
人脸部分遮挡条件下表情识别研究的新进展
2022-06-23 06:24李南星吴庆岗常化文
计算机工程与应用 2022年12期
蒋 斌,李南星,钟 瑞,吴庆岗,常化文
郑州轻工业大学 计算机与通信工程学院,郑州 450001
作为人类重要的主观体验,情感是左右人类行为的一个关键因素,在人际交往活动中发挥着巨大的作用。人类以多种方式表达自己的内心情感,比如语言语音[1]、肢体动作[2]、面部表情等。其中面部表情是观察人类情感的直接手段,人们可以通过面部表情准确地表达自己的思想和感情,也可以通过面部表情识别他人的态度和内心世界,在上述表达方式中具有两个显著的特点:(1)面部表情与人类情感之间的关联度非常高。在有关的情感信息中,面部表情约占总体信息量的55%,因此通过面部表情可以很好地解释人类的情感;(2)面部表情的表达方式简单自然,直截了当。不需要听者猜测语言语音背后蕴含的说者含义,也不像肢体动作那样隐秘或夸张。对面部表情的准确判断就有助于正确地评估人类的情感状态;而人工智能技术的实现,加快了人类情感信息的需求,所以在所有的信息交互方式中,人脸表情识别脱颖而出,成为了人工智能技术落地的一个关键研究方向。吸引研究者在驾驶员疲劳驾驶监测[3]、教育场景中对学习者的学习状态检测[4]、服务型机器人的智能服务[5]等方面展开了持续的探索。
虽然目前人脸表情识别已经在许多领域上展现出很高的应用价值,但是在技术的应用化过程中,仍然存在巨大的挑战,尤其是在获取识别对象图像时经常遇到的人脸部分遮挡问题。人脸部分遮挡通常发生在各种应用场景之中,比如:头部姿态偏转时出现的姿态遮挡[6],人脸光照不均衡时出现的色斑遮挡,图像采集过程中发生的人脸区域的噪声像素遮挡,以及日常生活中的实物遮挡[7],包括:饰物遮挡(口罩、围巾、墨镜)、面部部件遮挡(如头发、胡须、疤痕)、静物遮挡(建筑、树木)、动作遮挡(打哈欠时手放在嘴上)。意外遮挡(行驶的车辆、走动的行人)等。这些种类各异的遮挡会导致人脸外观在空间上发生显著变化,造成采集图像的缺损、人脸区域的形变,以及面部像素的异化。对人脸表情识别的应用带来了极大的麻烦和阻碍。于是在人脸部分遮挡状态下,提升人脸表情识别性能,成为了研究者重点关注的问题。
如图1所示,面部遮挡表情识别系统主要包括:人脸检测、遮挡处理、特征提取和表情分类。首先,人脸检测环节按照实际的应用场景,还存在着两种方式:第一、在线表情识别系统,需要根据人脸检测算法,实时获取人脸区域图像;第二、离线表情识别系统,主要根据专业的表情数据库训练算法模型;而专业数据库的人脸图像通常背景简单、面部区域突出,所以在这种情况下可以省略人脸检测环节。其次,遮挡处理环节需要根据所选模型的实际情况考虑,通常有舍弃法和重构法两种方式,舍弃法是检测到遮挡部位将其舍弃,主要聚焦于未遮挡的区域;而重构法是通过浅层模型或者深度模型对遮挡的区域进行重构,使其恢复成未遮挡的状态。最后,特征提取和特征分类在浅层学习中是两个分离的环节;而在深度学习中,特征提取与特征分类环节被融合在同一个深度人工神经网络之内,一般将两者合二为一。
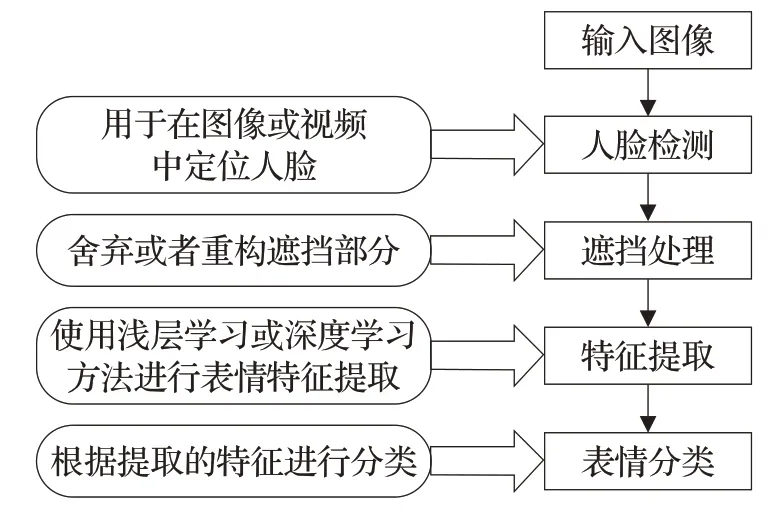
图1 人脸部分遮挡状态下的表情识别过程Fig.1 Outline of facial expression recognition under partial occlusion
1 人脸表情数据库
传统的人脸表情数据库是指在实验室等受控条件下,让采集者模仿标准的表情图片,做出相对应的表情,最后人工筛选出合格样本的过程,因此受控条件下采集的数据样本噪声比例相对比较低;非受控条件下的数据样本更为接近真实场景下的人脸图像,更强调人脸表情的实时性和真实性。除了上述区分方法之外,还可以站在不同角度所示,如表1本文将从样本模态(视频/图片)、类别数目(6,7,8)、引导方式(模仿/自然)、收集来源(实验室/自然环境)和数据规模等维度加以分类[8]。下面将详细介绍常用的人脸表情数据库。
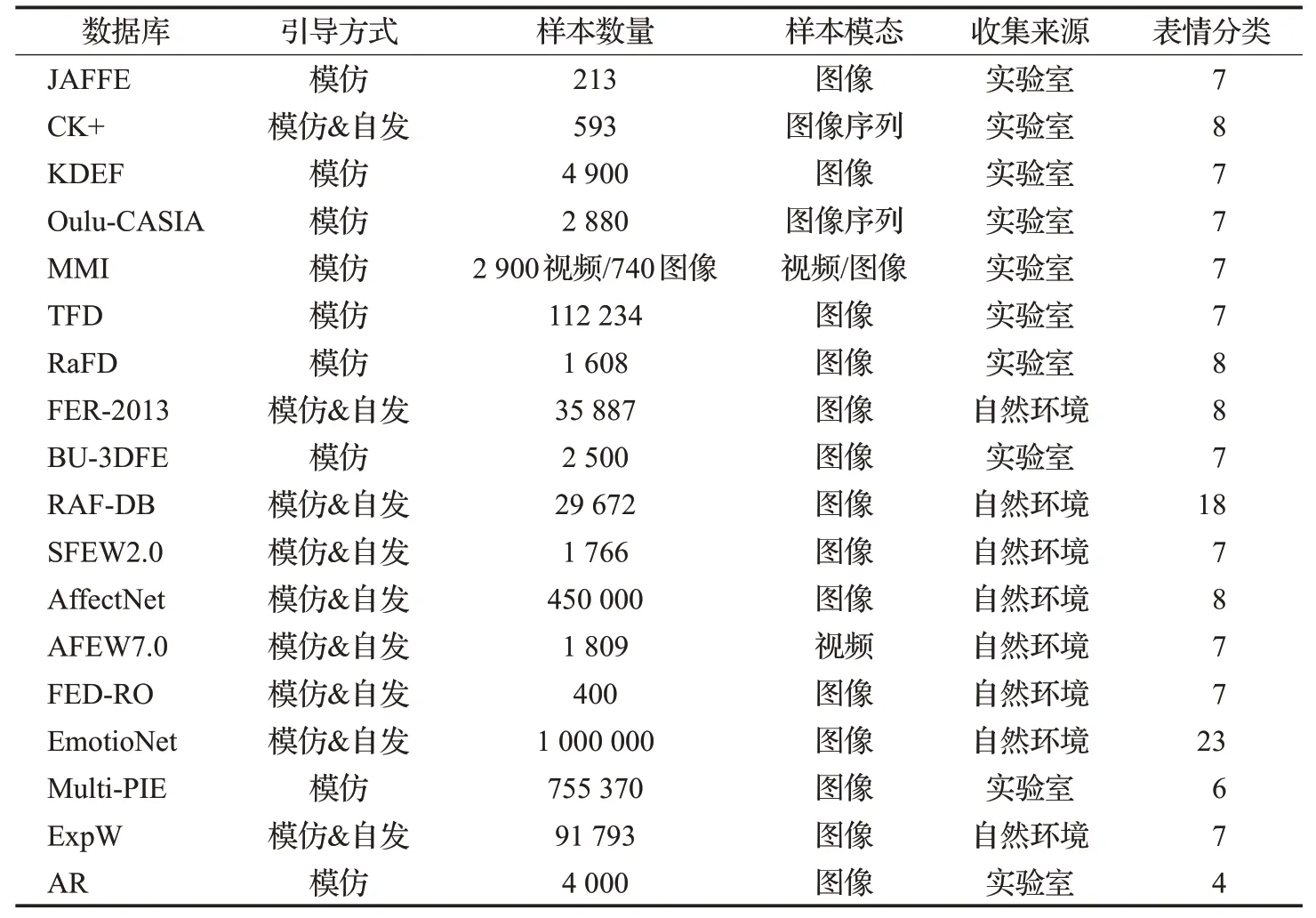
表1 人脸表情常用数据库Table 1 Commonly used facial expression databases
1.1 包含未遮挡图像的数据库
JAFFE[9]包含10名不同日本女性一共213幅正面人脸图像,每人有7种表情,每种表情大约有3、4幅灰度图像,该数据库是以(生气、厌恶、恐惧、高兴、悲伤、惊奇、中性)7种基本表情为基础的数据库。
CK+[10]数据库包含123个志愿者的593个图像序列,其中包括不同性别、族裔的表情序列。在593个图像序列中有327个具有情感标签,包含6种基本表情外加中性表情和蔑视表情。
KDEF[11]数据库在均匀、柔和的光照条件下,采集到70个志愿者的7种表情的人脸图像库。志愿者们年龄在20至30岁之间,没有胡须、耳环或眼镜等遮挡物进行遮挡,共包含4 900张彩色图像。
1.2 包含遮挡图像的数据库
Oulu-CASIA[12]数据集包含在弱光、正常光和暗光三种不同程度的照明条件下收集80名23至58岁参与者的6种基本面部表情。
MMI[13]数据集包含43个主体,6种基本表情的213个视频序列,这些视频序列中的一些对象带着帽子或者眼镜,具有面部部分遮挡的常见示例。
RaFD[14]数据库是Radboud大学行为科学研究所整理的人脸图像库,包含67个模特,共8 040张图片,该库包含8种表情,即愤怒、厌恶、恐惧、快乐、悲伤、惊讶、蔑视和中性。每种表情有3种注视方向和5种姿态。
FER-2013[15]数据库包含35 887张网络数据集。数据集按照28 709张训练图像、3 589张验证图像和3 589张测试图像进行划分,共包含8类情感标签。图像质量相对较低。
BU-3DFE[16]数据库是人脸三维图像数据库,收集了来自不同种族的100张面孔,每个对象有25个3D表情模型,部分模型存在人脸部分遮挡。
RAF-DB[17]是第一个在野外收集数据库,数据库包含29 672张不同年龄、不同性别、不同肤色的人脸图像;而且具有遮挡的表情数据。该数据库中包含6种基本情感标签以及12种复合情感标签。
SFEW2.0[18]的图像由两个独立的标签进行标记,该数据库包括遮挡、姿态等700幅从电影中截取的图像。
AffectNet[19]是一个大规模带有强度标记的人脸表情数据库。它在超过百万张人脸图片中对其中的450 000张图像进行手工注释,分为8类表情类别,是迄今为止最大的含有情感强度和情感类别标签的数据集。
AFEW[20]是一个动态时间面部表情数据库,该数据库一共包含957个电影片段,标注了愤怒、厌恶、恐惧、快乐、悲伤和自然6种基本表情。
SFEW[21]是真实环境中的面部表情图像数据库。数据库中包含不受约束和受约束的各种人脸表情图像,SFEW2.0版本包含958个训练样本、436个验证样本以及372个测试样本在内的7种基本表情。
FED-RO[22]是一个具有真实遮挡的面部表情数据库,通过标记搜索引擎Google和Bing中挖掘出的具有遮挡的人脸图像,获得了7种基本表情的400幅图片。
EmotioNet[23]数据库包含了100万张带有相关情感标签的野外面部表情图像,该数据库中的图像具有不同分辨率和不同光照条件,表情类别分为23种。
Multi-PIE[24]是一个含有不同姿势和光照大型表情数据库,该数据库包含337名志愿者在多种角度以及多种光照环境下拍摄的750 000张照片,标注了厌恶、中性、尖叫、微笑、斜视以及惊奇6种表情。
ExpW[25]数据库包含在互联网上搜索的91 793张人脸图像,每个图像均被手工注释为7种基本表情类别之一。
AR[26]人脸数据库包含126人的4 000张人脸图像,数据库包含自然、喜悦、羞恼和吃惊4种基本表情,也包含不同角度光照影响以及实物局部遮挡的人脸图像。
2 人脸部分遮挡条件下表情识别方法
真实场景中往往难以获得清晰、正面、完整的人脸图像。更多的情况下,计算机捕捉到的人脸往往受到很多干扰,比如光照变化、头部偏转、实物遮挡等。遮挡直接影响人脸图像的像素值,导致人脸图像信息的丧失。当面部的遮挡面积过大时,会造成表情特征的严重缺失,从而导致识别困难甚至无法识别。
近年来,随着深度学习网络的发展,很多研究者将深度学习引入部分遮挡的人脸表情识别中来,在传统的处理方法之上使用深度学习网络可有效地获取更准确的表情特征。不仅减少了传统特征提取与分类方法的盲目性,并且提高了识别精度。
由于环境的复杂性,会导致表情识别面临许多遮挡。文献[27]将遮挡分为长期遮挡和临时遮挡,长期遮挡是指面部固有的一些存在,比如配饰及自身所拥有的成分,而临时遮挡是指面部被其他物体在面部移动造成的遮挡、外界环境变化以及自身角度偏转等造成的遮挡。文献[5]指出人脸表情识别主要的挑战来自于光照变化、遮挡、变异姿势、身份偏差、定性数据不足等,而遮挡和变异姿势常发生在显示生活之中,因此将部分遮挡根据真实物体是否导致遮挡分为人工遮挡和现实生活遮挡。文献[28]将现实生活中的遮挡类型分为光照遮挡、物体遮挡、姿态变化引起的遮挡以及以上遮挡所导致的混合遮挡等。文献[29]指出低分辨率问题同样也是造成人脸表情识别方法在现实环境中性能下降的一大原因,普通相机捕捉到的面部图像的分辨率可能会比较低甚至出现模糊的情况,会导致人脸图像缺乏足够的视觉信息进行特征提取。文献[30]指出光照变化会给人脸表情识别带来一定的阻碍,尤其是在光线过亮或者过暗的情况下,影响对情感特征的提取。本文综合分析了该领域的最新进展,从光照遮挡、噪声遮挡、姿态遮挡以及实物遮挡的角度展开论述。
2.1 光照遮挡
人脸在现实中是以立体的形式出现的。在现实生活中,光源可能来自不同的方向,会导致面部明暗分布存在明显的差异。同时,过度光照和光照不足也可能导致采集到的图像出现光照遮挡,出现面部表情细节丢失,这会对后续的处理带来一定的影响。
文献[31]使用对比度受限的自适应直方图均衡化(combines the limited contrast adaptive histogram equalization,CLAHE)将图像划分的子块进行直方图均衡化,在限制的裁剪值处截断灰度分布,将大于裁剪值的像素均匀分布到整个灰度范围,可以缩小子块中局部灰度快速变化引起的局部细节差异,从而增强图像的局部对比度。然后加入Gamma灰度校正算法来提高图像的整体亮度,最终有效地处理了因光照过度、弱光和不均匀造成的面部图像光照遮挡的问题。
为了降低光照遮挡对表情特征提取的干扰,研究者考虑使用多特征的提取模式,从不同角度描绘表情特征的“容貌”。文献[32]首先利用Haar小波变换和Gabor滤波器分别提取人脸表情图像的全局和局部特征,然后使用非线性主成分分析(nonlinear principal component analysis,NLPCA)方法对提取的高维特征信息进行降维处理,以降低训练的时间复杂度,最后使用支持向量机(support vector machine,SVM)分类器对人脸表情进行识别分类。以实现在不同的光照条件下获得更高的人脸情感识别和分类精度。
文献[33]使用一种在尺度不变特征变换(scaleinvariant feature transform,SIFT)方法的基础上改进的方法来进行情感识别。首先定义权重向量对检测到的人脸图像进行形状分解,使用特征点约束算法优化表示表情变化区域的特征点的最佳位置。然后对每个特征点计算特征参数以便获得更多的情感信息,最后用SVM分类器结合主成分分析法(principal component analysis,PCA)降维并进行表情分类。本算法可提高不同面部姿势和光照下面部表情识别的稳健性。
文献[34]研究了复杂光照环境下视频中的面部表情识别,引入一种新的基于时间局部尺度归一化的自适应滤波器来提高对光照条件的稳健性。具体操作是使用Viola-Jones算法进行面部检测并使用深度卷积网络(deep convolutional neural network,DCNN)进行表情预测,由于视频信息是高维数据,DCNN中的自编码器可以从这些高维信息中提取有意义的特征,DCNN中的半监督学习器可以防止自编码器过度拟合,在半监督学习器之前添加额外的网络层作为光照不变网络来引入像素强度的尺度不变性,从而利用辅助神经网络实现对光照不变量的计算。
但是单任务神经网络在应对复杂问题时有些力不从心,因此研究者又专门设计了针对复杂光照问题的多任务神经网络方法。文献[35]提出多任务神经网络,首先利用共享编码器-解码器将输入的图像提取有识别能力的特征,并生成光照不变的特征。其次图像恢复分支和图像分类分支并行使用共享权重将输入的图像进行情感预测。该网络由于对光照变化具有鲁棒性的特点,因此可以处理光照变化下的人脸表情识别分类。且可以支持在不带标注的数据集上进行半监督学习,缓解小数据集上可能出现的过拟合问题。但由于是多网络并行处理,因此网络结构较为复杂,这会导致网络运行时间成本较高,识别速率相对降低。
上述方法均是在可见光的条件下展开实验,而部分研究者决定绕开可见光领域,从不同的光谱频率上切入部分遮挡的表情识别问题。其中主动近红外成像(nearinfrared,NIR)是克服光照变化问题的一种方法,它甚至在接近黑暗的情况下依旧有一定的稳健性。相比可见图像的面部特征,主动近红外成像表征的面部清晰无遮挡。文献[30]使用一种新颖的自动面部表情识别的框架,首先通过使用从数据集中学习特征向量之间的余弦距离计算表情特征相似度,然后通过卷积神经网络(convolutional neural network,CNN)根据特征相似度来进行表情分类。最终实验证明在强光和弱光的情况下均有不错的识别效果。由于该模型能够学习不同表达式的歧义或者相关性,因此有效地减少相似表达式的分类误差,如表2。
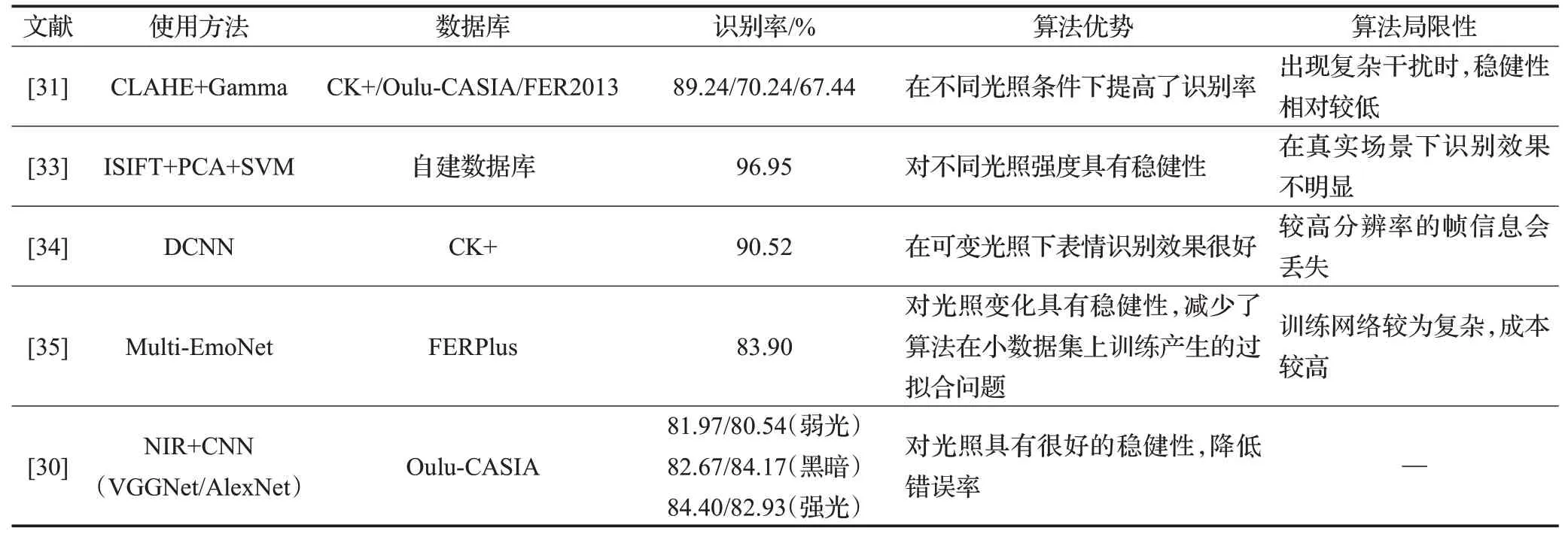
表2 光照遮挡的方法性能对比Table 2 Performance comparison of light occlusion methods
为处理光照不变量造成的光照遮挡,处理方法可分三大类:第一类作用于原始图像的预处理阶段,使用简单且有效的数学方法直接计算像素灰度值。该种方式主要适用于人脸表情数据集数量不多的情况下;第二类方法作用于特征提取阶段,使用对光照具有稳健性的特征提取算法来提取不同光照条件下的人脸表情特征,通过提取不随光照条件变化的特征,来减少不良光照的干扰。相比第一类的方法,该类方法通过在复杂的光照情况下提取更多的光照不变量,对人脸表情识别有着更好的估计结果;第三类则是使用深度学习网络对人脸图像进行重建,构建出光照不变模型。在不同的光照条件下通过使用大量的人脸表情数据进行网络训练、图像重建,从而得到更精准的分类识别结果。
2.2 噪声遮挡
在现实环境中,由于人脸采集设备和环境条件的影响,人脸图像质量会变得较差,低分辨率面部图像通常缺乏足够的视觉信息来提取信息特征,低分辨率通常会导致人脸表情识别方法识别性能下降。
传统的滤波学习方法具有较高的泛化能力和稳健性,滤波器的设计目的是抑制噪声信号,放大有用信号,从而增强滤波后信号的可分辨性。然而传统的滤波器是手工设计的,没有学习能力,但随着卷积神经网络的发展,卷积滤波器可以获得更丰富的表征,因此文献[29]提出一种基于图像滤波器的子空间学习(image filter based subspace learning,IFSL)方法来对低分辨率的面部表情进行识别。该方法是一种整体识别方法,相比局部识别方法相比,整体识别方法对图像的分辨率的敏感性较低。首先将判别图像滤波器(discriminative image filters,DIF)学习的过程中加入二类线性判别分析(linear discriminant analysis,LDA),可将高维样本投影到最佳判别子空间有效的进行样本分离,然后线性组合由学习的判别图像滤波器生成过滤图像,最后根据组合的结果使用线性脊回归(the linear ridge regression,LRR)算法进行特征提取。使用此种方法可以显著地去除不相干信息,有效保留有价值的表情信息,使得保留下的信息具有很高的可辨别性,提高识别效率。此方法从图像滤波的角度解决了训练数据受限的问题,因此可以实现在小训练样本下完成人脸表情识别。
文献[36]基于局部二值模式(local binary pattern,LBP)提出一种具有自适应窗口的新的方法来进行人脸表情特征的提取,分别对邻域和对角邻域进行计算,有效地降低了计算的复杂度,对于情感特征描述引入了自适应窗口和径向平均方法修改特征提取的窗口,实现了噪声的稳健性,这也可以有效地缓解噪声遮挡的问题。
文献[37]提出一种具有多标签分布学习的有效红外面部表情识别方法,使用柯西分布标签学习网络(Cauchy distribution label learning network,CDLLNet)来构造表情标签来克服模糊的面部表情问题。首先计算同一个主题的不同面部表情的相似度值,然后利用相似度值构造表达式多标签,使用基于柯西分布的标签学习构建一个基于GoogleNet主干网络来学习红外表情图像中的面部特征,引入KL散度来测量预测和真实分布,这样对低质量的图像是稳健的,利用协方差池化层来捕获二阶图像特征,根据标签的相似度进行分类。
文献[38]提出了一种微小边缘感知反馈神经网络(edge-aware feedback convolutional neural network,E-FCNN)来缓解因图像分辨率降低而导致人脸表情识别精度下降的问题。采用超分辨率反馈(facial superresolution,FSR)网络的反馈机制,使用残差块在低分辨率特征提取块和反馈块之间构建分层特征提取结构。并嵌入边缘增强块来增强人脸图像的清晰度,利用上采样块放大人脸图像,补充低频信息。融合重建的图像在识别精度上面保持了良好的水平。
文献[39]提出一种将人脸的结构信息合并到人脸超分辨率网络方法,文献将超分辨率生成对抗网络(superresolution generative adversarial network,SRGAN)作为基础网络,并将网络的残差块用密集块替换来提高收敛效果,使用面部关键点的描述面部结构和面部轮廓的趋势作为先验信息,添加到人脸特征网络层中提高人脸图像重建的效果。
文献[40]在特征提取阶段采用多示例注意力机制进行人脸特征提取,以缓解低分辨率等不利因素对特征提取的阻碍。该文献人脸表情识别为主,利用人脸性别和年龄双属性因子为辅,创造出一个多任务识别模型,使得在低分辨率的图像中也具有一定的稳健性,提高识别准确率。由于使用的是基于注意力机制的多示例特征融合的方法,使得模型结构较为复杂,增加了运算量,进而会导致运算速度下降。
对于低分辨率图像处理可分为两种方式:第一类是超分辨率重建算法。使用人脸超分辨率方法将低分辨率的图像构建成高分辨的图像,使用重建后的图像再进行人脸表情识别,这类方法是用于从小尺寸低分辨率图像恢复大尺寸高分辨率图像,因此适用于放大较小的人脸图像。第二类应用于特征提取的方法。又可分为基于几何的方法和基于外观的方法[41]。基于几何特征的方法是提取面部成分和形状位置的特征向量,由于实时提取几何特征相对困难,因此该方法不适用实时的人脸表情识别;基于外观的方法,获取整个面部或者未被遮挡的特定区域的人脸表情的纹理结构特征信息,再使用分类器识别不同人脸的表情。该类方法从人脸中可以提取具有较高区分度的不同类别之间的特征,从而达到更好人脸表情识别效果,如表3。

表3 噪声遮挡的方法性能对比Table 3 Performance comparison of noise occlusion methods
2.3 姿态遮挡
人体旋转会导致面部信息的缺失,而手势等姿态更会在生活中造成自遮挡的情况。因此姿态遮挡下的表情识别,同样会面临面部遮挡的困扰。
文献[42]提出了一种完全端到端级联的卷积神经网络(fully end-to-end cascaded convolutional neural network,FEC-CNN)结构。首先将标志点周围的原始图像裁切成区域块,再由三个具有相同网络结构的子卷积神经网络进行特征提取并进行特征连接,最后通过网络中全连接层进行预测。通过实验证明,FEC-CNN能够准确地检测人脸标志点位置,并且对姿势、遮挡等大变化具有稳健性。但由于为了实现更好的泛化性,因此该方法选择进行数据增强,也增加了网络过拟合的风险。
文献[43]提出一种区域注意网络(region attention network,RAN)来缓解卷积神经网络模型对遮挡和姿势变化环境中的性能的退化。该算法可以自适应地捕获人脸区域信息的重要性,并在区域特征和全局特征之间做出合理的权衡。首先将人脸图像进行固定或者随机裁剪,将其裁剪成为多个区域,将裁剪的区域和整个人脸图像输入到主干卷积神经网络模型中进行区域特征提取,然后自注意力模块为区域进行分配注意权重,并使用选择性区域偏损函数对RAN施加一个简单的约束来调整注意权重,增强有价值的区域。该文献对图像进行裁剪区域可以扩大训练数据,并且将区域重新缩放到原来图像的大小,可以突显出更为细微面部特征,使用区域偏向损失来提高重要特征点的权重。由于自注意力机制需要额外的监督机制来确保功能,因此在较大的遮挡和姿势下,该网络模型可能无法准确定位这些未遮挡的面部区域,网络的泛化性较差,在一些数据库中识别效果有待提升。
文献[44]聚焦于未遮挡人脸区域的表情特征,提出了一种遮挡自适应深度网络(occlusion-adaptive deep network,OADN)方法。遮挡自适应深度网络由两个分支组成,地标引导注意力分支和面部区域分支。首先利用ResNet50网络对面部区域进行全局特征的提取,随后地标引导注意力分支作用是利用标志点检测定位引导网络专注于未遮挡的面部区域。主要是利用这些检测出的标志点的单元信息生成注意图,通过注意图对全局特征进行调制,引导模型滤除遮挡区域并着重于非遮挡区域。面部区域分支是为了缓解因为人脸严重遮挡时地标引导注意力分支的不准确性。主要方法是将特征映射划分为非重叠的图像块,面部区域分支来训练表情分类器,以此来学习互补的上下文信息从而增强稳健性。利用两分支互补学习特征的特点,可以更有利地聚焦辨别力很好的面部区域。相比自我注意力机制的方法,提出该方法可以更准确地定位到非遮挡的面部区域。
文献[45]提出了一种新的基于手势的深度学习情感识别方法解决了因手部遮挡以及头部旋转的自遮挡而造成无法表情识别的问题。该方法与新的编码模式相结合,从输入的图像中准确地提取出手势,然后使用卷积神经网络从输入的人脸图像中提取各种颜色和纹理特征,使用循环神经网络(recurrent neural network,RNN)对提取的特征进行训练生成情感类别。最终实验的效果不仅大大提高情感识别的准确率而且还能识别比如自信、羞耻等一些高级情绪。
相对聚焦面部未遮挡区域的方法,还有研究者认为还原面部遮挡区域,最大程度地近似人脸图像的未遮挡状态,能够获得图像中更多的表情信息。文献[46]使用生成对抗网络(generative adversarial network,GAN)对多角度的人脸表情进行识别,首先为了降低特征提取的难度,利用深度回归网络检测人脸图像的关键点进行人脸对齐,预处理之后可以去除图像中的冗余信息,然后将人脸图像输入到GAN网络的生成器中,在生成器中添加跳过连接使网络能够适应多角度图像,在编码阶段生成器中的编码器提取人脸图像的人脸特征,将特征与新的人脸角度编码信息融合输入解码部分,生成不同角度的人脸图像,然后将多角度的人脸图像输入到卷积神经网络中进行分类。
文献[47]提出一种合成生成网络(compositional generative adversarial network,Comp-GAN)来生成新的真实的人脸图像来解决姿势和复杂表情的变化问题,该网络可根据输入的图像动态的改变表情和姿势,同时还保留不包含表情的信息。
为解决深度学习中个体差异干扰,减少特征空间中相同表达的图像之间的距离,文献[48]提出一种基于GAN的特征分离模型,用于高纯度分离表达相关特征和表达无关特征的Exchange-GAN,通过部分特征交换和各种损失函数的约束实现特征分离,可以获得高纯度相关情感特征,在人脸表情识别中,文中使用经过训练的编码器提取输入图像的特征,并将提取的特征分离为与表达无关的特征张量和与表达相关的特征张量,将与表达相关的特征张量部分特征输入分类器进行人脸表情分类,在遮挡的人脸图像提取特征时,可以将遮挡部分定义为与表达无关的特征张量,进而更专注于提取用于分类的相关特征。
文献[49]提出基于几何信息引导的GAN网络结构,利用面部标志点为限制条件,为了合成任何表情和姿态的面部图像。文中将面部图像以及目标标志点作为信息输入,网络最终合成一张具有面部标志点为主题的新的人脸图像,并在网络中嵌入一个分类器,以方便图像表情分类,有效地缓解了因姿态偏转造成的面部遮挡问题。
然而为了提升GAN等深度学习网络对样本的表情识别率,最直接的网络结构深度化、复杂化的设计思路已被不少研究者放弃,因为这种做法会增加算法运行的时间成本和设备成本。目前,越来越多的研究者秉承深度学习网络的轻量化设计理念,开始将其应用于表情识别任务。文献[50]提出了一种基于人脸分割的实时复杂表情识别框架。该框架包括人脸区域分割网络(face segmentation network,FsNet)以及轻量级表情分类网络(tiny classification network,TcNet)。FsNet采用全卷积的U型网络结构分割出复杂环境人脸图像中与表情识别相关的感兴趣区域,避免了复杂环境下利用特征点分割人脸失败的状况,大幅度提升复杂环境下人脸表情识别的精度。然后使用深度可分离卷积、线性bottle-necks和倒置残差结构构建的TcNet对分割的图像进行表情分类。该方法可以减少网络参数,提高运行速率;并且使用倒置残差结构可以有效地缓解网络特征退化问题。但该网络对负面情绪的表情辨别能力仍有待提高。
对于姿态偏转导致的遮挡,从处理遮挡的角度来说,研究方法大体可分为两类:第一类是利用剩余可见信息的方法。通常检测定位出人脸面部的关键点,利用这些关键点对人脸进行面部姿态矫正,或者在神经网络中添加注意力机制,捕获未被姿态偏转遮挡的重要的人脸区域信息,有效地提取相关表情特征。第二类则是重建面部隐藏的部分。利用算法生成新的人脸图像来解决姿势导致的复杂表情问题,重建的优势在于可以识别面部表情的整个面部的理想状态,如表4。
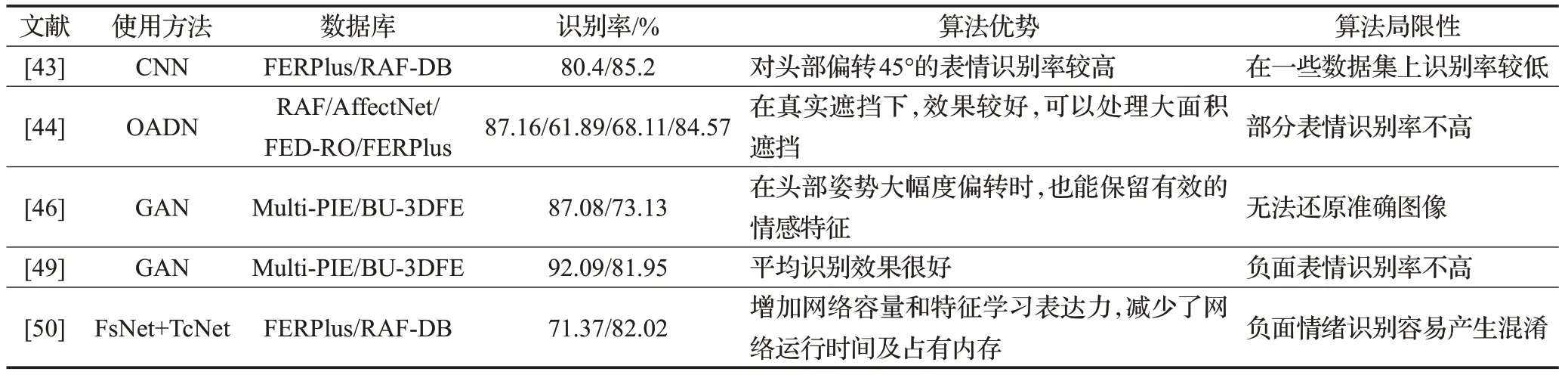
表4 姿态遮挡的方法性能对比Table 4 Performance comparison of posture occlusion methods
2.4 实物遮挡
在实际的场景中,实物遮挡也是较为普遍的遮挡方式。日常所佩戴的口罩、眼镜、帽子、围巾等装饰品都会导致面部信息遮挡,进而对计算机的分类识别带来巨大的干扰。这些因素通常会让模型提取的特征包含冗余的信息,从而失去判断力,为提高人脸表情识别在真实场景下的性能,解决实物遮挡问题是非常必要的。
以往的面部出现实物遮挡时,对待遮挡的方法一般为两种:基于整体的方法和基于部分的方法。基于整体的方法或将人脸作为一个整体直接识别,或对遮挡区域进行重建,以复原出完整的人脸。基于部分的方法通常是将图片进行分割,然后获取每一个分割块的表情特征。文献[51]提出了一种新的门控卷积神经网络(patchgated convolutional neural network,PG-CNN),这是一个具有自注意力机制的卷积神经网络结构,它可以关注面部图像的不同区域,自动感知人脸的遮挡区域,并根据遮挡情况对每个区域进行重新加权,聚焦于信息量最大的且未遮挡区域,这样可以减轻因遮挡而导致的信息缺乏问题。该网络主要分为两部分:区域分解和遮挡感知。首先图像通过VGG网络进行特征映射,然后使用PG-CNN网络将整个人脸的特征图分解成多个子特征图,以满足不同的局部补丁的获得,使用PG单元为每块的局部特征加权,为遮挡部分学习较低的权重,为未遮挡并且信息丰富的部分增加比较高的权重,最后将加权局部特征连接起来进行人脸遮挡表示。使用该方法可以减轻由于缺乏局部信息而造成的影响,可以很好地应用于真实场景的面部遮挡下的人脸表情识别,但是该方法靠地标定位方法来获取遮挡部位,因此过度依赖于具有稳健性的人脸检测模块和人脸地标定位模块。
文献[52]提出了一种端到端的具有注意力机制的卷积神经网络(convolutional neural network with attention mechanism,ACNN)学习框架,可以感知人脸的遮挡区域,并将注意力集中在最有分辨率的未遮挡区域。它在文献[51]基础上增加了为整个人脸的特征映射进行全局加权,将加权的全局面部特征与局部表示相连接作为遮挡表示,由于全局区域与局部区域的不同,文献使用基于局部的ACNN(pACNN)进行局部面部块的特征提取,而使用全局-局部的ACNN(gACNN)将局部表示和全局表示进行集成。pACNN可以关注大多数相关的局部补丁,而gACNN借助全局加权的特征获得更好的准确率,可以提供pACNN中被局部补丁忽略的基本上下文信息,识别率有所提高。
文献[53]提出一种基于空间注意机制的光注意嵌入网络(light attention embedding network based on the spatial attention mechanism,LAENet-SA),使用DenseNet和ResNet作为主干网络构成LAENet样本,替换原始主干网络的较低卷积层,并在每个结构化CNN块之间嵌入注意块。SA模块通过根据表情标签的监督自适应地重新校准空间特征图,使得网络专注于面部表情相关的重要面部局部区域,通过SA模块数量最小,以限制模块复杂性的增加,可以将注意掩码应用于不同层次的LAENet-SA中使用,可以增强浅层和深层情感相关的局部特征,以获得更优的特征提取。通过实验证明基于DenseNet的LAENet-SA在不同的人脸表情数据集中有很好的泛化能力,而基于ResNet的LAENet-SA执行时间短,但在特定的数据库中识别效果好。
文献[54]从全局和局部的角度提出一种全局多尺度局部注意网络(multi-scale and local attention network,MA-Net),由于在卷积神经网络中较浅的卷积具有较窄的感受野,所以可以降低遮挡带来的敏感性,从而学习更全面的特征。在单个基本块中提取多尺度特征,而不是以分层方式获取多尺度特征。所提出的MA网络能够获得稳健的全局和局部特征,MA网络中的特征预提取器利用两个ResNet网络构建基本块获取中间层次的人脸特征。设计一个二分支网络对提取的特征图进行处理,一个是多尺度模块来提取全局特征,将提取的整个特征图作为输入,由于融合不同感受野的特征,有效降低深度卷积对遮挡的敏感性;另一个是用局部注意力模块更专注于几个不重叠的区域特征图的局部显著特征,消除遮挡的干扰。最后使用决策融合进行分类。该网络具有很强的稳健性,在一些常见的野外数据集都实现了很好的性能,但是图片出现模糊的情况时便会降低识别率。
现有的一些方法通常是将整个面部作为一个特征源来进行人脸表情分析,但是心理学研究表明,对于人脸表情贡献最大是眼睛和嘴巴等关键区域,这些区域通常与表情的表达有着密切的联系。文献[55]提出了关系卷积神经网络(relation convolutional neural network,ReCNN),该框架是一种端到端的体系结构能够自适应地捕捉关键区域和面部表情之间的关系,并聚焦于最具辨别力的区域,使用两级关系模块计算关系权重,关系权重用于量化关系,可以着重关键区域。该网络分为三个模块,特征提取模块使用VGG-Face来提取整个人脸的全局特征图,利用关键区域生成模块基于面部肌肉运动来提取具有代表性的关键区域,关系模块用来发现和利用关键区域和面部表情之间的关系。
文献[56]提出含有三元损失函数的师生训练方法,在最后的分类或回归层之前的一层激活函数使用三元损失函数。在神经网络中,利用三元损失函数对于同属一类的物体产生接近的嵌入,对不同属一类的物体产生较远的嵌入的特点。来对遮挡的人脸进行表情识别,该种方法可以应用于大面积遮挡的人脸表情识别,但是在下半脸遮挡的情况下,算法性能有待提高。
文献[57]针对口罩遮挡下的人脸表情识别,提出了一种改进的Xception网络模型,即M-Xception Net(modified Xception net)方法。该方法简化了Xception的参数,保留了残差机制和可分离卷积特征。在保证网络轻量级特性的同时,还保留了Xception模型将低层次特征与高层次特征进行融合的特性。但是该方法倾向于识别负面情绪,对蕴含正面情绪的人脸表情图像的识别效果不明。
文献[58]提出了一种针对佩戴虚拟现实眼镜造成人脸上部遮挡的面部表情识别方法。首先使用几何模型进行遮挡模拟,然后使用迁移学习学习不同数据集的图像在卷积之后相似的低级特征,最后使用VGG和ResNet网络对严重遮挡的面部表情进行分类。加入迁移学习,可以减少从头训练的成本,更好地提高计算速度,但是由于对眼部进行模拟遮盖,对真实场景下的训练结果还未知,对于不同的数据集的识别理想效果不一。
对于实物遮挡的图像,通常也会采用遮挡区域重构的方法进行研究。文献[59]提出一种用原始数据的未损坏区域重建被遮挡区域的方法,以达到人脸图像重建的效果。文中基于人脸大致对称的现象,提出另一半未遮挡的人脸来重建有遮挡区域的遮挡部分,从而降低遮挡的影响。文献分别从整个面部遮挡级别、半面上的块遮挡级别以及遮挡眼睛、鼻子和嘴等部位多种方式进行遮挡处理,使用AlexNet对人脸图像的各种遮挡进行特征提取分类,通过结果测试卷积神经网络与翻转策略的结合可以大大提升遮挡影响下的人脸识别精度。遮挡策略用于一半脸出现遮挡时效果较好,但如果遮挡出现在无法使用翻转策略的区域时,此种方法便不再适用。
文献[60]提出了一种基于对称快速尺度不变特征检测器和描述符(SURF)和异构软分区的新框架,首先利用快速遮挡检测模块来检测出被遮挡的区域,将面部特征点检测算法用于遮挡部分的初步检测,并计算图像梯度并设置阈值得到遮挡区域,然后基于对称转换的无监督人脸修复模块用来进行遮挡修复,根据人脸特征点检测算法建立的关键点坐标找到遮挡部分利用水平翻转用原始图像替代遮挡区域,最后利用基于异构软分区的人脸识别网络进行表情分类。这种方法不仅耗时更少,而且计算量也更少。通过实验证明,相比遮挡的图像复原块重建之后的人脸表情识别率大幅度提高。
文献[61]提出了两阶段的遮挡感知生成对抗网络(occlusion-aware GAN,OA-GAN),第一个生成器合成相应的遮挡图像;而第二个生成器在前者生成的遮挡图像的条件下生成无遮挡的图像。这样可以透明地去除真实世界的遮挡,最大程度地保留有价值的表情特征,使得去除遮挡的过程具有可解释性。
文献[62]提出基于并行GAN网络的有遮挡的动态表情识别方法。对Inception网络进行改进作为生成模型的编码器,相比传统的生成模型,采用双线路对图像进行补全。首先使用并联网络(Para inception network,P-IncepNet)对人脸表情特征进行提取。然后将所提取的特征输入循环网络(long-short term memory,LSTM)增强视频中的时间信息编码。
文献[63]基于WassersteinGAN(WGAN)网络提出了一种稳健的面部表情识别方法,可以通过抑制类内差异和新的数据驱动特征提取框架来突出面部特征,然后建立人脸表情识别任务和身份识别任务之间的对抗关系,以抑制人脸表情特征提取过程中身份信息引起的类内差异来提高表情识别的准确性和稳健性。
文献[64]针对有局部破损或遮挡的低质人脸图像设计了一个端到端的网络模型,将存在局部遮挡的人脸图像作为生成对抗网络的输入,利用对抗损失将遮挡区域进行复原。在分类过程中使用低质人脸表情损失、修复人脸表情损失和原始人脸表情损失三类分类约束判别损失函数构建分类器,对图像进行表情分类。修复后的图像在算法识别率上得到大幅度提升。由于是人工遮挡,遮挡区域主要聚焦于眼部以及嘴部。因此与真实场景下的遮挡情况相比,缺乏多样性,这会影响算法在实际应用中的识别效果。
不同人产生的相同表情在面部运动方面有着很强的相似性,并且不依赖于人的身份信息。文献[65]提出了一种具有跳跃链接的自动编码器的新方法,以在光流域中重建遮挡部分。该方法利用所有可见部分进行重建,因此重建的图像具有更高的可信度,对于眼睛遮挡的图像有着很大的改善。但伴随着重建图像真实性的提高,算法也变得更加复杂,如表5。
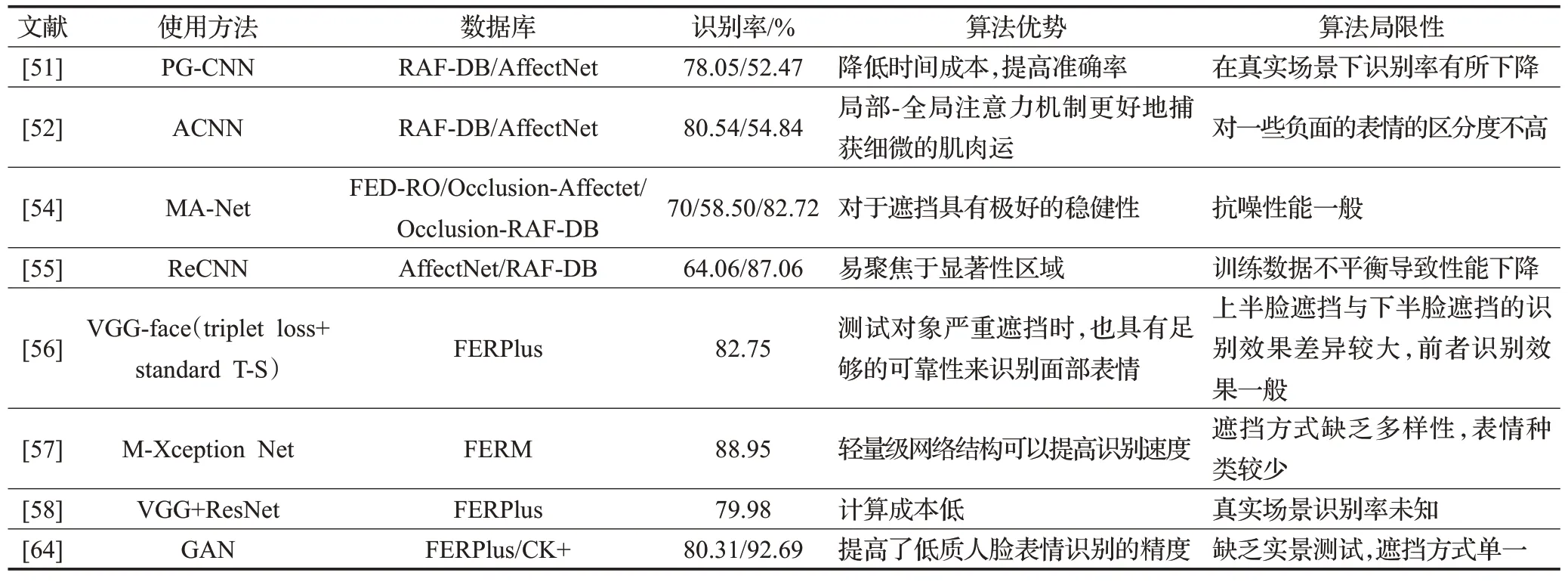
表5 实物遮挡的方法性能对比Table 5 Performance comparison of physical occlusion methods
对于实物遮挡的遮挡方法可根据数据库的类型分为静态表情识别方法和动态表识别方法。
静态人脸表情识别方法可分为三类:第一类是基于人脸关键点的方法,由于人的面部可以被划分为多个人脸关键点标识,即使面部被部分遮挡,仍可关注未遮挡区域的关键点,因此提出注意力分支来引导神经网络关注无遮挡区域的关键点进行表征学习,来获取更多的情感信息;第二类是基于人脸局部区域的方法。将图片分解成较小的区域块,通过加入注意力机制模块可以自适应的捕获人脸区域的重要特征信息,对未遮挡且重要的区域进行较高权重的分配,来提高相关特征的重要度;第三类是基于重构遮挡的方法。试图通过恢复纹理、几何形状以及面部运动来重建人脸。利用一些方法对遮挡部分进行遮挡重构处理来去除遮挡,尽可能地还原图像,从而减少面部遮挡带来的信息损失。
动态表情识别方法可分为三类:第一类是基于人脸关键点轨迹的方法。获取人脸关键点轨迹,则是依据人脸生理结构捕捉人脸形状特征在时间序列内的动态变化。第二类是基于时序编码的方法。提取有表情判别能力的空间特征然后将该信息依次输入到时序网络中进行时序信息的编码。第三类是基于多任务网络的方法。训练多个网络来捕捉时间信息和空间信息,然后将其输出加权融合。
3 总结与展望
人的面部独特性对于人类的身份以及情感分析具有非凡的意义,通过利用人脸进行表情识别将对人们的工作、学习、生活都将带来极大的便利[66]。但这项技术仍然面临着诸多的挑战。遮挡表情识别可以在以下方面开展深入研究:
(1)从实验数据入手,建设以实践为导向的专业数据库
遮挡表情识别是一个刚刚起步的研究领域,因此在实验过程中缺乏专业的、多样的、大型的人脸表情数据库[67]。研究者为了解决这一问题,通常采用两种方式:其一、在专业的无遮挡表情数据库上,采用人工遮挡的方式获取面部遮挡图像。例如:文献[58]为了解决没有佩戴VR头戴设备人群的数据库,便使用标准的面部表情图像的上区域进行遮掩,实现相应的遮挡需求。文献[68]为了使用遮挡图像对网络进行训练,使用一定大小的遮挡块对现有的无遮挡数据进行模拟遮挡操作;其二、搜集网络图片或自建小型的面部遮挡数据。例如:文献[69]自建一个新的多模态数据库来进行情感识别。但是这两种做法的局限性较为突出,前者与真实情况有出入,而且表情类型受限于源数据库;后者搜集的样本面临着表情类别标记问题。自建图像库则受限于规模,而且亟需行业内的认可。
针对这一问题可以通过两个方面加以完善。首先,远期目标是建立自然场景下的专业的大型数据库。以便研究在真实环境下,遮挡物的材质、大小、形状、位置等不同属性对人脸表情识别带来的挑战,增强算法的泛化能力,降低实验数据与真实数据的距离。
其次,近期目标是在现有数据库的基础上进行深度开发。一方面在算法上入手,研发针对小样本数据集的面部遮挡表情识别算法。例如:文献[70]就基于SIFT算法不依赖大数据的特点,利用融合模型解决了卷积神经网络依赖大数据集训练的问题,提高在小样本集中的准确率;另一方面在数据上入手,针对目前面部遮挡条件下,对复合表情[71]识别研究不足的现状,积极开展对现有数据集进行复合表情标注与识别的研究。提高对遮挡图像的复合表情识别的研究深度。
(2)从模型方法入手,设计以实践为导向的轻量级网络
深度学习成为了席卷表情识别领域的一股浪潮。为了提高深度学习模型的表情识别率,普遍的网络设计方法是通过堆叠网络层增加尺度和深度。此类模型往往具有复杂的结构,并且占用着大量的计算资源。这使得它们很难部署在移动端等常见的软件应用平台之上。因此降低网络复杂度,构建以实践为导向的轻量级网络,成为了遮挡表情识别研究的另一个重要方向。目前出现的轻量化手段有两种:一种是在现有网络基础上的模型轻量化处理。常见方法有剪枝、量化、低秩分解、教师-学生网络[72]等;一种是构建专门的轻量化模型。例如:经典的轻量化模型SqueezeNet,通过设计的Fire模块将原始的卷积层进行分解,从而达到减少模型参数,提高运算速度的目的。
然而,与遮挡表情识别任务相匹配的轻量级网络研究仍处于起步阶段,因此本领域亟待研究者钻研、开拓。
(3)从研究思路入手,开展以实践为导向的多领域研究
遮挡表情识别的研究不能局限于人脸识别和表情识别的一般思路。应该从实践出发,结合多领域的研究成果,拓展该项研究在交叉学科下的发展。
首先,结合在测谎、国民安全等领域发挥重要作用的微表情理论,探索人脸部分遮挡下的表情识别研究。
从理论上看,面部遮挡条件下表情识别的准确性取决于对局部人脸细节的精确把握。而微表情正是面部肌肉细微运动下展现的表情形态。因此,遮挡表情识别正是微表情应用的直接领域。目前微表情研究成果多与表情识别中的面部行为编码系统相结合。通过人脸动作单元[73]描述脸部,即,有运动产生的表观变化。例如:文献[74]使用一种基于动作单元注释的新型GAN网络调节方案,使得GAN网络生成的图像对光照变化以及各种遮挡具有一定的稳健性。然而微表情的主攻方向是心理学,很多研究成果还不具备自动化计算的基础,仍需要多学科研究者的密切配合才能实现。
其次,结合在人机交互领域发挥重要作用的多模态情感计算技术,探索人脸部分遮挡下的表情识别研究。
在遮挡条件下,研究者虽然无法获取遮挡区域的完整表情细节,但却可以另辟蹊径,绕开面部视觉特征,从其他角度获取情感信息。进而缓解遮挡带来的表情识别阻碍,催生出更优的方法来处理人脸部分遮挡问题,综合各种情感特征,实现情感判断。例如:文献[75]认为情绪化的肢体语言也是情感识别的重要参考依据,并总结出从身体姿态来进行识别情感的相关研究。文献[69]使用颜色、深度和热视频来识别维度域中的面部表情。文献[76]使用热模态的头部运动和皮肤温度的信息用于面部表情识别当中。
综上所述,遮挡表情识别是人脸表情识别从实验室走向实际应用过程中,亟待解决的重要技术难题。解决这一问题,对于模式识别领域相关技术的落地也会起到重要的指导作用。
猜你喜欢
中国机械工程(2022年8期)2022-05-09
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
儿童时代·幸福宝宝(2021年1期)2021-03-29
小资CHIC!ELEGANCE(2019年40期)2019-12-10
动漫星空(2018年9期)2018-10-26
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
