
结合多分支结构和U-net的低照度图像增强
2022-06-23 06:24卫依雪周冬明王长城
计算机工程与应用 2022年12期
卫依雪,周冬明,王长城,李 淼
云南大学 信息学院,昆明 650504
随着计算机视觉领域[1-2]的发展,携带着丰富信息的高质量图像无论是在日常生活还是科学研究中都有着巨大的研究潜力。但是,由于不同的光照条件、周围的噪声等原因,图像质量高低不一,严重影响了人们判别图片中的信息,从而引起不必要的冲突和结果。尤其是在黑暗条件下,人们难以识别摄像头捕捉到的图像信息,而且智能系统很大程度上也依赖于高质量的输入图像,为了解决这个问题,本文就低照度图像问题进行了研究。
在此之前,大量的传统算法已经被提出。其中直方图均衡化算法[3-4]就可以很好地提高图像的对比度,但同时也会增加图像的噪声。还有暗通道先验算法[5]早期一般被用于图像去雾,后来有人将低照度图像的各个像素进行反转,即将低照度图像转换为带雾图像,再利用暗通道先验算法进行去雾,再反转,间接地实现了图像增强。此外,基于Retinex理论[6]的算法引入了反射分量和光照分量的概念,这些算法[7-14]在提升亮度的同时,也保留了图像细节,但遗憾的是色彩恢复得不够完善,最终导致增强后的图像不真实。随着深度学习的发展,很多研究人员开始尝试利用深度学习算法去解决图像增强问题,比较经典的是利用卷积神经网络的方法[15-17],其代替了人工设计特征提取的方法来实现图像增强。但是神经网络结构的性能非常依赖于网络的深度,而网络层数的增加会引起退化现象和梯度下降,从而导致深层网络并不能实现理想的训练效果。此外,深度卷积网络的池化层扩大了特征提取的感受野,虽然提高了网络性能,但同时也更容易造成信息细节的丢失。因此,本文引入了基于多分支结构的深度残差网络[18]和U-net[19]。多分支结构使网络更加快速有效。深度残差网络不仅能解决网络结构饱和问题,还能提高图像特征提取能力。而U-net是一种编码-解码网络,能在特征提取时逐步减小空间维度,可以更好地恢复出图像细节。
本文提出的基于多分支结构和U-net结合的低照度图像增强算法有以下三点贡献:
(1)本文提出了一种新颖的端到端的低照度图像增强网络,可以应用于多种场景,计算速度和准确率也都有所提升。此网络还结合了多分支网络和U-net进行特征提取,取得了不错的结果。
(2)本文的方法在噪声抑制、对比度增强等方面有着较好的效果,能够有效地减少噪声的影响。
(3)本文使用大量的实验来证明所提出模型的有效性,且使用了很多优秀的方法来进行对比,并且从定性和定量的角度分析对比结果,取得了满意的效果。总体来说,本文提出的方法在各方面很大程度上优于现有的算法。
1 相关工作
主要介绍与低照度图像增强相关的算法。在深度学习被广泛应用之前,一般都使用传统算法去解决低照度图像的问题,例如低通滤波器可以去噪,高通滤波器可以增加清晰度。
传统算法可以分为二大类,第一类是基于直方图均衡化的方法,这类方法理论并不复杂且易于实现。利用直方图还可以很直观地看出图像的一些统计信息,了解图像的各个部分亮度值以及是否存在曝光不足或者曝光过度的情况,再对不同灰度级进行相应扩展或缩减,从而得到清晰的图像。其中Kong等提出了动态直方图均衡化算法(DHE)[3],该算法对太亮或太暗的图像都非常有效。Ibrahim等提出了保持亮度的动态直方图均衡化算法(BPDHE)[4]。但直方图均衡化的方法只适用于对比度较低的图像中,所以此方法在某些程度上存在一定的缺陷。
第二类是基于Retinex理论[6]的方法,其原理是将图像分为照明分量和反射分量两部分,恢复出图像原本的细节信息,同时估计和增强照明图,最后融合两张图像达到增强的效果。其中,单尺度Retinex算法(SSR)[7]是将高斯函数和图像卷积近似表示反射分量。而多尺度Retinex算法(MSR)[8]是对SSR的改进,它使用了不同尺度的高斯滤波,再对滤波结果进行加权平均来近似估计照明图像。而带颜色的多尺度Retinex算法(MSRCR)[9]则是在MSR的基础上又添加了颜色恢复因子,以解决图像失真等问题,使其更接近真实场景。此外,很多结合了Retinex理论和其他理论的算法也陆续被提出,例如SRIE[10]采用了一种补偿方法,以弥补对数域梯度过度放大的暗部区域。LIME[11]是通过估计亮度分量,利用反向算法直接得到反射分量。Dong等[12]提出的方法,首先要对图像进行反演,然后再利用去雾算法进行图像增强。MF[13]提出了多曝光融合算法,找到最佳曝光率,使对比度和亮度增强得更加精确。NPE[14]利用Retinex理论和log双边转换使光照分量映射更加接近自然色。总的来说,基于Retinex理论的传统算法虽然取得了很大的进步,但是仍然存在着色彩混乱、噪声大等问题。
随着深度学习算法的日渐成熟,低级视觉任务慢慢开始融合深度学习的优点。其中,RetinexNet[15]结合了Retinex理论和深度学习,其增强后的图像质量明显提高,色彩也更加丰富,但是仍然有很大的提升空间。LLNet[16]利用深度自编码器同时进行图像对比度的增强和去噪。而将CNN与传统算法结合起来的LLCNN[17],则是利用不同的内核去过滤暗的图像,然后将多尺度特征图结合在一起生成最终的图像,因此它能比较好地保留原始图像的特征和纹理。MBLLEN[20]把不同层次的特征提取和融合应用到了低照度图像增强上,增强效果更加明显。KIND[21]在基于RetinexNet算法的分解和重建结构上进行了优化,增加了调节网络,有效地实现了连续调节光亮图的机制。ALIE[22]是对MBLLEN的改进,在增强图像亮度和对比度的同时,运用注意力机制进行了去噪,并且扩展了数据集。LIEDHN[23]提出了空间变体RNN,而且引入了对抗判别损失,对图像细节和边缘部分都进行了很好的增强。此外,基于深度学习的图像增强算法都需要成对的低光照图像数据集进行训练,但是公开且全面的低光照数据集少之又少。LSD[24]就提供了一个新的思路,其利用相机的短曝光和长曝光收集了raw格式的成对低光照图像数据集。而Jiang等提出的EnlightenGAN[25]则另辟蹊径,其利用全局-局部鉴别器和自正则注意力机制使网络架构不需要成对图像数据集的训练,更能适应真实世界的大多数情况,所能应用到的领域也更是广泛,但是GAN难训练,在训练过程中容易出现梯度消失和梯度爆炸等问题。
在现有的方法中,直方图均衡化方法虽然能够较好地提升图像的亮度和对比度,但是在细节和色彩方面的恢复并不完善;基于Retinex理论的方法由于需要将图像分解成光照分量和反射分量,因此许多网络往往被设计成非端到端,并且现有的方法对光照分量的估计并不理想。此外,基于深度学习的方法大多在细节方面恢复的不够充分,仍有比较大的提升空间。
综合考虑到现有方法的优点和缺点,本文探索出了一种基于多分支结构和U-net结合的方法,首先利用了残差网络对输入图像进行特征提取,然后利用了不同深度和结构的U-net网络对提取到的任意两个特征进行增强,最后进行融合得到最终增强后的图像。
2 主要方法
2.1 模型结构
本文提出的模型是基于多分支结构设计的算法框架,其主要是由特征提取和图像增强两部分组成,模型的输入为低光照图像,输出为同尺寸增强后的清晰图像。具体内容如图1所示。

图1 算法框架图Fig.1 Algorithm frame diagram
特征提取部分使用了3个残差元(RESBLOCK),每个残差元堆叠了两个卷积层,其中第一个卷积层的输入是原始低光照图像经过Relu函数处理之后的图像,Relu函数可以使输入的原始图像更加稀疏化,从而能够更好地挖掘不同层次的特征。每个卷积层使用的都是3×3大小的卷积核、步长为1、标准差为0.02、Relu激活函数。接着,把每个残差元提取出来的特征进行交叉合并。
图像增强部分分为了3个支路,EM1支路采用比较浅的U-net对第一个残差元和第二个残差元交叉合并得到的特征进行增强。EM2支路利用的是比EM1支路要更深1倍U-net来对第一个残差元和第三个残差元交叉合并得到的特征进行增强。EM3支路上使用的U-net网络深度虽然与EM2一样,但在结构上进行了一些改进,同样地,EM3支路对第二个残差元和第三个残差元交叉合并得到的特征进行增强,其详细说明如下。
本文所提出的图像增强网络EM1支路的U-net具体结构如图2所示,其采用卷积核尺寸为3×3和LRelu非线性激活函数的卷积层,核数分别为32、64、128、64、32。最大池化层的核尺寸为2×2,步长为2。上采样阶段经历了与下采样阶段同样数量的反卷积操作,而且通过跳跃连接将上下采样层的特征映射进行拼接,防止下采样层提取到的特征丢失,这使得U-net更加准确,得到增强后的图像具有更多的细节信息。EM2支路的具体结构如图3所示,它与EM1支路的区别在于层数,其卷积层的核数分别为32、64、128、256、512、128、64、32。EM3支路相较于EM2来说,层数未改变,但对U-net的结构进行了优化,经历两个卷积层后再进入最大池化层,同样经历两个卷积层后再进入上采样,其核数分别为32、32、64、64、128、128、64、64、32、32,其具体结构如图4所示。
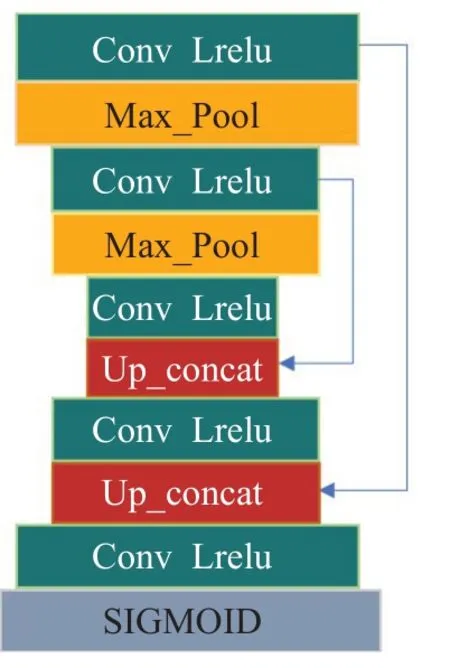
图2 EM1网络结构图Fig.2 EM1 branch network structure
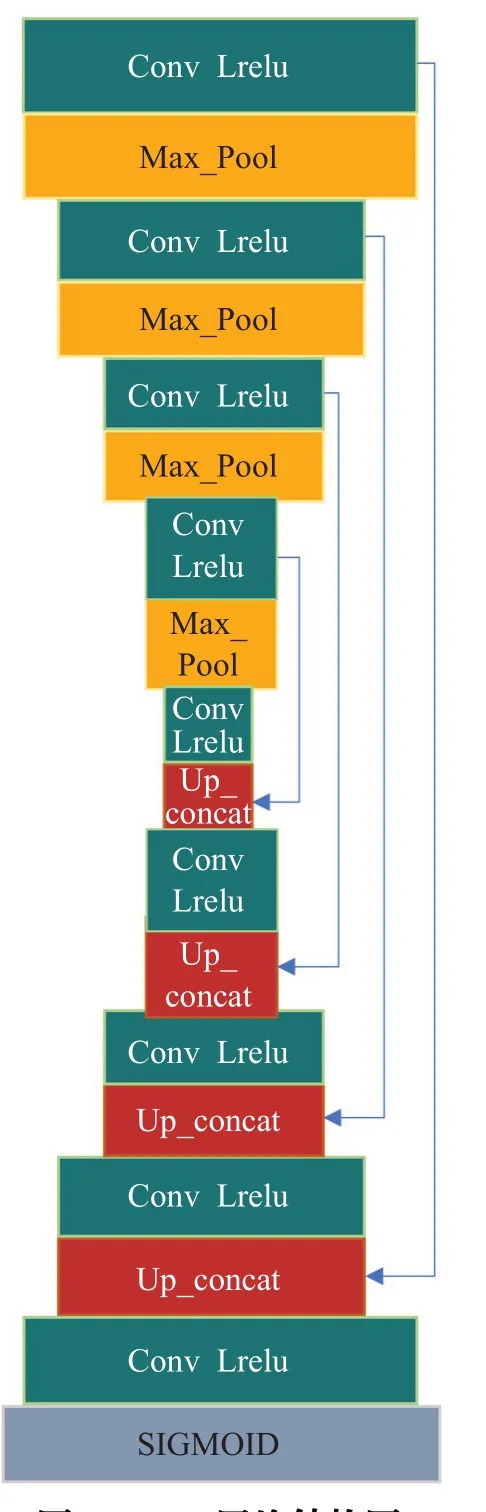
图3 EM2网络结构图Fig.3 EM2 branch network structure
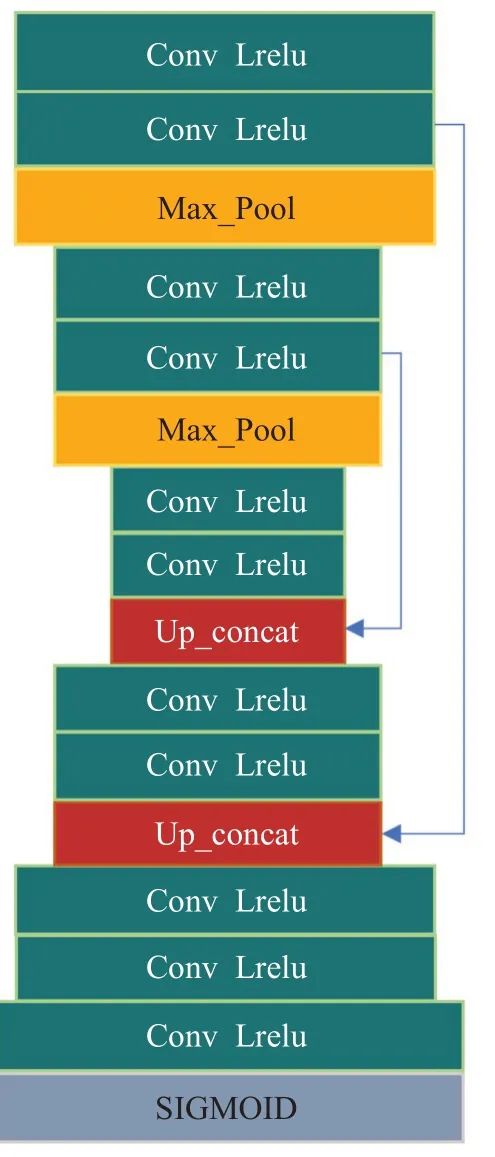
图4 EM3网络结构图Fig.4 EM3 branch network structure
2.2 损失函数
在训练神经网络的时候,想要输出图像和真实图像越来越接近,于是通过损失函数来实现这一目标。为了在定性和定量上提高图像质量,使用常用的误差度量已经不能体现图像在各个方面的优化程度。通过各方面的综合,本文最后确定使用三个损失函数,分别是,结构性相似损失(SSIM)、均方误差(MSE)和梯度损失(grad)。其计算公式如下:
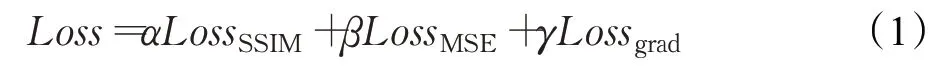
结构性相似性损失函数LossSSIM指的是整体视觉效果,用来衡量真实图像和使用本文算法增强后的图像之间的差异性,旨在改善输出图像的视觉质量。
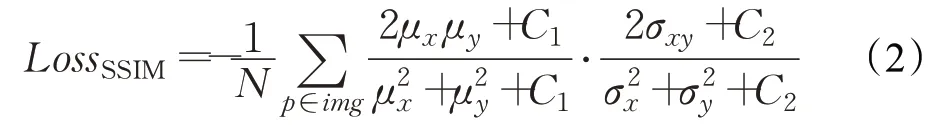
式中,μx和μy分别是x和y的平均值,σ2x和σ2y分别是x和y的方差,σxy是x和y的协方差,C1=(k1L)2和C2=(k2L)2是常数,用来保证损失函数的稳定,防止分母为0。其中k1=0.01,k2=0.03。
均方误差是目标变量和预测值的差值平方和的均值。均方误差损失函数会放大最大误差和最小误差之间的差距,而且均方误差损失函数对异常点非常敏感。
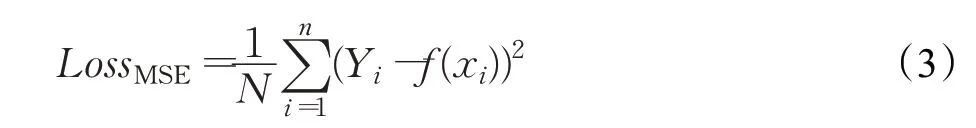
在训练网络的时候,如果只使用均方误差损失函数,很容易陷入到局部最优解中,所以,本文还引入了梯度损失。
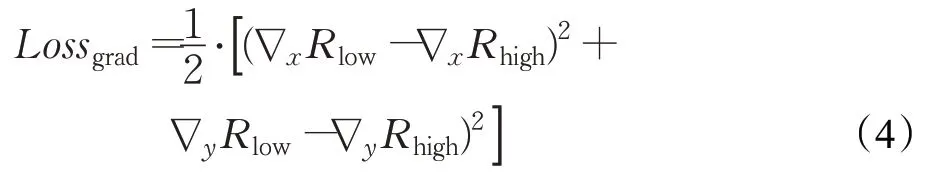
式中,∇表示的是梯度算子,其包含二维图像的两个维度方向。通过对梯度信息的优化,极大地保留了分解图的边缘信息和平滑一致性。∇x和∇y分别表示水平和垂直方向的一阶导数运算符。
3 实验评价
通过大量的实验,对本文提出的算法进行了评价和验证,并与现有的方法进行了比较。利用LOL-dataset数据集对一些比较有代表性且较新的方法进行了测试,并和本文方法进行了不同指标间的比较。最后,对本文建议的算法结构框架进行了消融实验。
3.1 实现细节和数据集
本文实验使用的是Tensorflow1.15的开源框架在Windows10,Intel i7 9700kF3.6 GHz,16 GB RAM,Nvidia 2070s GPU平台上完成的。本文设置学习率参数为1E-4的Adam优化算法对模型进行优化。损失函数的权重参数设置为:α=1,β=1,γ=1,网络训练次数为2 000次。其损失随迭代的收敛曲线如图5所示。
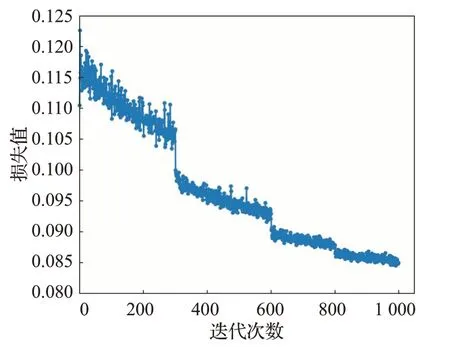
图5 训练损失曲线Fig.5 Training loss curve
由于真实的低光照图像的数据集很难成对捕捉,所以本文使用了RETINEX方法中构建的LOL-dataset和MBLLEN方法中构建的MBLLEN-dataset。LOL-dataset数据集是第一个通过改变曝光时间获取低光照-正常光图像成对数据集,该数据集包含485对低光照和正常光照训练图像,和15张低照度测试图像。MBLLEN-dataset数据集包含了16 925张训练的成对低光照-正常光图片和144张成对的测试图像,其实验结果如3.4节所示。
3.2 LOL-dataset实验结果
本文方法与经典的算法和现阶段主流的算法均做了比较,对比传统算法有MSRCR[9]、SRIE[10]、LIME[11]、DONG[12]、MF[13]、NPE[14]以及基于深度学习的RETINEX[15]、MBLLEN[20]、KIND[21]等算法,LOL-dataset测试集的实验对比结果如图6所示。
由图6可以看出,SRIE方法在亮度上就没有达到一个很好的增强效果。MF方法比SRIE要有一定的提升,但是仍然没有恢复到正常图像的亮度。DONG方法的亮度主观效果要比MF提升很多,但是在细节处理方面又有很大的欠缺。LIME方法在一定程度上解决了DONG方法的边缘细节问题,但在色彩保留方面又有所缺失。MSRCR方法增强出来的图像有点过曝,真实度也有待提高。RETINEX算法的色彩更加丰富,但是整体效果较混乱,噪音过多,主观视觉效果不理想。KIND算法部分区域增强得非常好,但是对比度过高,部分区域有伪影。NPE算法、MBLLEN算法与本文提出的算法在主观效果来看比较相似,都很大程度上改善了低照度图像,但在细节方面本文算法增强的图像更胜一筹。更详细的对比结果图如图7所示。

图6 LOL测试集实验结果对比Fig.6 Comparison of experimental results of LOL test set
在图7中,设有三组图像,前两行是“DOLL”图片,中间是“BOWLING”图像,最后两行是“POOL”图像。其中每组图像的第一张是低光照图像,第二个是真实图像,后面依次是MSRCR方法[9]、SRIE方法[10]、LIME方法[11]、DONG方法[12]、MF方法[13]、NPE方法[14]、RETINEX方法[15]、MBLLEN方法[20]、KIND方法[21]和本文所提出的方法增强后的图像。

图7 LOL测试集实验结果细节对比Fig.7 Comparison of LOL test set experimental results in details
通过比较,在“DOLL”图片中,首先储物柜中衣服颜色真实还原度和层次分明度,其次床上放的玩偶的颜色真实度和视觉感官程度,本文提出的算法相比来说都会更好一些,且墙上悬挂的牌匾的反光层次也更真实一些。在“BOWLING”图片中,首先地板上的倒影,其次暗处保龄球的摆放,本文提出的算法都更为清晰。在“POOL”图片中,首先墙上的时间表以及水中的映射,其次窗边盆栽植物的颜色恢复以及叶片轮廓的边缘结构,还有窗户外的景色,本文算法的分辨率都会更高一些,主观效果都会更好一些。
3.3 LOL-dataset性能评估
本文使用大量的数据集去测试提出的方法,除了主观视觉的效果外,还采用了几种图像质量客观性指标去评估。
首先,本文将真实图像作为参考图像,基于像素统计基础的质量评价指标有峰值信噪比(PSNR)[26]、信噪比(SNR),通过计算待测图像和真实图像对应像素点灰度值之间的差异,从而分析增强后的图像质量。PSNR值或SNR值越大,表明待测图像的失真越小,图像质量越好。基于信息论基础的质量评价指标为视觉信息保真度(VIF)[27]、信息保真度准则(IFC)[28],由于互信息被广泛用来评价图像质量,所以本文通过计算待测图像与真实图像之间的互信息来衡量图像的质量。VIF的值和IFC的值越大,表示细节信息没有丢失,保留得更好。基于结构信息基础的质量评价指标为结构相似性(SSIM)[29],它改进了PSNR的缺点,可以很好地拟合人眼视觉的系统特性。SSIM的值越大,人眼感知特性效果越好,图像质量越可靠,实现起来也比较简单。
其次,本文还选择了两个基于无监督学习无参考的图像质量评价指标,自然图像质量评价(NIQE)[30]和亮度顺序误差(LOE)[14],直接计算增强后图像的视觉质量。LOE的值或NIQE的值越小,即表示被测图像越接近真实图像。
在LOL-datasets数据集上进行了测试,表1、2、3分别为图7中三张图片的客观指标,其中黑色加粗表示最优结果。
表1是“DOLL”图像的评价指标对比,由表可以看出,本文算法增强后的DOLL图像的PSNR和SSIM指标远远大于其他算法,而SNR、NIQE、LOE的值与MBLLEN比较接近,但效果稍有提高,VIF和IFC的值各算法间相差都不太大,但本文的方法仍然是最优的。
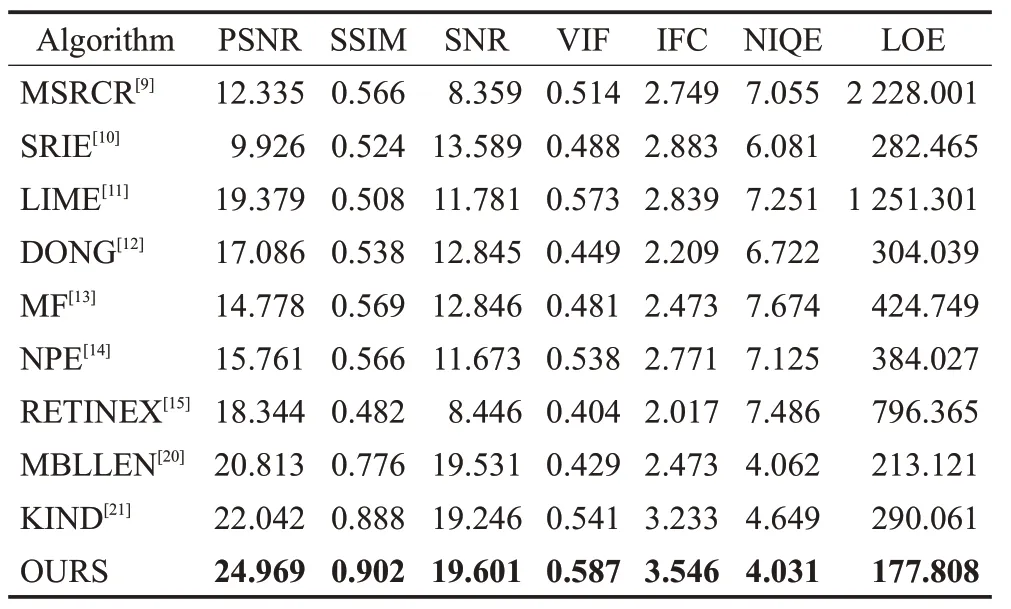
表1 DOLL图像评价指标对比Table 1 Comparison of DOLL image evaluation index
表2是“BOWLING”图像的评价指标对比,通过分析可以看出,本文增强后的“BOWLING”图像在不同的度量标准下的效果都优于其他所有的方法。而且如图7所示,主观效果也更加符合人眼感官特性,很明显可以看出本文算法增强的图像比其他几种方法更真实。
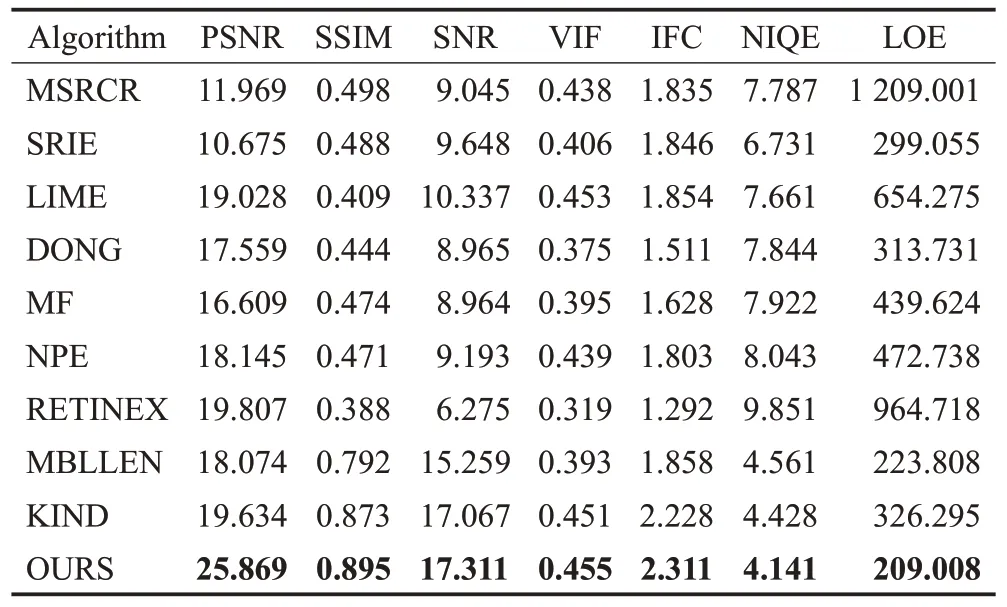
表2 BOWLING图像评价指标对比Table 2 Comparison of BOWLING image evaluation index
表3是“POOL”图像的评价指标对比,由这些表可以看出,本文的方法产生的结果在所有的情况下都是最好的,通过其他数据集的测试也证明了这一点。
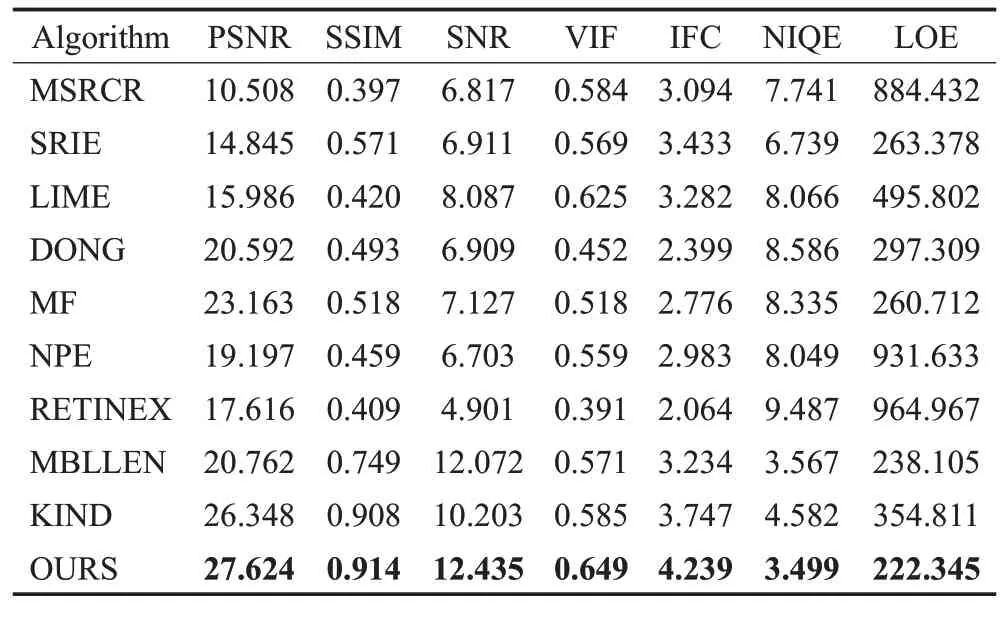
表3 POOL图像评价指标对比Table 3 Comparison of POOL image evaluation index
3.4 MBLLEN-dataset实验结果及性能评估
由于空间限制,本文只挑选了MBLLEN[20]和KIND[21]与本文算法进行对比。而且利用了PSNR和SSIM两个客观指标更加验证了本文算法的有效性,其结果如表4所示。其测试集的实验结果对比如图8所示。
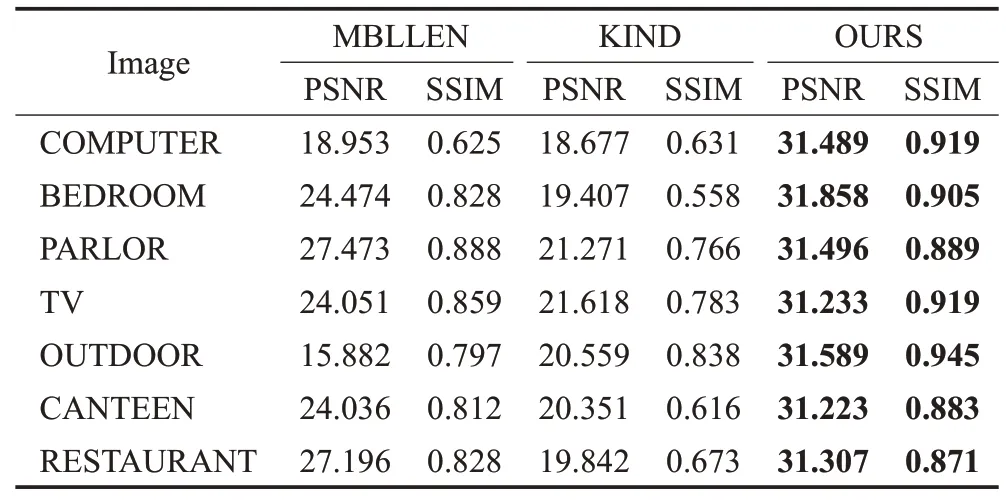
表4 MBLLEN-dataset测试图像评价指标对比Table 4 Comparison of MBLLEN-dataset test image evaluation index
由表4可知,本文算法在7张图片中的客观评价指标都是最优的,而且比MBLLEN和KIND算法增强的结果要优秀很多。
而从图8中可以看出,“COMPUTER”的低光照图像偏绿,所以由MBLLEN和KIND算法得到的清晰图像也偏绿,而本文算法增强出来的图像发白,最真实且清晰。“BEDROOM”图像各个算法增强的结果很相似,但是在白沙发扶手的细节方面,本文算法更胜一筹。“PARLOR”图像中的颜色比较丰富,由此可以对比出本文算法在颜色恢复方面比MBLLEN和KIND要好很多。在“TV”和“OUTDOOR”图像中,躺在沙发上的人和在拍照的人所穿衣服的蓝色,本文算法恢复得非常真实,效果最好。从“CANTEEN”图像中的人脸细节表明,本文算法在增强图像的整体亮度和对比度的同时,细节恢复得也特别好,而MBLLEN和KIND算法增强后的图像中人脸模糊且噪声太大。最后还选择了一张黑白图像进行测试,“RESTAURANT”图像的测试结果更加清晰地表明本文算法在细节恢复方面的优势。

图8 MBLLEN测试集实验结果对比Fig.8 Comparison of experimental results of MBLLEN test set
3.5 消融研究
在本节中,对本文提出的网络模型的各个部分进行了消融研究。
首先对特征提取部分进行了消融实验,通过图9可以看出去掉残差块之后,特征提取能力明显下降,最后增强出来的图像细节比较模糊,噪声大,部分图像中还有黑影的存在。

图9 去掉残差的消融实验对比结果Fig.9 Contrast results of ablation experiments with residual removed
由表5可以看出,本文的方法在大多数图像下的效果仍然是最好的,唯一不是最好的是SOFA图像,那是因为SOFA的真实图像偏暗,导致PSNR和SSIM的值偏小。而本文的消融实验大多排在第二,仅次于本文提出的算法,说明本文提出的框架结构还是较为完美。
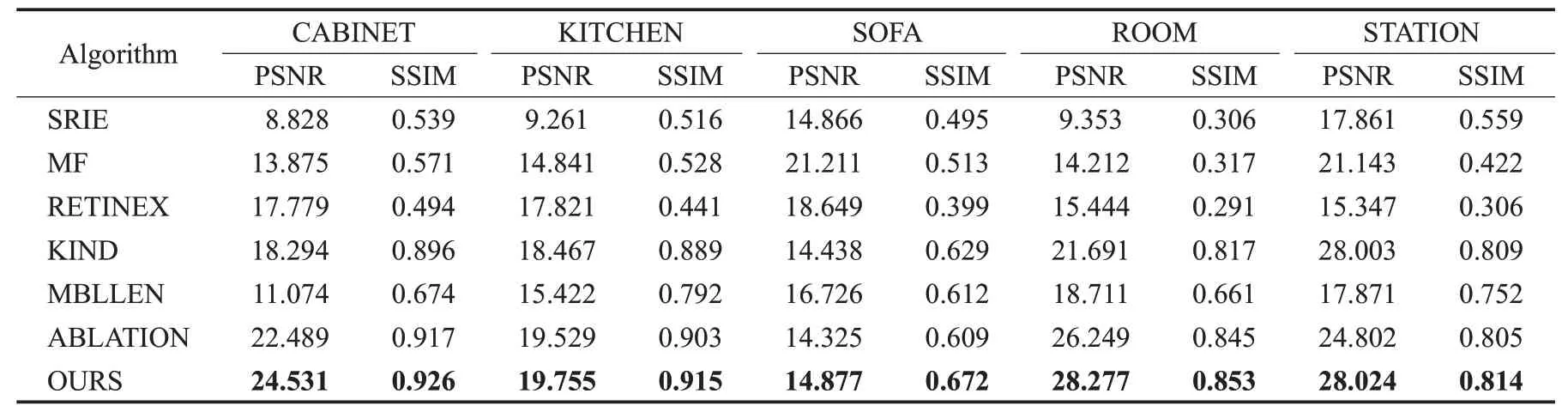
表5 去掉残差的消融实验的图像评价指标对比Table 5 Contrast of image evaluation indexes of ablation experiments with residual removed
把SOFA图像中效果较好的几个方法经过放大以对比细节如图10所示,可以发现本文算法增强后的图像中毛绒玩具的绒毛根根分明,红色毛线的轮廓也更为清晰,颜色更为鲜艳。而KIND和MBLLEN算法的毛绒玩具和红色毛线都非常模糊,细节信息缺失较多。本文的消融实验比KIND和MBLLEN的细节处理要好很多,但是在亮度和对比度上不及本文的算法。

图10 SOFA图像细节对比Fig.10 Comparison of SOFA image in details
其次去掉了梯度损失函数,结果如图11所示。如果单独研究消融出来的图像,可以发现其整体效果还是较理想的。亮度、对比度都有所提升,细节也恢复得不错,但是和真实图像差别较大。

图11 去掉grad损失函数的消融实验对比结果Fig.11 Comparison results of ablation experiments with grad loss function removed
通过表6更直观地可以看出,去掉梯度损失函数的消融实验的PSNR和SSIM虽然比大多数算法更优秀,但仍然没有本文的方法好。其中“WARDROBE”和“DESK”图像的PSNR低于MBLLEN和KIND,是因为“WARDROBE”真实图像中的衣服偏旧、颜色偏暗,而增强后的图像中的衣服颜色更加鲜艳。“DESK”真实图像中的墨水盒上的字体不清晰,右上角角落由于背光偏暗,而增强后的图像中的墨水盒上的字体非常清晰,所有角落甚至桌板亮度都明显增强。因此导致PSNR偏小,具体的细节对比如图12所示。

图12 WARDROBE和DESK图像细节对比Fig.12 Comparison of WARDROBE and DESK image in details
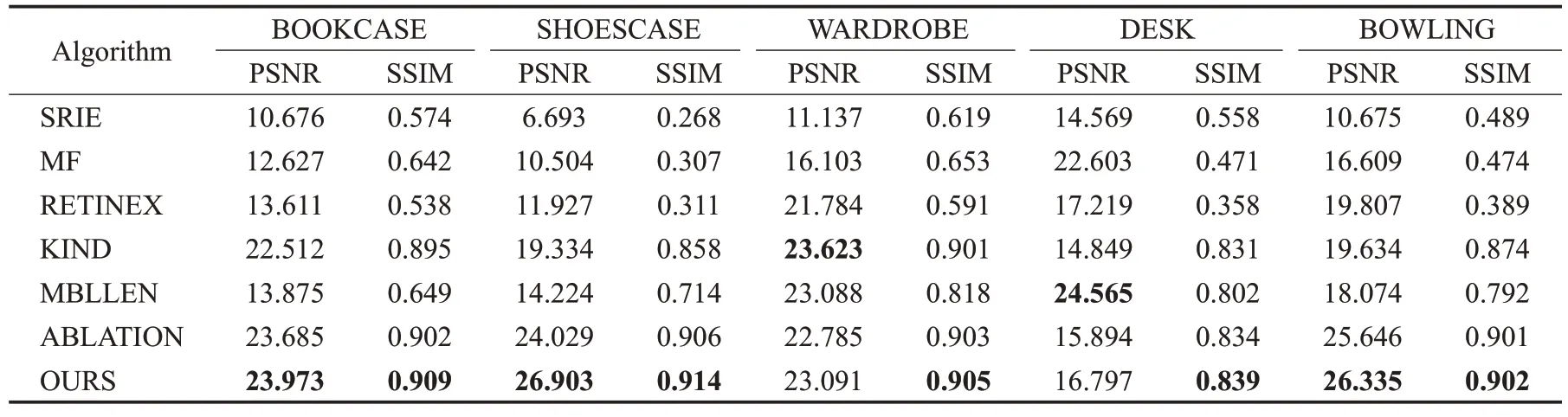
表6 去掉grad损失函数的消融实验评价指标对比Table 6 Comparison of evaluation indexes of ablation experiment of grad loss function removed
综上所述,采用本文提出的结构框架和损失函数训练的网络胜过其他网络,且具有较好的增强效果。
4 结束语
本文提出了一种新的解决低照度图像增强的方法,并且取得了较好的效果。在对现有的图像增强算法的研究中发现很多网络不仅结构复杂,而且细节恢复得还不理想。于是,为了提升整个网络的计算速率和准确性,本文引入了多分支结构。而深度残差网络和U-net可以更好地提取图像的纹理特征,恢复出边缘细节。在不同的数据集上进行了测试,大量的实验结果表明,无论是在图像的主观效果还是客观指标方面,本文的算法都优于现有的大多数图像增强算法。此外,为了使本文所提出的方法应用更加广泛,考虑到扩大数据集和优化损失函数,这将是后续工作。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
航天返回与遥感(2022年2期)2022-05-12
中国机械工程(2022年8期)2022-05-09
燃气涡轮试验与研究(2021年6期)2021-08-01
儿童时代·幸福宝宝(2021年1期)2021-03-29
海洋信息技术与应用(2020年4期)2021-01-18
北京航空航天大学学报(2020年10期)2020-11-14
小资CHIC!ELEGANCE(2019年40期)2019-12-10
北京航空航天大学学报(2019年9期)2019-10-26
