
构建基于健康医疗数据的急危重症数据集的技术规范
2022-06-17 08:49执笔人高珍珍朱华玲
中国急救医学 2022年6期
执笔人: 高珍珍, 杨 军, 朱华玲
近年来随着科技的发展和医疗信息化水平的提高,“医疗大数据”的概念深入人心,逐渐被应用到临床、科研、教学、管理等环节,尤其专科专病数据库已经应用到了临床科研方面,对开展真实世界研究有重要的意义和价值。急诊医学(emergency medicine)是1979年被国际上正式承认为一门独立的二级临床学科,在专业知识、临床思维、诊疗技术等方面与各传统专科相互交叉且具有自己独特的鲜明专业特征[1]。急诊患者的特点是急、危、重,急诊科医生对患者的诊断、治疗涉及到多个专业,仅凭某一专业或某一专科的知识不能很好解决患者的问题,急诊科医生不得不以最少的数据、在最短时间内、以最快捷有效的方法救治患者。基于真实世界数据循证医学的出现和发展,给急诊医学指引了一个方向,已经深入影响和指导急诊科医生的医疗行为[2]。因此基于健康医疗数据开展急危重症的科学研究和转化应用,为更多的患者提供更优方法学指导下的临床医疗服务,对学科发展起着重要的推动作用。而由于健康医疗数据容量巨大、类型繁多,如何从中进行分类、筛选,获取有价值的信息成为大数据时代信息处理的难题。
本技术规范旨在阐述基于健康医疗数据的急诊医学急危重症数据集的概念、特征、应用范围、参考依据、构建流程、规范及其质量评价指标等,以期为建设急诊医学专科大数据平台或共享平台所需的数据集标准提供依据和参考,并为国家制定急诊科建设与管理方案提供参考。
1 概念和适用范围
1.1健康医疗数据
健康医疗数据是指在医疗行业中产生的数据,包括医疗数据信息、卫生事业、生命健康数字化等存储的海量数据[3]。90%的健康医疗数据来源于医疗机构,而医疗机构信息化系统发展较早、标准形成较晚,导致医疗机构数据格式繁杂。仅仅HIS系统,国内就有2000多家医疗信息化公司,数据格式各有不同,数据标准不统一。这导致数据难以融合,也就难以支撑数据的应用[4]。同时数据的产生通常是基于医疗管理和决策目的,而非特定研究目的,通常不能直接用于开展研究。要使用这些数据开展研究首先需基于一定的研究目的,通过数据提取及清理等数据治理过程,将基于管理目的收集的数据转化为适用于临床研究的数据库,这一过程即构建研究型数据库[5],而构建研究型数据库的重要前提需要有与之应用相匹配的标准化数据集。
1.2急危重症数据集
急危重症常累及多个器官和系统,可出现严重和复杂的全身内环境和病理生理紊乱,主要研究器官与器官之间的相互关系,探讨危重患者的病理生理变化、监护和处理,研究由多种致病因素引起的复杂临床综合征[2]。基于急危重症的诊疗不只强调某一器官而是兼顾整体的特征,使得急诊科的健康医疗数据不同于其他专科数据,既包含几乎全学科的疾病诊疗信息,又突出包含急诊诊疗抢救、手术、留观和护理评估等方面的信息。开展真实世界数据研究需要将急诊科患者相关的所有数据进行整合,因此用于急危重症的专科数据集是为了实现急危重症患者全生命周期数据(本研究目前限于院内数据)的数据整合,以满足后续不同专病、专项科研需求和其他应用。
1.3数据元、数据集
数据元(data element)是指用一组属性规定其定义、标识、表示和允许值的单元。若干个数据元可以组成数据集。例如将患者病案号、入院时间、出院时间、住院总费用、诊断编码、手术名称、护理等级等100多个数据元组合在一起形成住院病案首页数据集。
数据集(data set)指具有一定主题,可以标识并被计算机处理的数据集合,是若干个数据元组成的集合体,即数据元目录[6]。主题是指围绕某一项特定任务或活动进行数据规划和设计时,对其内容的系统归纳和描述。例如急危重症数据集是根据急危重症的临床和科学研究的需求对相关信息进行归纳、提炼和描述而形成的。可标识是指通过规范的名称和标识符等对数据集进行标记,以供识别。其命名和标识需要通过具体的命名或编码规则来规范,以保证其准确性、专业性和通用性。能被计算机处理是指可以通过计算机技术对数据集的内容进行发布、交换、管理和查询。数据集是在特定主题下由必需、基本数据元组成的集合,是对所必须采集记录的数据元基本范围的标准化要求。根据实际情况,在数据集范围内可以进一步分类、分级,形成若干部分或子集。电子病历基本数据集就包括住院病案首页等17个部分,每一部分又包括若干个子集。
1.4适用范围
本技术规范是基于首都医科大学国家健康医疗大数据研究院急危重症大数据临床研究中心相关项目的建设经验产出的实践成果,并经过80多位急诊医学专家和10多位数据、信息专家的评审、修改和完善。主要阐述基于健康医疗数据构建急危重症数据集的思路、框架、流程、规则及评价的技术要点和关键指标,可促进学科范围内的医院信息有效交换和广泛共享,是顺利开展真实世界研究的基础[7]。适用于各医疗机构急危重症数据集的建设,并为其他学科或病种的数据集建设提供参考。
2 健康医疗数据的现状与特征
健康医疗数据是基于医疗或行政管理目的形成的,因医疗或行政管理目的不同,健康医疗数据又分为不同类型,包括医保数据、单一医疗机构电子病历、出生/死亡登记数据、区域化医疗数据及其他链接数据等[8]。这些不同职能的数据分别存储于不同的系统中,造成同一家医院有多种、多个不同厂商系统,包括HIS、LIS、PACS、EMR等。开展科学研究需要汇集患者诊疗过程的全生命周期的数据,因此对来源广泛的数据元进行标准化,通过建立概念数据模型和数据规范,明确数据的应用语境,保证信息的准确性和一致性,是实现语义互操作的基础。世界发达国家健康数据标准化工作起步较早,普遍以建立信息模型和元数据规范为主要技术路线和方法,以指导信息系统建设、规范数据收集、增进共享为最终目标。我国自2009年以来参照国际通用标准,陆续推出多项国家卫生信息标准,包括基础类标准、数据类标准、技术类标准、应用与服务类标准、管理类标准、安全与隐私标准等,逐步形成面向国内数据现状的可供参照的卫生信息标准体系。其中数据标准是健康信息标准体系的重要组成部分,国家卫健委发布了《卫生信息数据元标准化规则》《卫生信息数据集元数据规范》《卫生信息数据集分类与编码规则》《卫生信息数据元目录》《卫生信息数据元值域代码》和《电子病历基本数据集》(WS445-2014)等一系列数据标准和规范。这些标准和规范对我们开展数据集成和标准化工作有指导性作用,但目前医疗信息化的现状是各医院、各系统、各厂商并未做到统一化、标准化,因此原始数据尚未统一,研究型数据库尚无标准化数据集,急危重症等专科专病数据集也尚缺乏建设规范,这就是本技术规范的目的所在,即建立、健全用于专科专病研究的数据模型基本数据集的一套建设方法和理论体系。
3 建设思路与方法
3.1总体思路
急危重症数据集的建设思路是,一方面收集和分析医院信息系统中医疗数据表结构,广泛搜集原始数据项,去除系统日志、操作日志等与科研相关性低的数据元;另一方面结合现行的医疗卫生行业数据标准和政策文件,并借鉴医疗大数据科研平台或研究型数据库建设的相关研究文献,基于实践提炼和梳理制作流程和规范;同时结合急危重症科学研究的需求,并从临床应用和使用习惯为出发点,经过整理、归类,形成数据表单,然后按照卫生信息数据元的基本模型和属性模型对数据元进行抽象、命名和描述,见图1。选择该思路主要的原因:一是目前医院的信息化、标准化水平有限,信息系统业务需求和科研需求存在差异;二是院内核心医疗数据大部分为非结构化数据,很难直接为科研所用,需要根据科研需求提炼所需数据元,方便后续加工、整理,更准确有效地利用数据;三是在现有卫生相关标准、文献及科室已有科研项目的基础上进行数据集建设,可以快速获得更实用的研究结果。
3.2数据来源
3.2.1 卫生信息标准文件 电子病历基本数据集(WS 445.1-2014)(53部分)作为临床部分数据集的主要参考对象。
3.2.2 医院的主要临床记录文档,如门诊病历、住院病历、护理记录、出院记录、体温记录单等。
3.2.3 科研项目需求文档 基于过往急危重症学科领域的科研项目需求文档、课题申报文档以及发表文献等,尤其是文档中关于科研数据的来源、采集方法、构建方式、加工方法等的描述信息。
3.3数据集分类框架
3.3.1 分类框架描述
构建数据集的关键在于确定数据集的范围和分类框架,本技术规范主要依据国家卫生行业标准——电子病历基本数据集(WS 445.1-2014)[9]和《卫生信息基本数据集编制规范》[10],结合院内信息系统数据结构,并紧扣医院急危重症相关研究和数据应用的数据需求形成急危重症大数据库数据集的分类框架,同时采用兼顾面分类法和线分类法的基本原则,即从医院业务领域出发横向定界、划面,从急危重症体系角度出发纵向分层。目录表现为四级树状结构,具体分类描述如下(见表1):
一级目录:按业务类别分为临床、护理两方面。
二级目录:表达以患者为中心不同的就诊类型和产生的数据类型为分类轴心,设置的类别相对独立。临床包括住院、门诊、急诊;护理包括护理文书、体温单、护理评分。
三级目录:以数据业务类别进行分类,住院包括病历文书、检查检验记录、医嘱记录等。
四级目录:为各类业务类型的数据中具体的表单,为目录的末级。基于四级目录定义具体包含的数据元。比如,三级目录“病历文书”包含“入院记录”“出院记录”“治疗记录”“操作记录”等四级目录,“入院记录”数据集的数据元包含“入院时间”“主诉”“既往史”等。
3.3.2 分类原则 ①系统性:综合考虑数据集主题一致性,按其内在联系进行系统化排列,确保类目唯一、结构合理、层次清晰、减少冗余。②实用性:满足数据集分类编目的简便性、可操作和通用性需求和临床数据集查询和浏览的习惯。③可扩展性:保证分类体系框架适应数据集不断丰富的内容和日益增长的种类与数量。④兼顾科学性:自顶向下,优先选择最能代表卫生信息数据集主题的语言、词条定义类目名称,编制受控分类体系表。⑤稳定性:使用稳定的因素作为分类依据,同时提高分类体系的可延展性或兼容性,促进稳定性。
3.4数据元制定
第四级目录的每个数据集都包含若干数据元,数据元的筛选、编制和标准化严格遵循《卫生信息数据元标准化规则》(WS/T 303—2009)《卫生信息数据模式描述指南》(WS/T 304—2009)《卫生信息数据集元数据规范》(WS/T 305—2009)中关于数据元名称的对象类术语和表示类术语、数据元值的数据类型、表示格式、数据元允许值等的规范要求,并建立相关具体原则,包括:①求准不求多原则:数据元遵照严格的命名规则和扩展规则执行,保证数据元概念标准、规范、统一。排除不同数据集中表示同一含义的不同数据元。②复用性原则:数据元必须有明确分类归属,同时也允许在一个或多个数据集中应用。确保数据元面向各数据集实际需求,并有一定的复用性,排除孤立、一次性。依据《卫生信息数据元标准化规则》(WS/T 303—2009)[6]数据元的基本模型和属性模型,本技术规范的设计如下:
3.4.1 数据元命名
3.4.1.1 数据元命名的基本组成 数据元名称成分一般包括对象类术语、特性类术语、表示类术语、限定类术语。
(1)对象类术语: 对象类术语是构成数据元名称的一个成分,表示某一相关环境中一项行为或一个对象。例如科室名称、患者血压、调查对象的身高,组成数据元各个成分的科室、患者和调查对象等都是对象类术语。
(2)特性类术语: 特性术语集是由一个特性分类体系中的一个名称成分的集合构成。这个集合应由离散的(术语的定义之间不重迭)和完整的(作为一个整体,该集合包括了规范使用特性的数据元、数据元概念或值域所需的所有信息概念)术语构成。例如,在上述的数据元中名称、血压、身高是特性类术语。
(3)表示类术语: 表示类术语是一个数据元名称中描述数据元表示形式的一个成分。每个表示类术语可以从一个受控词表或一个分类体系中得出。表示术语分类的表示形式如下:——名称——总额、——测量——数目。见表2。
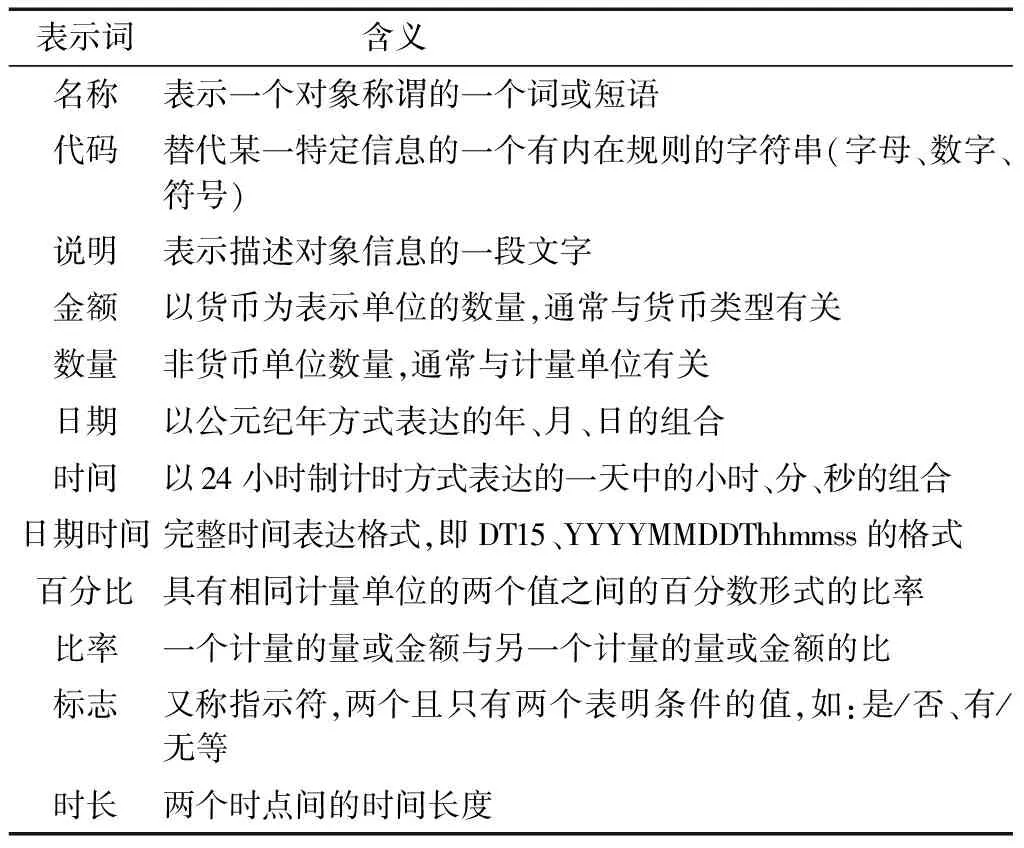
表2 数据元通用表示类术语
(4)限定类术语:如果必须对一个数据元进行唯一标识,可以将限定类术语加到对象类术语、特性类术语和表示类术语上,这些限定术语也许是从一个相关环境规定的结构设置中产生的。在(确立)命名约定的规则中(时),建议对限定术语的数量予以限定。例如,在数据元“传染病患者的婚姻状况”中,成分“传染病”是限定类术语。
3.4.1.2 命名约定规则 数据元名称应当是唯一的,并且以字母、汉字、数字式的字符串形式表示。数据元的命名应使用一定的逻辑结构和通用的术语。
(1)结构规则:完整的数据元名称=对象类术语+特性类术语+(表示类术语)+(限定类术语)。
(2)语义规则:1)数据元需要有一个且仅有一个对象类术语。2)数据元需要有一个且仅有一个特性类术语。特性类术语是任何一个数据元名称所必需的成分,在数据元概念可以完整、准确、无歧义表达的情况下,其他术语可以酌情简略。3)表示类术语是可选的。当表示类术语与特性类术语有重复或部分重复时,可从名称中将冗余词删除。4)限定类术语由专业领域给定。限定类术语是可选的。
(3)句法规则:1)对象类术语应处于名称的第一(最左)位置。2)限定类术语应位于被限定成分的前面,限定名称的顺序不应用于区别数据元名称。3)特性类术语应处于第二位置。4)表示类术语应处于最后位置。假如表示类术语中有任何字与特性类术语中的字重复,则删去冗余词。
(4)数据元英文名的词法规则:1)名词仅用单数形式,动词(若有的话)为现在时;2)名称的各个成分间和多个单词术语之间用空格分隔,不允许用特殊字符;3)名称中所有单词应组合在一起;4)允许使用缩写词,如首字母缩略词和大写首字母。
3.4.2 数据元属性
3.4.2.1 属性列表 WS/T303《卫生信息数据元标准化规则》共列举了5类22个基本属性。纵列“约束”是指该属性描述条目是“必选(M)”,还是“条件选(C)”,或者是“可选(O)”。见表3。
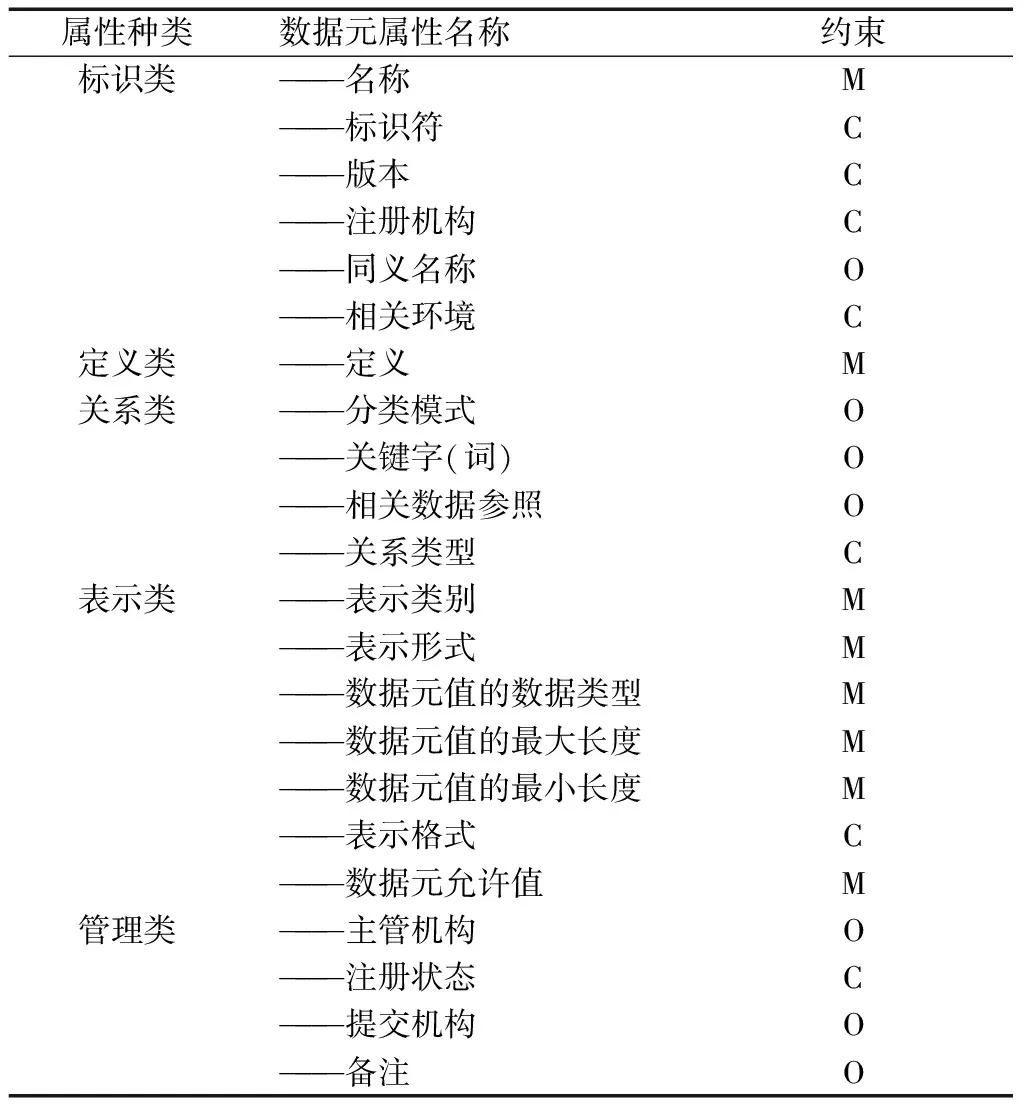
表3 WS/T303数据元属性
本技术规范在遵照卫生信息数据元基本属性的基础上结合实际需求和应用进行选择和扩展,确定的数据元属性见表4。
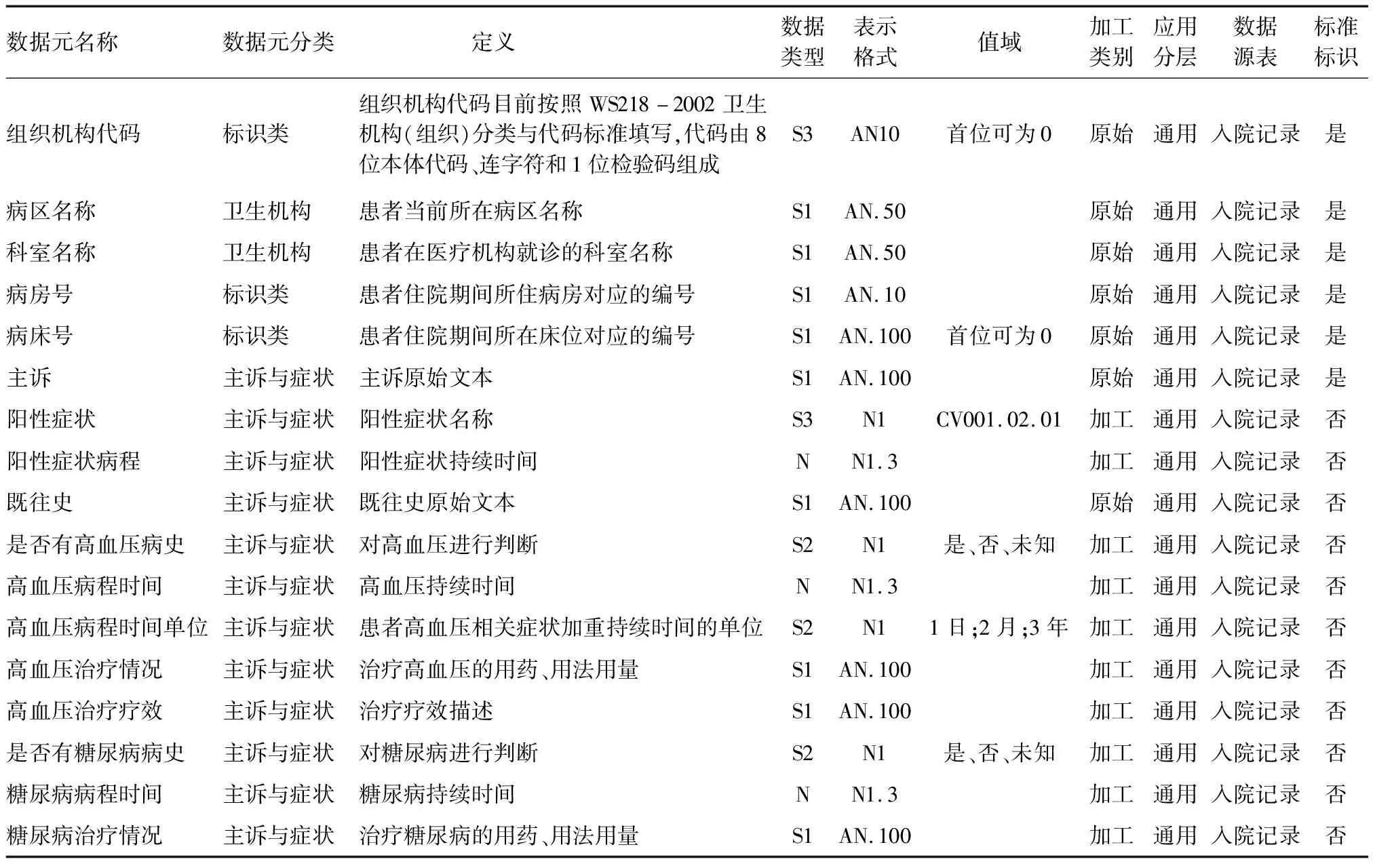
表4 数据元属性列表样例
(1)关系类:包括数据元分类。数据元分类是根据数据元的来源、组成、结构、应用、功能等共同特性,将数据元排列或划分成组的模式分类参照(参见下节描述)。
(2)表示类:包括数据元名称、数据类型、表示格式、值域(可允许的值,例如婚姻状况,值域为已婚、未婚、丧偶、离异、未知)。并根据构建过程需要增加加工类别(表示和区分数据元是出自信息系统常用命名还是根据学科需求提炼的自命名数据元)属性。
(3)定义类:包括定义,用于表达一个数据元的本质特性并使其区别于所有其他数据元的陈述。
(4)管理类:包括应用分层(通用层/专科层/专病层)、数据来源表(数据元所在信息系统内位置,即存储的表单名称)和标准标识(数据元是否是出自国标或行标)。
3.4.2.2 数据元分类 本技术规范参考了WS 363.l-2011《卫生信息数据元目录》[10]的分类,结合自身实际形成本标准的数据元类,对数据元分为12个大类(见表5)。本分类为1.0版,大类相对固定,后期可能主要对大类进行细分形成小类,并对其进行修改、完善或扩展。

表5 数据元分类目录
3.4.2.3 数据元属性编制要点
(1)根据需求设置:数据元的提取首先遵循卫生信息标准化文件和规则进行设置,数据元的设置最大程度与标准文件一致。因非结构化文档导致数据元不能满足实际需求时,依据编制规范可自定义数据元,即加工类别为“加工的字段”,例如现病史中阳性症状、每日吸烟量、发育是否正常等。
(2)分层管理:根据数据元的应用、来源及其专业属性,设置了通用层、专科层、专病层三个层级,对数据元的应用范围进行分级管理,便于快速识别通用数据元和学科特征数据元。
(3)可溯源:对数据元的来源路径进行备注,清楚地指向数据元所在信息系统的具体位置,方便后续的数据抽取、加工整理和标准化工作的开展。
3.5技术路线
构建急危重症数据集数据元的过程,根据院内真实病历数据,参考国家信息标准文件和文献,在电子病历基本数据集(53个部分)的基础上增加缺失护理部分数据集并加工整理急危重症特征数据元,结合临床专家的意见和建议,反复提取、修改而定。具体技术路线图见图2。
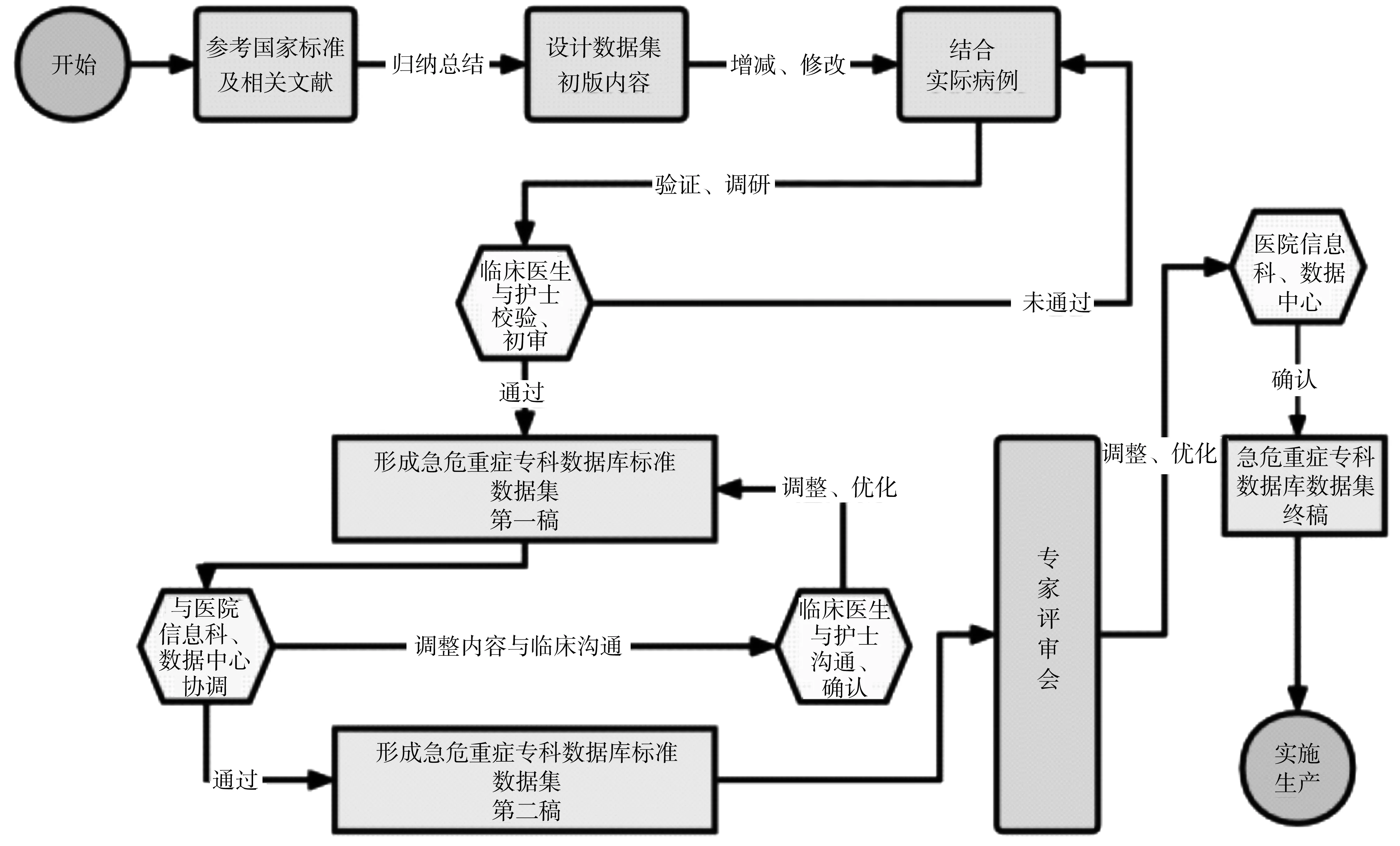
图2 急危重症数据集建设流程图
在数据集研制项目的基础上成立项目组,包括临床专家、护理专家、信息专家、科研专家等,具体负责数据集的调研、制作、校验等工作,并协调数据负责相关部门医院信息科、数据中心,召开专家评审会,形成急危重症专科数据集终稿。
3.6数据集编制和维护原则
3.6.1 以标制标原则 本技术规范构建的数据集均在国家卫生信息标准规定的数据集基础上进行扩展,并严格遵照其相关规范进行创建和维护,增加学科研究需要的特色数据集和数据元,因此本质上本技术规范形成的数据集与现行的卫生信息标准形式上是一致的。
3.6.2 以需求目标为导向原则 本技术规范收录并维护的数据集是为满足急危重症学科开展研究所需的数据集成、数据应用分析和数据质量控制等数据需求构建的是核心业务数据集,并非卫生信息系统中所有数据集都会收录和维护。集中体现学科特性,而信息系统中的过程数据、操作类型数据、其他不相关学科的特征数据等,应根据应用需求目标选择性收录。
3.6.3 开放兼容原则 本技术规范坚持以国家医药卫生事业、急危重症发展和科学研究为导向,以国家卫生信息标准文件为基础,制定开放兼容的数据集,以适应多中心的数据来源接入,兼容不同医院的不同信息系统,适配多种数据格式。并可不断扩充新的医学数据集和数据元,满足不断发展的临床医学技术的需要。
3.7研究结果的评价
在数据集编制过程中的各个阶段项目组会组织专家进行研讨,以保证数据集的建设思路、建设方法和建设结果符合既定要求。由专家集中审核、讨论,保证数据质量,达到应用需求标准。具体包括以下三种形式:
3.7.1 专家咨询会 为保证研究思路和研究方法的正确性,在研究初期组织专家咨询会,集中收集专家的需求、意见和建议。立项开题时,邀请相关专家,评估编制规范和技术路线。
3.7.2 专题讨论 在研制过程中,针对阶段性成果和过程中的问题,邀请相关专家审核是否符合设计思路,并就相关问题进行研讨,制定解决方案和规范。
3.7.3 专家评审 在项目收尾阶段,请专家全方位进行评估,包括建设标准的参考依据是否全面;数据集总体建设的方法;数据集内容建设是否全面,给出补充和修订建议。在此基础上修改完成,形成最终使用版本的数据集。
4 小结
急危重症数据集是应用于急诊医学学科领域的健康医疗数据的数据结构设计,是便于后续进行数据集成和电子病历的数据挖掘,以满足基于健康医疗数据的科学研究和临床应用需求,具有明显的学科特色。本技术规范是基于首都医科大学国家健康医疗大数据研究院急危重症大数据临床研究中心相关项目建设经验的实践成果,参照卫生信息行业标准规范,根据实际需要设计、编写,并组织专家论证保证质量。本数据集基本覆盖急危重症研究需要的数据范围,构建方法和内容符合行业标准规范要求,基本满足后续数据集成形成科研数据库的实际应用需要。信息标准化是一项长期持续的工作,还需要在实践中进一步改进、完善,并需要动态管理和修订。因此本技术规范希望建立的是一套构建专科专病数据集的技术方法和实现规范,供有需要的单位或个人参考和使用。
开展真实世界研究依赖于高质量的健康医疗数据,而高质量的健康医疗数据需要有科学、专业、可靠的数据目录和规范来支撑,本技术规范构建的数据集就是为了将分散、杂乱、非结构化、非标准化的数据,转化为集中、有序、连贯、标准化的可高效利用的数据。数据目录分类和标准化的数据元犹如大数据的核心脉络,按此脉络形成的数据集可以在后续的数据应用各环节起关键作用,反之,没有标准化的数据集在数据建设和应用中会寸步难行。因此,数据集建设是开展研究型数据库建设和科研的基础和核心,而这些思路和方法是相通的,我们认为不限于急诊医学,其他学科也适用。
专家组名单(排名不分先后):戴忠(联仁健康医疗大数据科技股份有限公司);郭树彬(首都医科大学附属北京朝阳医院);梅雪(首都医科大学附属北京朝阳医院);刘颖青(首都医科大学附属北京朝阳医院);高珍珍(首都医科大学附属北京朝阳医院);韦力(首都医科大学附属北京朝阳医院);腾飞(首都医科大学附属北京朝阳医院);王军宇(首都医科大学附属北京朝阳医院);何新华(首都医科大学附属北京朝阳医院);马剡芳(首都医科大学附属北京世纪坛医院);王真(首都医科大学附属北京世纪坛医院);曹秋梅(首都医科大学附属北京同仁医院);郭伟(首都医科大学附属北京天坛医院);赵丽(首都医科大学附属复兴医院);王荃(首都医科大学附属北京儿童医院);王晶(首都医科大学宣武医院)王国兴(首都医科大学附属北京友谊医院);米玉红(首都医科大学附属北京安贞医院);单晶(首都医科大学附属北京佑安医院);张静(首都医科大学附属北京胸科医院);常宇飞(首都医科大学附属北京地坛医院);李凤杰(首都医科大学附属北京潞河医院);姚卫海(北京中医医院);乔瑞省(北京康复医院);何威(中国康复研究中心);张洪波(中日友好医院);姚丹林(首都医科大学丰台教学医院);王学军(首都医科大学电力教学医院);张红(首都医科大学石景山教学医院);李颖(首都医科大学大兴教学医院);张爱新(首都医科大学平谷教学医院);赵炳朕(首都医科大学良乡教学医院);殷文朋(首都医科大学怀柔教学医院);赵树凯(首都医科大学昌平教学医院);胡振春(首都医科大学延庆教学医院);李筱姝(首都医科大学门头沟教学医院);张海燕(首都医科大学顺义教学医院);张文中(北京急救中心);王勇(北京急救中心);张新超(北京医院);马青变(北京大学第三医院);熊辉(北京大学第一医院);朱继红(北京大学人民医院);朱华栋(北京协和医院);陈玉国(山东大学齐鲁医院);徐峰(山东大学齐鲁医院);朱长举(郑州大学第一附属医院);韩小彤(湖南省人民医院);田英平(河北医科大学第二医院);柴艳芬(天津医科大学总医院);赵剡(武汉大学中南医院);杨立山(宁夏医科大学总医院);吕传柱(四川省医学科学院·四川省人民医院);曹钰(四川大学华西医院);陈旭岩(清华大学附属北京清华长庚医院);蒋龙元(中山大学孙逸仙纪念医院);李培武(兰州大学第二医院);李小刚(中南大学湘雅医院);张劲农(华中科技大学同济医学院附属协和医院);赵敏(中国医科大学附属盛京医院);陈凤英(内蒙古医科大学第一附属医院);董士民(河北医科大学第三医院);封启明(上海市第六人民医院);洪玉才(浙江大学医学院附属邵逸夫医院);张茂(浙江大学医学院附属第二医院);黄亮(南昌大学第一附属医院);康健(大连医科大学附属第一医院);李超乾(广西医科大学附属第一医院);马渝(重庆市急救医疗中心);马岳峰(浙江大学医学院附属第二医院);毛恩强(上海交通大学医学院附属瑞金医院);潘曙明(上海交通大学医学院附属新华医院);秦历杰(河南省人民医院);商德亚(山东省立医院);史继学(山东第一医科大学附属第二医院);许铁(徐州医科大学附属医院);闫新明(山西白求恩医院);穆叶赛(新疆维吾尔自治区人民医院);杨正平(青海省人民医院);尹文(空军军医大学西京医院);李桂云(贵阳市第二人民医院);张泓(安徽医科大学第一附属医院);陈锋(福建省立医院);邢吉红(吉林大学第一医院);邓颖(哈尔滨医科大学附属第二医院);李艳美(佳木斯大学附属第一医院);钱传云(昆明医科大学第一附属医院)
猜你喜欢
祝您健康(2022年11期)2022-11-06
现代仪器与医疗(2022年4期)2022-10-08
祝您健康(2022年9期)2022-09-07
现代仪器与医疗(2022年2期)2022-08-11
健康体检与管理(2021年10期)2021-01-03
英美文学研究论丛(2017年2期)2017-03-01
中国中医药图书情报(2017年1期)2017-02-28
少年文艺·我爱写作文(2016年9期)2016-05-14
