
改进Relief-C5.0的恶意域名检测算法
2022-06-09 11:58马栋林张澍寰
计算机工程与应用 2022年11期
马栋林,张澍寰,赵 宏
兰州理工大学 计算机与通信学院,兰州 730050
域名系统(domain name system,DNS)作为互联网的一项基础服务,提供域名和IP地址之间的相互转换。此外,DNS还作为信任的凭据,为邮件服务器和证书时域控制权提供验证服务。由于DNS应用广泛,且自身缺乏安全检测机制,因此成为恶意域名主要的攻击对象。
恶意域名攻击常伴随邮件发送、短信和网页点击等内容中,通过使用一些迷惑性的文字和图片来引诱用户点击,也可能以某种形式存在于软件代码中,伴随软件的运行对某一服务器发起大规模访问,导致服务器宕机,影响合法域名的正常访问。利用恶意域名检测技术,及时发现网络中出现的恶意域名并进行拦截,可以有效防范恶意域名的攻击。
根据国家互联网应急中心(National Internet Emergency Center,CNCERT)2020年第51期《网络安全信息与动态周报》显示[1],该周内因恶意域名攻击导致境内感染网络病毒的主机数量达75.8万个,境内被篡改网站数量达4 327个,被植入后门的网站数量达839个,境内网站的仿冒页面数量达4 374个,可见由恶意域名引起的网络安全形势不容乐观。
在众多恶意域名攻击中,僵尸网络攻击[2]所产生的负面作用尤为巨大。目前,僵尸网络的控制者大部分使用DGA(domain generation algorithm)算法来生成域名,从而逃避黑名单的检测。国内外的研究者如Mao等[3]提出了一种针对DGA的恶意域名检测算法,应用机器学习方法提取特征集,构建DGA检测模型。Can等[4]将域名数据模糊化为Neutorsophic集,来减少良性域名的误检。Sivaguru等[5]提取域名的边界信息特征,与域名进行内联,构造深度学习框架,并使用随机森林算法进行分类。殷聪贤[6]利用随机森林算法构建了基于DNS行为特征的恶意域名检测模型。该算法因使用的特征过多,导致时间开销较大,此外,该模型对训练数据要求极高,若存在干扰数据,随机森林模型会出现过拟合现象,导致检测准确率不稳定。Zhao等[7]提出了一种基于词法分析和特征量化的恶意域名检测算法。该算法首先根据待测域名和黑名单上域名之间的编辑距离,将待测域名划分为明确恶意或潜在恶意;然后利用N-gram计算潜在恶意域名的信誉值,根据信誉值判断潜在恶意域名的恶意性,通过在公开数据上验证了该方法的有效性。
此外,域名变换技术Fast-Flux和Domain-Flux也常用来隐藏复杂代理网络背后的恶意服务器,使得恶意域名的状态处于不断变化中。如Truong等[8]提出了一种基于被动DNS流量跟踪分析的恶意域名检测方法,通过提取十个URL关键特征,并利用机器学习算法来建立分类器。崔甲等[9]结合黑/白域名过滤器、DNS记录解析器以及基于特征分类的检测引擎等三种域名检测技术,构建了新型恶意域名检测框架,具有较好的完备性。
在域名生成和变换算法的基础上,Fu等[10]提出了一种隐身域名生成算法SDGA(stealthy domain generation algorithm),与传统的基于字符的DGA恶意域名检测算法相比,该算法的隐蔽性更强,更难实时捕获访问日志记录。Yang等[11]利用SDGA域名的特征层特征,提出了一种异构深度神经网络框架。采用改进的多尺度卷积核并行CNN结构,从域名中提取多尺度局部特征,并加入基于自注意力机制的双向LSTM网络架构,提取带有注意力机制的双向全局特征。杨路辉等[12]针对SDGA生成的域名难以检测问题,在现有卷积神经网络模型的基础上,增加了提取更深层字符级特征的卷积分支,同时提取恶意域名的浅层和深层字符级特征并融合,提高对复杂样本的检测准确率。
以上恶意域名检测方法各有优势,相比而言,使用机器学习方法检测时,若提取的特征过多,则时间开销较大,若提取的特征较少,则不具备代表性,准确率不高;基于深度神经网络的检测方法准确率较高,但耗时较长,实时性不强;通过建立黑名单过滤器的检测方法耗时较短,准确率也较高,但容易被攻击者所规避,普适性不强。
综上,基于目前恶意域名检测算法中存在的实时性不强、准确性不高等问题,本文提出一种基于Rf-C5的恶意域名检测算法。首先,通过使用改进的Relief特征选择算法解决了字符特征数量过多造成计算开销大、运行时间长的问题;其次,通过C5.0决策树分类器,降低分类的复杂度,在保证检测准确率的基础上降低检测的时间开销。
1 算法设计
图1给出了本文算法的检测流程。首先,收集与整理国内外合法域名与恶意域名公开数据集,并进行预处理;然后,整合当前已有特征,并在此基础上增加了域名的全局URL构词特征种类,将其作为特征选择层的输入;其次,在特征选择层中使用改进的Relief算法计算全局特征的权重,并输出关键特征集,作为分类层的输入;最后,在分类层中使用C5.0决策树进行二分类,实现合法域名与恶意域名的检测。
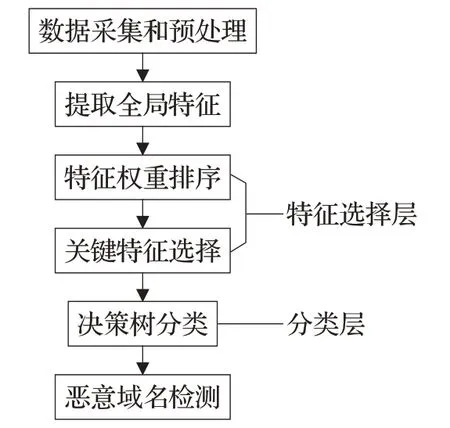
图1 算法流程Fig.1 Algorithm flow
1.1 数据采集和预处理
在Alexa、Malware Domain List等知名网站上收集与整理合法域名与恶意域名,构造合法域名与恶意域名数据集。此外,为降低噪声数据对检测准确率和实时性的影响,将http、www等字符串进行剔除。
1.2 提取全局特征
本文特征提取在文献[13-18]等的研究基础上,丰富了特征类别。具体分为字符特征、域名特征、访问特征、TTL(time to live)特征、解析特征和IP地址集特征六个大类。如表1所示。
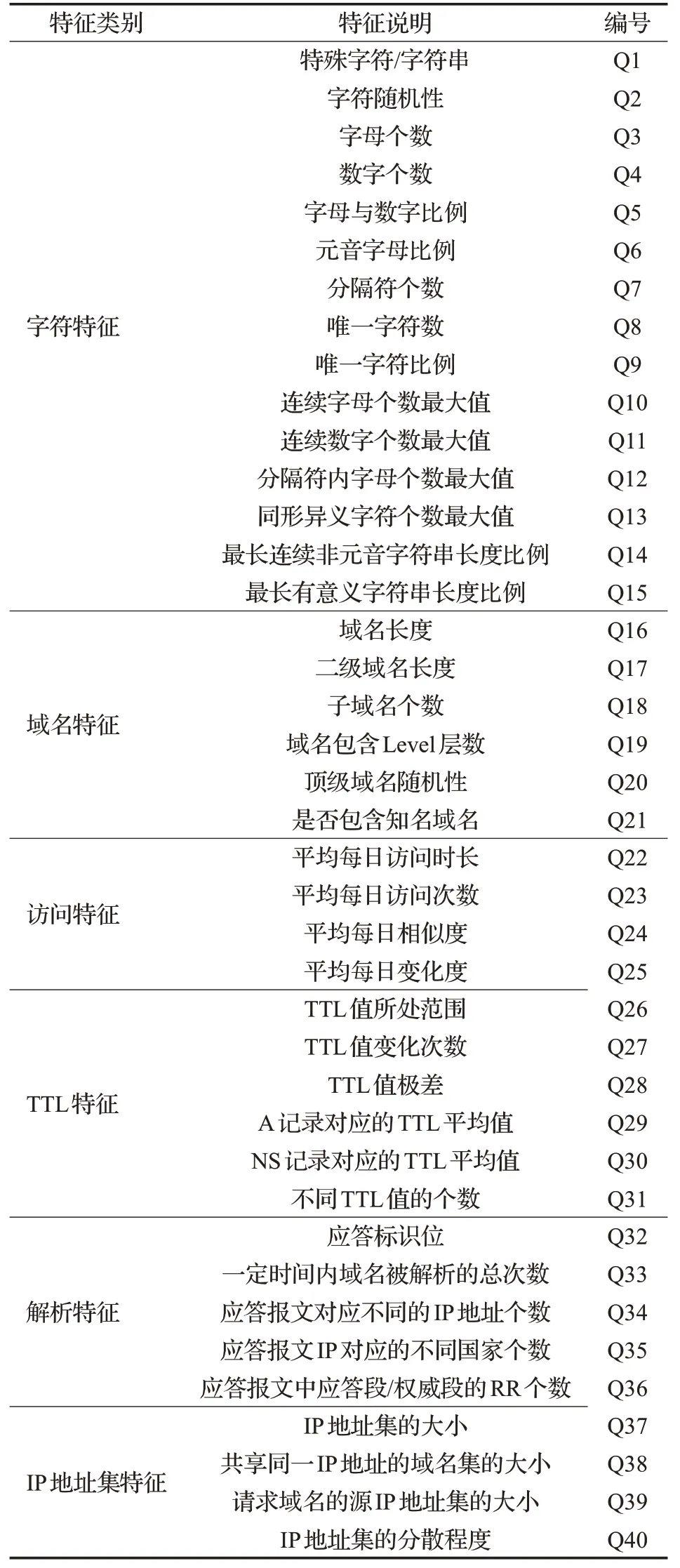
表1 全局特征说明与编号Table 1 Description and numbering of global features
整合了15个字符特征(Q1~Q15)。由于DNS的主要功能是为用户提供可读且易于记忆的名称,字符特性如随机性、字母个数和数字个数等与恶意行为紧密关联。域名字符的随机性通过字符的熵来计算,如式(1)所示:
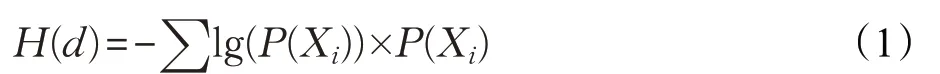
其中,d为待测域名,X i为d中的某一个字符,P(X i)为该字符出现的概率。
整合了6个域名特征(Q16~Q21)。一般正常域名的长度、随机性、子域名个数等都较为规范,顶级域名也较为常见,比如.cn和.com等。而恶意域名较为混乱和随意。
整合了4个时间特征(Q22~Q25)。通过分析域名在时间序列上的查询点,可以发现恶意行为的特征。设置每日为一个观测窗口,统计域名在一日之内的状态变化规律。恶意域名一般不会持续保持活跃,查询次数变化范围较大。
整合了6个TTL特征(Q26~Q31)。TTL值被用来设定域名响应记录的最长缓存时间。恶意网络会产生频繁的TTL变化,其管理者通过设置不同的TTL值为僵尸节点分配资源,表现出更加分散的特点。
整合了5个解析特征(Q32~Q36)。攻击者所使用的IP地址随机性比较高,会将恶意域名解析到不同国家、不同地区的主机上,IP地址也会在多个不同的域名间共享来躲避封堵。
整合了4个IP地址集特征(Q37~Q40)。一般请求恶意域名的源IP地址集较小,而共享同一IP的恶意域名集较大。通过计算IP地址的16 bit前缀的熵来表示IP地址集的分散程度,如式(2)所示:
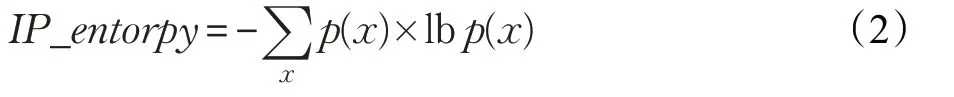
其中,p(x)=count(x)/|I|,I表示IP地址集,p(x)为IP地址的16 bit前缀x在I中所占的比例,熵越大,IP地址越分散。
1.3 特征选择层
本文总结与分析了大量的URL构词特征,但实际该类特征中只有一部分是对分类有效的特征,如果使用全部的特征训练,可能会导致以下问题:
(1)特征数量过多导致特征向量维度过高、容易出现模型过拟合;
(2)特征数量过多导致模型训练过程缓慢,影响检测实时性。
因此,本文采用改进的Relief算法来对全局特征进行权重排序,根据排序结果选择最佳分类特征,删除冗余特征对于检测结果的影响。同时,选择主流特征选择算法Filter相关系数法和Wrapper递归特征消除法进行对比实验,验证Relief算法的有效性。
1.3.1 Filter相关系数法
Filter按照特征与标签的相关性进行评分,并根据动态阈值判别法来选择所需的特征。本文借助机器学习算法中的sk-learn模块,使用feature_selection库的SelectKBest类构建Filter相关系数模型,代码如下所示:
SelectKBest(lambda X,Y:array(map(lambda x:pearsonr(x,Y),X.T)).T,k=20).fit_transform(iris.data,iris.target)
该模型的输入为40维特征矩阵和标签值,输出为包含了特征和皮尔逊相关系数(P值)的数组。取10次实验的平均P值作为特征的排名依据,由于20位以后的特征P值较低,对检测结果影响较小,本文设定参数k=20,P值排名最高的20个特征如表2所示。

表2 Filter关键特征组合Table 2 Filter key features combination
1.3.2 Wrapper递归特征消除法
递归消除特征法通过使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征;然后,再次基于新的特征集进行下一轮训练。本文通过借助机器学习算法中的sk-learn模块,使用feature_selection库的RFE类构建Wrapper递归特征消除法模型,代码如下所示:
RFE(estimator=LogisticRegression(),n_features_to_select=20).fit_transform(iris.data,iris.target)
该模型的输入为40维特征矩阵和标签值,输出为选择的关键特征集。基模型采用Logistic Regression逻辑回归函数,为使对比实验结果更加准确可靠,本文设定参数n_features_to_select=20,将所选择的特征个数与Filter关键特征组合保持一致,取10次实验的平均值作为检测结果。输出如表3所示。
会上,山东省化肥与煤化工协会顾问杨春升分析了山东省化肥与煤化工行业在当前时期的实际情况,以及今后一个时期的行业发展特点,指出山东省的整体发展和盈利状况较好,并提出行业间要保持这种良好的沟通传统,为高层决策和企业发展提供强有力的借鉴和支持。
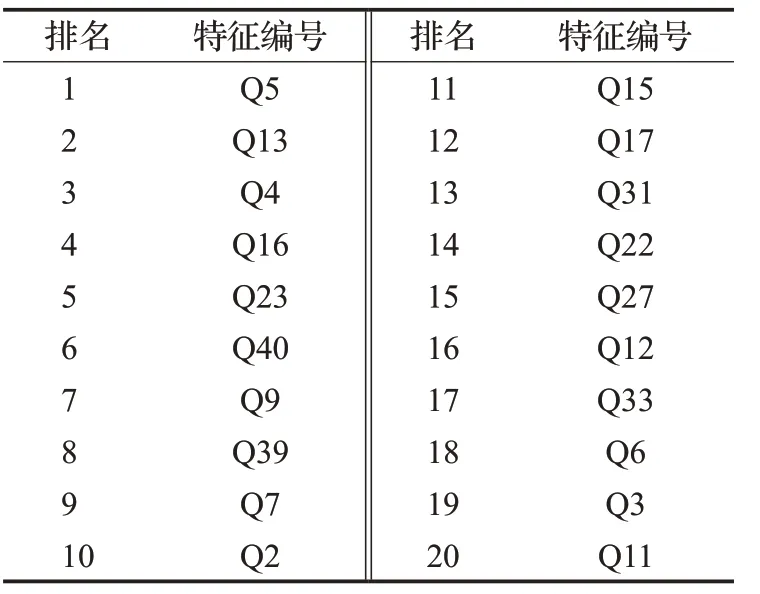
表3 Wrapper关键特征组合Table 3 Wrapper key features combination
1.3.3 改进的Relief算法
Relief算法根据各特征与标签的相关性计算权重,移除权重小于设定阈值的特征。由于其简洁的算法和优秀的特征选择能力被广泛应用,伪代码如下:

其中,参数为数据集E,抽样次数m,特征权重阈值T,特征权重向量S,样本点H,正样本集合中距离H最近的样本X+,负样本集和中距离H最近的样本X-,特征总个数N=40。
由于Relief算法的运行时间由抽样次数m和输入的特征个数N决定,计算某一个样本点的最近邻样本需要全部的训练空间,所以存储率较高且运算时间较长。为了解决此问题,本文在Relief算法的基础上进行改进,将原始训练集划分为若干个小训练集,分别计算每个小训练集内的特征权重,减小训练空间大小,降低硬件存储率,最后将计算出权重的特征合并,输出关键特征集T。
根据提取的40维全局特征的天然属性,将其分为6个小训练集,作为改进的Relief算法的输入,流程如图2所示。
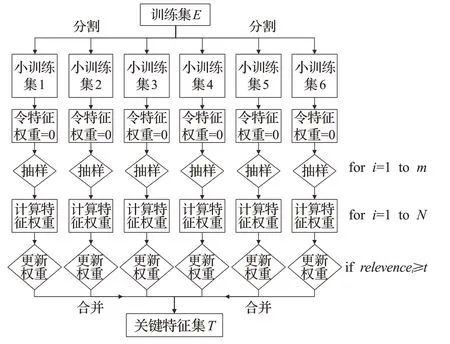
图2 改进的Relief算法Fig.2 Improved Relief algorithm
由图2可以看出,改进的Relief算法与原算法的区别在于将数据集分割之后同时并行处理,极大地缩短了运算时间。
取10次实验的平均权重值作为检测结果,为了使输出更加直观便于比较,将排名最高的特征权重值归化为1,其他特征权重值等比例转化。由于后20位特征权重值较低,与结果的关联性不强,同样取权重值排名前20位的特征作为关键特征,如表4所示。
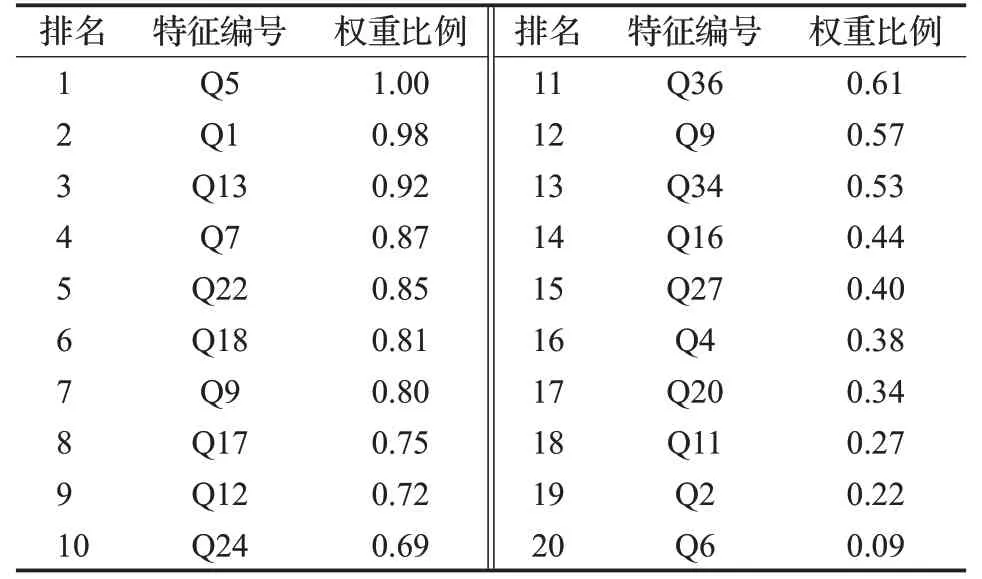
表4 改进的Relief关键特征组合Table 4 Improved Relief key features combination
1.4 分类层
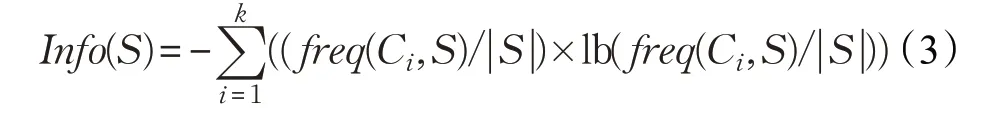
如果某属性变量T,有n个分类,则属性变量T引入后的条件熵定义为式(4):

随着决策树的生长,越深层处的节点所体现的数据特征就越个性化,会出现过拟合现象,所以需要修剪决策树,采用Post-Pruning法从叶节点向上逐层剪枝。一般决策树会使用测试数据进行检验,但C5.0分类器使用了统计的置信区间的估计方法,直接在训练数据中估计误差。在执行效率和内存使用方面进行了改进,采用Boosting方式提高模型准确率,计算速度较快,占用的内存资源较少。
2 实验与分析
2.1 数据集
实验的数据集包括合法域名和恶意域名两部分。从Alexa网站排名中选取前60 000条域名作为合法域名集,从DGA Domain List、Malware Domain List和360等知名恶意域名网站上收集并整理60 000条恶意域名作为恶意域名集,保证了恶意域名种类的完整性和全面性。将合法域名集与恶意域名集进行合并,共120 000条,选取其中80 000条作为模型的训练数据,40 000条作为测试数据。
2.2 实验环境
实验环境如表5所示。
表5 实验环境Table 5 Experimental environment
2.3 模型评价标准
使用召回率(recall)、准确率(accuracy rate,AR)、漏报率(false negative rate,FNR)、误报率(false positive rate,FPR)、精确率(precision rate,PR)和AUC(area under curve)[19]来评估本文提出的Rf-C5模型在恶意域名检测时的性能。评价指标均基于实验结果的混淆矩阵计算。
2.4 改进的Relief算法效果评估
分别使用Filter相关系数法、Wrapper递归特征消除法和改进的Relief算法对提取的40维全局URL特征(Q1~Q40)进行选择,得到不同的三组特征组合,如表2~表4所示。将其分别作为支持向量机(support vector machine,SVM)、K最近邻算法(K-nearest neighbor,KNN)、随机森林(random forest,RF)、C4.5和C5.0五个分类器的输入,交叉验证模型检测效果。图3~图5分别是三种特征选择算法的关键特征组合在不同分类器上的检测结果。
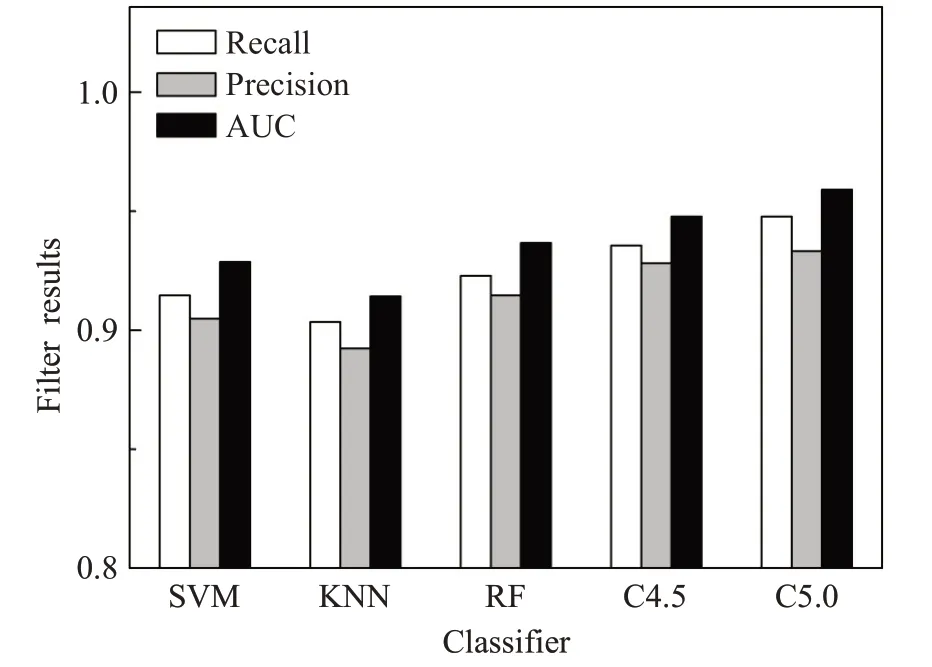
图3 Filter特征组合检测结果Fig.3 Filter feature combination detection results
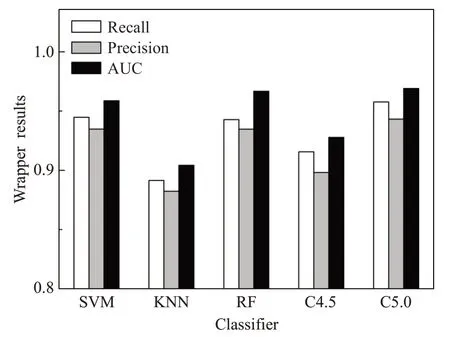
图4 Wrapper特征组合检测结果Fig.4 Wrapper feature combination detection results
由图3~图5可以明显地看出,经过改进的Relief算法选择出的特征组合,对恶意域名的检测效果在召回率(Recall)、精确率(Precision)和AUC值三个方面都强于Filter相关系数法和Wrapper递归特征消除法,即改进的Relief算法对关键特征的选择更准确,能够更好地提取出与标签关联度更高的特征。
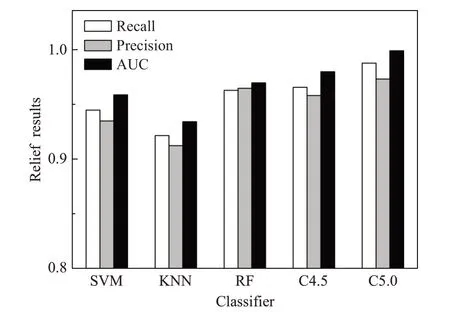
图5 改进的Relief特征组合检测结果Fig.5 Improved Relief feature combination detection results
2.5 C5.0分类器效果评估
将改进的Relief算法与SVM、KNN、RF、朴素贝叶斯(Naive Bayesian,NB)、线性回归(linear regression,LiR)、逻辑回归(logistic regression,LoR)以及C5.0共七种分类器分别结合,构建Rf-SVM、Rf-KNN、Rf-RF、Rf-NB、Rf-LiR、Rf-LoR和Rf-C5模型,测试不同分类器与改进的Relief算法结合之后在域名分类上的效果。
各模型的输入端是提取的40维全局URL特征,首先通过改进的Relief特征选择层计算,输出关键特征集,然后作为分类层的输入,使用分类器进行二元分类。
以AR、PR、FNR、FPR四项指标深入具体对比七种模型的检测性能,如表6所示。
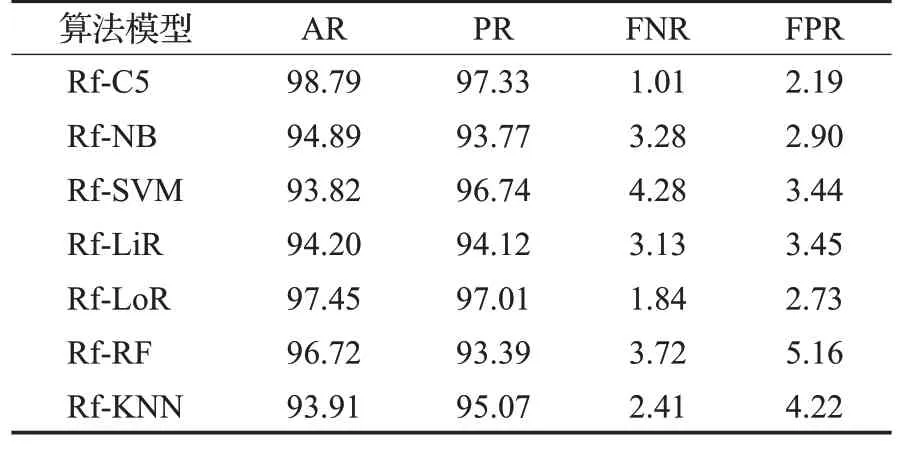
表6 七种模型的检测性能对比Table 6 Comparison of detection performance of seven models %
由表6可以看出,使用C5.0分类器与改进的Relief算法相结合,在各项指标下均可以达到良好的效果。其中,在准确率方面,C5.0相比SVM、KNN、NB和LiR优势明显;在精确率方面,C5.0相比NB、LiR和RF优势明显;在漏报率方面,C5.0相比NB、SVM、LiR和RF优势明显;在误报率方面,C5.0相比RF和KNN优势明显。
2.6 Rf-C5模型综合效果评估
为了验证Rf-C5恶意域名检测模型的综合性能,在相同的实验环境下分别构造目前国内外主流的各类恶意域名检测模型。分别为文献[20]基于语义表示和深度学习的恶意域名检测模型、文献[21]基于N-grams和随机森林的恶意域名检测模型、文献[22]基于优化支持向量机的恶意域名检测模型、文献[23]基于卷积神经网络CNN的恶意域名检测模型。使用相同的数据集,与本文恶意域名检测模型进行性能比较,具体结果如表7所示。
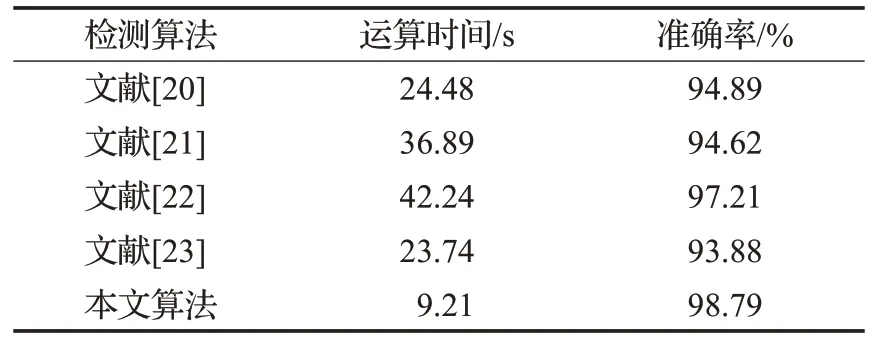
表7 五种算法性能比较Table 7 Performance comparison of five algorithms
由表7可以看出,本文提出的恶意域名检测算法模型Rf-C5相较于主流神经网络和机器学习的检测方法,在运算时间和准确率方面都有显著的提升。
在运算时间方面,由于改进的Relief算法将原始数据集划分为若干个小训练集,减小了训练集的计算空间,降低了存储率,提升了运算速度;同时,C5.0分类器使用统计的置信区间的估计方法,直接在训练数据中估计误差,占用的内存资源较少,与随机森林、支持向量机等分类器相比,极大地减少了运算时间。
在准确率方面,由于Rf-C5模型在对域名分类之前先对特征进行了排序选择,删除了无用特征,降低了过拟合;再者,C5.0决策树分类器采用信息增益率来确定最佳分组变量和最佳分割点,通过Boosting方式提高模型准确率,相较于其他分类算法效果更好。从结果来看,准确率略高于文献[22],提高了1.58个百分点,优于文献[20]、文献[21]和文献[23],分别提高了3.9、4.17和4.91个百分点,具有更高的准确性和更好的实时性。
3 结束语
针对目前恶意域名检测算法分类模型计算复杂度较大等问题,构造了一种Rf-C5恶意域名检测算法模型。通过对全局特征进行选择,删除了冗余信息;通过与传统的各分类器模型对比,证明了C5.0分类器在检测准确率上的优势;进一步在相同的实验环境内,通过与各类主流恶意域名检测模型进行对比,证明了本文Rf-C5模型的优良综合性能。在未来的工作里,计划加入多标签分类,可以将良性域名和恶意域名根据内容或功能进一步细分,为用户提供更多有用的信息,提高网络安全。
猜你喜欢
计算机系统应用(2021年2期)2021-02-23
江苏教育研究(2020年2期)2020-04-10
铁道通信信号(2020年11期)2020-02-07
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
科学中国人(2017年14期)2017-01-28
中国信息技术教育(2015年22期)2015-09-10
航天返回与遥感(2014年5期)2014-07-31
互联网天地(2012年6期)2012-03-24
