
基于卷积注意力的情感增强微博立场检测
2022-06-07 06:14耿源羚张绍武张益嘉林鸿飞杨亮
山西大学学报(自然科学版) 2022年2期
耿源羚,张绍武,张益嘉,林鸿飞,杨亮
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
随着互联网的快速发展和社交媒体的广泛应用,越来越多的人倾向于在互联网上发表自己对新闻时事、商品优劣等的评论及看法[1]。这些评论往往包含着舆情走向、用户消费习惯等信息,为政府、企业等机构提供了重要的决策依据[2]。立场检测任务旨在挖掘评论中的态度和立场。因此,立场检测任务成为自然语言处理中的重要研究热点之一。另外,基于Twitter数据的立场检测任务[3]SemEval-2016Task6和基于微博数据的立场检测任务[4]NLPCC-2016 Chinese Stance Detection Shared Task公布后,进一步促进了立场检测任务的研究和发展。
立场检测任务的目的是通过分析用户对特定话题的评论,检测用户对该话题的立场倾向性是支持、反对还是中立的[5]。该任务与传统的三分类情感任务相似,但不同的是,立场检测需要结合具体目标话题进行判断,而情感分析则不考虑任何话题;与方面级情感分类任务相比,在立场检测任务中,文本信息不会明确提及具体话题信息。另外,微博立场检测任务中的数据还有着语法随意,文本短小等特点。例如,针对话题“深圳禁摩限电”而言,其相关文本“最反感这些拉客的!还有在机动车道上行驶的”的情感极性是消极的,而且该文本中没有显示出现特定话题信息,无法单独根据文本判断其立场倾向,但结合了话题信息后,检测该文本的立场倾向性是支持的。因此,捕捉文本中与对应话题的相关特征是立场检测任务的重点。
在近期的立场检测研究中,几乎所有的工作都是围绕如何将话题信息与文本信息相结合而展开的。Augenstein等[6]将话题信息和文本信息进行拼接,然后使用BiLSTM(双向长短期记忆网络)对其共同编码以用于分类。Du等[7]和Wei等[8]提出了针对特定目标话题的注意力机制,利用注意力机制有效地捕捉了文本中与目标话题信息有关的部分,从而改善了模型表现。Bai等[9]和Wang等[10]将 CNN(卷积神经网络)抽取的局部信息与注意力机制结合以捕捉与话题相关信息,有效提高了模型预测结果。然而上述方法仍存在不足,其通过CNN模型抽取的局部信息,虽然能显著表示文本特征[11],但是往往会因为缺乏对话题信息的关注,而丢失文本与话题的相关特征,从而导致注意力机制无法完全捕捉文本信息与话题信息相关特征而干扰分类输出,使得任务结果无法进一步提升。
另外,挖掘并结合文本中蕴含的情感信息已被证明有助于提高立场检测的结果[12]。但是由于文本情感倾向和立场倾向存在不一致的情况,如引言中的例子,文本的情感倾向是消极的,而立场倾向是支持的,使得目前中文微博立场检测研究还未充分展开对引入情感信息的探讨。虽然 Sun 等[13]和 Li等[14]通过多任务学习等方法在英文Twitter数据集上引入情感资源尝试解决该问题,但是由于微博立场检测数据与Twitter立场检测数据的标注不同,其中微博立场检测数据仅有立场标签,而没有情感标签,另外由于中文情感资源相对缺乏以及中文与英文存在如句法结构不同等本质语言差异,无法将已有的英文情感增强立场检测方法用于中文立场检测中。
针对由于提取文本特征时缺乏结合话题相关特征,以及忽略了情感信息对立场检测的影响而导致分类效果差的问题,另外考虑到中文立场检测中情感特征与英文立场检测的情感特征存在资源、句法和使用习惯等的差异,无法将英文情感增强立场检测方法直接迁移,因此本文提出基于卷积注意力的情感增强微博立场检测模型(BERT-SECA)。该模型通过卷积注意力将话题信息引入文本特征提取过程,获得文本与话题相关特征的卷积注意力权重,通过情感增强模块中的词语级情感增强和句子级情感增强挖掘文本的局部情感特征和整体情感特征,然后将局部情感特征与卷积注意力权重交互,得到针对话题的情感表示向量,再拼接整体情感特征得到最终的句向量,最后通过多层感知机和Softmax得到立场倾向。
1 相关工作
早期的立场检测研究大多集中于解决在线辩论中的立场问题,大部分研究人员尝试了将人工提取特征与传统机器学习方法相结合的方法,其中人工提取特征包括结构特征[15]、语法特征[16]和语义特征[17]等。
随着社交媒体的快速发展,越来越多的用户更加习惯于直接在社交媒体上发表自己的观点,因此立场检测也广泛用于社交媒体产生的大量文本中,目前已有的立场检测方法主要有基于特征的机器学习方法和深度学习方法。
对于基于特征的机器学习方法,Tutek等[18]提取词汇特征和基于特定任务的特征,利用基于支持向量机(SVM)、随机森林(RF)、梯度提升(GB)和逻辑回归(LR)的集成学习算法对各个特征进行分类预测,得到文本的立场标签。Sun等[19]提取了词汇特征,形态特征,语义特征和语法特征,通过SVM分类器以获得立场倾向性。Dian等[20]融合了多种文本特征,包括词袋特征,话题词与立场词的共现特征等,使用SVM等机器学习分类器对上述特征进行立场分类,取得了相对优秀的结果。
近年来,随着计算机算力的不断增强、神经网络方法的不断完善,以及深度学习方法可以利用多层神经网络自动捕捉文本特征的特点,使得基于深度学习方法的立场检测研究成了新的热点。早期的深度学习相关工作都是以单一的卷积神经网络或循环神经网络为研究模型,其中Vijayaraghavan等[21]通过分别构建字符级和词语级CNN模型以提取文本特征用于分类;Zarrella等[22]采用了LSTM(长短期记忆神经网络)模型,并利用迁移学习将其他领域知识用于立场检测。但是由于这些工作没有考虑文本信息与话题信息的相关部分,因而其结果无法得到进一步的提升。为解决此问题,特定目标的注意力机制被引入,以捕捉文本中与话题相关部分[7-8],使得结果得到改善。Yue等[23]提出了基于两段注意力机制的立场检测模型,通过在文本表示和分类输出两个阶段利用注意力机制,从而使得话题信息与文本信息进行深度的交互。为了深度挖掘文本特征,越来越多的研究采用了多种神经网络集成的方法,Zhang等[24]提出一种基于词向量技术和CNN-BiLSTM的深度融合模型,首先利用卷积神经网络提取文本向量的局部特征,再运用BiLSTM网络提取文本的全局特征以提高微博立场文本分类结果,Yang等[25]提出基于依存语法树的GCN(图卷积神经网络)和BiLSTM获取文本特征的立场检测模型,进一步提高了微博立场检测的结果,另外在英文Twitter立场检测数据集上,Sun等[26]将多种语言结构特征与层次化注意力神经网络结合,并发现自动学习情感信息的重要性,随后利用联合模型同时检测立场和情感[13];Li等[14]受其启发,提出了基于情感和立场的词典的多任务学习立场检测,使得Twitter立场检测任务结果有所提升。
在以上利用多种神经网络集成的立场检测模型中,虽然能够通过深度挖掘文本特征有效增强立场分类,但是由于获取文本特征时,忽略了与话题相关的特征,而导致模型性能不能进一步提升。针对此问题,本文提出卷积注意力以同时关注文本的局部特征和文本与对应话题的相关特征。
立场检测结合情感信息在英文Twitter数据集上已初步尝试[13-14],但由于中文情感资源的缺乏以及中英文语言间本质上的差异,中文微博立场检测无法直接利用已有的情感增强立场检测模型,因此本文从词语级情感挖掘和句子级情感挖掘两个维度挖掘微博立场检测中文本的情感信息,以辅助立场检测任务。另外,Devlin等[27]提出的预训练模型BERT(基于变换器的双向编码器表示技术),能够获得表示包含上下、左右文信息的句向量,通过引入BERT对微博立场检测数据表示,使任务结果得到有效提升[11]。因此本文引入BERT预训练模型对文本信息和话题信息进行编码,提出基于卷积注意力的情感增强立场检测模型BERT-SECA。
2 BERT-SECA模型
本文针对已有的微博立场检测模型存在提取文本特征时,缺乏关注话题相关特征,以及忽略了情感信息对立场检测的影响而导致分类效果差的问题,提出了基于卷积注意力的情感增强微博立场检测模型BERT-SECA,该模型结构如图1所示。其主要分为获取文本与话题的卷积注意力权重和提取情感特征两个部分。首先将话题信息引入卷积注意力层,在获取文本特征的同时关注话题相关特征,从而得到卷积注意力权重;然后将提取后的情感特征与卷积注意力权重交互,通过多层感知机和Softmax分类以得到立场类别。接下来将介绍各部分实现的具体步骤。
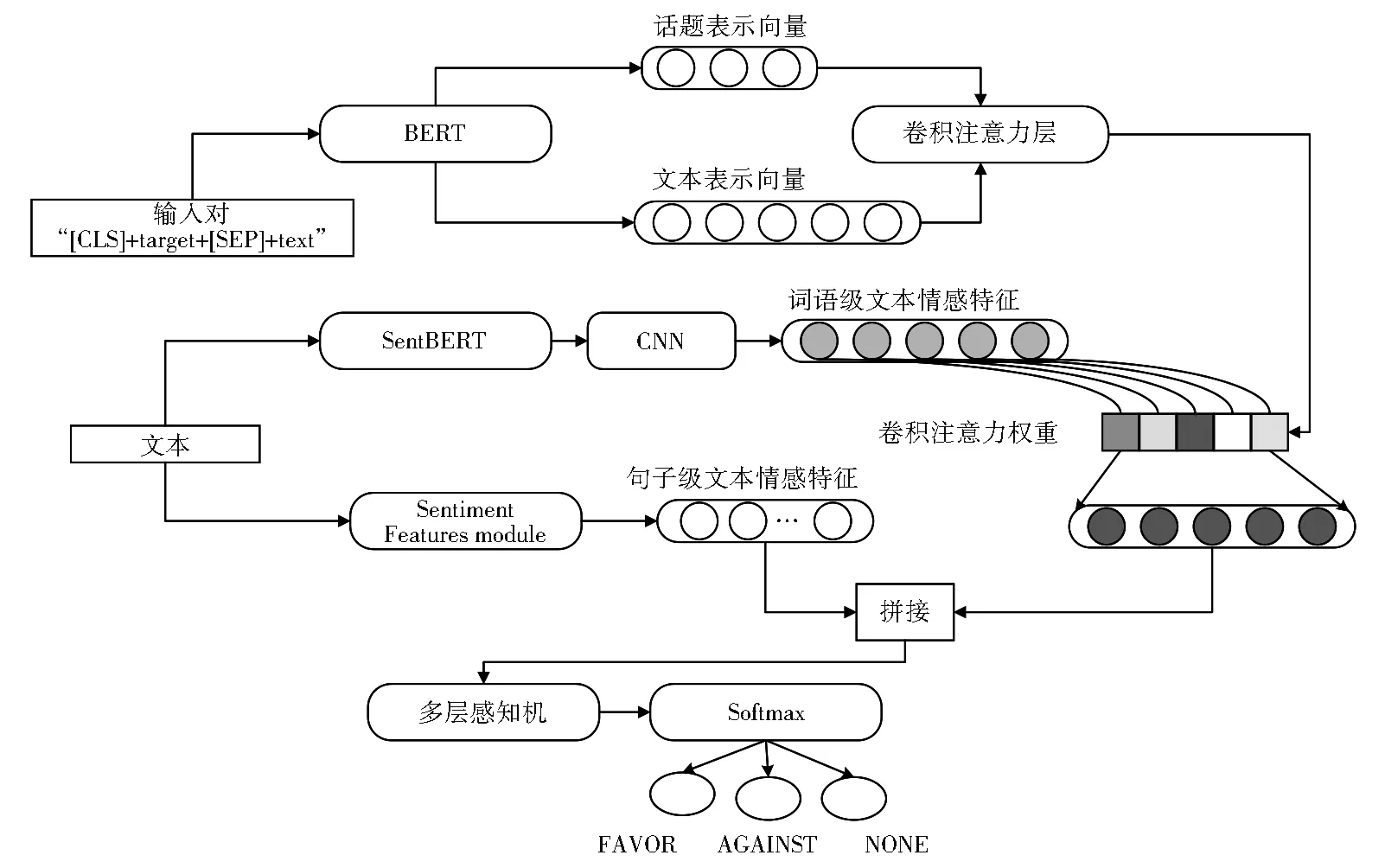
图1 BERT-SECA模型的结构Fig.1 Structure of the BERT-SECA model
2.1 卷积注意力层
目前已有的立场检测模型通过集成卷积神经网络以抽取文本的局部信息,虽然能显著的表示文本特征[11]以有效改善模型性能,但是由于提取特征时,缺乏对话题信息的关注,从而丢失了文本信息和话题信息的部分相关特征,而导致模型在后续分类表现不佳,而使得其性能到达瓶颈。为了解决此问题,本文提出卷积注意力,以在抽取文本局部特征的同时,关注与话题相关的部分,得到高度关注话题的卷积注意力权重,构建过程如图2所示。

图2 卷积注意力层的构建过程Fig.2 Construction process of convolutional attention layer
相较于Yue等[23]为获取词向量使用的word2vec模型和 Li等[14]使用的 fastText模型,本文所采用的预训练模型BERT是基于Transformers的多层双向编码表示模型,能够获得深层双向表示,从而增强文本表示的语义信息。本文以话题信息拼接对应文本信息的信息对作为输入信息 Inputp_air={G,X},其中文本信息表示为 X={x1,x2,…,xi,…,xm},m 表示文本的长度,xi表示为文本中的第i个token,G={g1,g2,…,gi,…,gn}代表该文本对应的话题信息,n表示话题信息的长度。利用BERT对话题信息和文本信息进行编码,得到对应的上下文表示 hG,hX:

n为话题信息的长度,m为文本信息的长度,而d为词向量的维度。
为了将话题信息引入到提取局部特征的过程中,首先将话题中的词向量进行平均作为话题向量hv∈Rd,然后将其以文本长度扩充后,与文本向量拼接得到hP∈Rm*2d,从而在抽取局部特征时,充分与话题信息交互。利用卷积过滤器 WP∈Rk*2d,偏差项 bP∈R,激活函数elu[28],对其进行卷积操作如公式3所示。另外由于通过多个卷积过滤器可以抽取多种文本局部特征,本文采用T个卷积过滤器以更多地抽取文本特征和与话题相关特征。
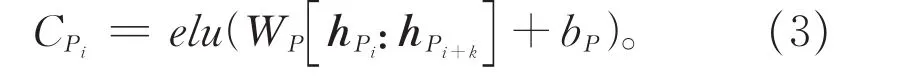
为了获得文本中每个字符与话题信息的相关特征,在卷积操作时,通过padding操作,使得卷积所得到的特征向量

与输入文本有着相同长度。由于最大池化策略优于其他池化策略[29],本文在获取文本和话题相关特征后,为最大化文本中每个字符与话题的相关特征并且使模型后续更加关注与话题相关的特征,通过最大池化策略和归一化后获得卷积注意力权重。由公式4和5可以获得文本中每个字符与话题信息的卷积注意力权重αi。

其中表示特征向量CP转置后的列向量。
本文不仅考虑了与文本与话题相关的特征,而且同样关注了文本信息本身的特征,从而使最终的句向量包含更多特征以泛化模型。为抽取文本本身的特征,将通过BERT编码的文本信息hX以T个卷积过滤器WX∈Rk*d,偏差项bX∈R进行卷积操作如公式6,然后将该特征信息与卷积注意力权重点乘后得到特征表示r={r1,r2,…,ri}∈RT*m,其中ri的计算过程如公式7所示,通过最大池化策略来获得最终的句子表示向量Q={Q1,Q2,…,Qi}∈RT,Qi的计算过程如公式8所示。
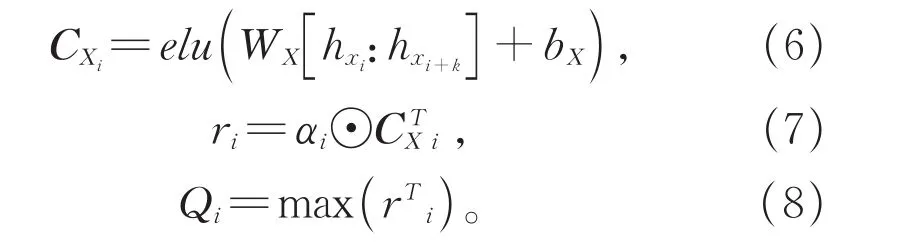
2.2 情感增强
用户在表达对特定话题所持立场时,其中往往会伴随着对该话题的情感,该情感信息与立场倾向性有一定的相关性,因此识别文本中的情感信息对立场检测任务是有促进作用的[12]。例如,针对话题“春节放鞭炮”,其相关微博“春节真美好啊!有红包,还可以放鞭炮”,根据其中的情感正向词“真美好”可以判断该微博的情感是正向的,当结合话题时,可以推断出用户对于话题“春节放鞭炮”的立场是支持的,因此通过情感词与话题信息的相关性可以促进立场检测[14]。但是由于文本的情感倾向性和立场倾向性并不是一直保持一致,所以不能简单地提取文本的情感特征以辅助立场检测。虽然在英文Twitter立场检测任务中,通过多任务等方法以同时判断情感和立场有助于缓解该问题,但是由于中文情感资源相对缺乏,且中英文语言间存在句法、使用习惯等本质区别,所以无法将Twitter立场检测中的方法在微博立场检测中有效利用。
本文通过词语级情感增强和句子级情感增强以解决上述问题,首先抽取词语级的情感信息并与卷积注意力权重交互实现针对话题信息的情感增强,然后拼接句子级的情感信息以全面结合情感倾向和立场倾向。接下来将详细介绍情感增强的具体步骤。
2.2.1 词语级情感增强
文本中的情感信息,如2.2章节例子中话题“春节放鞭炮”的相关微博中的“真美好”,它的情感倾向是积极的,该情感极性是无关话题的,不会随着话题的改变而改变,因此可以通过外部数据训练得到的情感预训练模型,获得微博立场检测数据中的词语情感表示。
首先通过公开的微博情感分类数据训练得到情感分类模型,将微博情感分类数据表示为S={S1,S2,…,Si},利用 BERT 对其编码得到上下文表示 hS={hS1,hS2,…,hSi},计算过程与公式1相似。SCLS作为文本信息的聚合表示,将其输入到多层感知机层和Softmax分类层后,得到情感倾向性SY:

其中,BertPooler为BERT中的池化函数。
经上述训练后得到的情感BERT模型,(SentBERT),不仅可以表示文本语义信息,而且可以一定程度上表示文本的情感信息。将微博立场检测的文本信息通过SentBERT模型进行编码,得到的上下文表示:

将该上下文表示hsentX替代公式6中的hX,得到特征向量CsentX,再通过公式7、8,使得带有情感信息的文本表示与卷积注意力权重交互,实现针对话题的词语级情感增强,最终得到带有情感的句子表示向量Qsent。
2.2.2 句子级情感增强
为了避免过多地关注局部特征而影响判断,本文通过拼接句子级情感信息以更加全面地进行检测。对于微博立场检测中的文本信息X={x1,x2,…,xi,…,xm},为获得其句子级情感信息表示 Xemo,受 Zhang 等[30]的启发,本文采用了情感分类特征、情感词特征和情感强度特征。
对于情感分类特征,为了丰富语言倾向性表示,本文同时提取了细粒度情感分类特征和粗粒度情感分类特征。本文通过公开的细粒度情感分类器判断输入的文本含有某类细粒度情感的概率,该细粒度情感包括积极情绪:喜爱、愉快、感谢;消极情绪:抱怨、愤怒、厌恶、恐惧、悲伤以及中性情绪。给定情感分类器f和文本信息X,假设输出维度为Df。因此细粒度情感分类特征。粗粒度的情感分类特征针对的是文本的正向得分和负向得分,可通过字典或公开的工具得到文本的粗粒度情感分类特征为输出维度,通常Ds=1。
对于情感词特征,基于公开可信的情感词典,针对其中存在的每种情感计算情感词特征。假设情感词典中有Dζ种情感,表示为Z={ζ1,ζ2,…,ζDζ},若存在情感 ζ∈Z,情感词典则提供该情感对应的情感词语列表Ωζ={wζ,1,wζ,2,…,wζ,Lζ},其 中Lζ是 情 感 词 语 列表 长度。针对情感ζ,首先计算文本中词语对于该情感的得分γ(xi,ζ),如果该词语属于对应的情感词语列表Ωζ,在计算时,不仅要考虑该词语出现的频率,而且要同时考虑其前面存在的程度词和消极词的权重,它们的权重可以通过情感词典获得,如在计算“我很不高兴”文本中对于“高兴”情感得分,需考虑位于“高兴”前的“很”(程度词)和“不”(消极词)的权重,计算过程如下:
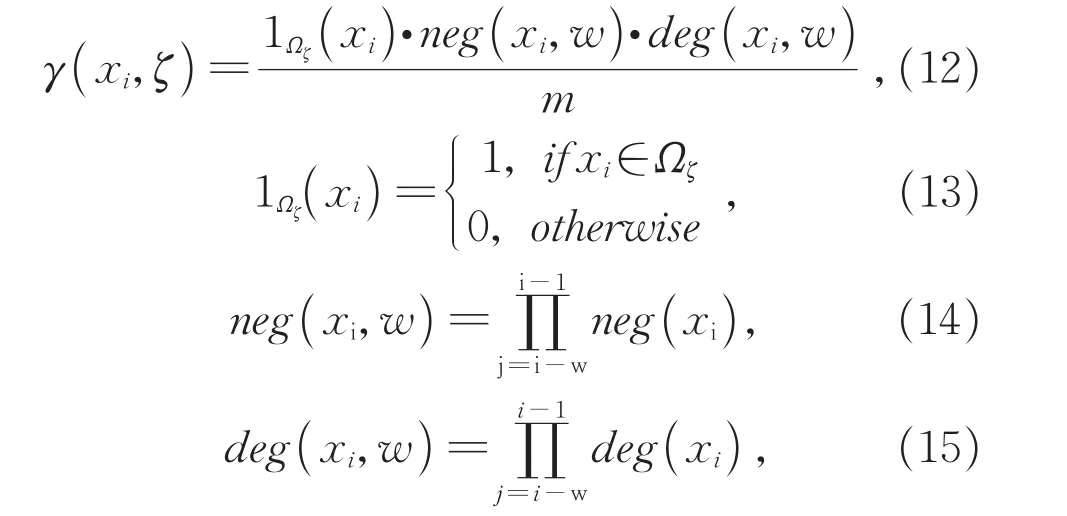
其中w为词语xi查找程度词和消极词的窗口大小,m为文本信息的长度,neg(xi),deg(xi)分别为消极词权重和程度词权重。
然后,通过将各词语的情感得分求和,可得到针对情感ζ的句子情感得分γ(X,ζ),最后将每种情感的句子情感得分拼接得到文本情感词特征
针对同属于一类情感的词语,存在表达的情感强度不同的情况,本文通过情感强度特征将情感强度结合以充分表示情感信息。比如“激动”相较于“开心”有更高的强度来表达情感。该特征的提取过程与情感词特征提取类似,不同的是在此过程中结合了强度特征,计算过程如下所示:

提取到词语的情感强度特征后,相似于句子的情感词特征提取过程,可得到句子的情感强度特征
最终,通过拼接上述所得特征以得到句子级情感信息表示Xemo:

2.3 立场分类层
将针对话题进行词语级情感增强后得到句子表示向量Qsent与句子级情感信息Xemo拼接后,经过多层感知机和Softmax得到最后的预测结果,计算过程如下:
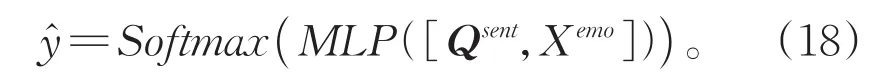
在模型训练时,利用交叉熵损失函数作为目标函数如公式19所示,通过最小化该目标函数以获得最佳网络参数。

其中N为样本数目,C为类别数,为真实的立场标签,代表第i个样本是否属于第j个类别,表示预测的立场概率。
3 实验
3.1 实验数据和评价指标
本文采用NLPCC-2016中文微博立场检测任务的数据集①。该数据集已标注立场倾向的数据接近3 000条,未标注的数据接近1 000条,区别立场的标签为:“FAVOR”“AGAINST”“NONE”。数据集中涉及的话题有:“iPhone SE”“俄罗斯在叙利亚的反恐行动”“开放二胎”“春节放鞭炮”“深圳禁摩限电”,其中每个话题包含600条训练数据和200条测试数据。数据集的分布如表1所示。

表1 NLPCC数据集分布Table 1 Distribution of NLPCC dataset
本文采用的评价指标是根据NLPCC-2016的任务要求,将Favg作为评测指标,计算公式如下:

其中Ffavor和Fagainst分别是立场标签为“支持”和“反对”的F1值,其计算过程如下:

其中P和R分别是精确率和召回率。
3.2 实验参数设置
针对每个话题,本文将其训练集打乱后,随机选取15%的数据作为验证集,迭代次数epochs=150,以调整参数获得最优模型,再利用最优模型对测试集进行预测,得到最后的实验结果。本文采用Pytorch 框架,选用 Cui等[31]提出的 chinese-bertwwm中文预训练BERT模型对文本信息进行编码表示。提取句子级情感信息时,利用公开的百度AI情绪分类器获得细粒度情感分类特征,利用BosonNLP获得粗粒度情感分类特征,利用Hownet[32]和大连理工大学情感词汇本体库[33]获得情感词特征和情感强度特征,各特征维度根据具体的词典而定。该模型中的特征维度和其他实验参数如表2所示。

表2 模型参数设置Table 2 Settings of model parameter
3.3 实验结果与分析
为验证本文所提出的BERT-SECA模型的有效性,将模型在5个话题单独训练的结果与下列强基线模型的结果进行对比:
Dian[20]:该模型通过对比不同立场特征的实验结果后,对立场特征进行融合的机器学习
①http://tcci.ccf.org.cn/conference/2016/模型。
TAN[7]:该模型通过BiLSTM 提取文本特征,利用注意力机制捕捉了文本与话题的相关特征,实现了针对特定话题注意力机制的深度学习模型。
ATA[23]:该模型是在 TAN 模型基础上,利用注意力机制分别将话题信息和文本信息在表示和分类两个阶段相结合的两阶段注意力深度学习模型。
BCC[10]:该模型是通过BERT得到句向量,再将话题信息和文本信息通过CNN交互的深度学习模型。该模型目前取得了该任务的最优结果。
CBL[24]:该模型通过CNN获得文本局部特征,再结合BiLSTM捕捉的全局信息以进行立场检测。
BGA[25]:该模型通过BiLSTM获得句子特征,再根据依存句法树构建GCN,结合注意力机制以检测文本立场。
BERT-SECA:该模型为本文提出的模型,基于卷积注意力的情感增强立场检测模型。由表3的实验结果可以发现,针对五个话题训练结果的均值而言,由于CBL利用CNN-BiLSTM仅挖掘了文本特征,而未考虑话题信息在立场检测中的作用,从而获得了最差的实验结果,TAN模型考虑了话题对于立场检测的影响,在CBL的基础上提高了3.0%;Dian模型充分考虑了针对话题的文本的立场特征,相对于TAN模型取得了较大的提升6.1%;而ATA模型在表示文本信息和分类层两个阶段都引入了注意力机制,使得话题信息和文本信息相对于TAN模型有更充分的交互,从而更加精确地捕捉两者的相关部分,取得了5.1%的提升,但是它同样忽略了文本本身的立场特征,所以结果稍差于Dian模型;BGA模型在结合话题的基础上,利用GCN充分捕捉了长距离词语的特征信息,将结果提高了0.4%;而BCC模型引入了BERT对文本进行表示,丰富了文本的语义表示,另外通过CNN模型提取文本特征,并与话题进行交互,取得了目前最优的结果74.4%。本文所提出的模型BERT-SECA充分关注了文本与话题相关特征,因此相较于CBL模型提高了15.8%,而对于使用BiLSTM+Attention架构的TAN和ATA,得益于BERT的深度语义表示以及卷积注意力更加关注话题与文本局部的相关特征,使得结果分别提高了12.8%、6.7%,而相对于Dian,BCC,BGA,本文提出的BERT-SECA还通过引入了情感信息以增强立场检测,因此分别提高了7.7%,6.3%和5.1%。

表3 五个话题分开单独训练的实验结果Table 3 Experimental results of separate training on five topics
综上,BERT-SECA相对于各个强基线模型分别提高了15.8%、12.8%、6.7%、6.3%和5.1%,证明了同时捕捉文本特征和关注话题相关特征的有效性,以及挖掘情感信息在立场检测任务中重要性。而针对具体话题而言,BERT-SECA模型通过情感增强与卷积注意力交互实现了针对话题的共同作用,在“春节放鞭炮”“俄罗斯在叙利亚的反恐行动”“开放二胎”“深圳禁摩限电”四个话题上获得了当前的最优结果,相较之前的最优结果,分别提升了5.6%,5.3%,1.3%,3.8%。对于“iPhone SE”话题而言,模型在提取话题信息与文本信息相关特征时,由于英文字符与中文字符的相关性不大,并且对于文本中不出现“iPhone SE”话题的文本,更无法判断文本针对该话题的立场,从而导致该话题的结果稍差于TAN模型,但是相对于Dian模型、ATA模型、CBL模型、BGA模型和BCC模型,在此话题上分别提高了9.5%,11%,21.6%,7.8%和7.9%。
3.4 消融实验
为了验证BERT-SECA模型中各部分的有效性,在五个话题数据集上进行了下列实验。
BERT-SECA:本文所提出的模型,其中通过卷积注意力来获得话题和文本相关信息,通过情感增强以获得更丰富的语义表示。
BERT-CNN:为验证抽取文本特征的同时,关注与话题的相关特征的有效性,去掉BERTSECA中的情感增强部分,然后将卷积注意力替换为普通的CNN模型。
BERT-CA:为验证本文提出的卷积注意力的有效性,去掉BERT-SECA中情感增强的部分,仅保留卷积注意力部分。
BERT-SE:为验证本文提出情感增强部分的有效性,去掉BERT-SECA中的卷积注意力,仅仅保留情感增强部分。
BERT:为验证本文所提出模型各部分的有效性,构建用于微博立场检测的基线BERT模型。将话题信息和文本信息拼接输入到BERT中进行分类,为每个话题微调一个BERT分类模型。
由表4中的消融实验结果所示,BERTCNN模型由于仅仅关注了文本局部特征,使得结果稍差于BERT模型,而BERT-CA模型相对于BERT-CNN提高了2.2%,说明了在提取局部特征时,同时关注话题信息的有效性。BERT-CA模型对于BERT模型提高了1.4%,证明了本文提出的卷积注意力能够有效地同时关注文本特征和与话题相关特征。BERT-SE相对于BERT模型同样有所提高,其证明了挖掘文本情感信息对于立场检测的重要性,同样证明了本文提出的情感增强策略能够有效捕捉中文文本的情感特征,但是由于存在情感倾向和立场倾向不一致的情况,使得提高仅有0.5%,这说明仅仅简单地增加情感信息并能显著改善模型性能。BERT-SECA相对于BERT提高了2.4%,证明本文将卷积注意力情感信息针对话题结合的策略有效地缓解了情感倾向和立场倾向不一致的情况。

表4 消融实验结果Table 4 Results of ablation experiments
4 结论
本文提出了基于卷积注意力的情感增强微博立场检测BERT-SECA模型,该模型构建卷积注意力层以同时捕捉文本特征和关注文本与话题的相关特征,构造情感增强模块挖掘文本情感特征,以辅助立场检测任务,利用其中的词语级情感增强和句子级情感增强分别获得局部情感特征和整体情感特征,通过局部情感特征和卷积注意力权重针对话题交互,再拼接整体情感特征以解决情感倾向和立场倾向存在不一致的情况。
BERT-SECA模型在NLPCC-2016微博立场检测数据集上取得了目前最好的任务结果,证明了在立场检测任务中,同时捕捉文本特征和关注文本与对应话题相关特征的有效性,以及挖掘并结合文本情感特征对于立场检测的重要性。通过消融实验结果证明,BERT-SECA模型中的卷积注意力能够同时捕捉文本和关注文本与对应话题的相关特征,使得结果得到提升,其同样证明了该模型将情感增强提取的情感特征与卷积注意力针对话题结合的策略,有效地缓解了情感倾向与立场倾向存在的不一致情况。
在未来工作中,将探索中英语言之间本质的语法结构、组织类型和语义连贯方式的差异,以研究跨语言的立场检测任务;另外结合用户的社交网络信息、背景画像信息等信息,以探究多模态化的立场检测。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
武术研究(2020年3期)2020-04-21
中外文摘(2019年20期)2019-11-13
文萃报·周五版(2019年5期)2019-09-10
第二课堂(课外活动版)(2016年2期)2016-10-21
中学英语之友·高一版(2008年10期)2008-12-11
