
依托大数据构建基于地域特点的就业推荐模型
——以广东省民办院校为例
2022-06-14 02:02刘丽娜
太原城市职业技术学院学报 2022年5期
■刘丽娜
(广州工商学院工学院,广东 广州 510850)
随着我国教育政策的普及和发展,高校扩招的热潮逐年攀升,特别是珠三角等发展较快的地区。广东近五年来毕业生实际参加就业人数从2016年的53.5万人发展到2020年的60.3万人[1-2],就业竞争愈加激烈。此外,产业升级和网络的快速发展促使招聘形式和就业手段更加多样化,但随之暴露出来的问题也更多。一方面由于高校毕业生初次进入社会对自身认识评估不足,在用人单位和就业方向的选择上存在诸多困惑[3],部分高校毕业生在连连碰壁之后迫于生计选择了不适合自己的职业,后续“闪辞”的情况也屡屡发生,既浪费双方的时间和前期投入又消耗了社会资源;另一方面则是用人单位种类杂多,少部分用人单位缺少规范甚至违法,让高校毕业生难以分辨抉择。另外,就业面试的选择有线上和线下之分,加之近年疫情影响,进入后疫情时代,增加了就业成本和困难。因此,本文以广东省民办院校为研究对象,提出依托大数据分析技术分析往届毕业生信息数据构建面向广东民办院校毕业生的就业数据库,探索精准指导高校毕业生就业的模式,以期降低就业成本提高就业质量。
一、相关研究介绍
越来越多的高校毕业生陷入就业困境引起了很多专家学者对该课题的研究兴趣,结合当前高度发达的网络催生了许多就业推荐体系模型。沈士强[4]根据学生各方面的能力测评构建基于AHP-Fuzzy的评估体系,对大学生的就业能力进行综合评价排序,然后推荐给用人单位,该体系可以比较全面地评价大学生的就业素质,为用人单位招聘提供有益参考,但并未对用人单位的把控进行相关说明。李恒凯等[5]构建了一个结合聚类算法、多元回归和关键字且集高校、用人单位和毕业生于一体的开放性双向推荐平台,该平台能通过关键字算法向用人单位推荐应聘人员同时也可以向高校毕业生推荐用人单位,但同样未对用人单位进行一定的筛选把控。杨明等[6]提出构建一种基于Apriori算法结合高校毕业生兴趣特征的就业推荐模型,该模型可以有效地提高学生的就业满意度,但是并未说明企业数据的由来。褚蓉等[7]认为应该推进就业信息化建设,构建精准匹配的就业推荐平台。隋占丽等[8]采用协同过滤算法结合高校毕业生的兴趣特征实现与用人单位双向匹配的推荐功能,该模型可以有效提高高校毕业生的就业质量和企业的招聘效率,但该模型亦未说明企业数据的来源。
因此,基于学生对自身定位及对用人单位的认识不足且用人单位信息来源可靠性难以得到有效的保证,本文提出以往届毕业生的就业信息为研究对象,根据高校对往届毕业生的就业单位跟踪评估构建可靠的用人单位数据库,利用关联规则算法预测适合高校毕业生的用人单位,同时向用人单位推荐符合其要求特征的高校毕业生,形成就业信息可靠且可双向智能推荐的就业模型。
二、构建高校毕业生就业推荐模型
(一)大数据分析技术在高校毕业生就业数据中的作用
大数据分析技术旨在从海量数据中发现共性规律并应用该规律预测当前或未来可能发生的情况。目前大数据分析技术主要有频繁项集生成、频繁模式增长和垂直格式等[9]。频繁项集生成通过计算候选频繁项集的支持度产生强规则[10];频繁模式增长只扫描一次扫描数据库即可构建FP树找出频繁项集[11];而垂直格式则是对数据库矩阵进行行列转置后再不断迭代裁剪候选频繁项集得到频繁项集直至候选集为空[12]。
随着高校毕业生规模的不断扩大,就业指导在高校毕业生就业中的作用越来越重要。然而,传统的高校毕业生就业指导依旧停留在就业指导课程中的职业生涯规划、大学生创新创业项目、校园讲座或校园招聘会宣传等,难以为高校毕业生提供个性化或实际意义上有效的就业指导。
自我国全面推进信息化以来,各高校陆续实现信息化办公,因此高校往届及应届毕业生的教务学籍数据、学生成绩数据、学生选课数据、学生图书借阅数据和学生就业信息数据基本齐全,且随着时间与空间的推移,横向与纵向的数据合并,数据量将越来越大。
因此,面对如此多的高校学生数据,如何利用大数据分析技术分析往届毕业生的海量数据,从纷杂的数据中整理分析提取出共性规律,为应届毕业生提供用人单位和就业岗位预测,甚至根据薪酬区间或兴趣测评实现具有个性化或具体的推荐具有重要意义和作用。
(二)构建就业推荐模型
近年来,随着产业结构的调整,珠三角经济不断发展,密集型产业需要更多的专业人才,而广东省高校数量及毕业生人数占比也一直居高不下,如此供求双方需求量较大较频繁的情况但由于种种原因大部分用人单位及高校毕业生并不能在短时间内找到最适合的目标。高校在长期发展中毕业生输出稳定,对毕业生的就业情况跟踪基本可以确定就业单位的可靠性,且广东高校毕业生的就业地区大部分集中在珠三角地区,因此为稳定的就业推荐提供了可能性。为缩短高校毕业生就业签约时间、提高就业质量,本文采用大数据分析技术中的关联规则Apriori算法分析广东省其中两所高校2014—2019届毕业生的就业数据及其在校期间的数据,包括图书信息、选课信息、专业信息、学生成绩、用人单位、就业岗位和薪酬区间等形成就业数据库。构建就业推荐模型的具体实施步骤如下。
首先,对所收集到的往届毕业生信息数据进行融合,融合后共得到34个属性约7万条记录,对一些信息不全的记录例如个别学生休学退学转学或缺少就业信息的记录进行删除清洗,再抽取关键字对不适合分析的数据加以概化[13],如成绩跨度太大不适合分析则按区间分为不及格、及格、中等、良好和优秀五个等级得到适合分析的数据集。
其次,利用SPSS Modeler数据分析平台构建Apriori模型,用Apriori分析学生各个信息之间的关联关系,在其他属性作为前导入项的条件下分别取用人单位、就业岗位或用人单位所属区域作为输出后项的概率并设置最小支持度和置信度[9]分析处理后的数据集得到不同支持度与置信度的频繁项集。
最后,从频繁项集中筛选出强规则,根据不同的规则匹配应届毕业生当前的数据从而预测用人单位或就业岗位或就业方向等,根据预测结果指导应届毕业生进行相应方向的选择或投递简历至推荐到的用人单位或岗位,从而提高应届毕业生的就业签约速度,为其找到对口的岗位或方向,从而提高就业率及就业质量。
(三)利用Apriori模型分析就业数据
Apriori是数据挖掘中的关联规则算法,该算法通过分析记录中属性重复的概率,首先以最小支持度判定各个属性是否大于或等于最小支持度,符合条件则加入第一候选频繁项集,第一候选频繁项集进行自身连接后再对比最小支持度判定是否加入第二候选频繁项集,然后重复自身连接与最小支持度对比判定直至候选频繁项集为空,最终得到频繁项集,最后通过最小置信度筛选出强规则。本文试图利用强规则预测用人单位和毕业生之间的就业信息实现快速精准就业从而提高就业率及就业质量。
SPSSModeler是一款专门用于挖掘海量数据或数据建模将数据挖掘算法贯穿于业务流全程的可视化数据分析平台。本文利用SPSSModeler构建的Apriori数据流模型如图1所示,源数据从Excel文件中读取,然后进入类型确定并控制字段元数据以读取各个属性字段的区间值后再将数据导入到Apriori模型,该模型中设置最低支持度为10%,最低置信度为10%,运行流之后生成挖掘模型。

图1 Apriori挖掘模型
通过筛选挖掘结果后截取部分规则如附表1所示,由附表1可以看出,规则(平均成绩=优→工作岗位=行政事务人员)的支持度置信度几乎都达到25%,说明一般成绩比较好的学生找工作会倾向于比较稳定的行政事务岗位。规则(专业=建筑技术→工作岗位=技术人员)和规则(专业=会计→工作岗位=技术人员)的支持度占百分之十几,置信度却高达近40%,说明建筑技术和会计专业的学生专业性较强,一般这些专业的学生比较适合应聘相关专业的技术岗位。规则(平均成绩=优→就业速度=高)、规则(是否学生干部=是,平均成绩=优→就业速度=高)和规则(平均成绩=优,图书浏览量=高→就业速度=高)的支持度约为18%,置信度也几乎达到50%,可以看出一般学习成绩比较好、学习比较认真并且有一定职务经验的学生对自己的职业规划都比较明确,在找工作上比较积极。而规则(专业=建筑技术→工作单位=广东**建筑工程有限公司)的支持度和置信度约为17%,表明该公司与广东多所开设建筑专业的民办院校均有长期合作,并且对这些毕业生的表现都较为满意,是高校建筑专业毕业生的稳定输出点。

附表1 挖掘结果(部分)
三、实施应用效果
本研究选择广东省其中两所民办高校2020届和2021届的毕业生作为实践对象,主要通过三方面指导应届毕业生的就业。一是学生干部成绩优秀就业速度快则可以细分学生干部职责让更多的学生有机会担任学生干部从而加速就业签约速度;二是专业性较强的毕业生适合推荐至相应的专业技术岗位,通过该规则,学校可以有指向性地为他们推荐多一些专业性较强的用人单位;三是直接推荐学生至规则指导的后项用人单位应聘,但由于用人单位较多,人员就业较分散,缺少更多就业数据的支持,因此需调小支持度,以达到更多规则后项为单位的规则,由此推荐更多的学生至用人单位应聘。
对比2018—2021届毕业生同一时间点的就业率、用人单位对毕业生的满意度、毕业生对用人单位的满意度、毕业生对学院就业指导服务的满意度和转岗比率,结果如图2所示。
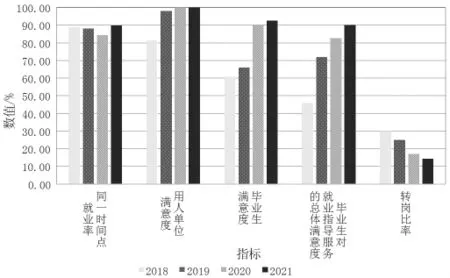
图2 2018—2021届就业质量对比
由图2可以看出,同一时间点的就业率中,2018和2019届的往届毕业生就业率基本持平,2020和2021届则以挖掘规则指导学生就业,因为疫情影响就业率有所下降,但下降幅度较小,而2021年虽然也受疫情影响但就业率却比2019年有所提高。同时,通过对比可以看出,用人单位对毕业生的满意度也在2020和2021届达到百分之百,特别是毕业生对用人单位的满意度有明显向好的改变,毕业生对学校就业指导服务的总体满意度也逐年提高。另外,从转岗率可以看出,毕业生对所在单位满意度提高,因此辞职转岗率也在下降。
四、结论及展望
本文针对高校毕业生就业难题和广东省高校与企业密集的地域特点提出以广东省民办院校为研究对象构建毕业生就业推荐模型,依托SPSSModeler平台中的Apriori模型分析往届毕业生的信息数据,提取其中有益的数据规律,然后将数据规律应用于应届毕业生的就业指导工作中,最终通过实践效果验证了该就业推荐模型能有效提高高校毕业生的就业率和就业质量。
虽然本研究所构建的高校毕业生就业推荐模型取得了一定的成效,但SPSSModeler中Apriori分析模型在数据量不断增加时执行效率急剧下降,后期随着高校毕业生的规模不断扩大需进一步优化。同时,由于往届毕业生数据量支撑度不足且就业信息相对分散导致规则支持度普遍偏低,但随着就业数据库规模的不断扩大,规则的可靠性将进一步提高。
猜你喜欢
工会博览(2023年1期)2023-02-11
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
反歧视评论(2021年0期)2021-03-08
机电产品开发与创新(2020年2期)2020-05-07
今日农业(2019年11期)2019-08-15
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
大连理工大学学报(2017年5期)2017-09-20
就业与保障(2015年9期)2015-04-17
