
基于Transformer的单通道语音增强模型综述
2022-06-23 06:24范君怡杨吉斌张雄伟郑昌艳
计算机工程与应用 2022年12期
范君怡,杨吉斌,张雄伟,郑昌艳
1.陆军工程大学 指挥控制工程学院,南京 210007
2.火箭军士官学校 测试控制系,山东 潍坊 262500
语音增强技术是指从带噪语音信号中恢复出尽可能干净的语音信号,提高噪声条件下语音的质量和可懂度,在学术界和工业领域中得到了广泛的研究和应用[1-3]。和多通道语音增强相比,单通道语音增强具有硬件成本低,能耗小的优势,但由于缺失声源信息和噪声的空间信息,研究更具挑战性。
和传统的单通道语音增强技术[4-10]相比,基于深度神经网络的语音增强技术,不需要对数据设置额外假设条件。通过挖掘大规模数据的内在关联,能够准确实现语音和噪声的估计,在平稳噪声环境下取得了较大的进展。目前,各种网络模型都得到了应用,如深度神经网络(deep neural network,DNN)[11-13]、递归神经网络(recurrent neural network,RNN)[14-15]、卷积神经网络(convolutional neural network,CNN)[16-18]、U-net神经网络[19-22]等。Wang等人在文献[11-12]中率先将深度学习用于语音增强任务的研究。他们使用DNN估计出理想二值掩模(ideal binary mask,IBM)值,将带噪语音信号直接映射到干净语音信号,但DNN存在参数量大、无法利用上下信息等问题。Weninger等人在文献[14]中利用RNN对上下文的特征信息进行建模,在文献[15]中进一步采用长短期记忆人工神经网络(long short-term memory,LSTM)对语音信号进行近似估计,但RNN存在训练时间长、网络规模大、难以实现并行化处理等问题。Park等人在文献[16]中提出了基于CNN的增强模型,通过输入前几帧的带噪语音信号来预测当前干净语音信号,很好地利用了时间相关性。与RNN相比,这种基于时域的卷积网络具有更小的网络规模、更短的训练时间,但CNN存在感受野受限,上下文建模能力弱等问题。为了缓解传统CNN模型的问题,Rethage等人在文献[17]中采用扩张卷积神经网络来提高语音增强的性能。张天骐等人在文献[18]中采用门控机制和扩张卷积神经网络,在增加感受野的基础上,门控机制可以较好地处理上下文特征信息。
近两年,Transformer因可并行、能处理长时间依赖的优势,在语音识别、自然语言处理、图像分割等领域取得了很大成功[23-25],然而由于其采用的解码器(decoder)结构需要同时使用上下文特征信息,不适用于实时处理,在语音增强方面的工作相对较少[26-29]。为了更好地利用Transformer模型提升单通道语音增强的性能,挖掘其在单通道语音增强方面的应用潜力,本文在归纳基于深度学习的语音增强框架基础之上,对基于Transformer的语音增强模型进行了系统梳理,根据Transformer集成的结构不同分类介绍了基于Transformer的语音增强模型,并综合对比了它们的性能。最后,对基于Transformer的语音增强发展方向进行了展望。
1 基于深度学习的单通道语音增强模型
1.1 单通道语音增强数学模型
单通道语音增强中,带噪语音信号可由公式(1)给出:

其中,x(n)表示干净语音信号,d(n)表示加性噪声信号,y(n)表示带噪语音信号。加性噪声是对语音信号质量影响最为严重的噪声之一[30],混响噪声等非加性噪声可以通过某些方式将其转换为加性噪声。
语音增强需要从带噪语音信号y(n)中估计出干净语音信号x̂(n),使得x̂(n)和x(n)差异尽可能小,如式(2)所示:
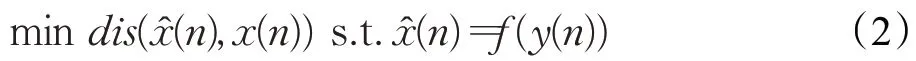
其中,dis(⋅)度量了x̂(n)和x(n)之间的差异,常见的度量方法包括均方误差(MSE)、平均绝对误差(MAE)等。
由于语音中叠加的噪声存在不同类型、不同信噪比的变化,语音增强模型需要对噪声拥有很好的泛化性能,即需要拥有去除不同类型和不同信噪比噪声的能力。
1.2 基于深度学习的增强模型
传统的单通道语音增强模型为了建模和求解的方便,在公式(2)的基础上加入了其他一些约束或者假设条件,然后根据假设的先验知识来直接估计x̂(n)。这些约束和假设不满足时,语音增强性能难以提升。而基于深度学习的语音增强模型不再直接求解模型(2)中的信号估计问题,而是依据设定的目标函数在数据集上获得最优化解的参数,从而隐式地挖掘出带噪语音信号和干净语音信号之间的非线性映射关系f(⋅),实现由带噪语音信号y(n)到干净语音信号x̂(n)的映射。
基于深度学习的语音增强模型如图1所示,其中神经网络可以采用DNN、RNN、CNN、LSTM、U-net、Transformer等不同的网络结构。形式化描述可以用如下函数表示:
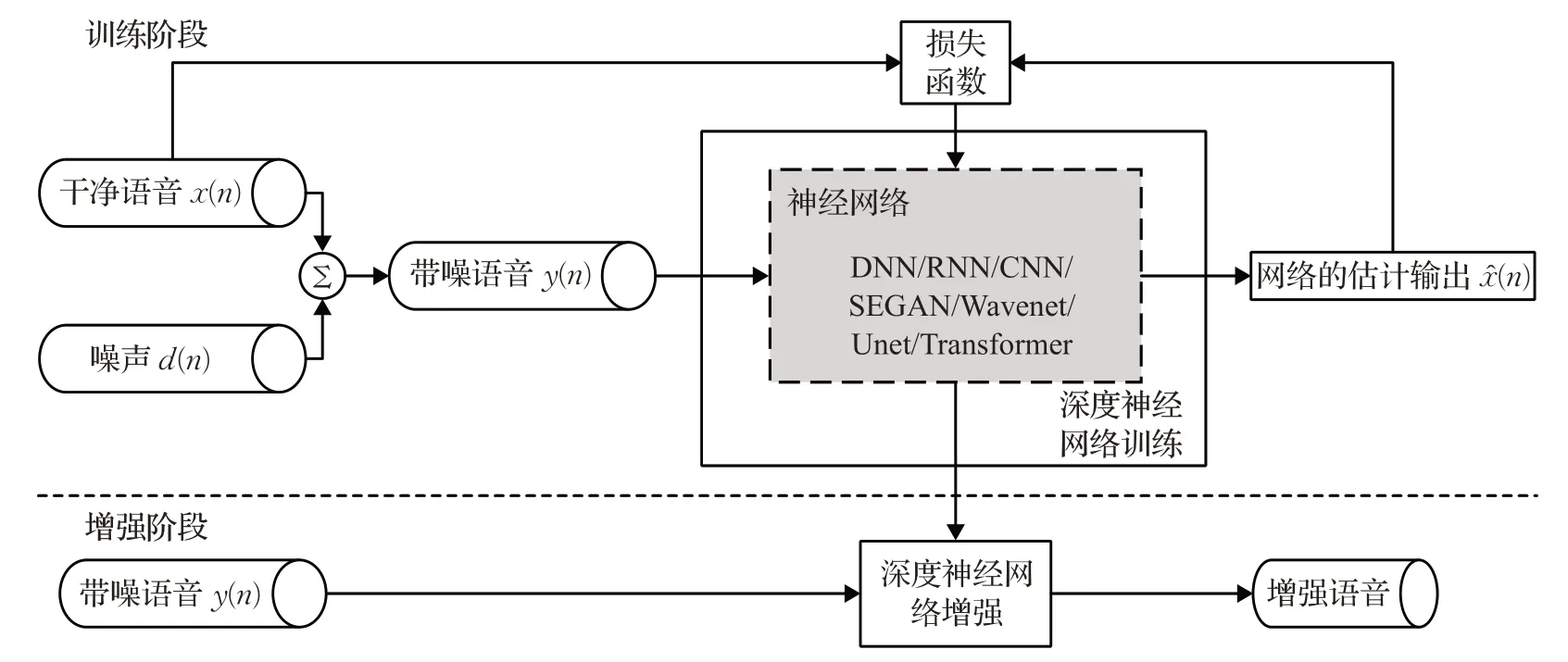
图1 基于深度学习的语音增强模型框图Fig.1 Block diagram of deep learning-based speech enhancement model

其中,y和x̂分别表示网络的输入和输出,它们既可以是时域波形,也可以是时频域变换特征。x̂还可以是时频域掩码估计值。此时,利用x̂对y进行掩模操作得到干净语音的估计。F(⋅,θ)表示参数为θ的网络模型。基于深度学习的语音增强模型将语音增强的问题转换为求参数θ最优解的问题,如公式(4)所示:
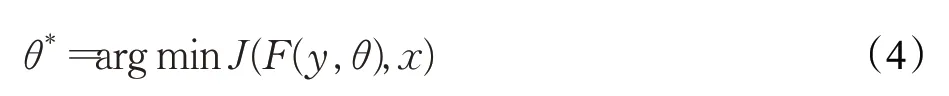
其中,J表示目标函数,可以采用MSE等度量形式。
2 基于Transformer单通道语音增强模型
Transformer神经网络能够以并行方式处理输入数据,有效地解决长时依赖问题,显著减少训练时间和推理时间,已在许多自然语言处理任务上展现了突出的性能[31]。然而,语音增强对上下文特征信息的使用不同于机器翻译等自然语言处理任务,因此传统的Transformer神经网络在语音增强方面表现并不佳。为此,需要使用经过改进的Transformer神经网络[26-29],才能在语音增强中有效发挥Transformer模型的优势。
2.1 传统Transformer模型
传统的Transformer模型如图2所示,由位置编码模块、多头注意力机制模块和前馈网络模块组成。
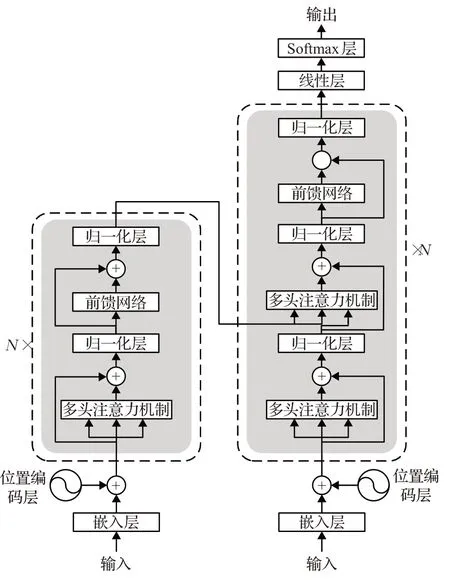
图2 传统的Transformer模型示意图Fig.2 Schematic diagram of conventional Transformer
多头注意力机制模块的核心是自注意力机制。在自注意力机制的实现中,利用一组键K和值V记录已学习的信息,通过查询Q来得到注意力输出,如图3所示。首先将Q和K进行相似度计算获得权重,缩放层除以参数dk(k表示维度)起到缩放调节作用,控制内积不至于太大,然后使用softmax函数对相似度权重进行归一化,最后将归一化的权重和相应的V进行加权求和得到注意力输出。
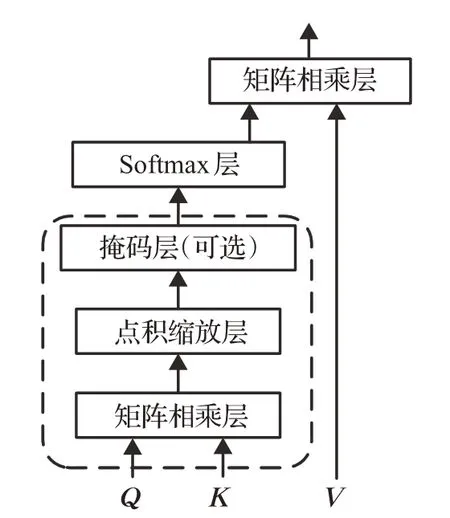
图3 自注意力机制示意图Fig.3 Schematic diagram of self-attention mechanism
计算自注意力机制输出向量的公式如下:
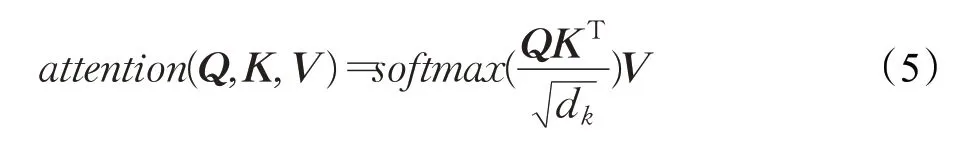
自注意力机制可以“动态”地生成不同连接的权重,从而得以处理变长的信息序列,在一定程度上解决长时依赖问题。
多头注意力机制模块如图4所示,本质是h个自注意力机制的集成,其模块结构并不是很复杂。其中,所有自注意力机制都关注相同的Q、K和V,但每个模块只对应最终输出序列中的一个子空间,并且输出序列互相独立,这就使得多头注意力机制模块能够对不同位置表征子空间中的不同信息实现同时关注。而在自注意力机制情况下,归一化会抑制这种信息
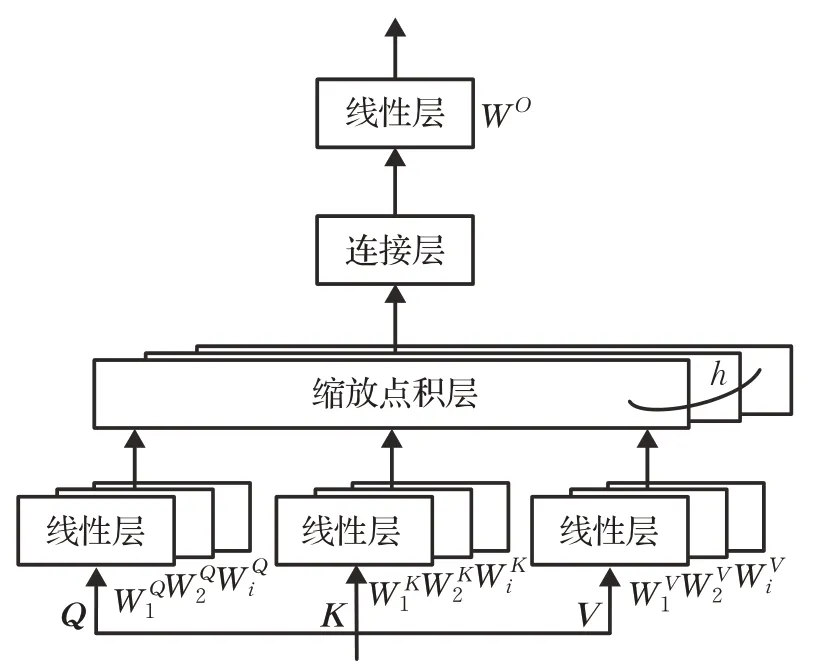
图4 多头注意力机制模块示意图Fig.4 Schematic diagram of multi-head self-attention mechanism
在实现时,首先初始化h组Q、K和V向量,每组Q、K和V的权重参数W都不一样,如式(6)所示,通过引入不同的权重可以允许多头注意力机制模块在表征子空间里学习到更多的信息。然后对每组进行自注意力机制的计算,将得到的自注意力机制输出结果连接起来,再乘以一个权重向量WO就可以得到最终多头注意力机制模块的输出向量。
多头注意力机制模块的计算公式如下所示:
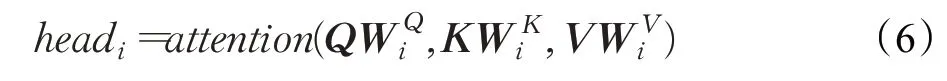
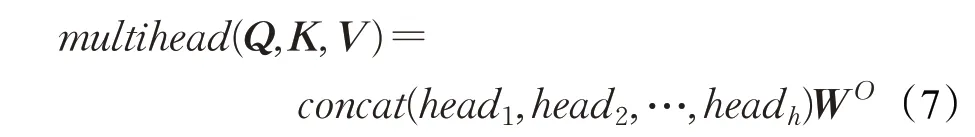
Transformer模型完全避免了循环结构[31],采用多头注意力机制实现了输入输出的全局依赖估计。由于每个注意头可以学会执行不同的任务,多头注意力机制可以产生更具解释性的模型。
前馈网络模块如图5所示,由两个线性变换和一个ReLU激活组成。虽然不同位置的线性变换是相同的,但它们在层与层之间使用不同的参数。受RNN对序列信息跟踪有效性的启发,用于语音增强的前馈网络模块通常会把第一个线性变换层替换为GRU层,来学习位置信息[32]。
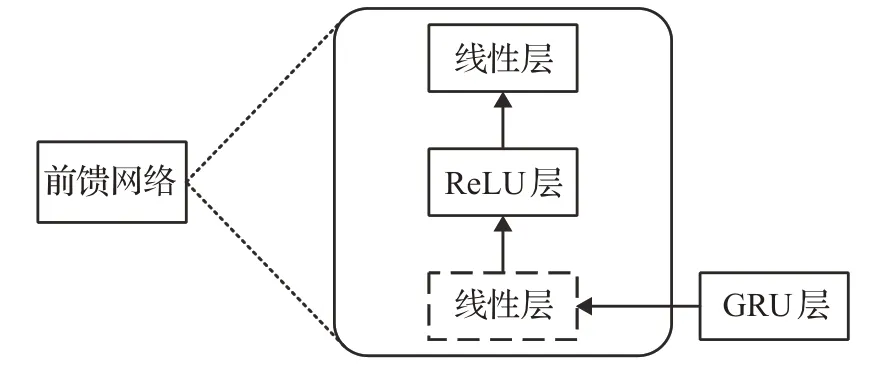
图5 前馈网络模块示意图Fig.5 Schematic diagram of feedforward network module
2.2 改进Transformer模型
已有研究表明,位置编码模块不适合用于声学建模[33]。为了适应语音处理的应用需求,研究者们已提出多种改进的Transformer模型。
文献[26]在Transformer模型中引入高斯加权矩阵,提出了带有高斯加权的自注意力机制,可以实现以高注意力关注较近的上下文帧,以低注意力关注较远的上下文帧。文献[27]利用局部LSTM对语音信号的位置结构进行建模,替换了原模型中的位置编码模块。文献[29]通过引入两个级联的Transformer模块实现双路径Transformer,用于能同时学习语音信号的局部和全局上下文信息。
为适应流式语音处理的需要,需要对自注意力机制或Transformer模型进行修改,避免其全序列上下文信息进行建模。Transformer-Transducer[34]利用两个VGGnet实现位置信息编码,然后将特征送入Transformer进行编码,在Transformer中利用截断的自注意力限制上下文窗口,降低了处理延迟。文献[35]提出了Conv-Transformer Transducer模型,将自注意力限制为只获取上文信息,实现了流式的处理。文献[36]提出了Chunk自注意力编码器,在利用Transformer编码时只需要使用一个Chunk的上下文信息,不再依赖于整段音频输入。Conformer也是一种改进的Transformer模型[37],其包含一维深度卷积,以实现更有效的上下文特征信息建模。文献[38]提出了DF-Conformer模型,使用线性复杂度的注意力和堆叠的扩张卷积来扩展Conformer,通过减少相邻时间帧的建模范围和观察实时因子(real-time feedback,RTF)可知,该模型可以完成实时任务。
2.3 基于Transformer的增强模型
人类在处理复杂听觉场景时,既能注意到关注的语音内容,又能注意到场景中的背景变化。实际上听觉存在多个注意的焦点。同时,由于关注的语音发音通常由同一人发出,和噪声内容相比,语音在较长时间尺度上特征分布的相似性较强。Transformer所具有的多头注意力机制、长时依赖关系估计能力强的优势可以很好地与人类听觉感知的这些特点相吻合。表1给出了目前已有的多种集成Transformer的语音增强工作,这些模型不同程度地改善了原有系统的增强性能。
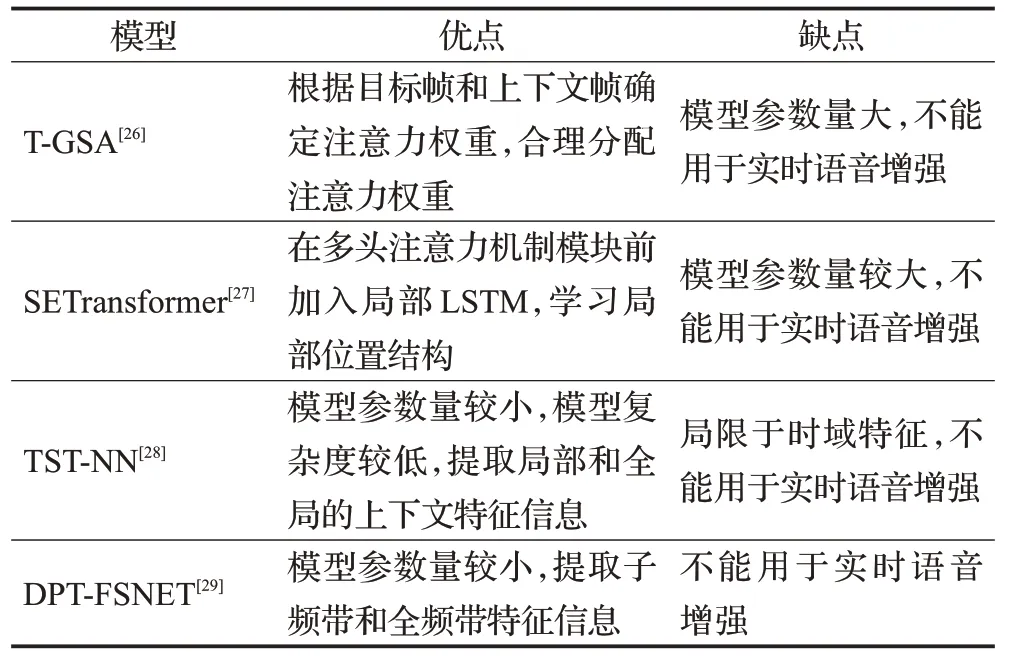
表1 集成Transformer的语音增强模型分析Table 1 Analysis of speech enhancement model integrated with Transformer
根据Transformer模块在网络中的不同位置,可将已有工作分为嵌入式结构和组合式结构两类。采用嵌入式结构的模型在网络的编码层或者解码层中加入Transformer,主要用于改善编码层或者解码层的学习效果(如图6所示)。采用组合式结构的模型则在编码器和解码器之间加入Transformer,主要用于计算掩码(Mask)值,以改善解码器的输入(如图7所示)。
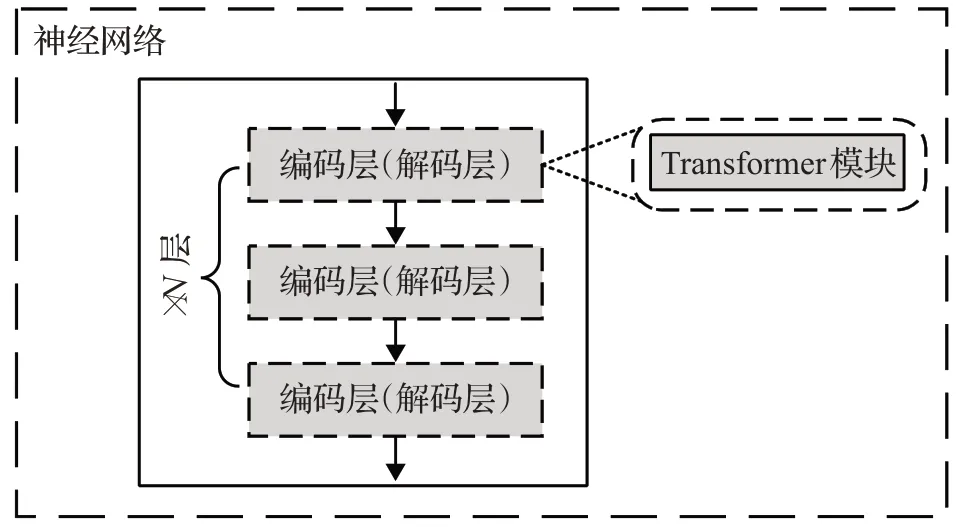
图6 嵌入式结构的Transformer语音增强模型Fig.6 Embedded structure in Transformer speech enhancement framework
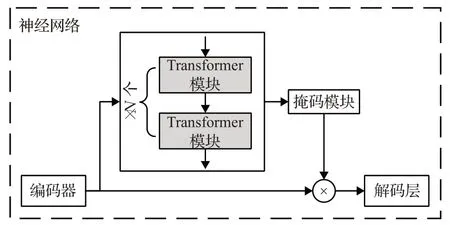
图7 组合式结构的Transformer语音增强模型Fig.7 Combined structure in Transformer-based speech enhancement framework
2.3.1 嵌入式结构的Transformer增强模型
带有高斯加权自注意力机制的Transformer(Transformer with Gaussian-weighted self-attention,T-GSA)模型和语音增强Transformer(speech enhancement transformer,SETransformer)模型是两个采用嵌入式结构的Transformer增强模型。
T-GSA模型。和传统的Transformer不同,T-GSA模型通过部署一个高斯加权矩阵来修改分数矩阵,使注意力权重可以随着目标帧和上下文帧之间距离的增大而减弱,符合语音信号之间的相关性关系。该模型的自注意力机制输出向量的计算公式如下:

在语音增强过程中,为了避免实施输入和输出序列的对齐操作,T-GSA单独使用编码网络或解码网络。图8是在编码网络上进行语音增强的Transformer模型图。每个编码网络层由多头注意力机制模块、全连接层模块和归一化层模块组成。网络的输出是一个时频掩码。将掩码和带噪语音信号幅度谱相乘,得到干净语音信号幅度谱的估计。然后结合原始带噪语音信号的相位重构干净语音信号。
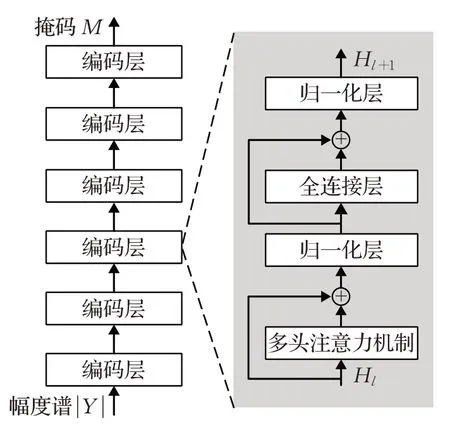
图8 基于Transformer的编码网络模型图Fig.8 Transformer-based coding network model diagram
上述模型只对幅度谱进行处理,缺乏对相位信息的处理,利用复数网络可以同时保留幅度信息和相位信息。复数网络上的Transformer模型需要两个输入和两个输出,分别是带噪语音信号频谱的实部和虚部、时频掩码的实部和虚部。编码网络中只有一个多头注意力机制模块,不能混合提取实部和虚部的隐藏特征,所以需要使用具有两个多头注意力机制模块的解码网络。图9是在解码网络上进行语音增强的Transformer模型图。
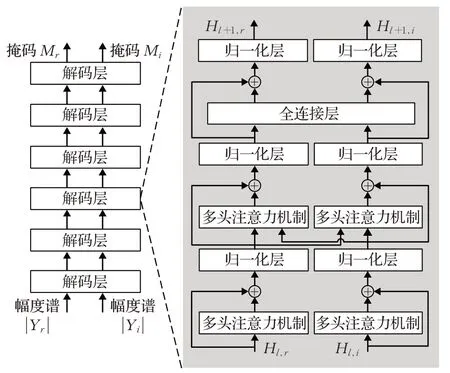
图9 基于Transformer的解码网络模型图Fig.9 Transformer-based decoding network model diagram
和编码网络中的Transformer模块不同,图9右侧的第一层多头注意力机制模块各自关注上层实部和虚部的输出。第二层多头注意力机制模块关注实部和虚部混合路径的输入,利用它们之间的交叉关系来获取更多的隐藏特征。
SETransformer模型。该模型由局部LSTM、多头注意力机制模块和一维卷积网络模块组成,如图10所示。
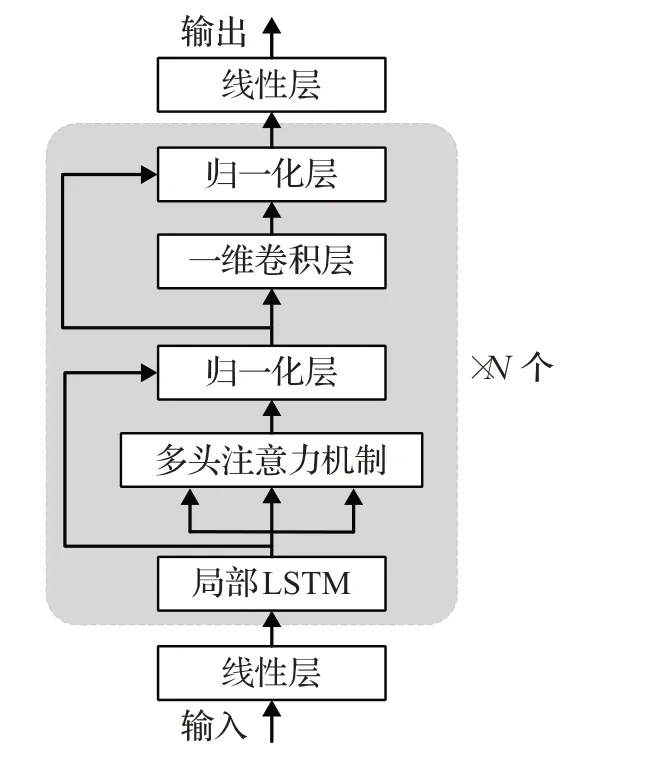
图10 SETransformer整体框架图Fig.10 Framework diagram of SETransformer
SETransformer与T-GSA有两个不同之处。第一个不同是在多头注意力机制模块之前加入了局部LSTM来描述语音信号的位置结构。局部LSTM能够充分捕捉每个窗口内的顺序特征,再通过逐一地滑动操作就能包含全局的顺序特征。另外,局部LSTM只关注本地的短期依赖,不考虑任何长期依赖,因此可以以并行方式来独立处理短序列,降低计算复杂度。第二个不同是把传统Transformer中的前馈网络模块替换成一维卷积网络模块。采用具有ReLU激活的两层一维卷积网络,能够使顺序特征之间的关系更加密切,对提升语音增强效果十分有利。
2.3.2 组合式结构的Transformer增强模型
基于双阶段Transformer的神经网络(two-stage transformer based neural network,TST-NN)模型和基于双路径Transformer的全频带/子频带融合网络(dualpath transformer based full-band and sub-band fusion network,DPT-FSNET)都是组合式结构的Transformer增强模型。
TST-NN模型。该增强模型采用了时域端到端的增强结构,由分割模块、编码器模块、双阶段Transformer模块(two-stage Transformer module,TSTM)、掩码模块、解码器模块和重叠添加模块组成。其中采用的双路径Transformer模型位于编码器和解码器之间,用于估计带噪语音的掩码。图11给出了TST-NN模型图,图中C、N、F分别表示通道、帧的数量帧的大小。
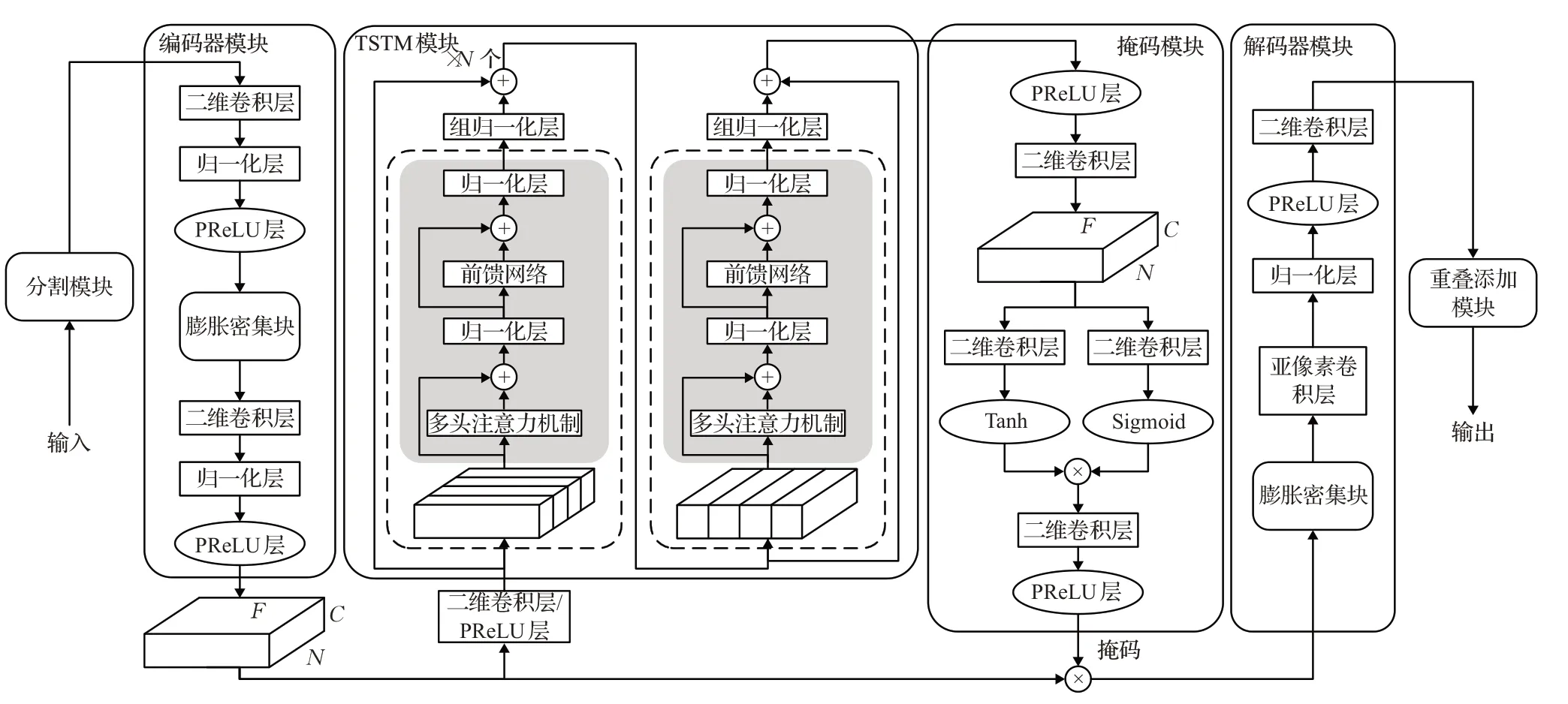
图11 TST-NN模型图Fig.11 TST-NN model diagram
TSTM模块由四个堆叠的双阶段Transformer块组成。双阶段Transformer块由一个局部Transformer和一个全局Transformer组成,可以同时提取局部和全局的上下文特征信息。局部Transformer模块对输入的局部特征信息进行平行化处理,全局Transformer模块用来融合局部Transformer模块的输出信息,以学习全局特征信息,它们都包含了多头注意力机制模块和前馈网络模块。
掩码模块利用TSTM模块的输出来计算用于增强的掩码。该模块首先将TSTM模块的输出通过PReLU运算和卷积对通道维度进行加倍,然后,通过双路二维卷积和sigmoid/tanh非线性运算,将两者的输出相乘,再一次经过二维卷积和PReLU运算后得到掩码。
TST-NN模型直接对时域波形进行处理,避免了频域变换可能带来的失真。
DPT-FSNET模型 该模型在频域上进行语音增强,考虑到语音的频带分布特性,利用双路径Transformer来分别处理全频带和子频带融合网络模型。图12给出了DPT-FSNET模型图,图中C、T、F分别表示通道、帧的数量、频域带数。
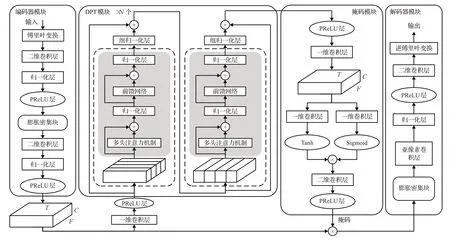
图12 DPT-FSNET模型图Fig.12 DPT-FSNET model diagram
DPT-FSNET的编码器模块和解码器模块结构与TST-NN模型的相同,不同之处仅在于输入输出的特征不同。DPT-FSNET模型的编码器模块输入的是高维时频特征(通道数×帧数×频域带数),解码器模块输出频谱用于恢复增强波形。与TST-NN模型相比,这种处理具有更强的可解释性和更多的特征信息。
虽然DPT-FSNET模型的双路径Transformer(dualpath transformer,DPT)模块和TST-NN模型的TSTM模块中的网络模型都是对局部和全局的上下文特征信息进行建模,但是它们的物理意义不同。DPT中的局部Transformer模块是对输入的局部特征信息进行建模,即对语音信号每个子带的所有时间步长的特征进行建模;全局Transformer模块用于汇总局部Transformer模块输出的每个子带特征,即对语音信号所有子带的特征进行建模以学习语音信号的全局特征信息。和TSTM模块相比,DPT具有更好的解释性。
2.3.3 一种融合U-net的组合式语音增强模型
和CNN不同,U-net采用了具有跳跃连接的U型网络结构,可以实现多尺度特征融合处理[39-40]。文献[19]提出了一种端到端的Wave-U-net语音增强模型,不再需要预处理或后处理,为语音增强任务提供了新的解决方案。文献[21]提出了一个融合LSTM的U-net网络,可以实现基于时域的端到端语音增强。该网络目前能够在用户级别CPU上实现实时语音增强。
基于U-net的特征分析能力,在U-net的框架中引入Transformer,设计了一种新的组合式结构语音增强模型(TU-NET),该模型实现了基于时域的端到端单通道语音增强。如图13给出了TU-NET模型图,图中C、N、F分别表示通道、帧的数量、帧的大小。

图13 TU-NET模型图Fig.13 TU-NET model diagram
TU-NET模型与TST-NN模型、DPT-FSNET模型仅在编码器模块和解码器模块上有不同。TU-NET编解码器模块采用U-net网络的编解码层结构,能够实现不同尺度下的特征融合。
TU-NET的编码器模块如图14所示,该模块包括一个上采样层和多个卷积编码层。该模块直接输入语音时域波形。编码模块首先对语音信号进行上采样,然后通过多层编码层分别进行卷积编码。每个编码层都由一维卷积、ReLU函数激活层、一维卷积层和GLU函数激活层级联而成。
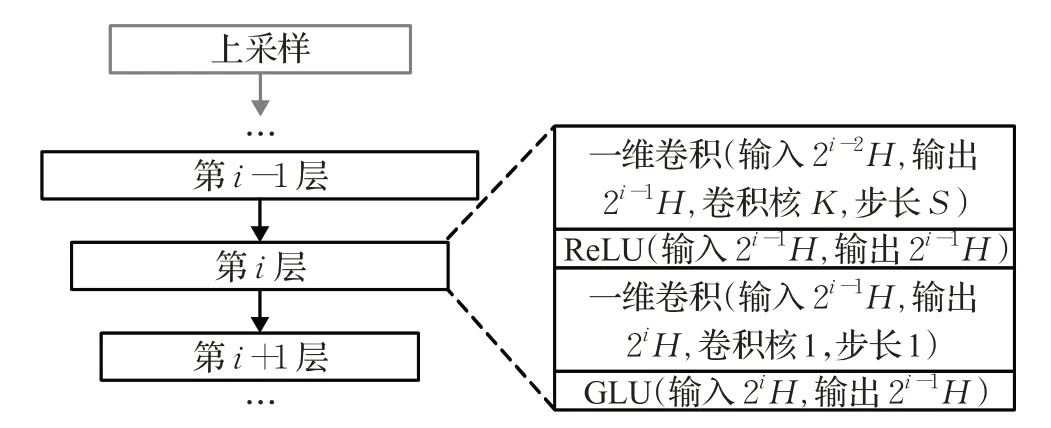
图14 TU-NET编码器模块示意图Fig.14 Schematic diagram of TU-NET encoder module
TU-NET的解码器模块如图15所示,该模块包括多个解码层和一个下采样层。每个解码层由一维卷积层、GLU函数激活层、一维转置卷积层级联而成。同时,每个解码层的输入都由上一个解码层的输出和同级编码层的输出拼接而成。在最后一层,通过下采样将语音信号的采样频率还原为原始输入频率。
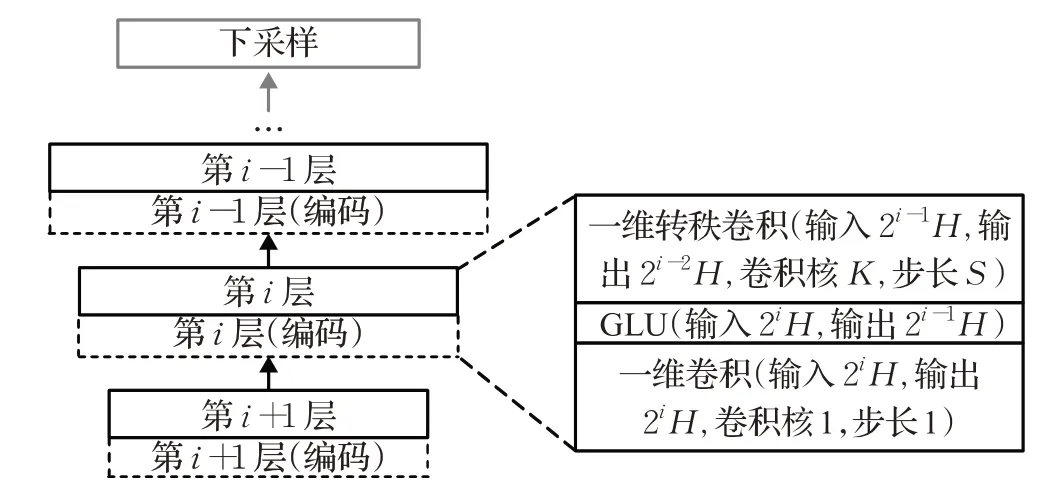
图15 TU-NET解码器模块示意图Fig.15 Schematic diagram of TU-NET decoder module
3 Transformer单通道语音增强模型的性能分析
为分析不同Transformer模块对提升单通道语音增强模型的效果,本章选择几种典型Transformer语音增强模型,在不同测试集上进行对比分析。
3.1 测试数据集
对比实验共采用了两个语音增强中常用的测试数据集。一个数据集是VoiceBank-DEMAND数据集[41],其包含干净语音信号和对应预混合的带噪语音信号。干净语音信号选自Voice Bank corpus数据集[42],噪声信号选自DEMAND数据集[43]和2种人工合成的噪声数据集。带噪语音信号使用ITU-T P.56方法将干净语音信号和噪声信号按不同信噪比加性合成。
另一个数据集包含有由TIMIT干净语音数据集和Musan噪声信号数据集[44]生成的带噪语音数据。TIMIT数据集一共有6 300条语音信号,包括了630个说话人,每人10条语句的发音。带噪语音信号是将Musan数据集中不同类型的噪声信号按照不同信噪比添加到TIMIT干净语音信号上形成的。
3.2 评价指标
语音增强的性能评价指标主要有两大类,一类是客观质量指标,一类是主观测试指标。客观指标主要包括PESQ(perceptual evaluation of speech quality)[45]和STOI(short-time objective intelligibility)[46],主观指标[47]主要包括MOS(mean opinion score)评估方法中的CSIG(MOS predictor of speech distortion)、CBAK(MOS predictor of intrusiveness of background noise)和COVL(MOS predictor of overall processed speech quality)。
PESQ方法侧重于评估处理语音的总体质量。其分值范围为-0.5~4.5,分值越高,语音的总体质量越好。STOI方法是短时客观可懂度得分方法,侧重于评估处理语音的可懂度。其得分范围为0~1,得分越高,语音的可懂度越高。
MOS分由一组测试者试听原始语音和测试语音,并按照评分标准进行主观打分得到。由于MOS评估成本较高,多用CSIG、CBAK和COVL等客观计算方法来拟合。CSIG是用于计算语音失真度的MOS值,CBAK是用于计算背景噪声干扰的MOS值,COVL是用于计算整体语音质量的MOS值。它们的评分范围都为[1,2,3,4,5],共5个等级,1表示语音质量很差,5表示语音质量非常好,且评分越高,语音质量越好。本文对测试模型分别计算PESQ、STOI、CSIG、CBAK和COVL的评估值(用于计算评估值的代码:HTTPS://GITHUB.COM/IMLHF/SPEECHENHANCEMENTMEASURES),来综合评估增强语音的客观质量和主观质量。
3.3 结果及分析
3.3.1 Voice Bank corpus数据集上增强效果对比
为综合对比基于Transformer的语音增强模型性能,引入SEGAN模型[48]、Wave U-net模型[19]、DCUNet-16模型[20]、PHASE模型[49]、DEMUCS模型[21]作为对照。表2给出了不同增强模型在Voice Bank corpus数据集上五种评价指标的结果,前八种增强模型的实验结果源自原始论文。
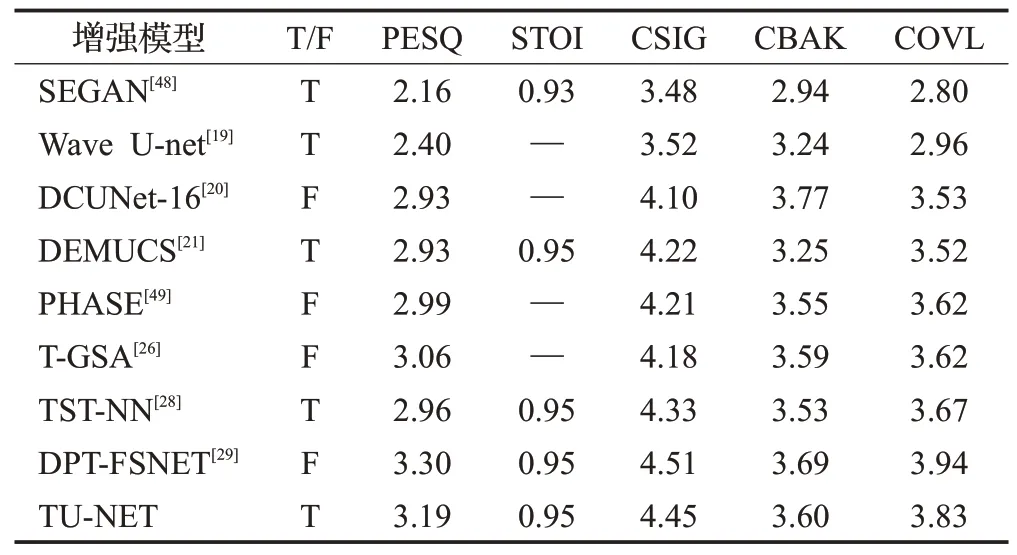
表2 在Voice Bank corpus上的语音评价得分Table 2 Speech evaluation scoreson Voice Bank corpus
从表2中可以分析得出:
第一,与表1的前五种增强模型相比,后四种使用Transformer的增强模型可以显著提升PESQ、CSIG、CBAK和COVL指标得分,这说明使用Transformer模型可以对语音内在关联信息的学习更为充分,因此增强后的语音音质有了较大改善。
第二,综合比较后四种基于Transformer增强模型的各项指标得分,T-GSA和DPT-FSNET的效果要优于TST-NN和TU-NET。T-GSA和DPT-FSNET都是基于频域处理的增强模型,这说明通过Transformer提取时频域特征所包含的注意力信息比原始的时域特征更加有效。由于自注意力机制采用了并行计算,无需将输入语音的特征拉平,避免了因使用全连接网络而产生对语音信号时频结构的破坏。因此,对时频域特征采用自注意力机制,可以更好地区分带噪语音信号中的干净语音和噪声。
3.3.2 TIMIT数据集上增强效果对比
在TIMIT数据集上,对SETransformer和TU-NET的增强效果进行对比,给出了不同信噪比条件下PESQ、STOI的指标得分,并绘制了不同信号的波形图和语谱图。SETransformer所有实验结果源自原始文献[27]。
由表3可知TU-NET的PESQ、STOI指标得分都优于SETransformer,且在不同信噪比条件下语音的增强效果都有了一定的改善。这说明,同时利用U-net不同尺度特征融合的优势和Transformer多头注意力的优势,能够有效提升不同信噪比条件下语音的增强性能。
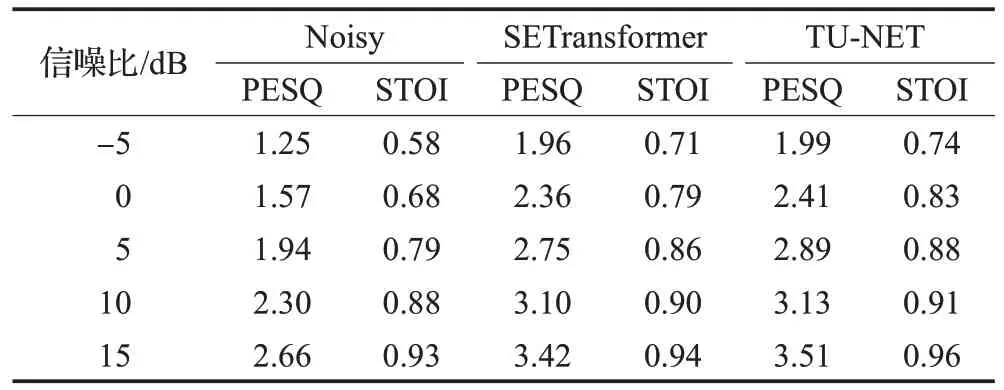
表3 在TIMIT上的语音评价得分Table 3 Speech evaluation scores on TIMIT
为了进一步对比SETransformer和TU-NET的增强效果,图16展示了带噪语音信号、干净语音信号、SETransformer增强语音信号、TU-NET增强语音信号的波形图和语谱图。图中的带噪信号被信噪比为0 dB的手机来电噪声所干扰。红色方框表示语音波形的变化,黑色圆框表示语音信号的谐波结构。对比红色方框中的语音波形可以发现,经过SETransformer增强后的语音波形图存在严重的失真问题且后半段语音信号的波形包络不太完整,而经过TU-NET增强后的语音波形包络依然可以完整的保存。对比黑色椭圆框中的频谱分量可以发现,SETransformer增强模型能够抑制更多的噪声,但会导致语音谐波结构的不清晰,语音信号已明显失真,在听觉感知上该增强后的语音信号音量较小且存在明显的机械声音,而TU-NET增强模型能够保存相对完整的谐波结构;通过观察语谱图可以发现图16(h)中的背景色调偏暖,这是因为舒适噪声的存在,在听觉感知上并不影响人耳的感受,该增强后的语音信号音量正常且较为清晰。
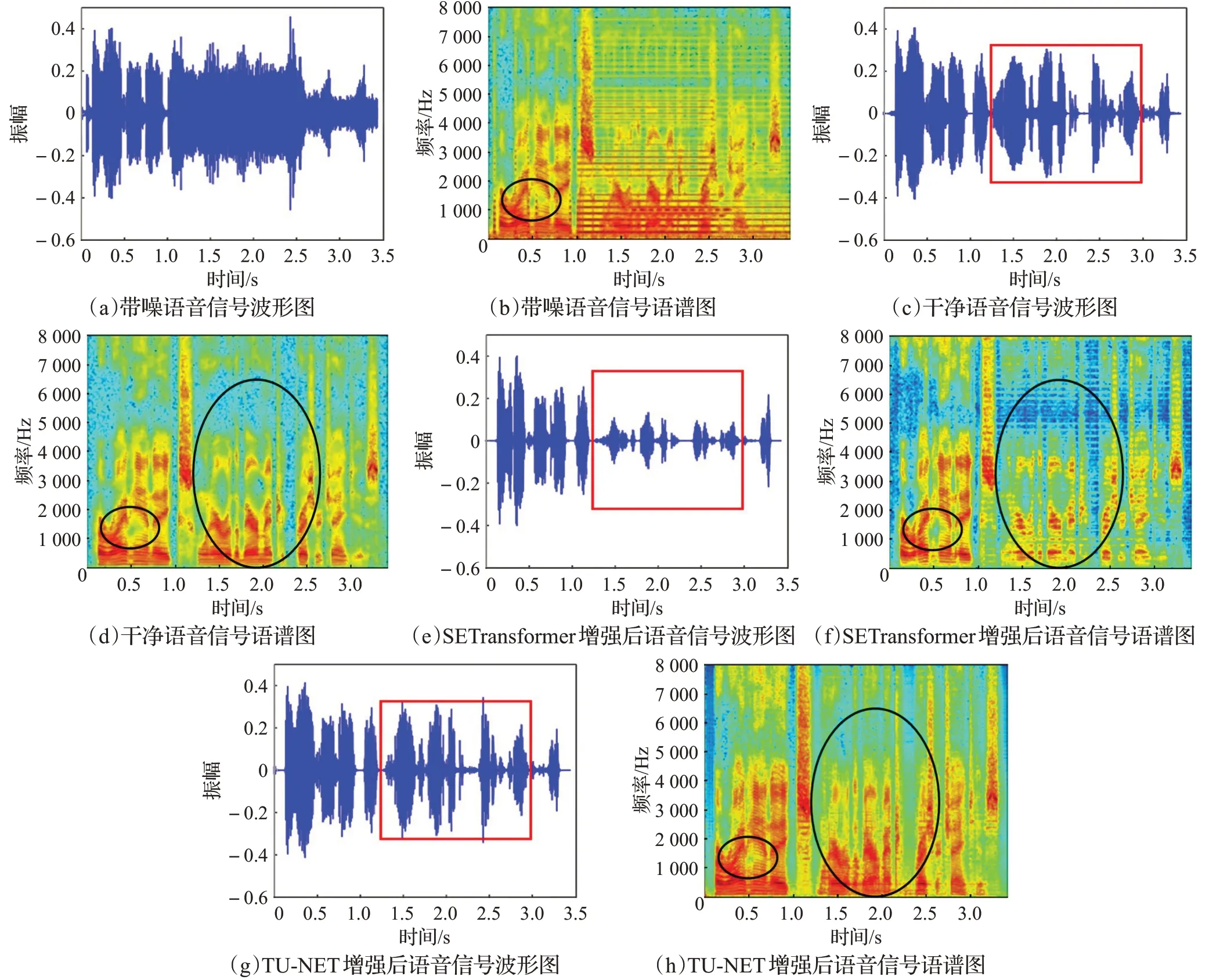
图16 语音质量的对比图Fig.16 Comparison chart of voice quality
4 发展趋势
由于Transformer模型具有可并行、长时预测的性能,在语音增强的研究中逐渐受到越来越多的关注。在现有模型的基础上,还将在以下几个方面有所发展。
(1)结合优化的网络结构和损失函数。深度网络结构和使用的损失函数对网络性能有着重要的影响。TU-net采用了U-net结构,性能在SETransfomer基础上有所提高。SETransformer增强模型采用均方误差(MSE)作为损失函数。而TST-NN同时结合了时域和时频域的损失函数,时域中采用MSE损失函数,时频域中采用平均绝对误差(MAE)损失函数。这些结果表明,采用表征学习能力更强的网络框架,以及更准确反映语音音质和噪音抑制效果的损失函数,将进一步提升语音增强质量。
(2)结合人类听觉感知。在低信噪比、混响等条件下,即使采用了深度神经网络仍难以较好地提升语音增强的质量[47]。若从人类听觉感知机理出发,研究基于听觉感知的语音增强模型或者基于听觉感知的损失函数,将对语音增强模型有很好的推动作用。
(3)引入噪声自适应机制。利用自适应字典学习算法为深度模型构造噪声字典,或者利用强化学习算法自适应学习不同噪声环境下的奖励,可以对网络模型的增强结果作进一步优化,有利于提升增强模型在不同噪声条件下的适应能力。
(4)设计因果Transformer模型。现有基于Transformer的语音增强模型,需要同时使用上下文特征信息,这种对下文信息的依赖使得Transformer模型并不具有因果性,实现的语音增强模型也无法适应即时通信场合。由于Transformer具有参数量少的优势,TST-NN[28]和DPTFSNET[29]的参数规模已低于4 MB,通过因果Transformer模型的优化设计,结合现有硬件发展成果,提高实时比,有望实现嵌入式的实时语音增强系统。
(5)设计多通道增强模型。本文所研究的内容都是基于单通道的语音增强模型。现在很多终端设备都具有多个麦克风,如果能够合理利用不同的通道信息,实现通道注意力机制或者空间注意力机制,从理论上来说有助于恢复干净语音信号。
5 结束语
本文系统介绍了基于Transformer的单通道语音增强模型,通过对网络结构的研究与分类,详细地阐述了T-GSA、SETransformer、DPT-FSNET、TST-NN和TU-NET等网络模型结构,对比分析了这些模型的各自优缺点。文中介绍的五种语音增强模型的原始网络都是基于编码-解码网络模型的,无论采用了何种集成方式,Transformer模块均可以发挥模型自身的优势,很好地提高语音的质量和可懂度。下一步,可根据发展趋势进一步探索Transformer模块在语音增强的深度应用,以更少的网络参数,更快的处理速度为最终的目标,从而更好地实现高质量的单通道语音增强。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
成都信息工程大学学报(2021年4期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国科技纵横(2017年15期)2017-09-09
科技传播(2017年2期)2017-04-06
第二课堂(课外活动版)(2016年2期)2016-10-21
