
基于异构网络表示学习的相关图书推荐研究
2022-05-15 06:35:48张金柱蒋霖琪
计算机工程与应用 2022年9期
张金柱,蒋霖琪,王 玥,孔 捷,高 扬
1.南京理工大学 经济管理学院,南京210094
2.南京理工大学,南京210094
随着图书资源的不断丰富,读者获取感兴趣图书的难度不断增大,图书推荐技术随之产生。图书推荐技术利用用户信息、图书信息以及用户历史行为信息来预测用户可能感兴趣的图书,主动地进行图书推荐,使得用户可以快速、准确地获得相关图书,节约大量时间[1]。此外,优质的图书推荐方法也能够帮助图书销售平台提升其精准化推荐的能力,从而增强核心竞争能力。
图书推荐主要包括以下三种方法,分别是基于内容的、基于协同过滤的和基于关联规则的图书推荐[1]。基于内容的图书推荐主要根据用户过去借阅或购买的图书,为用户推荐与历史书目相似的图书;基于协同过滤的图书推荐则根据用户偏好或图书相似性进行图书推荐;基于关联规则的图书推荐根据用户购买或者借阅的记录,从中选取频繁共同出现的图书形成图书组合,根据组合向目标用户推荐图书[2]。这三种方法在图书推荐方面取得了较好的效果,但利用的图书特征项还稍显单一,仍需进一步扩充和综合利用其他多种图书特征项提高推荐的准确性和效果,并区分和明晰不同特征对于图书推荐的贡献程度和影响。此外,这些方法推荐的图书在内容上都极为相似,缺乏多样性,无法为用户提供多样化的选择,难以满足用户的潜在兴趣和需求。因此,本文希望在推荐过程中充分扩展和融合多种图书特征及其关联关系,提高推荐的准确性,并从语义相关角度为读者推荐种类多样的图书。
网络表示学习能够将网络中的节点以及节点间的关联关系进行语义融合,进而将网络中的节点表示为稠密低维向量,作为多种分类、聚类和链路预测任务的输入,并取得了较好的效果[3]。基于此,本文综合利用图书、关键词、作者、购买者、类别和出版社等多种特征及其多维关联关系,引入网络表示学习方法对它们进行语义融合,形成图书的语义向量表示,进而借助向量相似度指标计算图书相关性,从语义相关角度提高图书推荐的准确性和多样性,明晰不同特征对于图书推荐的贡献程度和影响。
1 国内外研究综述
本部分首先介绍图书推荐的基本方法,分别从基于内容的推荐、基于协同过滤的推荐以及基于关联规则的推荐共三个方面展开;接着介绍网络表示学习的常用模型与方法,介绍异构网络表示学习在推荐中的应用。
1.1 图书推荐相关研究
根据推荐算法的工作机制,图书推荐可分为基于内容的推荐、基于协同过滤的推荐以及基于关联规则的推荐[2]。
基于内容的推荐技术(content-based recommendations,CB)是最早被使用的推荐算法[4],它根据用户过去购买或者借阅的图书,为用户推荐与历史书目相似的图书。基于内容的推荐简单有效,结果直观,容易理解,取得了较好的效果[4]。由于该算法主要考虑图书内容,两本图书间的内容相似性是作为推荐与否的重要依据[5],因此只会为用户推荐与过去相似的图书,推荐同质化较为严重,而且存在语言的语义模糊性问题;此外,用户对于图书的评价以及图书的重要性较难体现在该方法中。基于协同过滤的推荐技术(collaborative filtering recommendations,CF)是现如今应用最为广泛的推荐方法[6]。它根据用户的偏好发现图书的相似性,或者根据图书特征发现用户的相似性,然后再基于这些相似性进行推荐。该算法可以有效利用其他用户的偏好信息,但是随着用户数目的增大,用户兴趣相似度计算起来也越来越复杂,时间和空间复杂度与用户数接近于平方关系;且在实际应用中,用户的历史偏好信息是用稀疏矩阵存储,计算复杂度高,对于新图书或新用户存在“冷启动”的问题。基于关联规则的推荐技术(association rule,AR)[7]是根据用户购买或者借阅的记录,利用支持度和置信度挖掘频繁共同出现的图书组合,利用生成的图书组合向用户推荐图书。该算法只需用户的图书购买记录,对数据的要求简单,但该算法中最小支持度和最小置信度是人为设置,较难找到最优值;此外,由于采用用户的数据,不可避免地存在冷启动和数据稀疏性的问题,并且热门畅销的图书容易被过度频繁地推荐。
以上三种推荐方法从不同角度在不同领域进行了大量图书推荐研究,并取得了较好的效果,但是这些方法所用信息还需进一步扩展和融合,图书的关键词、类别、作者、出版社等可能对图书推荐产生作用的特征尚未加入进来;尤为重要的是,多种特征及其关联关系尚需进一步融合实现综合利用,从而提高图书推荐的准确性。此外,这些方法推荐的图书在内容上都较为相似,尚需从潜在需求角度提高图书推荐的多样性。
1.2 网络表示学习相关研究
网络表示学习是复杂网络与深度学习的交叉融合,可以将网络节点转化为低维稠密实值向量,并将其用作已有的多种机器学习算法的输入[3]。
针对异构网络的特点,学者们以同构网络中的deepwalk[8]和node2vec[9]算法为基础,从不同角度形成和改进了异构网络表示学习模型,部分研究在推荐系统上验证了方法的效果和效率。Yu 等人[10]基于元路径的潜在特征来表示用户和物品之间沿不同类型路径的相关性,利用异构信息网络中不同类型的实体关系,提出了一种隐式反馈的推荐框架。Zhao 等人[11]提出NERM(network embedding based recommendation model)模型,该模型利用用户的物品打分记录和打标签记录构建异构网络,通过表示学习算法学习各节点的向量,根据相似度计算以实现物品推荐。Zhang等人[12]基于用户的评分信息构建用户-物品及用户-用户网络,利用node2vec方法学习用户节点的向量表示,将潜在社交关系融入推荐排序模型中,结果显示在评分预测推荐场景中取得不错效果。Shi等人[13]提出基于异构信息网络表示学习的推荐方法HERec,用于挖掘网络中用户和物品的潜在结构与表示,并在豆瓣电影、豆瓣图书等数据集上验证了该方法的有效性,但其融合的特征尚需扩展。李树青等人[14]根据读者借阅记录构建异构网络,设计算法以测度图书推荐质量,从而为图书推荐服务提供了良好的推荐客体,并以高校图书馆借阅记录为实验数据,验证了算法可以有效提高读者满意度。
异构网络表示学习的部分算法已经在推荐系统上验证了模型的有效性和效率,提高了语义表达效果,降低了计算复杂度,然而,这些模型尚未根据图书推荐这一具体任务,针对性地设计、扩展和综合利用多种图书特征项及其关联关系,形成语义相关视角下的特定图书推荐方法。
2 基于异构网络表示学习的图书推荐方法
本文首先选取多种图书特征构建图书异构网络,定义特征间的多维关联关系,并基于异构网络表示学习方法,融合多种图书特征信息,构建每本图书的语义向量表示;然后,从语义关联角度,通过余弦相似度计算图书之间的相关程度,实现图书推荐;最后,利用均方根误差、平均绝对误差等指标,比较异构网络表示学习方法与传统协同过滤方法以及deepwalk 算法对于图书推荐的准确性,在类别和内容多样性两个方面比较推荐图书的相关性差异。
2.1 图书异构网络构建
图书异构网络构建包括图书特征提取以及多维关联关系定义。如图1所示,图书特征包括图书b(book)、购买者u(user)、类别c(category)、作者a(author)和出版社p(publisher)以及表示图书内容信息的关键词k(keyword)等。特征间的多维关联关系以多种基本关联关系为基础进行拼接和扩展,其中五种基本关联关系为图书分别与购买者、类别、出版社、作者、关键词来形成,即bu或ub,bc 或cb,bp 或pb,ba 或ab 以及bk 或kb,并由此可以扩展形成多种关联关系类型,如ub和ba形成uba的关联关系,ub、ba,ab和bu形成ubabu的关联关系。出于效率考虑,以及越长的路径对于图书推荐的作用可能越小,本文选取长度小于或等于5的路径作为图书特征间的多维关联关系。
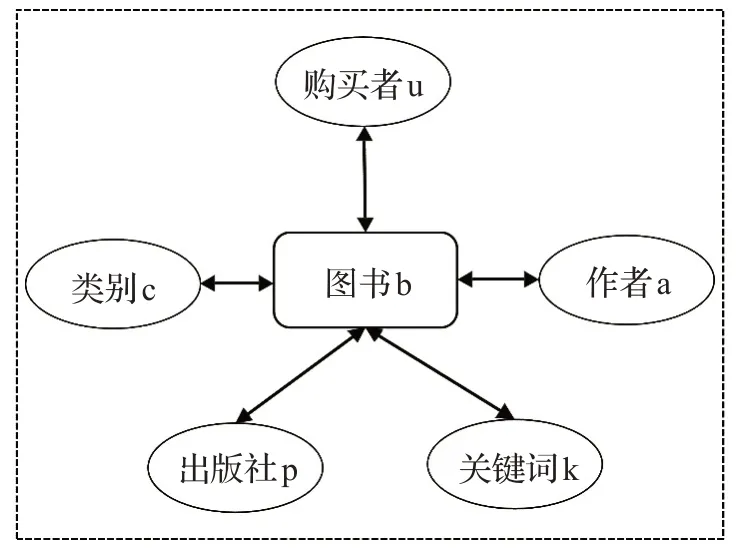
图1 图书异构网络Fig.1 Heterogeneous network of books
2.2 基于网络表示学习的图书特征语义融合表示
图书特征间的多维关联关系为图书提供了丰富的语义信息,可以通过网络表示学习形成图书的语义向量表示。首先,在图书特征间通过随机游走生成特征间的多维复杂关联关系序列。与一般的随机游走不同,图书推荐随机游走根据特征间的关联关系类型对游走路径进行了约束和限制,使得路径与图书密切相关,并且便于之后的融合表示。游走路径生成和约束的公式化表达如公式(1)所示[13]:
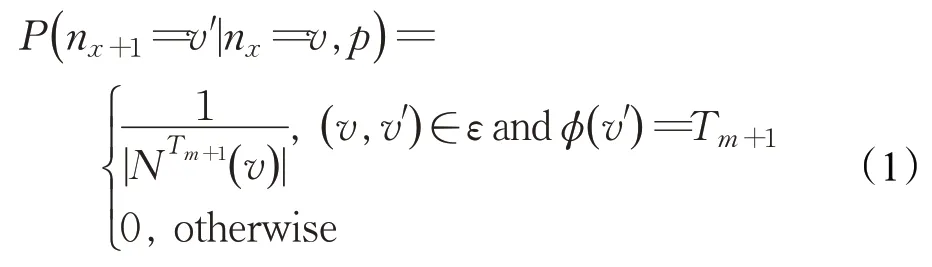
其中,nx为游走路径的第x个节点,v的类型为Tm,是类型为Tm+1的节点v的邻居。例如关联关系“bub”约束了游走时经过的节点类型为图书、购买者和图书,且游走顺序满足“图书→购买者→图书”。当一名购买者购买了多本图书时,这些被购买的图书便通过该名购买者产生了语义关联,表明这些图书可能具有一定的相关性;同样的,当多名购买者购买了多本不同的图书时,如图2 所示,通过图书购买关系使得图书之间具备了多种语义关联,如图书B1和B4通过U1和U2形成了关联路径B1U1B4和B1U2B4,图书B3和B4通过U2和U3形成了关联路径B3U2B4和B3U3B4。依此类推,通过约束随机游走可以产生多种关联类型、多种长度的关联序列。
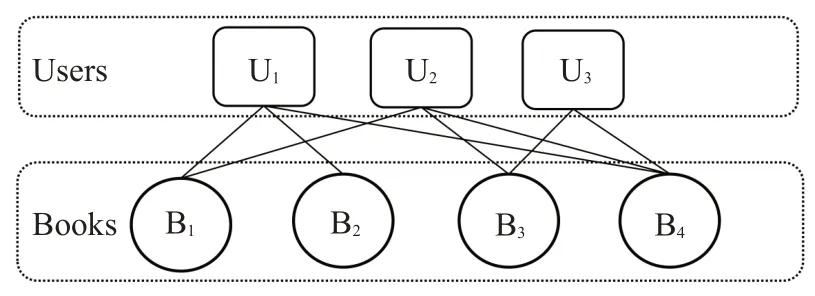
图2 约束随机游走下的图书购买者关联路径示例Fig.2 Example of book-user association path under constrained random walk
其次,本文利用图书特征项序列得到的路径信息,对每一条路径通过目标优化函数公式(2)来学习图书节点的语义向量表示,其中Nv是路径下图书节点v的邻居,采用随机梯度下降算法优化目标函数。

最后,对于一个图书节点v,可以学习到该图书节点的一系列表示,通过融合函数公式(3)对学习到的图书节点表示进行融合转换,其中为图书节点v在第l条路径下的表示,P为路径集合,是图书节点对于第p条路径的偏好权重,Ap和bp分别表示第l条路径下的变化矩阵和偏置向量,经过融合后得到图书的低维稠密向量表示。
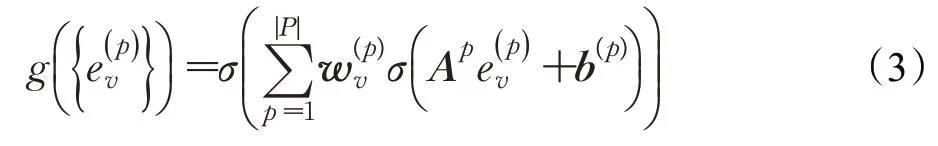
2.3 基于相似度计算的图书推荐
图书异构网络表示学习将图书特征项及其多种关联关系融合表示为图书的语义向量后,就可以借助多种向量相似度计算指标和方法,计算图书之间的语义相似性,进而实现图书推荐。
向量间相似度计算的方法很多,其中代表性的方法有余弦相似度、欧氏距离、Jaccard系数、马氏距离等。本文采用余弦距离来计算图书向量间的相似度。以x=(x1,x2,…,xn)T和y=(y1,y2,…,yn)T分别表示两本图书的向量,相似度计算公式如式(4)所示:
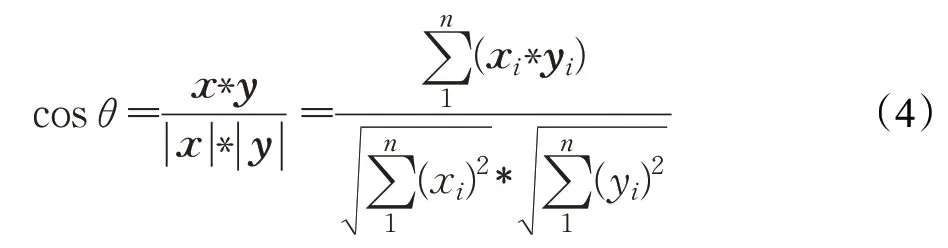
2.4 推荐效果评估
本文选择使用常用的平均绝对误差MAE(mean absolute error)和均方根误差RMSE(root mean squared error)方法来评价推荐准确度,通过计算预测的用户评分与实际用户评分之间的偏差度量,可以直观地度量推荐结果的准确性,MAE、RMSE 越小则说明推荐效果越好。计算公式如(5)、(6)所示,其中ri,j是用户i对于图书j的实际评分,r′i,j是用户i对于图书j的预测评分,Dtest是指测试集上的评分数据。
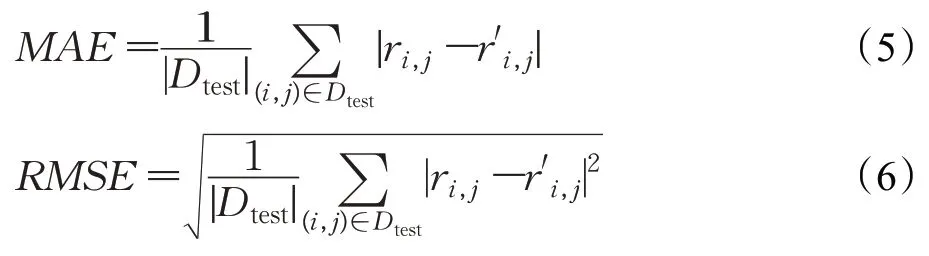
图书推荐不仅仅需要通过高准确率来满足用户,还需从多样性角度满足用户的潜在兴趣和需求,而这也是语义相关视角下的图书推荐的作用和优势。因此,本文从类别和内容多样性两个角度对图书推荐多样性进行评测。
(1)类别多样性的评价指标借助学科交叉测度中的多样性指标(diversity)[15]来实现,具体包括学科丰富度(varity)、平衡性(balance)和差异度(disparity),其中学科丰富度是指涵盖学科数量的多少,平衡性是指学科占比的均衡性,差异度是指学科间的差异性[15]。对应到图书推荐的多样性,将分别从类别丰富度NC(number of category)、平衡性SE(shannon entropy)以及类别差异度SIM(similarity)三个方面进行评价分析。如公式(7)~(9)所示:

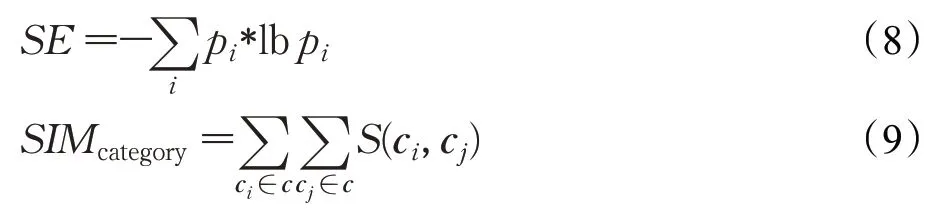
Ci表示推荐图书的所属类别,pi表示不同图书类别的概率分布,ci、cj表示基于word2vec的图书类别语义向量表示,S(ci,cj)是两本图书i、j所属类别之间的相似度。
(2)对于内容多样性的评价指标,选取差异度SIM作为衡量推荐图书内容层次多样性的指标。如公式(10)所示,bi、bj是基于doc2vec 的推荐图书摘要内容向量表示,S(bi,bj)是两本图书i、j之间的相似度。
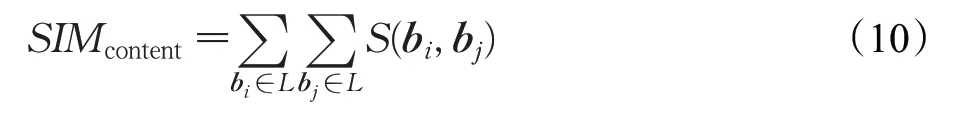
3 实证分析
本文以亚马逊图书数据集为基础,辅以爬虫技术获取图书的作者、出版社以及摘要中抽取的关键词,扩展图书特征项并构建图书异构网络,基于异构网络表示学习方法得到每本图书的向量表示,进而基于余弦相似度计算图书之间的相关度,然后基于RMSE、MAE指标比较异构网络表示学习方法与协同过滤方法以及deepwalk算法对于图书推荐的准确性,从类别和摘要内容多样性两个层次比较推荐图书的相关性,从而验证异构网络表示学习方法在图书推荐运用中的可行性和有效性,最后通过定量比较融合不同元路径后的推荐结果,以探究不同图书特征对推荐结果的影响。
3.1 数据来源
本文通过扩展亚马逊图书数据集中的图书特征项,形成本文的实验数据。首先从中提取已有图书特征项,如图书异构网络中所涉及到的图书b、购买者u、图书类别c 节点;在此基础上,利用网络爬虫方法获取图书作者a、出版社p 以及从摘要中抽取的表示图书内容的关键词k,扩展形成完整的数据集。其中,关键词抽取通过RAKE 算法(rapid automatic keyword extraction)来实现[16],每篇文章中选取排名前5的关键词作为其表示。最终,实验数据集包含28 382个用户、2 301本图书、11 124个关键词、55 个图书类别、2 106 个作者及927 个出版社。表1列出了实验中涉及的五种基本关联关系和对应路径的统计信息。
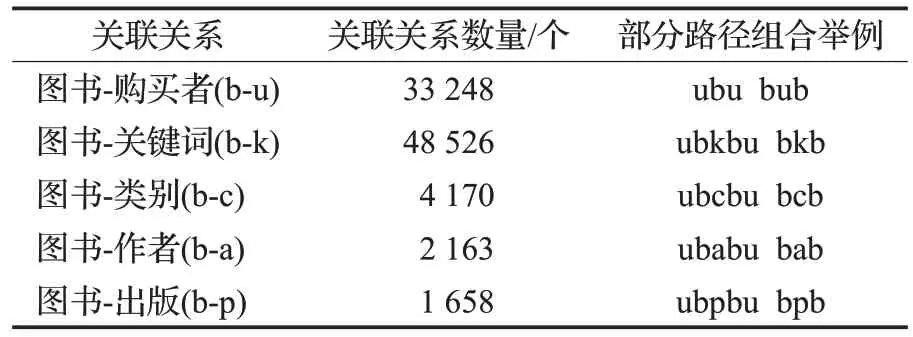
表1 实验数据统计Table 1 Statistics of experimental data
3.2 推荐准确性对比分析
本文将异构网络表示学习的方法运用在图书推荐这个问题上,并将推荐效果与现在最为主流的协同过滤推荐方法以及deepwalk方法进行对比,结果如表2所示。
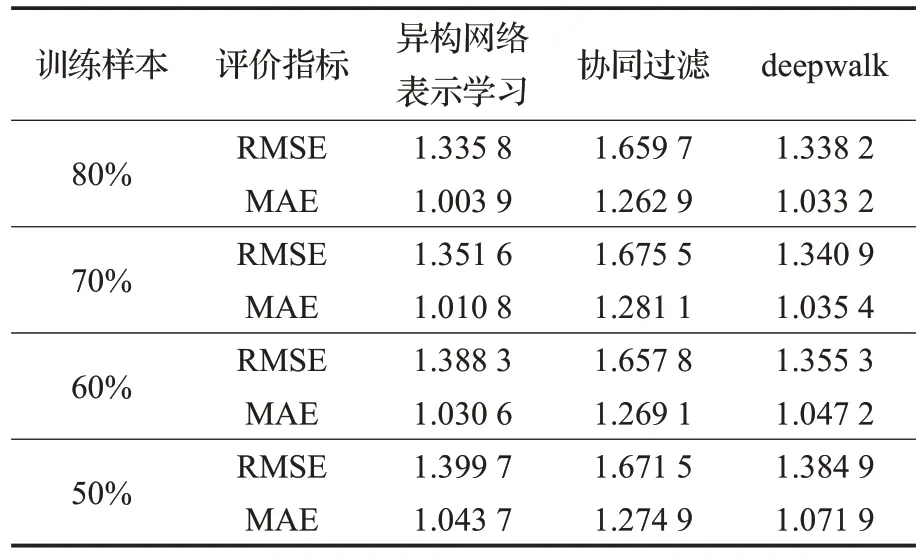
表2 实验结果对比Table 2 Comparison of experimental results
对于本实验数据,将评分数据按不同比例分成训练集和测试集,设置了不同的训练样本百分比,分别在80%、70%、60%、50%的数据集上进行训练,在对应余下的数据集上进行测试,实验结果如表2 所示。结果显示,异构网络表示学习的方法分别在80%、70%、60%、50%训练集情况下,图书推荐上的MAE 指标均低于协同过滤方法以及基于deepwalk 的推荐方法。在训练样本80%的情况下,异构网络表示学习的方法在图书推荐上的RMSE 也同样取得了最优的效果;在训练样本为70%、60%、50%情况下,deepwalk 图书推荐上的RMSE指标反而略微优于异构网络表示学习,其原因可能是deepwalk 的输入网络同样是包含了所有图书属性特征以及多维关联关系的异构网络,并在deepwalk中当作同一节点类型进行了训练,间接增加了图书间的关联关系。总体来看,异构网络表示学习所预测的即在图书推荐的应用上异构网络表示学习的效果是比较优秀的,采用异构网络表示学习模型进行推荐具有更好的推荐效果,提高了推荐的准确性。
3.3 推荐结果的多样性比较与分析
大多数推荐方法所推荐的图书可能在类别上具有单调性,内容上存在重复性,难以满足用户的多样性需求和可能的潜在兴趣,因此,下面将从多样性角度出发对推荐结果进行相关性比较和分析,更全面地对推荐结果进行评估。
3.3.1 类别多样性角度
图书推荐的类别多样性将从类别丰富度、平衡性以及类别相似度三个方面进行评价分析。针对每一本图书的推荐结果,取其前n本作为最相关的图书,当n等于1、3、5、7、9 时,计算平均类别数average_NC、平均信息熵average_SE、平均类别相似度average_SIMcategory,结果如表3所示。
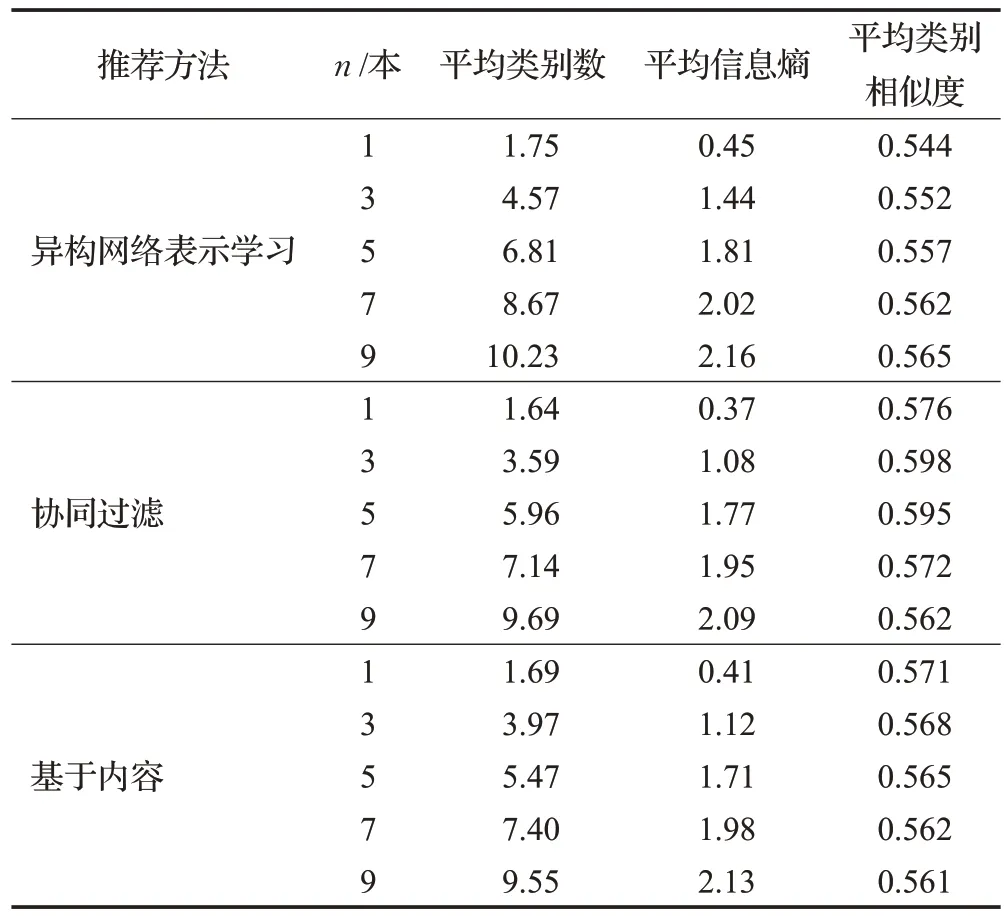
表3 图书推荐的类别多样性比较结果Table 3 Comparison results of diversity of recommended book categories
平均类别数随着n的变化如图3(a)所示,可以发现,随着推荐图书数量的增多,推荐图书的类别也随之增加。异构网络表示学习推荐的平均图书类别数目均多于基于内容和协同过滤方法,即异构网络表示学习推荐的图书更加多元化,推荐书目的类别更加丰富。平均信息熵和平均类别相似度指标所反应的结论和平均类别数指标基本一致,如图3(b)和图3(c)所示,其中,平均类别相似度越低,表明推荐图书类别的差异越大。值得一提的是,异构网络表示学习方法随着推荐图书数量的增加,平均类别相似度逐渐变大,这从侧面反映了异构网络表示学习方法首先推荐的可能是与原图书类别差异较大的类别的图书,并随着数量增加,推荐的图书类别越来越相似。
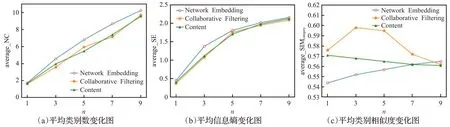
图3 类别多样性统计结果Fig.3 Statistics of category diversity
以ASIN码为“078510870X”的图书Ultimate Marvel Team-Up为例具体说明,此书的类别为“Children’s Books”,推荐的前10 本图书如表4 所示,分别计算NC、SE、SIM这三个多样性指标,结果如表5所示。
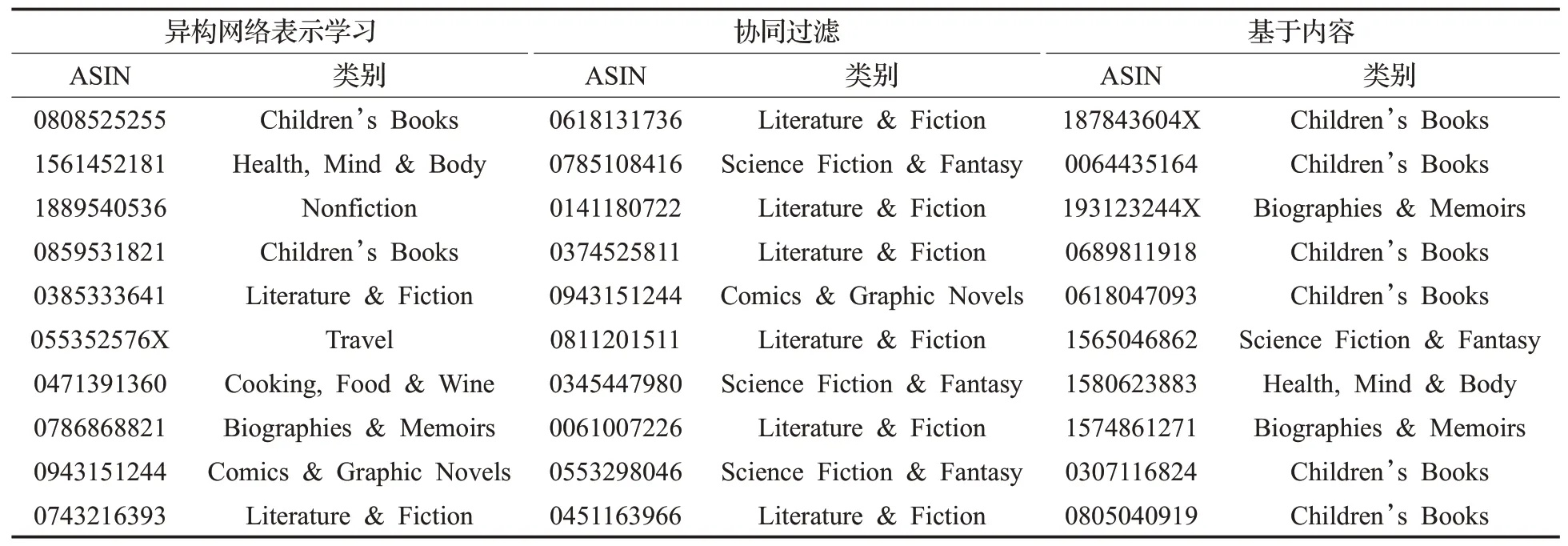
表4 图书Ultimate Marvel Team-Up的图书推荐类别Table 4 Recommended categories of Ultimate Marvel Team-Up
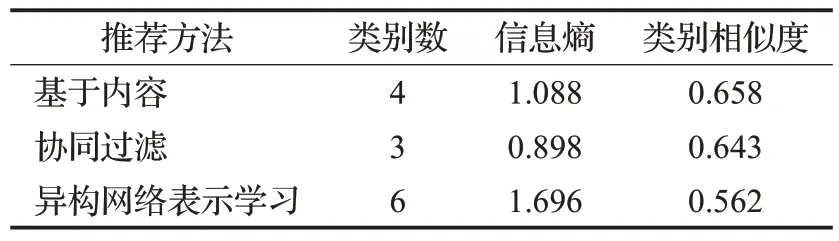
表5 推荐图书类别多样性比较结果Table 5 Comparison results of diversity for recommended book categories
根据表4 可以发现,基于内容的方法推荐了4 个类别的图书,其中“Children’s Books”类别图书共有6 本,协同过滤所推荐的图书种类只有3 种,其中,“Literature&Fiction”的类别有6 本,“Science Fiction &Fantasy”类别3 本,推荐的书本以小说文学类为主;而异构网络表示学习方法推荐的类别多达7 种,其中,“Children’s Books”“Comics &Graphic Novels”及“Literature &Fiction”类别的图书各2本,推荐的图书包含但又不限于儿童、小说文学类别,该方法推荐的图书更多元化,类别更丰富。表5的指标计算结果同样证实了该结论。
3.3.2 从内容多样性角度
针对每一本图书的前n个推荐结果作为最相关的图书,抽取这n本书的摘要内容,利用doc2vec进行语义表示,分别计算图书两两之间的内容相似度,并对其求平均得到平均内容相似度。如果平均内容相似度越小,表明推荐结果列表中的图书越不相似,推荐结果的多样性就越好。
不同推荐方法推荐的图书与原图书的内容相似度如表6 所示。可以看到,基于内容、基于协同过滤方法所推荐的图书平均内容相关性这一指标比较稳定,分别保持在0.96和0.92左右,这说明无论推荐图书的数量如何变化,基于内容及协同过滤指标所推荐的图书在内容上都与原图书相似度很高;而基于异构网络表示学习方法所推荐的图书平均内容相似度保持在0.87,低于其他两种方法,这同样说明了相比之下,基于异构网络表示学习方法所推荐的图书在内容上更加丰富。
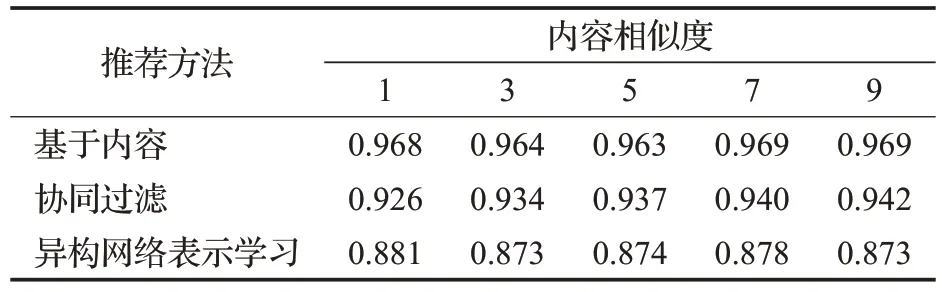
表6 推荐图书内容相关性总体比较结果Table 6 Comparison results of overall correction for recommended book content
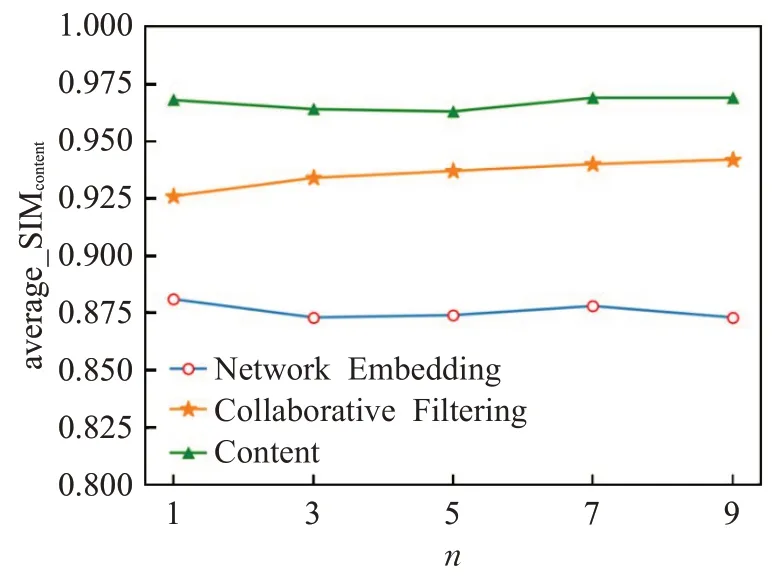
图4 内容多样性结果变化Fig.4 Results of change for content diversity
同样地,以ASIN码为“078510870X”的图书Ultimate Marvel Team-Up为例进行分析,结果如表7所示。从内容语义层面的相似度指标显示,异构网络表示学习算法所推荐的图书内容更加多样。
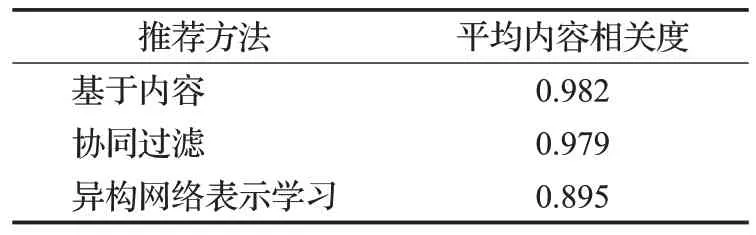
表7 推荐图书内容多样性比较结果Table 7 Results of diversity comparison of recommended books
上述结果显示,无论是在类别层面还是在内容层面上,协同过滤方法所推荐的图书都是更加相似,协同过滤更多地强调相似性;而异构网络表示学习推荐的结果类别更加丰富,内容更加多元,更多地强调相关性。基于异构网络表示的推荐不仅具有高准确率,而且所推荐的图书更加多样,注重相关性,能更好地满足用户的潜在兴趣。
3.4 图书特征对图书推荐的贡献度和影响分析
不同图书特征对图书推荐的贡献度和影响可能不同,本文通过逐步融合不同特征形成的关联关系,结合多种评测指标,评估图书特征对于图书推荐的贡献度和影响。本文首先选定和某个特征相关的路径信息,然后逐一将其他特征相关的关联关系加入到现有路径中,通过计算评估指标的变化发现特征项对于图书推荐的影响。具体实验流程如下:首先选定购买者相关的路径,即“ubu”和“bub”这一组元路径;随后在此基础上加入图书作者相关的路径,即融合“ubabu”和“bab”路径;依次加入主题词相关路径“ubkbu”与“bkb”、图书类别特征路径“ubcbu”与“bcb”以及出版社特征路径“ubpbu”与“bpb”。每个步骤中均分别计算均方根误差和平均绝对误差两个指标用于评估图书推荐效果,结果如表8所示。
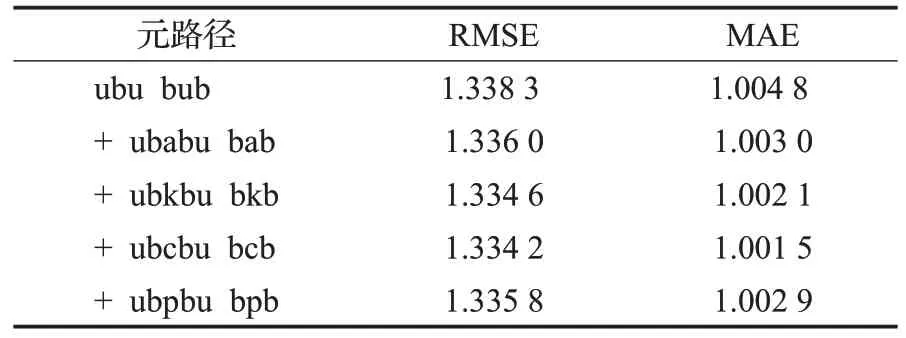
表8 图书特征影响Table 8 Results of effect for book characteristics
由表8可以看出,随着图书特征的逐步融入,RMSE、MAE 两个指标都有所降低,说明推荐效果逐步得到改善,但是随着融入的图书特征信息越来越多,RMSE、MAE 这两个指标却有所上升,效果不仅没有得到改进反而下降,这可能是因为一些路径包含噪音或与现有路径有冲突。由此可知,并非融入图书特征信息越丰富,模型越复杂就能达到更好的效果,在构建异构网络模型时应是有选择地融入重要特征,通过甄选少量高质量的图书特征及其路径来控制模型的复杂度,同时能够较大地提高推荐的准确性。
在此基础上,通过单独计算每种特征及其关联关系下的图书推荐效果,可以判断每种特征项对于图书推荐的贡献程度。本文分别把购买者、关键词、类别、作者和出版社相关的路径信息加入到图书异构网络关联模型中,计算均方根误差RMSE和平均绝对误差MAE,结果如表9 所示。由于平均绝对误差MAE 和均方根误差RMSE值越小,表明效果越好,因此,对图书推荐贡献程度从高到低的特征依次为作者、关键词、类别、购买者和出版社,这也为特征项选取提供了思路和方法。
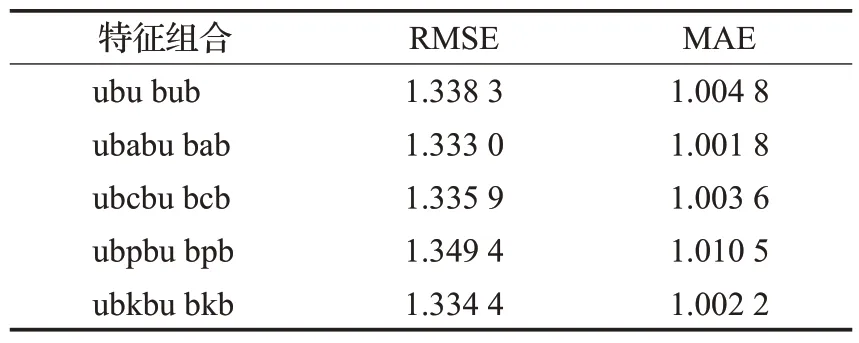
表9 不同图书特征推荐效果比较Table 9 Comparison of recommendation effects of different book features
4 总结与展望
为了提高图书推荐的准确性和多样性,满足用户可能的潜在需求,本文通过融合更多的图书特征信息,构建图书异构网络,引入网络表示学习方法,从语义相关的角度设计了图书推荐方法,利用平均绝对误差、均方根误差等定量指标评估推荐的准确性,利用丰富度、均衡性、差异度等指标分析图书推荐的多样性。在扩展的亚马逊图书数据集上的实证结果表明,相较于协同过滤,该方法的均方根误差、平均绝对误差最多分别降低了19.52%、20.51%,相较于deepwalk,该方法的均方根误差、平均绝对误差最多分别降低了0.17%和2.9%,准确性得到较大提高;多样性评测指标也显示该方法推荐的图书种类更多元、内容更丰富,多样性同样得到了提高;明晰了不同特征对图书推荐的贡献程度,从高到低依次为作者、关键词、类别、购买者和出版社。
该方法在图书推荐方面取得了一定的效果,但由于是初步研究和探索,在以下方面仍需进一步深入研究。首先,可以通过获取和融合更多的特征类型,以进一步提高推荐的准确性和全面性;其次,本文仅扩展了亚马逊图书数据集并验证了异构网络表示学习方法融合多种图书特征项的有效性,尚需扩展研究方法和研究领域,在多种平台和图书资源上进行推荐并进行方法验证。
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
新校长(2016年8期)2016-01-10 06:43:59
汽车零部件(2014年10期)2014-11-11 12:25:04
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
