
局部广义矩阵学习向量量化在多联机系统阀类故障诊断中的应用
2022-05-28 02:38张鉴心李正飞陈焕新刘倩王誉舟
制冷技术 2022年1期
张鉴心,李正飞,陈焕新,刘倩,王誉舟
(华中科技大学能源与动力工程学院,湖北武汉 430074)
0 引言
变制冷剂流量(Variable Refrigerant Flow,VRF)系统常被称作多联机系统,与传统空调系统相比,其显著特点是运行能量可调节,同时不需要设置其他附属装备如冷却塔和水输配系统等,也能达到较高的热舒适性[1]。VRF系统中的电子膨胀阀是室内机进行制冷剂节流膨胀和流量调节的核心部件,属于制冷系统四大件之一[2];四通阀通过内部滑块的移动来进行制冷剂流动调节,是实现制冷与制热模式切换的核心部件[3]。两种阀类故障都可能引发制冷/制热循环效率降低、机械部件损坏等问题。因此,准确检测出多联机系统的故障对提高其运行效率并减少能耗损失有重大意义[4]。根据已有文献可以总结出目前暖通空调系统故障检测与诊断方法(Fault Detection and Diagnosis,FDD)主要由三大类组成:基于专家知识的方法、基于模型的方法和基于数据挖掘的方法[5]。
近年来针对数据挖掘的故障诊断方法的研究越来越多。数据挖掘技术是通过一系列人工智能算法来发现故障数据中存在的大量隐藏关系,达到高度灵敏的诊断效果[6]。TUDOROIU等[7]描述了基于无迹卡尔曼滤波估计算法的交互式多模型,将其用于对暖通空调系统循环DAT回路中的阀门执行机构故障检测和诊断。WALL等[8]提出了基于动态贝叶斯网络和隐马尔可夫模型的动态机器学习暖通空调系统故障自动检测技术,还使用数据融合技术将冷却盘管阀门控制故障、热水阀泄漏故障等进行组合。DU等[9]开发了基于组合神经网络和减法聚类的空气处理单元故障检测与诊断方法,对5种传感器故障和冷冻水阀卡死故障进行检测。GUO等[10]提出了一种基于模块化主成分分析方法的故障检测策略,使用6个变量建立基于专家方法的多变量解耦策略来隔离故障,考虑了多联机系统的4种常见故障包括电子膨胀阀泄漏和四通阀换向故障。郭梦茹等[11]将遗传算法提取出的特征代入初始化参数优化后的反向传播神经网络,对多联机的电子膨胀阀和四通阀常见故障进行了检测和诊断。韩林志等[12]采用原始学习向量量化方法研究了3种制冷剂充注量状态。
上述文献中对模型的初始参数优化并没有同时考虑故障诊断正确率和运行耗时;同时学习向量量化算法在该领域运用也很少,且原始算法的诊断效果不佳,也没有相关文献作进一步的优化研究。本文将多目标进化算法框架添加到了模型参数优化中,并首次将带有特征自适应相关性矩阵训练的学习向量量化应用于多联机阀类故障的研究中。通过对不同故障的各项特征进行相关度分析,并对故障发生部位进行模糊的初步定位。
1 多联机阀类故障数据采集和预处理
1.1 多联机阀类故障实验平台
本文所进行的多联机实验平台如图1所示,系统额定制冷量为45 kW,制冷剂为R410A,采用单涡旋压缩机和5个室内机组合方式,其中5号机为主内机。

图1 多联机实验系统原理
实验中设置6种的运行状态:正常(L1)、5号机电子膨胀阀卡死在0开度(L2)、5号机电子膨胀阀卡死在满开度(L3)、2号机电子膨胀阀泄漏(L4)、四通阀掉电(L5)、四通阀掉电(L6),并对各类状态下收集到的数据进行编号以简化后续表示。L1、L2和L3数据包括制冷和制热模式,L4、L5和L6只有制热模式,所有运行状态的室内外设计工况一致,具体信息如表1所示。数据收集来自多联机系统中布置的多个传感器,温度与压力传感器在图1已标出。

表1 故障及正常模式实验设计
1.2 数据预处理
收集到多联机阀类故障数据后,需要对数据进行预处理。研究表明数据预处理的工作量可以占整个数据挖掘流程的80%以上[6]。一般而言数据预处理包括数据集成、数据清理、数据变换和数据简化这4个步骤[13],预处理的效果会直接影响到后续的数据挖掘效果。
本文的预处理工作主要由4个步骤组成:1)以专家知识剔除掉原数据集中的无意义特征参数,减小数据的特征维度;2)对特征中的文字标签进行编码,变为可进行运算的数字;3)对数据中的死值,即特征变量在所有运行状态过程中一直保持稳定不变的值,对其进行剔除;4)对数据异常值进行清除,包括机组启动后和停机前的异常变化数据、非稳定运行状态外的剧烈波动值以及稳定运行中的异常测量值。
将原始收集到的数据进行预处理后,得到了稳态运行下的可供分析的37个特征数据,一共有12 091个。其中L1~L6数量分别为3 163、2 056、1 723、1 362、1 140和3 163。
2 故障诊断模型建立
2.1 随机森林提取特征重要度
由于多联机特征参数较多,某些特征与某特定阀类故障的发生存在及其微弱的关系,或者对所有阀类故障的反应都是近乎一致的,无法依靠经验剔除掉。同时,如果特征维度过高,不仅会降低诊断的运行速度,同时可能导致算法的过拟合,所以需要对较重要特征提取以简化特征维度。本文采用随机森林(Random Forest,RF)算法来进行特征重要度分析[14]。
RF是一种集成学习方法[15],采用了bootstrap的集成方式,其进行特征分析的运行结构如图2所示。RF利用数据生成多棵决策树进行并行训练,评价标准可以依据信息增益程度或基尼指数来确定某个特征对数据的贡献程度,可以不用对数据进行归一化处理[16]。当达到设定的阈值或者分支到最后一个特征后,整合所有决策树的结果,得到训练好的森林,并同时得到特征的重要度排序表。

图2 随机森林运行结构
2.2 局部矩阵学习向量量化诊断故障
多联机系统的故障诊断实质上是一种运行模式的识别,学习向量量化是一种模式识别中应用非常广泛的算法,但极少被用来进行多联机故障的诊断,且原生学习向量量化的诊断效果不佳[12]。本文采用改进后的局部广义矩阵学习向量量化(Local Generalized Matrix Learning Vector Quantization,LGMLVQ)算法[17]作为多联机阀类故障模型的核心。图3所示为LGMLVQ网络的结构,它是一个具有3层结构的竞争神经网络[18],包括输入层、竞争层和输出层。

图3 LGMLVQ结构
输入层即为数据特征,与一般的人工神经网络所不同的是竞争层是类原型向量层,竞争层与输入层的关系是通过欧式距离计算来获得,同类数据可以设置多个类原型向量。输出层中每个点即代表相应的类别。特别注意的是在连接上,输入层和竞争层是全连接的,但竞争层和输出层是分类连接的,且一个类原型向量只能连接一个输出点,一个输出点可以和多个同类原型向量连接。
LGMLVQ是在广义学习向量量化算法基础上进行改进,对类原型向量的更新式进行了改进,更新式为:

式中,ws为与样本标签相同的类原型向量;wd为与样本标签不同的类原型向量;φ(ξ)为类原型向量成本函数更新式;Λ为类特征自适应相关性矩阵;ξ为随机选取的数据样本向量;ε(t)为自适应学习率。
更新式是LGMLVQ算法的核心改进部分,类特征自适应相关性矩阵和成本函数的加入,可以分析到不同特征的同类数据相关程度,并可以使类原型向量最大程度收敛到类别中心。同时由于类原型向量更新时采用的欧式距离计算,即无需对数据进行归一化处理,可以节省运算资源的消耗。
本实验中以5种故障数据和正常数据对一个LGMLVQ网络进行训练,根据测试集得到的数据类别来判断故障类别。
2.3 多目标进化优化算法框架
由于LGMLVQ的性能比较依赖于其初始化参数,因此需要对模型初始化参数进行优化。为了尽量取得最好的模型诊断效率,本文同时考虑模型故障诊断正确率和运行耗时两个优化目标,并设计了基于第二代非支配分类遗传算法(NSGA-II)的多目标进化算法优化框架[19]。其基本运算过程如图4所示[20]。

图4 NSGA-II结构
与单目标优化问题不同,由于本文的多目标优化是针对两个目标进行分析的,不存在随迭代次数增加而目标收敛的情况。同时最优参数集是多个Pareto最优解集,被优化目标值也分布在Pareto最优前沿上,需要依靠经验主观选择最为合适的优化参数。
2.4 多联机阀类故障诊断模型
上述对该模型中重要部分的说明,在此设计完整的多联机阀类故障诊断模型。该模型采用了离线的多联机实验运行数据进行训练和测试,同时整合了数据预处理、特征提取、多目标进化算法优化框架和LGMLVQ核心算法4个部分,图5所示为多联机阀类故障诊断模型流程。

图5 多联机阀类故障诊断模型流程
在特征提取阶段,根据数据特征重要度排序表依次从少到多选取特征,代入原始LGMLVQ模型中进行测试,确定最合适的特征数量;NSGA-II中的优化目标分别为模型对测试集数据的诊断正确率以及LGMLVQ模型训练和测试的整体耗时;将低维特征数据的75%分为训练集,25%分为测试集。本实验中各步骤均进行了10次运算,选取出现最多次数的结果,以消除硬件性能波动的影响。
为了评估模型的诊断性能,采用结果混淆矩阵和如下所示的模型诊断正确率计算公式:

式中,Ni为某类数据的分类正确数;Nall为测试样本数据总数量。
3 模型运行结果分析
3.1 多联机阀类故障特征选取
将37个特征数据导入到随机森林模型中,得到表2所示的特征重要度表。由表2可知,压缩机排气温度处于较高的重要度,由于压缩机运行状态基本可以代表多联机系统的运行状态,在不同的故障发生时导致压缩机具有不同的表现。

表2 特征重要性排序表
从两个特征开始逐步增加特征选取数,观察原始LGMLVQ算法的诊断正确率和运行耗时变化情况(图6)。由图6可知,运行耗时呈现增加趋势,而诊断正确率处于波动变化情况,且特征数达到30个后,变化趋于平缓。为了减少特征维度,同时尽可能保留重要的特征,结合趋势图,本文选择前19个特征数据作为最终低维特征数据集,从小到大依次标记为F1~F19。

图6 特征数对诊断正确率和运行耗时的影响
3.2 模型初始化参数优化结果分布
本文LGMLVQ神经网络所需要优化的参数详细信息如表3所示,NSGA-II的初始种群数量设置为100个,迭代次数100次。采用NSGA-II进行模型初始化参数的选优,选优过程一共耗时33 177 s,最终的100个Pareto最优前沿点分布如图7所示。

表3 优化参数表

图7 优化目标分布
优化分布点呈现明显的曲面变化边界,说明模型诊断正确率和运行耗时的确存在相互制约的关系。为了同时得到较高的诊断正确率和较低的运行耗时,本文选取的模型初始化参数集为图7中的星型标记点参数集。初始化参数设置类原型向量数为1,迭代次数130次,收敛阈值0.000 3,随机数种子223,正则化系数0。
3.3 模型诊断结果分析
将测试数据代入最优LGMLVQ模型中,得到诊断结果的混淆矩阵如图8所示。由图8可知,优化后的模型对每类数据的诊断正确率除了L2为99.222%、L3为97.448%之外,其它类别均达到了100%。模型整体诊断正确率达到了99.504%,且耗时为11.724 s。

图8 故障诊断结果混淆矩阵
图9所示为3种不同改造模型的模型诊断正确率和耗时对比,得益于LGMLVQ本身的结构先进性,即使在最为原始的模型下也具有91.4%的故障诊断正确率,但是由于特征较多,运行耗时较多。RF降低了特征维度,使得模型的诊断效率有一定的提高,运行耗时也大幅减少。最终模型诊断率很高,耗时处于中等水平,具有实用潜力。

图9 模型性能对比
为了直观得出各类数据在相应的特征自适应相关性矩阵下的分类效果,通过相关性矩阵将原始的19维特征数据投影到二维坐标上,以实现多维数据的分类可视化。图10所示为各类数据在各相关性矩阵投影。图10中各横纵坐标分别是特征数据在经过相关性矩阵贡献度最高的两个特征向量变换下的二维投影数值。其中L1、L3和L4的相关性矩阵前两个特征值贡献度分别达到85.36、80.05和83.95,除同类数据外其他类数据的聚集程度也很好。L2、L5和L6的贡献度分别只有69.52、65.33和56.51,虽然其他类数据存在一定的混合,但同类数据与其他类数据得到了一定的分离以及自聚集。证明特征自适应相关性矩阵可以较好提取出各故障中的特征相关性以达到更好的分类效果。

图10 各相关性矩阵下的相关性数据投影
3.4 正常数据特征自适应相关性矩阵分析
特征自适应相关性矩阵是LGMLVQ的核心结构,如果其越接近系统内在的物理联系,就越能得到更好的诊断效果。矩阵对角线数字表示某一特征与该类数据的相关性程度,相关性越高,表明该特征是区分该类数据与其他数据越重要的指标;非对角线数字表示各特征之间的相关性程度,相关性越高,表明两种特征具有同时变化的趋势,且正值表明变化方向一致。
图11所示为正常数据的特征自适应相关性矩阵。由图11可知,压缩机模块温度、室内环境温度2、室内环境温度5和气分进管温度的相关性分别达到了93、36、34和32。即当故障发生时,上述几种特征发生了比较明显的工作状态变化。结合本实验可知,当故障发生时会直接影响整个系统,而压缩机作为系统四大件之一,当运行状态发生变化时必然会受到影响,维修人员可以在实际检查中通过观察压缩机的各项工作指标是否处于正常,来初步判断是否发生故障。气分进管温度是离开各室内机并经过四通阀的制冷剂进行气液分离前的温度,可以一定程度上反映出经过四通阀后制冷剂的流动情况,通过气分进管温度可以判断是否四通阀出现了故障。初始实验中,人为设计了5号内机的电子膨胀阀故障和2号内机的电子膨胀阀泄漏故障。在电子膨胀阀泄漏时,2号机室内会发生一定的热量交换,影响室内温度。而5号机电子膨胀阀开度也会影响5号机室内的热量交换。可以看出,通过特征相关性表可以初步定位到故障发生点,证明数据分析的确可以反映多联机的实际运行状态,对实际故障检修可以提供一定的帮助。
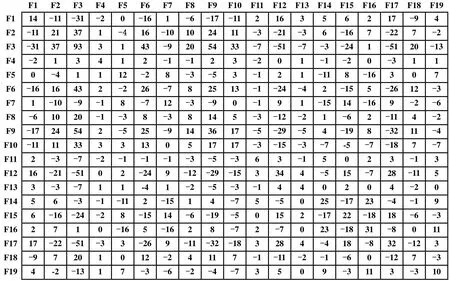
图11 正常数据特征适应相关性矩阵
对角线上相关性较大的特征之间具有较大的相关性,部分是正相关,部分为负相关。压缩机模块温度与室内环境温度2存在较强的正相关性,而与气分进管温度呈现较强的负相关性。分析考虑可能是在2号机电子膨胀阀泄漏后,与2号室发生了热交换,影响了室内温度,同时由于热交换不充分,在气液分离器处大量液态制冷剂被留下,而压缩机发生了空载,使得压缩机的模块温度发生变化。
图12所示为正常数据的相关性矩阵特征值,可知前两个特征值占比相当大,这也是其二维投影效果非常好的原因。

图12 正常数据相关性矩阵特征值
4 结论
本文针对多联机阀类故障诊断进行了研究,通过多联机实验系统人为设计故障,收集到了几种不同的阀类故障数据。对预处理后的数据进行了特征提取,对局部广义矩阵学习向量量化(LGMLVQ)参数进行了优化,最终建立了多联机阀类故障诊断模型,得出如下结论:
1)结合RF和原始LGMLVQ对特征进行降维,根据诊断正确率和运行耗时的变化趋势,可以证明特征数较多会增加模型运行耗时,对诊断正确率影响不大;最终选择19个特征变量,对比原始模型,诊断正确率从91.40%提升到95.73%,运行耗时从14.709 s下降至8.441 s;
2)利用NSGA-II多目标进化算法对LGMLVQ的参数进行优化,选择一组Pareto最优解集,将优化后的参数代入到模型中,最终优化模型的故障诊断正确率达到99.50%,耗时也仅有11.724 s;最优模型的精度已经具备可实际应用能力,同时证明了特征提取、参数优化具有明显的提升效果;
3)对正常数据的特征自适应相关性矩阵进行分析,发现高相关性的特征与故障发生部位有着密切联系,证明数据分析能够反映机组的实际运行状态,可以为实际故障维修提供一定的帮助;
4)本文提出的多联机阀类故障诊断模型相较于其他模型具有更清晰的运算结构,故障诊断正确率很高、反应速度较快、具备一定的实际应用能力。
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
能源研究与利用(2022年1期)2022-03-02
一重技术(2021年5期)2022-01-18
中华养生保健(2020年7期)2020-11-16
机电信息(2020年16期)2020-08-31
机电信息(2020年1期)2020-07-04
山东工业技术(2019年6期)2019-03-27
电子制作(2018年10期)2018-08-04
家教世界·创新阅读(2016年11期)2016-12-27
北京航空航天大学学报(2016年6期)2016-11-16
