
支持数据隐私保护的联邦深度神经网络模型研究
2022-06-18 10:37张泽辉高铁杠
自动化学报 2022年5期
张泽辉 富 瑶 高铁杠
近年来,人工智能技术已经在图像分类、目标检测、语义分割、智能控制以及故障诊断等领域取得了优秀的成果[1−7].在解决某些特殊问题方面,深度学习算法已经逼近甚至超过人类水平.深度学习技术的快速发展主要依赖于丰富的数据集、算法的创新和运算设备性能的大幅提升[8].其中,数据集的丰富程度对深度学习模型的性能水平产生直接影响[9−11].但是,某些行业考虑到数据隐私泄露的问题,难以共享数据进行集中式学习.例如医疗行业在数据共享的过程中,某些病人的信息可能会泄露到不法分子手中,不法分子则利用患者信息推销非法药品、谋财害命[12−14].因此,为进一步提升模型性能水平,能够组织多个研究机构通过共享本地模型参数的方式,实现协同训练全局模型的联邦学习算法被提出.
针对机器学习中数据隐私泄露的问题,一些隐私保护的方法被提出,主要可以分为以安全多方计算(Secure multiparty computation,SMPC)、同态加密(Homomorphic encryption,HE)为代表的基于加密的隐私保护方法和以差分隐私(Differential privacy,DP)为代表的基于扰动的隐私保护方法.
安全多方计算是指两个或者多个持有私有数据的参与者通过联合计算得到输出,并且满足正确性、隐私性、公平性等特性.Bonawitz 等[15]提出一种基于秘密共享的安全多方计算协议,旨在保证设备与服务端之间通信,并可以用于联邦学习的参数聚合过程.与传统密码学方法相比,该协议的优点在于其计算代价并不高,但由于通信过程涉及大量安全密钥及其他参数,可能导致通信代价会高于计算代价.
同态加密方案能够保证对密文执行的特定数学运算会对其明文有着相同的影响.贾春福等[16]提出一种在同态加密数据集上训练机器学习算法的方案.这类方法能够很好地解决隐私安全问题,既可以将加密的数据聚合在一起进行模型训练,也可以采用联邦学习进行模型训练.然而,该类方法[16−19]需要根据所构建的机器学习模型,选用或设计恰当的同态加密方案对训练数据进行加密,对密码学知识有着较高的要求.同时,由于对数据加密需要大量的算力资源,该类方法不适用于大数据环境下的深度学习模型训练.Phong 等[20]提出通过对联邦学习过程中各训练者产生的梯度数据进行加密,从而保证多个参与训练者的本地数据隐私安全.这类方法通过对梯度参数进行加密保护,能够很好地保护数据隐私安全.然而,该方法的加密运算量与训练数据量的大小直接相关,会大大增加模型训练时间和计算成本,并且没有对偏置项进行考虑.
差分隐私技术指在模型训练过程中引入随机性,即添加一定程度的随机噪声,使输出结果与真实结果存在着一定程度的偏差,从而防止攻击者推理.Agrawal 等[21]提出通过对训练数据集进行扰动,实现联邦深度神经网络的隐私保护.Shokri 等[22]通过在神经网络模型的梯度参数上添加噪声,从而实现数据隐私的保护.Truex 等[23]针对联邦学习模型,提出一种结合差分隐私和安全多方计算的隐私保护方案,能够在保护数据隐私的同时,还有着较高的准确率.然而在梯度参数上添加噪声,可能会造成机器学习模型训练时收敛难度增大、预测精度下降,降低模型的使用性能.
针对上述问题,本文提出一种支持数据隐私保护的联邦深度神经网络模型.本文主要贡献有两个:1) 对多层神经网络的训练过程进行分析,详细地论述模型权重参数与梯度参数是如何泄露数据集信息的.2) 基于此,将固定的偏置项参数改为随机数生成,从而避免由于梯度参数信息泄露而导致数据信息的直接泄露;并且将模型梯度参数加密替换为神经网络模型的权重参数加密,从而减少了加解密运算量;同时训练者可选择多种优化算法,不再局限于随机梯度下降法,使得提出的方法更加适用于真实场景.
1 问题陈述与预备知识
1.1 问题陈述
本文研究的联邦学习系统由两部分组成:多个训练者和参数服务器.所有训练者都预先同意训练一个确定框架的深度神经网络模型,并使用相同的优化算法(如随机梯度下降法) 和其他训练参数(如学习率、mini-batch、迭代次数).各训练者和参数服务器采用联邦学习的方式,互相联合、协作训练一个深度神经网络,在训练过程中各训练者的训练数据均在本地.另外,训练者和参数服务器之间需要认证与授权,授权后的训练者才可以获得从参数服务器下载参数和上传参数的权限.关于云环境下的用户认证和授权非本文研究重点,具体可见文献[24].
本研究使用 “诚实且好奇”的半可信威胁模型[25].假设所有训练者和参数服务器都是 “诚实且好奇”的半可信实体,所有训练者和参数服务器都会遵守训练协议,但是在训练模型过程中都想要通过推理得到其他训练者的数据信息.本文研究旨在在联邦学习训练阶段保护各训练者的数据隐私,使各训练者不能推理得到对方的数据信息,同时也不能泄露信息给第三方服务器.
1.2 神经网络模型
一个典型的神经网络模型通常包含三层,分别为输入层、隐藏层与输出层[26].深度神经网络模型可以包含多个隐藏层,每个隐藏层具有一定数量的神经元,并且不同隐藏层的神经元可以自动从训练数据中提取不同层次的特征.两个神经元之间的连接,即是神经网络模型的权重参数.每层神经网络除了神经元权重参数以外,还有偏置参数.权重参数和偏置参数统称为神经网络的模型参数.神经网络工作过程主要有两个:正向传播与反向传播.正向传播过程是指,输入数据正向通过各层神经元的计算,然后输出预测结果.反向传播过程是指,先计算预测结果与目标值的偏差值Loss,然后根据偏差值采用链式求导与学习算法(例如梯度下降法)对各层网络的权重进行更新.
1.3 联邦学习
当数据分散在不同组织中时,联邦学习提供了一种多方协作训练深度学习模型的解决方案,现在已成为深度学习领域的研究热点[27−29].
图1 为联邦学习结构图.首先,远程参数服务器将初始化的深度学习模型发送至各个训练者.然后,各训练者使用自己本地的数据集对模型进行训练,并将训练的梯度参数Gi(i=1,2,···,n) 发送至参数服务器,而不是将本地数据发送到云端训练.接着,参数服务器使用各训练者所上传的梯度参数,将全局模型的权重参数Wold更新为Wnew,并将更新后的权重参数发送至各个训练者.整个学习过程重复进行,直至达到设定的学习次数或满足用户设定的停止训练的条件.

图1 联邦学习结构Fig.1 Federated learning structure
可以看出,多个训练者可以通过使用联邦学习框架协同训练深度学习模型,从而提高模型性能.但是,该训练过程中主要存在两个缺点:1)通信过程不安全;2)模型权重参数与梯度参数可能存在隐私安全问题.经典的信息加密方法能够有效解决第一类问题[30−32],而第二类问题则需要根据深度学习具体问题建立一种隐私保护的机制.并且,由于隐私政策或法规的限制,大多数客户都不愿共享其数据.因此,需要对考虑数据隐私保护的联邦深度学习模型进行深入研究.
1.4 同态加密
根据支持的数学运算种类与运算次数,同态加密算法可以分为:支持一种数学运算且不限制运算次数的部分同态加密算法、支持特定数学运算且有限运算次数的有限同态加密算法、支持不限制数学运算种类且不限制运算次数的全同态加密算法.本研究采用的是Paillier 同态加密算法,该算法包括4个步骤(密钥生成KeyGen、加密算法Encryption、解密算法Decryption 和验证算法)[33−35].
1)密钥生成 KeyGen (λ) →(pk,sk):
随机选取两个长度相同的大素数p和q,且满足gcd(pq,(p −1)(q −1))=1,计算N=pq,λ=lcm(p −1,q −1),随机选取g ∈,则公钥pk=(N,g),私钥sk=(λ).
2)加密算法 Encryption(pk,m)→c:

2 深度学习模型的隐私泄露
经典的神经网络在训练过程中,可能存在数据集隐私泄露的风险.图2 为一个典型的三层神经网络,其中x1与x2为输入数据,wi(i=1,···,8) 分别为各神经元的权重,bi(i=1,···,4) 为各偏置项的权重,target为输出目标值.下面以三种情况为例,详细地对深度学习模型的隐私泄露问题进行说明.

图2 神经网络结构Fig.2 Neural network construction
1)第一种情况
首先计算神经网络的输出值与目标值的偏差,计算公式如下:
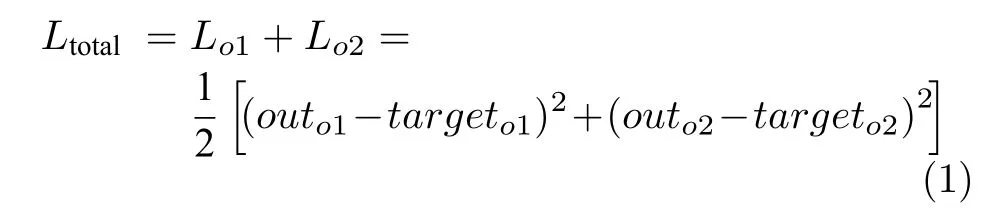
然后,根据链式求导法则,可以计算出w1、b1和w3的梯度:

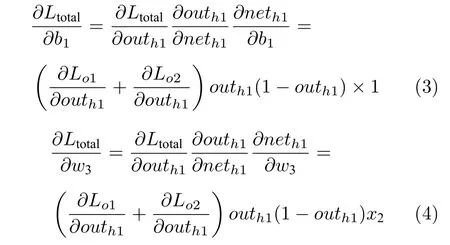
根据链式求导结果,可以得出:

从式(5)、式(6)看出,能够从梯度参数反推出输入数据.并且第一层网络的所有梯度参数,都能够通过与之相对应的偏置项推导出数据信息,例如x1也可以通过w2的梯度除以b2的梯度得到.
图3(a)~图3(d)分别为信息泄露100%、80%、50%和30%的图片.从图中可以看出,当获取一定数量的输入数据时,其关键信息就可能已经泄露.

图3 不同比例的数据信息泄露Fig.3 Different proportions of data information leakage
当求得训练数据中的输入数据后,通过神经网络模型正向传播求出模型输出值.然后,根据式(7)、式(8)可以求出数据集中的目标输出数据targeto1,类似可以依次求出所有的目标输出数据.经过上述过程,数据集的信息便泄露出来.
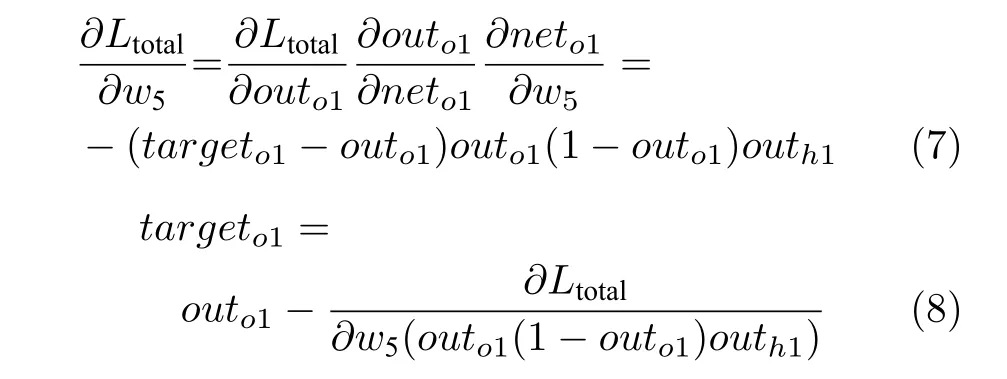
2)第二种情况
假如第一层的梯度参数(∂Ltotal/∂wi,i=1,···,4)被加密,但是依然可以根据式(9)~式(11)推导出隐藏层的输出值outh1与outh2.然后通过解方程组式(12),则可求出输入数据x1与x2.再按照第一种情况正向传播求解目标数据值,便可以得到数据集的所有信息.

3)第三种情况
假如神经网络模型偏置项数值不是固定值1,而是由随机数生成,可以通过式(13)求出各隐藏层输出值与偏置项的比值.然后,尝试可能使用的偏置项数值,将推测的偏置项数值根据第一种情况,计算出推测的输出值和推测的目标值,最后将使用推测结果计算的梯度值与真实的梯度值进行比较.重复上述过程,暴力求解可能使用的偏置项数值.从图4 中可以看出,当输入数据为图片时,与真实偏置项数值的差距即为推测图片与真实图片亮度的差距.因此,当推测的偏置项数值与真实的偏置项数值比较接近时,信息便可能出现泄露.

图4 不同偏置值的数据信息泄露Fig.4 Data information leakage of different bias values

3 支持数据隐私保护的联邦深度学习模型
支持数据隐私保护的联邦深度学习模型,其中包括一个参数服务器与多个训练者.模型运行过程主要分为三个部分:模型初始化、模型训练和模型部署.图5 为联邦深度学习算法训练过程交互图.采用文献[20]中提出的联邦学习隐私保护的通讯方案,各训练者与参数服务器之间建立不同的TLS/SSL (Transport layer security/Secure sockets layer)安全通道.各训练者之间采用经典的AES (Advanced encryption standard)加密算法,对同态加密算法的公钥pk与私钥sk、深度神经网络模型的结构参数、选用的优化算法及其学习率等进行加密传输.收到信息后,各训练者进行模型初始化、模型训练以及模型部署操作.

图5 训练过程交互图Fig.5 Interaction in the training process
模型初始化.训练者们预先确定负责模型初始化的训练者.该训练者对深度神经网络模型进行搭建,模型中的权重参数与偏置项参数使用随机数算法生成.然后,确定同态加密算法的参数,根据同态加密算法的定义生成公钥pk与私钥sk(具体过程见文中第1.4 节或参考文献[33−35]),并将公钥、私钥与偏置项数值使用AES 算法加密后发送至各训练者,对参数服务器保密.该训练者使用同态加密算法的私钥对深度神经网络模型的权重参数进行同态加密,并将加密后的权重参数发送至参数服务器.参数服务器将该训练者上传的加密参数广播至其他训练者.其他训练者使用私钥对加密的模型权重参数进行解密,将解密后的参数加载到自己的本地模型,从而完成初始化过程.
模型训练.如图6 所示,各训练者将下载的全局模型权重参数解密后,加载到本地模型上.使用本地数据对模型进行训练,完成一次学习后,将更新的本地模型的权重参数经同态加密后上传至参数服务器.进行加密的全局模型权重参数更新,并将加密的全局模型权重参数广播给所有的训练者.迭代上述学习过程,直至达到训练设定条件.具体训练过程见第3.1 节和第3.2 节.
模型部署.当模型完成训练后,各训练者不再上传深度神经网络的权重参数.将训练好的深度神经网络全局模型的权重参数经私钥sk解密后,加载至本地模型进行部署,并断开与参数服务器的连接.
3.1 训练者
各训练者对存储在本地的数据集进行预处理,然后对本地的深度神经网络模型进行训练.具体步骤如下:
1)各训练者首先根据具体项目内容,预先确定好所采用的数据预处理方式,然后对各自本地数据进行预处理;
2)各训练者从参数服务器下载深度神经网络全局模型权重参数密文,然后使用私钥sk对密文进行解密,最后将全局模型权重参数加载至本地深度神经网络模型;
3)各训练者根据预先设定好的mini-batch 值、迭代次数、优化算法和学习率,使用本地数据进行一次迭代学习,并使用公钥pk对本地深度神经网络更新的模型权重参数进行同态加密,最后将密文发送至参数服务器;
4)重复步骤2)和步骤3),直至达到设定迭代次数.
3.2 参数服务器
如图6 所示,参数服务器将各训练者上传的模型参数求平均值,并更新加密的全局模型权重参数.图中密文计算公式的合法性是由同态加密算法的性质来保证的,具体特性可见附录A.
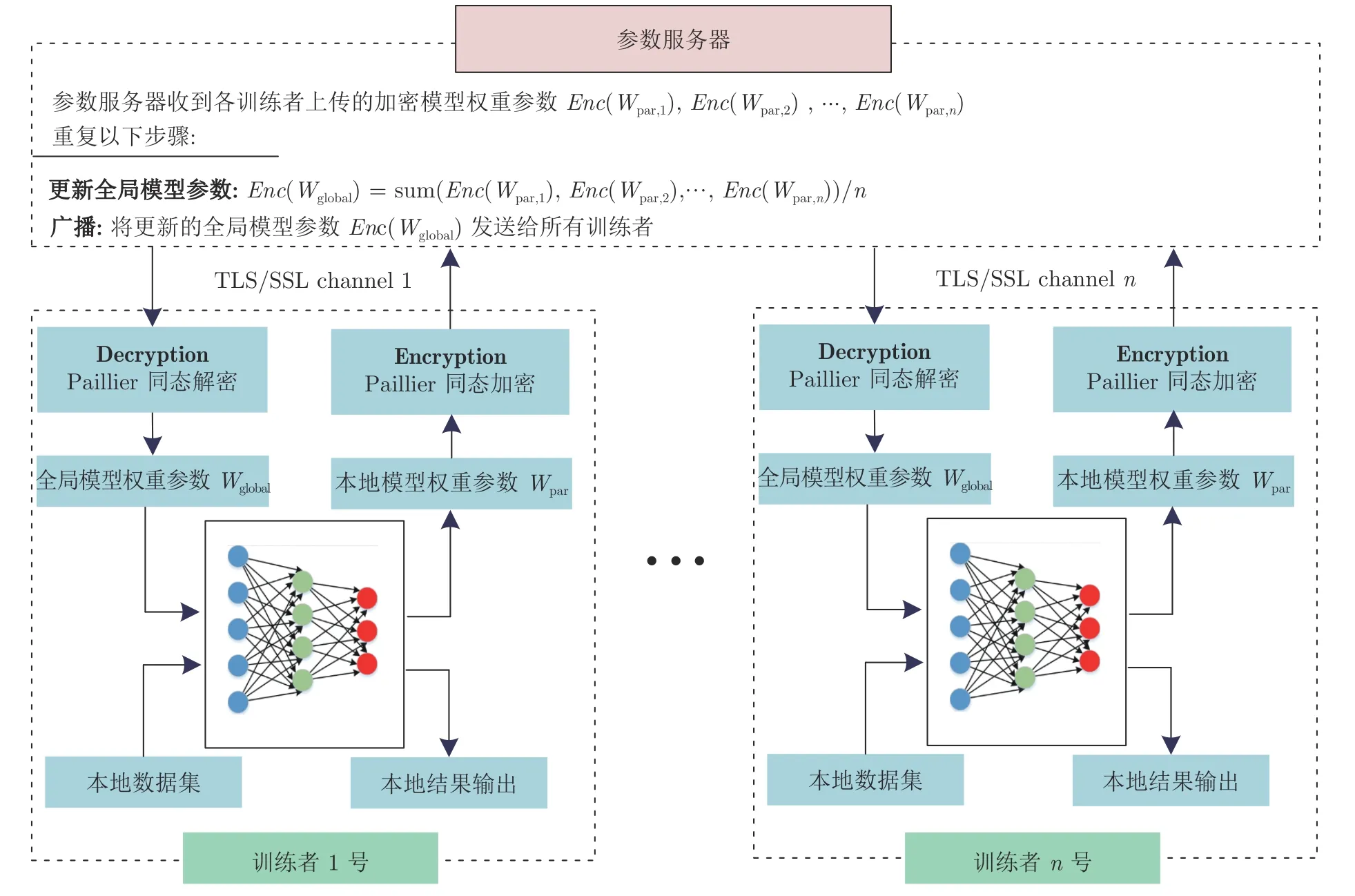
图6 支持数据隐私保护的联邦学习训练过程Fig.6 The training process of the date privacy-preserving federated learning
定理 1 (针对参数服务器的安全性).如果采用的加密方案是满足CPA (Chosen-plaintext attack)安全的,则训练者不会将数据集上的信息泄漏给“诚实但好奇”的参数服务器.
证明.训练者仅将加密的模型权重参数发送到云服务器.因此,在联邦训练过程中,如果加密方案是CPA 安全的,则不会泄漏有关训练者数据的任何信息.
注 1.当各参与训练者通过不同的TLS/SSL 通道连接到参数服务器时,假设参数服务器不会和任何训练者串通,训练者仅能够知道全局模型的参数,而不能知道其他参与训练者的梯度信息.
注 2.深度神经网络中的偏置项不是固定的常数项(例如数值为1),而是由某一训练者随机生成的常数项.
4 联邦深度学习算法分析
4.1 安全性分析
回顾上述联邦深度学习算法训练过程,训练者与参数服务器获得的中间数据如表1 所示.从表1中可以看到,在联邦深度学习训练过程中,各训练者通过私钥解密获得的是全局模型权重参数,无法获得其他训练者模型权重参数Wpar、梯度G、预测结果Prediction results 以及损失值Loss.同时,参数服务器获得的是各训练者加密过的本地模型权重参数Enc(Wpar) 和加密过的全局模型权重参数Enc(Wglobal),而参数服务器没有私钥,无法对参数数据进行解密.

表1 训练者与参数服务器获得的数据信息Table 1 Data information obtained by the participant and parameter server
联邦深度学习训练前,模型的偏置项参数与同态加密算法的私钥、公钥使用现代成熟的加密方法在各训练者之间进行信息传输;联邦深度学习训练过程中,参数服务器与各训练者传输的是模型参数的密文,即使模型参数信息被敌手截获,其也无法进行解密.
4.2 时间分析
与传统联邦深度学习算法相比,本文所提出算法额外产生的计算开销和通信开销分别为:模型参数加密/解密,模型参数上传/下载.本文使用Python 开源平台上的Paillier 同态加密算法库,密钥长度为1024 bit,计算机CPU 型号为Intel i7-6500.表2 所示为不同个数的模型参数运算100 次,同态加密算法操作(包括加密操作、密文加法操作和解密操作)和无加密算法的直接相加的平均每次执行时间.
训练过程中,迭代次数为epoch,训练者个数为n,网络模型参数个数为Mpar,则加密时间复杂度为O(epoch×n×Mpar×Epaillier),解密时间复杂度为O(epoch×n×Mpar×Dpaillier).可以看出,所提出的联邦深度学习算法加密/解密次数与数据集无关.本文模型参数量为53018 (模型结构如表3所示,Li代表第i层神经网络),n=2,一个迭代训练过程加密/解密操作数为2 × 53018=1.06 ×105次.如果采用文献[20]的方法,假设训练数据集个数为60000个,则其一个迭代训练过程加密/解密操作数为2 × 60000 ×53018/50=1.27 × 108次.通过对比能够看出,直接对参数进行同态加密,能够大大缩短模型训练时间.

表3 深度神经网络模型结构Table 3 Deep neural network model structure
本文所提出算法的通信开销为Tcost=2(epoch×n×Mpar×ct),其中ct为一条密文大小,空间复杂度为O(n×Mpar×ct).可以看出,所提出算法的空间复杂度与数据集无关,主要受到模型参数量的影响.本文模型参数量为53018,n=2,ct=256 bit,一个迭代训练过程通信开销为2 × 53018 × 256=25.88 MB.如果采用文献[20]的方法,假设训练数据集个数为60000个,则其一个迭代训练过程通信开销为2 × 60000 ×53018 × 256/50=0.12 GB.通过对比能够看出,直接对参数进行同态加密,能够大大减小通信开销.
5 实验与分析
5.1 实验环境与数据集
电脑运行环境如下:CPU 为Intel i7-6550,内存16 GB,显卡NVIDIA 1050Ti,Pytorch 1.1,CUDA 9.0,Win10 操作系统.使用开源的Paillier 库[36],对神经网络模型的权重参数进行加密与解密.实验数据集为Zalando Research 在GitHub 上推出的一个用于替代手写数字识别数据集MNIST 的全新数据集Fashion-MNIST,该数据集已经被广泛用于机器学习算法的性能评估[37−39].Fashion-MNIST 的训练集包含60000个样本,测试集包含10000个样本,共有10 类(Trouser,Pullover,Dress,Coat 等),每个样本都是28 × 28 的灰度图像.本文以两个训练者为例,实现支持隐私保护的联邦深度神经网络模型.训练集中,前30000个样本设定为数据集1,后30000个样本设定为数据集2,从而完成训练数据集的切割.传统训练模型使用完整的训练数据集,而联邦深度学习中的训练者1 使用数据集1 作为训练数据集,训练者2 使用数据集2 作为训练数据集.训练好模型后,采用Fashion-MNIST 测试数据集进行评估.
5.2 实验和结果分析
本节将传统深度神经网络模型与支持隐私保护的联邦深度神经网络模型采用如表3 所示相同的结构,采用SGD (Stochastic gradient descent)算法对深度神经网络DNN (Deep neural network)与联邦深度神经网络PFDNN (Privacy-preserving federated deep neural network) 进行训练,采用ReLU 激活函数,循环次数epoch为300 次.DNN-1与PFDNN-1 学习率设定为0.005,DNN-2 与PFDNN-2 学习率设定为0.01.
不同mini-batch 值下,各模型训练过程曲线如图7 所示,其中包含测试数据集识别准确率Accuracy曲线、测试数据集Loss曲线和训练数据集Loss曲线.从图7(a)和图7(b)中可以看出,DNN模型在迭代前50 次时,训练集Loss值与测试集Loss值迅速下降,识别准确率Accuracy快速提高.DNN-1 模型迭代至150 次左右时,Loss值与识别准确率趋近于稳定.由于学习率高于DNN-1,DNN-2 模型迭代至100 次左右时Loss值与识别准确率Accuracy趋近于稳定.从图7(c)和图7(d)的Loss值曲线可以看出,PFDNN-1 与PFDNN-2 模型在训练时模型收敛速度相比于DNN 模型较慢一些,迭代至200 次后Loss值与识别准确率趋近于稳定.并且从各模型的测试集Loss曲线可以观察到,使用较小mini-batch 值会加快模型收敛速度.在mini-batch=32 时,各模型的测试集Loss曲线都出现了不同程度的过拟合现象.可以看出,所提出的PFDNN 模型在不同参数下,识别准确率Accuracy、训练集Loss值与测试集Loss值都与DNN 模型总体保持一致.

图7 各模型训练过程曲线Fig.7 Training process curves of each models
为观察DNN 与PFDNN 具体物品分类的情况,4 种模型在测试集识别结果的混淆矩阵如图8所示.可以看出,DNN 与PFDNN 对测试集中的Shirt 识别效果都不理想,并且都主要误识别为Tshirt、Pullover 和Coat.以混淆矩阵的结果和训练过程测试集识别准确率对DNN 与PFDNN 的偏差进行评估.评估计算公式为:

图8 测试集预测结果的混淆矩阵Fig.8 The confounding matrix of the test dataset prediction results

式中,cn表示物品种类个数,DNNacc,i表示DNN识别第i类物品的准确率,PFDNNacc,i表示PFDNN 识别第i类物品的准确率,DNNacc,max表示DNN 在训练过程中测试集最高的准确率,PFDNNacc,max表示PFDNN 在训练过程中测试集最高的准确率.如表4 所示,随着mini-batch 值的增大,DNN 与PFDNN 在具体物品分类上的偏差加大.在mini-batch 值较大时,PFDNN-1 由于欠拟合,与DNN 最高准确率的偏差最大达到了2.82%;而当PFDNN 充分训练后,与DNN 最高准确率的偏差较小.总体可以看出,所提出的PFDNN 模型能够保证很高的精确度.

表4 不同模型偏差结果Table 4 The deviation results of the different models
表5 为4 种模型在测试集上,对不同种类物品的识别精确率Precision与召回率Recall.识别精确率是指正确预测为正占全部预测为正的比例,而召回率是指正确预测为正占全部为正的比例.识别精确率与召回率越接近1,说明分类器的分类效果越好.从表5 中可以看出,传统深度学习模型与所提出的联邦深度学习模型对各类物品识别的结果相差不大.这说明本文所提出的PFDNN 模型能在没有明显精度损失的前提下,保护数据的隐私安全.
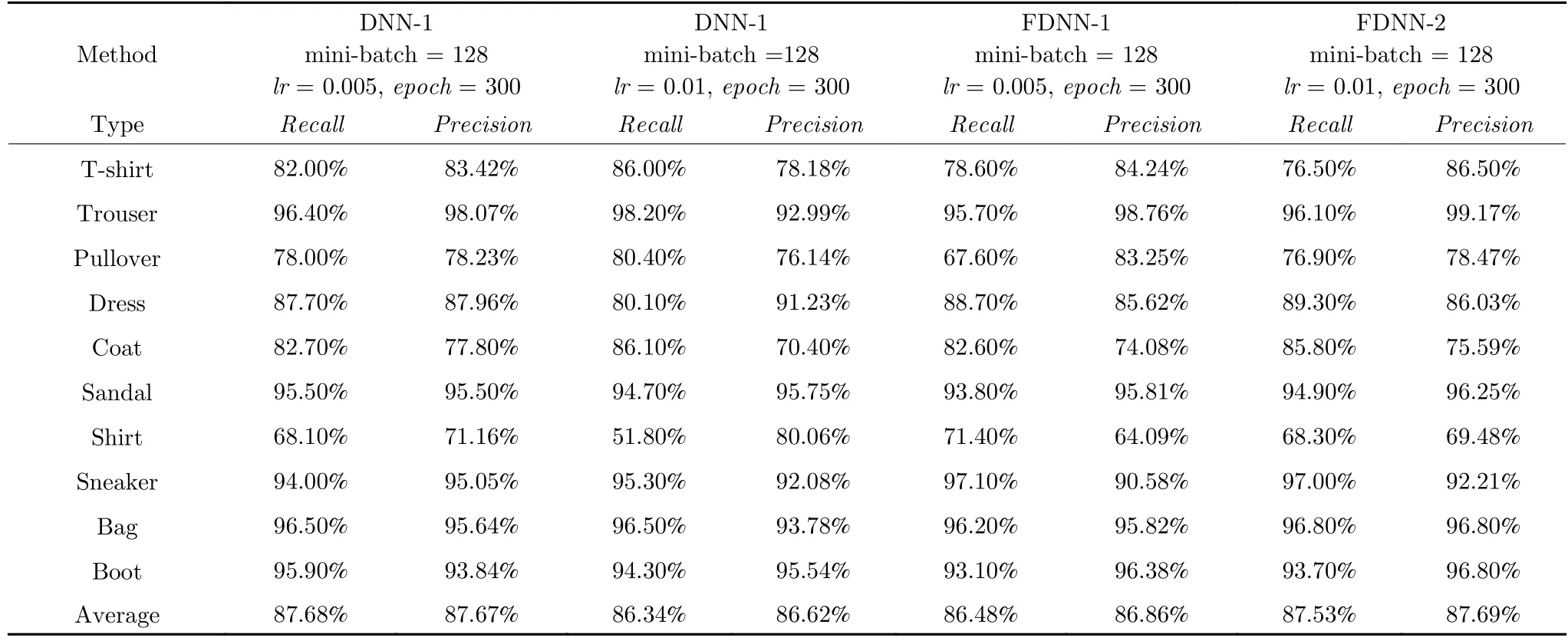
表5 不同类别物品的预测结果Table 5 Prediction results of the different items
6 结论
针对联邦学习中存在的数据隐私信息泄露问题,提出了一种支持隐私保护的联邦深度神经网络模型.本文以多层神经网络为研究目标,详细地分析模型梯度参数可能会造成数据隐私泄露的三种情况.基于此,初始化模型参数时,偏置项参数不再使用固定数值而使用随机数,以避免梯度参数泄露导致数据信息直接泄露.然后,引入同态加密算法,各训练者通过对深度神经网络模型的权重参数进行同态加密,从而保障了自身本地数据隐私安全.与传统联邦学习隐私保护方法相比,使用模型权重参数共享,能够将模型参数更新过程转移到训练者端(即边缘端),降低了参数服务器(即云端)性能要求,并且训练者不再局限于随机梯度下降法.理论分析与实验表明,所提出的联邦深度神经网络在没有明显损失模型精度的前提下,能够对用户数据的隐私进行有效的保护.
所提出的联邦深度学习模型收敛速度较慢,并且在非独立同分布数据集和较大mini-batch 值上会出现一定程度的精度损失.虽然提高全局模型更新频率能够进一步提高精度,但是会消耗大量的计算资源与训练时间.因此,下一步拟通过使用GPU对同态加密过程进行加速,以进一步缩短模型训练时间.并且,拟对参数服务器中的模型权重参数更新机制(例如,全局模型参数更新频率和mini-batch值)进行深入研究,从而增加支持训练者的个数,并提高模型收敛速度和计算精度.
附录 A Paillier 加密算法同态特性

可以看出,E(m1) 和E(m2) 的乘法结果相当于明文消息m1+m2在公钥pk和随机数r1、r2下进行加密,因此,Pallier 加密算法满足加法同态特性.
当对密文进行指数运算时,根据加密算法有:

从结果可以看出,对密文的指数运算等于明文之间的乘法运算.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
兰州理工大学学报(2022年3期)2022-07-06
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
兰州理工大学学报(2021年2期)2021-05-10
家庭影院技术(2020年10期)2020-12-14
兰州理工大学学报(2020年4期)2020-09-16
五邑大学学报(自然科学版)(2020年1期)2020-06-17
家庭影院技术(2019年7期)2019-08-27
课堂内外(小学版)(2017年5期)2017-06-07
网络空间安全(2016年3期)2016-06-15
