
采用编码输入的生成对抗网络故障检测方法及应用
2022-06-19 03:23吴晓东熊伟丽
智能系统学报 2022年3期
吴晓东,熊伟丽
(江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡 214122)
迅速准确地检出故障工况并进行故障隔离对现代工业生产过程的安全性及产品质量具有重要意义[1]。随着生产工艺复杂程度及自动化水平的提升,在故障检测中建立过程机理模型变得更加困难且不易求取,基于简化后模型的检测效果也并不理想。近年来,基于数据驱动的故障检测方法得到了广泛关注和应用[2],其中常用的有主元分析法(principal component analysis,PCA)[3]、偏最小二乘回归(partial least squares,PLS)[4]、基于k 近邻算法的故障检测(fault detection using k-nearest neighborhood,FD-KNN)[5]等。
基于数据的故障检测方法中,建模数据对于故障检测的效果起着决定性作用。传统机器学习方法中的浅层模型往往无法满足过程大数据的解析需求,因此学者们提出了不同的深层模型以解决实际复杂问题[6-9]。其中,生成对抗网络[10](generative adversarial network,GAN)由于其特殊的训练思想及生成能力受到了研究人员的广泛关注,已被应用于图像、视频、文本处理等领域。文献[11]提出一种新的对抗训练方法并证明了其在指定数据集上的准确性,提升了卷积语义分割网络的训练效果。文献[12]提出一种感知生成对抗网络,减少了小对象与大对象之间的表示差异,从而有效改善了低分辨率与高噪声带来的小对象检测困难问题。通过训练深度卷积生成对抗网络,文献[13]有效地提取出文本信息特征从而生成逼真的图像。利用一种基于多尺度密集注意力的生成对抗网络框架,文献[14]解决了现有方法无法处理复杂运动及远距离依赖的问题。近几年GAN研究和应用的不断扩展,逐渐应用到了复杂工业过程监控领域。
文献[15]利用GAN 生成虚假故障样本,实现训练集中正常与异常样本的平衡,再由深度神经网络进行分类从而实现故障检测。文献[16]采用深层卷积GAN 生成旋转轴承的二维图像信息以提升训练集样本平衡性,采用卷积神经网络区分样本类别。上述方法可以看作GAN 在工业过程中的一种运用,但其实际是通过有监督分类算法实现样本的分类,对于故障类型多且未知的过程如TE 过程,效果并不理想,本文后续所提故障检测训练集均仅包含正常工况样本。
经典的故障检测方法,比如PCA 通过选取方差贡献率大的主元检测故障,易忽略方差贡献率小的变量[17]。基于KNN 的故障检测方法假设异常样本较正常工况样本在变量上会存在较大偏差,计算样本的KNN 距离作为统计量进行故障检测。上述两种传统算法在故障检测前都存在着先验假设,对故障检测的效果具有一定影响。对此,Wang 等[18]提出了基于生成对抗网络的异常检测方法,并在手写数据集(national institute of standards and technology,NIST)及田纳西伊斯曼(Tennessee Eastman,TE)过程仿真中验证了方法的有效性。基于GAN 的故障检测方法采用正常工况数据训练生成对抗网络,根据网络中的生成器及判别器构建统计量进行故障检测,因此不存在对故障产生的先验假设,而是通过判别器从真实样本及虚假样本中提取出的潜隐特征并计算概率判断故障是否发生,更贴合检测过程中故障类型及发生原因未知的背景。文献[19]利用风电机组数据训练GAN,通过判别器输出概率判断机组运行状态是否健康。但基于GAN 的故障检测方法采用经典的生成对抗网络模型,不可避免地存在着训练困难及模式崩溃的问题。为此许多学者从生成对抗网络结构及寻找最佳GAN 模型的角度进行了改进。文献[20]引入BiGAN 模型,在保证检测精度的同时大大减少了程序耗时。文献[21]构建了一个基于自编码器的性能指标来衡量生成模型的生成能力,选取最优的生成模型作为最终的分类器。但上述方法中生成器均采用随机噪声作为输入,生成器得到的有效信息少,生成样本不逼真,以致判别器性能在对抗过程中提升有限,故障检出率不高。
综上所述,为进一步提升基于GAN 的故障检测的性能与效果,结合自编码器提出一种基于改进GAN 的故障检测方法(fault detection using GAN with encoded input,EIGAN)。首先,在训练数据集上通过最小化重构误差,得到自编码器模型,并将训练集经自编码器降维后的隐变量作为生成器输入,进行生成对抗网络的训练;然后,分别根据判别器及自编码器提取出的隐变量空间对正常工况样本计算统计量,并得出控制限;最后,计算待测样本的统计量,结合控制图进行故障检测。将本文所提方法用于TE 过程及火力发电厂磨煤机的故障检测,获得了较好的检测结果,从而验证了方法的有效性。
1 基于生成模型的故障检测原理
1.1 生成对抗网络
生成对抗网络是一种基于对抗思想进行训练的网络结构,通过寻找零和博弈中的纳什平衡确定模型中的参数[22],其结构如图1 所示。生成对抗网络包含1 个生成器和1 个判别器,两者均为深层神经网络。生成器的目标是生成与真实样本近似的以致判别器区分不出的“虚假样本”;相反,判别器的目标则是区分真实样本和虚假样本,将这2 种样本实现正确的分类。

图1 生成对抗网络的结构Fig.1 Architecture of GAN
生成对抗网络的训练过程为:样本数为b、特征数为n的小批量真实样本Xb×n与生成器生成的虚假样本Gb×n一并送给判别器;判别器通过计算样本x的得分D(x)判别真伪,在每一次的训练中,通过梯度下降方法对生成器和判别器的模型参数进行更新,以最小化两者各自的代价函数LD和LG,其计算过程分别如式(1)和(2)所示:

式中:E 表示求期望;x~Pdata表示样本x服从真实样本的数据分布;z~Platent表示变量z服从隐变量空间的数据分布;G(z)表示将隐变量z映射到与真实样本维度一致的生成样本空间;D(·)表示判别器输出,其值位于0~1;假设样本u为某一未知样本,D(u)越趋向于1,则判别器认为样本u为真实样本的概率越大,反之,为虚假样本的概率越大;表示输入为真实数据时,判别器输出概率的熵。
1.2 故障检测原理
Wang 等[18]首先提出了基于GAN 的异常点检测,将训练数据集进行最值归一化后进行网络训练,得到模型后,按照式(3)、(4)分别计算出统计量和控制限(本文采用核密度估计方法计算控制限,置信度取95%);最后如式(5)所示,通过比较待测样本x′的统计量与控制限大小,判断待测样本是否为故障样本。

式中:x为 待计算统计量的待测样本;表示待测样本x到其在生成样本集中最近邻样本的平方欧氏距离;D(x)表示输入为x时判别器的输出;fKDE({Gscore|x∈Xtrain},0.95)表示对训练集统计量利用核密度估计(kernel density estimation,KDE)函数计算控制限,置信度选取0.95;lG(x′)表示利用Gscore统计量对样本x′的故障检测函数;sgn()为符号函数;sgn(fG(x′)−TG)对样本x′的Gscore统计量与Gscore控制限的差求取符号函数,若为1 则表示样本故障,否则样本正常;Dscore控制限及其故障检测函数同Gscore类似,故不做赘述。
2 基于改进GAN 的故障检测策略
2.1 改进生成器输入
生成器的本质为多层感知机,由于网络结构及每一层中神经元的作用,可以提取出有利于提升拟合精度的潜隐特征。与此同时,每一层网络中适当的激活函数也使得模型可以更好地拟合出训练集数据分布中的非线性和多模态特征。如图2 所示的生成器生成样本:图(a)、(b)、(c)分别表示某非线性真实样本数据分布情况及不同训练次数后生成器生成样本的分布情况;图(d)、(e)、(f)分别表示某多模态真实样本数据分布情况及不同训练次数后生成器生成样本的分布情况。其中绿色点表示真实样本数据分布,红色点表示生成样本数据分布,横轴、纵轴表示生成样本的两个维度。从图2 中可以看出,经过一定次数的训练后,生成器可以生成与真实样本数据分布近似的样本。但传统生成对抗网络中生成器采用均值为0 标准差为1 的正态分布作为输入,生成器要从这样一个隐变量空间映射到与真实样本相似的空间分布,需要较长的时间成本;同时生成样本与真实样本的相似性也较差,对于最终的判别器效果具有一定影响。


图2 生成器生成样本Fig.2 Generated sample from generator
如何给生成器一个包含训练数据集更多信息的低维特征是本文改进GAN 用于故障检测的一个动机,PCA 作为一种降维方法,虽然能保证提取出的主成分含有较多的信息,但受制于变量服从线性相关及高斯分布的假设,具有一定的局限性。本文采用自编码器[23]提取低维特征,其网络结构如图3 所示。不同于PCA 方法:1)自编码器特殊的网络结构及引入的激活函数使得自编码器可以同时获取原始信息中线性与非线性特征;2)由于自编码器解码后的重构输出要与输入尽可能地接近,这也保证了编码器提取出的特征能够包含更多输入数据的信息。

图3 自编码器结构Fig.3 Architecture of autoencoder
最小化式(6)所示的代价函数得到自编码器网络参数,从而提取出训练集中较大程度表示原有数据信息的隐变量,将这组隐变量作为生成器的输入,生成样本过程如图4 所示,其中绿色样本点表示真实数据分布,红色样本点表示生成器生成虚假数据分布。对比图4(a)、(c)、(b)和(d)可以看出,改进生成器输入后,有效提升了生成器的生成能力,在相同迭代次数下,改进后的生成器生成的样本分布更接近真实数据分布,从而有效地避免了以随机正态分布作为生成器输入的不足。
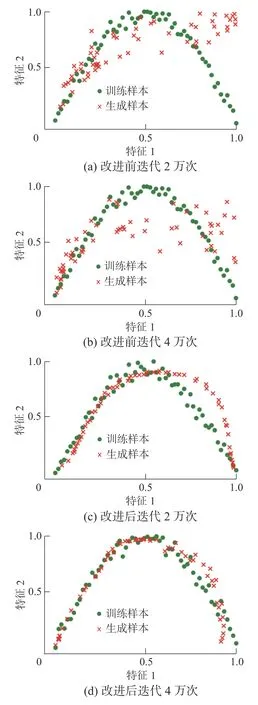
图4 改进前后生成样本分布对比Fig.4 Comparison of generated sample distribution before and after improvement

式中:θ表示自编码器网络参数;X表示自编码器输入;X′表示自编码器对输入X的重构输出;表示自编码器与其重构输出的平方欧氏距离。
2.2 基于自编码器的统计量改进
GAN 故障检测中将待测样本与其在生成器生成数据分布中最近邻样本间的欧氏距离作为统计量,这种统计量计算方法只寻找待测样本与生成数据中的最近邻样本,生成数据中的离群点对于检测结果具有很大的干扰;此外由于涉及欧氏距离的计算,无论是求统计量过程中计算生成数据间两两样本的距离,还是待测样本到生成数据的欧氏距离,都存在着样本数量多,数据维度高导致计算量大的问题。针对上述问题,本文提出一种新的统计量如式(7)所示:

式中:E(x)表示待测样本经自编码器编码后的降维输出;表示训练集经自编码器编码后降维输出的均值;为二者的曼哈顿距离。
通过比较待测样本映射到隐变量空间中的向量与训练集对应隐变量分布间的距离,即曼哈顿距离。在减少计算量的同时也降低了离群点对统计量的影响。针对新统计量的控制限计算如式(8)所示,本文采用核密度估计方法确定控制限,置信度选0.95。

由于编码器输出小于1,故式(8)中采用曼哈顿街区距离避免误差被缩小;fKDE({Escore|x∈Xtrain},0.95)表示对训练集Escore统计量以0.95 作为置信度采用KDE 计算控制限。
综上所述,本文提出的基于编码器输入的改进GAN 故障检测方法,检测流程如图5 所示,算法分为离线建模和在线检测两部分。其中,离线建模部分对正常工况下的训练数据集进行相关计算,得到训练集各样本的统计量,再根据置信度及核密度估计方法确定控制限;在线检测部分对未知的待测样本计算其统计量并与控制限比较,判断是否发生故障。
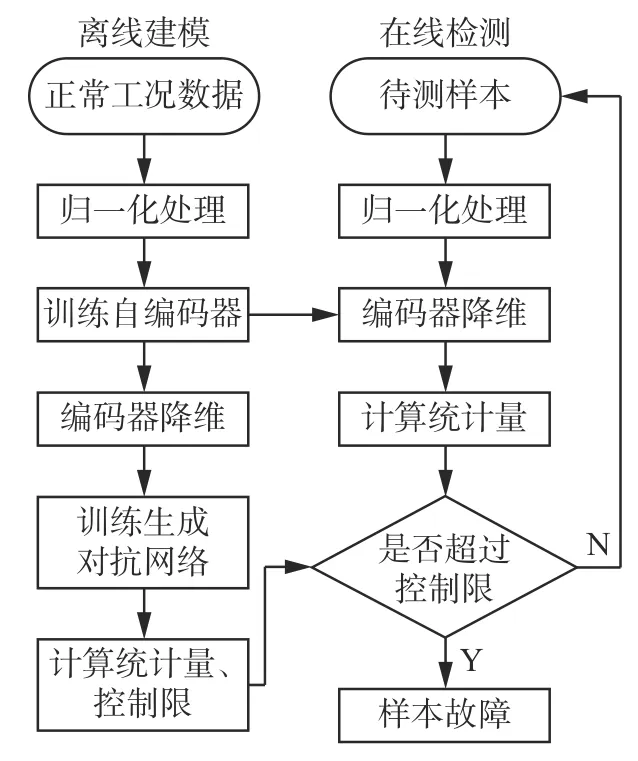
图5 改进GAN 故障检测流程Fig.5 Fault detection process using improved GAN
3 算法的应用仿真
3.1 TE 过程
美国Eastman 化学公司依据实际化工反应过程开发了TE 仿真平台,其产生的过程数据作为基准数据被广泛应用于不同故障检测方法中[24]。TE 工艺过程如图6 所示,共包含5 个操作单元和8个组成部分,含22 个过程测量变量、19 个成分测量变量及12 个操纵变量,本文选取22 个过程变量及除搅拌速度外的11 个操作变量用于建模与检测,详细的变量描述可参见文献[25]。数据分为训练集和测试集两部分,除正常工况数据外,还包含21 种异常工况。训练集对应正常工况下采集到的数据,测试集则为21 种异常工况下的数据,同时测试集中故障均在第161 个样本处被引入。

图6 TE 工艺过程示意图Fig.6 TE process diagram
首先将训练数据集通过自编码器得到维度为4 的隐变量作为生成器输入;然后对生成对抗网络进行训练,网络中生成器及判别器均采用多层感知机,生成器各层神经元个数分别为4、15、30、60、33,判别器各层神经元个数分别为33、60、30、10、1;除判别器及生成器的输出层采用sigmoid 激活函数外,其余层均采用lekay-relu 激活函数;进一步再计算出统计量及控制限。对测试集计算统计量,结合控制限绘制控制图如图7所示。可以看出,本文所提算法可以很好地通过统计量将正常工况样本与异常工况的样本区分开来,从而验证了其作为故障检测算法的有效性。

图7 TE 过程制图Fig.7 Control plot of TE process
同时将本文所提算法与传统的故障检测算法进行对比,结果如表1 所示。对比GAN 故障检测[18]结果可以看出,本文方法通过改进生成器输入,有效地改善了生成对抗网络的训练效果,提升了判别器区分真假样本的能力,从而提高了异常样本的故障检出率。与此同时,对比2 种传统的故障检测方法(PCA[3]及FD-KNN[5]),本文所提算法具有更高的报警率。
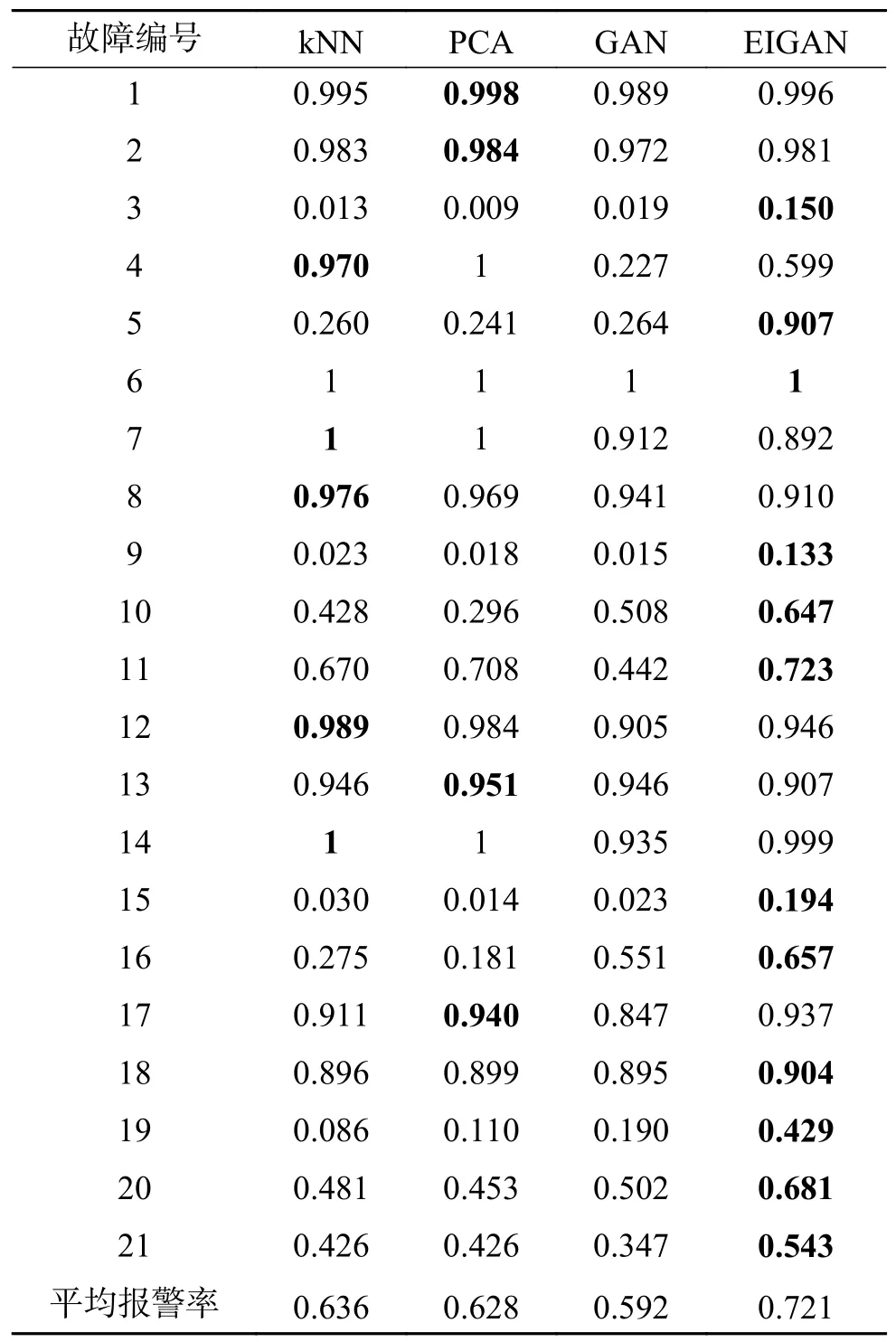
表1 TE 过程报警率对比Table 1 TE process alarm rate comparison
为进一步对结果进行分析,对TE 过程训练集及故障2、6、14 对应的测试集通过自编码器提取隐变量并绘制箱线图,如图8 所示,将图(a)分别与图(b)、(c)、(d)对比可以发现:使用自编码器提取TE 过程特征信息在还原原始数据集信息的同时,编码器提取出的故障样本的隐变量与正常样本隐变量具有明显的差异性,这也很好地解释了图7(c)、(d)中Escore统计量能很好地检出故障2、6、14 的原因。


图8 TE 过程正常工况与部分故障的隐变量箱线图对比Fig.8 Comparison of hidden variable box plots between normal operating conditions and partial failures of TE process
3.2 磨煤机数据仿真
磨煤机作为火力发电厂中的核心设施,准确快速地检出故障对安全高效地发电具有重要意义。用于对比仿真的磨煤机数据被划分为训练集和测试集两部分,训练集包含3 500 个正常工况数据,测试集包括1 000 个数据,其中前500 个是正常工况下记录得到的,后500 个为异常工况(输出煤粉温度降低)下记录的数据。训练集和测试集中过程变量个数均为46,关于磨煤机过程变量的详细描述见表2。

表2 磨煤机过程变量描述Table 2 Variable description of coal pulverizer process
对传统GAN、采用PCA 降维数据作为生成器输入的GAN(principal component based GAN,PCGAN)及本文所提的改进GAN 三者进行相同的参数初始化及网络结构设置,即生成器与判别器层数、每一层神经元个数、每一层激活函数、梯度更新规则、学习率设置(采用指数衰减法,基学习率为0.01,衰减系数为0.95,衰减速率为2000次迭代)均相同,训练相同次数后,采用Dscore、Gscore、Escore和Tscore统计量对磨煤机数据进行故障检测,其中Tscore为类比Escore统计量对采用主成分输入的GAN 故障检测方法计算得到的统计量,如式(9)所示:

式中:X∈Rm×n,x∈R1×n分别为训练集和待测样本;P∈Rn×k,分别为为主元载荷矩阵和残差载荷矩阵;xP、XP分别为待测样本得分向量和训练集得分向量均值;Tscore为统计量仿照本文所提Escore统计量。计算了xP、XP间的曼哈顿街区距离,从而衡量以PCA 提取信息作为GAN 输入时故障检测效果的好坏。
磨煤机过程检测结果对比图如图9、10 所示,检测效果见表3。可以看出采用包含信息量更多的编码器输出作为生成器输入,在帮助生成器生成更接近真实数据分布的虚假样本的同时也提升了判别器的效果,从而使得基于判别器的Dscore统计量能更好地检出故障。通过表3 及对比图10(a)、(b),可以发现相较于PCA 得到的主成分,采用自编码器降维后隐变量作为生成器输入,使得生成对抗网络在低误报的同时具有更高的报警率,从而体现出自编码器降维后得到的数据较PCA 降维后的数据包含更多原始数据中的信息,对生成对抗网络具有更好的训练效果。另外,本文所提统计量对比传统GAN 故障检测算法中的两种统计量对于磨煤机数据进行故障检测用时如表4 所示。结合表3、表4 可以看出本文基于自编码器隐变量空间提出的统计量较传统GAN故障检测中的Gscore统计量,计算速度得到了很大提升。而检测用时与GAN 故障检测中Dscore及PCGAN 故障检测中Tscore统计量为同一数量级的同时,检测效果均优于二者。

表3 磨煤机过程检测结果对比Table 3 Comparison of detection results of coal pulverizer process
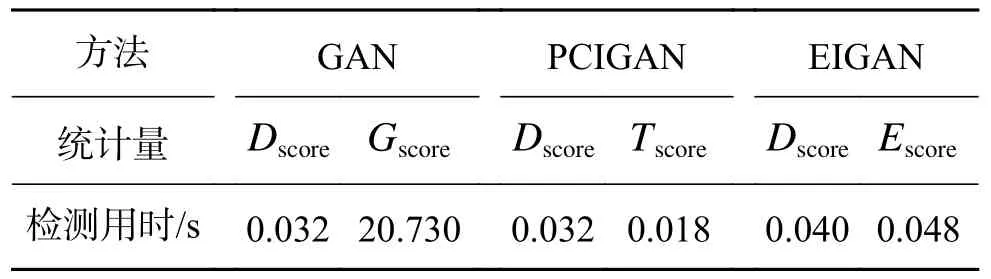
表4 磨煤机过程检测时间对比Table 4 Comparison of detection time of coal pulverizer process
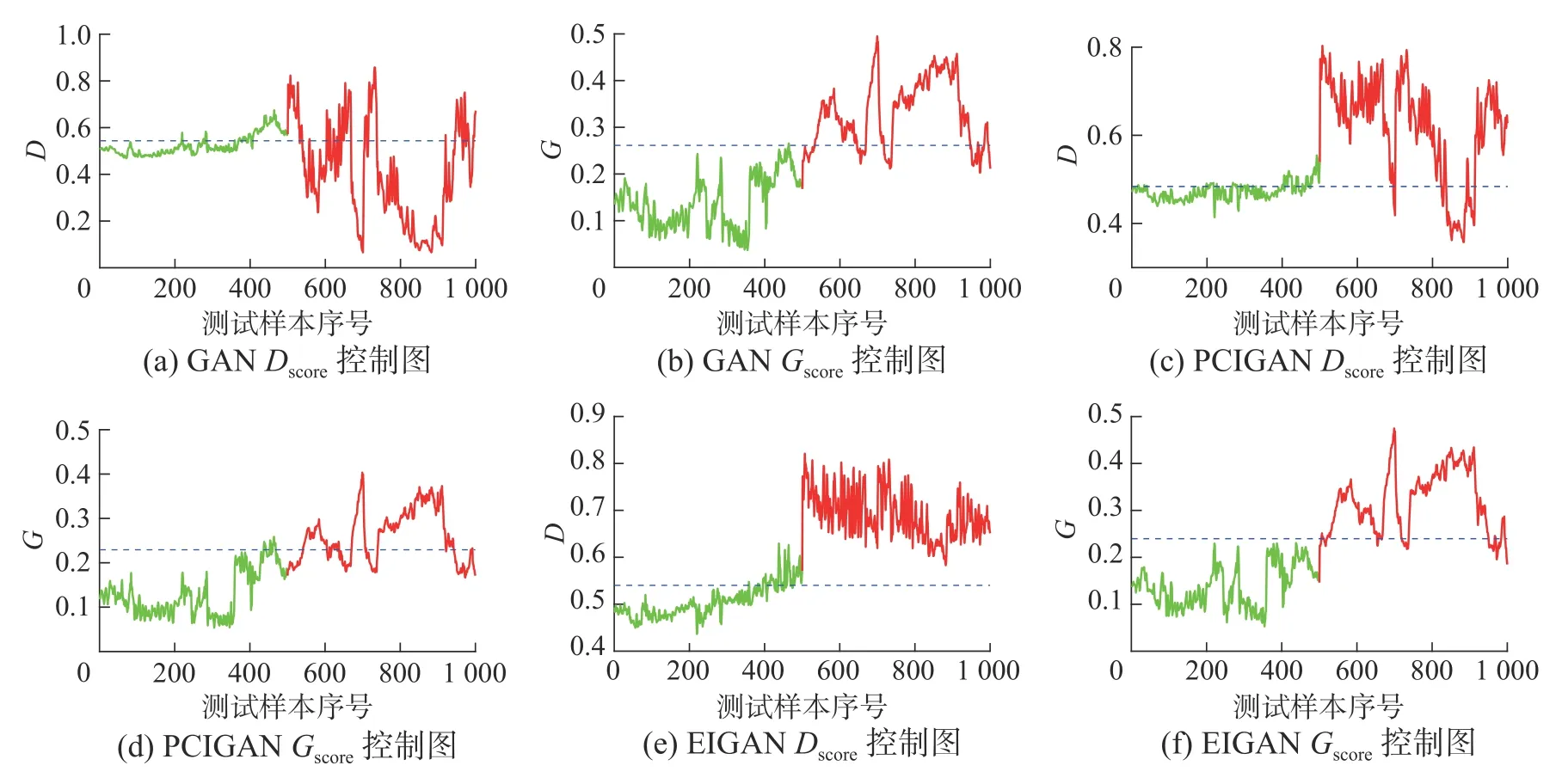
图9 磨煤机过程控制图对比Fig.9 Comparison of control plot of coal pulzerizer process

图10 关于生成器输入的统计量检测结果对比Fig.10 Comparison of the statistics using different generator input
对磨煤机数据训练集、测试集及其经自编码器编码后的隐变量空间绘制箱线图,如图11 所示。通过对比图11(a)、(c)、(e)可以看出:经自编码器提取出的隐变量空间及PCA 方法提取出的得分向量空间去除了线性相关及冗余的变量,以少量的变量最大程度地还原了原有数据集中的信息。但对比图11(d)、(f)发现测试集经自编码器提取出的隐变量空间在变量2、3、5 上均表现出了与训练集隐变量空间的差异性,而测试集经PCA 方法提取出的隐变量空间仅在变量2 上表现出了与训练集隐变量空间的差异性。此外,训练集经PCA 方法提取出的隐变量分布的离散程度高于测试集隐变量分布,不利于故障检测。这也解释了本文所提的Escore统计量较Tscore统计量有利于故障检测的原因。

图11 磨煤机数据及其隐变量箱线图Fig.11 Pulverizer data and its hidden variable box plot
4 结束语
本文提出了一种采用编码输入的生成对抗网络故障检测方法,通过引入自编码器,将自编码器降维后的数据作为生成对抗网络中生成器的输入,改善了传统生成对抗网络中生成器使用随机噪声作为输入带来的缺乏有效信息训练过程缓慢的问题,提升了生成对抗网络的训练效果和检测性能。所提方法与其他传统故障检测方法相比,在TE 及磨煤机过程仿真中具有更高的报警率,表明了方法的有效性和可靠性。但在仿真过程中发现生成对抗网络最终得到的生成器模型对于故障检测贡献率不高,与此同时判别器在对样本进行故障检测时仅考虑了待测样本维度上的信息。如何更好地利用生成器设计统计量及改进判别器模型得到关于待测样本更多更丰富的信息是未来需要进一步考虑和研究的问题。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
煤气与热力(2022年4期)2022-05-23
锻压装备与制造技术(2021年5期)2021-11-13
防爆电机(2021年5期)2021-11-04
舰船科学技术(2021年12期)2021-03-29
科学技术创新(2021年5期)2021-03-17
防爆电机(2020年4期)2020-12-14
铁道通信信号(2020年1期)2020-09-21
——编码器
演艺科技(2020年7期)2020-08-13
电子制作(2019年18期)2019-10-11
