
新型冠状病毒肺炎的深度学习诊断方法综述
2022-06-23 06:24马金林马自萍
计算机工程与应用 2022年12期
马金林,裘 硕,马自萍,陈 勇
1.北方民族大学 计算机科学与工程学院,银川 750021
2.图像图形智能信息处理国家民委重点实验室,银川 750021
3.北方民族大学 数学与信息科学学院,银川 750021
4.宁夏医科大学总医院 放射介入科,银川 750004
新型冠状病毒肺炎[1](COVID-19)的快速诊断对疾病治疗和疫情防控具有重要意义。逆转录-聚合酶反应(RT-PCR)[2]检测是COVID-19检测的“金标准”,但存在一些缺陷[3]。为了加快诊断速度,提高准确率,肺部影像筛查方法被大量使用。肺部影像筛查主要利用深度学习对肺部影像(X-ray图像和CT图像)进行分析,深度学习技术可以揭示图像中许多不显著的特征,进而给出明确的检测结果。随着大量COVID-19深度学习分类模型的涌现,其性能日益提高[4],COVID-19得以快速准确地诊断。
1 COVID-19图像数据集
自2019年,出现了大量的COVID-19数据集,这些数据集主要由肺部的X-ray图像和CT图像组成(如图1所示),一般分为COVID-19、病毒性肺炎、社区获得性肺炎、细菌性肺炎、其他肺炎和正常等类别。
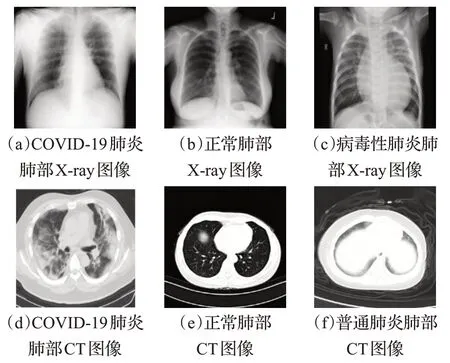
图1 肺部X-ray图像和CT图像Fig.1 X-ray and CT images of lung
1.1 X-ray数据集
X-ray数据集基于X射线获得胸部照片,因其费用较低,最早被广泛使用,但由于其辐射量大,逐渐被CT、MRI等技术取代。
COVID19-DB[5]数据集:COVID19-DB包含3 545张胸部X-ray图像,数据源于RSNA肺炎检测挑战赛收集的胸部图像和COVID-19胸部图像,湘雅医院的四名放射科医生对胸部X-ray图像进行了COVID-19验证和标注。此外,作者使用多种数据增强[6]技术(如随机裁剪、翻转、移动、倾斜和缩放)扩展数据。
Chest X-Ray Images(Pneumonia)[7]数据集:Pneumonia是非COVID-19数据集,包含来自健康受试者、病毒性肺炎患者和细菌性肺炎患者的5 863张X-ray图像。该数据集由训练集、测试集和验证集组成,通常被用于其他COVID-19数据集的数据增强。
Figure 1 COVID-19 Chest X-ray Dataset Initiative数据集:Figure 1 COVID-19 Chest X-ray Dataset Initiative是由COVID-Net团队收集的56个COVID-19图像组成,图像格式为PNG和JPG,可通过网址https://github.com/agchung/Figure1-COVID-chestxray-dataset获取该数据集。
COVID-19 radiography database数据集:COVID-19 radiography database是由来自卡塔尔多哈的卡塔尔大学和孟加拉达卡大学的研究人员连同巴基斯坦和马来西亚的合作者与医生合作创建的,包含3 616 COVID-19阳性、10 192正常、6 012肺部混浊(非COVID-19)和1 345病毒性肺炎图像,格式为PNG。可通过网址https://www.kaggle.com/tawsifurrahman/covid19-radiography-database获取该数据集。
ActualMed COVID-19 Chest X-Ray Dataset Initiative数据集:ActualMed COVID-19 Chest X-Ray Dataset Initiative由238张X-ray图像组成,分为COVID-19和No finding两类,该数据集可通过网址https://github.com/agchung/Actualmed-COVID-chestxray-dataset获取。
1.2 CT数据集
CT图像具有高密度分辨力且能够进行密度量化分析,易于检查病变,能够较早发现小病变,较准确显示出病变范围。临床中,CT图像可以克服X线影像重叠的问题,明显提高病灶检出率。另外,CT图像是数字化图像,能够运用计算机软件进行各种处理。
COVIDx[8]数据集:COVIDx是最大的COVID-19阳性病例数据集,数据集的13 975张CT图像来自5个公开数据库的13 870例患者,其中COVID-19患者266、普通肺炎患者8 066、正常患者8 066。该数据集可通过网址https://github.com/lindawangg/COVID-Net获取。
COVID19-CT[9]数据集:COVID19-CT包含216位患者的349份COVID-19阳性图像和397份COVID-19阴性图像,这些图像均使用PyMuPDF[10]从文献中分割而来,其中阳性图像全部来自于medRxiv[11]和bioRxiv[12]收录的760篇COVID-19的预印本文献,阴性图像的202个来自于PubMed Central(PMC)[13]搜索引擎,其余的195个来自于MedPix。
COVID-CT-Set[14]数据集:COVID-CT-Set是伊朗萨里的内金放射科收集的,包含来自95名患者的15 589幅COVID-19图像和来自282名患者的48 260幅正常图像,格式为16位TIFF灰度图像。
SARS-CoV-2 CT-scan[15]数据集:SARS-CoV-2 CTscan收集了来自巴西圣保罗医院的2 492位患者的CT图像,其中1 262例COVID-19阳性和1 230例COVID-19阴性。该数据集可通过网址https://www.kaggle.com/plameneduardo/sarscov2-ctscan-dataset获取。
CC-CCII[16]数据集:CC-CCII在全球范围内可用,其包含4 154名患者的617 775层CT图像,分为新型冠状病毒肺炎(NCP)、普通肺炎(CP)和正常(normal)三种类型,其中CP包括细菌性肺炎和病毒性肺炎。该数据集目前已经更新到2.3版本,相比1.0版本添加了病灶分割数据集和相应的CSV文件。
COVID-CT-Seg[17]数据集:COVID-CT-Seg包含了20个标注为左肺、右肺和感染的CT扫描图像(COVID-19图像),这些标注先由初级标注师圈定,再由两名有5年经验的放射科医师细化,最后所有标注由一名有10年以上胸部放射学经验的资深放射科医师验证细化。该数据集可通过网址http://medicalsegmentation.com/covid19/获取。
MosMedData[18]数据集:MosMedData包含1 000余位患者的胸部CT图像,分为COVID-19(CT1-CT4)和正常(CT0)五类,采用NIFTI格式。医学专家对一小部分图像(n=50)进行了标注,每个CT切片都标出COVID-19特有的像素区域,并标注肺组织异常。可通过网址https://mosmed.ai/datasets/covid19_1110/获取该数据集。
1.3 X-ray与CT混合的数据集
COVID-chestxray[19]数据集:COVID-chestxray是一个公开的COVID-19病例数据集,由434张COVID-19的X-ray图像和少量CT图像组成,分为COVID-19、普通病毒性肺炎和细菌性肺炎(MERS、SARS、ARDS)三种类型。
COVID-19-CT-CXR[20]数据集:COVID-19-CT-CXR是从PubMed Central Open Access(PMC-OA)子集的COVID-19相关文章中提取的公共数据库,包含COVID-19的1 327张CT图像和263张X-ray图像。
主要的COVID-19数据集如表1所示。
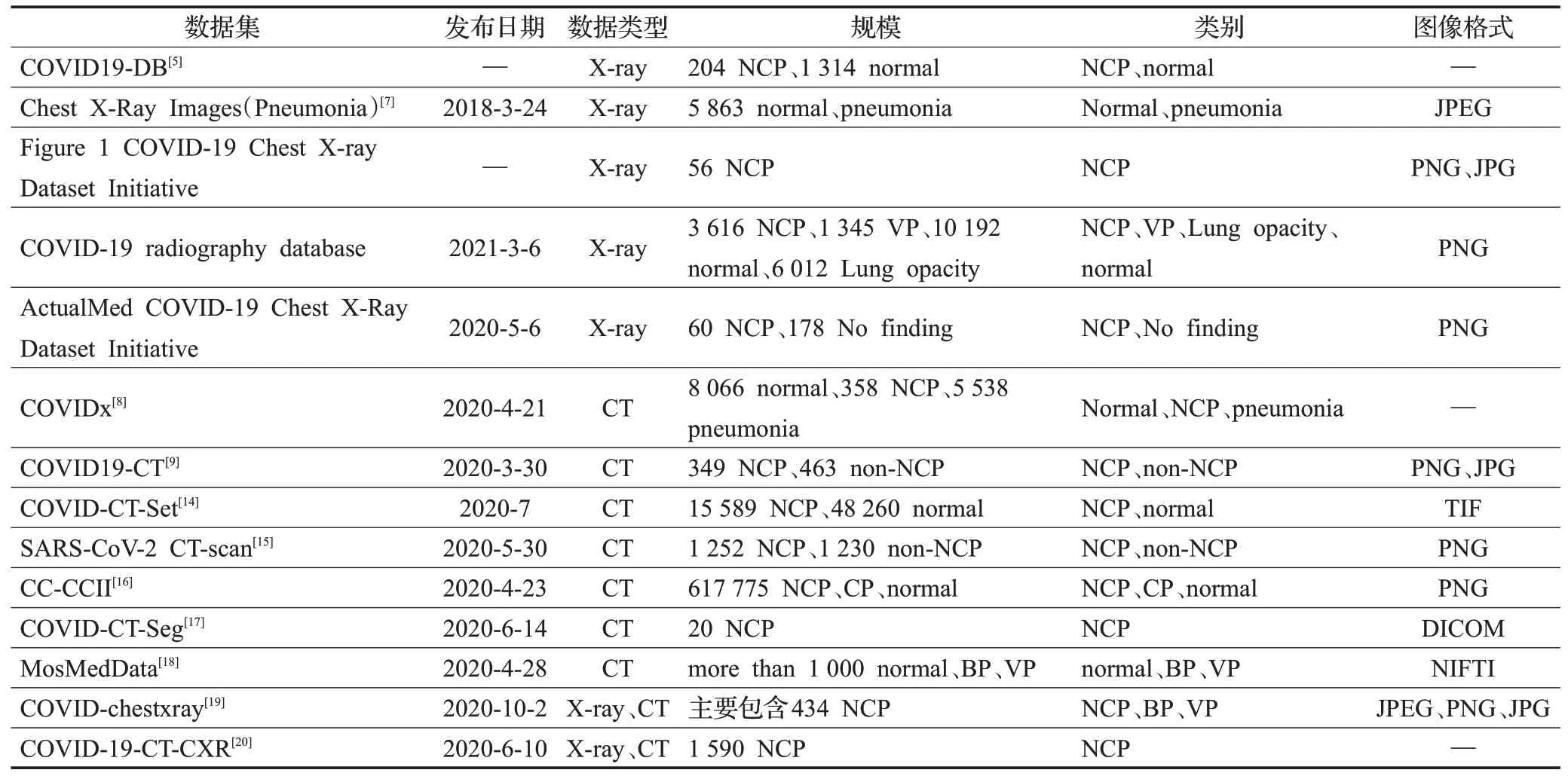
表1 主要COVID-19数据集汇总表Table 1 Summary table of major COVID-19 datasets
2 基于深度学习的诊断方法
基于深度学习的诊断方法主要是借助深度学习模型对图像进行分类,常用基础分类模型有:VGGNet[21]、Inception[22]、ResNet[23]、DenseNet[24]、CapsNet[25]和Efficient-Net[26]等模型,整体结构如图2所示。
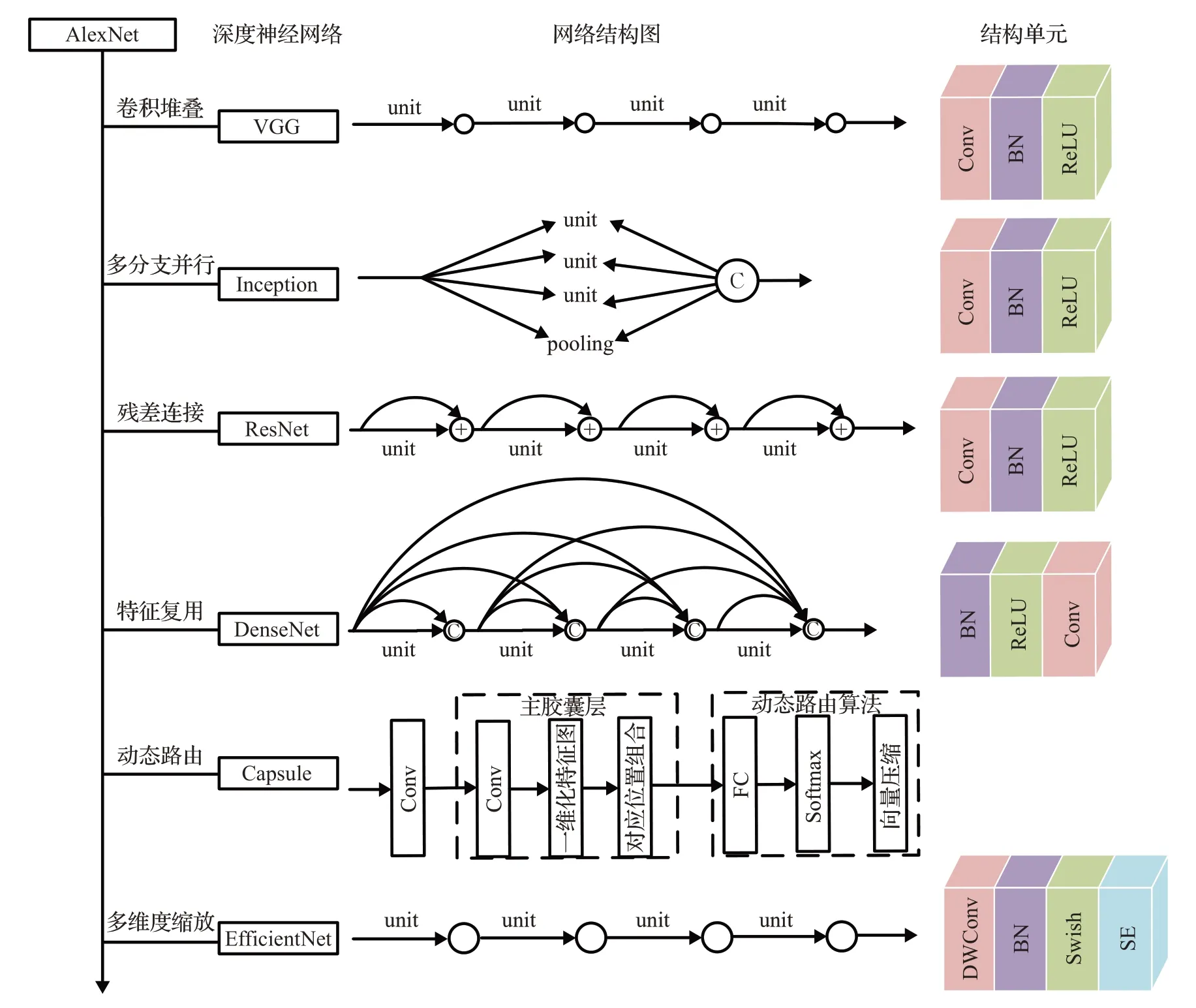
图2 基于深度学习诊断方法的整体结构图Fig.2 Overall structure diagram of deep learning-based diagnostic methods
2.1 基于VGGNet的分类模型
VGGNet主要包含VGG16和VGG19两种结构,通过采用小卷积核、小池化核,增加网络深度来提高特征学习和模型表达能力,在保证获得相同感受野下,减少网络参数同时捕获更多细节,部分学者将VGGNet用做诊断COVID-19的骨干网络。
自动化COVID-19筛查模型TLCoV[27]使用VGG16通过迁移学习[28]将在ImageNet数据集上学习的权值、偏差和特征转移到TLCoV模型,降低计算量,采用离线增强技术来增强数据,实验在COVID-19、病毒性肺炎和正常的三分类上取得97.67%的准确率,96.65%的精度,但是并未提及灵敏度和特异性等指标,且使用了大量池化层丢失了识别对象的空间信息,后续可以引入胶囊网络的路由机制来避免这一问题。
Wang等[29]提出以VSBN为骨干网络,集成卷积块注意模块[30](CBAM)和多路数据扩充方法(IMDA)的ACNC模型来检测COVID-19。VSBN以VGG作为骨干网络,CBAM通过通道注意模块(CAM)和空间注意模块(SAM)来细化三维特征图,专注显著特征并增强对噪声的鲁棒性,IMDA有助于减少数据集过小带来的过拟合,实验显示,该模型对COVID-19、社区获得性肺炎、继发性肺结核和健康四种分类的灵敏度、精度都在95%以上。
Shibly等[31]以VGG16为基础提出了一个由24个卷积层、两个全连接层和六个汇集层组成的新框架。该研究使用了13 800图片作为数据集(来自COVIDx和作者定制)进行实验,避免了数据集过小的局限。不足的是,该模型在较差图像的预测任务中做出了不正确的结论。
COV-VGX[32]引入了两种类型的分类器,一个是正常、COVID-19和普通肺炎的分类器,另一个是COVID-19和普通肺炎分类器,该模型使用了迁移学习,在经过预训练的VGG16模型上采用相等且足够多的数据集进行评估,结果显示两种分类器上均取得了良好效果,但是无法区分病毒性肺炎和细菌性肺炎的图像。
整体来看,使用VGG作为骨干网络的模型大多都针对小数据集实施了改进措施,对比结果可以发现,其中COV-VGX[32]效果最好,证明了一个平衡的大数据集对于基于VGG网络模型的训练的重要性。
2.2 基于Inception的分类模型
相比VGG来说,Inception模型采用不同尺度的多分支结构提取多尺度特特征,通过聚集相关性强的特征来保持网络结构的稀疏性,更多小尺度卷积核也使网络更加轻量化,还利用1×1卷积减少参数量并加深网络,提高网络计算效率和性能。模型使用全局平均池化层替换全连接层,提高了运算速度,Inception也常被研究人员应用到COVID-19检测中。
Das等[13]提出Truncated Inception Net从非COVID-19或健康病例中筛COVID-19阳性图像。该模型训练时间少,参数量少,使用六种不同类型的数据集进行验证,在COVID-19阳性、肺炎与健康的分类中取得99.96%的准确率(AUC为1.0)。但该模型受限于其在图像中定位疾病的能力,从更深层的激活图中可以看出,该模型开发的是图像特征的内在表示,而不是准确的空间热图,该问题可以通过在大量不同疾病的图像上预训练来避免。
CoroNet[33]使用Xception[34]作为基础模型,在末尾添加一个脱落层和两个全连接层,构成新的深度卷积神经网络,使用迁移学习来克服过度拟合的问题,实验结果显示CoroNet计算量较小,在小规模数据集上取得了较好的结果,但是由于数据集较小,患者信息较少,给实验带来了一定的局限性。
以Inception为基础的模型在减少参数量这一方面具有一定的优势,其中以Truncated Inception Net[13]最低,仅有COVID-Net[8]的18%。
2.3 基于ResNet的分类模型
ResNet提出残差连接将浅层特征信息直接连接到深层,利用新的表达方式实现层间恒等映射。ResNet的每层特征仅需要在前续层特征基础上学习新的特征,残差连接中反向传播的导数需要加上恒等项,有效地避免了过小梯度信息的消失,缓解了梯度弥散和网络退化问题。通过残差连接技术可以加深网络,从而获得更强的逐层学习能力和更强的模型表达能力,因此,基于深度学习的诊断方法多以ResNet为骨干网络。
以ResNet50[35]为骨干的3D深度学习框架COVNet[12]能够提取肺部CT图像的二维局部特征和三维全局特征。COVNet使用最大池化操作组合提取切片特征,并反馈到全连接层和softmax激活函数,以生成每种类型(COVID-19、社区获得性肺炎和非肺炎)的概率。为了提高模型的可解释性,作者采用梯度加权类激活映射(Grad-CAM)[36]方法可视化深度学习模型决策的重要区域,但是该方法主要关注异常区域,而忽略了正常区域,易造成错判。此外,COVNet只给出疾病的类别,未明确疾病的严重程度。
为明确COVID-19的严重程度,Goncharov等[37]提出了基于阈值的方法(因为病理组织比健康组织密度大,所以相应的CT体素在Hounsfield单位中具有更大的强度)来量化COVID-19严重程度,但是该方法存在血管和支气管的假阳性预测和无法将COVID-19相关病变与其他病理区分的缺点。因此作者采用了一个多任务模型,该体系结构的分段部分是切片式的2D三角网模型,输出用于评估严重性分数,分类与分割部分共享一个公共的中间特征图,这些特征图被堆叠并通过金字塔汇集层聚集成特征向量,在两个完全连接层后进行sigmoid激活,将特征向量转换为COVID-19概率。实验证明,该多任务架构同时实现COVID-19识别和严重性量化的最高质量指标,但是在非COVID-19患者中的分类管道会产生相对较少的假阳性警报,需要放射科医生二次查看。
相比COVNet[12]只检查和修改了一个CNN来说,Ardakani等[38]提出了10个广泛使用的网络,通过分析投资回报提高网络性能,同时避免了COVNet将整个肺部区域输送到网络进行区分时冗余数据造成的误诊。实验结果显示,所有网络中性能最好的是ResNet101,其灵敏度为100%,特异性为99.0%,准确率为99.5%。因此,作者认为ResNet101是一个高灵敏度的模型,比Rahimzadeh等[39]提出的模型灵敏度高了近20%。但该方法也存在一定的局限性,首先,该模型的性能并没有与放射科医生进行比较;其次,该实验数据是由医生复核得到的,由于小部分COVID-19患者的RT-PCR结果为阴性,导致医生在筛选图像时,这些患者可能被错误地排除在外,造成一定的实验误差。
迁移学习能够解决小数据问题,降低模型计算量,被部分研究人员应用到网络中。Narin等[40]使用五个预训练模型(ResNet50、ResNet101、ResNet152、InceptionV3[41]和Inception-ResNet-V2[42])实现三种不同的二分类,即COVID-19和正常(健康)、COVID-19和病毒性肺炎、COVID-19和细菌性肺炎。虽然作者使用迁移学习解决数据量少和训练时间不足的问题,但是有限的数据依然对研究造成了限制。实验结果表明,ResNet50预训练模型获得了最好的分类性能(数据集1的准确率为96.1%、数据集2的准确率为99.5%、数据集3的准确率为99.7%)。
Pathak等[43]用迁移学习调整深层的初始参数,作者用ResNet50提取潜在特征,采用平滑损失函数来增强结果,并用10倍交叉验证方法来防止过拟合问题,但是该研究并没有考虑超参数的最优选择问题(该问题由Ucar等[44]和Polsinelli等[45]解决)。
El-Kenawy等[46]提出了一种基于高级松鼠搜索优化算法(ASSOA)的两阶段分类方法,对胸部X-ray图像中的不同病例进行分类。第一阶段,使用迁移学习技术进行预训练,采用ASSOA对ResNet-50提取的特征进行选择;第二阶段,用选择后的特征优化多层感知器(MLP)神经网络的连接权值,对输入情况进行分类。该研究将ASSOA同灰狼优化算法(GWO)和遗传算法进行比较,验证其有效性。实验显示,(ASSOA+MLP)算法达到了99.7%的最高准确率。此外,该模型能够有效地对受灾情况进行分类,平均准确率为99.26%。
特征金字塔网络(feature pyramid networks,FPN)[47]的对模型性能有不小的影响。Rahimzadeh等[14]将FPN用于进行图像预处理,从而丢弃肺内无法正常显示的CT图像,以加快处理速度。但是由于测试数据集不平衡,导致该方法的实验准确性和灵敏度较低。Wang等[5]在COVID-19识别的基础上添加了肺部定位功能,该研究包含两个深度学习模型Discrimination-DL和Localization-DL:Discrimination-DL在ResNet基础上构建了一个FPN的基本单元作为COVID-19鉴别器确定识别概率;Localization-DL使用残差网络来定位受感染的肺部区域。其鉴别准确率和定位准确率分别为98.71%、93.03%。但由于缺乏来自数据源的对应图像,实验并未纳入其他类型病毒性肺炎的X-ray图像,导致实验过于单调。
ResNet模型轻量化也是一个研究方向,COVIDNet[8]就是一种基于ResNet50的轻量级网络,该网络先在ImageNet数据集上进行预训练,然后使用Adam优化器在COVIDx数据集上训练。COVID-Net不仅能够在保持低计算复杂性的同时增强表示能力,而且在检测COVID-19阳性病例的同时限制假阳性COVID-19检测的数量。虽然使用COVID-Net可以帮助临床医生改善筛查,并在加速计算机辅助筛查时提高信任度和透明度,但实验结果显示该模型对于COVID-19的检测准确率较低。
由于Resnet具有避免小梯度消失,缓解梯度弥散和网络退化的特性,但是该类模型在轻量化方面发展较为缓慢,轻量化的COVID-Net的参数量远大于Truncated Inception Net。
2.4 基于DenseNet的分类模型
DenseNet网络中任意层进行两两互连,将ResNet跨层连接进一步应用,通过对不同层特征图的复用,加强网络各层之间特征传递并减少层间相互依赖性,其中网络每层输入特征图由前续所有层信息组合而成,不同长短的跨层连接提供紧凑且有区别的特征,有效地缓解了深层网络中因梯度消失而难以优化的问题,DenseNet还利用全部特征进行最终预测来提升模型鲁棒性,最终利用较小模型尺寸和计算量,在标准数据集上获得较好性能,因此涌现出许多基于DenseNet的COVID-19分类模型。
Wang等[48]提出了一个用于COVID-19分类和预后分析的全自动深度学习系统,该系统包含:利用DenseNet121[24]+FPN完成肺部区域的自动分割、非肺区域抑制和分类与预后分析三部分。作者使用两步迁移学习策略解决数据集较小的问题,并用数据链可视化算法从两个角度分析COVID-19网络学习到的特征。虽然取得了较好的分类效果,但是也存在没有考虑患者的患病程度(该局限被Goncharov等[37]解决)和小数据集导致的准确性较低的问题。
Montalbo等[54]提出基于截断和连接的DenseNet轻量级模型Fused-DenseNet-Tiny来检测COVID-19。该方法融合了一个截断的DenseNet模型镜像,一半从COVID-19病例的X-ray数据集和ImageNet中重新训练了整个网络,另外一半上层部分冻结,以生成不同的特性批处理,两种模型的不同特征在网络结束前被融合,并通过一组带有正则化的层来处理,以防止过拟合问题。虽然该模型只有120万个参数,与其他先进的模型相比计算成本和参数尺寸相对大幅降低,但其提取特征能力下降,使得无法在更大的数据集上应用。
DWSDenseNet[55]用深度可分离卷积代替SDenseNet部分稠密块传统卷积,以降低网络的参数量。与VGG16、ResNet18、ResNet34、DenseNet121和SDenseNet模型的比较实验表明,DWSDenseNet在三分类实验中相较于ResNet34在准确率、灵敏度和特异性上都有提高。相较于基础网络SDenseNet,DWSDenseNet的参数量减少了43.9%,但分类效果并未下降。由于实验仅在一个数据集上进行,模型的可重复性未得到充分验证。
可以看出,基于DenseNet的分类模型大多一定程度上修改了,使网络的参数量大大降低,尤其是Fused-DenseNet-Tin的参数量仅有120万,相比基于Inception的模型更具优势。但是该类模型也存在难以复现的缺陷,轻量化应用是该类模型的发展前景。
2.5 基于CapsNet的分类模型
CapsNet与最先进的深度学习网络不同,它使用浅层网络,让capsule层嵌套在其他层中,从而避免增加更多的层使得网络深层次化。每个capsule被用于检测图像中的特定实体,动态的路由机制将检测到的实体发送给父层。相比CNN需要从多方面来考虑成千上万的图像,capsule网络能够在不同情况下,从多个角度识别物体,减少了数据量,在COVID-19检测中展现了良好的性能。
COVID-FACT[56]利用胶囊网络作为其主要构建模型,在第一阶段检测显示感染的切片,第二阶段对患者进行划分,同时增加了一种阈值方法对零个或很少的CT图像进行分类。虽然该模型的可训练的参数、监督要求和注释远少于其他模型,但是其会将社区获得性肺炎病例错误分类为COVID-19,需要放射科医生通过手动改变图像对比度来检测这些异常,不仅准确率低而且会给医生带来不便。相比之下,使用预训练和迁移学习的COVID-CAPS[57]取得了98.3%的准确率,比COVIDFACT高近8%。
神经网络Convolutional CapsNet[58]为二分类(COVID-19和无发现)和多分类(COVID-19、无发现和肺炎)提供了准确的诊断方法,Convolutional CapsNet模型相对简单,具有更少的层,但是所用数据集较大,要求输入图像的大小相同,需要大量的时间和硬件资源去处理图像。
对比发现,基于CapsNet的模型在小数据集上更具有优势。
2.6 基于EfficientNet的分类模型
EfficientNet提出了B0~B7的缩放尺度,交叉使用3×3和5×5的卷积核进行特征提取,提出了组合缩放系数,可同时对宽度、深度和图片分辨率进行参数调整,提高了精度。以EfficientNet为基础的COVID-19检测模型在准确率上取得了最佳结果。
由中国工程建设焊接协会主办的“中国工程建设焊接论坛”是我国工程建设焊接领域的年度盛会,论坛以“新技术、新工艺、新材料、新设备”应用推广和技术交流为主题开展论坛交流,助推工程建设领域的科技创新,提升工程建设相关行业和会员单位的焊接制造能力和产品质量水平,促进“产、学、研、用”的有效融合,推动中国由焊接大国向焊接强国的升级。
Monshi等[59]基于EfficientNet-B0提出CovidXrayNet模型,通过优化数据增强管道和模型超参数来检测胸部X-ray图像中COVID-19,解释并可视化不同数据增强技术,使用管道将最佳顺序进行组合,更好地提取COVID-19诊断相关特征,模型在增强的平衡COIVDcxr和基准COVIDx数据集的三分类任务中达到95.82%准确率。虽然结果表现良好,但假阴性的分类结果(它误认了四名COVID-19患者患有肺炎,一位COVID-19患者是正常的)会给临床带来不必要的负担。另外,通过额外的数据扩充和更好的超参数来构建和优化可以避免一些问题,但由于没有适当的COVID-19数据,CovidXrayNet很难在其他数据集上实现95.82%的准确度。
基于EfficientNet的集成卷积神经网络ECOVNet[60]使用ImageNet预训练权重,通过模型快照和集成预测降低泛化误差,通过Grad-CAM可视化一个激活图来解释预测并识别图像中的关键区域,实验在COVIDx上进行验证,显示对COVID-19的召回率为100%,准确率为96.07%,高于CovidXrayNet,但实验并未提及特异性等指标。
Bhatt等[61]在EfficientNetB3模型的基础上,结合迁移学习技术与渐进调整技术[62]增强效果,使用Grad-CAM[36]对图像进行分类,使用COVIDx数据集进行验证,在二分类和多分类上准确性都达到了100%,但是由于数据集过于单一,模型的分类结果很难复现。
从性能来看,基于EfficientNe的分类模型取得的效果最佳,但是网络往往缺乏可重复性,对数据集往往有很高的要求。因此,通过数据集的多样化来提高模型泛化能力是该类模型的一个发展方向。
2.7 基于多网络融合的分类模型
由于COVID-19的图像较少,很容易因数据集不平衡而影响模型的训练效果。因此,Rahimzadeh等[39]将实验分为训练和验证两部分,训练时将训练集分为8个连续阶段。作者使用基于Xception和ResNet50-V2的级联神经网络,实现了99.50%的平均精度,但灵敏度仅有80.5%。
Tiwari等[63]采用CapsNet与VGG16级联网络,既解决了传统CNN的局限,又增强了初始特征图的计算能力,在小数据上取得了良好的性能,但是该网络更加适用于二分类。
DenseCapsNet[64]由密集卷积网络和胶囊神经网络融合而成,利用各网络的自身优势,减少卷积神经网络对大量数据的依赖。该方法可取得90.7%的准确度和90.9%的F1值,其COVID-19的检测灵敏度可达96%。
COFE-Net[65]利用模糊逻辑的原理,通过Choquet模糊积分,结合三个最先进的CNN(InceptionV3、Inception-ResNet-V2和DenseNet201)测量决策值检测COVID-19。虽然使用了Sugeno模糊测量极大地减少了搜索空间,但是通过实验确定最佳测量仍然是一个耗时的过程。多个数据集上的实验均取得了良好效果。由于CNN分类器的特征提取自整个输入图像,但区别元素集中在图像的特定部分,会造成一定的分类误差。
多融合的网络模型是集合了两种或多种基础模型的优点,使融合模型的检测效果更佳显著。但是,这也增加了网络的深度,使得计算量和参数量提升,有必要引入轻量化模块。
表2汇总了基于深度学习的诊断方法。
表3汇总了基于深度学习的诊断方法的性能对比情况。
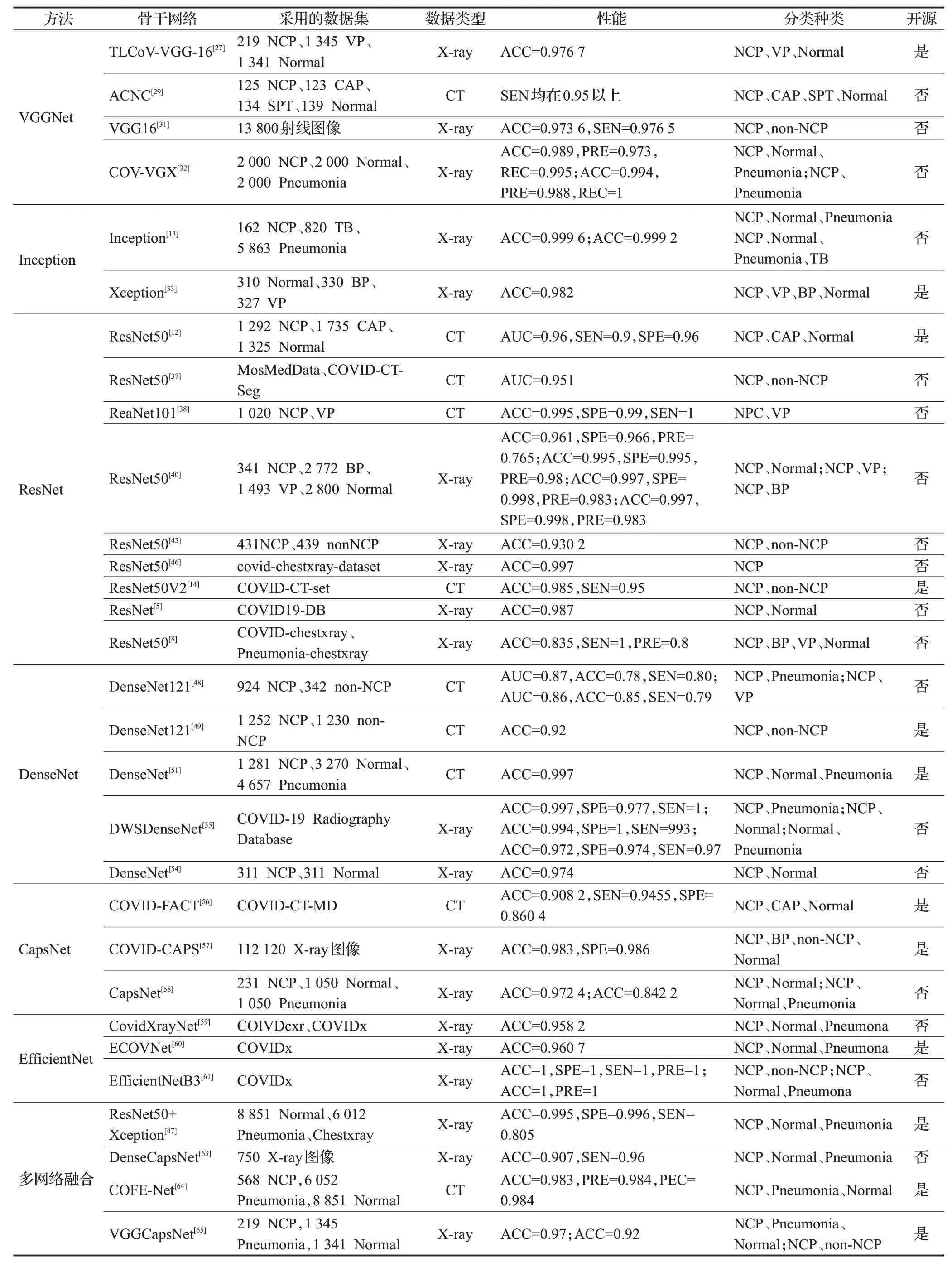
表3 深度学习诊断方法性能对比表Table.3 Performance comparison table of deep learning diagnostic methods
3 深度学习与其他机器学习方法结合的诊断方法
深度学习与其他机器学习方法结合的诊断方法主要分为三种:深度学习与有监督方法结合的分类模型、深度学习与弱监督方法结合的分类模型和深度学习与无监督方法结合的分类模型,其中深度学习与有监督方法结合的分类模型又分为结合SVM分类器的模型、采用贝叶斯算法的分类模型和结合其他有监督方法的模型三种,图3展示了深度学习与其他机器学习方法结合的诊断方法结构图。
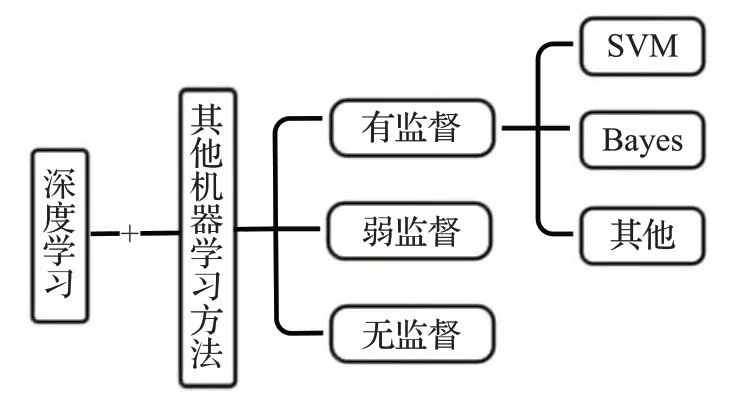
图3 诊断方法结构图Fig.3 Diagnostic method structure diagram
3.1 深度学习与有监督方法结合的分类模型
3.1.1 结合SVM分类器的模型
Canayaz等[66]分别使用AlexNet[67]、VGG19、GoogleNet和ResNet等网络进行特征提取,然后借助元启发式算法(二元粒子群优化[68]和二元灰狼优化[69])选择最有效的特征,最后用SVM[70]分类器进行分类。研究表明,使用BPSO[68]算法的VGG19模型获得了99.38%的最佳精度。该实验展示了不同深度学习模型在COVID-19诊断中的表现,但是对比发现不是每个深度学习模型都能在所提出的方法中取得足够的成功,模型缺乏广泛性。
Ozkaya等[71]提出了一种融合和排列深层特征的方法检测早期COVID-19。作者采用VGG16、GoogleNet和ResNet50模型进行特征提取,将得到的特征向量与这些模型进行融合,得到高维融合特征,以此来减少从单个CNN网络获得的特征不足的影响。同时采用t检验方法进行特征排序(通过考虑特征向量中相同特征的出现频率和平均特征的发现频率来进行排序),减少了时间损耗和计算机复杂性。在进行特征融合和排序后,训练二进制SVM分类器进行分类。SVM使用了线性核函数,并把特征转移到空间,从而更好地分类特征。通过观察混淆矩阵可以发现,该模型容易将图像错判为COVID-19。
Togacar等[72]开始时使用模糊颜色技术和叠加技术来处理数据,接着,采用两种深度学习模型(MobileNetV2[73]和SqueezeNet[74])对堆叠数据集进行训练,并用社会模仿优化(SMO)算法提取有效的特征,最后使用支持向量机(SVM)[75]对有效特征进行组合和分类。该模型具有参数量较少的优点,为集成到便携式智能设备中创造了条件。但是,由于采取了叠加技术该方法要求原始图像和结构化图像的分辨率必须相同,并且无法处理低分辨率的图像。在特定数据集上的实验结果显示,单独的COVID-19数据分类成功率为100%,COVID-19、正常和肺炎图像三分类的总成功率为99.27%。
CovXmlc[76]采用多模型分类方法将X-ray图像分为COVID-19和正常。该模型在VGG16卷积网络的最后一层结合了SVM,并在VGG16和SVM之间增加包含最大池化层、密集层和dropout层的新卷积结构,使得VGG16和SVM更好地同步。将CovXmlc与使用不同参数和度量的五个现有模型进行比较表明,在作者提出的最小数据集上,CovXmlc的准确率高达95%,显著高于现有模型的准确率,但实验未考虑存在不同COVID-19变体的情况。
3.1.2 采用贝叶斯算法的分类模型
贝叶斯算法是处理参数优化问题的有效算法[77-78]。Ucar等[44]和Polsinelli等[45]都是在SqueezeNet的基础上,使用了贝叶斯算法对初始学习率(在训练期间用于更新权重的比率)、动量(该参数影响权重更新,考虑到前一次迭代的更新值)、L2正则化(一个正则化项,用于损失函数的权重,以减少过度拟合)等超参数进行优化[44-45]。不同的是文献[45]所述方法添加了训练数据集的扩充、旋转(随机角度在0°到90°之间)、缩放(随机值在1.1到1.3之间)和高斯噪声等处理。而文献[44]则针对数据集的不平衡问题添加了多尺度增强过程。
较高的假阴性会造成诊断成本偏高,针对该问题Ghoshal等[79]采用加权贝叶斯[80]卷积神经网络(BCNN)估计深度学习的不确定性(缺乏训练数据造成的模型不确定性和由于类重叠、标签噪声等造成的随机不确定性)从而提高人机组合的诊断性能。在数据方面,作者使用数据集的平均值和标准偏差值对图像进行标准化,并进行实时数据增强以防止过度拟合并增强模型的学习能力;在网络方面,作者在ResNet50V2[81]的基础上引入全连接层,将最大激活层之后的下降权重作为高斯过程的近似,并将其转换为近似贝叶斯推理来估计模型不确定性。实验表明,模型的不确定性和预测的准确性之间有很强的相关性。
3.1.3 结合其他有监督方法的模型
Hu等[82]创建了一个具有挑战性的临床数据集COVID19 DIAG,提出一种新的不平衡数据分类方法,该方法采用自适应辅助损失(DSN-SAAL)深度监督学习方法进行诊断COVID-19。由于所有的模型参数都是通过网络迭代自动学习的,该方法可以应用于不同的数据集,但有限的数据集对深度学习模型的训练产生一定影响。
Elazab等[83]提出一种基于GCN的具有监督机制的新方法从X-ray图像中诊断COVID-19。该模型将监督机制与VGG网络结合起来,丰富了特征提取功能,取得了96.41%的准确率。该模型只关注二分类任务,且没有定量疾病状态。
3.2 深度学习与弱监督方法结合的分类模型
使用三维检索的DeCoVNet[84]采用弱监督[85]的方法:首先使用U-Net[86]分割肺部区域,然后将分割后的三维肺部区域输入三维深度神经网络来预测COVID-19感染的概率。为解决数据集过小带来的过拟合问题,DeCoVNet采用了数据增强技术。该模型易导致较高的假阴性,且存在一些局限性:首先,用于肺部分割的U-Net模型没有利用时间信息,而是使用不完善的真实度模板进行训练;其次,研究中使用的数据来自一家医院,没有进行跨中心验证;另外,在诊断COVID-19时,以黑盒方式工作,但由于该算法基于深度学习,其可解释性仍处于早期阶段。
Uemura等[87]开发了名为pix2surv的弱监督网络,可用于从图像中自动计算事件发生的时间信息,以进行愈后预测。与目前可用的实验室测试和现有的基于图像视觉和定量预测因子相比,该网络有利于预测COVID-19患者的疾病进展和死亡率。此外,还可以通过该模型将患者分为低风险组和高风险组,其范围比其他预测因子更广。但该方法只考虑基于图像的信息,将非成像临床数据集成到模型中是提高其预测准确性的有效方法。Chikontwe等[88]提出基于双注意对比的MIL(DA-CMIL)模型来检测COVID-19。DA-CMIL是一种端到端的弱监督模型,它将多个患者CT切片(视为实例包)作为输入,输出单个标签。基于注意力机制的池化层用于隐式选择潜在空间中的关键切片,而空间注意力机制通过学习切片空间上下文进行可解释的诊断。该模型取得了98.4%的AUC,98.6%的精度。但是该文献没有研究健康图像,在检测健康图像时会产生不利结果。
3.3 深度学习与无监督方法结合的分类模型
Mansour等[89]提出了一种新的基于无监督DL的变分自编码器(UDL-VAE)模型,用于COVID-19检测和分类。UDL-VAE模型采用基于自适应维纳滤波(AWF)的预处理技术提高图像质量,使用Inception V4作为特征提取器,无监督的VAE模型用于分类过程。UDL-VAE模型在二元类和多类上的准确率分别达到了0.987和0.992的效果。虽取实验取得了优良效果,但在超参数设计方面有待优化。
Bargshady等[90]提出CycleGAN-Inception模型来识别COVID-19,该方法首先采用无监督方法进行数据增强并调整数据大小,之后把规范化的数据传入InceptionV3预训练模型中进行验证,实验使用的数据集包含X-ray和CT图像。该模型具有较好的兼容性,但只使用了一个公共数据库,数据缺乏多样化,模型的可重复性有待验证。
表4汇总了深度学习与其他机器学习方法结合的诊断方法。
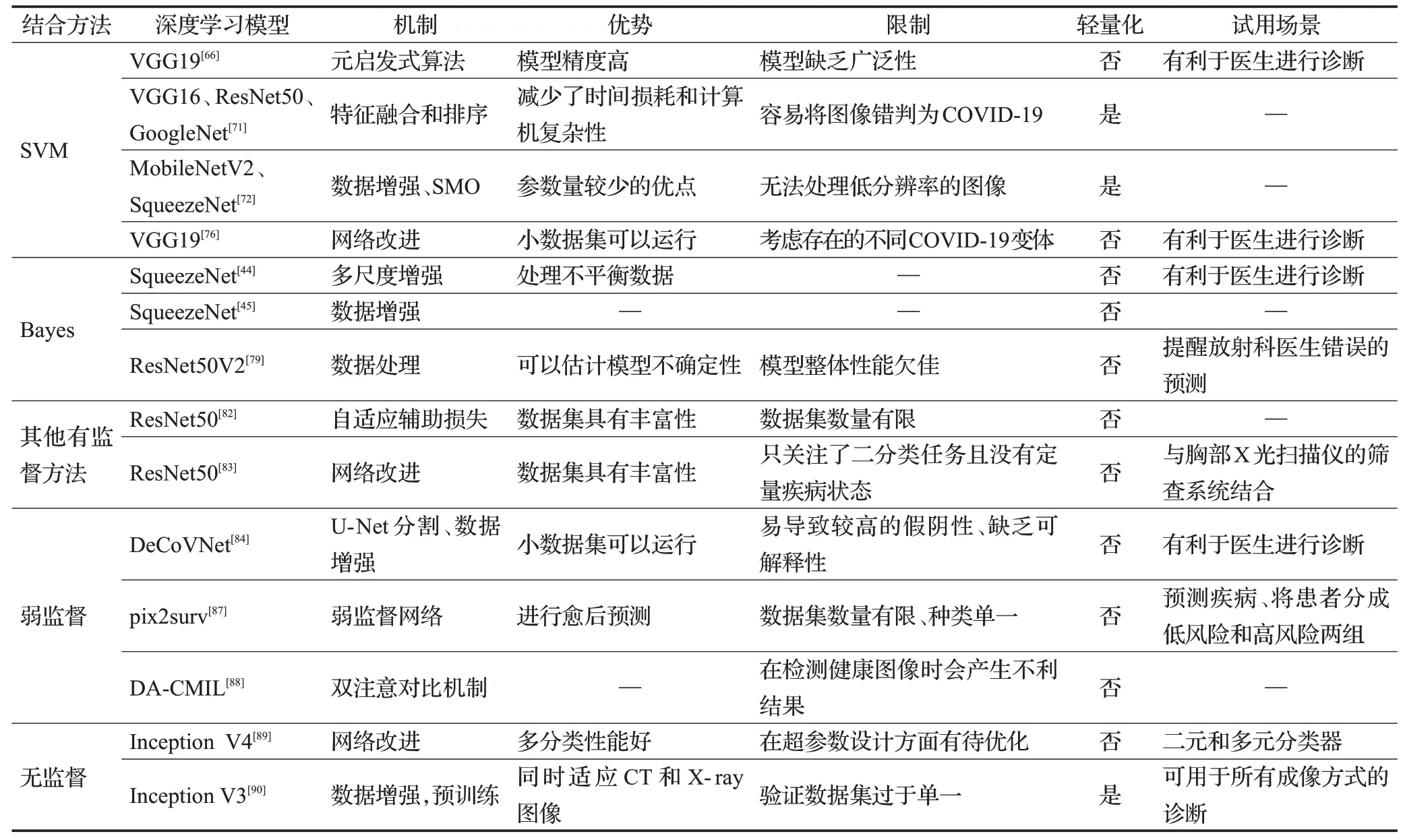
表4 深度学习与其他机器学习结合方法汇总表Table 4 Summary of deep learning combined with other machine learning methods
表5汇总了深度学习与其他机器学习方法结合诊断方法的性能对比情况。
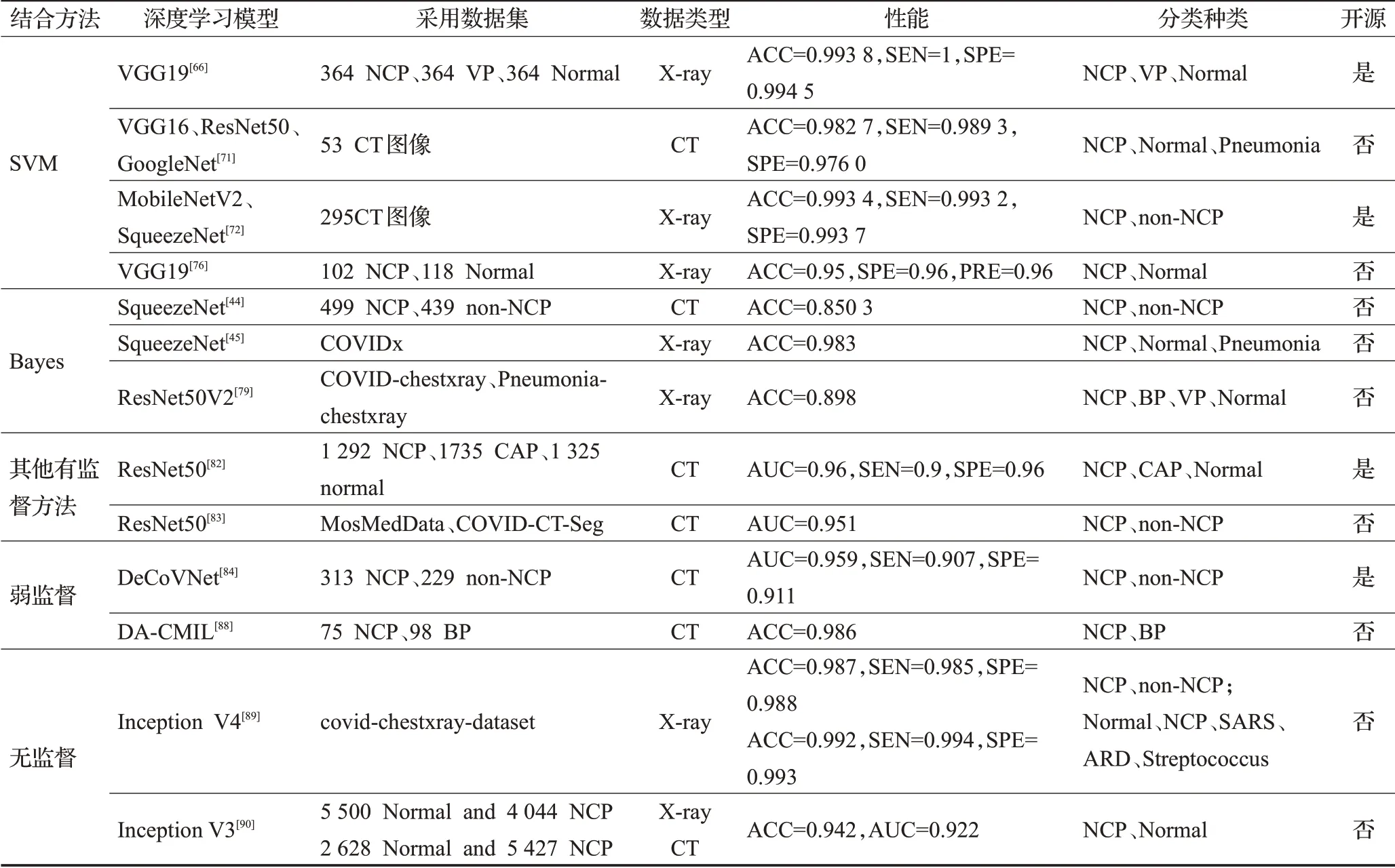
表5 深度学习与其他机器学习结合方法性能对比表Table 5 Table of performance comparison between deep learning and other machine learning methods
4 结束语
本文对COVID-19的深度学习诊断方法进行总结,通过对比可以发现:
(1)从骨干网络来说。基于COVID-19的诊断模型中,分类网络有VGG、Inception、ResNet、DenseNet、CapsNet、EfficientNet等多种,其中以ResNet应用最为广泛,部分作者在这些网络基础上添加其他辅助手段,如FPN、注意力机制、决策树等,提高模型性能。
(2)从数据集来说。大多数研究使用的COVID-19数据集的图像数量在几十到几千之间。为解决小样本问题,部分作者采用了迁移学习的方法。在公开可用的大型COVID-19数据集中以COVIDx应用最多。
(3)从模型性能来说。以EfficientNetB3[70]为骨干网络的方法在二分类和多分类上准确率达到100%,充分证明深度学习诊断方法在COVID-19诊断中的重要作用。
可以发现,随着计算机视觉的不断发展,深度学习在图分类领域不断进步,大多数基于深度学习的COVID-19诊断模型都取得了显著成果,但是其仍然存在改进空间:
(1)完善数据集。一个模型最终性能的确定离不开数据集,因此完整、清晰、精确的数据集是必不可少的。目前大部分模型在进行验证的时候所应用的数据集图像数目较少且有些数据集的图像不清晰,这很容易产生过拟合。此外,不少模型采用由不同数据集合并而成的新数据集,易导致数据重复。
(2)存在算法偏见(算法偏见是指算法在数据集构建、目标制定与特征选取、数据标注等环节中产生的信息偏差,导致算法失去公平和准确性)。部分研究采用了儿童的相关影像作为“COVID-19”非对照组,事实上相比于成人,儿童感染COVID-19的几率要小得多。因此这种设计上的偏差会让算法产生很大的偏见。
(3)模型具有不可重复性。一般来说有两种方法来验证算法的性能,即内部验证和外部验证。内部验证是指测试数据与开发数据属于相同来源;外部验证是指测试数据属于不同来源。如果该研究只是基于一家医院的数据,那么它很可能不适用于另一家医院。这些数据需要多样性,最好是国际化的,否则,当该方法被更广泛地测试时肯定是要失败的。
(4)模型轻量化[91-93]。随着卷积神经网络的不断进步,研究人员提出了很多结构更复杂、层数更深的卷积神经网络模型,但随之而来的即是效率问题,结构复杂的卷积神经网络虽然会有较好的准确率优势,但是具有效率不高、参数量大和计算量高等不可忽视的缺点,因此轻量化卷积神经网络的研究对于COVID-19模型的优化和应用推广具有深远意义。
(5)无监督学习。COVID-19的深度学习分类方法是监督式学习。但是人类大脑具有思考能力,更像是无监督式学习,人类视觉系统判断一幅图像之前并不需要被告知几千上万图像的类别。因此,使用单纯的无监督学习模型来检测COVID-19也是未来的一个发展方向。
随着COVID-19的常态化流行,肺部影像筛查的方法起着越来越重要的作用。本文从基于深度学习的COVID-19检测模型出发,首先简单地介绍了一些常用的COVID-19数据集,接着从深度学习和深度学习与其他机器学习方法结合两个方面对模型的骨干网络、数据集、性能等多个角度进行总结。随着各种技术的发展,检测模型在准确率、灵敏度、特异性等评价指标上有很大的提升,这对医学领域的诊断有着很大的帮助。但是部分模型仍然存在一些缺陷,期待未来COVID-19检测技术能够克服这些不足,更好地为医学领域做出贡献。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
福建基础教育研究(2019年6期)2019-05-28
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
初中生世界·七年级(2017年9期)2017-10-13
