
基于机器学习的航空公司乘客满意度预测
2022-06-02 04:35刘宇波
科技创业月刊 2022年4期
刘宇波
(湖北大学 计算机学院,湖北 武汉 430061)
0 引言
满意度是一种心理状态,是指一个人对一段关系质量的主观评价。航空公司对于乘客满意度的管理尤为重要,对乘客满意度进行测评,可以分析影响满意度的关键因素、衡量当前乘客的满意度水平、针对产品以及服务做出改进策略。通过构建满意度预测模型,可以对乘客进行市场细分,对于不同乘客推出不同的服务产品,充分挖掘大数据,提高乘客满意度。
随着计算机技术的发展,诸多学者采用机器学习等人工智能方式对顾客满意度进行预测。范晓婷[1]通过对头部企业“口碑”平台的交易数据进行挖掘分析,运用机器学习理论搭建顾客满意度预测模型,并对不同算法的预测结果进行对比分析。章凯兵[2]基于yelp官方用户和商户信息数据,运用LSTM模型进行用户偏好挖掘,最后运用人工神经网络对用户满意度进行预测。陈雪松等[3]通过对36名学生进行实验观察收集数据,然后运用GBDT模型和马尔代夫模型设计了图像搜索环境下的用户满意度预测模型。
1 数据分析
1.1 数据集介绍
本文采用kaggle网站公开数据集。其中包含了10万余条乘客数据,23种特征。具体如下:Satisfaction:乘客满意或不满意,待预测项;Gender:性别(男,女);Age:年龄;Type of Travel:飞行目的(个人旅行、商务旅行);Class:乘客飞机上的旅行等级(商务、环保、环保加);Flight Distance:本次行程的飞行距离;Seat comfort:座椅舒适度满意度(0:不适用;1-5);Departure/Arrival time convenient:出发/到达时间方便的满意度;Food and drink:食品和饮料的满意度;Gate location:gate位置的满意度;Inflight WIFI service:机上WIFI的满意度;Inflight entertainment:机上娱乐的满意度;Online support:线上支持满意度;Ease of Online booking:在线预订满意度;On-board service:机上服务满意度;Leg room service:腿部客房服务的满意度;Baggage handling:行李处理满意度;Checkin service:值机服务满意度;Cleanliness:清洁满意度;Online boarding:线上登机满意度;Departure/Arrival Delay in Minutes:出发/到达时延迟分钟数。
1.2 数据预处理
利用padas库将数据导入,随后用info函数查看数据的总体信息,该函数可以查看所有特征、类型,以及数据缺失情况,如图1所示。运行代码后发现只有到达时延迟分钟数存在缺失值,于是采取中值填充的方法弥补缺失值,代码如下:data['Arrival Delay in Minutes'].fillna(data['Arrival Delay in Minutes'].median(axis=0),inplace=True)。
然后要进行特征分类,分成数值特征和类别特征。年龄、飞行距离、出发/达到延迟分钟数四种都属于数值特征,除了上述四种以及预测目标满意度外,剩下的18种属于类别特征。将类别特征的类型进行修改,修改完成后再次查看数据信息,如图2所示,所有特征类型已经修改完成,无缺失值。
1.3 数据可视化
采用matplotlib库和seaborn库对数据进行可视化,以便能够更直观地观察特征之间的关系,挖掘数据信息。
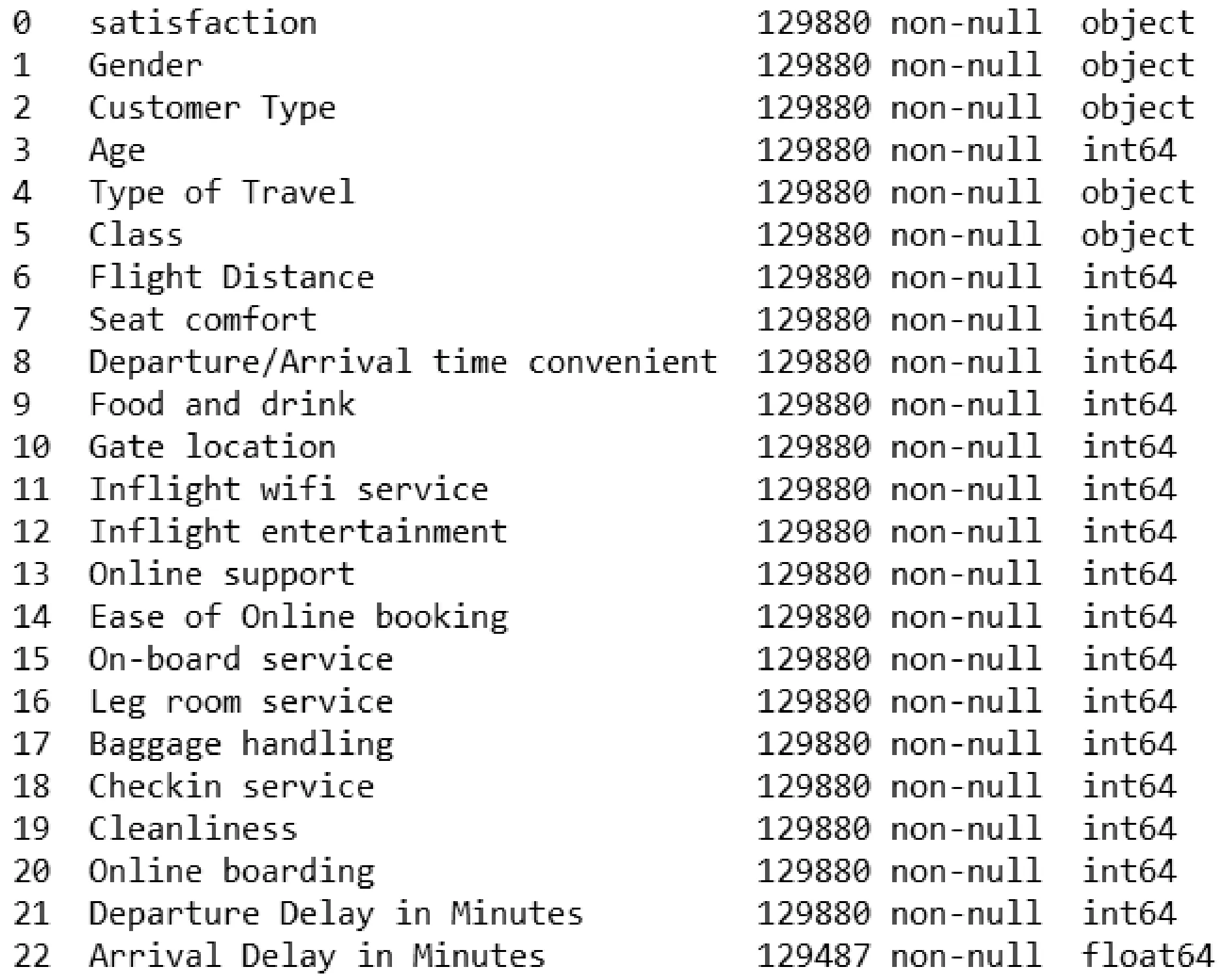
图1 数据总体信息
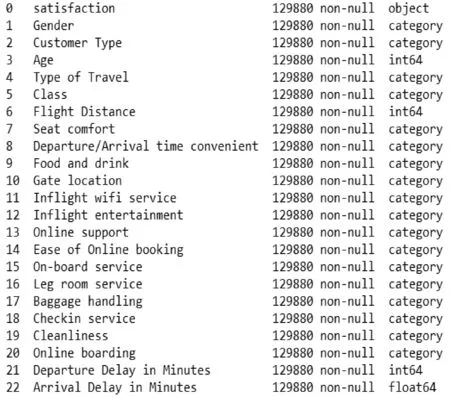
图2 修改后数据信息
(1)查看待预测目标:满意乘客的比例,如图3。发现满意与不满意的人数相差不大,趋近于平衡,分类可以看作均衡分类。

图3 满意度比例扇形图
(2)用热力图查看数值特征之间的联系,如图4,横轴为到达延迟分钟数,纵轴代表出发延迟分钟数。发现出发延迟分钟和到达延迟分钟的相关度很高,高达0.96,于是用散点图分析之间的联系,如图5。可以看出,这些点大部分呈直线排列,说明二者间有很大的线性相关性。而这也是符合逻辑的,因为一旦飞机起飞时延误了,那么它的落地时间也会很大概率延误。
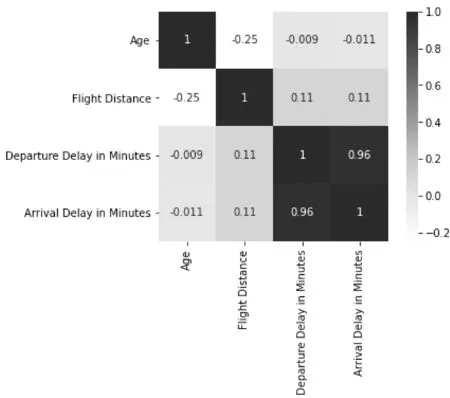
图4 数值特征热力图
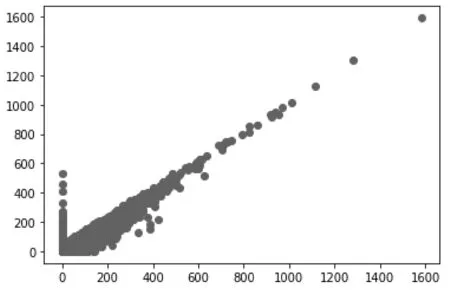
图5 出发和到达延迟分钟数散点图
(3)查看类别特征和满意度之间的关系,由于篇幅原因选取部分图片展示,如图6,每张图的下方有特征名。
2 特征工程
特征工程是机器学习建模中重要的一个环节,特征处理结果很大程度上决定模型拟合度根据上述特征分类结果,对数值特征和类别特征分别进行处理。
2.1 类别特征处理
对于类别特征,最常用的处理方式是将其进行编码。编码方式有很多种,本文对数据集中的类别特征主要采用独热编码和二分编码,类别数有两种的特征采用二分编码,类别个数两个以上的采用独热编码。
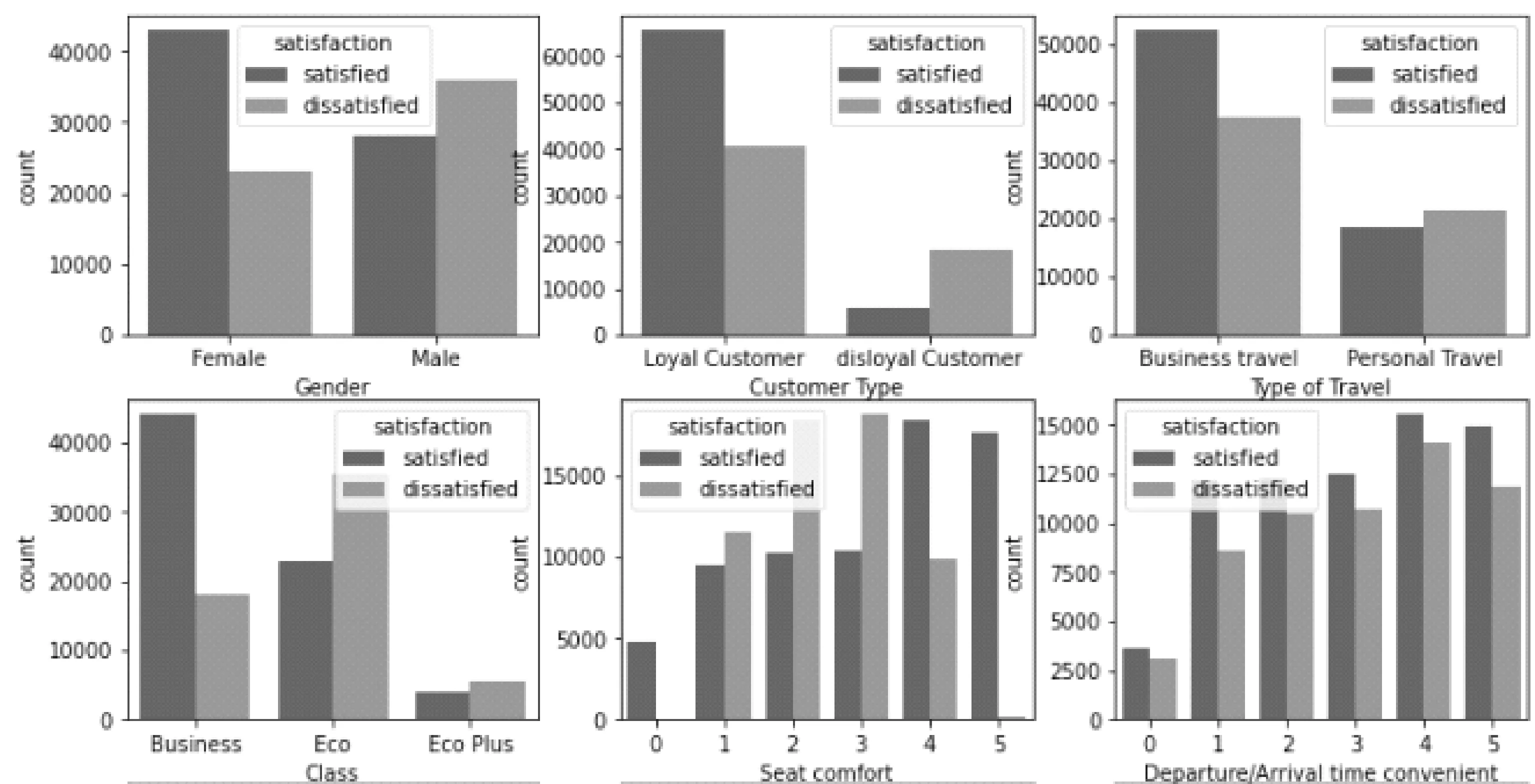
图6 类别特征和乘客满意度的关系
首先针对类别特征的类别个数进行分类,借助describe函数,将类别个数为2或大于2的分开。结果显示,类别个数为2的特征有性别、乘客种类以及飞行目的,剩下的特征类别个数都大于2。随后对这两类特征进行编码,类别个数为2的用二分编码将两种类别编为0和1,其余特征用独热编码,采用了pandas库中的get_dummies函数进行特征提取。
2.2 数值特征处理

2.3 后续准备
将两类特征处理完后,用concat函数合并,将要预测的目标顾客满意度进行编码处理,将不满意和满意编为0和1,方便后续的建模预测。
3 建模及结果分析
将处理完成的数据用train_test_split函数分为训练集和测试集,其中测试集比例为0.2。随后用机器学习的算法对训练集进行训练,然后预测结果并和测试集进行比较。采用以下5种算法进行建模:knn算法、决策树算法、随机森林算法、gradientboosting算法和catboost算法,随后采用了投票法将效果较好的模型进行融合,建模训练比较结果。
对于每种模型,都用了七种评价指标,分别为:准确率(accuracy)、精确率(precision)、召回率(recall)、f1值、roc曲线下面积(roc_auc)、均衡准确率(balance_accuracy)和混淆矩阵(confusion_matrix)。表1是模型的训练结果,保留了小数点后4位小数。vot是由gb、rf、cat进行投票融合的模型。
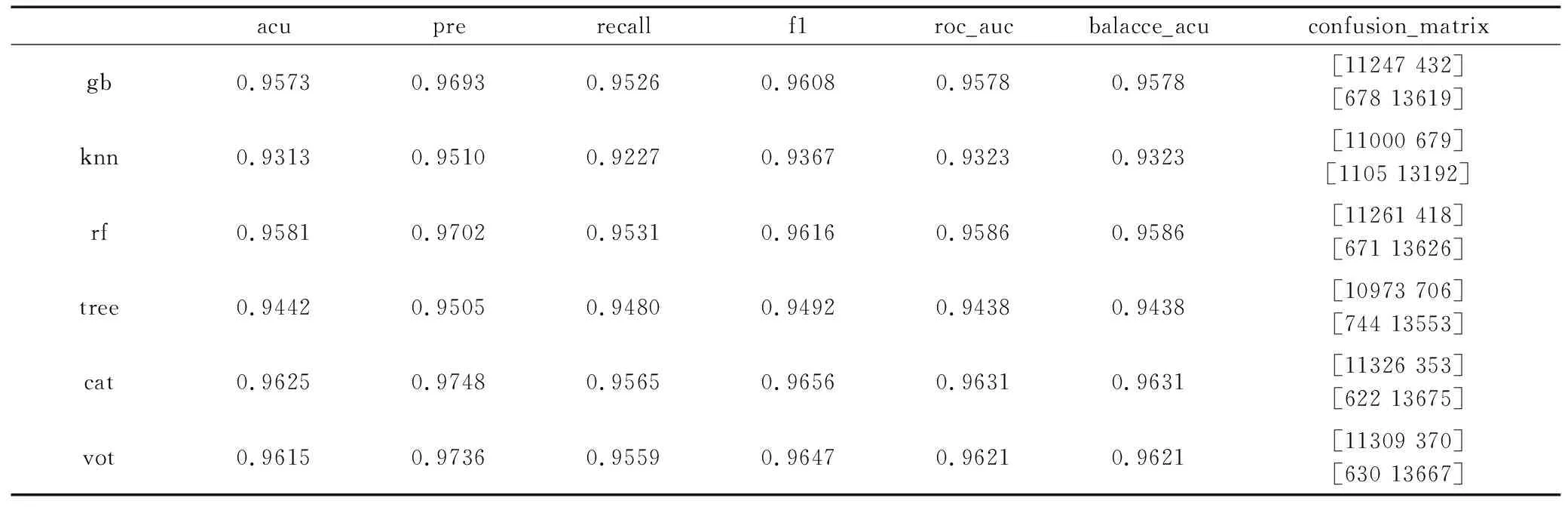
表1 模型训练结果
根据结果,这些分类器的准确度都在90%以上,具体为:gradientboosting算法:95.73%;knn算法:93.13%;随机森林算法:95.81%;决策树算法:94.42%;catboost算法:96.25%;模型融合:96.15%。其中,catboost算法各项指标最高,准确度达到了96.25%,融合模型的准确率次之。knn以及决策树算法均低于95%。在这6种模型中,除了knn和决策树,其他4种都属于集成算法,因此这可能是导致它们的准确度更高的原因之一。在训练中,仅仅对gradientboosting算法和catboost算法的参数进行了微调,而其他的算法都选择了默认参数,这也是导致预测结果不同的因素。在第二章的特征工程中如果采取不同的方式处理数据,可能也会对结果产生影响。
4 结论
虽然结果有些许差异,但本文几种模型的表现都较好,其中以catboost算法最优。还有许多分类算法在本文并没有提及,比如svm支持向量机,集成算法中的xgboost算法等。航空公司可以根据本文的数据及结果,对模型进行改进或者使用更多不同的算法进行建模,对算法参数进行调整,以得到更优性能的模型,也可以在本文机器学习基础之上采取深度学习算法,以得到更高的准确率。对乘客满意度进行更为深入的预测研究,以便提前制定策略,增加客流量。
猜你喜欢
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
小学生学习指导(中年级)(2021年12期)2021-12-30
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
文苑(2019年24期)2020-01-06
今日农业(2019年16期)2019-01-03
疯狂英语·新读写(2018年3期)2018-11-29
微型计算机(2009年4期)2009-12-23
