
人脸口罩佩戴检测研究综述
2022-05-19 13:25:14王欣然田启川
计算机工程与应用 2022年10期
王欣然,田启川,张 东
1.北京建筑大学 电气与信息工程学院,北京 100044 2.建筑大数据智能处理方法研究北京市重点实验室,北京 100044
自2019年12月以来,一场突如其来的新冠病毒传播疫情在我国乃至全球大范围蔓延并爆发。根据世卫组织最新统计数据显示,截至北京时间2021年10月19日,全球累计新冠肺炎确诊病例已达240 260 449例,死亡病例4 890 424例。目前,全球疫情形势依旧十分严峻,印度、越南等国家疫情的二次爆发,不断变异的病毒变种的出现,为各国的防疫工作带来了新的挑战。呼吸道飞沫是新冠病毒的主要传播途径[1],因此正确佩戴口罩可以有效阻挡病毒的侵袭。全球各国政府都制定了政策,鼓励或要求民众在难以保持社交距离的地方佩戴口罩。但是,仍然有一部分人因为戴口罩麻烦、佩戴时间长不舒服等原因不戴或者不规范佩戴口罩,极大增加了病毒传播的风险。
为了监管人员在人群密集的公共场所(如机场、车站等)中佩戴口罩,工作人员甚至专门被指派进行是否佩戴口罩的检查。然而这种人工监督的方式不但会消耗大量的人力资源,还极易出现误检、漏检等情况,不能实时准确地监控。利用监控摄像头等设备采集图像,再结合深度学习方法可以实现人脸口罩佩戴与否的自动检测,对当前的疫情防控具有重要的应用价值和现实意义。
人员佩戴口罩后,人脸最重要的口鼻区域被这些形状、颜色各异的口罩大面积遮挡,部分五官特征被隐藏,可提取的关键特征点大大减少。特征信息的缺失以及随之出现的噪声混叠等问题使得原本的人脸检测网络性能急速下降,无法准确检测出佩戴口罩的人脸目标,因此需要探寻新的方法解决口罩佩戴检测问题。随着深度学习在计算机视觉领域的飞速发展,利用深度网络可以捕获更多层次、复杂丰富的高级特征,达到更好的特征提取效果,因此受到了许多研究人员的青睐。在目标检测领域,深度学习发挥出了强大的作用,现有基于深度学习的目标检测模型无论在检测准确率亦或检测速度方面都有了质的提升。
近两年,为了更好地进行疫情防控工作,涌现出了大量口罩佩戴检测[2]的研究成果。总体来看,这些检测算法根据应用场景和目的的不同主要分为两大类:一类是在卡口、门禁等位置进行检测,人员距离采集设备近,通过摄像头获取的图像质量较高,一张图像中只含有一个人脸目标。这种应用场景被称为主动场景,对检测精度有一定的要求,通常采取特征提取+图像分类[3]的思路,基于深度神经网络模型来实现。另一类则是应用于人流量大、人群密集的公众场合中。这种应用场景被称为被动场景,背景更加复杂,受到的干扰因素较多,检测范围广、难度大,一张图像中包含多种尺度的口罩人脸目标且大部分为小尺度。为解决这类场景下的行人实时口罩佩戴检测,研究人员借助了一些优秀的通用目标检测模型,在其基础上为适应多尺度口罩人脸目标检测提出了对应的改进方法,取得了一定的进展。
本文梳理了现阶段国内外有关人脸口罩佩戴检测算法的研究工作和成果,依据其应用的不同模型结构归类了相关算法,重点介绍和分析了各类算法的适用场景、优缺点及改进优化策略。由于大部分研究都使用了深度学习方法,从网络结构的设计、多尺度目标检测的处理和训练技巧等方面对其进行了总结和归纳。然后,汇总了相关数据集,对比展现了各算法检测性能,以期为后续的研究提供一些参考。最后,对现有研究中依然存在的问题和未来的发展方向进行了讨论和展望。
1 口罩佩戴检测概述
口罩佩戴检测主要是利用图像分析与处理技术对人脸目标进行口罩佩戴与否的检测和分类,检测的主要步骤包括图像预处理、特征提取和目标分类。根据应用场景和需求的不同划分为两种研究思路:(1)主动场景下的口罩佩戴检测流程如图1所示,对于仅包含单一人脸目标的图像,利用深度卷积神经网络进行特征提取,再设计分类器对目标进行佩戴口罩和未佩戴口罩的分类。(2)被动复杂场景下的检测流程如图2所示,检测算法需要定位图像中所有出现的人脸目标并同时对其进行口罩佩戴与否的分类。
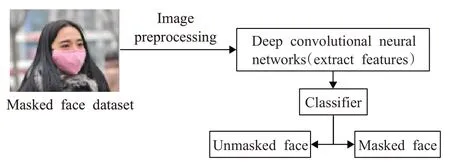
图1 主动场景口罩佩戴检测流程图Fig.1 Flowchart of mask wearing detection in active scenario
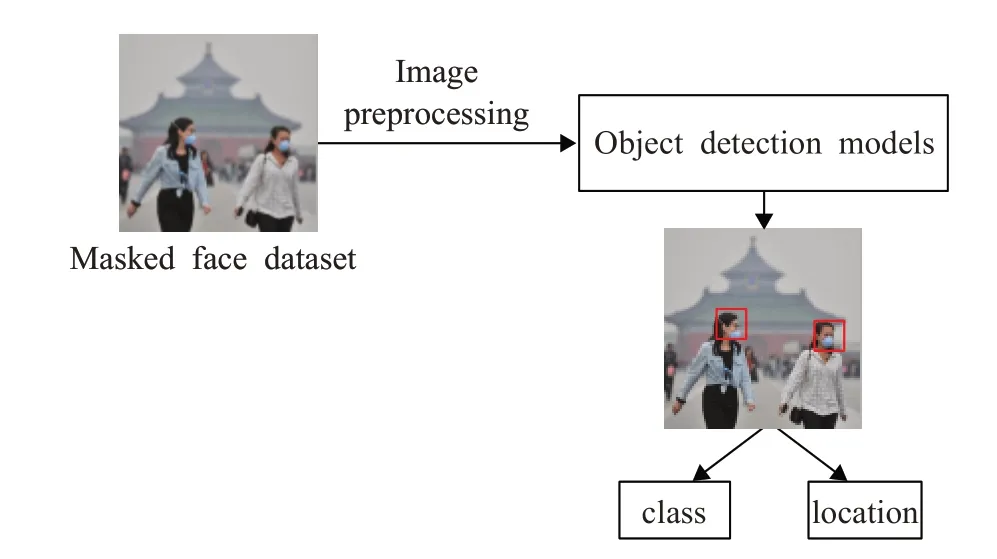
图2 被动场景口罩佩戴检测流程图Fig.2 Flowchart of mask wearing detection in passive scenario
2 基于深度神经网络的口罩佩戴检测
2.1 深度神经网络概述
卷积神经网络(convolutional neural networks,CNN)是深度学习构建的基础,主要由多个卷积层及其包含的卷积核、池化层、全连接层等组成。CNN的出现使得计算机视觉多个领域都得到了突破性的发展,研究人员利用CNN解决了许多一直以来难以克服的技术难关。
2012年,Krizhevsky等人[4]提出:多隐藏层神经网络具有更好的特征学习能力。这是第一次有研究者明确具体提出了深度神经网络(deep neural networks,DNN)的概念。作者设计的首个DNN网络AlexNet在当年的ImageNet识别竞赛(LSVRC)中大放异彩,以打破了历史记录的成绩取得了当时最好的分类结果,由此证明了深层网络的有效性,揭开了深度学习的序幕。自此之后,深度学习发展迅速,出现了一代又一代优秀的DNN网络模型,对于图像特征提取、分类与识别、目标检测等领域的快速发展起到了至关重要的作用。经典的DNN网络发展历程如图3所示。接下来具体介绍在口罩佩戴检测中应用的几种代表性经典网络——VGGNet[5]、Inception系列网络、残差网络(residual network,ResNet)[6]等。

图3 深度神经网络的发展历程Fig.3 Development history of deep neural networks
VGGNet是2014年由牛津大学提出的深层网络模型,通过不断加深卷积层的层数探索其网络性能,以3×3卷积层和2×2最大池化层为基础组件进行堆叠,构建了六种层深不同的结构。VGGNet在图像的特征提取以及分类识别上都表现出了优异的性能,证明增加卷积网络的深度以及使用小卷积核能够有效提升模型性能,减少错误率。目前,VGG-16、VGG-19等网络模型仍然被大量应用。
随着研究人员一味地不断增加网络深度,DNN存在的一些弊端,例如参数量过多、模型体量过大等问题逐渐显现,网络训练愈发难以收敛,甚至出现了梯度爆炸的情况。2014年Google公司提出Inception模块结构,如图4所示,同时发表了首个基于该模块的DNN模型——GoogleNet[7]。Inception模块通过封装不同卷积核的3个卷积层和1个最大池化层,利用模块化体系一定程度上缓解了这些问题。GoogleNet是Inception系列的第一个版本,其采用平均池化取代了全连接层,提高了模型的准确率。
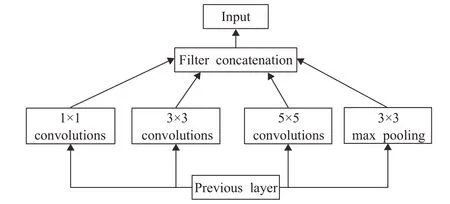
图4 Inception模块结构图Fig.4 Structure of Inception module
随后,Inception系列后续又发展出v2、v3、v4三个版本:Inception-v2[8]引入批量归一化(batch normalization)和级联结构,进一步减少了参数量,增强了网络的非线性表达能力。Inception-v3[9]利用RMSProp优化算法和标签平滑技术[10],降低了模型错误率。而Inception-v4[11]结合最新残差网络的思想进行网络更新,获得了最佳性能。
ResNet则是DNN网络发展的一个重要里程碑,开创性提出的深度残差框架从根本上解决了网络层数深带来的一系列问题,ResNet系列网络最深层级高达152层。这种残差结构的思想极大地推动了深层网络的发展,被广泛用于各类深度学习算法中,大幅提升了算法的准确率和效率。一般网络与残差网络结构对比如图5所示,残差网络引入一个shortcut分支,将期待的输出变为H(x)=F(x)+x,从而减小拟合F(x)的难度。ResNet也有不同的层数版本,ResNet-50最常被应用。
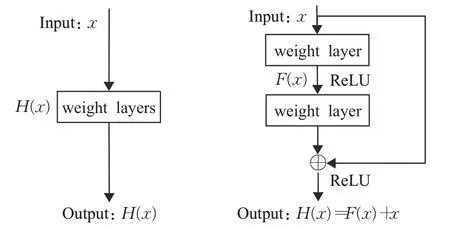
图5 一般网络与残差网络对比图Fig.5 Comparison of normal network and residual network
2.2 基于DNN模型的口罩佩戴检测
DNN模型在与计算机视觉相关的模式识别任务中展现出了优越的空间特征提取能力,因此得到了广泛的应用。与传统的手工特征提取相比,应用DNN对戴口罩的人脸目标提取出更深层次的高级别特征,最终能实现更高精确度的检测。因此,研究人员不约而同地选择DNN模型完成提取特征,由此得到了一系列基于DNN模型的口罩佩戴检测算法。
这类算法主要解决主动场景下人脸佩戴口罩与否的检测。根据算法设计的不同,分类器类型又分为两种实现策略。值得注意的是,DNN训练依赖从大量数据样本中学习图像特征,但当前口罩人脸图像数据集的数量不足以完全支撑深度学习的训练。而现阶段也几乎不存在大规模精确标注的相关数据集。为了克服样本不足的难题,研究人员引入了迁移学习技术,将预先在ImageNet等大型数据集上训练好的DNN模型“迁移”到新的口罩佩戴检测领域中,通过共享模型参数降低对口罩人脸图像数据量的需求,同时还提高了训练的效率。事实证明,在口罩佩戴检测中使用迁移学习是十分有效的方法。
2.2.1 DNN结合机器学习分类算法
近些年以来,利用机器学习方法解决分类问题成为了主流研究手段之一。主动场景下的口罩佩戴检测实质上是一种有监督分类问题,可以利用DNN提取图像特征,再结合机器学习分类算法完成。
Oumina等[12]首先提出了这种方法,他们选择VGG-19、Xception[13]、MobileNet-v2[14]三种DNN模型,结合支持向量机[15]和K最近邻分类[16]两种分类器分别组合实验,所有的组合准确率均超过94%,有效证明了方法的可行性。经过对比,MobileNet-v2+支持向量机的组合表现性能最佳。Loey等[17]则选择了另一种DNN模型ResNet-50,分类器选用决策树、支持向量机和集成学习[18],在混合了人脸佩戴真实口罩和模拟口罩的数据集上进行实验,同样在使用支持向量机做分类器的模型中获得了最高检测准确率。
这类方法在特征提取和目标分类中分别使用不同模型构建了两阶段口罩佩戴检测网络,检测准确率良好,但是建模耗时较长,工序繁杂,计算量大,推理速度慢,训练数据较少时机器学习方法容易产生过拟合,对于一些复杂情况例如用手蒙面的类型不能快速反应,易发生误识别。因此,有研究人员选择直接优化DNN模型的方法,端到端一步到位完成检测。
2.2.2 端到端DNN模型
刘国明等[19]直接基于ResNet-34实现了佩戴口罩与否的检测,主要研究了模型具体应用过程中的训练技巧,探索了解决口罩佩戴检测有效的预处理方法、最优学习率和批数据量大小,改善了对小尺度目标和戴口罩侧脸人脸目标漏检的不足。Gathani等[20]则基于ResNet-50模型,同时借鉴候选区域生成网络提高了检测性能。刘启刚等[21]利用GoogleNet搭建针对实时场景的单阶段口罩检测模型,采用1×1+3×3卷积层结构改进骨干网络来简化模型,设计了包含候选区域筛选与目标分类两个任务的多目标优化函数,极大提升了检测效率。Chowdary等[22]选择优化Inception-v3,删除最后一层,增加平均池化层[23]和ReLU函数减小特征提取误差,加入Dropout层[24]防止过拟合现象,最后通过softmax函数来完成口罩佩戴检测任务。金映谷等[25]则基于MobileNet-v2提出了一种适用于便携移动端设备的口罩佩戴识别算法。为探索不同DNN模型的口罩检测应用效果,Alawi等[26]分别对MobileNet-v2和DenseNet网络进行了实验,准确率均高达98.5%。
上述这些算法模型都取得了不错的检测效果,证明了端到端DNN模型在口罩佩戴检测任务中的有效性。比起结合机器学习的两阶段网络,这类单阶段模型在达到较高识别精度的同时具有更快的检测速度。
然而,基于DNN模型的口罩佩戴检测不能准确显示人脸位置,仅能完成单个目标是否佩戴口罩的判别。DNN模型层数多,体量大,从现实防疫需求的角度考虑,应用可行性较差,运行会占用大量内存,训练时间较长,在计算资源有限的情况下难以部署。实际上,随着疫情形势愈加严峻,仅完成主动场景下的检测已然无法满足需要,在难以保持距离的人群密集场所病毒传播的风险更大,通过智能检测手段及时发现未佩戴口罩的行人,对其进行监督和提醒才能做到最有效的防疫。
3 基于目标检测模型的口罩佩戴检测
3.1 概述
目标检测,通常是指在一幅图像中找到所有感兴趣的目标,并利用矩形边界框来确定其位置和大小[27],同时输出物体类别。目标检测是图像识别中最重要的基础任务之一,在自动驾驶[28]、目标跟踪[29]、视频监控[30]、遥感图像分析[31]中都发挥了关键的作用。目标检测也经历了由传统方法到基于深度学习的检测方法[32]的演变过程。传统目标检测算法基于手工特征提取,泛化性能差,鲁棒性不高,检测的精度和速度均不甚理想,远远达不到实际工业应用的要求。2014年Girshick等人[33]最早提出了首个使用深度学习实现目标检测的模型——RCNN(regions with CNN features),一举将检测平均精度均值(mean average precision,mAP)由35.1%提升到了53.3%,获得了极大的突破,从此开创了目标检测的深度学习新时代。
近些年,基于深度学习的目标检测模型逐步发展壮大,一系列性能优异的算法相继问世并得到了工业界的大规模应用,发展历程如图6所示。这些模型主要分为两大类:(1)基于候选区域的二阶段检测算法;(2)基于边框回归的一阶段检测算法。二阶段算法将检测分为两步进行:首先生成可能包含物体的候选区域,再对该区域做进一步分类校准得到最终结果,代表方法有RCNN系列。一阶段算法则基于回归思想,使用一阶网络直接对输入图像进行分类和定位,速度极快,其代表方法有YOLO(you only look once)系列、SSD(single shot multibox detector)[34]、RetinaNet[35]等。

图6 基于深度学习的目标检测模型发展历程Fig.6 Development history of object detection models based on deep learning
基于目标检测模型的口罩佩戴检测实现被动场景下人脸目标定位的同时判断是否佩戴口罩,这类应用对算法实现多尺度目标检测和实时检测的要求较高。根据应用模型的类别不同也分为两大类:基于二阶段检测模型改进的算法检测精度高,但检测速度较慢,实时性较差;而基于一阶段检测模型改进的算法速度快,可以满足实时性要求,但检测精度稍逊色。研究人员依据场景需求的不同在通用目标检测模型的基础上优化改进以适应口罩佩戴检测,取得了丰硕的成果。
3.2 基于二阶段检测模型的口罩佩戴检测
二阶段检测模型中,RCNN系列最适合用于口罩佩戴检测。在遇到多尺度、小目标、人群拥挤等较难场景的检测时,RCNN系列在检测的准确率上依然具有较强的优势。在RCNN的基础上,2015年Fast RCNN[36]首先通过卷积共享实现了端到端的检测,随后Faster RCNN[37]划时代提出区域生成网络(region proposal network,RPN)和“锚点”(Anchor)机制,取代了之前的选择性搜索,使模型在保证高检测精度的同时将检测速度推向一个新的高峰,RCNN系列也终于走向了实时。Faster RCNN是该系列的集大成者,在VOC 2012数据集上实现了mAP值70.4%,检测速度为17 FPS的优越性能。直到现在,Faster RCNN仍然是主流应用的框架之一,许多新型算法都是在其基础上进行改进实现的。
口罩佩戴检测也不例外,一些研究人员为了追求检测的准确性首选Faster RCNN作为基础架构建立检测模型。Shylaja等[38]利用迁移学习思想,在该模型训练中载入预训练权重,对普通背景和复杂背景两种口罩人脸数据集进行实验,平均精度达到了98.5%。任钰等[39]根据对比实验结果选择使用层数更深且运算量更小的ResNet-101替换原模型VGG特征提取网络,检测精度和速度比原来有明显提升,对场景变化和目标遮挡重叠等情况的鲁棒性也有所改善,但对小尺度目标检测依然不太理想。李泽琛等[40]则主要针对小尺度目标检测效果差的问题,在模型中加入残差结构和注意力机制[41],形成空间-通道注意力残差模块,通过深度融合深浅层特征保留更多输入特征的空间结构信息来有效抑制背景的干扰,提高了对小目标的检测精度,降低了漏检率。万子伦等[42]注意到传统单一的RPN网络在处理远距离口罩人脸小目标时会发生误检,于是引入多个RPN进行多任务增强,又设置五种新尺度,将Anchor数量增加至15,改进后模型对多尺度口罩人脸目标的检测能力有了明显提升。
目前基于二阶段检测模型的口罩佩戴检测重点关注多尺度目标检测能力的提高,利用多种优化策略增强模型性能,以应对被动场景下口罩人脸目标排列无序、尺度不一甚至不同目标发生重叠遮挡的情况。由于二阶段模型本身检测精度较高,在口罩佩戴检测应用中改进模型的mAP值均表现突出。但两阶段结构比较复杂,检测步骤多,运行消耗大,又为提高性能引入优化模块,进一步加重了训练的成本负担,在速度方面表现不甚理想,无法实现实时检测,也较难部署于便携式或移动端设备上。针对以上问题,后续研究可尝试利用轻量级模块或网络做进一步优化,在保持高精度的前提下突破速度难关。而一阶段检测模型在速度上具有先天性优势,更适合于公共场所中实时监督行人口罩佩戴情况的场景需求,其关注重点则是检测精度的提高以及现实应用对低成本部署和运行的要求。
3.3 基于一阶段检测模型的口罩佩戴检测
3.3.1 基于改进YOLO的口罩佩戴检测
一阶段检测模型中应用最多的当属Redmon等提出的YOLO系列。YOLO凭借其强大的实时检测性能真正推动目标检测走向了大规模落地应用。YOLO系列直到YOLOv3[43]版本才同时兼顾到检测精度和速度两方面性能,真正走向成熟。之后的YOLOv4[44]、YOLOv5虽然不再是一脉作者的延续,但也表现出了不错的性能。YOLO系列算法检测速度极快,并且具有良好的检测精度,适用于对实时性要求较高的被动场景下的口罩佩戴检测。这其中,YOLOv3具备独具特色的多尺度检测框架,可以有效捕捉复杂背景下不同尺度的口罩人脸目标。YOLOv4采用一系列优化和训练技巧提升检测性能,降低了模型的应用成本。而YOLOv5则更加灵活小巧,易于部署,且保持了较高检测精度的同时,进一步加快了模型的推理速度,耗时更短,达成了目前该系列速度和性能的最佳平衡。YOLOv5共包含4个版本,即YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,依次增加网络结构的深度和宽度,速度相对降低,但精度提升,以满足不同实际应用的需求。综上,YOLO模型能够实现高速度与高精度并存的多尺度检测,在现实场景的实时应用上更具优势。但YOLO模型即便对类别数较多的检测任务都具有很好的通用泛化性,对于口罩佩戴检测任务只需检测两类目标,更需要做出针对性的优化调整。
基于改进YOLOv3的口罩佩戴检测进一步加强了模型对小尺度目标的捕捉。王艺皓等[45]在原有模型框架上加入跨阶段局部网络[46]、空间金字塔池化[47],增强对浅层特征的提取,又利用特征融合策略实现特征复用,通过综合局部和全局两方面语义信息提升了小目标检测精度。曾成等[48]通过将3×3类金字塔结构扩建为4×4,对浅层特征提取部分增加一个新的预测分支,使模型对小目标的检测精度升高了7.2个百分点。张路达等[49]受此启发,增加4倍下采样和104×104尺度特征图,结合自上而下与自下而上的路径增强策略达到了更好的效果。孙世丹等[50]预先使用加权核K-Means聚类算法重新选取更适合小目标检测的Anchor Box,而后又通过将4倍下采样得到的特征图进行上采样与上层特征信息相融合的操作,整体提高了小目标检测准确率。曹城硕等[51]嵌入注意力机制模块SENet[52],增加重要特征通道的加权比重,抑制无关干扰,明显改善了对小目标的检测性能。而程可欣等[53]从改进损失函数的角度优化模型,选择GIoU[54]计算边界框回归损失,该方法使小目标漏检率明显降低。
基于YOLOv4的口罩佩戴检测比较容易受到复杂光照的干扰而导致效果不佳。管军霖等[55]建立了一种新型图像高低频成分融合法,应用数总变分模型分别获取高频和低频成分,采用最小二乘法来估计光照阴影的最佳重建系数,利用这种光线正则化方法重构均匀光照下的人脸图像,以消除光照不均匀影响。而冉鹏飞[56]则选择改进模型框架,在YOLOv4主干网络中嵌入卷积注意力模块,重点关注复杂光照下图像的特征表达,获取更多空间细节信息,实现了无论在光照偏强还是偏弱的条件下均表现良好的检测效果。
基于YOLOv5的实时口罩佩戴检测也具有很大的研究空间。谈世磊等[57]将归一化处理后的图像送入YOLOv5中进行训练,取得了优异的检测性能,证明了方法的可行性和实用性。肖博健等[58]则通过K-Means聚类算法重设初始候选框参数、利用可变形卷积修正特征图、优化特征函数等多方面对模型进行改进,稳定提升了模型的准确率和召回率。
总体看来,YOLO模型改进后实现了快速高效的口罩佩戴检测,且对光照、遮挡、小尺度等难题都有了一定程度上的改善,检测效果良好,目前已成为被动场景下口罩佩戴检测实现的主要方式。但改进后模型仍存在参数量大、结构冗余的问题,依旧难以部署,甚至由于优化策略反而加重了模型的复杂化。考虑到实际应用需求的硬件部署和训练成本问题,改进YOLO模型的轻量化研究也是不可或缺的一部分。
3.3.2 基于YOLO的轻量化口罩佩戴检测
研究人员在YOLOv4框架基础上进行口罩佩戴检测的轻量化研究。叶子勋等[59]将骨干特征提取网络替换为MobileNet-v3[60],再利用自注意力机制和SiLU激活函数优化检测性能。改进后模型参数量骤减,占用内存从244 MB减小到44 MB,运算量也减为之前的1/8,检测速度提升了近一倍。罗禹杰等[61]同样应用了MobileNet,又采用自适应空间特征融合方式[62]增强性能。丁培等[63]引入轻量级骨干网络Light-CSPDarkNet,又利用轻量级特征增强模块和多尺度注意力机制,使算法精度提高了3.55%,检测速度由35 FPS增加至75 FPS,可以满足实际应用的需求。
另有研究人员则直接选用了YOLOv4-tiny进行口罩佩戴检测。YOLOv4-tiny是该系列的一个轻量化框架,架构简单,经常被用于嵌入式平台中进行快速目标检测。但YOLOv4-tiny的特征提取能力相对较弱,为了提升检测精度,王兵等[64]加入Max Moudle结构,分别用大中小不同尺度的窗口对卷积特征进行最大池化,同时保留上层特征进行特征通道融合。改进后模型提取的特征图能够更好地表达输入图像的边缘信息和主要特征,从而取得了不错的效果。朱杰等[65]引入空间金字塔池化增强网络感受野,又结合路径聚合网络提升特征表达,并在训练时利用标签平滑技巧防止数据过拟合,对口罩目标的检测精度达到了94.7%,实时检测速度提升至76.8 FPS。叶茂等[66]改进残差结构简化模型以达成实时检测,增加多尺度输出结构,增强低层特征层表达,降低小目标漏检率,采用多层级交叉融合结构提高特征利用率,改进算法模型只要5.8 MB且mAP值提高了5.3%,CPU下处理时间加快了13 s,能够满足计算资源有限的条件下应用的实时要求。
彭成等[67]基于YOLOv5模型设计了成本更低的GhostBottleneckCSP和ShuffleConv模块,优化后模型的参数量和计算量分别减少为原模型的34.24%和33.54%,使其更加容易部署在资源有限的嵌入式或移动端设备上,大幅提高了运行速度。
整体来看,改进YOLO模型实现轻量化口罩佩戴检测实现了不错的效果,同时也是未来人脸口罩佩戴检测技术最大的发展趋势。但轻量化改进势必会造成精度的损失,现阶段多数算法弥补检测精度的策略良莠不齐,在不同数据集上的实验效果无法统一。轻量化改进是该领域一大重要研究热点,将成为理论走向现实场景应用最重要的关键性环节。
3.3.3 其他模型在口罩佩戴检测中的应用
除了大量使用YOLO作为基础框架解决口罩佩戴检测问题之外,一阶段检测模型中SSD和RetinaNet也常被应用。SSD结合了Faster RCNN的区域生成和YOLO的回归思想,通过增加深度卷积层提高检测精度,利用多层次特征图实现了多尺度目标检测。而RetinaNet则是提出Focal Loss损失函数,用以改善一阶段检测模型因正负样本类别不均衡导致的检测精度不理想的窘况,效果显著,其在COCO数据集上的平均检测精度甚至超过了Faster RCNN。同时,RetinaNet利用特征金字塔[68]完成多尺度目标预测。综上,SSD和RetinaNet具有一阶段检测模型的快速检测性能和良好的检测精度,具备多尺度检测能力,可以被应用于口罩佩戴检测任务。
研究人员基于SSD模型进行改进,完成口罩佩戴检测。李雨阳等[69]引入特征融合和协调注意力机制,结合Focal Loss损失函数调节正负样本权重,改进后算法精度提高了5.62%。阮士峰[70]引入多重阈值修正并增加特征融合层,结合数据集增广方法,有效提高了对口罩人脸的检测性能。Nagrath等[71]则首先使用SSD检测口罩人脸,然后结合MobileNet-v2进行分类,也得到了不错的效果。毛晓波等[72]则将特征提取网络直接替换为MobileNet-v3,选用计算量较小的H-Swish激活函数、轻量级注意力机制等优化策略加快了检测速度,提高了精度,在嵌入式设备Jetson Nano上进行了应用实验,虽实际效果不佳,但前后对比实验证明了改进方法的有效性。
邓黄潇[73]应用RetinaNet进行口罩佩戴检测实验,结果证明其对于小像素级目标表现性能较为突出。2019年Deng等[74]将RetinaNet应用于人脸检测,提出了单阶段人脸检测器RetinaFace,实现了多任务训练。而口罩佩戴检测也可以看作是一种特殊的人脸检测任务。牛作东等[75]在RetinaFace模型中加入注意力机制模块增强口罩人脸的特征表达,又设计了多任务联合损失提高训练效率。改进算法在自然场景下对口罩人脸的检测性能良好。基于以上研究,文献[76]专门提出了一种高精度、高效率的专用人脸口罩检测器RetinaFaceMask,虽然性能还有待提高,但是为后续研究提供了一个很好的研究思路。
综上所述,基于一阶段检测模型的口罩佩戴检测在检测速度、实时性能上略胜一筹,但检测精度相对较低,易受背景干扰。被动场景复杂多变,通过一系列优化改进策略可以有效提升算法的检测精度和鲁棒性。该类算法可以实现人脸目标定位和佩戴口罩检测并行多任务目的。目前,基于改进YOLO的模型最受研究人员青睐,是当前研究最多的主流方向,发展较为成熟,但后续还应顺应趋势,加强对模型轻量化压缩和降低部署应用成本的研究。而其他各类一阶段检测模型目前成果偏少,相对研究不充分,且从总体应用效果来看略显不足,还有待进一步探索。
4 相关数据集
数据集是深度学习训练的基础,对于模型性能的提升和量化评估具有重大影响。但目前专门用于口罩佩戴检测的相关数据集较少,一些大型遮挡人脸数据集,例如WiderFace[77]和MAFA[78],包含有佩戴口罩的人脸图像样本被研究人员关注到,他们从中对数据二次筛选,再重新清洗标注形成自己的实验数据集。而后才逐渐出现了一些质量良好的口罩佩戴检测专用数据集,常被应用的数据集主要有RMFD(real-world masked face dataset)[79]、AIZOO、MaskedFace-Net[80],详细介绍如表1所示。
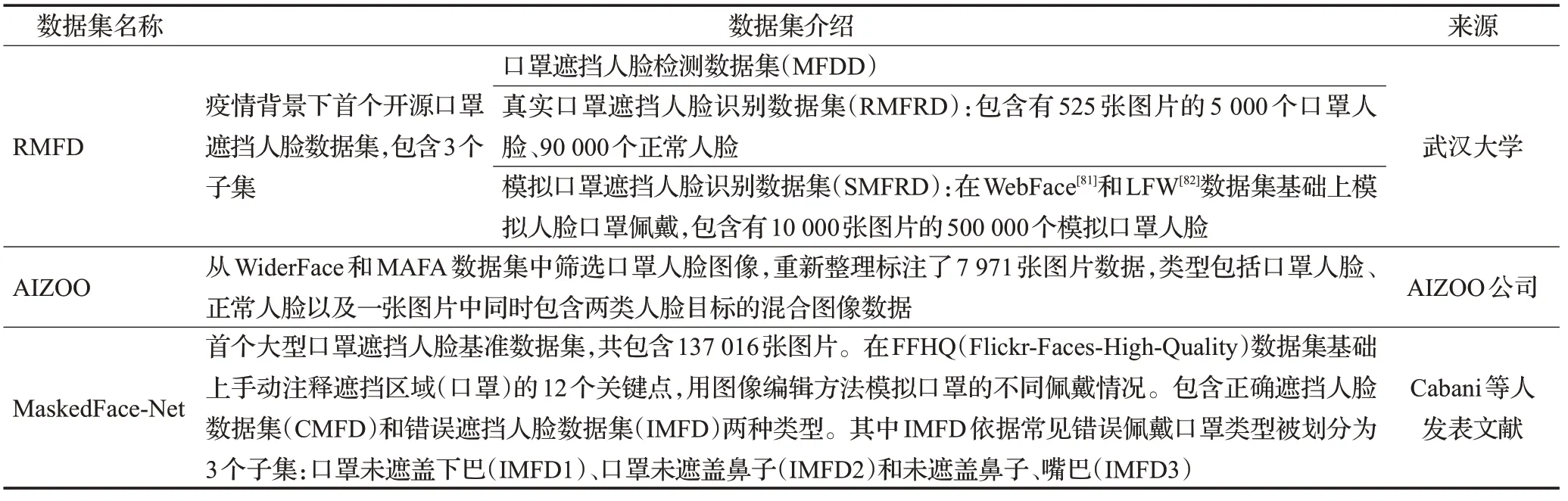
表1 常用口罩佩戴检测数据集Table 1 Common datasets of face mask wearing detection
5 检测算法性能对比
基于深度学习的口罩佩戴检测已经成为当前计算机视觉领域备受瞩目的热点话题,具有广阔的研究应用前景[83]。上文分别对各检测算法的改进策略、适用场景、优势和局限性进行了详细介绍。为展现各类方法在口罩佩戴检测任务中的最优性能,对上述性能表现优异的算法从关键改进结构、实验数据集和具体性能表现等角度进行全面对比总结[84],如表2、表3所示,表4为各方法综合定性分析结果。衡量这些检测算法常用的性能评价指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、mAP、FPS。准确率指正确预测的结果占全部样本的比重,精确率指预测正样本中实际正样本的比重,召回率指预测正确的正样本占实际正样本的比重,定义为:
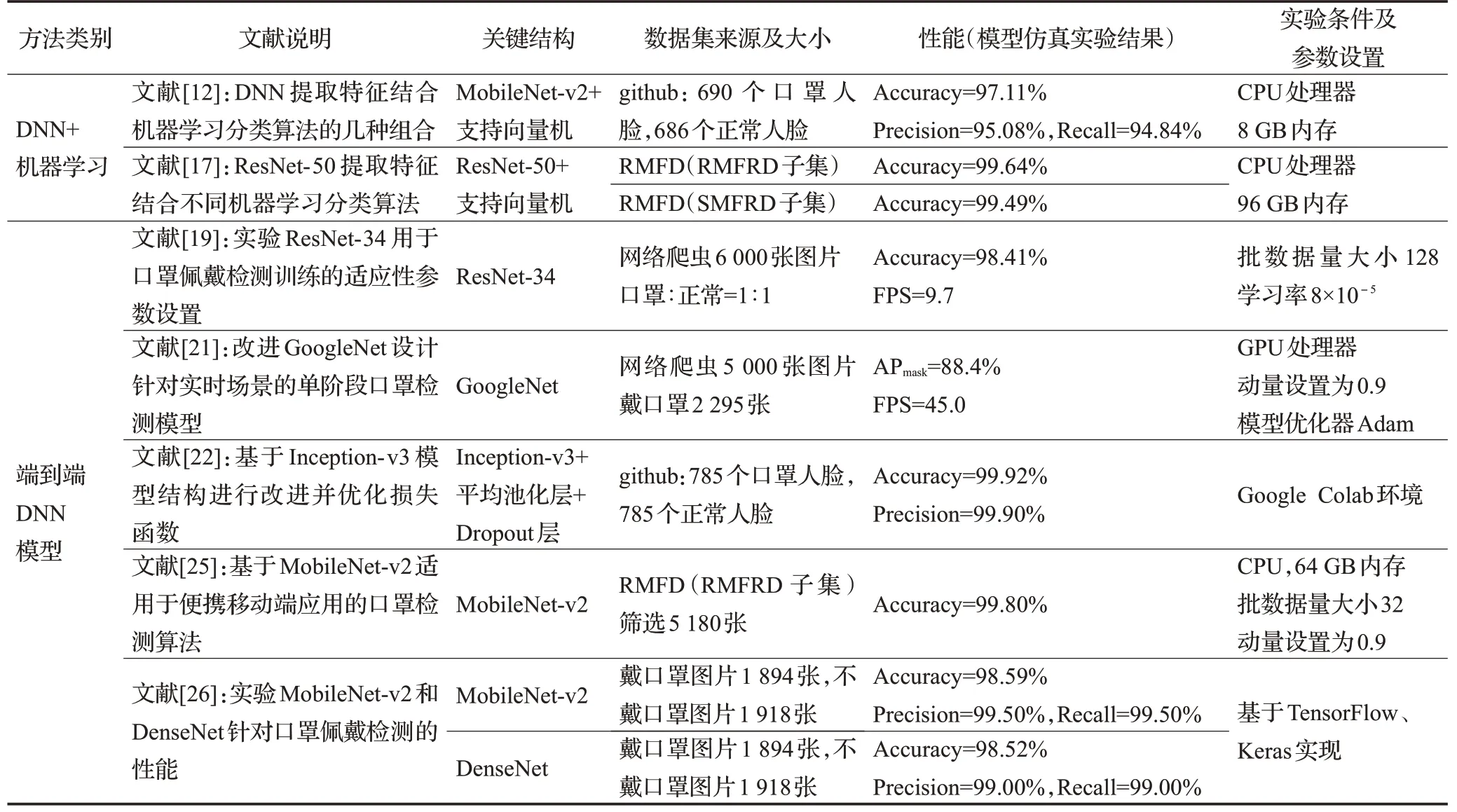
表2 基于深度神经网络的口罩佩戴检测算法性能对比Table 2 Performance comparison of face mask wearing detection algorithms based on deep neural networks
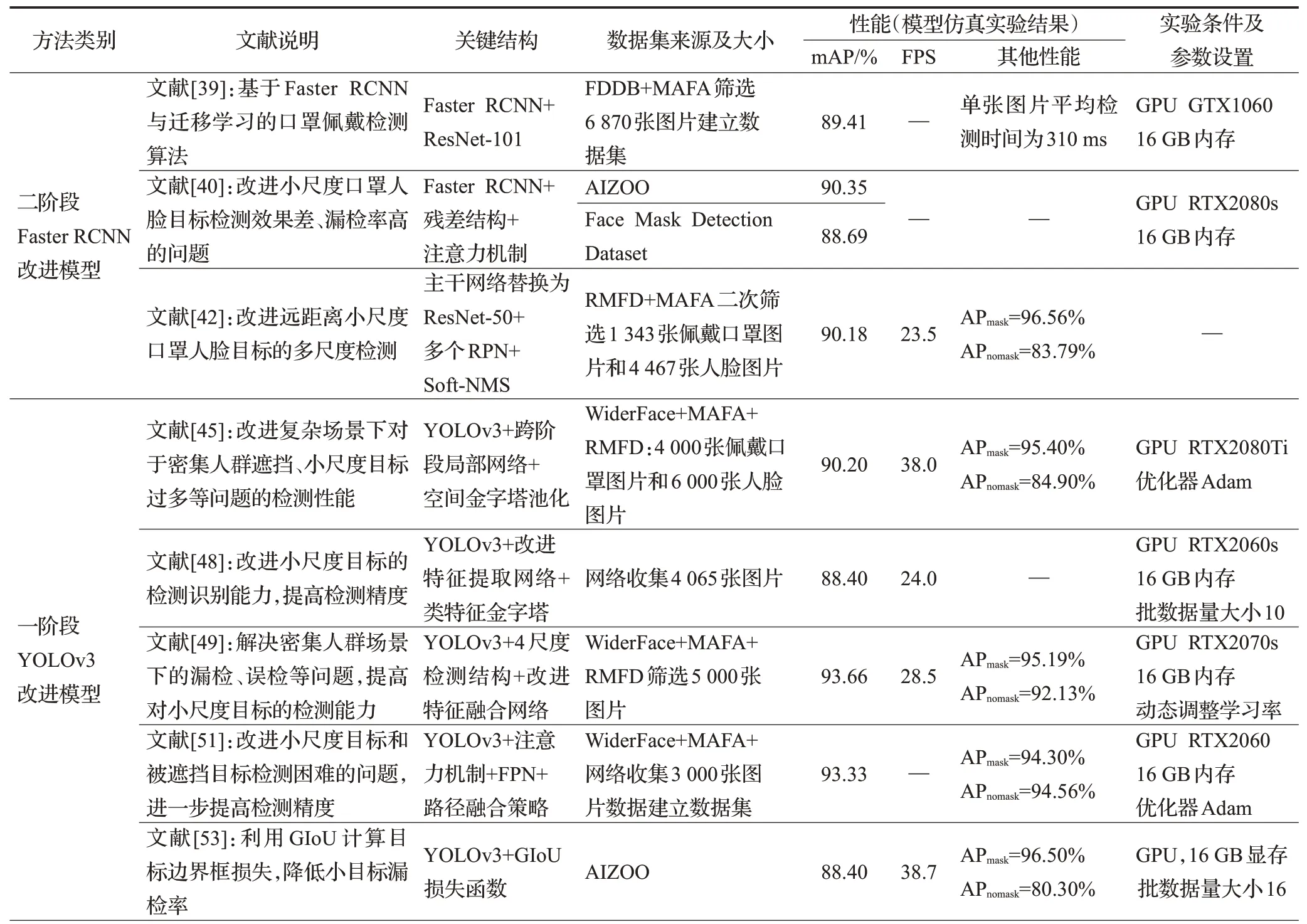
表3 基于目标检测模型的口罩佩戴检测算法性能对比Table 3 Performance comparison of face mask wearing detection algorithms based on object detection models
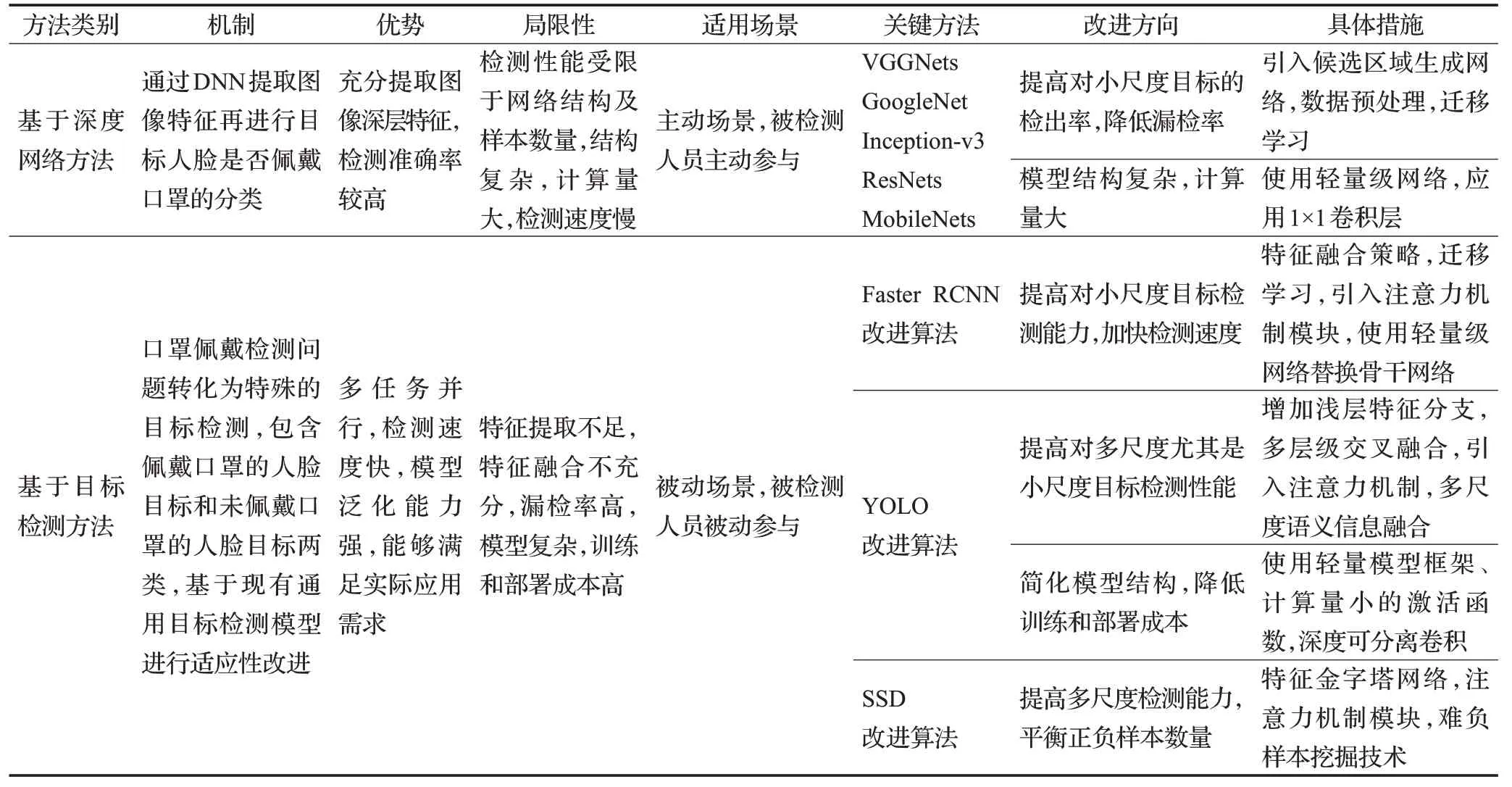
表4 口罩佩戴检测算法性能定性对比Table 4 Qualitative comparison of mask wearing detection algorithm performance
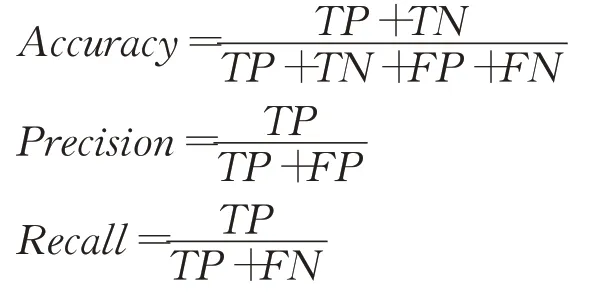
其中,TP指正样本被正确预测为正样本;TN指负样本被正确预测为负样本;FP指负样本被错误预测为正样本;FN指正样本被错误预测为负样本。
平均准确率(average precision,AP)、平均准确率均值(mAP)常用于评价目标检测精度。定义为:
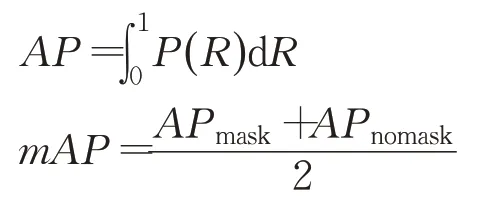
其中,P、R为精确率和召回率,P()R表示映射函数关系,n表示类别数,i为某个单一类别。mAP为全部类别AP的均值,在口罩佩戴检测中包含佩戴口罩和未佩戴口罩两种类别,mAP反映整体检测效果。
FPS指每秒传输检测图像的帧数,常用于评价目标检测网络的检测速度。
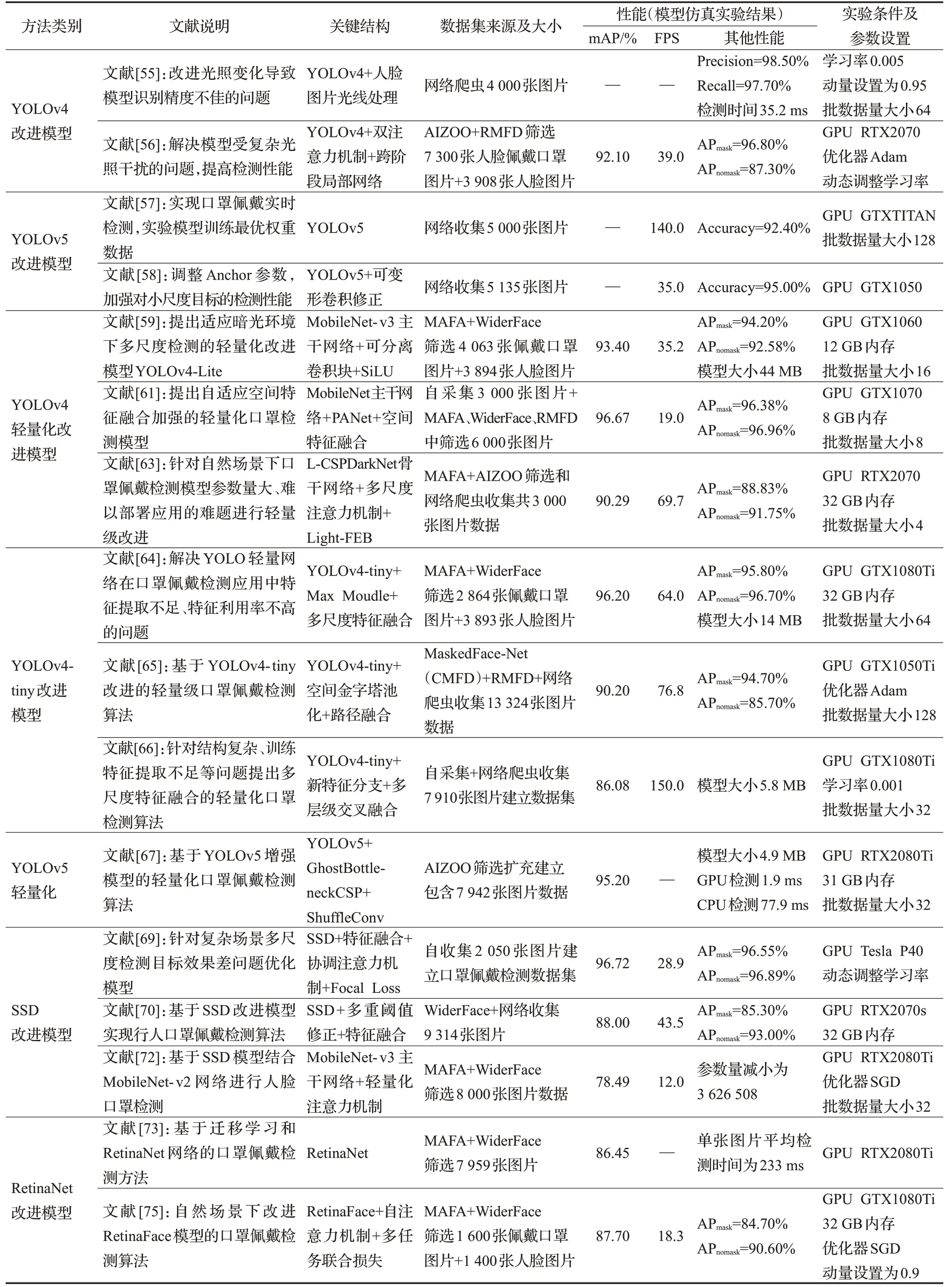
表3(续)
由上述分析可得,基于DNN模型的检测算法总体检测准确率均较高,检测精度良好,但速度方面表现不佳甚至无参考数据,证明此类算法检测速度慢,不能适用于实时性要求较高的场景。基于目标检测模型的算法中,YOLO改进算法在检测精度和速度两方面都明显优于其他模型,其中YOLOv4、YOLOv5的改进模型在精度和速度之间达成了很好的平衡,YOLOv3改进模型虽精度略胜,但速度稍逊。另外,最值得关注的当属YOLO轻量化改进模型,性能表现突出,进一步验证了轻量化模型研究的可行性和必要性。
从表中还可以看出,大部分算法的数据集都来源于遮挡人脸数据集的二次筛选,有些甚至直接利用网络爬虫收集。原因在于目前依旧缺乏具有代表性、质量良好的真实场景下大型口罩人脸基准数据集。这也是目前口罩佩戴检测存在的最大问题。但从数据表现总体来看,基于成熟的深度网络模型可以基本完成口罩佩戴检测任务,研究人员提出相应的改进算法也能有效增强对多尺度目标的检测能力,抑制复杂背景干扰,未来还需在更完整的数据集上探索更优的性能。
6 总结与展望
本文围绕国内外现有的口罩佩戴检测算法研究进行了分类总结,主要是主动场景下基于深度神经网络模型和被动场景下基于目标检测模型进行检测两大类方法。总体来看,这些算法都是在成熟模型的基础上改进实现的,并采用了多种优化策略以提升对口罩人脸图像的处理能力。这些新型改进算法在精度和速度上都有了长足的进步,在面对小尺度、复杂光照、遮挡等较难问题时也有所改善,基本完成了检测任务。但在具体应用过程中依然存在着一些问题,未来还有很大的发展空间,对此提出以下几点研究趋势展望:
(1)口罩不规范佩戴情况识别。目前口罩佩戴检测只解决了口罩佩戴与否的检测问题,但是在实际生活中经常出现行人不规范佩戴口罩的情况。例如,口罩只遮盖了嘴巴、挂到下巴上等,无疑使防护措施失效,加重了疫情传播的风险。因此,未来利用智能算法实现口罩不规范佩戴情况的识别也显得尤为重要,值得深入研究。
(2)研究更轻型、易部署的算法。口罩佩戴检测作为防疫利器,仅在理论实验中实现是远远不够的,更需要在现实场所中得到实际应用。这就需要模型更加轻量化,应用成本更低,且受硬件设备约束,这些模型大多都会被应用于嵌入式、移动式设备中[85]。如何从理论研究走向落地应用也是亟待解决的关键问题。
(3)弱监督口罩佩戴检测模型。从现有研究来看,口罩人脸相关数据集仍然稀缺,而DNN网络和目标检测模型的应用一般都基于监督学习,需要大量的标注数据。样本的缺少和大量繁杂的数据标注工作也是目前制约口罩佩戴检测发展的原因。因此,利用弱监督学习方法,在标注样本较少的情况下设计口罩佩戴检测模型可以成为未来研究的方向之一。
(4)口罩人脸识别。口罩遮挡下人脸识别的实现在检测算法逐步发展完善的基础上可以进一步研究[86]。疫情常态化发展形势下,人工智能技术如何在疫情防控中继续发挥作用,也是未来应继续重点关注的话题。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
动漫星空(2018年9期)2018-10-26 01:17:14
电子制作(2018年11期)2018-08-04 03:25:38
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
发明与创新(2015年33期)2015-02-27 10:40:09
