
图神经网络技术研究综述
2022-05-18 06:35李甜甜张荣梅张佳慧
河北省科学院学报 2022年2期
李甜甜,张荣梅,张佳慧
(河北经贸大学 信息技术学院,河北 石家庄 050061)
0 引言
近年来,深度学习技术在诸多领域,如图像处理,自然语言理解等领域广泛应用,主要用于处理图像、语音、文本等形式的欧几里得数据。但一直以来深度学习技术对于非结构化的图数据难以高效处理。而作为一类主要描述关系的通用数据表示方法,图能够很自然地表示出现实场景中实体与实体之间复杂的关系,在产业界有着更加广阔的应用场景,例如在社交网络、物联网等场景中数据多以图的形式出现。受到深度学习技术的启发,2005年Marco Gori等人首次将深度学习技术与图数据结合,提出了图神经网络(Graph Neural Networks, GNN)的概念,使深度学习能够在图数据的相关场景中得到有效利用。GNN的应用领域十分广泛,包括计算机视觉、化学生物、推荐系统以及自然语言处理等领域。
1 图的定义及表示
1.1 图的基本概念
图定义为G=(V,E),其中V表示节点集合,E表示边集合。VR是两顶点之间关系的集合,若
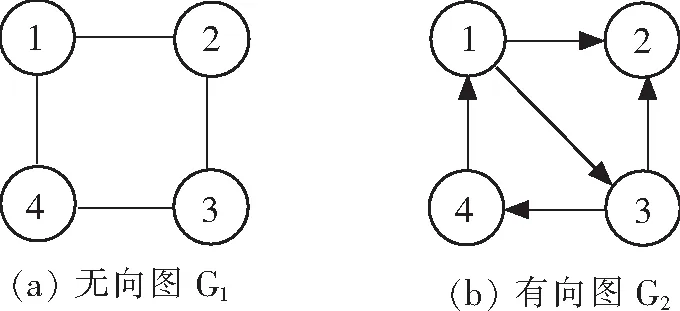
图1 图示例
1.2 图的表示
在图神经网络中,常用邻接矩阵、度矩阵、拉普拉斯矩阵等来表示节点之间的连接关系。
(1)邻接矩阵A:用来表示图中节点之间的关系。若节点vi和vj之间有边相连则ai,j=1,否则为0;
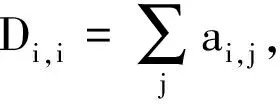
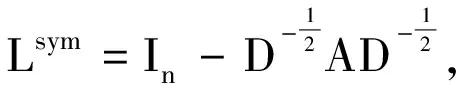
图1的邻接矩阵、度矩阵以及拉普拉斯矩阵如表1所示。
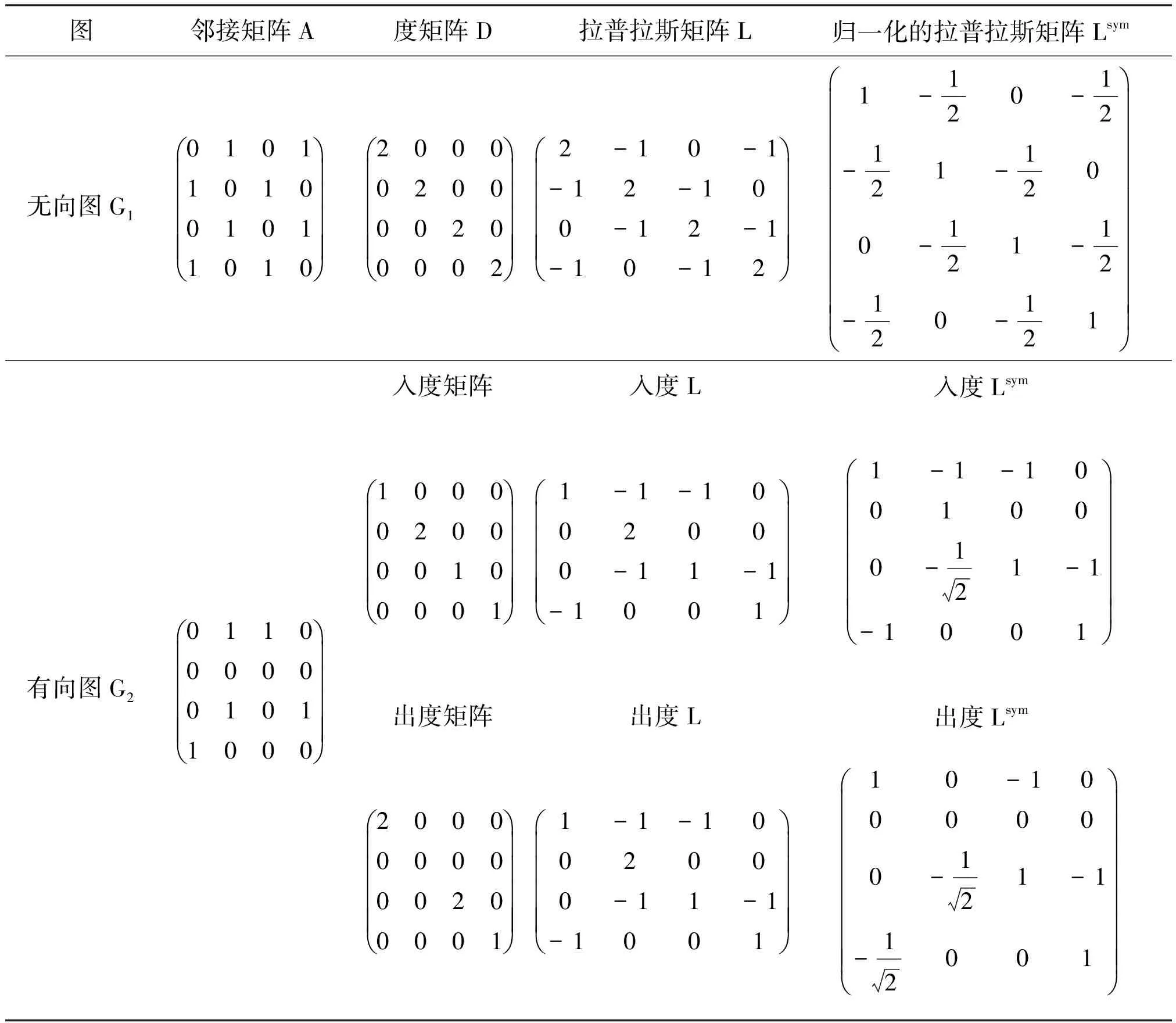
表1 图表示
2 深度学习的相关技术
2.1 卷积
卷积操作是k×k的卷积核以一定的步长在输入特征图上遍历移动;每次移动卷积核就会与输入特征图出现重合区域,重合区域对应元素相乘、求和得到输出特征的一个像素点[4]。卷积的定义如(1)式所示:
(1)
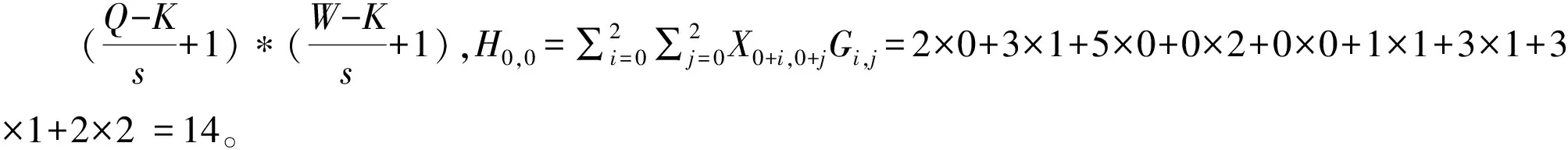
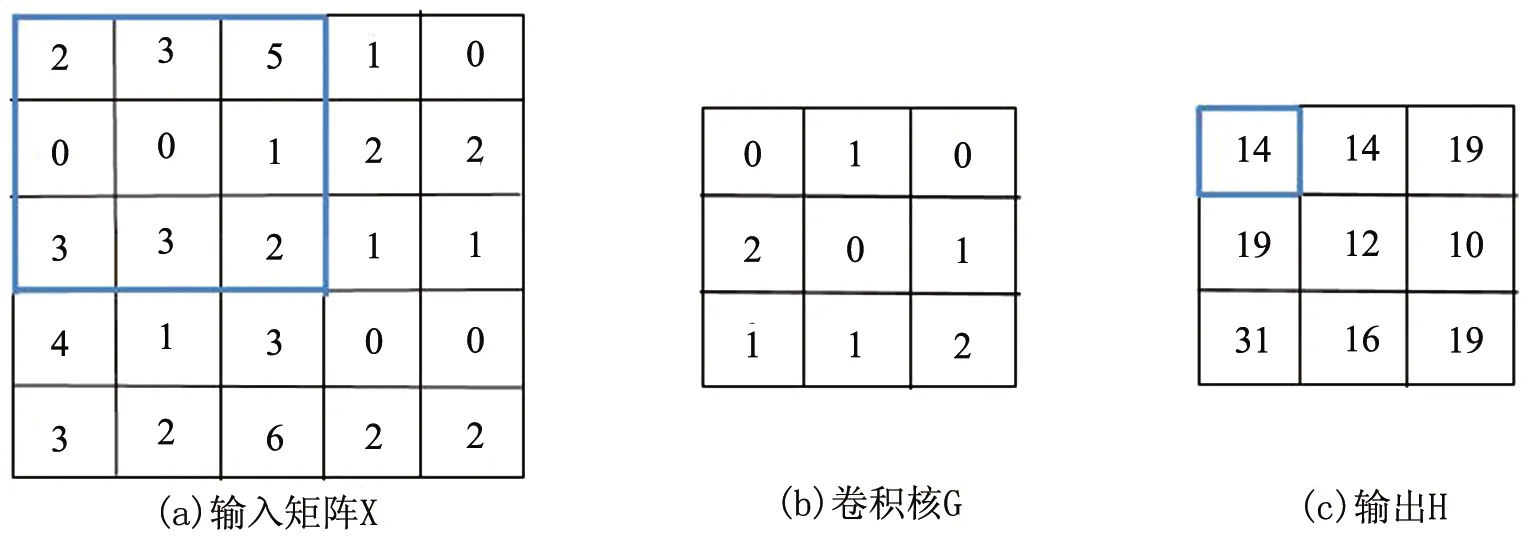
图2 卷积示例
2.2 池化
池化使用n×n的滑窗,在输入特征矩阵上滑动,每次将滑动区域内的元素聚合为一个值作为输出。池化将卷积层得到的特征矩阵作为输入进行降维以实现减小参数量的目标。根据聚合方式的不同,池化分为平均池化和最大池化。每个滑窗平均池化后的输出为输入矩阵滑动区域内元素的平均值。每个滑窗最大池化后的输出为输入矩阵滑动区域内元素的最大值。如图3所示利用步长为2,2*2的滑窗在4*4的输入矩阵上最大池化以及平均池化所得结果。
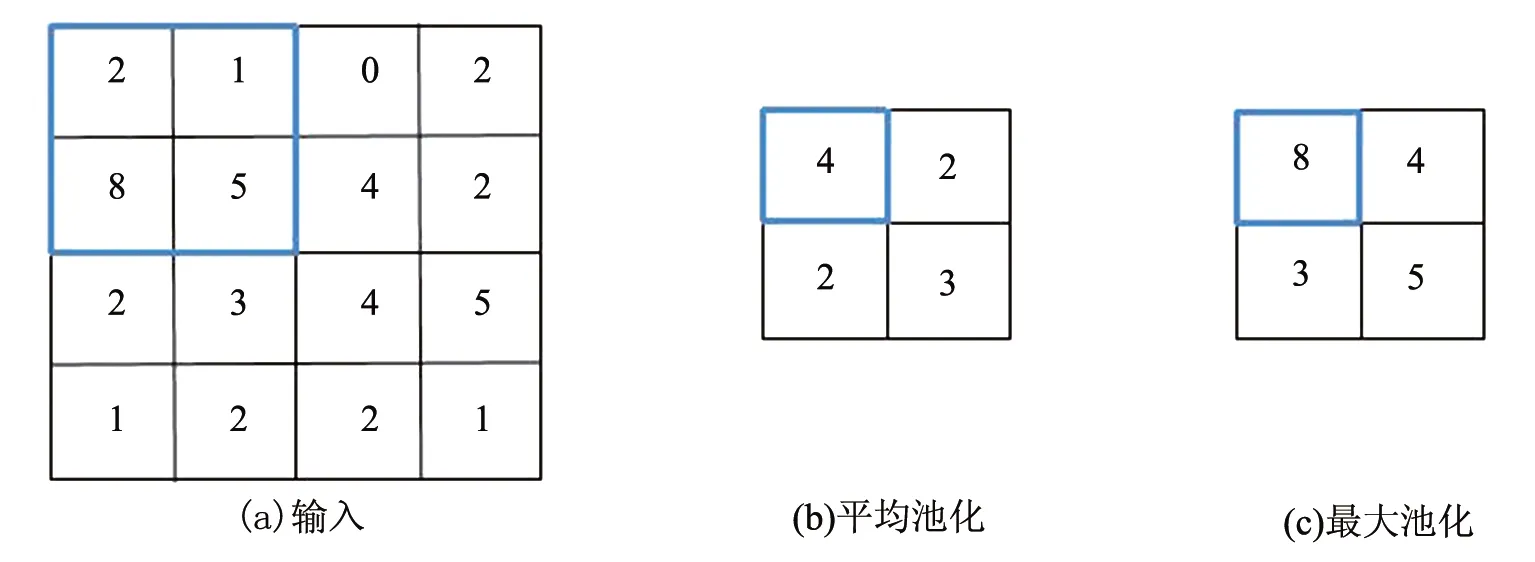
图3 池化示意图
2.3 自编码器
自编码器由编码器与解码器构成,是一种可进行数据降维及特征提取的无监督学习方法;自编码器模型如图4所示,分为输入层、隐藏层及输出层。其中,Encoder通过编码函数h=f(x)将输入的x编码得到中间表示h;Decoder通过解码函数r=g(h)重构中间表示h;自编码器对于输入进行重构的目的在于能够让隐藏表示h获得数据更显著的特征[5]。
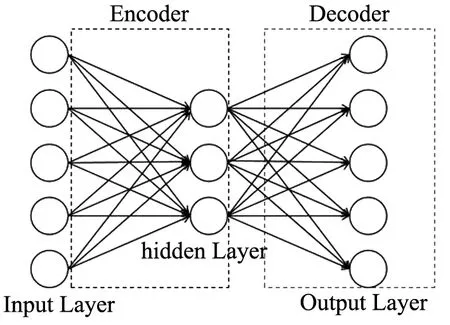
图4 自编码器模型
2.4 注意力机制
注意力机制是一种模拟人脑注意力机制的模型,其从大量的输入信息中选择对当前任务更为关键的信息,提高任务执行的效率及准确性[6]。以机器翻译为例,将输入序列X(x1,x2,…,xm)利用Encoder-Decoder框架得到目标序列Y(y1,y2,…,yn)。Encoder对输入序列编码后得到隐藏表示C=F(x1,x2,…,xm),Decoder利用隐藏表示C及已得到的y1,y2,…,yi-1解码得到i时刻单词yi=g(C,y1,y2,…,yi-1)。在未加入注意力机制之前,Encoder-Decoder只能经由定长的隐藏表示C实现数据的传输,若输入句子较长,会导致信息丢失,翻译错误率提高。引入注意力机制后,编码器将所有输出发送给解码器,解码器的记忆单元会计算这些输出的加权求和,从而确定在该步长中将重点放在哪一单词上,从而更好地提升翻译效果[7]。注意力机制原理如图5所示。
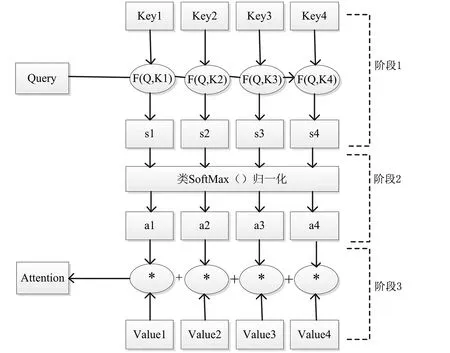
图5 注意力机制原理图
其中,Key为关键字;Value为关键字权重;Query为给定目标序列的一个查询;F表示相似度函数。si=F(Q,Ki)表示Keyi与Query间的相似度;ai表示注意力系数;Attention表示输出的注意力数值。计算Attention的阶段如下:
(1)利用F(Q,Ki)计算Query与Keyi间的相似度si。
(2)使用softmax函数对si进行归一化,得到注意力权重系数ai如式(2)所示:
(2)
(3)对ai与Valuei的乘积进行加权求和即可得到Attention数值,如式(3)所示:
(3)
Lx代表输入序列的长度。
3 图神经网络模型原理及应用
常见的GNN模型有:图卷积神经网络、图注意力网络、GraphSAGE以及门控图神经网络。
3.1 图神经网络
图神经网络通过嵌入传播迭代地聚合目标节点邻域的信息,通过堆叠多个传播层获得高阶邻域信息,更新目标节点表示[8]。以单层嵌入传播为例,目标节点v计算聚合后的节点表示如式(4)所示:
(4)
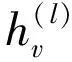
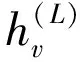
(5)
3.2 图卷积神经网络(Graph Convolutional Network)
3.2.1 GCN模型原理
GCN对图的拓扑结构和节点特征信息进行学习,将原始图数据结构G=(V,E)映射到一个新的特征空间中fG→f*,以单层向前传播图卷积神经网络为例,对于图上的每个节点vi在计算节点表示时,每一层神经网络的输出H(l+1)都可以用一个非线性函数表示,如公式(6)所示:
(6)

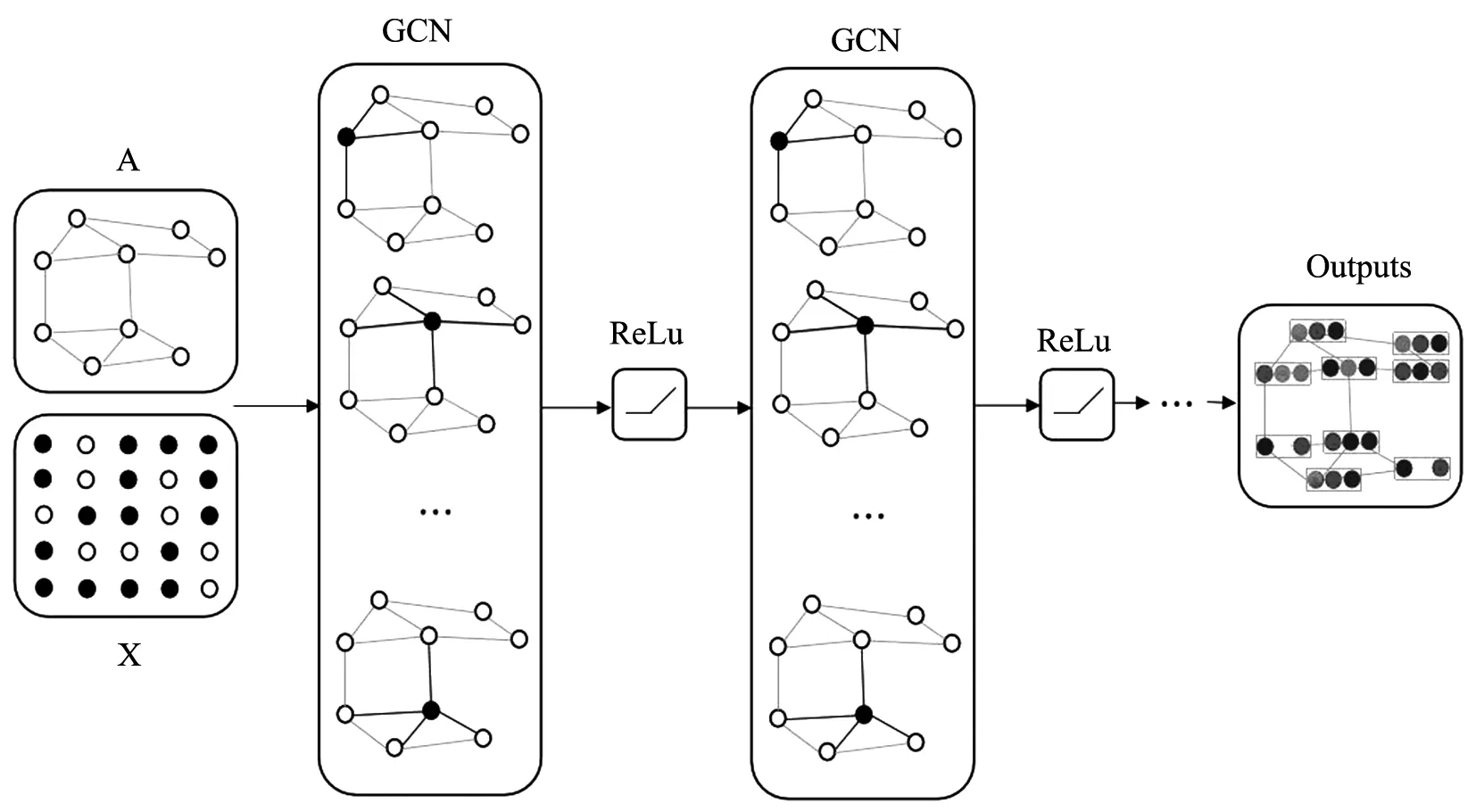
图6 GCN模型
3.2.2 GCN模型应用
GCN模型应用领域有:计算机视觉、生物化学、推荐系统以及自然语言处理等。常见的数据集包括:Cora、Citeseer、shapeNet、ModelNet40、ZINC等。在计算机视觉领域,Wu等人[10]提出一种基于图卷积网络的视频人物社交关系图生成模型HC-GCN,该模型首先将短期的多模态线索如视频、音频及文本等通过图卷积技术为人物生成帧级子图,再沿时间轨迹聚合所有的帧级子图形成一个全局的社交关系图。Wang等人[11]提出了神经网络模块EdgeConv,在点云数据上使用GCN,在保证置换不变性的同时能够获取足够的局部邻域信息,经过实验证明,该模型在形状分类和局部分割任务上有不错的效果。在生物化学领域,Duvenaud等人[12]提出了一种用于学习分子指纹的GCN模型,该模型将大小和形状任意的分子图作为输入,通过图卷积学习原子的特征并将其组合为分子指纹,该模型可解释性强且预测性能良好。You等人[13]提出了结合强化学习、对抗性训练的图卷积策略网络GCPN,首先利用GCN获得生成图状态的嵌入,将对抗性损失作为奖励,最后利用强化学习技术训练目标有向图。该模型通过策略梯度来优化特定领域的奖励和对抗性损失,并在一个包含特定领域规则的环境中运行,实验结果表明,GCPN在化学性能优化方面比基线方法提高了61%。在推荐系统中,Wang等人[14]提出一种基于图卷积网络的NGCF模型,利用用户-项目图结构,通过传播嵌入显式建模用户-项目之间的高阶连通性,有效地将用户和项目嵌入相互交互的协同信号注入到嵌入过程中,以学习更好的用户和项目表示。He等人[15]提出了LightGCN模型,该模型实现了将用户嵌入和项目嵌入在用户-项目交互图上线性传播达到学习用户以及项目嵌入的目的,并将在所有层上学习的嵌入的加权和作为最终嵌入。在自然语言处理领域,Yao等人[16]提出将单词和文档作为节点来构建语料库,并用TextGCN学习单词和文档的嵌入。该模型可以很好地捕获单词和文档之间的关系,具有很好的文本分类效果。
3.3 图注意力网络(Graph Attention Network)
3.3.1 GAT模型原理
GAT是图卷积与注意力机制相结合的网络模型,在传播过程中不再使用拉普拉斯矩阵更新节点状态,而是在每个节点更新状态时引入注意力机制计算其邻居节点的重要程度,为每个相邻节点分配不同的权重,关注作用较大的节点,提高模型计算的效率[17]。
(7)
eij为节点i的邻接点j的重要程度,eij的数值越大,邻接点j对于节点i来说越重要。eij通过softmax函数进行归一化操作,使节点间的注意力系数容易比较,如式(8)所示:
(8)

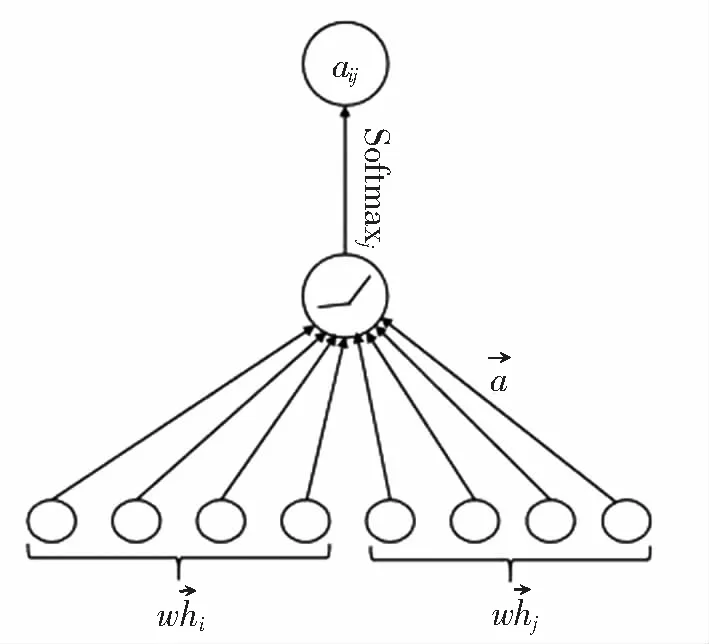
图7 GAT模型注意力机制
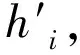
(9)
3.3.2GAT模型应用
GAT常应用领域为推荐系统、生物化学、文本分类及计算机视觉等。常用的数据集有:Decagon、VQA、MR、Amozon-book等。在推荐系统领域,Fan等人[18]提出了GraphRec模型,该模型在社交聚合阶段使用注意力机制,为用户不同的社交好友分配不同权重,选择更有代表性的社交好友对用户信息进行表征,从而提升模型性能。Wang等人[19]提出了一种知识图谱与图注意力网络相结合的KGAT模型,该模型在邻域节点嵌入传播阶段使用注意机制为邻居节点分配不同权重,并利用辅助信息知识图谱设计额外的损失优化推荐性能。在生物化学领域,Andreea等人[20]提出了一种基于图注意力网络的模型,其利用药物的副作用类型和药物的分子结构,在学习每种药物代表时使用共同注意力机制,使不同的早期整合药物对联合信息的重要程度不同,该模型能够实现对药物不良反应较好的预测效果。在文本分类领域,Hu等人[21]提出了一种异质图注意力网络模型HGAT,通过层次注意力机制,使邻域内不同节点的重要程度不同,降低噪声信息,该模型对短文本的分类具有较好的效果。在计算机视觉领域,党等人[22]提出了一种基于图注意卷积神经网络的三维模式识别的方法,在图注意力卷积层使用多个注意力机制聚合邻域的特征,丰富聚合特征信息的多样性。Li等人[23]提出了一种关系感知图注意力网络模型ReGAT,该模型将输入的每个数据建模成图的形式,并通过图注意力机制对多种类型的关系分配不同的权重,找到与目标最相关的关系。Li等人[24]提出了一个基于图注意力网络的模型SIGN,该模型通过图注意力层整合原子之间的距离和角度信息,交替传播节点和边的嵌入,进行三维空间结构建模。
3.4 GraphSAGE
3.4.1 GraphSAGE原理
GCN模型利用图的拓扑结构和节点特征信息学习节点嵌入表示且能够捕捉图的全局信息,但是其要求在固定不变的图上进行学习,不能直接泛化到未知的节点上,当图结构发生变化或者有新节点出现时,GCN模型需重新训练,从而会带来巨大的计算开销,GraphSAGE(Graph Sample and AggreGatE)将GCNs扩展到归纳的无监督学习任务中,能够利用邻域节点的特征信息为未知节点高效地生成节点嵌入[25]。其核心思想是如何学习一个函数从目标节点的局部邻域中聚合这些节点的特征信息。GraphSAGE模型如图8所示。
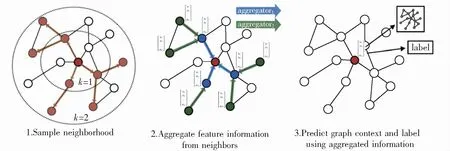
图8 GraphSAGE模型
第一步通过对目标节点的k阶邻域由高到低逐阶随机采样获得目标节点的第k阶特征。设Sk为第k阶需采样邻居节点数目,若目标节点邻居节点的数目小于Sk,则采用有放回抽样;若目标节点邻居节点数目≥Sk,则采用无放回抽样。图8中k=1时Sk=3;k=2时Sk=5。
其次,利用mean/LSTM/pooling聚合器聚合邻居节点的特征信息,并采用拼接操作更新目标节点的节点表示供下游任务使用。聚合操作由下列公式组成:
(10)
(11)

3.4.2 GraphSAGE应用
GraphSAGE模型常应用于推荐系统,图像分类、文本分类及欺诈检测等领域。其常用的数据集有Pinteres、Reddit、Camelyon16。在推荐系统领域,Ying等人[26]提出了基于GraphSAGE的PinSage模型,能够利用随机游走的方式并通过图卷积的方式聚合邻居节点的特征信息,实现更新节点嵌入的同时减小了模型计算成本。该模型在大规模工业推荐任务中具有很好的推荐效果。在图像分类领域,崔等人[27]提出了一种基于细胞图卷积的组织病理图像分类方法,将高分辨率的病理图像建模为图结构,在GraphSAGE模型中加入图池化,使模型能够提取出病理图中更显著的特征。在欺诈检测领域,郭等人[28]提出了一种带权采样GraphSAGE模型,该模型的采样以节点间的相似度为依据。经实验表明,该模型准确率较高并对之前未发现的两个作弊团队进行召回。GraphSAGE在Reddit数据集上有很好的论文预测和文章分类的效果。
3.5 门控图神经网络(Gated Graph Sequence Neural Network)
3.5.1 GGNN模型原理
GGNN在图神经网络更新节点表示的步骤中使用了门控循环单元(gate recurrent unit,GRU)[29],且节点表示的更新次数固定为T,通过门控循环单元控制网络传播中的节点表示更新次数T来迭代循环的实现门控图神经网络。有向图及其邻接矩阵示例如图9所示,图(a)中为一个示例图G=(V,E),其中节点表示v∈V,边表示e∈E;(b)代表(a)的邻接矩阵A,其由输入边和输出边邻接矩阵构成,B,C,B′,C′是边的特征。
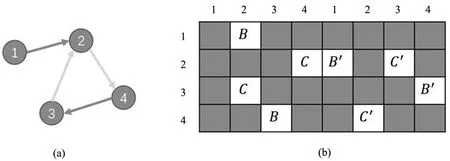
图9 有向图及其邻接矩阵
门控图神经网络的传播过程主要包括公式(12)-公式(17)所示:
(12)
(13)
(14)
(15)
(16)
(17)
(18)
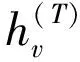
对于整张图的输出如式(19)所示:
(19)
3.5.2GGNN模型的应用
门控图神经网络主要的应用领域为计算机视觉、推荐系统、机器翻译及预测化学反应等。其常用的数据集有COCO、Gowalla、USPTO。在场景图生成领域,Damien等人[31]分别对视觉模态和文本模态进行图构建,再利用GGNN模型训练两种模态的图结构得到最终嵌入,供预测任务中使用,该模型预测效果较好。干等人[32]提出一种模型将门控图卷积用于骨架模态的动作识别中,该模型通过门控时序卷积模块来提取时域顶点之间的多时期依赖关系;通过多维注意力机制来增强图的全局表征。在推荐系统领域,Wu等人[33]提出了一种用于会话推荐的GGNN模型SR-GNN,该模型将输入的数据建模成图的形式,用门控图神经网络学习项目节点的嵌入,该模型相较于其他先进方法有更好的性能。Tao等人[34]利用门控图神经网络在项目趋势表示建模中的作用提高模型的表示能力。在机器翻译领域,Beck等人[35]在语法可感知神经机器翻译任务中使用GGNN,通过将边变成新节点,将句法依存图转换成Levi图,进而将边的标签表示为嵌入,从而更好地学习引入的句法信息。在化学反应预测领域,John等人[36]将化学反应描述为分子中电子的逐步重新分布,提出一种电子路径预测模型。使用四层GGNN表示节点和图嵌入,然后优化分解路径的生成概率,用以预测化学反应产物。
3.6 图神经网络的开放资源
基于上述对四种常用GNN模型应用的介绍总结了常用的GNN数据集以及GNN库。常用的数据集包括Reddit、Gowalla及Movielens-1M。其经常用于推荐任务。按照模型不同,统计了GCN、GAT、GraphSAGE及GGNN四个图神经网络模型主要数据集,如表2所示。
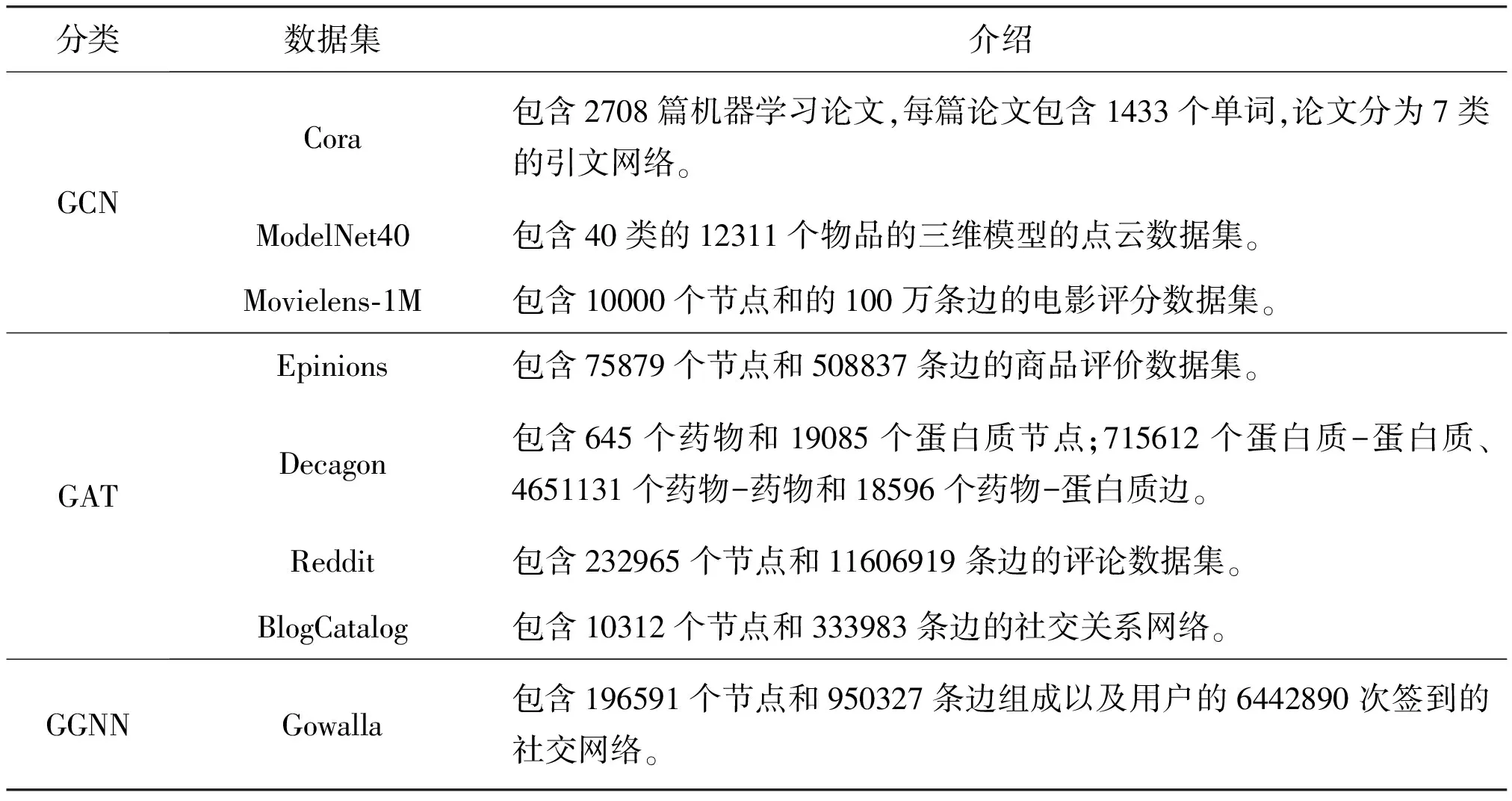
表2 开放数据集
常用的图神经网络库如下:
(1)Deep Graph Library:支持PyTorch、TensorFlow等多种框架的开源GNN库,包含消息传递机制、自动批处理以及用以提升模型速度的灵活调整的稀疏矩阵。
(2)PyTorch Geometric是基于PyTorch框架封装的GNN平台,其包含了图数据的处理、多种常用的GNN模型及数据集等。
(3)TensorFlow Geometric是基于TensorFlow框架的使用消息传递机制实现GNN的库,其内置了多种GNN常用的模型及数据集,利用稀疏矩阵提升框架性能。
(4)AliGraph是阿里集团开发的一个大规模的GNN平台,致力于数据采样建模及训练一体化。由数据层、采样层、算子层及算法层构成,适用于大规模图、多种类型的图。
4 问题与总结
近年来图神经网络已在许多重要领域得到了广泛应用,但是目前图神经网络发展不够完善,仍然存在一些问题有待解决。
(1)深度神经网络通过堆叠不同网络层使网络结构加深,参数增多,以便提升表达能力[37]。但现有的图神经网络结构层次较少,例如GCN在参数较多时会存在过平滑的问题,而限制图神经网络的表达能力,因此如何设计深度的图神经网络是未来的一个重要研究方向。
(2)在社交网络、推荐系统等应用场景,GNN往往需要对大规模的图结构数据进行处理,而现有的许多GNN还不能满足处理大规模图的需求。GCN在使用拉普拉斯矩阵进行图卷积计算时需要很高的时间复杂度及空间复杂度,并且GraphSAGE、GAT等模型在更新节点表达时过分依赖大量的邻域节点,计算代价过大。目前主要通过快速采样、子图训练的方式处理。
猜你喜欢
计算机应用(2022年9期)2022-09-25
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
北京航空航天大学学报(2018年1期)2018-04-20
