
基于电影属性和交互信息的电影推荐算法
2022-06-09 07:46顾亦然张远之杨海根
南京理工大学学报 2022年2期
顾亦然,张远之,杨海根
(南京邮电大学1.自动化学院、人工智能学院;2.智慧校园研究中心;3.宽带无线通信技术教育部工程研究中心,江苏 南京 210003)
在大数据时代,互联网给用户带来了大量信息[1],也产生了信息过载问题,使得用户在面对网络上海量资源时,无法快速准确的选择自己想要的那部分信息,这样反而降低了信息的使用效率。推荐算法是信息过滤技术之一,它能够自动地过滤与目标用户无关或用户不感兴趣的数据[2]。
作为推荐系统的经典解决方案,协同过滤(Collaborative filtering,CF)算法利用协同信息推荐用户感兴趣的信息[3],因为其拥有较高的准确性,而被应用于电影、音乐和电子商务等领域[4]。协同过滤算法主要有两个基本算法:基于用户的协同过滤(User collaborative filtering,UCF)和基于物品的协同过滤(Item collaborative filtering,ICF)。基于物品的协同过滤算法主要是基于用户和物品的交互来为用户进行推荐,用户和物品的交互信息真实性和完整性直接影响推荐的效果。在实际应用中,协同过滤的数据稀疏问题比较严重,因为用户的数量和物品的数量都比较多,而用户和物品的交互信息却相对较少,这使得协同过滤算法推荐的效果不够理想。为了解决这个问题,研究者们尝试在协同过滤算法中加入辅助信息,例如社交网络、图片和用户-物品特征等。本文考虑融合知识图谱和协同过滤算法来缓解该问题。知识图谱可以从3个方面改善推荐系统:(1)知识图谱中实体之间通过语义相关联,这有助于发现实体间的潜在联系,从而提高推荐准确率;(2)知识图谱中包含了多种关系,有助于推荐结果的多样性;(3)知识图谱中包含了用户的历史记录和待推荐物品,因此推荐系统有更好的可解释性[5]。
1 相关研究
1.1 基于协同过滤的推荐
传统的推荐算法主要有3类:协同过滤算法、基于内容的推荐算法以及混合推荐算法。Sarwar等[6]提出了基于物品的协同过滤算法,通过识别不同项目之间的关系为用户推荐物品。Jin等[7]将用户的年龄和性别等特征引入到相似度计算中,从而提高推荐系统的推荐效果。Chae等[8]提出AR-CF模型,通过为冷启动用户和物品生成虚拟邻居并扩充来缓解冷启动问题。基于内容的推荐算法以物品的特性和用户偏好等为依据进行推荐。于洪等[9]通过综合考虑用户、时间、项目属性和标签来预测评分,有效解决了冷启动问题。Bhatt等[10]通过结合余弦相似度和视觉相似度来计算与锚定视觉概念向量的距离。混合推荐将多种推荐技术结合来弥补单个推荐技术的不足,从而获得更好的推荐效果。Li等[11]结合多种相似度算法,构建了基于用户偏好和产品特征的混合推荐算法。Bi等[12]总结了多层感知的有效学习能力,提出了一种多层感知的混合推荐方法。传统的协同过滤算法具有较高的准确性,但是未能充分利用物品信息。
1.2 基于知识图谱的推荐
知识图谱的理论方法可以使人们更加便捷、准确地获取到自己所需要的信息[13],将知识图谱引入推荐系统的工作主要分为两类:基于嵌入的推荐算法和基于路径的推荐算法。Wang等[14]融合知识图谱和推荐系统,缓解了推荐系统的冷启动和数据稀疏问题。Wang等[15]设计了一个深度自动编码器,用于名人推荐。Yu等[16]将知识图谱看作一个异构网络,通过提取基于元路径的特征来表示用户之间的连接以及不同类型的关系路径的物品。
现有方法重点关注了用户和物品的交互信息,而忽略了物品本身的属性信息。本文提出的基于电影属性和交互信息的电影推荐算法,简称RippleNet协同过滤(RippleNet collaborative filtering,RippleNet-CF),在使用交互信息的同时关注了电影本身的信息,将知识图谱作为推荐系统的辅助信息来源,利用实体关系三元组分析用户的偏好倾向并推理出用户可能喜欢的电影,同时使用协同过滤算法来处理用户和电影的交互信息,最后融合两次结果以达到更优的推荐效果。此外,知识图谱利用不同的关系来连接不同的实体,这提高了推荐系统的可解释性并弥补了数据稀疏的问题。
2 RippleNet模型
2.1 Ripple集
知识图谱中包含了大量的实体以及实体与实体之间的关系。如图1所示,电影《Toy Story》通过“主演”关系和Tom Hanks联系在一起,通过“导演”关系和John Lasseter联系在一起,而Tom Hanks和John Lasseter又与他主演的电影《Apollo13》和导演的电影《A Bug’s Life》联系在一起。这些实体与实体之间复杂的联系就提供了一个探索用户喜好的思路。比如,某个用户的历史观影记录中有《Toy Story》,那么他有可能会喜欢上这部电影的主演Tom Hanks,从而喜欢上电影《APollo13》。因此定义了Ripple集,对于用户U,定义他的Ripple集为

式中:(h,r,t)为知识图谱中的三元组表示,h表示头结点,r表示关系,t表示尾节点,k表示跳数,H表示最大跳数,为用户U第k-1跳的相关实体集,定义为

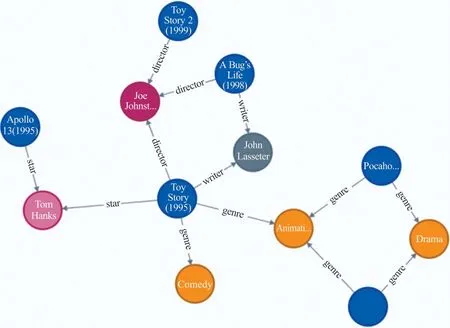
图1 知识图谱局部图
当k等于0时,为用户U历史观看的电影。如图1,假设用户观只看过《Toy Story》,则中只包含《Toy Story》,中包括Tom Hanks,John Lasseter,Animation等,中包含三元组(Toy Story,star,Tom Hanks),(Toy Story,writer,John Lasseter),(Toy Story,genre,Animation)等。
2.2 RippleNet
在RippleNet中,将用户U和电影V作为输入,输出用户U对电影V的点击概率。对于用户U,将他的历史观影记录V u视为种子,然后沿着关系延伸以形成Ripple集。这些Ripple集用于与电影V的嵌入交互以获得用户U关于电影V的响应,然后将其组合以形成最终的用户偏好表示,最后使用电影V的嵌入和用户偏好来计算用户U对电影V的点击概率。
如图2所示,首先将待推荐电影V进行词嵌入得到电影的向量表示v∈Rd,其中,d表示待推荐电影V嵌入的维度。之后将待推荐电影V和用户U的第一跳Ripple集中的头部节点h i和关系r i进行比较,从而为中的每个三元组(h i,r i,t i)分配一个关联概率,关联概率的计算公式如下

式中:Ri∈Rd*d和h i∈Rd分别是关系r i和头部节点h i的嵌入。将关联概率P i看作是待推荐电影V和头部节点h i的相似性。由于电影和电影之间存在着不同的关系,因此需要加入关系Ri。比如,如果是考虑导演或者编剧的话,则电影《Toy store》和电影《A Bug’s life》非常相似,但是若考虑主演的话,这两部电影则没有相似性。
在得到关联概率P i后,通过将关联概率P i和S1u对应的尾部节点t i相乘,得到一个输出向量

式中:t i∈Rd是尾部节点t i的嵌入。这时得到的输出可以看作是用户U的一阶兴趣偏好。如果此时未达到设置的跳数,则使用替换待推荐电影的嵌入v,并循环执行式(3)和式(4),每执行一回合将得到一个输出,直到达到设置的跳数,结束循环。将每次输出的结果相加作为最后的用户兴趣偏好,最后组合用户兴趣偏好和待推荐电影嵌入v得用户点击该待推荐电影的点击概率

式中:U定义为

对RippleNet有以下的损失函数

式中:N表示用户和电影的实际交互情况,N=1表示用户观看了这个电影,N=0表示用户未观看这个电影。
根据图2的流程,可以得到一个用户-电影点击概率预测矩阵。如表1所示。

图2 RippleNet结构图
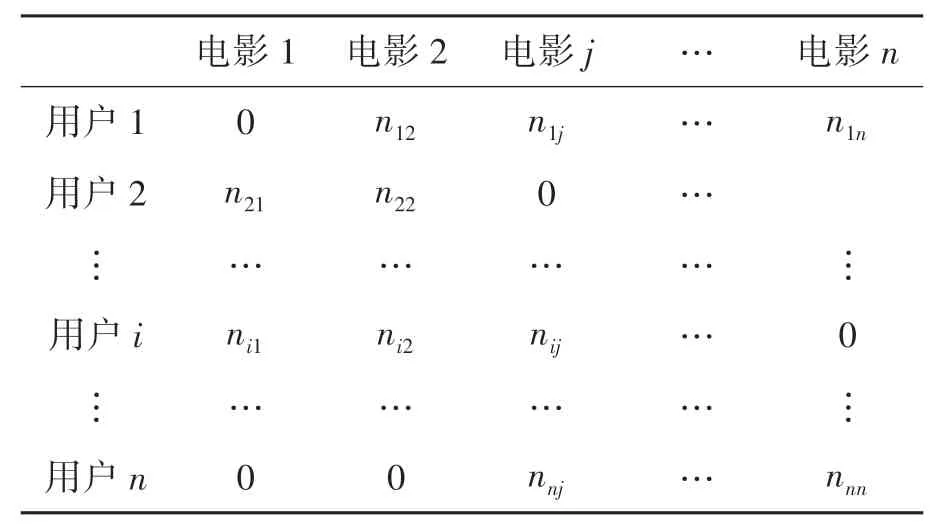
表1 电影点击概率预测
表1为不同用户对于不同电影的点击概率,其中,n ij表示用户i对电影j的点击概率。在预测过程中不会对用户已经看过的电影进行预测,因此有些电影的预测值为0。
3 协同过滤推荐算法
本文使用基于物品的协同过滤来进行电影推荐,它以用户的偏好为假设,将用户对电影的历史评分嵌入为一个向量,并利用评分向量计算电影间的相似度,最后向用户推荐相似度最高的一个或几个电影。如图3所示,喜欢电影A的用户(用户A和用户B)也喜欢电影C,则电影A和电影C相似,又因为用户C喜欢电影A,所以系统为用户C推荐与电影A相似的电影(电影C)。推荐过程可分为3个步骤:
(1)构建电影评分矩阵
假设数据中有m个用户和n部电影,用户集合表示为U={U1,U2,U3,…,U m},电影集合表示为V={V1,V2,V3,…,V n},则用户Ui对电影V j的评分表示为S ij,评分矩阵Rm×n表示为

(2)计算电影相似度
本文采用余弦相似度来计算电影与电影之间的相似度。若将用户对电影的评分嵌入成一个m维的向量,用户对电影Vi的评分嵌入为v i=[S1i,S2i,…,S mi],对电影V j的评分向量为v j=[S1j,S2j,…,S mj],则电影Vi和电影V j的余弦相似度为
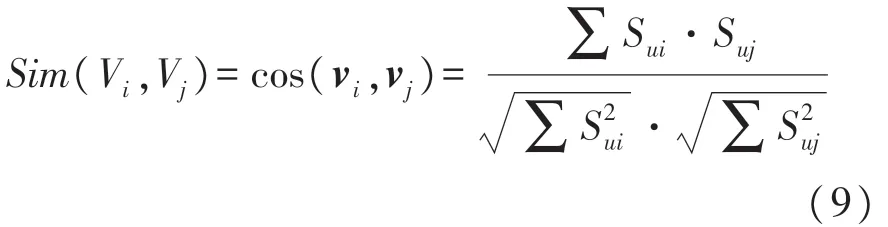
式(9)中余弦相似度的取值范围为[0,1]。
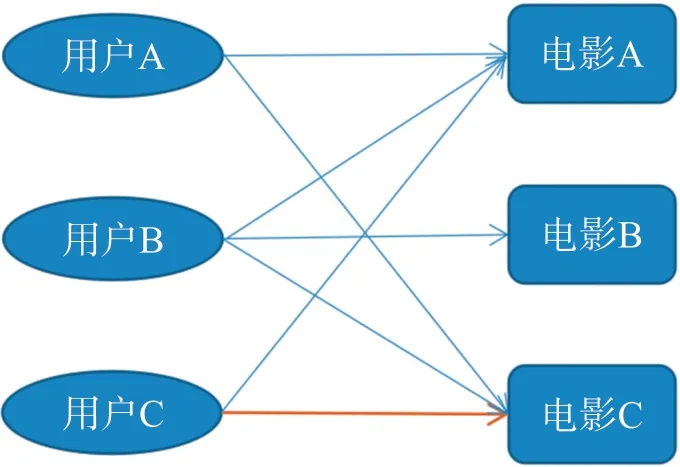
图3 基于物品的协同过滤推荐实例
上述的余弦相似度在实际运用中会存在一些问题。因为有些用户给电影的评分普遍偏高,而有些用户给电影的评分普遍较低,则不同用户对一部电影评分相同,但他们的喜欢程度可能不一样。因此对上述式子进行调整,将用户的打分习惯考虑进来,改进的公式如下
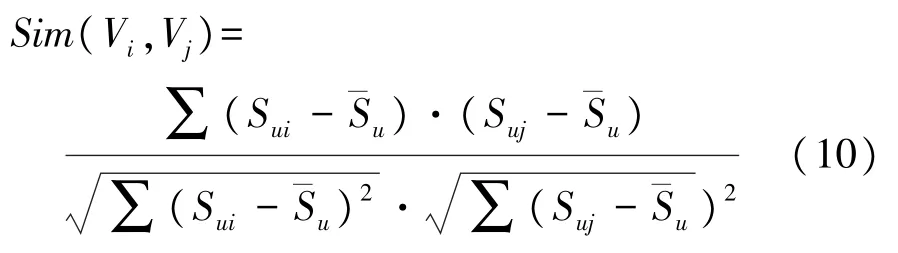
(3)点击概率预测
确定了电影间的相似度,通过计算用户历史观看的电影与待推荐电影的相似度的总和并进行归一化得出用户对这一待推荐电影的点击概率。公式定义为

4 基于电影属性和交互信息的电影推荐算法
用户-电影评分矩阵可以用来计算电影相似度并以此来为用户推荐,但是,由于协同过滤算法仅仅使用用户和电影的交互信息,所以用户-电影评分矩阵会存在数据的稀疏性问题,导致推荐效果不理想。因此本文提出RippleNet-CF算法,充分利用用户和电影的交互信息以及电影与电影间的属性关系,并以RippleNet-CF的结果作为依据向用户进行推荐。
4.1 构建电影知识图谱
在电影领域中,知识图谱中的实体主要包括电影名、导演、主演、编剧、类型、语言、国家、年代等。不同的电影之间会存在相同的属性值,通过这些相同的属性值,就将两个电影节点联系起来,从而形成一个电影知识图谱。
本文抽取出电影名、导演、主演、编剧、类型、语言、国家、评分和年代这些属性,并利用这些属性构建8张数据结构表,分别为电影名-导演、电影名-导演、电影名-主演、电影名-编剧、电影名-类型、电影名-语言、电影名-国家、电影名-年代。基于上面的8张表,接下来利用neo4j批量的导入这些节点以及节点和节点之间的关系,形成一张电影知识图谱。
4.2 结果融合
基于物品的协同过滤推荐算法利用用户和电影的评分信息计算电影间的相似度,并对电影进行推荐。但是基于物品的协同过滤推荐算法仅仅利用了用户和电影的评分信息,而未能利用电影与电影之间的内在关系信息,并且用户对电影的评分存在一定的主观性。可能同一用户在不同的时间或不同的场景下对同一部电影给出不同的评分,这会导致推荐结果的不准确。此外,因为用户对电影的评分数据相对于用户和电影的数量较少,因此评分数据也是稀疏的,这也会影响推荐的效果。
利用知识图谱从电影的特征出发,通过电影和电影之间的内在关系来发现电影之间的联系,从而发现用户的潜在兴趣。
为了改善推荐的效果,同时利用电影与用户之间的交互信息和电影与电影属性之间的相互关系。充分利用两种算法的优点,克服他们的缺点,对基于知识图谱的RippleNet推荐算法和基于用户-电影评分数据的协同过滤算法的结果进行线性融合。融合公式定义为

式中:C表示融合概率,α表示权值,M表示RippleNet算法计算出的用户对电影的点击概率,P表示协同过滤算法计算出的用户对电影的点击概率。
4.3 算法框图
基于电影属性和交互信息的电影推荐算法流程图如图4所示。
5 试验分析
本节通过试验验证RippleNet-CF模型的有效性,分析了试验的数据,并讨论了不同的参数设置对试验结果的影响。
5.1 数据集
RippleNet-CF采用MovieLens-1M数据集作为试验数据集[18]。这个数据集中包含了6 000多位用户记录,以及4 000多部电影,共有1 000 000多条评论数,评分在1~5之间。

图4 RippleNet-CF算法流程图
利用TMDB数据集在neo4j中构建电影知识图谱。在爬取数据后,对数据进行知识抽取,最终得到了33 311个实体,包括电影名、主演、导演、电影类型等在内的620 997个关系。
5.2 评价指标
常用于推荐系统的结果分析的主要指标包括:准确率(Precision)、召回率(Recall)和覆盖率(Coverage)。参数含义如表2所示。
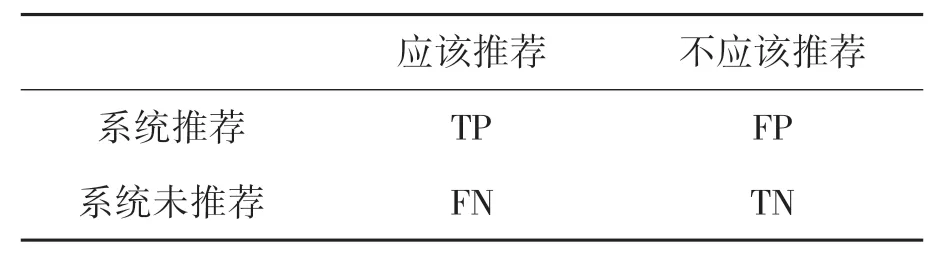
表2 混淆矩阵
准确率定义为

召回率定义为

覆盖率定义为

准确率反映了是否正确预测了用户的喜好。召回率给出了向用户正确推荐的电影占所有应该被推荐电影的比例。覆盖率反映了被推荐电影占电影总量的比例。
5.3 参数设置
为了提高原有推荐系统的准确性,本文将知识图谱作为辅助信息加入到协同过滤算法中,提出了RippleNet-CF算法。本文在公开数据集MovieLens-1M进行测试。α的取值从0递增到1,步长设为0.1,验证模型的准确率、召回率和覆盖率。结果如图5、图6和图7所示。

图5 准确率结果

图6 召回率结果
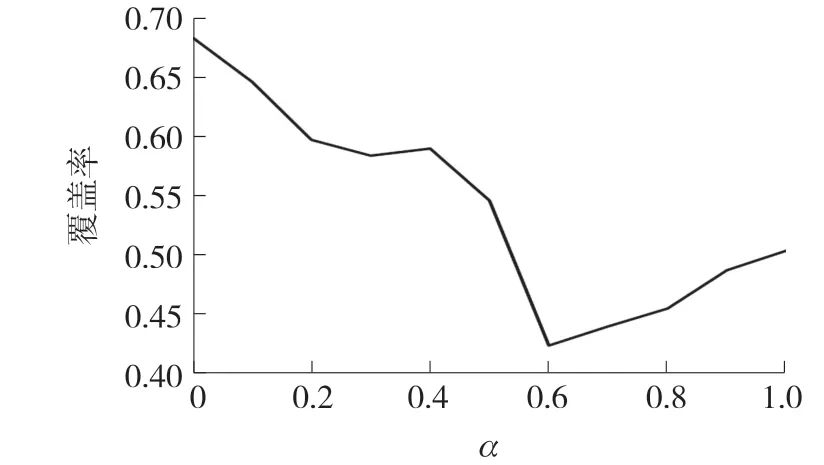
图7 覆盖率结果
从图5、图6和图7可以看出。随着权值α的增大,推荐系统的准确率和召回率的整体趋势变好,在α=0.6时,推荐系统的准确率和召回率达到最优值,之后随着权值的增大,系统性能逐渐下降;而覆盖率与准确率的变化相反,当α在0~0.6时覆盖率呈下降趋势,之后随着α的增大,覆盖率逐渐变大。
5.4 算法比较
本文在公开数据集MovieLens-1M上进行测试,本文提出的模型权值α取值为0.6,将本文的方法与经典的协同过滤算法以及近期比较先进的推荐算法模型进行比较,包括Sarwar等[6]提出的IBCF模型、于洪等[9]提出的CUTA、Pirasteh等[19]提出的CIS-GD模型以及任永功等[20]提出的IMCF模型。试验结果如表3所示。

表3 各算法准确性对比结果
从表3可以看出,当推荐个数为2时,本文模型的准确率低于对比的算法,但是随着推荐电影数目的增加,本文算法的准确性都优于其他算法;当推荐电影数目为4时,本文算法的准确率比IBCF、CUTA、CIS-GD和IMCF分别提高了8.4%、10.7%、11.9%和7.7%;当电影推荐数目达到6时,本文算法比IBCF、CUTA、CIS-GD和IMCF分别提高了8.9%、12.6%、11.7%和7.7%;当推荐数目为8时,分别提高了10.2%、13.2%、11.5%和8.3%;当推荐10部电影时,准确率分别提高11.4%、13.1%、12.5%和11.2%。
仅仅基于用户-电影评分信息进行推荐,数据会存在稀疏性问题,推荐结果也会因用户评分时的环境不同而受到影响,会使推荐结果变差,因此这并不能准确反映用户的兴趣。本文提出的RippleNet-CF算法,能够有效挖掘用户的兴趣。RippleNet对电影属性的关系进行挖掘,进一步探讨电影属性与属性之间存在的关系,丰富了可用的属性信息,再融合协同过滤算法,能够更好地反映用户的兴趣。
6 结束语
针对传统推荐算法准确率低、可解释性差以及数据稀疏等问题,本文基于电影属性和交互信息提出RippleNet-CF算法。在影视推荐过程中更充分地考虑了影视作品的信息,包括用户和电影的交互信息以及电影和电影之间属性的内在联系。本文的算法通过RippleNet算法模型充分利用电影属性和电影属性的内在联系,进而挖掘用户的潜在兴趣,同时也通过协同过滤算法发现用户的现有兴趣,并将两种结果融合,得到最终的推荐结果。试验结果表明,本文提出的算法模型在准确率方面优于现有的模型。这一算法模型也有一些待优化的地方,例如能否在保证准确率的前提下提高覆盖率,这为接下来的工作提供了新的方向。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
新城乡(2018年6期)2018-07-09
小天使·二年级语数英综合(2017年3期)2017-04-01
小天使·一年级语数英综合(2015年8期)2015-07-06
读者·校园版(2015年13期)2015-07-01
