
多尺度渐进式残差网络的图像去雨
2022-05-23 03:55卢贝盖杉
中国图象图形学报 2022年5期
卢贝,盖杉
1.南昌航空大学信息工程学院,南昌 330063; 2.江西省图像处理与模式识别重点实验室,南昌 330063
0 引 言
在雨天条件下,雨滴运动产生的雨线会造成采集图像局部区域被遮盖或者亮度升高的问题; 雨痕的积累还会使图像模糊, 清晰度降低。数字图像处理中的诸多操作如图像修复、目标识别和图像分类等的实现都要求在清晰图像条件下进行。因此, 图像去雨具有重要的研究意义。
传统的去雨方法可以分为基于核(Kim等,2013;Wang等,2021)、低秩近似(Chen和Hsu,2013;Chang等,2017;Kim等,2015)和字典学习(Kang等,2012;Luo等,2015;Wang等,2017)等方法。
1)基于核的去雨方法。基于核的方法先通过核回归检测雨痕区域, 再对雨痕区域进行去雨操作。Kim等人(2013)使用核回归和非局部均值滤波的方法来检测和自适应去除雨纹。Wang等人(2021)提出一种基于运动模糊核的雨纹生成模型用于去雨。这类方法虽然可以提高图像整体的能见度, 但仍存在过度平滑背景图像的问题。
2)基于低秩近似的去雨方法。基于同一雨图像中的雨条纹具有相似的形状和方向这一规律, 雨痕可以很好地表现为低秩性质。这就产生了基于低秩近似的去雨方法。基于这一原理, Chang等人(2017)提出了一种全变分低秩模型来分离图像层和雨痕。同样地, Chen和Hsu(2013)以及Kim等人(2015)通过建立低秩模型来捕捉时间相关的雨条纹。
3)基于字典学习的去雨方法。字典学习的目标是提取事物最根本的特征、去除冗余信息并保留本质信息。字典学习要求建立具有稀疏性的模型, 提取关键的特征作为字典。在图像去雨中, 通过建立稀疏模型, 将有雨图像中的雨痕分离出来。例如Kang等人(2012)先用滤波器将有雨图像分解为低频和高频部分, 再通过字典学习将高频部分分解为有雨和无雨分量。同样, Wang等人(2017)也对图像进行分解, 然后采用字典学习将高频部分分为3类。Luo等人(2015)通过学习具有互斥性的字典, 采用稀疏编码方法准确地分离出背景层和雨痕层。
随着神经网络的崛起, 研究者们发现将卷积神经网络(convolutional neural network, CNN)应用在图像去雨(Fu等,2017a,b;Zamir等,2021;Qian等,2018;Bi和Xing,2020;Wang等,2019;Yang等,2017;Zhang和Patel,2018)上的表现比传统方法更优秀。基于CNN的去雨方法是通过建立CNN的模型将雨痕从有雨图像分离出来, 得到无雨的背景图像。Fu等人(2017a)提出了一种深度细节网络, 首先对有雨图像进行分解, 再用残差网络对高频细节图像进行去雨。此外, 针对雨水积累的问题, Yang等人(2017)提出了一种循环多次的雨纹检测和去除网络, 用来反复渐进地清除雨纹积累。Wang等人(2019)用IRNN(iteratively reweighted nuclear norm)(Lu等,2014)捕获空间上下文信息来构建空间注意力模型, 获得表示雨空间分布的注意力图, 用于驱动后续的去雨环节。
尽管上述算法均可以有效改善单幅图像去雨效果, 但是其大都将去雨看做是一个简单的分离问题, 使用单一的网络进行去雨。然而雨痕具有复杂的结构,它们有不同的形状、方向和密度。通过单一的网络进行图像去雨, 难以彻底去除复杂的雨痕, 且容易在去除雨痕的同时丢失部分真实图像的信息。针对上述问题, 本文提出了多尺度渐进式残差网络MSPRNet(multi-scale progressive residual network)进行图像去雨, 具体去雨结果如图1所示。
本文的主要工作如下:
在残差网络的基础上提出一种多尺度逐步去雨的网络模型。利用渐进式的思想设计网络框架, 将整个模型设计为具有多级不同感受野的网络, 达到逐步去雨和恢复图像的效果。
针对网络模型, 本文设计了两个模块: 空间注意力模块和改进残差模块。为了充分利用残差网络每个残差分支上包含的重要信息, 本文提出一种改进残差网络结构。另外, 提出一种小规模空间注意力模块,重新分配权重, 使网络能够进一步聚焦受雨影响而产生严重退化的区域。
在合成的数据集和真实数据集上与一些主流的去雨方法进行了对比测试, 结果显示本文方法在客观和主观观测方面都优于其他对比方法。
1 相关工作
1.1 注意力机制
在计算机视觉中, 注意力模型的作用是让系统学会把注意力聚焦在感兴趣的区域, 并且降低对其他无关信息的关注度。另外, 还能提升网络模型的特征表达能力。基于这些优点, 注意力机制广泛应用于神经网络(Chen等,2017;Hu等,2020;Woo等,2018)中并作为网络结构的一部分。在神经网络中, 注意力机制的作用是给网络提供可供训练的权重参数, 通过调节这些权重能够使网络学习到感兴趣的特征。Woo等人(2018)提出了卷积注意力模型(convolutional block attention modul, CBAM), 这是一种由CNN构成的通道注意力和空间注意力机制, 该模块可以嵌入到当前主流的网络中,进而提升网络的特征提取能力。通道注意力和空间注意力机制区别在于:通道注意力机制是把W×H×C(特征图长、宽、通道数)的特征图在空间维度上进行压缩, 重新分配权重得到一个1维矢量1×1×C的注意力权重; 而空间注意力则是将W×H×C的特征重新分配权重得到W×H×1的注意力权重。通道注意力的作用是探索不同通道之间的关系, 使得网络模型聚焦到感兴趣的局部特征; 而空间注意力机制则是利用不同特征图之间的空间关系,来指导网络需要关注特征图的哪些特征空间位置。
近年来, 注意力模型广泛应用于各个领域, 如语音识别、自然语言处理和图像处理等。采用注意力机制对特征图进行通道加权重新分配权重, 达到学习图像主要特征的目的。陈庆文等人(2021)提出了一种深度聚类注意力机制用于显著对象检测。同样, 注意力机制在图像去雨问题(Zamir等,2021;Qian等,2018;Bi和Xing,2020;Wang等,2019)上也能够起到很好的作用,它可以让网络针对有雨部分进行操作,并且降低对无雨区域的关注度。例如Peng等人(2020)在去雨过程中引入了空间注意力对不同的空间位置赋予不同的权重来去除伪影。
1.2 残差网络
近年来, CNN以强大的表达能力受到许多学者青睐。随着对神经网络的深入研究, 相继提出了各种高效的网络, 如LeNet-5、AlexNet、VGGNet、Inception Net和ResNet等。传统的CNN随着网络变深, 存在着梯度爆炸或者梯度消失的问题。为了解决这个问题,提出了ResNet。ResNet是由多个残差块堆积构成的一个很深的神经网络, 图2所示为一个残差块结构。
在图2的残差块结构图中, 一个残差块包含两个分支: 直接映射分支h(xl)和残差分支F(xl,Wl)。相应的残差块表示为
xl+1=h(xl)+F(xl,Wl)
(1)
图2中直接映射h(xl)一般为跳跃连接, 在残差网络中通过这种跳跃连接方式使网络训练的输入信号可以从低层传播到高层, 从而使得训练误差减少。这样, 残差网络能够有效解决梯度消失和梯度爆炸问题。残差网络不仅能够很好地解决CNN造成退化的问题, 而且在和一般卷积网络相同深度的情况下收敛更快。残差网络最早应用于分类任务上。随后, 许多学者发现将残差网络用在其他计算机视觉任务中也能取得很好的效果。程德强等人(2021)利用一种多通道递归残差学习方法来提高网络训练效率和图像重建质量。Yeh等人(2020)使用多尺度残差网络和U-Net实现图像去雾。
2 本文方法
本文基于残差网络的基本结构,提出了一种多尺度渐进式图像去雨网络模型。该网络模型考虑到雨条纹具有不同的尺度与密度, 与现有的方法相比 能有效提取不同尺度特征, 还可以在去除不同尺度雨痕的同时有效保留图像原有的结构。该模型包括初步去雨子网络、残留雨痕去除子网络和图像恢复子网络3个子网络。为了提取不同尺度的特征, 该网络模型使用卷积核大小为3×3、空洞率(dilation rate)不同的扩张卷积获得不同的感受野。扩张卷积的原理是在标准的卷积核中加入空洞, 以此来增加模型的感受野。不同的感受野可以获得不同尺度的雨痕信息, 这样网络模型就能从粗到细去除不同尺度的雨痕。为了简化网络, 本文网络模型的每一级网络结构采用相似的设计, 每个子网络由注意力模块和改进残差网络模块构成。以初步去雨子网络为例, 首先输入图像通过一个卷积层提取特征, 然后经由注意力模块重新分配权重, 再通过改进残差网络模块得到残差雨痕图像,最后得到初步去雨图像。由于残差图像主要是雨痕和一些图像结构, 具有稀疏性, 因此选择残差图像作为网络的中间输出, 去雨图像则由输入雨图像减去训练得到的残差雨痕图像得到。本文所提去雨模型的整体框架如图3所示。
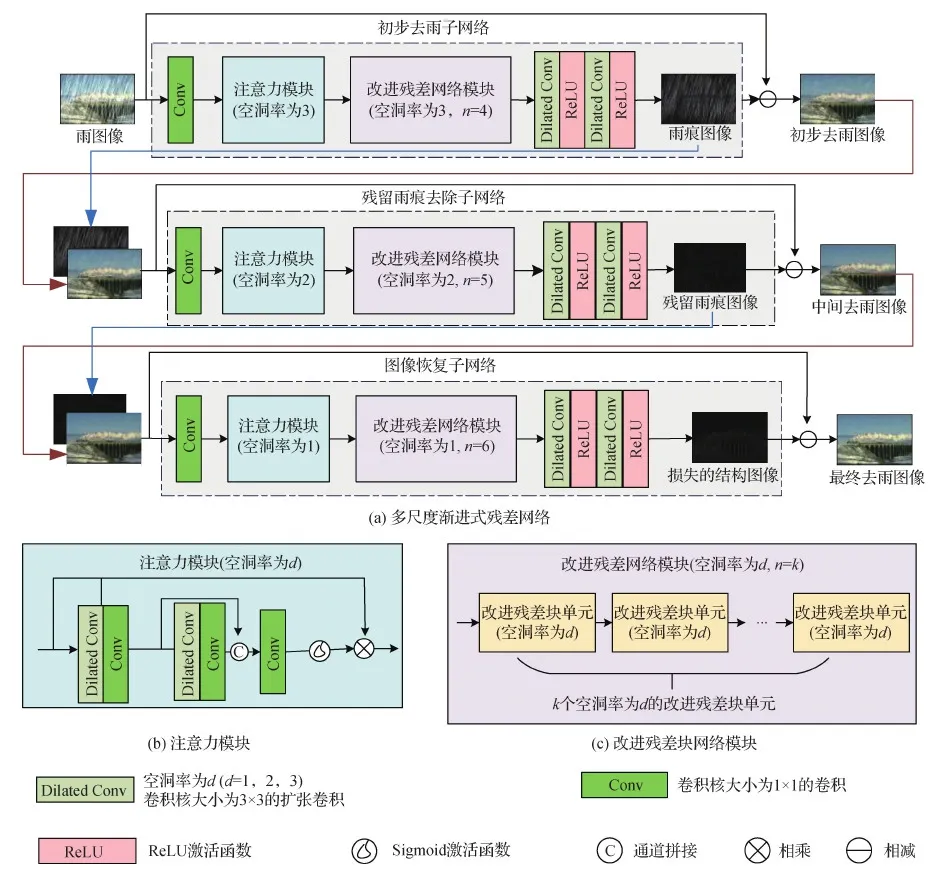
图3 多尺度渐进式残差网络模型框架
2.1 网络框架
网络由初步去雨子网络、残留雨痕去除子网络和图像恢复子网络构成。3个子网络扩张卷积的空洞率分别设为3、2和1。表1为MSPRNet模型参数表, 该方法的基本组成为注意力模块和改进残差块单元。因此, 以输入图像尺寸为321×481×3为例介绍这两部分的参数。接下来将详细介绍注意力模块和改进残差块网络模块。
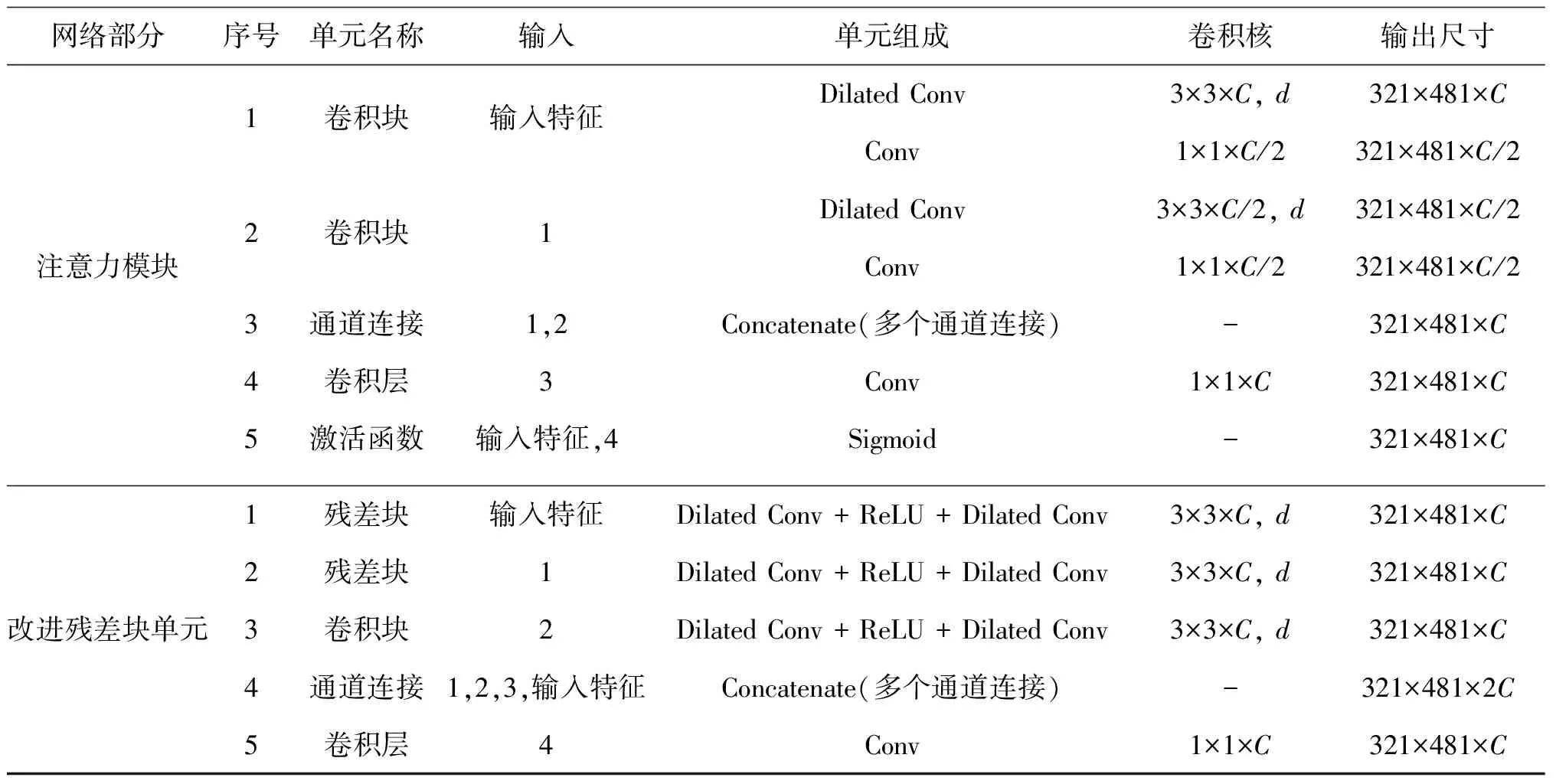
表1 MSPRNet模型参数表
2.1.1 注意力模块
为了最大限度地提高网络框架的有效性, 引入空间注意机制使网络更多地聚焦到有雨区域。针对本文的网络结构, 设计了一个空间注意力模块。由于要将该模块嵌入到网络结构中, 因此设计的注意力模块规模要足够小。此外, 注意力机制工作还需要有大的感受野。基于此, 提出的注意力模块首先用3×3的扩张卷积提取特征,再用1×1的卷积减少信道尺寸, 这样整个模块规模较小; 然后为了扩大感受野, 本文使用扩张卷积; 最后使用1×1的卷积层来恢复通道尺寸,具体结构如图3(b)所示。
2.1.2 改进残差网络模块
研究者们在图像去雨中引入了残差学习, 用来进一步提高网络性能, 缓解梯度消失问题。常见的策略是将残差块堆叠作为网络的基本组成之一。由于网络中需要连续使用多个残差块, 第1个残差块的残差分支的特征必须经过一条长路径, 经过多次加法和卷积运算到达最后一个模块。因此, 在整个网络的学习过程中残差块中的残差分支上的信息没有得到充分利用。针对这一问题, 本文提出一种改进残差块单元, 以便更好地利用局部残差特征。图4(a)为3个残差块级联构成的残差块单元,图4(b)为本文提出的改进残差块单元。与一般残差学习的不同之处在于: 本文将前两个残差块的残差特征直接连接到第3个卷积块的尾端, 最后用1×1卷积融合这些特征。与简单堆叠多个残差块的方式相比,本文提出的方法能充分利用残差分支的信息。

图4 改进的残差块结构
此外, 为了证明提出的改进残差单元的优势, 使用图4(a)的残差单元代替图3中的改进残差单元作为本文改进残差网络模块的组成单元进行实验并与MSPRNet进行对比。采用一般残差学习方法和MSPRNet方法在同一数据集上训练得到的峰值信噪比(peak signal to noise ratio, PNSR)变化曲线如图5所示。实验结果表明, MSPRNet方法在训练过程中比一般残差学习方法上升速度更快, 并且当一般残差学习方法达到收敛时,MSPRNet仍在继续优化缓慢上升; 另一方面在训练过程中MSPRNet比一般残差学习方法得到的PSNR值高, MSPRNet最终约收敛于37 dB, 而一般残差学习方法约收敛于35.1 dB, 低于MSPRNet约2 dB。这说明本文提出的改进残差块的连接方式能够加快训练中梯度下降的速率, 并且得到的训练效果更好。
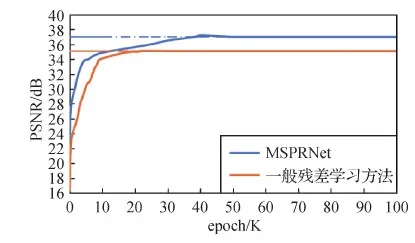
图5 随训练次数变化的PSNR变化曲线
2.2 损失函数
针对每个子网络的作用, 采用不同的损失函数组合。在初步去雨子网络采用均方误差损失函数得到雨痕图像R1。对于通道数为C、长宽分别为W和H的有雨图像X和干净图像Y, 初步去雨子网络的损失函数L1为

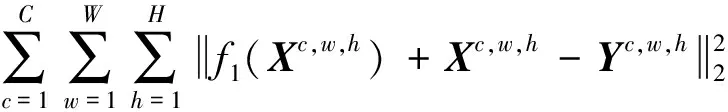
(2)
式中,f1(X)为通过初步去雨子网络得到的输出,λ为权重因子。残留雨痕去除子网络的目的是对初步去雨子网络未能完全去除的雨痕进行全部去除。因此, 本文使用均方误差损失函数LMSE1得到残留雨痕图像R2。若X1为初步去雨图像,f2(X1,R1)表示残留雨痕去除子网络的输出, 则可得到LMSE1为

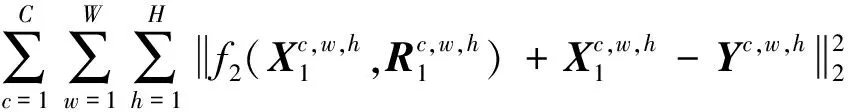
(3)
同时, 对于初步去雨图像使用感知损失函数Lp来衡量去雨图像和清晰图像之间的语义特征差异。对此, 采用常用的VGG(Visual Geometry Group)来进行特征提取获得感知损失函数,V()表示用VGG16预先训练的模型中ReLU2_2层提取的特征映射, 则对应的感知损失LP为


(4)
那么, 由式(3)(4)可以得到残留雨痕去除子网络的损失函数L2为
L2=α1LMSE1+α2LP
(5)
式中,α1和α2为权重因子。由于雨痕已在前两个阶段被移除, 因此, 最后一个阶段的主要目标是恢复图像的结构。同样, 在图像恢复子网络中使用均方误差损失函数LMSE2得到残留雨痕图像R3。如上一级子网络将图像恢复子网络输出设为f3(X2,R2), 那么LMSE2为
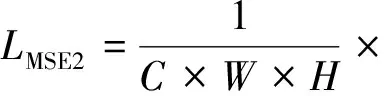
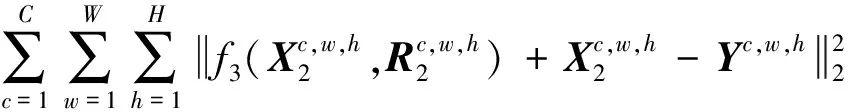
(6)
另外, 为了获得高质量的最终去雨图像X3, 本文使用结构相似度损失函数LSSIM和1损失函数来逼近真实无雨图像。1损失函数为


(7)
为得到LSSIM需先计算结构相似度(structural similarity, SSIM)(Wang等,2004), SSIM计算式为
(8)
那么, 进一步可以得到结构相似度损失函数LSSIM为


(9)
式中,μs、μt分别表示两幅图像x、y的像素平均值;σs、σt分别表示两幅图像x、y的像素标准差;σst表示x、y之间的协方差;C1、C2是两个常数。在式(8)中,S为网络输出和真实无雨图像Y的结构相似度。那么, 由式(6)(7)(9)可以得到图像恢复子网络的损失函数L3为
L3=β1LMSE2+(1+LSSIM)
(10)
式中,β1为超参数。根据上述子网络的损失函数式(2)(5)(10), MSPRNet的联合损失函数L为
L=ω1L1+ω2L2+L3
(11)
式中,ω1和ω2为权重因子。
2.3 网络训练
在网络训练过程中, 使用常见的Adam(Kingma和Ba,2015)进行优化。在网络训练中设置学习率初始值lr0为0.001; 当迭代次数达到30、60和90时, 学习率以乘以0.5衰减。为了更好地缓解梯度消失的问题, 本文网络依次对每个子网络进行优化更新参数。对初步去雨子网络的参数进行优化, 计算L1的梯度进行反向传播, 更新初步去雨子网络的参数;在下一次训练时将图像输入初步去雨子网络、残留雨痕去除子网络的参数依次进行优化更新;将图像输入整个网络进行更新参数。如此每3次训练作为一个周期。MSPRNet去雨算法过程为:
输入:合成有雨图像、真实无雨图像对数据集;
fort=1,2,…,Tdo;
k= 0;
ift=30 或t=60 或t=90 do;
k=k+1;
lr=lr0×0.5k;
从数据集随机取batch size对图像对ξt;
if(t+2)%3==0 do;
ξt输入初步去雨子网络;
计算L1的梯度,更新网络参数;
end if;
if(t+1)%3==0 do;
ξt输入初步去雨子网络、中间去雨子网络;
计算L2+L1的梯度,更新参数;
end if;
ift%3==0 do;
ξt输入网络;
计算L的梯度,更新参数;
end if;
end for。
3 实验结果与分析
从合成雨图像和真实雨图像两方面详细展示所提去雨方法得到的实验结果, 并且与DSC(discriminative sparse coding)(Luo等,2015)、DDN(deep detail network)(Fu等,2017b)、JORDER(deep joint rain detection and removal)(Yang等,2017)、LPNet(lightweight pyramid network)(Fu等,2020)、UMRL(uncertainty guided multi-scale residual learning-using)(Yasarla和Patel,2019)、ReHen(recurrent hierarchy enhancement network)(Yang和Lu,2019)、MSPFN(multi-scale progressive fusion network)(Jiang等,2020)和Syn2Real(syn2real transfer learning)(Yasarla等,2020)主流去雨方法进行对比, 进一步验证本文去雨方法的有效性。
3.1 实验设置
网络参数和实验平台: 本文所有实验均在Pytorch的框架上实现。服务器配置是ubuntu16.04版本的Linux系统, 并配有Inter(R)Core(TM)I7-8700 h CPU,128 GB RAM, Nvidia Titan X GPU。为了增大图像集,本文对输入图像进行剪裁,剪裁尺寸为80×100像素。训练采用衰减速率β1,β2分别为0.9和0.099 9, 初始学习率为0.001的Adam优化算法。为了提高网络训练效率, 网络的输入数据采用小批量输入法, batch size设置为 8。网络模型的权重因子设置为:λ=50、β1=50、α1=50、α2=0.2、ω1=ω2=0.2。
3.2 数据集
由于缺乏无雨图像和有雨图像的数据对, 因此采用合成图像进行训练。如表2所示,分别在5个合成数据集上进行测试,表中每列的值表示对应数据集训练和测试图像对的数量。由于实验中对有雨图像进行剪裁扩大了数据集,并未使用源数据集中的所有图像,而是随机选取了部分有雨图像进行训练。Rain100H和Rain100L均来自Yang等人(2017)。Rain100H是由大雨合成, 其中包含1 800对训练图像, 100对测试图像; Rain100L是由小雨合成, 包含200对训练图像, 100对测试图像。Rain12(Li等,2016)包含12幅合成有雨图像。Rain1200(Zhang和Patel,2018)训练集包含“light”、“medium”和“heavy”3种雨密度的有雨图像, 每类有4 000对有雨图像, 测试集包含1 200幅不同雨密度的合成有雨图像。Rain1400(Fu等,2017b)是由900组14种不同方向和密度的有雨图像构成。此外, 真实有雨图像数据集来自Yang等人(2017)和Zhang等人(2020),分别随机选取其中30幅真实有雨图像作为本文的测试集。

表2 合成数据集构成
3.3 评价指标
通过峰值信噪比PSNR、结构相似度SSIM和特征相似度(feature similarity, FSIM)(Zhang等,2011)对实验结果进行评价。


(12)
式中,fMSE为两幅大小均为m×n的灰度图像I和K的均方误差,MAXI为图像灰度的最大值。SSIM可以综合对比样本x和y之间的亮度、对比度和结构。式(8)为SSIM的计算公式。SSIM可以获得更符合视觉效果的结果。
根据Zhang等人(2011)的实验结果, 与其他全参考图像质量评价指标相比,FSIM在主观评估上表现出更高的一致性。因此,为了保证在主观和客观上的一致性,选择FSIM作为实验结果评价标准之一。FSIM是根据图像之间的相位一致性(phase congruency, PC)和梯度幅度(gradient magnitude, GM)来进行计算的。
另外,使用了无参考的图像评价指标NIQE(natural image quality evaluator)和BRISQUE(blind/referenceless image spatial quality evaluator)来定量分析在真实有雨图像上的实验结果。NIQE和BRISQUE值越小说明图像质量越好。NIQE是一个全盲的无参考图像质量评价指标。它在原始图像库中提取图像特征,再利用多元高斯模型描述这些特征, 用待评价图像的特征模型参数与预先创建的模型参数之间的差距来衡量图像质量。BRISQUE的原理是将图像视为成一个由人工设计的特征向量,然后使用支持向量机(support vector machine, SVM)进行分类。将图像的特征向量放入SVM,得到从而每种特征失真的最终质量得分, 这个值为BRISQUE。
3.4 合成数据集上的实验结果
将本文方法与其他方法在合成数据集上的结果进行定量和定性的对比分析。图6和图7为本文方法和其他主流去雨方法得到的去雨图像。表3为各方法在合成数据集上测试的平均PSNR、SSIM和FSIM值。

图6 不同去雨算法在合成有雨图像“horse”上测试的去雨结果对比图

图7 不同去雨算法在合成有雨图像“ship”上测试的去雨结果对比图
本文放大了部分雨痕重叠区域以便更好地进行视觉比较。从图6和图7中可以看出DSC残留雨痕明显, DSC还存在着运行时间较长的问题。DDN能够去除尺度较小的雨痕, 但是大尺度的雨痕无法去除, 且不能解决雨痕重叠的问题。LPNet在大尺度雨痕上测试的效果不理想, 并且从图6(e)中的放大区域仍能看到雨痕残留,这说明LPNet不能完全解决雨痕积累的问题。Syn2Real虽然也存在这些问题, 但是相比于其他去雨方法,其优点在于使用的是一种半监督学习方法。另外, LPNet最大的优点是使用参数很少, 这使得LPNet更适合存储。从图6(d)和图7(d)的放大区域可以看出,JORDER去雨后仍然有轻微的雨痕残留。如图6(g)所示, MSPFN存在过度去雨的问题, 这将造成图像局部模糊。UMRL虽然能去除雨痕, 但是从图7(i)中可以看出在去雨后雨痕位置留下的痕迹。从图7(h)可以看到ReHen去雨效果不如本文方法, 在天空处有较明显的白条纹雨痕残留, 说明MSPRNet处理大尺度雨痕的效果要好于ReHen。因为在MSPRNet中先用大感受野的扩张卷积把大尺度雨痕进行了去除。MSPRNet的去雨图像不仅几乎没有雨痕残留, 而且能保留图像原有的结构色彩。MSPRNet在多级子网络逐步去雨过程中不仅把雨痕去除了, 还能够逐渐地把雨痕从有雨图像中进行分离, 从而解决雨痕重叠的问题; 另一方面经过图像恢复子网络把去雨过程中损失的边缘信息进行了复原。

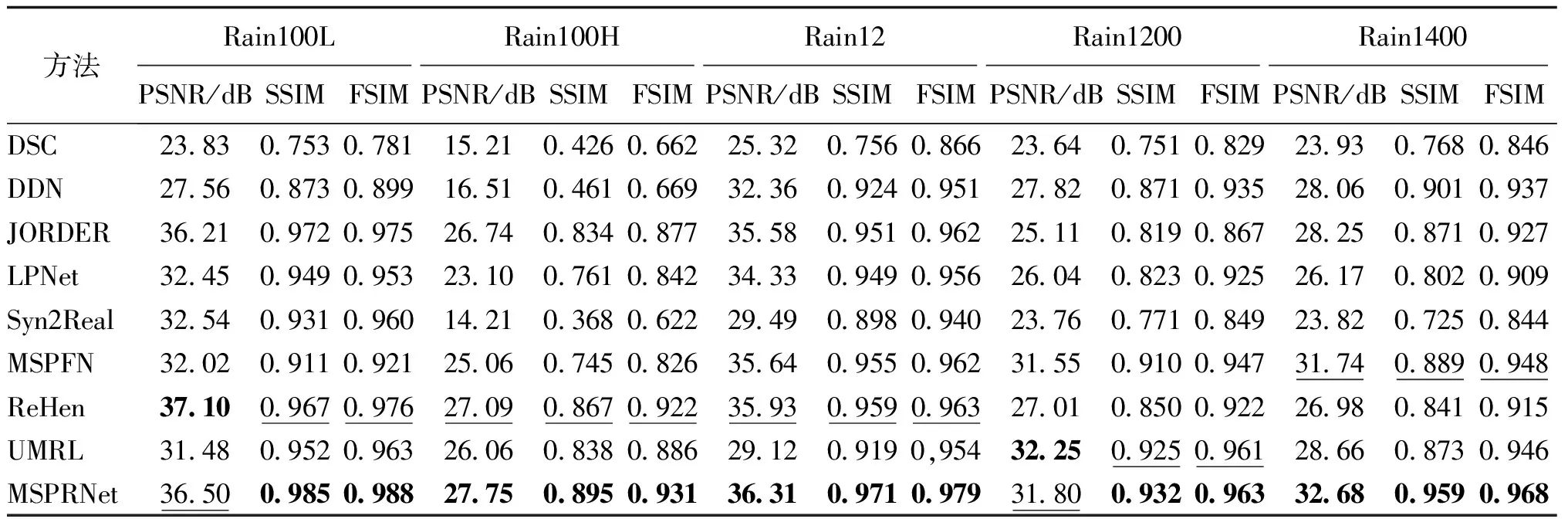
表3 在合成数据集上测试的平均PSNR、SSIM和FSIM
3.5 真实有雨图像上的实验结果
3.5.1 真实有雨图像上的对比实验
表4为各算法在真实有雨数据集上测试的平均NIQE和BRISQUE值。在其他方法中,JORDER和Syn2Real在真实有雨图像上获得的指标最低,在真实有雨图像上的去雨性能最好。从实验结果可以看出,MSPRNet的值最小,比Syn2Real的NIQE值低0.021,比JORDER的BRISQUE值低1.29。

表4 在真实有雨图像数据集上测试的平均NIQE和BRISQUE
图8—图11为MSPRNet与其他算法在真实有雨图像上得到的结果, 可以清晰地看出,MSPRNet的效果要比其他几种去雨方法表现得更优秀。如放大的区域所示, DSC、DDN和MSPFN的结果中大部分雨条纹未被去除;LPNet可以去除周围细粒度的雨痕, 但是粗粒度的雨痕未被去除;ReHen处理如图8(h)这种复杂雨痕效果不理想;JORODER虽然处理雨雾图像结果好,但是在去除图9(a)中的雨痕后有少量的雨痕残留。MSPRNet能够有效去除如图8(a)、图9(a)和图10(a)中各种尺度的雨痕,对于雨雾图像,如图11(a)中的雨痕仍然可以有效地去除。

图8 不同去雨算法在真实有雨图像“flower”上测试的去雨结果对比图

图9 不同去雨算法在真实有雨图像“tree”上测试的去雨结果对比图

图10 不同去雨算法在真实有雨图像“grass”上测试的去雨结果对比图

图11 不同去雨算法在真实有雨图像“woman”上测试的去雨结果对比图
从定性定量两个方面都能够证明本文方法不仅在合成图像上能够获得优秀的去雨效果,在处理真实有雨图像上也能有效地去雨,能够取得较好的实用效果。本文提出的MSPRNet方法能够有效地将各种条件下的所有雨痕都去除, MSPRNet在不同感受野的去雨子网络中逐步地去除真实有雨图像中不同尺度的雨痕。
3.5.2 真实有雨图像上目标检测结果
本文还对MSPRNet去雨后的图像进行目标检测,以验证MSPRNet具有一定的实用性。图12为用RetinaNet(Lin等,2017)方法对去雨前后图像目标检测的结果。图12中雨水的遮挡导致无法检测到所有人,而在经过MSPRNet去雨后的图像中能够将所有人都检测出来。这说明MSPRNet具有一定的实用效果。

图12 在真实有雨图像上的目标检测结果
3.6 消融实验
3.6.1 关键网络参数设置
本文采用具有不同空洞率和感受野的扩张卷积来实现多尺度去雨。为了得到最佳的参数设置,本文尝试使用不同卷积核大小的扩张卷积进行实验。k为扩张卷积核大小,图13为k分别取值3和5时得到的训练曲线图。从图中可以明显看出,在训练过程中k为3得到的PSNR值一直保持比k为5时的PSNR值高。k为5的PSNR训练曲线收敛于33.7 dB, 低于k为3时最终收敛得到的值约3.3 dB。另一方面,模型使用5×5的卷积核比使用3×3的卷积核需要更多的网络参数。因此,本文的卷积核大小设为3是最为合适的。

图13 随训练次数变化的PSNR变化曲线
确定了卷积核大小后,就需要确定每个子网络的深度。设n1、n2、n3分别为初步去雨子网络、残留雨痕去除子网络和图像恢复子网络中的改进残差单元个数。对每个子网络的改进残差单元个数设置不同的组合进行实验。表5为卷积核大小为3时n1、n2和n3为不同值得到的对应去雨图像的图像评价指标。表5中第3列的值比第1、2列高,说明每个子网络应该根据感受野的大小选择合适的深度,网络不是越深越好。表5中第4列的值最高,说明这组参数设置最优。
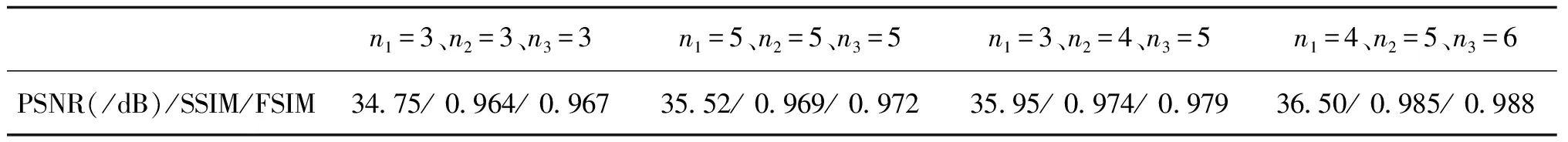
表5 不同参数设置得到的去雨图像的平均PSNR、SSIM和FSIM
综合上述分析,当k=3、n1=4、n2=5、n3=6时得到的指标最高,即卷积核大小为3,初步去雨子网络、残留雨痕去除子网络和图像恢复子网络中的改进残差单元个数分别为4、5、6时为最佳参数设置。
3.6.2 每个子网络的功能
为了验证MSPRNet中每个子网络的作用, 进行了以下实验: 分别在不使用初步去雨子网络(方法A)、残留雨痕去除子网络(方法B)、图像恢复子网络(方法C)的条件下进行实验, 表6为在Rain100L数据集上进行实验得到的定量指标。

表6 在Rain100L合成数据集上的平均PSNR、SSIM和FSIM
本文方法MSPRNet比方法A、B和C的PSNR值分别约高5 dB、1 dB和0.5 dB, SSIM值分别约高0.028、0.007和0.004, FSIM值分别约高0.019、0.005和0.003。这体现出本文提出的多尺度网络模型去雨性能最好, 每个子网络的缺失都会造成去雨性能的下降, 其中图像恢复子网络最为重要, 在多个子网络的共同作用下才能够实现逐渐从有雨图像获得清晰无雨图像的功能。同时, 为了研究不同子网络的作用, 选取有雨图像“cottage”和 “church”作为MSPRNet的输入,进而得到如图14和图15对应的不同子网络的输出, 接下来通过实验结果图像详细介绍各个子网络在MSPRNet中起的作用。

图14 输入图像“cottage”与对应每个子网络输出的残差图像和去雨图像

图15 输入图像“church”与对应每个子网络输出的残差图像和去雨图像
1)初步去雨子网络。对雨图像进行粗粒度去雨以去除大部分明显的雨痕, 得到初步去雨图像。经由初步去雨子网络获得雨痕图像(图15(f)), 该图中有大量的雨痕, 说明大部分雨痕被该子网络从雨图像中分离出来了。但是另一方面, 图15(f)中还有少量建筑物的结构说明该子网络虽然能够有效地初步去除雨痕, 但在去除雨痕的过程中损失了部分图像结构信息。
2)残留雨痕去除子网络。将初步去雨图像和残留雨痕图像作为残留雨痕去除网络的输入, 子网络进一步进行细粒度去雨得到中间去雨图15(c)。图中基本没有雨痕,说明图像中的雨痕可以基本去除。另外, 由图15(c)可以看出,图中的建筑物的边缘结构不够清晰, 所以需要进一步进行图像恢复。
3)图像恢复子网络。对图像进行恢复, 恢复上一阶段去雨过程中损失的结构。图15(h)所示的图像为损失的结构信息图像, 中间去雨图像加上损失的结构就可以获得清晰的最终去雨图像。
4 结 论
本文提出了一种基于多尺度渐进式残差网络模型的单幅图像去雨方法, 该方法可以有效解决现有方法去雨不彻底和去雨后图像结构信息丢失的问题。本文提出的网络模型充分考虑了雨痕的多样性, 通过具有不同感受野的子网络从粗到细去除雨条纹。本文方法可以在逐步去除不同尺度的雨痕同时恢复图像的结构。此外, 为了简化去雨过程, 每个子网络均使用相似的端到端的改进残差网络。为了在每个子网络中提高去雨性能, 本文采用注意力机制来引导改进残差网络进行去雨。通过实验验证, MSPRNet不仅能够有效地去雨, 同时还能够有效地解决雨痕重叠问题。
MSPRNet能够解决去雨不彻底和去雨后图像结构信息丢失等问题。但是, MSPRNet对于雨水积累形成的雨雾不能够有效地去除。因为本文主要针对有雨图像中的雨痕进行分析,并未额外针对雨图像中的雾进行分析。因此,考虑将结合去雾模型达到去除有雨图像中的雾气的作用。未来将探索如何将去雾模型和去雨模型进行有效结合,从而提高真实图像去雨效果。
参考文献(References)
Bi X J and Xing J Y.2020.Multi-scale weighted fusion attentive generative adversarial network for single image de-raining.IEEE Access, 8: 69838-69848[DOI: 10.1109/ACCESS.2020.2983436]
Chang Y, Yan L X and Zhong S.2017.Transformed low-rank model for line pattern noise removal//Proceedings of 2017 IEEE International Conference on Computer Vision.Venice, Italy: IEEE: 1735-1743[DOI: 10.1109/ICCV.2017.191]
Chen L, Zhang H and Xiao J.2017.SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 6298-6306[DOI: 10.1109/CVPR.2017.667]
Chen Q W, Xie H W, Zha H, Xi Y and Zhang X.2021.Salient object detection based on deep clustering attention mechanism.Journal of Image and Graphics, 26(5): 1017-1029(陈庆文, 谢宏文, 查浩, 奚瑜, 张雪.2021.深度聚类注意力机制下的显著对象检测.中国图象图形学报, 26(5): 1017-1029)[DOI: 10.11834/jig.200081]
Chen Y L and Hsu C T.2013.A generalized low-rank appearance model for spatio-temporally correlated rain streaks//Proceedings of 2013 IEEE International Conference on Computer Vision.Sydney, Australia: IEEE: 1968-1975[DOI: 10.1109/ICCV.2013.247]
Cheng D Q, Guo X, Chen L L, Kou Q Q, Zhao K and Gao R.2021.Image super-resolution reconstruction from multi-channel recursive residual network.Journal of Image and Graphics, 26(3): 605-618(程德强, 郭昕, 陈亮亮, 寇旗旗, 赵凯, 高蕊.2021.多通道递归残差网络的图像超分辨率重建.中国图象图形学报, 26(3): 605-618)[DOI: 10.11834/jig.200108]
Fu X Y, Huang J B, Ding X H, Liao Y H and Paisley J.2017a.Clearing the skies: a deep network architecture for single-image rain removal.IEEE Transactions on Image Processing, 26(6): 2944-2956[DOI: 10.1109/TIP.2017.2691802]
Fu X Y, Huang J B, Zeng D L, Huang Y, Ding X H and Paisley J.2017b.Removing rain from single images via a deep detail network//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 1715-1723[DOI: 10.1109/CVPR.2017.186]
Fu X Y, Liang B R, Huang Y, Ding X H and Paisley J.2020.Lightweight pyramid networks for image deraining.IEEE Transactions on Neural Networks and Learning Systems, 31(6): 1794-1807[DOI: 10.1109/TNNLS.2019.2926481]
Hu J, Shen L, Albanie S, Sun G and Wu E H.2020.Squeeze-and-excitation networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(8): 2011-2023[DOI: 10.1109/TPAMI.2019.2913372]
Jiang K, Wang Z Y, Yi P, Chen C, Huang B J, Luo Y M, Ma J Y and Jiang J J.2020.Multi-scale progressive fusion network for single image deraining//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 8343-8352[DOI: 10.1109/CVPR42600.2020.00837]
Kang L W, Lin C W and Fu Y H.2012.Automatic single-image-based rain streaks removal via image decomposition.IEEE Transactions on Image Processing, 21(4): 1742-1755[DOI: 10.1109/TIP.2011.2179057]
Kim J H, Lee C, Sim J Y and Kim C S.2013.Single-image deraining using an adaptive nonlocal means filter//Proceedings of 2013 IEEE International Conference on Image Processing.Melbourne, Australia: IEEE: 914-917[DOI: 10.1109/ICIP.2013.6738189]
Kim J H, Sim J Y and Kim C S.2015.Video deraining and desnowing using temporal correlation and low-rank matrix completion.IEEE Transactions on Image Processing, 24(9): 2658-2670[DOI: 10.1109/TIP.2015.2428933]
Kingma D P and Ba J.2015.Adam: a method for stochastic optimization//Proceedings of the 3rd International Conference on Learning Representations.San Diego, USA:[s.n.]: 273-297
Li Y, Tan R T, Guo X J, Lu J B and Brown M S.2016.Rain streak removal using layer priors//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE: 2736-2744[DOI: 10.1109/CVPR.2016.299]
Lin T Y, Goyal P, Girshick R, He K M and Dollr P.2017.Focal loss for dense object detection//Proceedings of 2017 IEEE International Conference on Computer Vision.Venice, Italy: IEEE: 2999-3007[DOI: 10.1109/ICCV.2017.324].
Lu C Y, Tang J H, Yan S C and Lin Z C.2014.Generalized nonconvex nonsmooth low-rank minimization//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus, USA: IEEE: 4130-4137[DOI: 10.1109/CVPR.2014.526]
Luo Y, Xu Y and Ji H.2015.Removing rain from a single image via discriminative sparse coding//Proceedings of 2015 IEEE International Conference on Computer Vision.Santiago, Chile: IEEE: 3397-3405[DOI: 10.1109/ICCV.2015.388]
Peng J Y, Xu Y, Chen T Y and Huang Y.2020.Single-image raindrop removal using concurrent channel-spatial attention and long-short skip connections.Pattern Recognition Letters, 131: 121-127[DOI: 10.1016/j.patrec.2019.12.012]
Qian R, Tan R T, Yang W H, Su J J and Liu J Y.2018.Attentive generative adversarial network for raindrop removal from a single image//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 2482-2491[DOI: 10.1109/CVPR.2018.00263]
Wang T Y, Yang X, Xu K, Chen S Z, Zhang Q and Lau R W H.2019.Spatial attentive single-image deraining with a high quality real rain dataset//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 12262-12271[DOI: 10.1109/CVPR.2019.01255]
Wang Y L, Liu S C, Chen C and Zeng B.2017.A hierarchical approach for rain or snow removing in a single color image.IEEE Transactions on Image Processing, 26(8): 3936-3950[DOI: 10.1109/TIP.2017.2708502]
Wang Y T, Zhao X L, Jiang T X, Deng L J, Chang Y and Huang T Z.2021.Rain streaks removal for single image via kernel-guided convolutional neural network.IEEE Transactions on Neural Networks and Learning Systems, 32(8): 3664-3676[DOI: 10.1109/TNNLS.2020.3015897]
Wang Z, Bovik A C, Sheikh H R and Simoncelli E P.2004.Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600-612[DOI: 10.1109/TIP.2003.819861]
Woo S, Park J, Lee J Y and Kweon I S.2018.CBAM: convolutional block attention module//Proceedings of the 15th European Conference on Computer Vision.Munich, Germany: Springer: 3-19[DOI: 10.1007/978-3-030-01234-2_1]
Yang W H, Tan R T, Feng J S, Liu J Y, Guo Z M and Yan S C.2017.Deep joint rain detection and removal from a single image//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE: 1685-1694[DOI: 10.1109/CVPR.2017.183]
Yang Y Z and Lu H.2019.Single image deraining via recurrent hierarchy enhancement network//Proceedings of the 27th ACM International Conference on Multimedia.Nice, France: Association for Computing Machinery: 1814-1822[DOI: 10.1145/3343031.3351149]
Yasarla R and Patel V M.2019.Uncertainty guided multi-scale residual learning-using a cycle spinning CNN for single image de-raining//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, USA: IEEE: 8397-8406[DOI: 10.1109/CVPR.2019.00860]
Yasarla R, Sindagi V A and Patel V M.2020.Syn2real transfer learning for image deraining using gaussian processes//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle, USA: IEEE: 2723-2733[DOI: 10.1109/CVPR42600.2020.00280]
Yeh C H, Huang C H and Kang L W.2020.Multi-scale deep residual learning-based single image haze removal via image decomposition.IEEE Transactions on Image Processing, 29: 3153-3167[DOI: 10.1109/TIP.2019.2957929]
Zamir S W, Arora A, Khan S H, Hayat M, Khan F S, Yang M H and Shao L.2021.Multi-stage progressive image restoration//Proceedings of 2021 IEEE Conference on Computer Vision and Pattern Recognition.[s.l.]: IEEE: 14821-14831
Zhang H and Patel V M.2018.Density-aware single image de-raining using a multi-stream dense network//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City, USA: IEEE: 695-704[DOI: 10.1109/CVPR.2018.00079]
Zhang H, Sindagi V and Patel V M.2020.Image de-raining using a conditional generative adversarial network.IEEE Transactions on Circuits and Systems for Video Technology, 30(11): 3943-3956[DOI: 10.1109/TCSVT.2019.2920407]
Zhang L, Zhang L, Mou X Q and Zhang D.2011.FSIM: a feature similarity index for image quality assessment.IEEE Transactions on Image Processing, 20(8): 2378-2386[DOI: 10.1109/TIP.2011.2109730]
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
小雪花·成长指南(2022年1期)2022-04-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
第二课堂(课外活动版)(2016年2期)2016-10-21
科技与创新(2015年19期)2015-10-14
科技经济市场(2014年2期)2014-06-20
