
基于新型卷积神经网络的非侵入式负载监测方法
2022-05-19 05:49:44马临超
智慧电力 2022年4期
马临超,杨 捷,肖 鹏,曾 杰
(1.河南工学院电气工程与自动化学院,河南新乡 453003;2.云南电网有限责任公司,云南昆明 650000;3.东北电力大学电气工程学院,吉林长春 132012)
0 引言
非侵入式负载监测(Non-intrusive Load Monitoring,NILM)的目的是通过负载总耗电量来估计某一特定设备的耗电量,并将多个设备的总耗电量分解为单个设备的能耗量[1-2]。NILM 的优势是终端用户可获取单个设备的能耗数据,并优化单个设备的能耗行为[3]。已有研究表明,获取单个设备的用能行为有利于为用户节省12%的能源,因此,NILM 有利于电网公司和用户降低自身运行和用能成本[4-5]。NILM 的方法一般可分为有监督算法和无监督算法2 类。有监督算法指通过已有的单个设备能耗数据训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单地判断,从而实现预测和分类的目的,具有了对未知数据进行预测和分类的能力[6-7]。无监督算法事先无任何设备能耗的训练样本,直接对数据进行建模,通过聚类对数据进行处理。有监督算法与无监督算法的区别在于数据是否存在标签[8-11],且有监督算法更适合于解决复杂负载监测问题[12-13]。然而,2 种方法在某些方面具有一定局限性[14-17],如精度较低、未考虑负载数据多时间尺度耦合特性等,故需要研究更为精确全面的有监督型NILM 方法。
随着深度神经网络的发展,提出多种基于神经网络的有监督NILM 方法[18-20]。神经网络在NILM中的应用始于递归神经网络(Recurrent Neural Networks,RNN)、卷积神经网络(Convolutional Neural Networks,CNN)和去噪自编码器(Denoising Auto-Encoders,DAE)。CNN 结构灵活性较大,受到国内外学者的广泛关注[21-22],提出了各种改进CNN模型,如序列对点、序列对序列等,进一步丰富了CNN 架构的设计。文献[23-25]通过增加开/关状态分类子网络,使模型可以直接学习开/关状态信息,从而提升CNN 网络的估计精度。文献[26-28]通过增强CNN 多时间尺度特征,以对更多层次进行采样,并实现多时间尺度特征的关联,其广泛应用于目标检测、语义分割等计算机视觉任务中,以获取多尺度信息及耦合关系。文献[29]指出当信息前后的相关性较高时,通过增加自我关注机制,可有效提升模型的预测精度。考虑到不同设备的能耗特性往往不同,不同设备的负载特性曲线差异性较大,当多个设备组合使用时其负载曲线特性将更为复杂[30],因此,NILM 需要具备处理大规模复杂负载变化的能力。除了短时间尺度本地信息外,考虑大规模负载在时间上的耦合特性,挖掘能耗行为具有重要意义。因此,在处理大规模复杂负载集群过程中会产生很高的错误率。
基于此,本文提出了一种基于可缩放感知卷积神经网络的非侵入式负载监测方法,模型包括多时间尺度感知与特征提取模块、自我关注模块和对抗损失模块等。多时间尺度感知与特征提取模块可获取与整合不同时间尺度负载数据的耦合特征,自我关注模块和对抗损失模块根据耦合特性来进一步提高监测模型的估计精度。本文设计了一种多时间尺度感知与特征提取的CNN 结构,极大地提高了对多种用能设备能量分解的准确度,并能挖掘不同设备的用能相关性;在所建模型中增加了对抗性损失,有效提高模型的准确度和广泛性。最后,通过实例仿真验证了所提模型的有效性和优越性。
1 监测模型及训练方法
1.1 负载监测问题的描述
1.2 监测模型的设计
监测模型具有2 个子网络[31-32],即fpow和fon。为表示第i个设备开关状态的辅助序列,预测的开关状态概率序列为因此,模型的最终输出为:

式中:⊙为相乘。
1.2.1 尺度感知特征提取
模型的尺度感知是通过在原始网络中加入不同扩张率的平行分支,并通过简单的门控机制将2个子网络中的分支连接起来,使回归网络只保留最重要的部分以不同比例绘图。图1 为不同扩张率(rd=1,2,3)的扩张卷积图。

图1 不同扩张率的扩张卷积图Fig.1 An illustration of dilated convolution with different dilation rates
由图1 可知,相同的层数和参数下,更大的rd使输出节点对输入时间范围响应更大。因此,不同rd分支的输出将反映输入时不同时间尺度的元素。同时,当使用更大的rd时,输入端的元素将影响更多的输出节点。为fpow支的输出,为含s激活函数的fon分支的输出,2个子网络之间的门控机制可表示为:

由于门控制机制是针对每个扩张率单独进行的,所以可以在不同的时间尺度上实现丰富的特征组合。将连接起来,得到p(2)和s(2)。p(2)和s(2)都经过核大小为1 的卷积层处理,生成p(3)和s(3)作为自我关注模块的输入。
1.2.2 前后信息感知特征的关联性
前后信息感知特征的关联性是通过自我关注模块实现的,模块含L时间步长和C通道的输入z∈RC×L。模块学习1 个额外的特征映射r∈RC×L,每个时间步长值通过关注z中的所有时间步长得到的。首先,映射输入z含g(z)=Wgz和g(z)=Wgz,自我关注矩阵A中的元素可表示为:
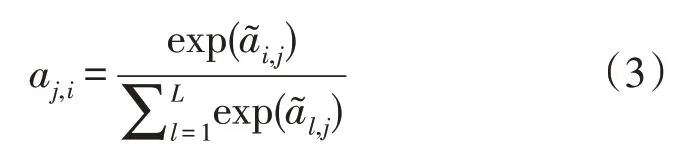
式中:aj,i为计算第j个时间步长的响应时分配给第i个时间步长的关注值。
计算额外的特征图r为:

自我关注模块的输出定义为:z+γr,γ初始化为0,在训练模型时进行更新,使模型可以首先依赖局部前后信息,逐渐学习提取全局前后信息中的关联性。权矩阵Wg,Wh和Wd运用到卷积层,其核大小为1。
对于2 个子网络,自我关注模块可以表示为:p(4)=p(3)+γprp和s(4)=s(3)+γsrs,其中,γp和rp为附加特征映射;γs和rs为相关系数。模型的损失函数和2 个子网由L=Lout+Lon得到,其中,Lout为采用均方误差测量整个解集模型的误差;Lon为采用二进制测量开/关状态分类子网络的误差。
1.3 提高模型准确性的训练方法
通过在模型中增加对抗性损失,进一步提高监测模型的性能。本文在模型中加入1 个对抗网络,使模型可以部分训练为带有梯度惩罚的Wasserstein 模型。原始模型由产生器G 和鉴别器D 之间的极小-极大对策来表述,即:

式中:Pr为真实数据的分布;Pg为=G(b),b~p(b)产生的数据分布,表示G 的输入是从某个噪声分布中采样的。
鉴别器的目标是获得区分真实样本和生成样本的能力,生成器试图通过学习生成真实的数据样本来混淆鉴别器。轮流训练产生器和鉴别器,使产生器逐渐获得产生真实样本的能力。本文采用WGAN-GP 模型[25],该模型采用Wasserstein 距离来稳定模型的训练。WGAN-GP 中的梯度惩罚是D的梯度的范数,而不是裁剪D中的权重。WGANGP 损失可表述为:

其中,前两项为Pr和Pg之间的Wasserstein 距离。最后一项为梯度惩罚,â~Pâ为从Pr和Pg采样的线段连接点进行均匀采样。本文采用产生网络fout(xt)作为发生器,不是从噪声分布中生成样本。本文在模型中增加了对抗性损失Ladv,这样整体损失函数变为:
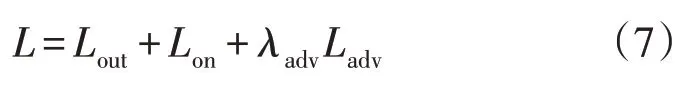
式中:λadv为对抗性损失的权重。
期望对抗性损失可以帮助模型产生更真实的输出序列,特别是当训练数据集的大小相对较小的时候。此外,本文采用通路状态增加来解决用电设备负载需求的变化。给定设备,确定最大偏移量e-和e+,将每个输出序列y替换为y+eo,其中,e~U(e-,e+)。添加同样数量的通路状态偏移量到相应的输入序列x中。在模型的训练过程中应用这个增量。本文将通态增量应用于家用冰箱,因为通态功率的偏差估计是分解误差的主要来源。
2 实验结果与分析
2.1 实验参数与实现手段
本文使用2 个真实的数据集REDD[26]和UKDALE[27]来评价所提模型的性能。REDD 数据集包含来自美国6 个家庭的测量数据,不同家庭的数据集时间跨度为23~48 d。每1 s 记录1 次电力消耗,每3 s 记录1 次电器消耗。UKDALE 数据集包括5 个英国家庭的数据,每6 s 记录1 次总消耗和个人电器的消耗。1 号家庭的监测时间超过600 d,其余房屋的监测时间范围为39~234 d。本文采用2-6 号家庭的数据创建训练集,保留1 号家庭的数据作为REDD 数据集的测试集。家用电器有冰箱、洗碗机和微波炉。此外,本文使用的REDD 数据集的预处理数据方法出自文献[2]。对于UKDALE 数据集,本文使用1 和5 号家庭进行训练,使用2 号家庭进行测试。为了使数据归一化,本文将2 个数据集的功耗值除以612,这是REDD 数据集中2~5房屋的总功耗的标准差。
子任务网络(Subtusk Gated Netword,SGN)中每个子网中有6 个卷积层和2 个全连接层(Fully Connected Layer,FC)层。每层的滤波器个数分别为30,30,40,50,50,50,核大小分别为10,8,6,5,5,5。所有卷积层都以步长1 和“相同”的填充来实现,权重为“正常”初始化器初始化。第1 层FC 有1024 个隐藏节点,第2 层FC 有与模型输出相同的节点数。除了最后一层以外,所有的层都使用了ReLU 激活函数。对于REDD 数据集,输出序列大小s为64,附加窗口大小w为400,而UKDALE 数据集s和w分别为32 和200。由于UKDALE 数据集的输入和输出大小减少了一半,故将内核大小更改为5,4,3,3,3 和3,而其他超参数保持不变。此外,本文采用初始学习率为0.000 1 的Adam 优化器,对模型进行5 个时期的训练,批处理规模为16。对于所提模型,从第4 个卷积层开始,在每个子网络上增加2 个并行分支rd=2 和rd=3,并产生p(3)和s(3)的层有64个过滤器,因此,对于自我关注模块C=64,本文设置Cˉ为32。本文模型的超参数来自文献[2],所有模型都是在Python 3.6 和Keras 2.1.6 中实现。
输入样本是通过滚动采样周期在具有特定步长的输入序列上运行产生的,对于REDD 数据集,步长设置为2。微波炉、洗碗机、冰箱、洗衣机和热水壶的步长分别为4,8,32,32。UK-DALE 数据集为32。本文通过确保SGN 模型的性能不低于文献[2]来选择步长。1 个步长为2 的滚动采样周期生成输入样本,将多个重叠输出序列取平均值以产生最终输出。此外,作为通路状态事件在一些设备中相对比较少见,故通路状态的不平衡会给模型的训练带来困难,因此,本文从一些设备的训练数据集中随机删除非状态样本。对于REDD 数据集保持断开状态样本的概率,洗碗机为0.2。对于UK-DALE数据集,洗碗机、微波炉和热水壶的概率分别为0.02,0.05 和0.1。
为了实现WGAN-GP,本文给出了1 个简单的对抗网络,它有4 个卷积层,每层有32 个滤波器。内核大小设置为3,用256 个隐藏节点的FC 层连接卷积层和输出节点,Ladv的权值λadv为0.5。本文采用平均绝对误差(EMA)和信号累积误差(ESA)作为每个设备的评价指标[2]。具体来说,给定1 个T个时间步长的预测输出序列,,其中,N为长度为M的不相交时间段的个数;T=NxM;τ为第r个时间段的预测总功耗;rτ为对应的真值。本文设置N=1 200,对于REDD 数据集,每个时间段大约对应1 h,对于UKDALE 数据集,每个时间段大约对应2 h。
2.2 实验结果及分析
2.2.1 实验结果对比
表1 和表2 分别为REDD 和UK-DALE 数据集的评估指标比较表。每个值均为3 次试验结果的平均值。从表1 和表2 中可知,所提模型在所有设备上,尤其是REDD 上的EMA和ESA都低于SGN数据集,平均EMA和ESA提升了22.39%和28.60%。UKDALE 数据集的平均提升也超过了10%。

表1 REDD数据集的评价指标表Table 1 Evaluation index table of REDD dataset W
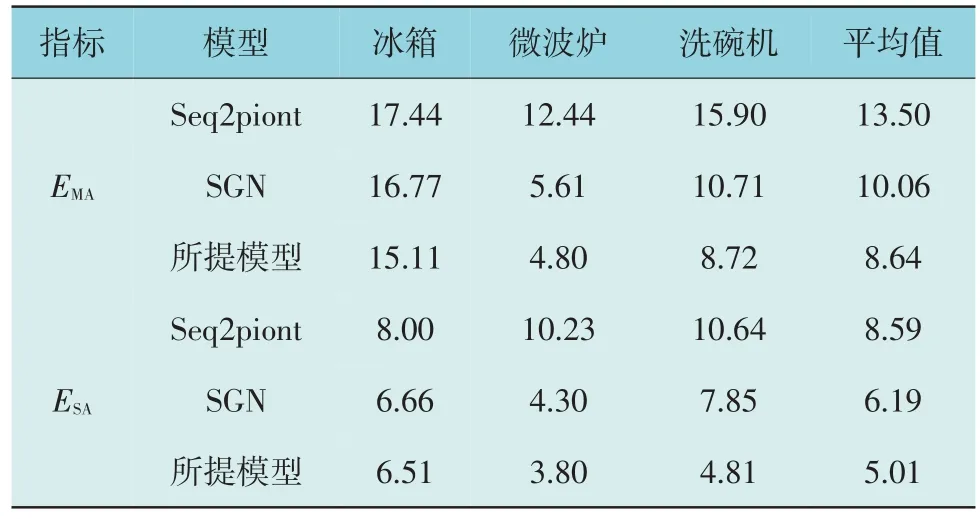
表2 UKDALE数据集的评价指标表Table 2 Evaluation index table of UKDALE dataset W
图2 为针对微波炉的SGN 和所提模型的分解结果图。其中,数据时间跨度大约为100 h。
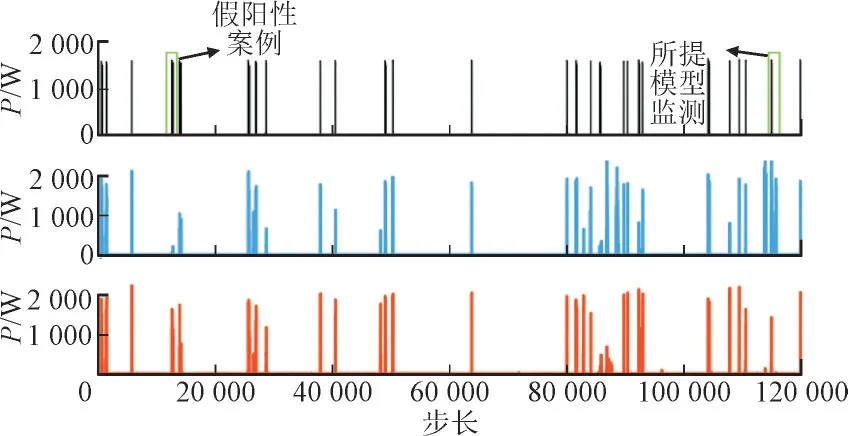
图2 REDD数据集下SGN和所提模型对微波炉的比较图Fig.2 Decomposition result of SGN and proposed model for microwave oven under REDD dataset
由图2 可知,本文所提模型在功耗水平上更准确,且误差较小。
图3 和图4 为本文所提方法与SGN 下样本分解结果比较。其中横坐标为采样周期,用步长表示,每步长时间3 s。下同。由图3 和图4 可知,所提模型比SGN 解聚结果更为精确,这是因为通态增强有助于模型捕获冰箱的通态功耗。

图3 REDD数据集样本解聚结果Fig.3 Samples disaggregation results of REDD dataset
2.2.2 特征可视化图分析
图4(b)中2 个子网络分支末端的激活如图5所示。其中,右侧渐变图例表示激活度,负值表示抑制。无量纲。下同。

图4 UKDALE数据集样本解聚结果Fig.4 Samples disaggregation results of UKDALE dataset
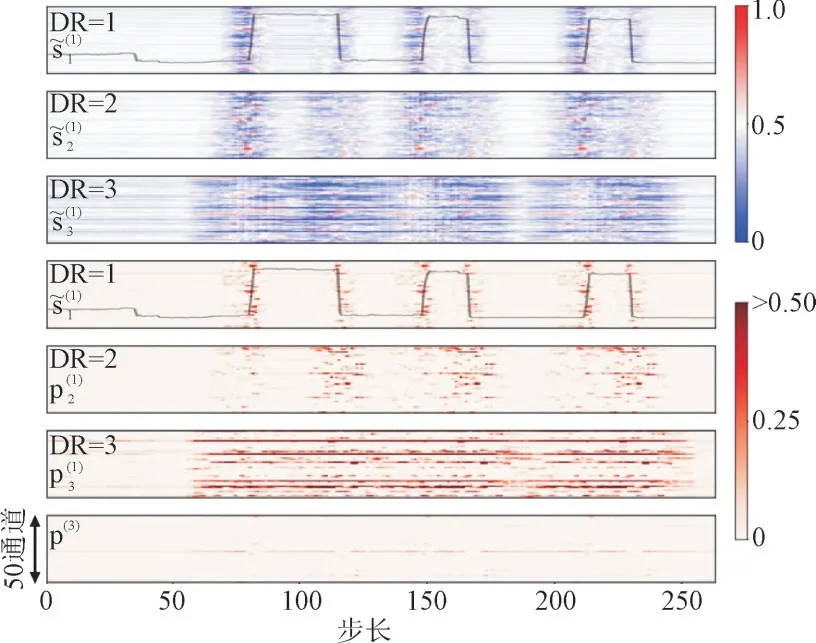
图5 REDD数据集下微波炉多尺度特征的可视化图Fig.5 Visualization of multiple scales feature maps for microwave oven under REDD dataset
图5 中绘制了可视化样本中256 个时间步长。每个特征图包含256 个时间步长和50 个通道。很明显,这些分支都可对微波炉负载信号中的上升边和下降边做出响应,其中很大一部分是选通信号抑制了回归子网络的选通信号激活。因此,特征图p(3)的激活程度一般要低得多。另外,本文还用图4(b)的案例来说明自我关注模块的作用机制。
图6 为图4(b)案例下将分类子网络中的关注矩阵的可视化图。由图6 可知,该模型主要关注一定时间范围内的边,3 条上升边的关注值最高,即当观察其中1 条边为上升边时,模型指是所有上升边。
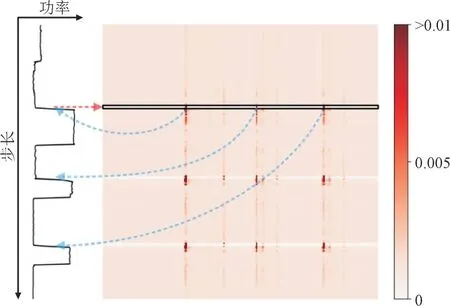
图6 图4(b)的关注矩阵Fig.6 Attention matrix for Fig.4(b)
图7 为图4(b)的情况下,分类子网络的自我关注模块的输入S(3)和输出S(4),以及在所有3 个上升边高度激活的附加特征图rs。
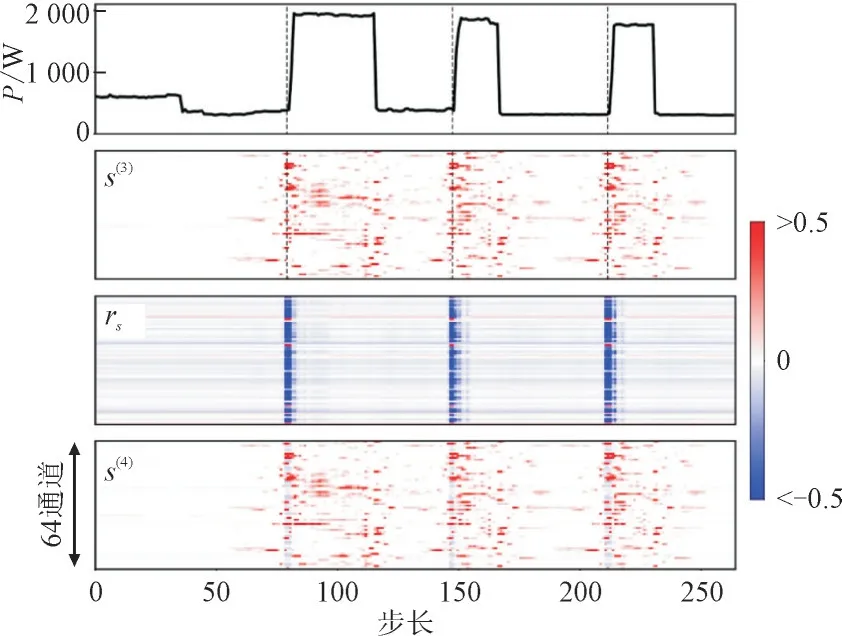
图7 REDD数据集微波炉开关状态分类子网络可视特征图Fig.7 Visual feature maps in on/off state classification subnetwork for microwave oven under REDD dataset
3 结语
针对大规模负载能耗的复杂特性,为实现精确的NILM,本文提出了一种基于可缩放感知卷积神经网络的非侵入式负载监测方法。实验结果表明,所提方法能较好地降低设备功耗的估计误差。此外,验证了通过增加的对抗性损失和通态增强有利于对用能设备的精确监测。与其他NILM 方法比较,本文所提可缩放感知模块有助于提高负载分解精度,从而提高了NILM 的监测精度。为了提升本文所提NILM 技术的适用范围,未来工作的一个重要方向就是将监督学习和非监督学习的优点结合起来,以产生更好的负载分解效果。
猜你喜欢
商丘师范学院学报(2023年9期)2023-09-06 06:03:42
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
力学学报(2021年10期)2021-12-02 02:32:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
能源工程(2021年1期)2021-04-13 02:06:12
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
水利技术监督(2016年6期)2017-01-15 14:01:30
河北科技大学学报(2015年5期)2015-03-11 16:16:37
电测与仪表(2014年2期)2014-04-04 09:04:00
