
基于混合多模态深度学习框架的交通量预测
2022-06-21 11:27:44吴文平高铭悦
北部湾大学学报 2022年2期
吴文平,高铭悦
(宿州学院 信息工程学院,安徽 宿州 234000)
0 引言
随着城市化的推进和机动车数量的快速增长,城市和景区每年的拥堵情况逐年严重,造成时间和燃料的浪费,也带来了环境污染和一系列的安全问题,同时致使交通网络效率低下,如表1所示[1]。因此,城市和景区交通流的预测研究有着重要的意义。
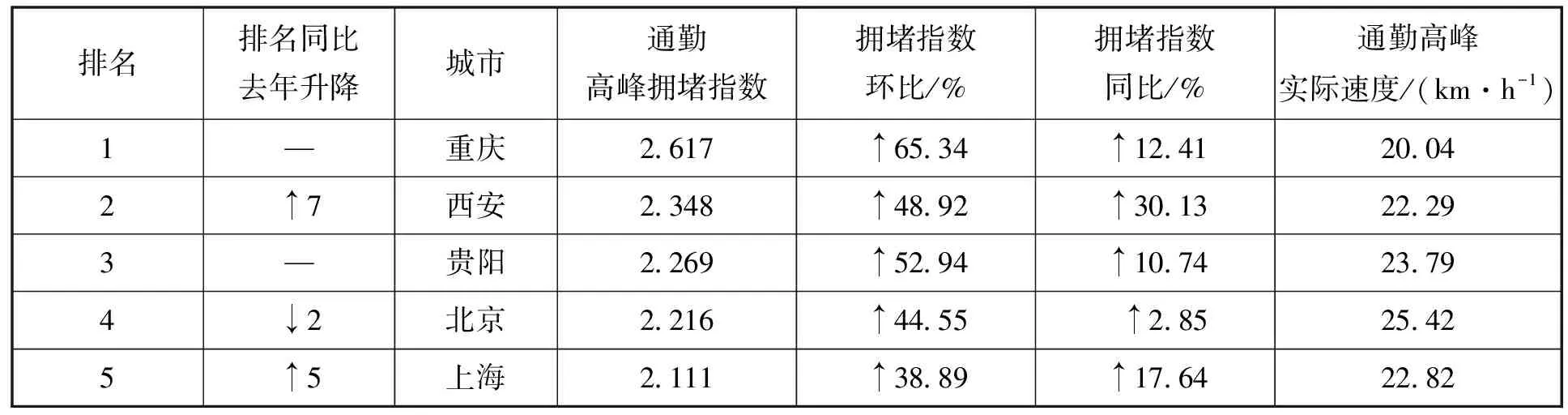
表1 2020年第二季度全国百城交通拥堵排名TOP10的城市
对交通拥堵的早期研判和对交通流的预测是指导交通管理科学决策的重要依据,是实现智能交通的关键,是智能交通的重要辅助手段[2]。在过去的几十年中,学者们尝试用数学方程和模拟技术来预测交通流,但是由于交通流的预测受天气、节假日和时空关联性等外界因素的影响,传统的数学模型和浅层学习算法很难准确地描述交通网络,所以交通流的预测存在很大的不确定性。随着物联网的发展和交通数据采集技术的广泛应用,交通流预测已经进入大数据时代。
交通流的预测越来越依赖各类传感器及其采集的相关多模态数据,如交通量、速度、行程时间、密度、天气和事故等。但传统模型不能很好地预测交通量,因此交通量预测模型需要数据驱动[3]。近些年深度学习在图像处理和自然语言处理等方面都取得了极大的进展,交通量的预测需要综合时间、空间和天气等多个模态数据进行分析,本文在多模态深度学习框架的基础上,从多个层次自动提取相关数据,利用深层特征深度学习中的卷积神经网络(convolution neural networks,CNN)—门控循环单元(gated recurret unit,GRU)模型[4]来提高交通量预测的准确度,为实现智能交通奠定基础。
1 混合多模态深度学习框架(HMDLF)

1.1 单模态数据的时空特征处理
交通量不仅与时间有关,还与地理位置有关,以2019年“十一”期间全国高速的交通量[6]为例(见图1),高速去程拥堵发生在9月30日晚上11点左右,返程拥堵出现在10月5日16点左右,说明交通量数据与历史局部特征的数据密切相关[7]。交通量时间序列的上下文信息相互关联,这些数据点的行为存在类似性。换言之,交通流的邻近数据点和周期性间隔数据之间通常有很强的相关性,交通流时间序列数据的局部邻域特征与长相关特征之间存在相关性。

图1 2019年“十一”期间全国高速交通量
1.2 多模态数据的相互依赖性
交通量数据的预测与多种因素密切相关。交通量数据的非线性特征是由自由流、故障流和拥堵流综合决定的。由于行驶环境是快速变化的,在故障流和拥堵流的情况下,多种模态数据(交通速度、交通行程时间、交通事故、节假日和天气情况等)都会对交通量的预测产生影响,而这些多模态数据的变化又是高度复杂非线性的,而且存在着相互依赖性,这对交通量的预测是一个不小的挑战。
为了解决上述两个关键问题,笔者采用CNN和GRU相结合的多模态深度学习框架来对交通量进行预测,模型框架如图2所示[8]。

图2 混合多模态深度学习框架
一般说来,由于不同模态数据的统计特性不同(每种模态具有不同的表示形式和结构),很难使用浅层模型进行融合建模。多模态深度特征学习是指在多特征层次融合的基础上,如多模态交通数据的特征串联或局部趋势特征与长相关特征的线性组合,将CNN和GRU神经网络相结合,把注意力机制作为一个CNN-GRU注意力模块,考虑单模态交通数据的时空依赖性。然后基于多个CNN-GRU注意力模块,融合不同形态交通数据的共享表示特征。
1.3 CNN空间局部特征学习
CNN是一个前馈神经网络,它的人工神经元可以对覆盖区域的一部分做出反应。CNN具有良好的图像处理性能,一些研究者也将其用于时间序列分析。CNN有三个级联层(convolutional layer、activation layer和pooling layer)。由于交通流数据的时移性和周期性,笔者使用一维CNN进行序列局部趋势学习,通过CNN的卷积运算提取局部趋势特征,这些特征可以作为本文提出的多模式深度学习框架中更深层次的表现。CNN的三层模型[9]可描述为:
Clj=∑ixl-1iWlij+blj,
(1)
xlj=(clj),
(2)
xl+1j=pool(xlj)。
(3)
其中,式(1)表示卷积运算,式(2)表示激活函数,常用的有Tanh函数和ReLU函数,这里采用的是ReLU函数,式(3)表示池化函数,常用的池化函数有最大池化tf.nn.max_pool和平均池化tf.nn.avg_pool,这里采用的是平均池化tf.nn.avg_pool。xl-1i和Clj分别表示convolutinal layer的输入和输出。
1.4 CNN-GRU时空相互依赖性特征学习
GRU是循环神经网络的一种,是处理时间序列预测的一种常用动态系统,图3是一个典型的GRU框图[10]。GRU有一个重置门和一个更新门,它能够学习捕捉不同时间尺度上的依赖关系,如果重置门被激活,那么它倾向于学习短期依赖关系,否则,它倾向于捕捉长期依赖关系。

图3 经典GRU框图
经典的GRU系统在学习过程中存在一个问题:由于时空依赖,上下文(观察片段)对时间序列的深层表示没有同等的贡献。增加的注意力层会在HMDLF模型应该参与的每个模态数据的共享表示中选择时空上下文,并促进对下一个时间序列值的精确预测,其工作原理如图4所示。它根据GRU层输出的不同时空步预测的隐状态计算出相应的注意力权值,利用softmax函数对输入时间序列上的注意力向量et进行归一化处理[式(4)~(6)],得到隐状态的加权和。

图4 基于注意机制的GRU框图
et=tanh(whht+bh),
(4)
(5)
(6)
式中,ht为GRU层的输出隐藏状态;ch为模型中随机数;e′t为下一个注意力向量;γ为每个输入序列数据的最终共享表示。
2 预测结果对比分析
采用的数据集是洛杉矶高速路数据集“metr-la.h5”对主流的几种模型进行对比分析,80%用于训练,20%用于验证。
定量分析结果见表2。其中给出了SVR(不同核)、ARIMA、LR、DTR、RIDGE、RNN、LSTM、GRU、CNN、CNN-GRU和笔者提出的HMDLF框架[11](三个不同模块:CNN-LSTM、CNN-GRU和带有注意力机制的CNN-GRU)的模型误差比较分析。发现HMDLF在预测精度方面优于其他方法。与基线模型相比,笔者的HDMLF模型(带有注意力机制的CNN-GRU模块)可以将RMSE值降低到4.35,显著提高了精度。基线深度学习模型的RMSE值近似,特别是CNN、CNN-LSTM和CNN-GRU,这意味着训练单模态数据并不能明显提高性能。

表2 HMDLF模型的RMSE值及其与其他基线模型的比较
HMDLF模型(特别是带有注意力机制的CNN-GRU模块)和基线深度学习方法的预测性能优于SVR、ARIMA等经典的浅层机器学习方法。单时态数据的时变性和长时程相关性是充分利用时变特性的原因。此外,HMDLF模型(带有注意力机制的CNN-GRU模块)还充分利用了多模态交通流相关序列数据之间的相互依赖性。实验结果表明,笔者提出的混合多模态深度学习框架可以通过融合这些深层特征信息来提高学习效率。
通过对实验数据的比较分析,可以发现,在笔者提出的混合模型中,使用GRU比使用LSTM能获得更好的预测性能。这是因为GRU比LSTM更简单,超参数更少,但仍然具有与LSTM相同的性能,因此更容易修改。在某些情况下GRU需要更少的训练时间,效率更高,并且在笔者提出的混合模型中使用CNN-GRU basic模块显示了最佳的重铸性能,这在GRU的实验中得到了验证。在某些情况下优于LSTM,如图5所示。

图5 各种模型预测结果比较
通过对以上数据的对比分析可知,笔者提出的HMDLF模型对长交通量数据(包括工作日和节假日,正常情况或异常情况)的高峰或低谷点预测是有效的,如图5所示。交通量预测能够很好地与实际情况相匹配,这意味着笔者提出的混合多模态深度学习预测框架能够有效地学习多模态输入交通数据的趋势性、相互依赖性和时空相关性,有助于智能交通系统的发展。
3 结论和展望
本文提出的混合多模态深度学习模型(HMDLF)适用于非自由流的交通量预测。首先,模型整合了一维CNN和GRU作为一个基本模块,来捕捉单模态交通数据局部趋势和长相关性之间的相关特征。其次,CNN-GRU辅助注意力机制基于联合自适应的多模态表示和融合学习框架,能够更有效地挖掘和学习多模态输入交通数据的深层非线性相关特征,如交通速度、流量、通过时间和天气状况等。
该方法在交通流预测方面的主要改进来自特征融合的多模态学习,它考虑了不同交通量数据之间的相关性,因为交通状况与流量、速度、事件性质等有关。该方法的主要特点包括时间序列的局部趋势和长依赖性学习,峰值和波谷点具有容错性的鲁棒匹配,有效地利用多模式交通数据的时空相关性,通过对实际交通数据集的多角度实验,验证了模型在各种情况下的有效性。作为研究方向,笔者认为相邻交通网络节点之间的交通流状况是相互依存的。如何分析和利用这种相互依赖关系,对提高交通流预测模型的性能具有重要意义,但短时间内有效的数据采集是一大障碍,交通事故或极端天气情况下的数据采集更加困难。混合多模态深度学习框架还需要使用更多的交通数据集进一步研究和完善。
猜你喜欢
中国交通信息化(2022年4期)2022-06-17 01:05:00
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国交通信息化(2018年6期)2018-08-29 01:19:34
传媒评论(2017年3期)2017-06-13 09:18:10
中国交通信息化(2017年5期)2017-06-06 07:20:05
北方交通(2016年12期)2017-01-15 13:52:51
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
西南交通大学学报(2016年3期)2016-06-15 20:29:35
中国工程咨询(2016年1期)2016-02-14 06:47:44
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:12
