
基于随机森林算法的小学生成绩分析与预测研究
2022-05-24 13:27张新蕾张春蕾
教育观察 2022年14期
张新蕾,张春蕾
(1.天津市和平区劝业场小学,天津,300041;2.河北工业大学经济管理学院,天津,300401)
在大数据时代的背景之下,教育与信息技术深度融合衍生出以云计算、大数据处理、机器学习等新手段为载体的数据驱动教学模式,引领教育走向“互联网+”的个性化新时代。在海量的教育大数据中,无论是学习者还是教育者,普遍关注的是学生的学业等级评价。这不仅是评估教育者教学质量的重要指标,而且是评价学习者综合素养的重要依据。在素质教育理念的引领下,成绩虽然不再是衡量学生综合素质的唯一因素,但它仍然是当下学业等级评价中较为重要的参考依据。因此,挖掘影响学生成绩的重要因素显得尤为迫切。本研究对天津市某地区1000名小学五年级学生阅读学习的相关数据进行分析,挖掘影响学生学业发展的重要因素。
一、文献综述
(一)利用统计学方法分析学生成绩影响因素
许多研究者利用多种技术手段,从不同学段、不同学科切入,挖掘影响学生成绩的因素并进行相关性分析。例如,易芳等人对中小学生学习成绩主要影响因素进行元分析,结果显示在学生的个人因素中,学习动机、自我效能感与学习成绩的关联度最高。[1]杨建奇等人对影响学生成绩的因素进行相关性和方差分析后得出,家庭因素、网络接触、早恋均能影响学生成绩。[2]
(二)利用机器学习算法挖掘成绩影响因素并进行预测分析
随着机器学习技术的发展,诸多学者开始借助数据处理技术挖掘影响学生成绩的因素,并对学生的学习成绩进行预测分析。例如,吴青等人运用决策树、贝叶斯网络、神经网络和支持向量机(SVM),分别构造了不同的学习成绩预测模型,比较得出基于贝叶斯网络的成绩预测模型具有较好的分类性能,自主学习行为是高校学员在线学习成绩的直接影响因素。[3]谢娟英等人利用密度全局K-means 算法对UCI机器学习库中葡萄牙两所学校的学生成绩数据集和我国蒲城县第三高级中学学生成绩数据集进行聚类、关联、成绩预测分析后得出,父母的陪伴、母亲受教育程度、学习态度直接影响学生成绩。[4]
(三)利用随机森林算法分析成绩影响因素并进行成绩预测
随机森林(Random Forest)是近年来新兴的一种机器学习算法,它以决策树为基分类器,采用Bootstrap方法从原始训练样本集中有放回地抽取多个训练样本集,以实现样本的随机选取,并将抽取的多个样本集生成不同决策树以形成随机森林。[5]在决策树的生长过程中,特征选择采用随机的方式分裂每一个节点,保证了特征属性的随机选择。这样生成的多棵决策树组合在一起就形成随机森林,最终对所有的决策数据进行投票,投票数最多的作为随机森林算法的最终输出结果。
为了提高预测模型的性能和预测精度,部分学者采用了集合多个分类器处理数据的随机森林算法。何韵竹等人利用高校大学生成绩数据集,对几类经典的数据挖掘算法进行研究,表明随机森林算法具有较高的分类性能,能分析出影响学生综合学习效果的重要因素。[5]王岳卿利用多元线性回归、支持向量机和随机森林算法,从家庭因素方面对学习葡萄牙语的学生成绩进行预测并构建模型,对比得出随机森林算法具有较强的预测性。[6]顾金池利用多元线性回归、决策树模型以及随机森林算法建立学生成绩预测模型,表明学生学习时间、母亲受教育程度成为影响大学成绩最主要的两个因素。[7]
基于上述研究可知,运用机器学习的数据处理技术预测学生成绩,并对影响成绩的因素进行挖掘和分析,已受到研究者关注。但现有研究也反映了数据处理技术预测学生成绩的局限性。从研究内容看,数据较多源于中高等教育,缺少对基础教育领域的调查和研究,而且着重从学生、学校、家庭、社会等较为宏观层面分析影响因素,缺少对学习者自身机制的挖掘。从研究方法看,部分学者多采用决策树、神经网络等单一分类器建立成绩预测模型,而单一分类器的性能和预测精度易受参数影响,具有不稳定性。还有学者虽然综合介绍了多种数据处理算法,但其研究中对各模型运行环境和具体运行过程涉及较少,导致数据处理算法的可操作性不强,推广较少。
对此,本研究运用随机森林算法对小学五年级学生的阅读、学习等方面的数据及期末语文成绩数据进行分析,构建学生语文成绩等级预测模型,并根据特征重要性排序分析影响学生语文成绩的重要因素。
二、研究设计
(一)研究对象及研究变量
本研究通过问卷调查和现场访谈,收集了天津市某地区1000名小学五年级学生的相关数据,经过数据预处理,保留有效数据960条,每条数据记录包括学生的基本情况(性别、家庭所在地、是否独生子女、父/母亲的学历、父/母亲每天的陪伴时长)、阅读情况(是否喜欢阅读、每天阅读时长、每周阅读量、阅读时是否边读边做标记、父母对阅读是否了解/支持、教师是否指导阅读方法等)、学习及课余(是否想上大学、课上听讲状态、课前预习情况、作业完成情况、写作业前复习情况、每周娱乐游戏时长、每周锻炼时长等)共计28个特征属性和0(优秀)、1(良好)、2(合格)、3(不合格)共计4个成绩类别属性。
(二)数据处理与分析
数据预处理,即对原始数据中的缺失值、重复值、异常值进行删除,对性别、家庭类别、是否独生子等属性数据进行量化,对学生成绩数据进行离散化。为了避免各维属性间因取值范围的差异对模型训练造成影响,本研究还对数据进行标准化处理。
预测模型构建,即采用随机森林算法构建学生成绩的预测模型,对学生语文成绩进行预测。随后,本研究利用随机森林算法中的Gini指数对特征重要性进行排序,挖掘影响学生学业发展的重要因素。
三、预测模型建立
随机森林是一种灵活、简易、实用性较强的机器学习算法,在样本集和特征集上两次引入随机性,使算法具有较好的抗噪能力。同时,随机森林算法能够通过Gini值实现对特征重要性的排序,从而为特征的选择和分析提供依据。[8]
本研究借助python的工具包scikit-learn(sklearn)完成实验,通过对数据的预处理,得到学生成绩有效数据960条。然后,本研究将70%的数据用于训练模型,30%的数据用于后续测试,具体建立过程如下。[9]第一,导入算法模块,即导入sklearn包中随机森林算法建模所需模块。第二,实例化模型类并设置模型参数。第三,创建数据,即导入预处理的特征集(X)与类别标签(Y),分割训练集与测试集。其中,X包含0—27共28个属性,Y包含0—3共4个类别。本研究利用train_test_split()函数将数据划分为训练集与测试集,其中,test_size划分比例设为0.3,即70%的样本作为训练集,其余30%的样本作为测试集用于后续测试。第四,模型建立与训练。
四、结果与讨论
(一)实验结果
基于上述的随机森林算法的预测模型,本研究用70%的数据集完成参数调优和模型训练,用30%的测试数据集进行测试。实验结果显示,该模型的预测准确率为88.89%,能较好地实现对五年级学生期末语文成绩等级评价的预测。
(二)重要特征可视化分析
1.不同类别的学生在各项特征的重要性分布
实验结果表明,基于随机森林算法的成绩预测模型达到了较高的预测精度,可以为学生提供学业预警,增强教师对学生学习的规划和指导。依据模型的预测结果,将模型中Gini指数各变量重要性的得分情况进行可视化后发现,属性12、13、19、21、22等的重要性排名靠前,属性0、1、2、14、27等的重要性排名靠后。各类特征变量的重要性分布如图1所示,据此可以找出影响小学生语文成绩的重要因素。
如图1所示,重要性排名靠前的是属性12、13、19、21、22,分别对应父母对阅读是否支持、每周阅读量、课上听讲状态、作业完成情况、写作业前复习情况。其中,每周阅读量(属性13)是影响学生语文成绩最为重要的因素。属性3、8、9、18、26等的重要性分值紧随其后,说明母亲的学历、每天阅读时长、对阅读能否帮助提高语文成绩的认知、是否想上大学、每周锻炼时长等对语文成绩存在一定影响。属性10、16、23、24、27等对语文成绩的影响不大,即学生阅读时是否边读边做标记、教师是否指导阅读方法、学生课后写作业时长及每周课外补习班时长和每周缺勤时长等与语文学习成绩的关联较弱。而属性0、1、15等的重要性分值相对较低,说明性别、家庭所在地、教师是否布置阅读任务等对成绩的影响微弱。
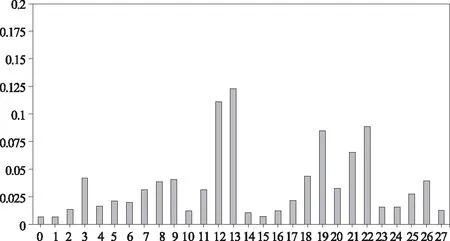
图1 影响小学生语文成绩的各项特征重要性分布图
分析可知,影响小学生语文成绩的因素不仅有学生自身因素,而且有家庭因素。值得注意的是,在众多因素中,学生每周阅读量及父母对阅读是否支持成为影响成绩的两个极为重要因素。这一发现在帮助教师和家长关注学生的课上和课后学习情况的同时,还可以引导教师和家长加强对学生阅读情况的关注,也为教育研究者制订下一步的教学规划提供新思路。
2.重要特征排序
为进一步发掘影响学生成绩关键因素,根据Gini指数得到的特征重要性分值,本研究提取了分值排名前8个重要属性,其重要性排序如图2所示。不同成绩类别的学生在重要特征的属性值如图3所示。
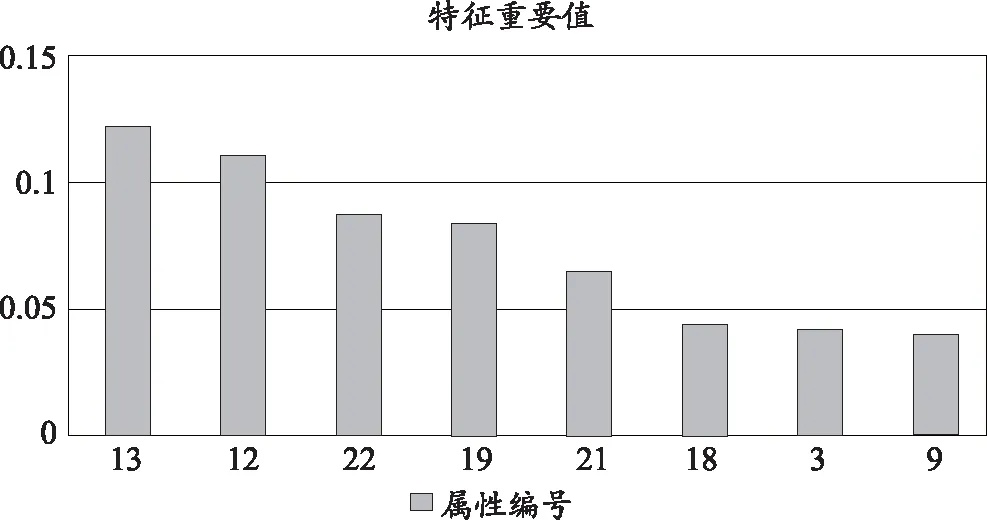
图2 影响学习成绩的重要特征排序图
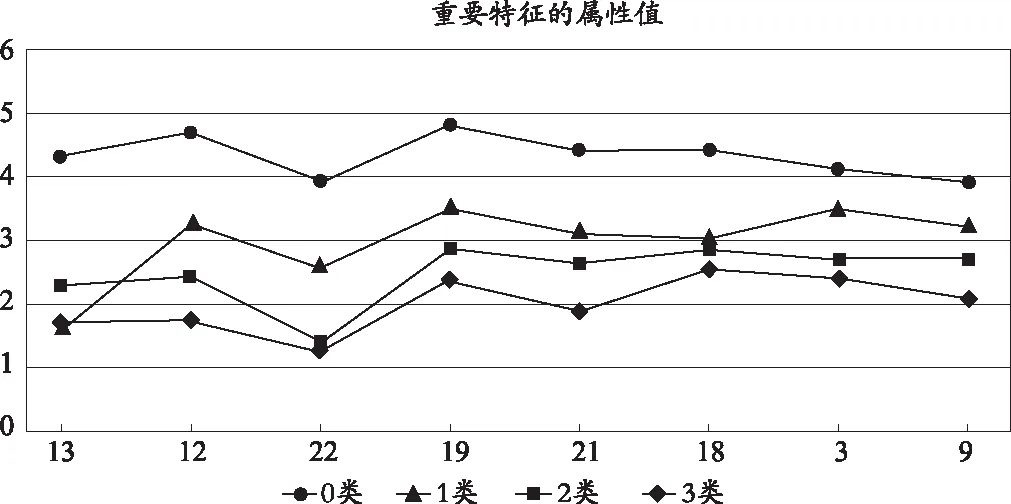
图3 不同成绩类别学生重要特征属性值分布图
在图2、图3中,属性13表示每周阅读量,属性12表示父母对阅读是否支持,属性22表示写作业前复习情况,属性19表示课上听讲状态,属性21表示作业完成情况,属性18表示是否想上大学,属性3表示母亲的学历,属性9表示阅读能否帮助提高语文成绩。由此分析得出,语文成绩的影响因素如下。
一是阅读活动的影响。在影响学生成绩的特征变量中,属性13排在首位,其次是属性12。由此看来,阅读已经成为影响学生语文成绩的首要因素。随着教育改革不断深化,尤其是统编版教材的广泛使用,阅读变得更为重要。从属性9的排序看,学生已经意识到阅读的重要性,但阅读实践还需要一个过程。从重要特征的属性分布图可知,成绩优秀的学生的阅读量均值远远高于其他三类学生,四个类别的学生在属性12上呈现出梯度性。由此可以看出,父母越支持孩子阅读,孩子的语文成绩越高,侧面反映出家庭环境对阅读的重要作用。这也说明了广泛开展中小学生阅读活动的重要性。学生多读经典、原著,才能在系统阅读、大量阅读、深层次阅读中发现问题、思考问题、提升素养、增长知识见识。[10]
二是学习活动的影响。属性22、19、21被普遍认为是影响语文成绩的因素,但与属性19、21相比,属性22略胜一筹。这充分说明了,作为学习内容输入的过程和学习结果输出的过程,课上听讲状态和作业完成情况跟学生的学习成绩有关,但写作业前复习情况影响着输入与输出间的内化吸收。在内化吸收过程中,学生通过不断加工整理知识框架,在脑海中形成知识图谱,进而呈现在作业上。从属性22的属性值来看,四个类别的学生存在明显的差异,成绩优秀和成绩良好的学生课后复习情况远远优于其他两类学生,但所有学生课后复习的整体情况不容乐观。这提醒教育工作者务必关注学生学习后的复习情况,引导学生对已学知识进行内化吸收。
三是学习动机的影响。除阅读活动和学习活动外,属性18也成为影响学生成绩的重要因素。这说明学生的学习不仅要有实际的行动,而且要有强烈的学习主观愿望和学习动机。因为强烈的愿望和动机能够促使学生端正学习态度,提高学习积极性,进而收获良好的学习效果。如图3所示,学习目标明确和学习动力较强的学生更容易获得较高的成绩等级。这进一步明确了,教育工作者需加强对学生学习态度和正向价值观的引领,通过良好学习态度和积极价值观的引领,帮助学生形成正向学习力,激发学生学习兴趣。
四是家庭环境的影响。在影响学生成绩的前八项特征中,除了学生自身的因素,家庭环境因素对学生成绩也有一定影响。属性3反映了母亲受教育程度对学生成绩的影响,属性12从侧面反映出家庭环境通过影响学生阅读情况进而对学生成绩产生影响。从图3得出,成绩优秀/良好学生的属性3、12的属性值均高于其他两类学生。由此可见,良好的家庭环境和氛围能为学生提供更好的学习环境,为学生健康快乐地学习成长保驾护航。因此,家长要注重家庭、注重家教、注重家风,自觉成为立德树人的有生力量。[10]
本研究运用随机森林算法构建出学生成绩预测模型,并对收集到的有效数据进行实验分析。实验结果显示,该预测模型具有较高的预测准确率和精度,有助于实现对学生的学业预测,能够帮助教师及时提醒帮扶成绩相对落后学生取得学业的进步。本研究还运用模型中的Gini指数找出影响学生成绩的因素,其中小学生的每周阅读量对其语文成绩的影响最大,即学生阅读活动与语文成绩的关系最为密切。这不仅为教育工作者制订未来教学规划、加强学校管理提供了参考和依据,而且为因材施教提供了有效途径,同时为家长如何做好家庭教育指明了方向,为倡导全民阅读、构建书香校园、推进语文教学的变革发展提供理论支撑。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中国宝玉石(2019年5期)2019-11-16
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
现代防御技术(2016年1期)2016-06-01
冰雪运动(2016年4期)2016-04-16
