
基于多尺度上下文信息的遮挡行人检测
2022-06-09 11:58赵世阳王晓峰
计算机工程与应用 2022年11期
赵世阳,王晓峰
上海海事大学 信息工程学院,上海 201306
行人检测是计算机视觉中的一个经典问题,在自动驾驶汽车、智能监控、机器人等应用中发挥着重要作用,引起了越来越多的关注[1]。大多数早期的行人检测方法都是基于手工特征构建的,由于当时缺乏有效的图像表示,人们只能选择设计复杂的特征表示,并且需要各种加速技术用尽有限的计算资源。比较典型的方法有梯度特征直方图[2](histogram of oriented gradients,HOG)和形变部件模型[3](deformable part model,DPM),但传统基于手工设计的特征易受外部条件的影响,并且所提取特征的鲁棒性较弱,所以检测精度不高。
近年来随着深度学习技术的不断发展,由于深度卷积神经网络(convolutional neural networks,CNN)能够学习图像的鲁棒且高级的特征表示,出现了大量基于深度神经网络的行人检测方法。通常,基于CNN的行人检测器主要分为两类:第一类称为二阶段检测器,具有代表性的方法如R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]等,这类算法首先会生成一系列的候选区域用来作为样本,随后再通过卷积层来进行样本的分类,从而检测出目标的位置;第二类称为一阶段检测器,常见的算法有YOLO[7]、SSD[8]等,这类算法不需要产生候选区域,而是直接将目标定位的问题转化为回归问题来进行处理。最近,受到关键点检测的启发,CornerNet[9]提出了一种基于关键点检测的anchor-free检测方法,在一些研究中,anchor-free思想被应用到行人检测中,并为行人检测开辟了新的视野。与传统的基于anchor-base的检测方法(如RCNN和SSD)相比,新兴的anchor-free检测方法(如CornerNet)在设计上灵活,取得了更有前景的结果。
通常情况下,现实场景中的行人检测总是会受到遮挡带来的影响,从而导致行人的可见率低,尺度小,难以检测。因此,如何有效地解决行人遮挡是行人检测中的一个重要问题。对此,为提高行人遮挡检测准确率,一些针对遮挡设计的模型也被提了出来。解决遮挡最常见的策略是基于零件模型的方法,DeepParts[10]构建了一系列与特定遮挡模式相对应的零件检测器,但这种基于零件模型的方法通常很耗时并且难以训练。Bi-Box[11]使用两个不同的分支:可见部分预测分支和行人整体预测分支,两个分支相互补充,根据行人的可见部分来进行遮挡检测。Repulsion Loss[12]引入了一种全新的回归损失函数,用来使生成的预测框尽量接近指定目标框,远离周围其他的目标框。FasterRCNN+ATT-vbb[13]发现不同特征通道与不同的身体部位之间的关系,使用通道注意力机制来处理不同的遮挡模式。在各种行人检测方法中,最近由Liu等人[14]提出的基于中心点和尺度预测的模型(center and scale prediction,CSP)是一种有前途的anchor-free行人检测器,它可以通过预测行人的中心和尺度来进行检测。尽管CSP检测器解决了行人检测中各种规模的挑战,但它并未明确解决行人遮挡问题,为了解决这个问题,在CSP算法的基础上使用了一种多尺度上下文模块和注意力模块,用来改善CSP检测器。本文的主要贡献包括:
(1)设计了一种多尺度上下文提取模块,级联不同的扩张卷积来增大感受野,使用密集连接实现多尺度特征共享,提取上下文信息。
(2)引入了通道注意力模块来进行多尺度特征融合的调整,增强特征的可分辨性和鲁棒性。
(3)在Caltech数据集上取得了41.73%的MR-2。
1 相关工作
1.1 CSP行人检测器
CSP是由Liu等人提出,首次将anchor-free的方法应用到行人检测领域,取得了很好的检测结果。一般来说,基于anchor-base的模型在进行预测之前会先设定好一组anchor,然后在推理过程中会在特征图上使这些anchor进行滑动来提取n个候选框,最后再做进一步的分类和回归。给定特征图Φdet和锚框Β,检测可以表示为:
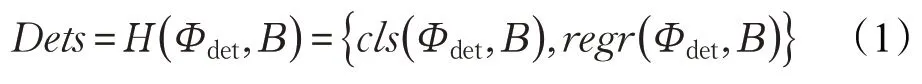
然而这些anchor-base的方法都不可避免地需要针对特定的数据集设计甚至优化滑窗或者anchor超参数,从而限制了检测的精度和通用性。和anchor-base模型不同,CSP认为行人检测中行人的中心点和尺度都是一种高级的语义特征,行人检测完全可以转化为这些语义特征的检测。在anchor-free的检测方法中,只需要Φdet这一个参数,检测任务可以表示为:

CSP模型的网络结构主要包括两个部分:特征提取部分和检测头部分。在特征提取阶段,使用ResNet50作为主干网络来提取不同级别的特征,将ResNet50的第3、4、5阶段的特征图分别进行反卷积将尺寸提升到跟2层特征图相同的大小,并在通道维度上进行拼接生成最终用于检测的特征图。在检测头部分,在最终的特征图上使用3×3卷积将其通道缩小到256,并且通过两个1×1卷积分别来生成中心点的特征热图和尺度预测图,并且额外增加了一个1×1卷积来进行偏移量的预测,用来调整中心点的位置。并根据中心点和尺度进行检测框的生成。
基于CSP检测器的目标损失函数表示为L,由三个损失函数加权相加组成:
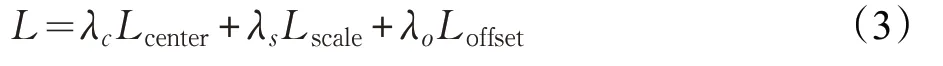
其中λc、λs、λo分别代表中心点分类、尺度回归、偏移量回归的权重。在实验中分别设为0.01、1和0.1。
中心点分类损失函数定义为Lcenter,为平衡训练中正负样本的数量,使用focal loss的思想进行设计:

其中,s k、t k分别代表网络的预测值和真实值。
偏移损失函数由SmoothL1表示,与公式(5)类似。
1.2 上下文信息
在现实世界当中,一个目标不可能是单独存在的,在它周围一定存在着各种各样的对象,而这个目标则会受到周围这些对象的影响,这些跟目标有着或多或少关系的对象信息,就是通常所说的上下文信息。当大脑进行目标识别时,上下文信息可以帮助人们利用背景与目标之间的关联进行目标的判断,因此,即使在周围环境特别复杂和多变的情况下,依然可以准确地识别和定位多个目标。上下文信息一般分为三类,分别是语义上下文信息、空间上下文信息和尺度上下文信息,有效地运用上下文信息可以提高目标识别的准确度。
近年来,各种类型的上下文信息被应用到计算机视觉各个领域:如目标检测、语义分割、人体关键点估计等,文献[15-16]指出背景信息也就是所谓的上下文信息对检测遮挡的物体至关重要。例如:一个预测框的背景信息为斑马线,那么该预测框检测到行人的概率相对比较大,如果检测框的背景为墙壁或者天空,那很大可能就不是行人。通过上下文信息,往往可以利用行人的可见部分以及周围的背景信息推测出行人的整体部分,进而进行检测。由于被遮挡的人群中包含各种尺度的行人实例,越是遮挡严重、尺寸较小的行人,需要的上下文信息就越多,而尺寸较大、比较分散的行人需要的上下文信息就比较少。因此,如何提取多尺度的上下文信息是解决遮挡的一个重要问题。Inception[17]运用多个分支结构,多个不同大小的卷积核来捕获多尺度信息。ASPP[18]引入扩张卷积,利用不同扩张率的3×3卷积来提取多尺度特征。而RFB Net[19]则在两种方式的基础上进行改进,堆叠大小和扩张率都不同的卷积核来提高感受野的大小,捕获更多的上下文信息。受上述方法启发,本文结合上下文以及多尺度信息,将扩张卷积以及密集连接结合在一起以增强特征的表述,来解决行人遮挡问题。
1.3 注意力机制
在认知科学中,人们对所观察的事物,一般而言并不会去关注事物的全部信息,而是选择性地关注一些比较重要的信息而忽略其他可见的信息,这种方式就被称为注意力机制。人类的视觉注意机制启发了计算机视觉中注意力机制的发展。如今,注意力机制的思想被广泛地应用到许多计算机视觉任务之中,比如图像分类、语义分割、目标检测等。基于注意力机制的模型也是取得了良好的效果。SENet[20]通过模拟通道之间的相关性,对特征图实现通道重构。SKNet[21]受到SENet和Inception的启发,将SENet和Inception的多分支卷积层相结合,从而进行了改进。此外,CBAM[22]提出了通道注意力机制和空间注意力机制相结合的双重注意力结构。注意力机制会在提取特征时引导网络关注有用的信息,抑制没用的信息,从而让网络认识到什么样的特征需要关注,哪里的特征需要关注。受到上述方法的启发,本文在网络特征融合阶段引入通道注意力机制,分配给特征通道不同的权重,对融合的特征图进行自适应的调整。
2 模型设计
2.1 总体网络结构
模型的整体框架如图1所示。骨干网络为ResNet50,与CSP算法相似,检测头部分主要包括三个1×1卷积层,分别用来预测中心位置、尺度信息和偏移量。ResNet50分为五个阶段,将2到5个阶段的输出特征图分别定义为φ2、φ3、φ4、φ5。考虑到基于中心点检测需要更高分辨率的特征图,因此输入的图片分别进行倍数为4、8、16、16的下采样用来提高分辨率。其中在特征融合阶段,引入了多尺度上下文提取模块(multi-scale context block,MCB)来进行周围上下文信息的提取和融合。首先把输出的特征图φ3、φ4、φ5通过归一化和反卷积后将分辨率提升到和φ2相同大小,然后将φ2、φ3、φ4、φ5分别输入到上下文提取模块进行上下文信息提取,把提取的特征图进行拼接后送入通道注意力调节模块(channel attention block,CA)进行通道权重调整,生成特征图φconc,最后将特征图φconc送到检测头进行检测。接下来将详细介绍上下文和通道注意力两个模块的构造。
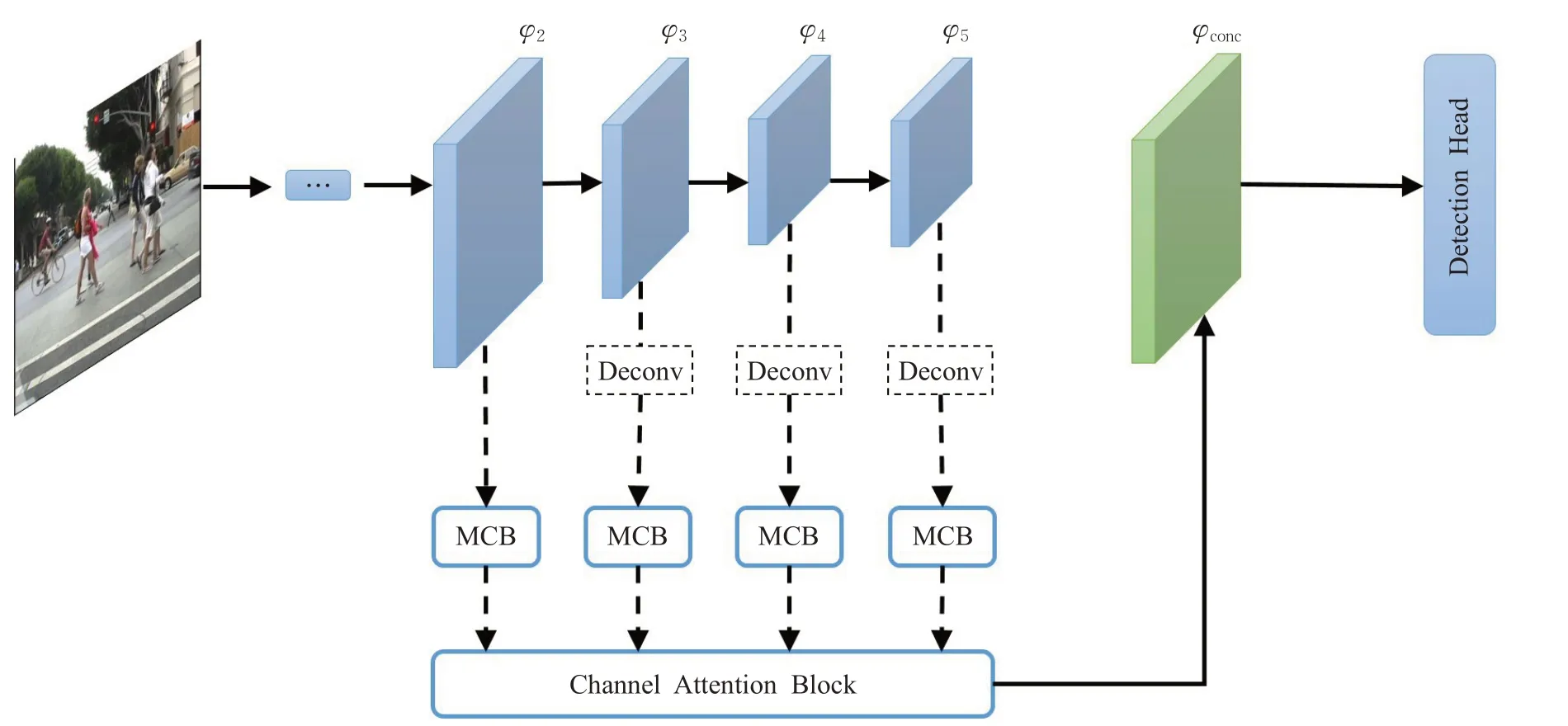
图1 模型总体网络结构Fig.1 Overall architecture of model
2.2 多尺度上下文模块
为了增强感受野的大小,提取不同尺度的上下文信息用来加强遮挡检测,受到ASPP和RFBNet模型的启发,本文引入扩张卷积来进行上下文信息的提取,但是由于分割和检测任务的不同,可能会带来两个问题,一是过大的扩张率可能会容易引入较多的背景噪音,而较小的扩张率则无法提供足够大的感受野。二是采用并行设计的结构,每个分支各自独立,在前馈过程中不会共享任何信息,而且相对于串行设计来说,还会影响模型的效率。
为了解决上述存在的问题,本文采用级联连接的方法来进行扩张卷积,采用较小的扩张率,并且利用DenseNet[23]的思想,在扩张卷积层之间引入跳跃连接来使之共享不同尺度的特征信息。相对于并行设计的结构,使用级联方式堆叠的卷积块可以保持更大的感受野。举例来说,扩张卷积可以增加卷积核的感受野,一个扩张率为r,卷积核大小为k的感受野为RF=(r-1)×(k-1)+k,因此对于扩张率分别为3、5、7的扩张卷积,基于并行设计的感受野大小为max{k(3),k(5),k(7)}=15,而基于级联方式的感受野大小为sum{k(3),k(5),k(7)}-3=30,很明显,级联连接可以在保持效率的同时捕获更大的感受野,在更大范围内生成更多尺度的上下文信息。
MCB的详细结构如图2所示,一共有三个卷积块,每一卷积块的扩张率逐渐增加,分别为3、5、7,并且在卷积块之间采用密集连接。每个卷积块都由一个1×1卷积和扩张率为r的3×3卷积组成,其中1×1卷积也就是常见的bottleneck结构主要是用来降低计算量,由于密集连接采用的是通道连接(即图中所示的C)而不是相加,所以通道数会飞速上升,故采用1×1卷积来进行特征通道的降维,之后再接扩张率为r的3×3卷积用来扩大感受野,提取上下文信息。每一个卷积块的输入都是前面所有卷积块的输出,每一个卷积块都会与前面所有卷积块的输出在通道维度上做一个连接,连接来自不同层的特征图,提高特征的可重用率。另外,为了保持初始输入的粗粒度信息,使用全局平均池化和1×1卷积对全局特征进行提取,并经过上采样操作与三个卷积块的输出特征图进行连接生成最终的特征图。
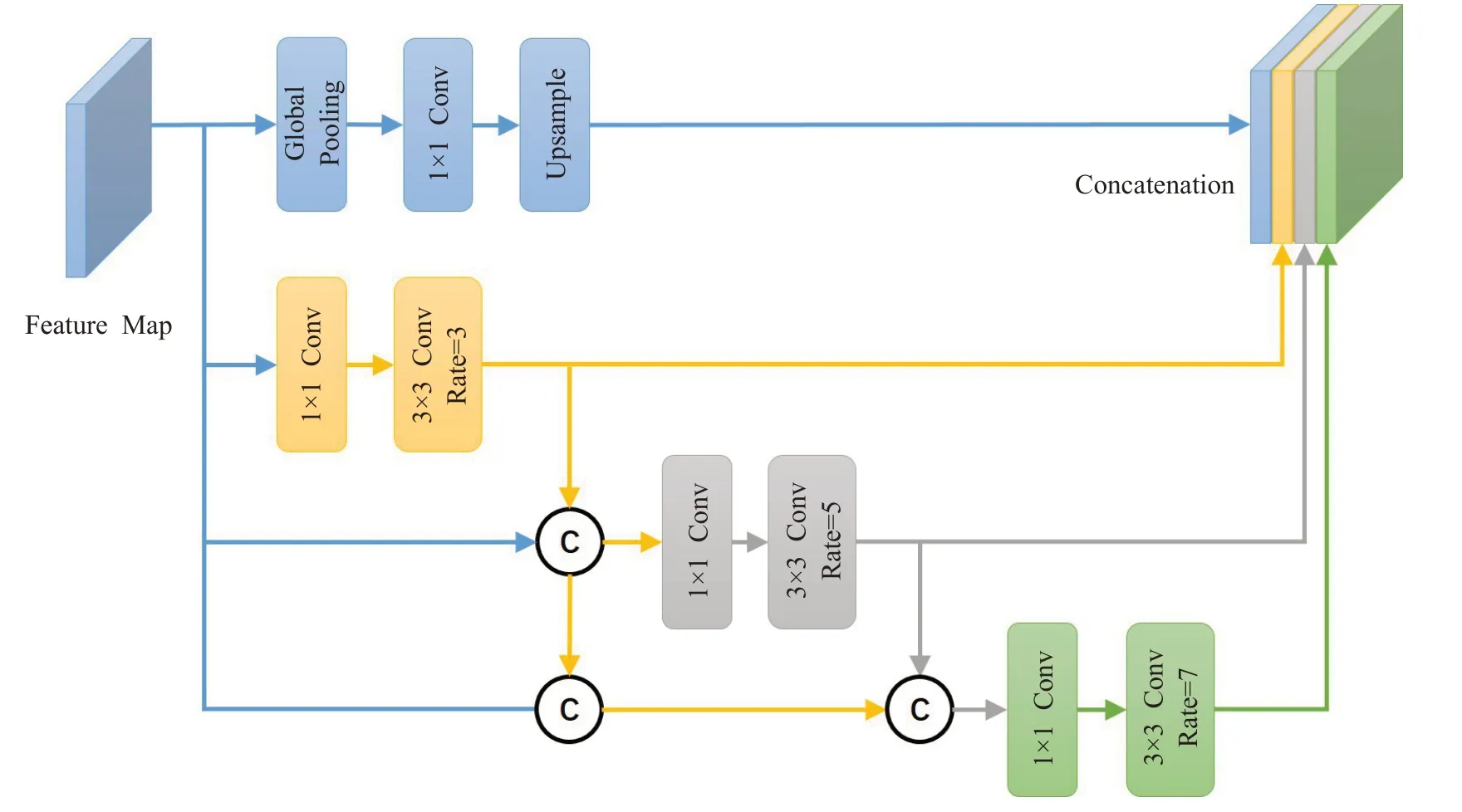
图2 多尺度上下文模块Fig.2 Multi-scale context block
2.3 通道注意力模块
尽管上下文提取模块包含丰富的上下文信息,但并非所有的信息都有助于提升行人检测的性能,可能会由于冗余信息的误导而使准确率降低。因此,为了消除冗余信息的负面影响并且进一步增强特征的表示能力,设计了一种注意力引导模块。对ResNet50每个阶段提取的特征图进行融合时,由于每个特征图的尺度不同,并且每个特征通道的重要性也不同,因此网络在进行预测时,对每个特征通道上信息的关注度也应该不同。为了能够让检测器在检测不同行人时能够自适应地为每个特征通道分配不同的权值,进而提高有用信息的关注度,受到SENet中通道注意力模块的启发,本文将通道注意力机制与多尺度特征融合结合使用,通过通道注意力为融合的特征图进行自适应的加权调整。该模块的网络结构如图3所示。具体而言,该通道注意力模块主要包括两个操作,Squeeze和Excitation。其中,Squeeze部分主要是为了获取每个通道特征图的全局信息,生成一个特征向量。这一步通过使用全局平均池化(global average pooling,GAP)来实现。设原始特征为F={f1,f2,…,f c},其中f c代表第c个通道的像素值,那么首先GAP可以表示为:
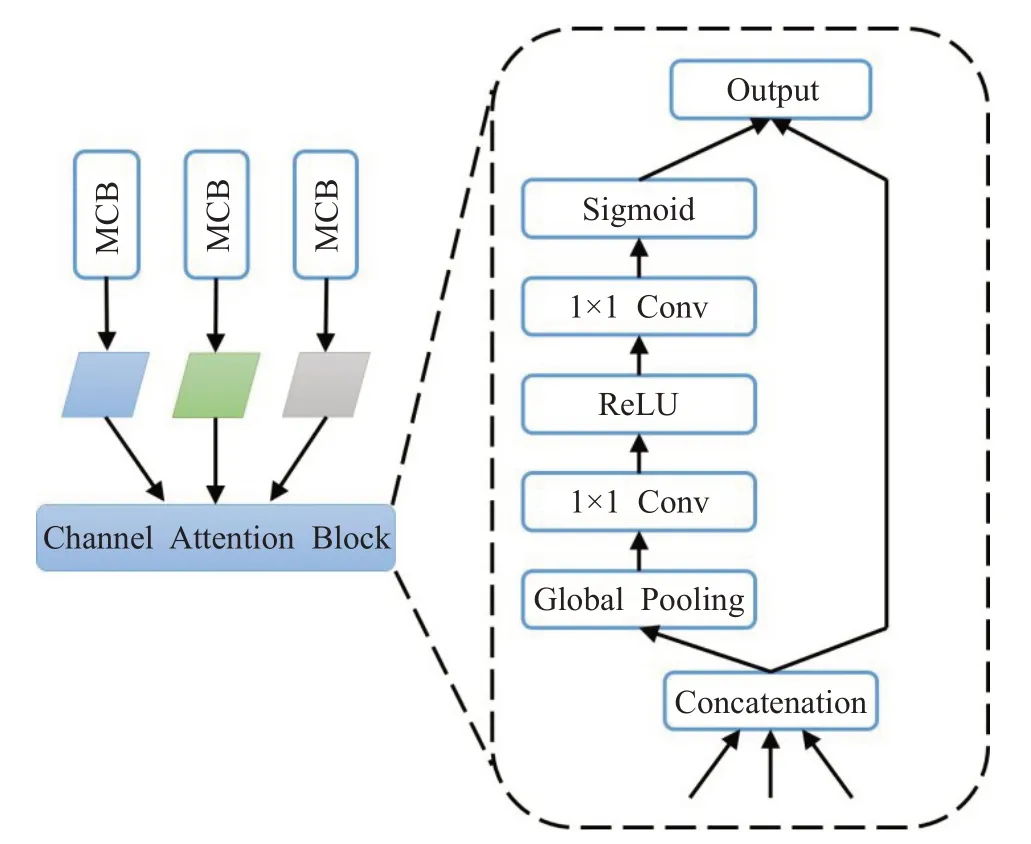
图3 通道注意力模块Fig.3 Channel attention block
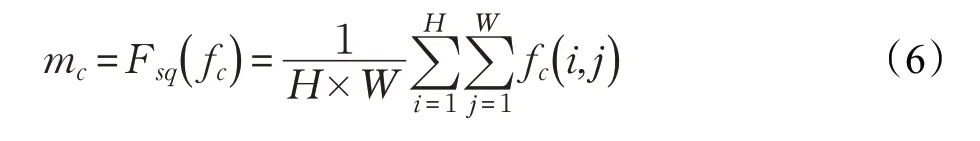
其中mc为每个通道特征图的平均值。
当Sequeeze操作得到了通道的全局特征之后,接下来需要对全局特征做Excitation操作,来获取通道之间的非线性关系。因此,使用激活函数Sigmoid来进行操作:

最后,经过特征向量e调节后的特征图作为最终的特征图送到检测头进行预测。该通道注意力模块可以有效地将不同尺度的特征进行融合,并为特征通道分配不同的权重,使网络可以自适应地对行人进行检测。
3 实验结果及其分析
3.1 数据集
为了证明该方法的有效性,在目前比较流行的Caltech行人检测数据集上进行了评估。Caltech行人检测数据集是由Dollar等人提出,由于其出色的泛化能力和数据规模被广泛应用到行人检测中。Caltech数据集主要是通过车载摄像头,在城市街道进行拍摄收集的视频数据,共包括11组视频。前6个视频集set00~set05用于训练,其余5个视频集set06~set10则用于测试。训练集和测试集分别具有42 782张和4 024张图像。Caltech数据集的图像分辨率为640×480,并对大约2 300个不同的行人进行了标注,包括各种复杂场景中的各种遮挡行人。绝大多数行人尺寸较小,分辨率较低,像素在30~100之间,并且道路背景复杂,识别比较困难,因此具有一定的检测难度。本文在合理子集(reasonable,R),遮挡子集(heavy occlusion,HO)和总体数据集(ALL)对算法进行评估。
评估的标准是使用对数平均漏检率(log-average miss rate,记为MR-2)来检验检测器的性能,计算方式为FPPI-MR(false positives per image against miss rate)曲线在对数空间[10-2,100]之间均匀分布的9个点的平均值。其较低的值能够反映出更好的检测效果。其中MR和FPPI的计算方式如公式(9)和(10)所示,其中FN代表假阴性样本数量,FP代表假阳性样本数量,TP代表真阳性样本数量,N代表图片的数量。

3.2 实验环境及训练细节
实验环境参数如表1所示。

表1 实验环境参数Table 1 Experimental environment parameters
实验的主干网络是在ImageNet上经过预训练的ResNet50,使用Adam方法进行参数优化,并且应用移动平均权重策略[24]来实现更加稳定的训练。为了增强训练数据的多样性,采用了标准的数据增强技术,包括随机色彩失真、随机水平翻转、随机缩放和随机擦除。对于Caltech数据集,训练期间将网络的输入分辨率设为336×448,将一个GPU上的Batch Size设定为8,学习率设定为10-4,训练120个Epoch后停止。
3.3 实验结果与分析
为证明本文提出的改进方法的有效性,首先在Caltech行人数据集上跟原CSP算法进行对比。计算得到的FPPI-MR曲线如图4所示,其中4(a)、(b)、(c)分别代表了在合理子集、严重遮挡子集和总体的检测结果。合理子集R的遮挡比例不超过35%,严重遮挡子集HO的遮挡比例为35%~80%。实验结果表明,该算法在HO子集上对原算法提升最大。这是由于遮挡比例大的行人可提取的特征较少,需要更多的上下文信息帮助检测,MCB模块采用级联的方式来提取上下文,相对于串联来说感受野更大,提取的上下文信息更加丰富,并且使用小扩张率,相对于大的扩张率来说,减少了噪音的加入。将MCB模块添加到CSP算法中,在遮挡行人子集上的MR-2降低了2.92%,引入注意力模块(CA)进行调整之后,在遮挡子集上的MR-2降低了4.08%。
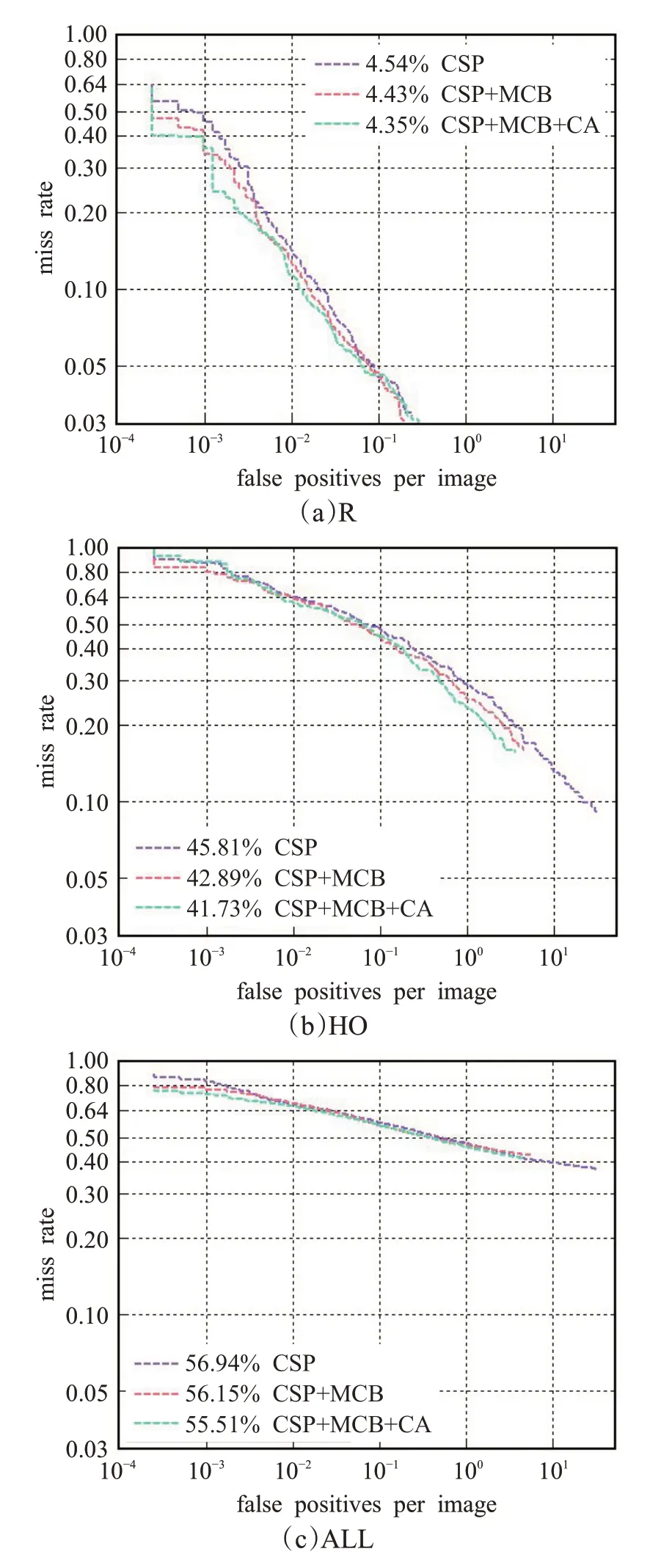
图4 FPPI-MR曲线Fig.4 FPPI-MR curve
相对于HO子集,原CSP算法在R子集上的性能已接近饱和,所以提升较小,MR-2由4.54%降低为4.35%。R子集由于遮挡较轻,检测时对周围上下文信息需求较少,过多的上下文信息可能会影响检测性能。因此,MCB模块使用跳跃连接实现特征复用,并使用平均池化和1×1卷积提取原始特征的粗粒度信息进行融合,配合CA模块利用通道加权抑制冗余的上下文信息,防止在遮挡较轻甚至无遮挡的情况下网络退化。
最后在总体行人上添加MCB模块,MR-2降低了0.79%,添加CA模块后MR-2降低了1.43%,有效地提升了模型的检测性能。
这些结果表明,不同的遮挡比例会减少行人的有效特征,对算法性能的提升有一定的影响。本文提出的算法在遮挡比例达到35%以上时对原算法提升最大,另外在遮挡比例低于35%时也能保持优于原算法的检测性能,因此该算法在不同程度的遮挡比例中有着良好的泛化能力。
为了更好地评估模型,针对算法的查全率和查准率也做了对比,得到的PR曲线如图5所示。改进后的算法在R、HO和ALL三个子集上的精确率分别提高了0.09%、3.88%和0.54%,降低了误检率,证明了该算法的有效性。
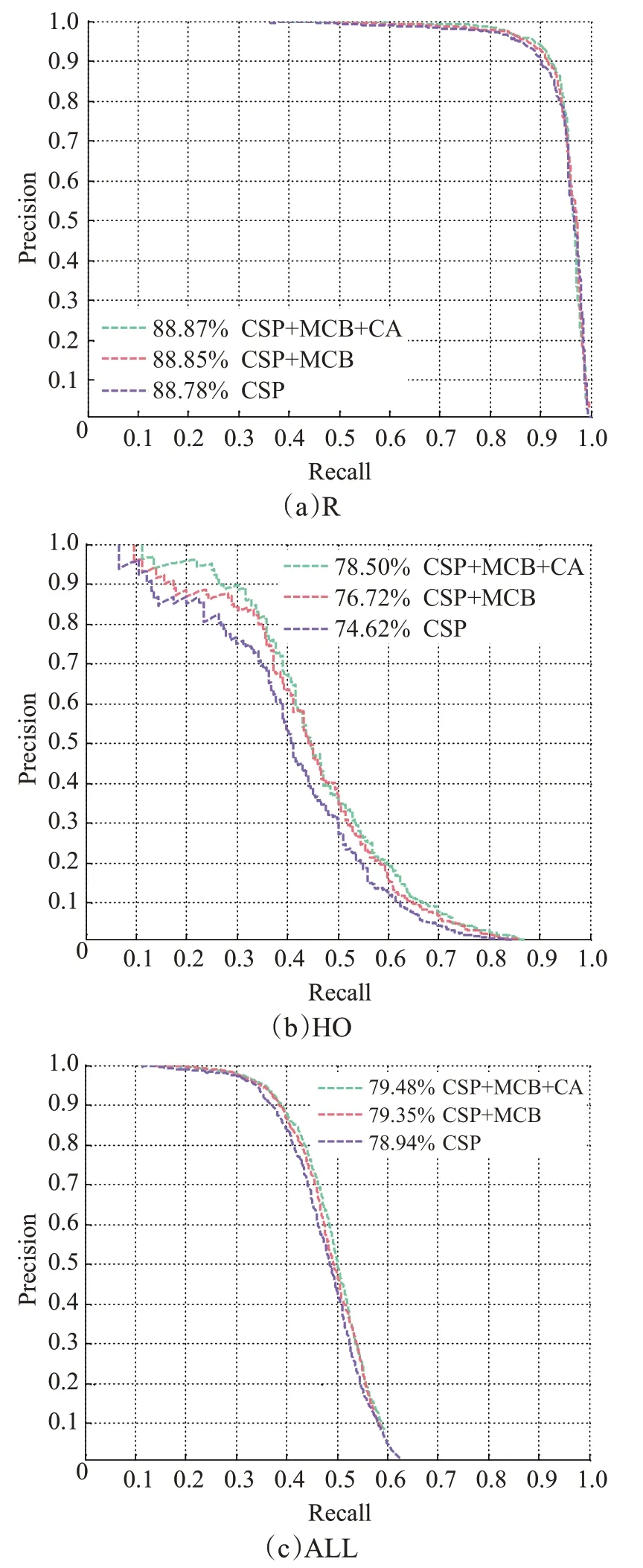
图5 PR曲线Fig.5 PR curve
其次,比较了在特征融合阶段的特征图的不同组合,适当的特征融合有利于各种规模的行人检测。从表2中可以看出,没有结合φ4、φ5的{φ2、φ3}组合由于没有融合高级语义特征,因此漏检率最高,为51.63%,但参数较少,检测速度最快;结合了φ4的{φ3、φ4}、{φ2、φ3、φ4}组合,漏检率分别为48.09%和49.26%,较{φ2、φ3}组合有所下降;而结合了φ4、φ5的{φ4、φ5}、{φ3、φ4、φ5}、{φ2、φ3、φ4、φ5}组合,因为融合了高级语义特征,因此检测效果较好,但会占用更多的运行内存,所以检测速度较慢。另外,由于MR{φ3、φ4、φ5}<MR{φ2、φ3、φ4、φ5},MR{φ3、φ4}<MR{φ2、φ3、φ4},因此结合了φ2这种低级的特征图会使模型的漏检率升高。所以对于该模型来说,最佳的性能来自于{φ3、φ4、φ5}的组合,漏检率为41.73%。
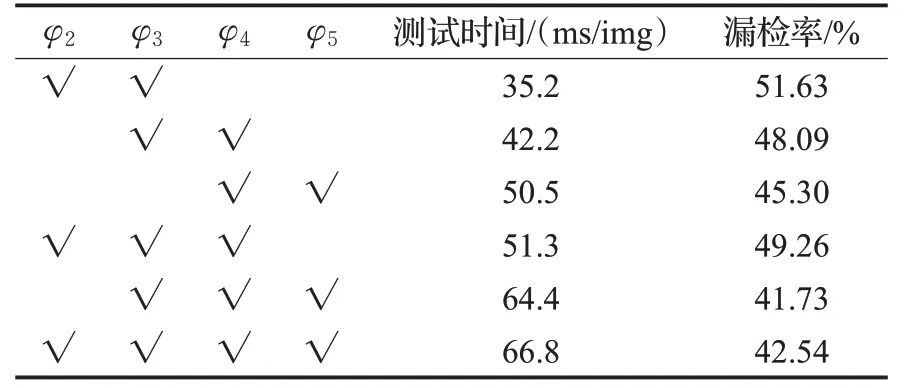
表2 特征融合对比实验Table 2 Comparisons of different fusion methods
另外,为了表明MCB模型结构的有效性,在CSP模型的基础上分别嵌入ASPP、RFBNet进行比较,得到的结果如表3所示。在不加CA模块的情况下,三个模块的漏检率分别为43.60%、43.15%、42.89%,加上CA模块后漏检率为42.55%、42.16%、41.73%。由此可以看出,MCB模块的设计表现效果更好。
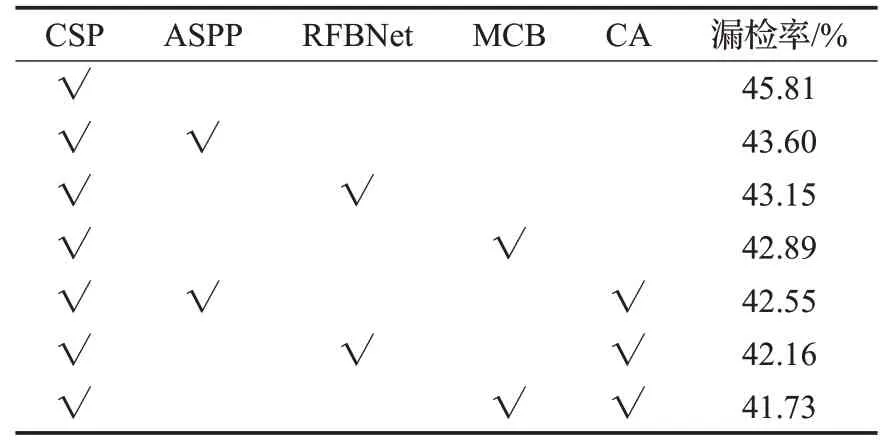
表3 MCB与经典模型的对比实验Table 3 Comparison of MCB and classic modules
最后,在Caltech的合理子集(R)、遮挡行人(HO)和总体行人(ALL)三个子集上与当前最先进的模型的MR-2进行比较,包括RPN+BF[25]、MS-CNN[26]、SDS-RCNN[27]、GDFL[28]、ALFNet[29]、CSP以及专门针对行人遮挡设计的DeepParts[10]、Bi-Box[11]、RepLoss[12]、ATT-part[13]。实验对比结果如表4所示。
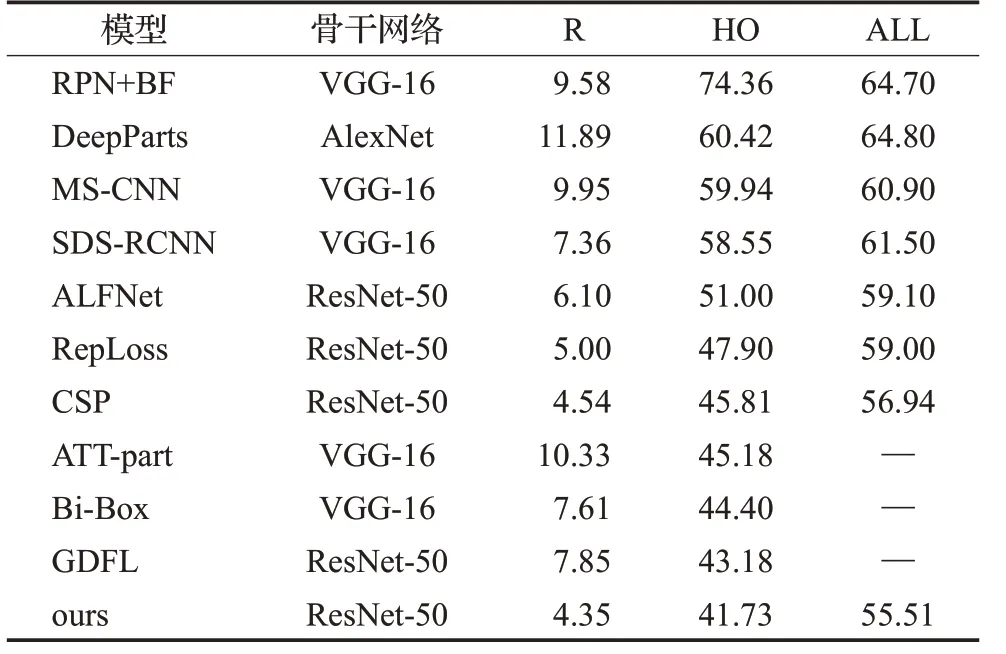
表4 在Caltech上的结果对比实验Table 4 Comparisons of state-of-the-art detections on Caltech%
由表4可知,在遮挡情况下,限于行人的可见率和尺度大小,普通的行人检测器漏检率普遍较高,而专注于行人遮挡问题提出的检测器则表现较好。与上述算法相比较,本文提出的算法在遮挡行人中取得了最好的效果。能取得如此良好效果的原因是:由于上述基于anchor-base的算法,直接对整个锚框进行总体的分类来检测行人,行人的遮挡信息是包含在整体推断里的,容易造成干扰,而本文采用基于anchor-free的检测器,行人中心点和尺度的预测是分开进行的,并且使用了高分辨率的特征图,因此受遮挡和尺度大小的影响相对较小;另外,采用多尺度上下文提取模块可以提供更多的信息来帮助检测器进行遮挡行人的推断,并且注意力模块通过对特征通道间的调整,增强了行人特征的表示,可以在遮挡方面取得更好的效果。
图6展示了CSP模型和本文改进后的模型对于遮挡行人的检测效果。其中,左边为原CSP算法的检测效果,右边为本文提出的改进后的CSP算法的检测效果。其中红色的检测框代表漏检,绿色的检测框代表正确检测。可以看出本文的改进的模型在遮挡比例较高的场景下更加具有鲁棒性。

图6 遮挡场景检测结果对比Fig.6 Comparisons of occlusion scene detection
另外,对该算法失效部分的实验也进行了分析,图7展示了本文改进的模型在数据集中失效的场景。通过分析,可以得出失效的场景主要有两种,像素值过低和遮挡范围过大。具体来说,行人尺度大小在30~40像素,遮挡比例70%~80%的情况下模型的漏检率较高;在30像素以下,遮挡比例80%以上模型基本失效。在这种场景下,检测器可以利用的信息太少,以至于无法进行准确的检测。大多数行人都是在30~80像素之间观察到的,而对于汽车应用而言,进行行人检测也必须在这个尺度下进行。举例来说,对于身高1.8 m的行人,可以根据观察到的像素值对行人的距离进行估计,当车辆以55 km/h的速度行驶时,一个30像素的行人距离车有4 s的距离,而一个80像素的行人只有1.5 s的距离,这就表明,对于30像素以下的行人,检测会留出足够的时间来提醒驾驶员,而80像素的行人由于距离过近,对实时检测的准确性要求就足够高。所以,尽管该模型会在行人像素过低、遮挡范围过大的场景中失效,但在一定程度上满足实时检测的要求。

图7 模型失效场景Fig.7 Model failure scene
4 结语
在本文中,针对行人遮挡问题,对基于anchor-free的行人检测器进行了两点改进:一是通过上下文模块级联多个扩张卷积层来扩大感受野,使用密集连接实现多尺度特征共享,提取上下文信息;二是利用通道注意力模块对多尺度特征图融合进行自适应的调整,增强特征表示。与原算法相比,本文提出的算法在行人遮挡上面表现得更为出色,在Caltech数据集上的漏检率降低到了41.73%,验证了本文方法的有效性。在未来的工作中,将从特征提取能力更强的骨干网络中进行研究,并且考虑引入时空上下文信息来提高检测效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
甘肃教育(2020年22期)2020-04-13
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
