
基于多尺度感受野融合的小目标检测算法
2022-06-23 06:24李成豪肖贤鹏
计算机工程与应用 2022年12期
李成豪,张 静,2,胡 莉,肖贤鹏,张 华
1.西南科技大学 信息工程学院,四川 绵阳 621010
2.中国科学技术大学 信息科学技术学院,合肥 230026
目标检测是图像分割、图像标注和图像理解等高级计算机视觉问题的一项基本任务。与图像分类不同,基于卷积神经网络(convolutional neural network,CNN)[1-2]的目标检测算法需要用一个网络完成目标分类和目标定位两个任务。目前基于CNN的目标检测算法主要分为两类,第一类是两级(two-stage)检测算法,例如R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]等;第二类是单级(one-stage)检测算法,例如YOLO[6]、SSD[7]、RetinaNet[8]等。随着现代生活中计算机视觉系统的逐渐复杂化和智能化,如无人驾驶中对远处车辆、行人和交通标志的识别[9],医学成像中一些早期疾病的检测,自动化工业中的工件检测等,都需要考虑到目标太小、像素低,不便于提取特征的问题,因此研究小目标检测以适应这些特定场景的检测任务很有必要。
虽然目前通用的目标检测算法已经大大提高了检测精度和效率,但是因为CNN重复使用卷积层、池化层提取高级语义信息,使小目标的像素在这个过程中被过滤掉了,导致小目标的检测性能很差。为解决这个问题,SSD算法采用一种特征分级结构的思想,即在每一个尺度提取的特征图上都进行检测,相比单一尺度特征的检测算法有了很好的提升。可是由于SSD浅层特征语义信息不丰富,加之小目标对应的Anchor较少,SSD在实际应用中的小目标检测效果不理想。DSSD[10]算法针对SSD中小目标对应Anchor较少导致的训练不充分问题做出改进,改善了对小目标的检测能力。但DSSD依然没有获得足够的小目标语义信息,并且引入反卷积后,计算开销大,使得DSSD的预测速度不如SSD。文献[11]通过建立由深层特征到浅层特征的恒等映射的方式,直接利用深层特征的高级语义信息对浅层特征进行增强,改善了SSD在小目标检测上的缺陷。但是这种方法得益于SSD框架,也局限于SSD框架,对小目标检测的提升空间不大。特征金字塔网络FPN[12]是第一种通过融合不同层级特征来增强特征的方法,采用Top-Down的特征融合结构,很好地解决了浅层特征语义信息不丰富的问题。尽管FPN提高了小目标的检测精度,但FPN只对相邻特征进行了融合,忽略了顶层和底层的特征融合,同时没有很好地解决感受野与目标尺度匹配的问题,无法充分发挥出小目标的检测性能。
针对FPN的两个问题,以RetinaNet作为基础框架,提出一种基于多尺度感受野融合的小目标检测算法S-RetinaNet,采用具有反馈结构的递归特征金字塔网络RFPN[13]对特征进行充分融合,并增加三个多尺度感受野融合模块MRFF分别处理RFPN的不同大小输出,使感受野与目标尺度相匹配。通过在PASCAL VOC和MS COCO数据集上的对比实验和消融实验表明,相比RetinaNet,S-RetinaNet对小目标检测有较大改善。
1 小目标检测算法S-RetinaNet
1.1 递归特征金字塔网络RFPN
人类通过视觉识别目标时会通过把高级语义信息回传到反馈连接中,来选择性地增强和抑制神经的输出。递归特征金字塔网络RFPN引入这个思想,在普通特征金字塔的基础上增加了一个反馈结构,通过这种反馈连接能够直接获取来自分类和回归预测的梯度信号,使得目标检测的错误回传信息能够更直接地调整主干网络参数,从而加快训练速度并提高检测性能。另外RFPN的特征融合操作采用两阶段结构,能够避免单阶段融合造成的特征融合不充分的问题。如图1所示,第一阶段的融合同FPN,设bi(i=3、4、5)为主干网络的第i级操作,Bi为自下而上的主干网络的第i级输出。fi为自上而下的特征金字塔的第i级操作,Fi为特征金字塔的第i级输数。输入和输出的关系可以表示为:
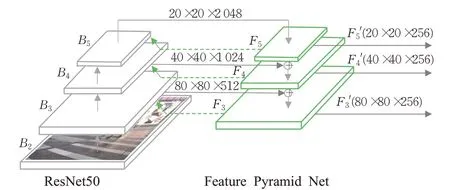
图1 RFPN结构图Fig.1 RFPN structure
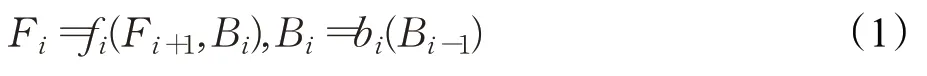
第二阶段的融合通过反馈连接将第一阶段的输出Fi与第二阶段的输入Bi(Bi')联系起来。设Ri为将Fi和Bi(Bi')结合的操作,因此输入和输出的关系可以表示为:
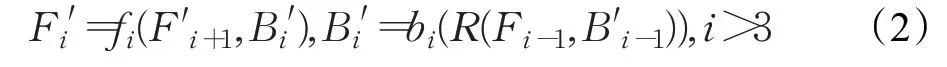
其中当i=3时,此时Bi=B3为bi(R(F3,B3))。
1.2 多尺度感受野融合模块MRFF
尽管较小的感受野有利于检测小目标,但是相对于目标尺度而言的,小于或接近小目标尺度的感受野不能发挥出对小目标检测的最佳效果[14]。需要适当增大感受野,借助被检测目标周围的有效上下文信息,以提升对小目标的检测效果。
多尺度感受野融合模块MRFF通过多个共享卷积进行不同尺度的感受野扩大,并进行融合,其设计思路来源于Inception module[15],Inception module将1×1、3×3、5×5卷积和3×3 pooling堆叠在一起,一方面增加了网络的宽度,另一方面增加了网络对多尺度的适应性。相比Inception module,MRFF不同之处在于使用了3×3、5×5、7×7、9×9卷积进行堆叠,其中5×5、7×7、9×9卷积分别使用两个3×3、三个3×3和四个3×3卷积等效,并且多个等效3×3卷积可作为共享卷积,这样在引入上下文信息的同时,不但减轻了因为多次卷积导致目标分辨率下降的问题,而且大大简化了网络结构,使MRFF易嵌入到RetinaNet网络框架中。
MRFF的结构如图2所示。首先通过1×1卷积调整通道数为原来的1/4,并对输入的特征分别进行3×3、5×5、7×7、9×9卷积操作,卷积过程中通过控制stride、padding和卷积核数量的变化保持输出特征图大小和通道数不变。然后对获得的不同尺度感受野的特征进行融合输出,融合操作采用concatenate,即将四次卷积后的输出进行堆叠,使其和调整前的通道数256保持一致。最后通过输出的特征进行目标分类和边框回归。为减少网络的参数量,提高训练和检测效率,MRFF使用两个3×3卷积代替一个5×5卷积,三个3×3卷积代替一个7×7卷积,以及四个3×3卷积代替9×9卷积,其中第二、三、四个3×3卷积为共享卷积。相比二阶段目标检测算法Faster R-CNN基于区域提议扩大感受野的方法,MRFF使用的参数更少。针对单独使用3×3、5×5、7×7或9×9卷积增大感受野,造成感受野与目标尺度不匹配的问题,MRFF模块对感受野进行四种不同尺度的扩大,并进行融合,能够有效地解决这个问题,提升小目标的检测精度。
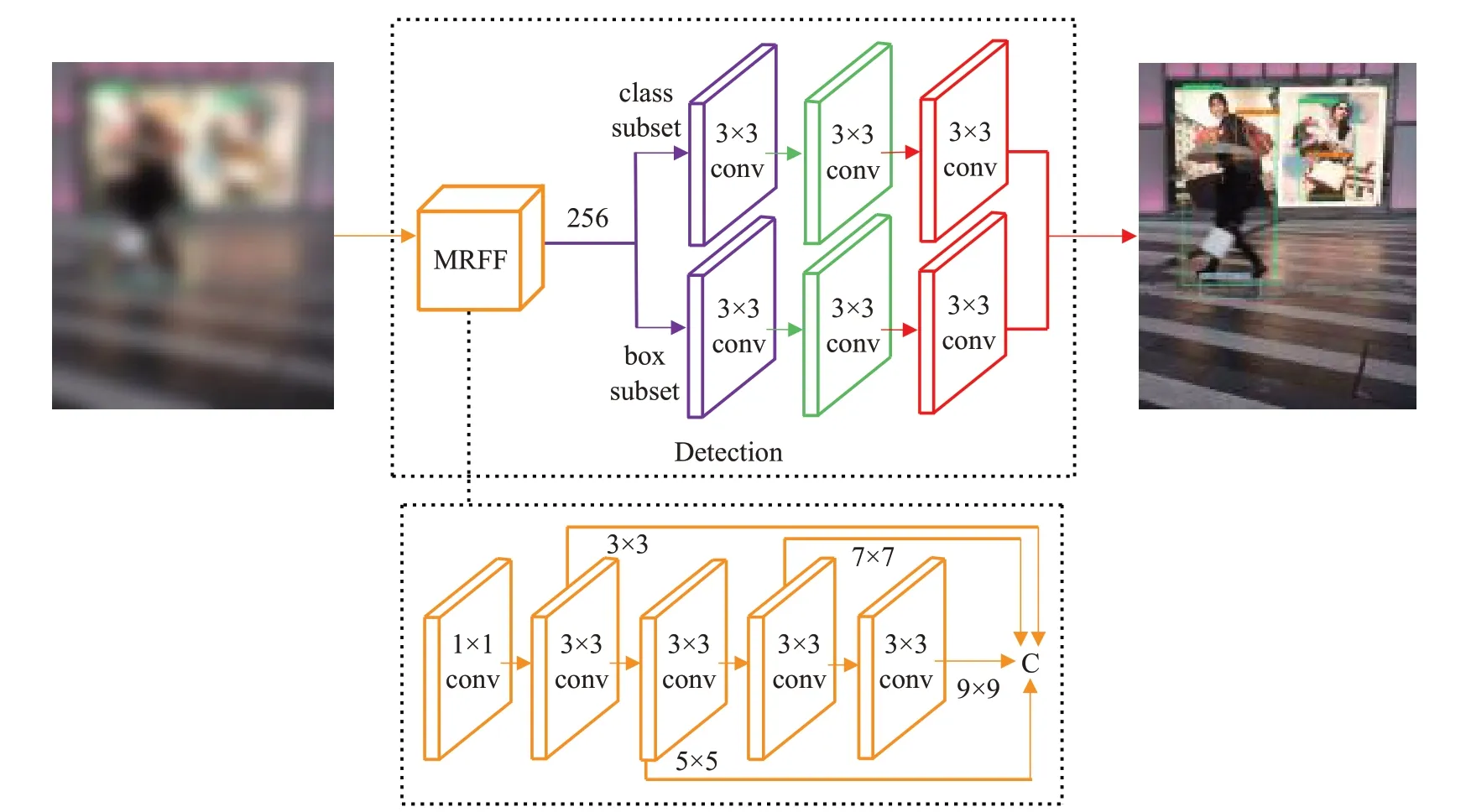
图2 MRFF结构图Fig.2 MRFF structure
1.3 网络结构
S-RetinaNet目标检测算法以RetinaNet框架为基础,网络结构如图3所示,包括四个部分。第一部分是主干网络,采用ResNet50,输出为B5、B4、B3三个有效特征层。第二部分是递归特征金字塔网络RFPN,对B5、B4、B3三个特征层进行特征融合。针对第一阶段融合,首先分别通过1×1,步长为1的卷积调整B5、B4、B3的通道数为256,然后对B5进行第一层金字塔操作得到F5,并对F5上采样产生与B4相同大小的特征图,最后与B4相加,并通过金字塔第二层操作得到F4,同样的以F4为基准与B3进行特征融合可以得到F3。针对第二阶段融合,首先通过输出的Fi(i=3、4、5)调整通道数为Bi大小,并与Bi相加得到Bi'(当i>3时,Bi'为Fi+B'i-1),然后继续第一次融合的操作,最后可以得到RFPN的最终输出F5'、F4'、F3'。第三部分是MRFF,分别处理RFPN的三个输出,对不同尺度的特征层进行四种不同尺度感受野的扩大,并进行融合。最后一部分是目标分类和框的回归,输入为经过三个MRFF处理的结果,输出是目标的位置和类别。
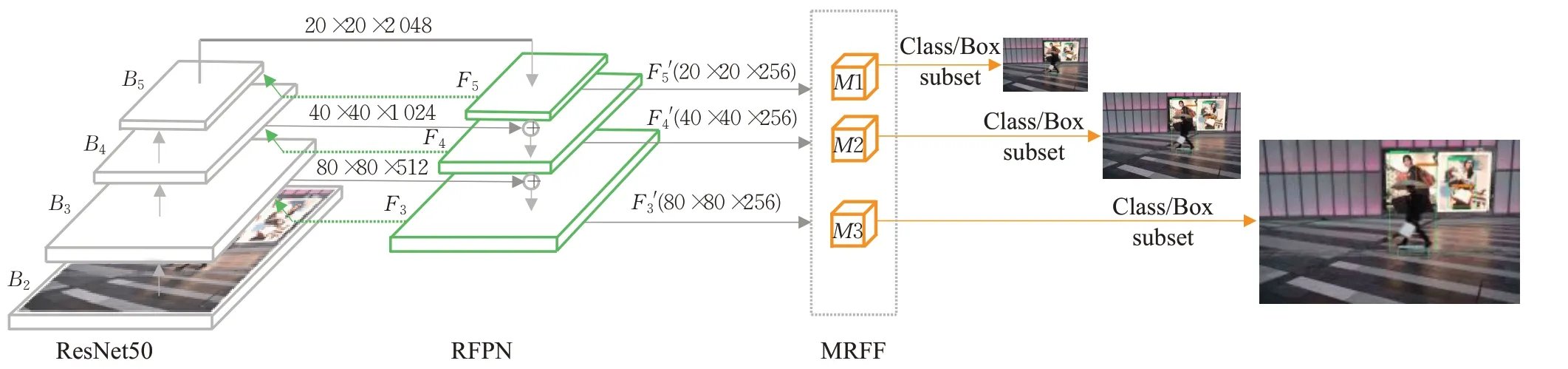
图3 网络结构图Fig.3 Net structure
网络的改进主要有三点:一是引入了RFPN,通过在FPN中增加反馈连接,弥补FPN特征融合不充分的问题;二是在递归特征金字塔的多尺度输出后加入MRFF模块增大感受野,使感受野与目标尺度相匹配,以获取更多有效上下文信息;三是增加MobileNetV1[16]主干网络,构建了轻量化版的S-RetinaNet目标检测算法,使得S-RetinaNet能够更好地部署在硬件资源有限的平台上。
2 实验结果及分析
2.1 实验准备
2.1.1 数据集
本实验在PASCAL VOC和MS COCO数据集上进行网络训练和测试。针对VOC数据集,训练集采用VOC2007(train+val)+VOC2012(train+val),测试集采用VOC2007 test;针对COCO数据集,训练集采用COCO2017 train,测试集为COCO2017 val。
2.1.2 评估标准
S-RetinaNet算法采用mAP(mean average precision)来评估检测性能,其公式如下:
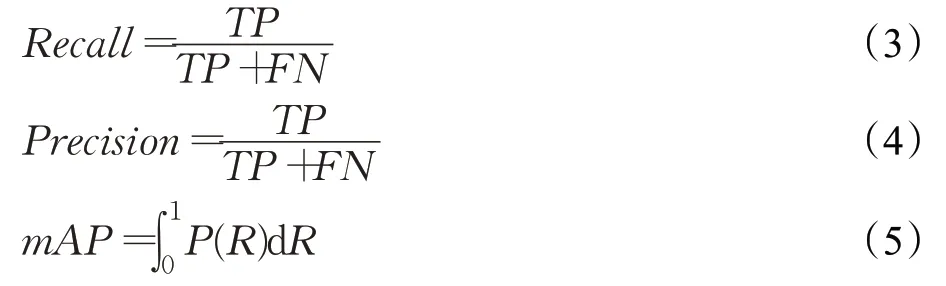
这里Recall(R)是召回率,Precision(P)是精确度,TP为正样本被分为正样本的数量,FN为正样本被错误的分为负样本的数量,FP为负样本被错误的分为正样本的数量,TP+FN为全部正样本数量,TP+FP为全部被分为正样本的数量。
TP和FP根据IOU(intersection over union)阈值来判断,IOU计算公式如下:

其中,A表示真实框(Ground Truth Box),B表示基于Anchor并通过检测模型预测出来的框。
2.1.3 训练细节
训练过程中为加快收敛速度,backbone采用ImageNet分类任务的预训练权重;另外在前半段epoch冻结backbone训练,后半段epoch解冻backbone进行训练,提高资源利用率,并进一步加快收敛速度。
2.2 在PASCAL VOC上的对比实验
实验采用SGD作为优化器,其中momentum为0.9,weight decay为5E-4。在一块NVIDIA Titan Xp GPU上进行训练,训练的batch size设为8,迭代次数设置为100个epoch,初始学习率为0.01,在70和90个epoch后分别降低10%,每张图像的尺寸被调整到500×500,并利用图像旋转、颜色变化、平移等方法进行数据增强。
表1显示,在不同主干网络下,增加MRFF和RFPN后的S-RetinaNet均比改进前RetinaNet的mAP高,其中MobileNetV1提高了2.1个百分点,ResNet-50提高了2.3个百分点。同时相比Fast R-CNN、Faster R-CNN、SSD、YOLO、DSSD五种目标检测算法的mAP,基于ResNet-50的S-RetinaNet算法分别高出11.5、8.3、5.3、16.1、4.9个百分点。另外基于MobileNetV1的轻量化S-RetinaNet算法,精度接近Faster R-CNN,检测速度比Faster R-CNN快了10倍。
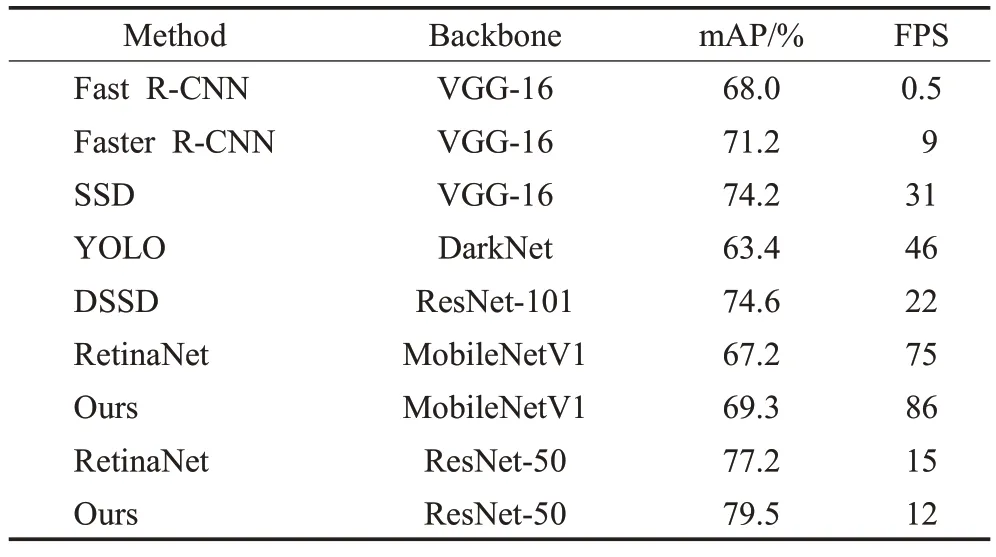
表1 VOC2007 test对比Table 1 VOC2007 test comparision
图4是S-RetinaNet算法与其他算法的可视化对比,直观地反映出了各个算法的检测精度和速度。
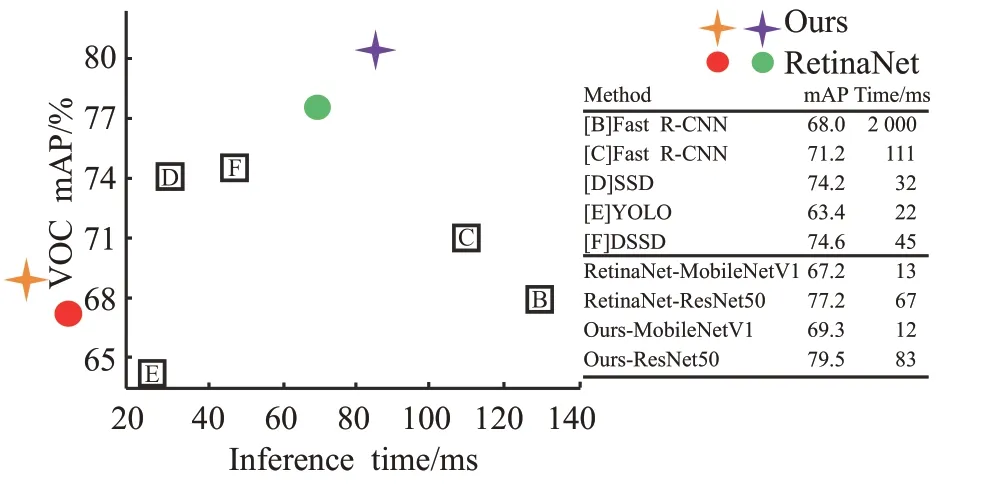
图4 VOC2007 test对比可视化Fig.4 VOC2007 test comparision contrast visualization
表2列出了RetinaNet和S-RetinaNet在不同Backbone下每一类的AP值的对比结果。从表中可以看出,通过对RetinaNet增加MRFF模块和RFPN,Bird、Bottle、Plant等小目标的AP值提升明显,如选择ResNet-50作为主干网络,分别提高了4.8、4.6、2.1个百分点。
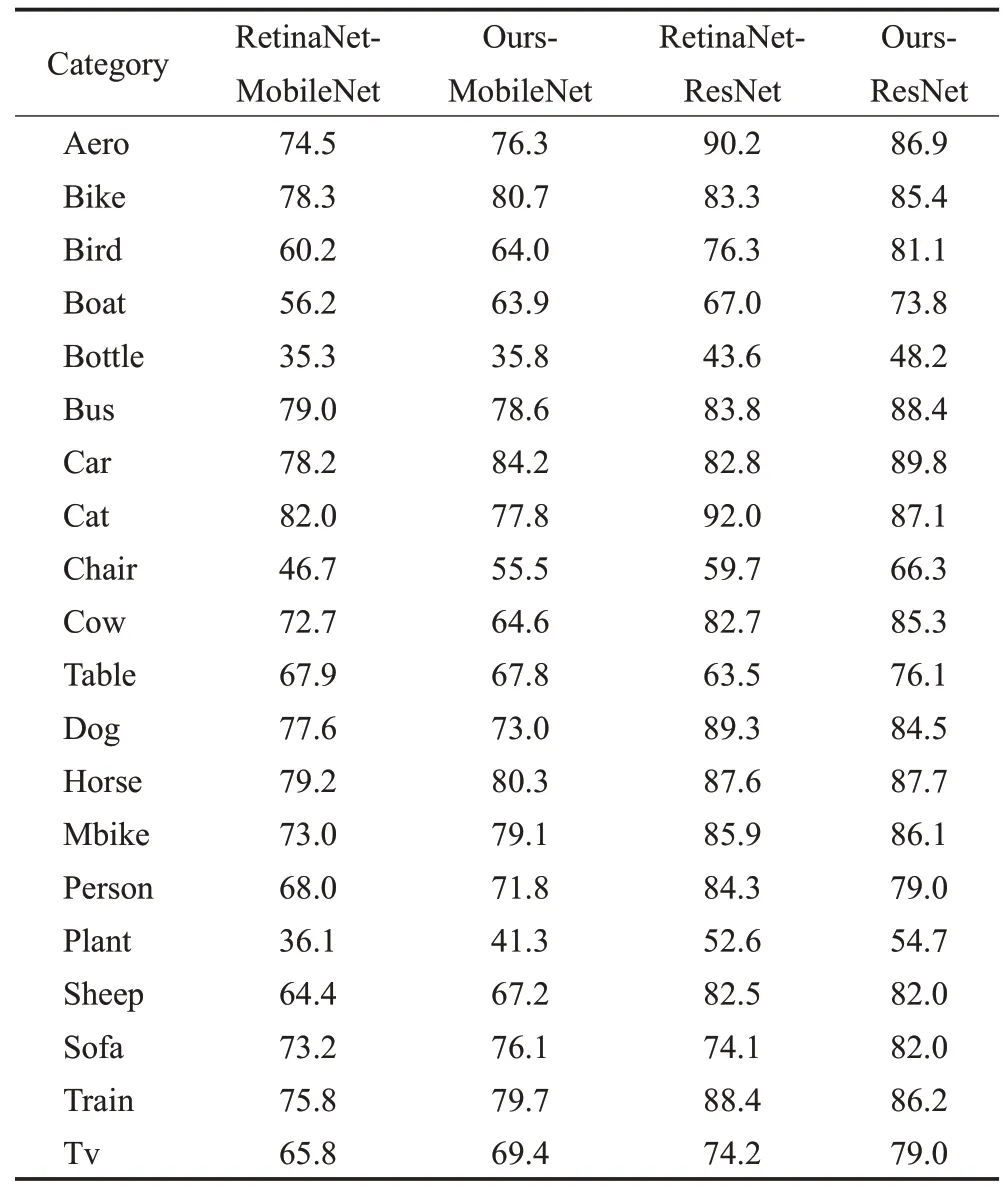
表2 每个类别的mAP对比Table 2 mAP for each category %
2.3 在PASCAL VOC上的消融实验
本实验采用与2.2节相同的设置进行,其中主干网络采用ResNet50。从表3可以看出,通过单独加入MRFF模块和RFPN,mAP分别达到了78.7%、78.4%,相比未加入之前,分别提高了1.5、1.2个百分点。证明了MRFF模块和RFPN都对提升检测精度带来了帮助。在同时加入MRFF模块和RFPN后,mAP达到了最高79.5%,进一步证明了MRFF模块和RFPN对提升RetinaNet检测精度的有效性。
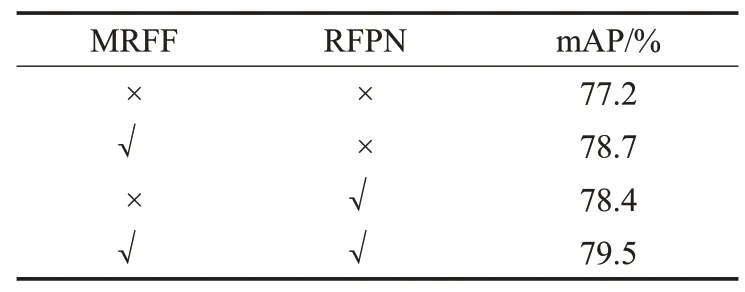
表3 VOC2007 test对比Table 3 VOC2007 test comparision
2.4 在MS COCO上的对比实验
不同于PASCAL VOC数据集上的优化器选择,在MS COCO数据集上的实验采用Adam作为优化器。在一块NVIDIA Titan Xp GPU上进行训练,训练的batch size设为8,迭代次数设置为50个epoch,初始学习率为0.01,在30和40个epoch后分别降低10%,每张图像的尺寸被调整到500×500,并利用图像旋转、颜色变化、平移等方法进行数据增强。
表4显示在主干网络MobileNetV1下的S-RetinaNet比RetinaNet的AP值高出1.2个百分点,在主干网络ResNet-50下高出1.6个百分点,其中针对小目标精度APs的提升更为显著,分别提高了2.1、2.7个百分点。
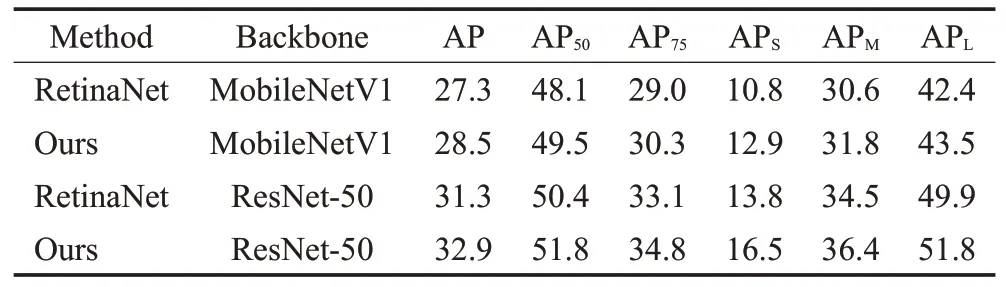
表4 COCO2017 val对比Table 4 COCO2017 val comparision %
图5是RetinaNet和S-RetinaNet的可视化检测结果对比。共五组,其中上面是RetinaNet的检测结果,下面是S-RetinaNet的检测结果。通过对比可以发现,S-RetinaNet能够检测出更多的小目标,如(1)组中的broccoli,(2)组中的toothbrush、cellphone。同时针对已经检测出的小目标,检测精度也得到了提高,如(3)组中主角后方的person、chair,(4)组中较小的dog,(5)中较小的sheep。

图5 两种算法的可视化对比Fig.5 Visual comparison of two algorithm
3 结束语
为提高RetinaNet算法的小目标检测性能,提出一种小目标检测算法S-RetinaNet,引入多尺度感受野融合模块MRFF和递归特征金塔网络RFPN,使用MRFF分别处理RFPN的三个输出,对不同尺度的特征层分别进行四种尺度的感受野扩大,并进行多尺度感受野融合,有效解决了感受野与目标尺度不匹配的问题,为小目标提供了更多的上下文信息。实验表明,S-RetinaNet在PASCAL VOC和MS COCO数据集上的平均精度较RetinaNet分别提高了2.3和1.6个百分点,其中小目标检测精度APS提升更为显著,验证了MRFF模块和RFPN的有效性。由于在现有公共数据集中的图片所含小目标太少,使得网络对小目标的训练不充分,因此后续将建立小目标数据集并开展相关研究工作。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
