
基于改进YOLOv3算法的挖掘机检测方法
2022-05-31 07:52周斌,苏鹏,高鹏
数字制造科学 2022年2期
周 斌,苏 鹏,高 鹏
(武汉理工大学 机电工程学院,湖北 武汉 430070)
近年来,西气东输工程中积极采用自动化的管理措施,以降低工人的工作强度,并及时发现西气东输管道系统存在的安全隐患[1]。在西气东输油气场站的管道沿线存在第三方施工,其中最大的威胁就是施工方的工程挖掘机非正常施工时对油气管道的误破坏。因此,在这种环境下对具有自动识别检测工程挖掘机功能的智能监控系统有着迫切的需求。
在智能监控的发展中,对目标物体的检测是研究重点。近年来,随着深度学习技术的快速发展,尤其以卷积神经网络为代表,将深度学习和计算机视觉相结合,使得目标检测的准确性和实时性不断提升。基于深度学习的目标检测框架利用卷积神经网络从大量的图像数据中学习特征,从而能更好地刻画数据内在的丰富信息,并且此类网络在一个模型中融合了特征提取、特征选择和特征分类,提高了对图像特征的辨识力,使其在定位和分类的准确度上明显优于基于传统图像处理的目标检测方法,成为目前处理目标检测任务的研究热点[2]。其中应用较为广泛的目标检测方法主要可以分为两类:一类是基于候选框的目标检测算法,如R-CNN(region convolutional neural networks)[3]、Fast R-CNN(fast region convolutional neural networks)、Faster R-CNN(faster region convolutional neural networks)[4]等,这类算法首先获取图像中可能存在目标的子区域,接着将所有的子区域作为输入,并通过深度卷积神经网络提取目标特征,最后进行类别检测和边框修正;另一类是基于回归位置的目标检测算法,如SSD(single shot mutibox dectecter)[5]、YOLO(you only look once)[6]系列等,此类算法只使用一个卷积神经网络便可以在整个图像上实现对目标的定位和类别概率的预测,网络结构相对于第一类目标检测算法简单,并且能够实现端到端的优化,使检测速度有了很大的提升,具有对视频图像进行实时处理的功能。
在油气场站中,当工程挖掘机误进入危险区域,智能监控系统能够实时检测到挖掘机位置,并发出报警信号。因此笔者采用YOLOv3算法为工程挖掘机检测的基础框架,并在提高检测精度和防止漏检问题方面提出改进设计。
1 YOLOv3算法
2015年,Joseph Redmon等提出了YOLO第一代算法,在2017年和2018年期间,Redmon等人又分别提出了YOLOv2[7]和YOLOv3[8],增强了检测精度与速率,并且在数据集上的mAP(mean average precision)率得到大幅度提高。
在YOLO算法中,不再采用Faster R-CNN中先利用RPN(region proposal network)网络找出目标候选区域,再去对区域内的物体进行识别的方式,而把整幅图的目标检测视为回归问题,直接将图像输入一个网络层,就可以得到图像中所有待检测目标的位置和目标类别,直接输出检测框和类别概率。从YOLOv2开始,借鉴Faster R-CNN的思想预测bounding box的偏移,引入了anchor box来预测bounding box,解决了YOLO中一个网格只能预测一个类别的弊端。并在YOLOv3中实现了多尺度预测,在满足一定实时性的基础上,进一步提高了小物体的检测精度。
YOLOv3网络结构如图1所示。不同于YOLOv2,YOLOv3采用Darknet-53作为目标检测框架的backbone,用于提取输入图像的特征。YOLOv3能够输出3种尺度的特征图,其中尺度2和尺度3,通过卷积块与上采样层的方式实现,3个尺度分别预测不同大小的目标物体。目标物体的中心存在于哪个一个网格中,就采用这个网格来预测该目标。YOLOv3设定每个网格单元预测3个bounding box,同时每一个bounding box都需要预测bounding box的位置信息(x,y,w,h)和置信度(confidence)。然后采用非极大值抑制算法(non-maximum suppression, NMS),去除置信得分较低的bounding box,保留置信得分较高的边界框为目标的检测框。
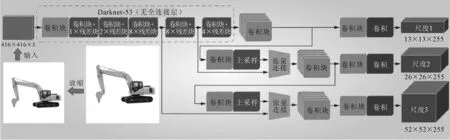
图1 YOLOv3网络结构图
2 YOLOv3模型改进
2.1 使用K-means++算法得到anchor box
在原作者的YOLOv3框架中,9个anchor box值是通过K-means聚类算法[9]对COCO(common objects in comtext)数据集中的20类物体的形状比聚类学习得到的,这9个anchor box的数据为:(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90)、(156,198)和(373,326)。对于文中的目标对象工程挖掘机,不宜再使用原本的anchor box值,需要对其进行改进,通过聚类算法得到适合工程挖掘机的anchor box数据。在原有框架中的K-means算法有一个不足,即最开始的K个划分类别的聚类中心是随机产生的。一般来讲,对于绝大多数数据集,最初聚类中心点选择的不同一般都会产生不一样的聚类结果。为了避免这种随机情况,使用对K-means算法优化后的K-means++算法。K-means++算法中的第一个聚类中心点是随机抽取的,在选择之后的聚类中心点时,优先选择相隔最远的中心点,直到K个聚类中心全部找出,最后对这K个聚类中心使用K-means算法进行数据点分类。
K-means++算法相比于K-means算法只是在聚类中心点的选择上不同,前者选择了更加符合样本规律中相隔最远的点,这样会更合理,使得数据在聚类时更容易收敛,最后的分类效果也会更好。同时,聚类求anchor box的目的是使其与邻近的真实框有更大的IOU(intersection over union)值,IOU表示真实标注框与网络最终产生的预测框的交并比,用来衡量预测边界框的准确性。因此在进行K-means++聚类的过程中,将算法中找出欧式距离最大的步骤更改为找出使distance(box,centroid)最大的聚类中心。其计算公式如下:
Distence(box,centroid)=1-IOU(box,centroid)
(1)
式中:box为某个类别的真实标准框;centroid为聚类中心框。
为了保证聚类的数据更加一般化,重复K-means++算法3~4次,直至相邻两次的聚类中心点变化不大。K-means++算法迭代结束后,根据聚类的结果统计得到一组工程挖掘机的anchor box值为(27,23)、(78,45)、(94,89)、(107,71)、(136,96)、(203,138)、(257,157)、(324,247)和(375,201)。
2.2 改善遮挡物体的识别效果
在YOLOv3框架中,每个物体可能会有多个预测边界框,而选择预测效果最好的边界框是采用非极大值抑制(NMS)算法。它的原理就是简单的将置信度最大的预测边界框留下,而与其重叠过多的边界框直接删去。但这种过于直接的“贪心式”算法就会导致YOLOv3在检测部分有遮挡的物体时发生错误,删除遮挡物体的预测边框从而导致漏检。如图2所示。

图2 互相遮挡的工程挖掘机
在图2中,对于黑色边界框和白色边界框中的工程挖掘机,前者的置信度为0.98,后者的置信度为0.86,由于两者有遮挡,两个边界框有重叠部分,因此在使用传统NMS算法时,若重合度阈值过小,会保留置信度更高的黑色边界框,删除白色边界框,就会产生由于遮挡而漏检的问题。黑色和白色边界框遮挡面积不大,还能由较大的阈值消除影响,但白色和灰色边界框遮挡面积过大,若再增大重合度阈值,也会影响算法整体准确度,产生误检。因此针对该问题尝试使用软化非极大值抑制算法soft-NMS来对YOLOv3算法进行改进[10],优化其对遮挡工程挖掘机漏检的问题。
在soft-NMS算法中,不再直接将高于一定阈值的边界框删除,而是借鉴软间隔支持向量机的思想,对其置信度分数进行衰减,公式如下:
(2)
式中:Sc为某边界框的置信度;M为输出位置的边界框;bc为与M有重叠的边界框;T为阈值大小。
针对工程挖掘机的soft-NMS算法步骤(步骤(1)~步骤(3)与NMS一致)为:
(1)先将低于一定置信度的边界框删除;
(2)将剩下所有边界框按置信度大小排序;
(3)将置信度最大的边界框添加到输出位置;
(4)计算每个边界框与输出位置边界框的IOU大小,若高于设定阈值,则使用式(2)对其置信度进行衰减,低于阈值则不变;
(5)重复步骤(2)~步骤(4),将所有的边界框对象处理完成;
(6)按需求删除输出位置的边界框,最后显示的则是最好的工程挖掘机预测结果。
在上述的优化步骤后,虽然理论上会降低被遮挡工程挖掘机的预测置信度分数,但相较于NMS直接删除边界框的暴力求解而导致的漏检现象,该优化方法能对YOLOv3检测遮挡物体时的精度起到一定提升作用。
3 实验过程
3.1 数据集准备
实验数据集中图像主要来自拍摄现场存在工程挖掘机的视频取帧得到的图像,为了增加数据集的数量,从网络爬虫中得到部分图像。最后经过筛选,剔除了模糊、遮挡严重的图像,并在保证样本的多样性后,数据集总共选取了2 000幅图像,其中1 800幅图像归为训练集,200幅图像归为测试集。
3.2 图像标注
准备好数据集后,需要对其进行标注,使标注后的图像具有学习的意义[11]。对于几千幅图像,不可能采用人工的方式去标注挖掘机在图像中像素点的位置信息,可采用labelImg数据标注工具,分别对训练集和测试集共2 000幅图像进行边界框的标注。在图像中画出工程挖掘机的边界框后,labelImg工具可以自动生成YOLOv3所需的txt配置文件。其中信息包括:物体类别(从0开始,本文属于单目标识别,因此挖掘机类别记为0)、x,y(挖掘机目标中心点的坐标相对于整幅图像的比例大小)、w,h(挖掘机目标框的宽高相对于整幅图像的比例大小),训练集标注过程效果图和生成的部分txt配置文件如图3和图4所示。

图3 训练集标注过程效果图

图4 生成的txt配置文件
3.3 实验环境
深度学习的实验环境对训练的速度影响很大,笔者所采用的软硬件环境如表1所示。
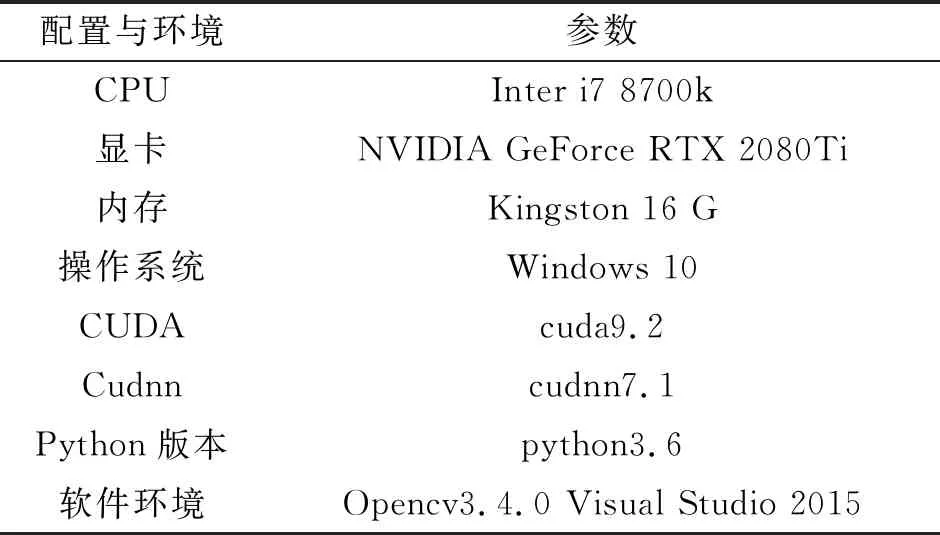
表1 相关环境配置
3.4 模型训练
训练过程中随着时间的推移损失值loss函数慢慢开始收敛,训练过程的界面如图5所示。
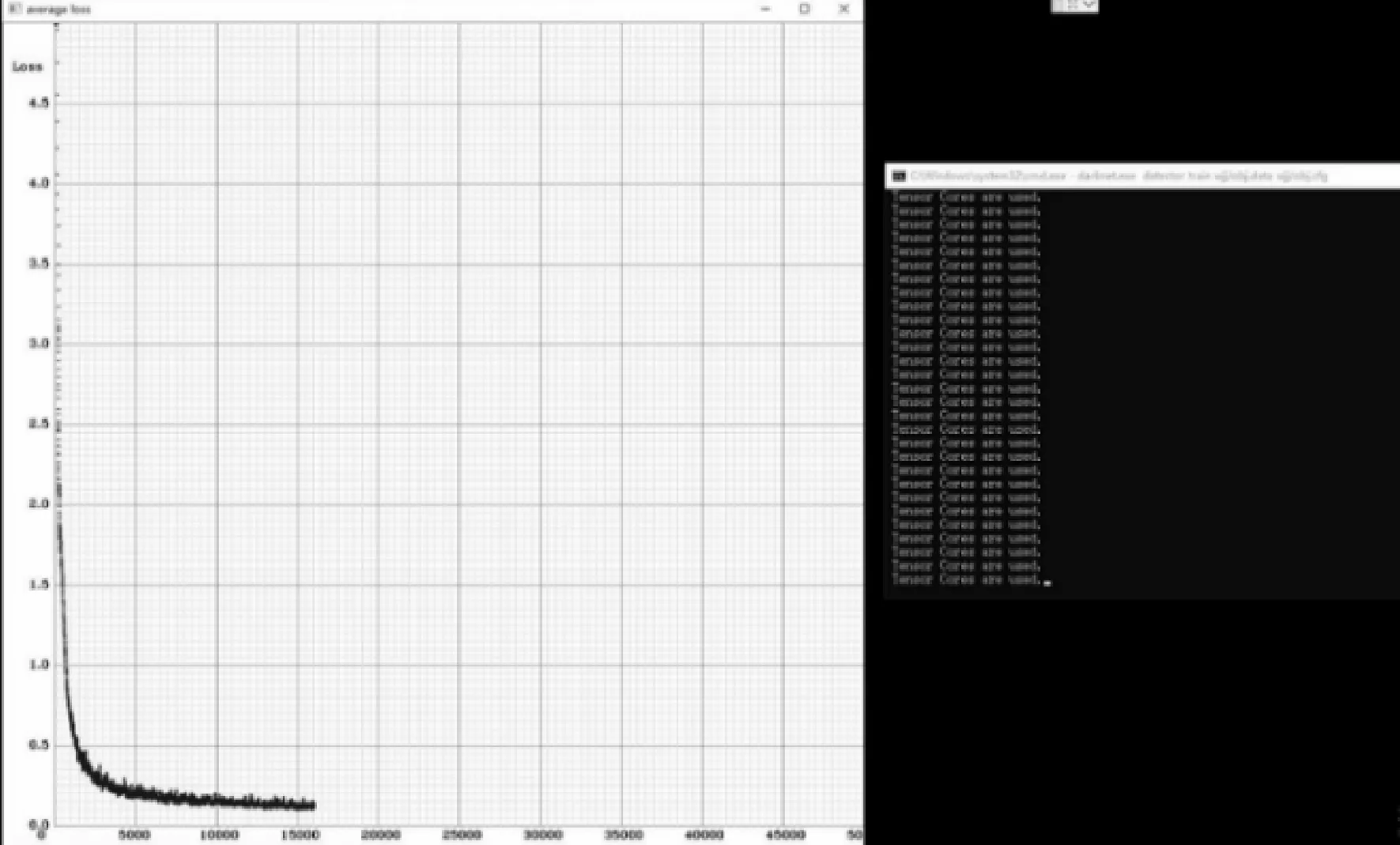
图5 训练过程界面图
训练迭代次数超过15 000次后,损失值loss图像变化缓慢,趋于稳定状态,最终停止训练。本次训练持续了一整天,迭代训练了20 000次,得到了最后的模型和训练日志。同时,在与上述数据集和实验环境相同的条件下对无优化的YOLOv3算法进行训练,得到相应的模型。
3.5 实验评价指标和结果分析
采用平均检测精度(mAP)和平均检测时间作为评价指标,对测试集的200幅图像进行测试,两算法的实验结果如表2所示。

表2 检测算法结果对比表
从表2可知,改进后的YOLOv3算法在mAP上表现更好,相较于无改进的YOLOv3算法提升了5%。在检测图像的响应时间上,由于没有对其做针对优化,因此两者相差不大。但是一般来讲,当平均检测时间达到25帧/s以上时,检测识别在视觉上就不会有卡帧的情况,因此改进的YOLOv3算法能达到实时检测识别的功能。
分别采用两个模型对工地现场图像进行预测,图像实验结果如图6和图7所示。

图6 改进后YOLOv3测试图像

图7 无改进YOLOv3测试图像
从同一图像的检测结果对比可以看出,改进后的YOLOv3算法可以识别出图像中所有工程挖掘机的位置,特别是左上角被遮挡的工程挖掘机也能正确识别。而无改进的YOLOv3算法没有识别出被遮挡的工程挖掘机,产生了漏检现象。
改进的YOLOv3算法在保证实时检测识别的前提下,提升了对工程挖掘机的检测精度,并且改善了工程挖掘机互相遮挡时的识别问题,能够有效防止漏检现象的发生。通过实验对比,改进后的YOLOv3算法针对工程挖掘机的识别效果更好,符合工程实际需要。
4 结论
针对西气东输工程中无人值守的油气场站,提出了一种基于改进YOLOv3的识别算法用于智能监控中实时检测工程挖掘机位置,防止工程挖掘机在作业时进入危险区域破坏油气管道。通过采用K-means++聚类算法得到适合工程挖掘机的anchor box,以提高检测精度,其次,使用soft-NMS算法选择输出预测框,解决工程挖掘机互相遮挡引发的漏检问题。实验结果表明,相比于原YOLOv3算法,改进后的YOLOv3算法检测精度明显提高,并且能够检测出互相遮挡的工程挖掘机。在检测时间上,也能满足智能监控中实时性的要求。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
学生天地(2020年16期)2020-08-25
现代装饰(2020年4期)2020-05-20
计算机应用(2018年5期)2018-07-25
中国科技纵横(2016年20期)2016-12-28
有色金属设计(2015年2期)2015-02-28
