
基于Two-Stage的目标检测算法综述
2022-05-18 06:35王彦雅
河北省科学院学报 2022年2期
王彦雅
(河北经贸大学信息技术学院,河北 石家庄 050061)
0 引言
计算机视觉[1](Computer Vision)领域包括目标检测、图像分割、图像增强、图像检索和图像分类等方向。近年来,目标检测领域运用了大量的深度学习算法,在众多优秀算法的加持下,许多检测模型的性能和效率有了较大的提升。
目标检测[2](Object Detection)在计算机视觉领域的地位尤其重要,其首要任务是表示出图像中的目标(如:猫、狗和人等),其次是检测出目标物体的种类。目标检测技术在日常生活中的应用十分广泛,如:人脸识别、行人识别、车牌识别和自动驾驶等。可见,目标检测技术性能的提升对人们生活有着重要意义。
传统的目标检测算法使用的是手工特征加分类器的组合模式,为目标检测领域的研究开辟了道路,如:Haar[3]与Adaboost[4]的组合、Hog[5]与SVM的组合以及经典算法DPM[6]等。但由于手工特征提取的效果一般,使得传统算法检测的效果并不尽如人意。
2014年,R-CNN搭载着Region Proposal(候选框)+卷积神经网络+SVM(支持向量机)的组合模式出现在大众的视野中,这种Two-Stage目标检测模型以其优秀的准确率为目标检测的研究提供了一个新的思路。Two-Stage(两阶段)目标检测是将检测流程分为两部分,首先要生成候选区域,再判断候选区域中是否存在需要检测的物体,以及该物体的类别。目前最为流行的Two-Stage算法是R-CNN系列,其中包括R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN等,本文就以上具有代表性的算法进行详细综述。
1 R-CNN
R-CNN[7](Region-CNN)是由Facebook人工智能科学家Ross Girshick在2014年提出。该算法使用CNN进行特征提取,较传统目标检测算法准确率提升了近20%,成功的将卷积神经网络引入了目标检测领域,并为目标检测领域开辟了一条新的道路。
1.1 R-CNN算法流程
(1)生成候选区域
R-CNN使用图像分割算法Selective Search生成2000个Region Proposals。Selective Search的算法原理是将图像打碎,生成尽可能多的子区域,再以颜色和纹理等判断标准,对大量的相似区域进行融合,并重复上述过程,最后成功提取候选区域。
(2)候选区域变形
候选区域的大小并不固定,为了符合特征提取对输入图像尺寸的要求,需将所有的候选区域进行变形与缩放。
图像尺寸的缩放包括各向同性缩放和各向异性缩放。其中,各向异性缩放是指将图片暴力拉伸为所需要的大小,这会导致图像失真比较严重,间接影响特征提取的效果。而R-CNN的方法是各向同性缩放,其特点是将候选区域边界相邻的图像进行一定的补充,再进行裁剪,若扩充后超出了图像边界,会用图像均值进行补充,这样会减少一定的图像失真,使得特征提取效果更优。
(3)特征提取
R-CNN作者选用卷积神经网络进行特征提取,网络的Backbone是基于AlexNet[8]的网络结构,由五个卷积层、三个池化层和两个全连接层组成。AlexNet的网络结构如图1所示。
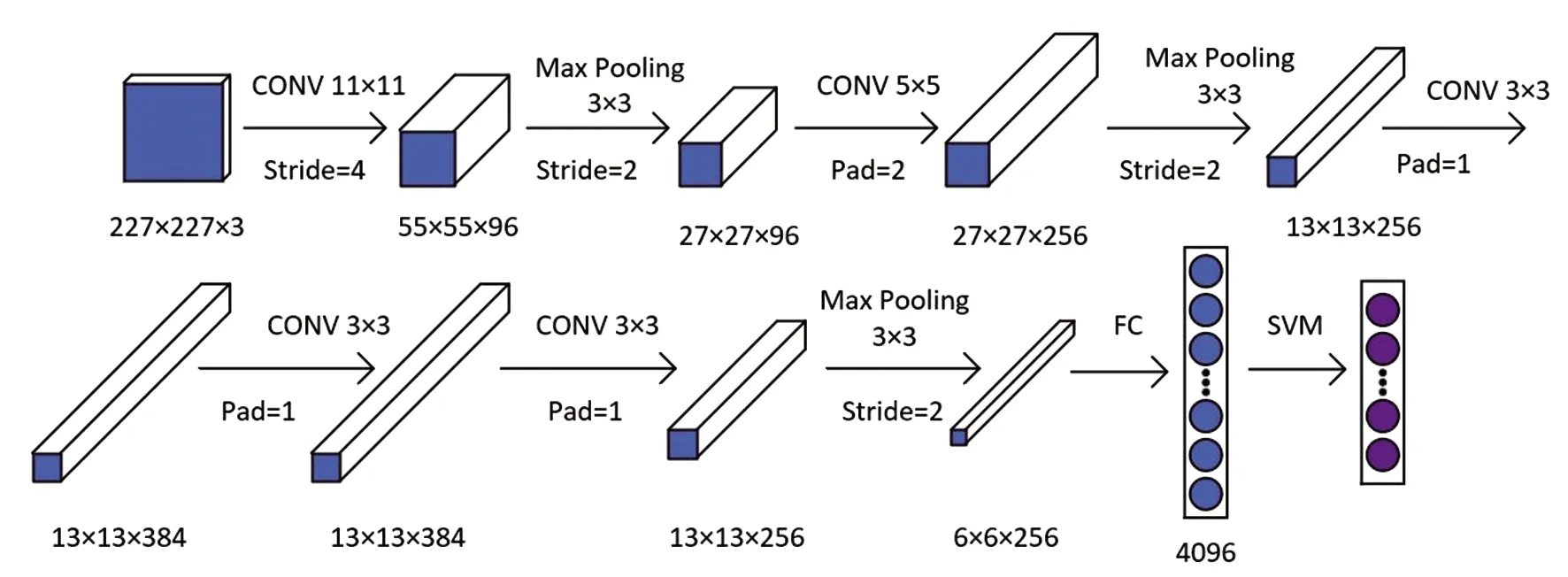
图1 AlexNet网络结构
AlexNet网络对图像的固定输入尺寸为227×227,输出4096维的特征向量,与Selective Search算法生成的2000个候选框组成了2000×4096维的矩阵。
(4)SVM分类器
SVM[9](Support Vector Machines)是一种二分类模型。其基本原理是找出一条线,可以最好地分割开一组数据,即使得两组数据距该条线几何间隔最大。由于SVM是二分类,只能判断特征向量是否属于某一种类别,故作者使用了20个SVM分类器对20类物体进行检测。
如图2所示,AlexNet输出的4096维特征向量输入到20个SVM分类器中,会得到4096×20维的矩阵,完成2000个候选框的输入之后得到一个2000×20维的得分矩阵,其中2000行分别表示2000个候选框,20列对应20个类别,其中的数字表示每个候选框对应每一类的得分,最后认为该候选框属于得分最高的一类。
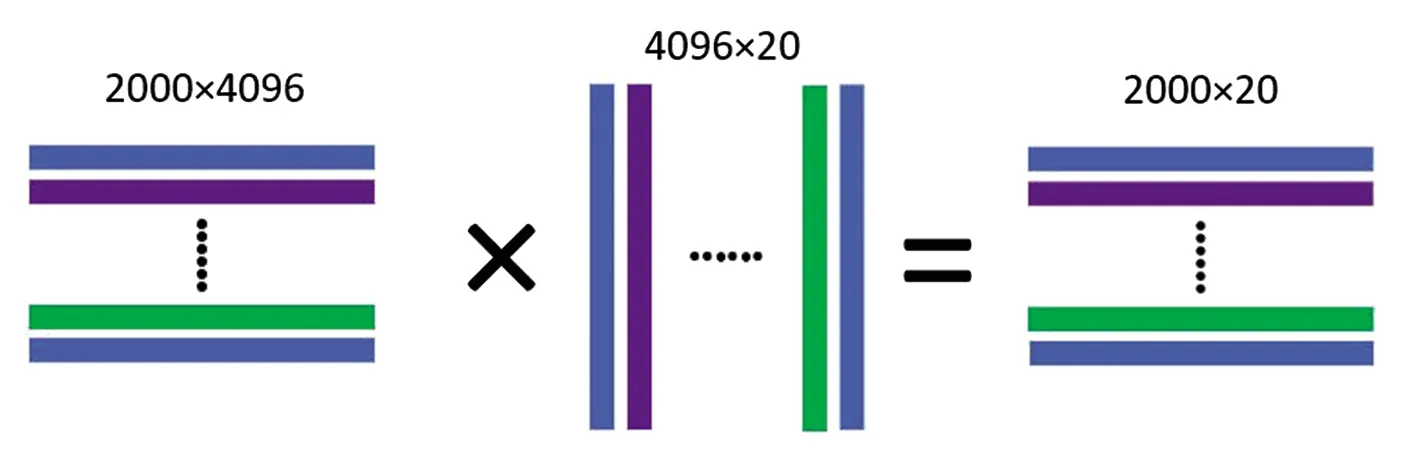
图2 特征向量的计算
(5)IOU(交并比)和 NMS(非极大值抑制)
目标检测需要检测出物体所在图像的具体位置,这就需要一个指标来评价定位的精度。IOU(交并比)就是专门评价目标检测精度的指标,用两个候选框的交集面积比上并集面积,得到的值称为交并比。交并比的范围区间为[0,1]。交并比等于1时,候选框与真实框完全重合。如图3所示。
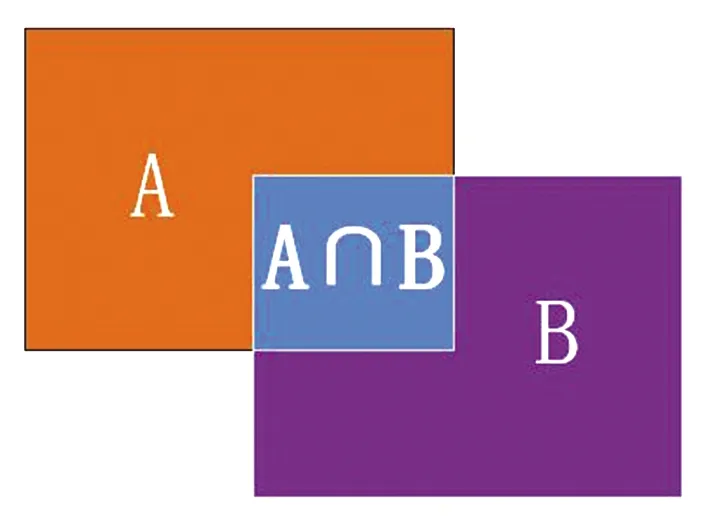
图3 IOU交并比
(1)
Selective Search[10]算法所产生的2000个候选区域会存在大量的交叉重叠,有时一个物体会被几个或者几十个候选框所覆盖,这就需要去除一些重叠的候选框。R-CNN采用的NMS[11](非极大值抑制)方法能够解决这个问题。NMS的思想是从IOU(交并比)大于一定阈值的候选框中选择得分最高的确定为最终的候选框,并将其它的候选框删除。例如图4中将阈值设定为0.5,左侧汽车的两个候选框重叠部分大于50%,右侧汽车的三个候选框重叠部分同样大于50%,那么将会删除左边得分为0.76和右边得分为0.62、0.75的候选框,保留得分最高的两个候选框。

图4 NMS确定候选框
(6)边框回归器
经过以上步骤生成的候选框不一定是标准的,所以R-CNN最后采用了边框回归的方法对预测候选框进行了修正,使预测候选框更加接近真实候选框。这种回归算法的思想是将预测候选框向真实候选框的方向进行缩放和偏移,使预测候选框识别的效果更加准确。
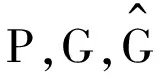
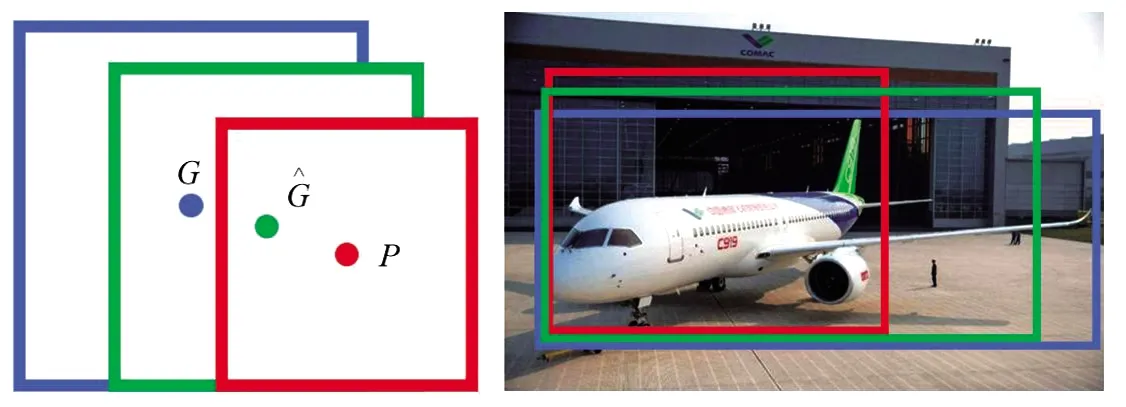
图5 边框回归
一般采用四维向量(x,y,w,h)表示候选框的位置,(x,y)表示候选框中心点横纵坐标,(w,h)表示候选框宽度和高度,这样一个四维向量就可以表示出图像中的一个候选区域。
计算流程:
令P={Px,Py,Pw,Ph}表示未进行边框回归修正的预测候选框。
令G={Gx,Gy,Gw,Gh}表示人工标注的真实候选框。
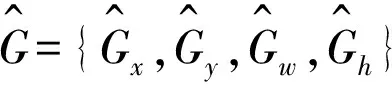
修正后的候选框中心点横纵坐标、宽和高表示为:
(2)
R-CNN原文将Δ表示为:
Δx=Pwdx(P)
Δy=Phdy(P)
Δw=edw(p)
Δh=edh(p)
(3)
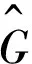
(4)
真实候选框表示为t*={tx,ty,tw,th}:
tx=(Gx-Px)/Pw
ty=(Gy-Py)/Ph
tw=log(Gw/Pw)
th=log(Gh/Ph)
(5)
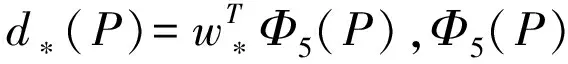
(6)
需要优化的目标:
(7)
w*可以用梯度下降法或最小二乘法得到。
2 SPP-Net
SPP-Net[12](Spatial Pyramid Pooling Network)由何恺明在2015年提出,并在ImageNet比赛中获得了目标检测组第二名和物体分类第三名的成绩。
SPP-Net只对原图做一次卷积,大大提升了检测速度,并可以输入任意尺寸的图片,输出固定维度的特征向量。
2.1 Feature Map映射
SPP-Net作者使用一种新思路,将整幅图片输入到神经网络进行特征提取,将候选框所在区域直接映射到对应的特征图中,从而避免了所有的候选区域都进行一次特征提取的过程,使得检测效率大幅提升。
2.2 空间金字塔池化
R-CNN中要对输入CNN中图像的尺寸进行统一,使得图像会有不同程度的失真,导致特征提取效果不佳。
其实,卷积和池化可以适应任意大小尺寸的图像。图像尺寸的统一是为了使卷积层输出固定维度的特征向量,原因是全连接层需要固定维度的特征向量作为输入才可以进行分类操作。
SPP-Net使用了空间金字塔池化[13]的方法有效解决了输入图像尺寸需要统一的问题,并且可以完美适应任意大小的特征图输出相同维度的特征向量。
空间金字塔池化层代替了原网络的最后一个池化层Pool5,相当于在卷积层与全连接层之间加入了一个SPP层。如图6所示,SPP层会生成4×4、2×2和1×1三种不同大小的网格,每个尺寸的网格分别对特征图进行一次最大池化操作。三种不同尺寸的网格共有21个不同大小的块,每个块进行一次最大池化,就会得到21维的特征向量,这样就可以使不同大小的特征图输出固定维度的特征向量。
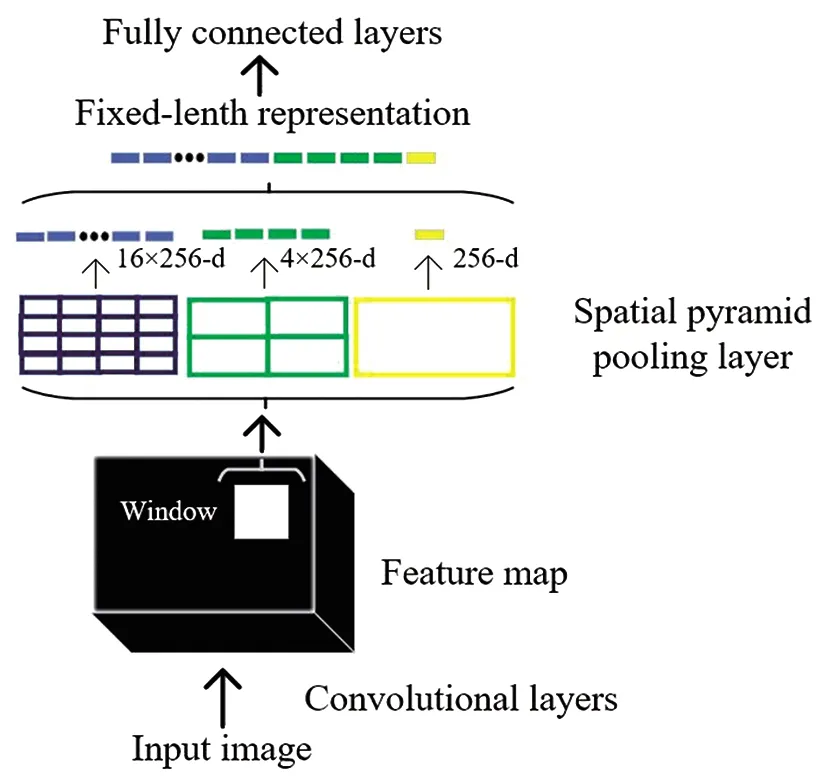
图6 空间金字塔池化
3 Fast R-CNN
Fast R-CNN[14]是R-CNN的改进版本,由Ross Girshick发现R-CNN存在的问题后,2015年提出了Fast R-CNN算法。Fast R-CNN只对原图进行一次卷积,对64个候选区域的特征进行预测,并加入了RoI Pooling层,不再限制输入图像的尺寸,特征提取、物体分类和边框回归三个部分融合到了CNN网络中,使Fast R-CNN基本实现了端到端的检测。
3.1 正负样本采样
Fast R-CNN对Selective Search算法生成的2000个候选区域进行正负样本采样,将IOU大于等于0.5的候选框定义为正样本,IOU在0.1-0.5之间的样本定义为负样本。为了保证正负样本数量的平衡,在2000个候选框中随机使用64个候选框进行RoI Pooling,其中的正负样本数量基本相同。
3.2 RoI Pooling Layer
如图7所示,由于候选区域对应的特征图尺寸不同,为了输出固定维度的特征向量,RoI Pooling做了如下操作:
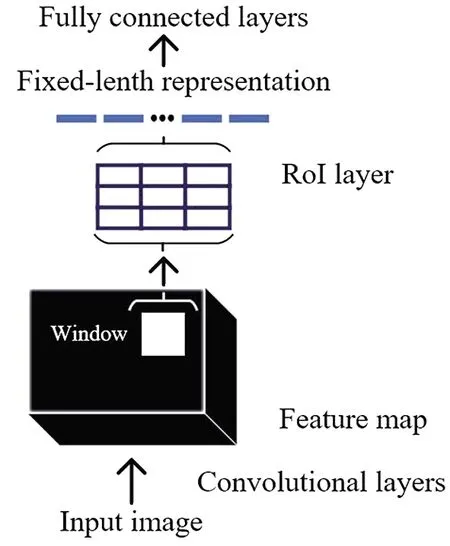
图7 RoI池化层
(1)根据输入的图片和候选框所包含的区域,RoI Pooling层直接找到每个区域所对应的特征矩阵的位置。
(2)将映射的特征区域使用m×n大小的网格进行划分,网格的大小可以手动设置。
(3)对每个小网格中的特征矩阵进行最大池化,得到固定大小的特征矩阵。由于特征矩阵大小可能为奇数,所以可能导致网格对特征矩阵的划分并不平均。
以上操作就可以将不同大小的特征图输出为固定维度的特征矩阵。
与SPP-Net不同的是,RoI只使用一种尺寸的网格对特征矩阵进行划分,速度要比SPP-Net快很多。
3.3 分类器与回归器的整合
在RoI Pooling层输出特征向量后,并联了两个全连接层,一个是使用Softmax进行物体的概率预测,另一个是使用回归器进行边框回归参数的预测。
Fast R-CNN解决了各部分单独训练的问题,将特征提取、分类器分类和边框回归整合到CNN模型中,一次训练就可以完成,基本实现了端到端的检测。
4 Faster R-CNN
Faster R-CNN[16]是SPP-Net的作者何恺明在2017年基于Fast R-CNN提出的一种改进模型。Fast R-CNN使用Selective Search算法生成候选框,这种方法效率比较低,会导致模型的整体检测速度较慢,在包括候选区域生成的基础上检测一张图片需要两秒多的时间。Faster R-CNN使用了RPN(Region Proposal Network)[17]网络生成候选区域的方法,使检测速度达到了5FPS(每秒检测五张图片),近乎达到了实时的效果。
4.1 RPN生成候选区域
Faster R-CNN原文使用的Backbone是ZF结构和VGG16结构。将原图送入特征提取网络,输出的特征图为后续流程的共享特征图,如图8所示。
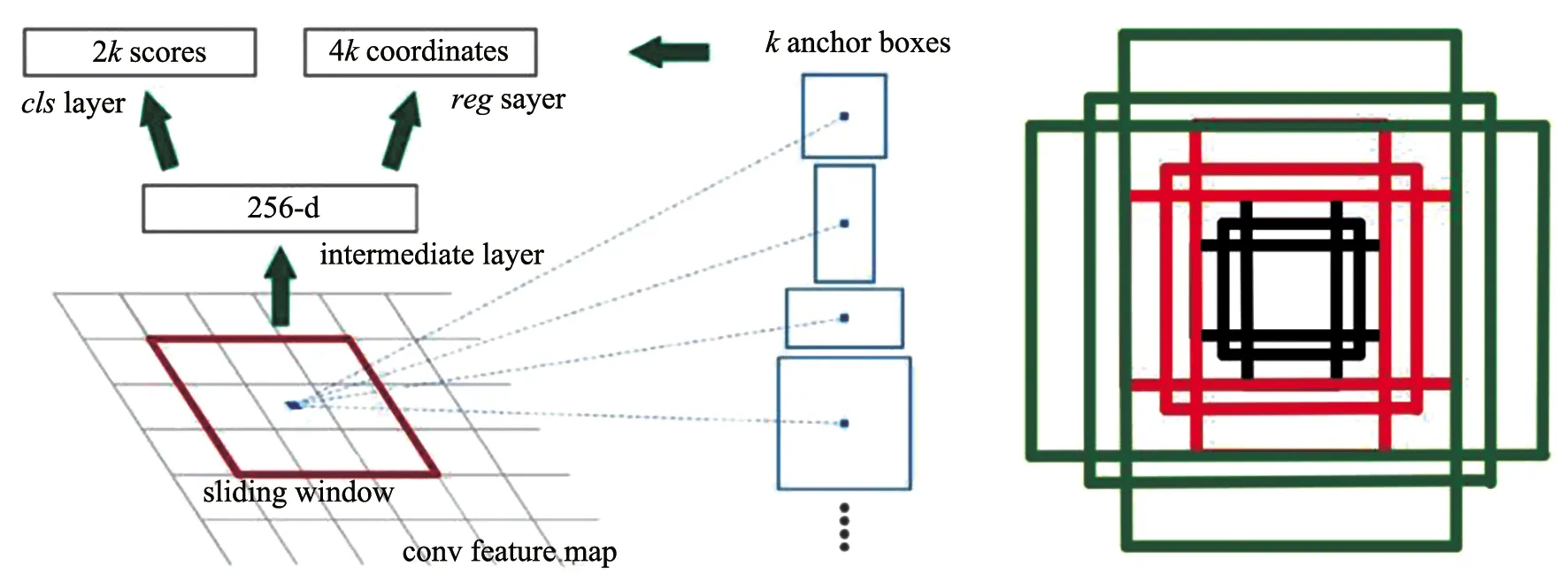
图8 RPN网络
如图8左图,在特征图中会生成一个3×3的滑动窗口遍历整幅特征图,滑动窗口每经过一个位置产生9个Anchor boxes矩形框,如图8右图。这9个Anchor boxes分为三组,每组的面积分别为1282,2562,5122,且比例为1∶1、1∶2和2∶1。滑动窗口经过每个位置的同时会生成对应区域的特征向量,该特征向量会被一个分类器和一个回归器进行目标概率的预测以及边框回归参数的预测。分类器会对每个Anchor boxes进行前景概率和背景概率的预测,k个Anchor boxes会输出2k个预测得分。回归器会对每个Anchor boxes进行边框回归预测,k个Anchor boxes会输出4k个预测参数。
一张图片可能会生成上万个Anchor boxes,数量较多且存在大量冗余,Faster R-CNN将会去除超出边界的Anchor,并采用非极大值抑制方法保留IOU大于等于0.7的Anchor,最终会产生2000左右的候选框。
至此,RPN生成候选区域的任务完成,成功取代了Selective Search生成候选区域的方法,后续步骤与Fast R-CNN相同。
5 Faster R-CNN算法改进
Faster R-CNN检测精度高且速度快的特点使其被快速应用于各个领域,但模型检测不同物体时的准确率并不统一。为了解决这一问题,使其在目标领域有更好的性能,各路学者纷纷对其进行了改进。
2019年,杨薇[18]等人使用K-means算法对Faster R-CNN进行改进,对车辆进行检测,准确率由75.8%提升至82.2%,并且检测时间由0.039s降低至0.038s。
2020年,徐义鎏[19]等人提出了改进fater区域卷积神经网络,对木材运输车进行识别,检测精度较原始Faster R-CNN提升了7.5%,模型平均精度提升了4.3%。
2021年,李祥兵[20]等人使用ResNet-50为Faster R-CNN的网络主干,并对特征图进行多尺度融合,在Wider Face数据集中准确率由85.5%提升至89%,在FDDB数据集中准确率高达95.6%。
2021年,林娜[21]等人在Faster R-CNN中引入空洞残差块进行多特征融合,对飞机进行检测,在UCAS-AOD数据集中准确率达到97.1%,在NWPU VHR-10数据集中准确率达96.2%。
2021年,吕本远[22]等人在Faster R-CNN中加入自适应候选区域数目调节层,使模型检测速度提升25%,准确率提升1.1%。
6 总结与展望
本文就当前流行的Two-stage目标检测算法进行了综述,详细分析了算法的具体流程及优缺点,对目标检测领域的研究学者们提供一定的帮助,以及对算法的改进方向提供了思路。最后汇总了近年来各学者对Faster R-CNN的改进成果。
目前,Two-stage算法较One-stage算法精度更高,但速度偏慢,不能很好地实现实时检测,也很难应用于视频检测。如何使Two-stage算法在保证高准确率的前提下提升检测速度是目前学者们面临的关键问题。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
计算机技术与发展(2020年2期)2020-04-15
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子技术与软件工程(2019年4期)2019-04-26
电子制作(2018年19期)2018-11-14
数学学习与研究(2018年15期)2018-11-12
电子技术与软件工程(2018年24期)2018-05-10
