三个子特征图进行自适应空间融合,如图3中(2):以整张图的维度形成一种注意力。通过注意力得到概率图,将其乘上3个子特征图,最后进行像素相加,融合得到P6特征图,该操作对应于图3中(3)。自适应空间融合类似但又不同于PSP[23](pyramid scene parsing network),它考虑到图片的不同比率。
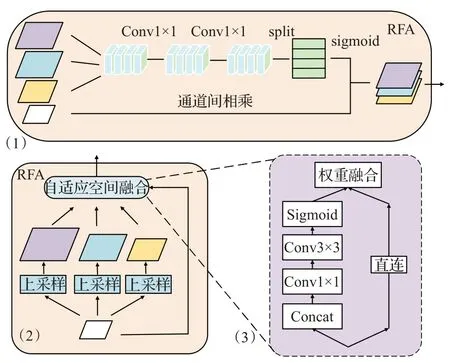
图3 残差特征图增强模块Fig.3 Residual feature graph enhancement
图3中(1)表示残差特征图增强的卷积过程结构图,(2)为残差特征图增强的整体流程,(3)为RFA中的自适应空间融合的具体结构图。
1.5 损失函数
通常衡量两张图的相似程度使用均方误差,但是对于一些在亮度降低或对比度调整的情况,均方误差的误差程度相差特别大,但两张图在内容表现上还是很相似的。为了避免出现类似问题,本文引进了一种SSIM结构性相似损失,该损失模仿图片的3个特征(亮度、对比度和结构性)判断两张图像是否相似。其中亮度的μx表示N个像素点的平均亮度,见公式(3)。l(x,y)表示衡量两个图片的亮度相似度,见公式(4)。
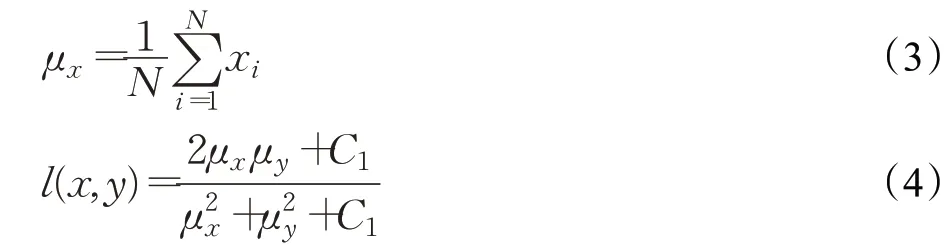
对比度σx表示图片明暗变化剧烈程度,利用像素的标准差来表示,如公式(5),并使用公式(6)的c(x,y)来衡量对比度相似性。
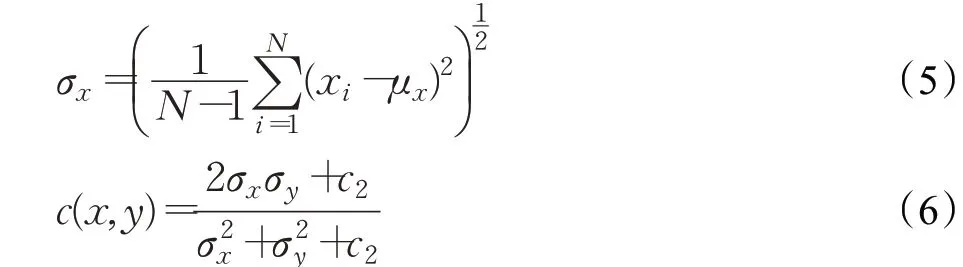
结构性s(x,y)利用两个图片的归一化向量表示,然后使用余弦相似度衡量相似程度,而协方差公式表达式可以使用σxy表示如公式(7)所示,最后化简为公式(8)所示。

同时,还联合IOU(intersection over union)损失函数为了使得结果更好地逼近二值显著性区域。IOU可以反映预测检测框与真实检测框的检测效果,并且该损失对尺度不敏感具有尺度不变性,在回归任务中有很好的表现。
IOU损失也就是交并比损失。不仅可以确定正样本和负样本,还可以计算得到候选框与真实值的距离。

BCE(binary cross entropy loss)二元交叉熵损失可以运用在大多数的分割任务中,同时也是常用的分类任务损失,起到像素的分类任务。
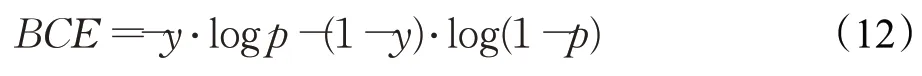
本文模型的损失函数采用以上三种损失结合的方式。其中利用二值交叉熵的分类准确性进行判断,利用交并比的位置敏感性调整整体区域,利用结构性相似的图像准确性监督图像细节。三者使用相同权重共同计算整体损失。TotalLoss表示整体损失函数构成,如公式(13)所示:
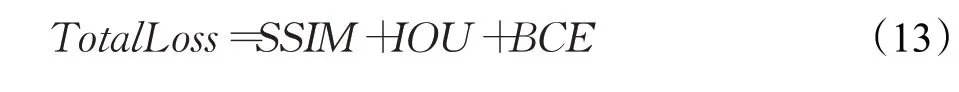
2 实验与结果分析
2.1 数据来源与实验设置
本文选择5个最具代表性的数据集进行实验测试:DUTS[24]、HKU-IS[25]、PASCAL-S[26]、SOD[27]、DUT-OMRON[28]数据集。其中DUTS数据集包含10 553个训练图像和5 019个测试图像,分别为DUTS-TR和DUTS-TE。HKU-IS数据集包含4 447个带有注释的图像。PASCAL-S数据集包含850张来自PASCAL VOC数据集的图像并带有标签。SOD数据集包含来自7个对象的300张带有标签的图像。DUT-OMRON数据集包含5 168张真实标记的图像。
本文方法将与当前流行的6种显著性目标检测方法BASNET[15]、C2S[20]、PAGRN[18]、BMPM[16]、RAS[19]、DSS[17]进行实测效果图和检测精度对比。
同时本研究采用的是DUTS-TR数据集训练,图片数量为10 553张。并且实验设置中学习率为1E-4,权重衰减为0.000 5,优化器为Adam,动量为0.9,迭代次数为24轮,损失函数参见1.5节。
2.2 评价指标
为了增加实验说服力,使用测量性能指标准确率-召回率曲线(P-R曲线)、准确率和召回率的综合评价指标(F度量值,F-measure[29])和平均绝对误差(MAE[30])三种评价标准进行实验结构分析,对应的计算公式如下:其中,S和G是预测的结果和人工标注的真值图,W和H为图像的宽和高,x和y为像素点的横纵坐标。

2.3 消融实验
本文方法采用了表1中相应的策略进行优化,其中EX表示不同的实验,每行代表不同方法组合下的实验结果,AM(add-merge)代表相加融合机制,MM(multiplymerge)代表相乘融合机制,GM(globle guidance module)代表全局引导模块,RFA(residual feature augmentation)代表残差特征增强模块,SI(ssim-iou-bce)代表组合结构性相似、交并比和交叉熵作为损失函数的方法。该实验为DUTS-TE数据集测试得到的结果。
通过表1可见,表中第一行和第二行在只改变融合方式条件下,相乘融合有更低的MAE和更高的MeanF,并且相乘操作得分普遍高于相加操作,说明相乘处理是有效的改进方式。而在RFA残差特征增强模块的实验中发现,该处理都有0.1~0.2个百分点的提升。说明确实存在最高层特征图P5信息单一,而逆向构造的P6层可以强化最高层,解决最高层特征图信息不丰富的问题。通过表1中第四行和第五行的实验结果发现,添加了SI(SSIM&IOU&BCE)操作可以在三种指标中同时获得提升,说明在三种损失函数的监督下可以比单独使用二值交叉熵(BCE loss)获得更高的泛化能力,具备更好的检测精度。
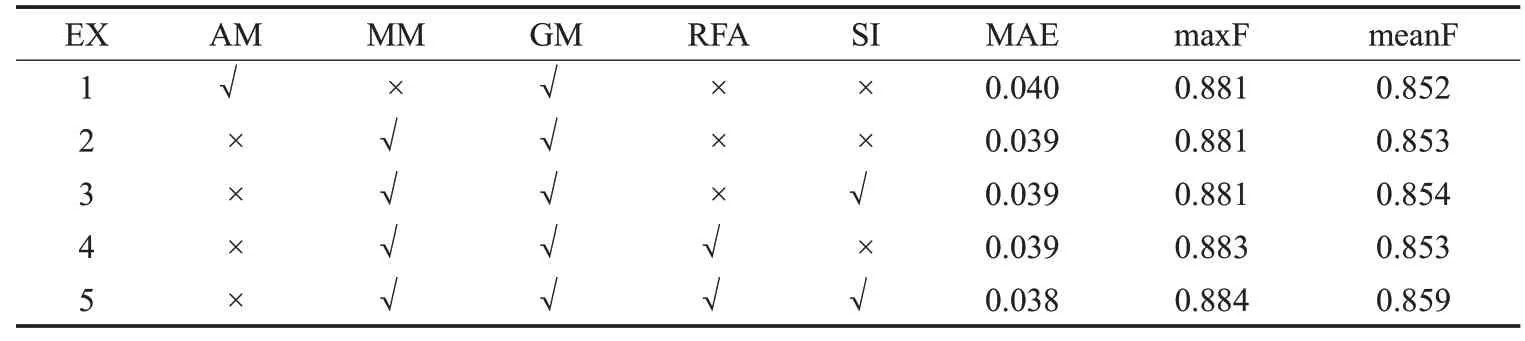
表1 本文提出方法的消融实验表Table 1 Ablation experiments for proposed method
2.4 对比实验
对主流显著性目标检测方法BASNET、C2S、PAGRN、BMPM、RAS、DSS进行对比实验,得到相应的PR曲线图和F-measure曲线图,同时获得以MAE、maxF、meanF作为指标值的表格,见表2,其中DT、MK、MB分别为训练集DUTS-TR、MSRA10K、MSRA-B数据集的结果。
如图4的PR图中,本文方法对应图中红色曲线,可以看到本文方法基本都超过其他主流方法,虽然在DUT-OMRON数据集中,结果出现波动,偶尔和BASNET效果持平,但是不影响最终的评判结果。观察图4的F-measure图,可发现本文方法依旧保持良好效果,但是出现在DUT-OMRON数据集中略低于BASNET。分析原因,BASNET在损失函数和编码结构上与本文算法相似,而BASNET通过串行修复网络进行修复,修复能力有一定随机性,可能对DUT-OMRON数据集敏感,所以有一定的性能提升。综上PR图和F-measure图,本文方法保持较高准确率的前提下获得了更好的F-measure值结果,可以认为该方法在各种场景和数据集中具有很好的泛化能力和检测能力。
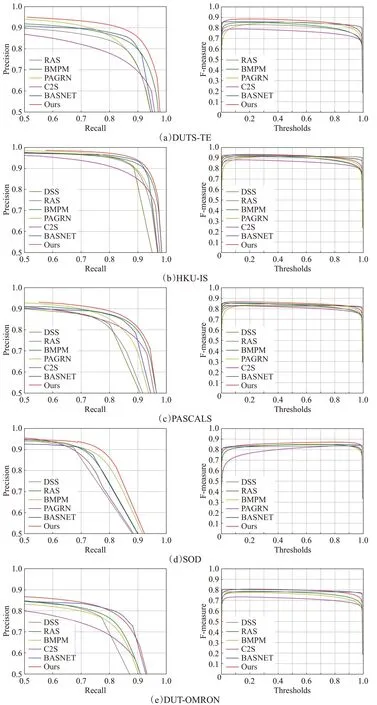
图4 不同数据集下各种方法的PR图和F-measure图Fig.4 PR graph and F-measure graph of various methods under different data sets
由表2可见多个数据集下,本文方法基本都超过主流方法,虽然在DUT-OMRON数据集下meanF指标略逊于BASNET,但是差距非常小,不影响本方法的整体表现。所以可以认为本文提出的显著性目标检测方法具有场景适应性。
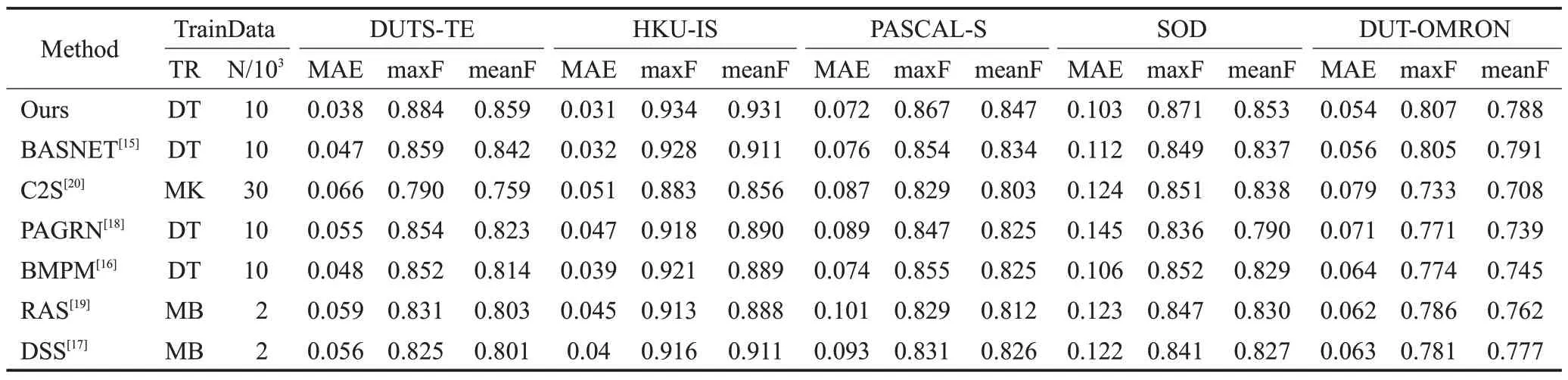
表2 不同数据集下各种算法的实验对比表Table 2 Experimental comparison table of various algorithms under different data sets
可以在图5实验效果对比图中看到本文方法和主流方法的实际效果。本文方法基本保持了较高水准的检测结果。着重于BASNET的对比分析中,BASNET虽然也采用了多种损失函数混合的方式,但是由于其模型结构并没有多次特征融合处理,仅依靠后续串行修正并不能达到特别好的效果,可以观察到BASNET的模糊白噪声场景的情况比较多。
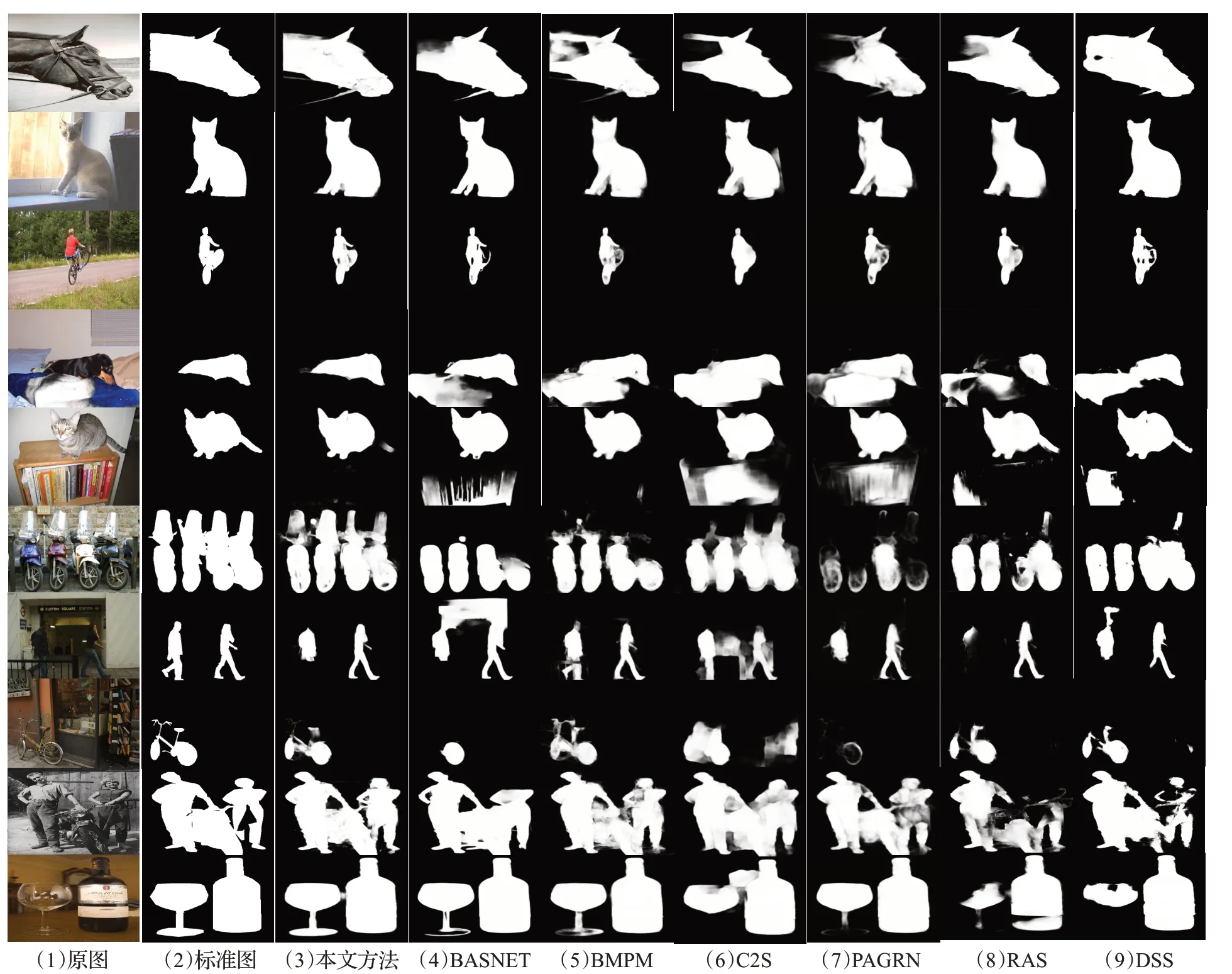
图5 各种方法下的实验效果对比图Fig.5 Comparison diagram of experimental results under various methods
3 结束语
本文改进了显著目标检测算法的损失函数,结合了多种具有不同特点的损失函数,使得模型训练时同时关注图像边缘信息、位置细节信息和语义分类信息。通过修改特征金字塔网络的融合机制,使得深度网络模型对显著性目标区域更加敏感。利用残差特征图增强模块逆向构建更高层特征图,以此增强最高层特征图的语义信息,有效避免最高层的信息来源单一问题。采用全局指导模块,将高层语义信息作用于每一层解码层中,指导加强语义能力,进而获得一种高精度的检测网络。本文在常用的几个数据集上对比了最新主流方法进行实验。实验结果显示,本文方法可以取得良好的检测结果,准确地定位显著性目标物体。
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
数学小灵通·3-4年级(2021年5期)2021-07-16
中国人兽共患病学报(2020年11期)2020-12-08
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
今日农业(2019年15期)2019-01-03
