
改进YOLOv5的轻量级安全帽佩戴检测算法
2022-05-15 06:35杨永波
计算机工程与应用 2022年9期
杨永波,李 栋
内蒙古工业大学 信息工程学院 内蒙古自治区感知技术与智能系统重点实验室,呼和浩特010051
随着社会信息化水平的不断提升,智能应用在不同行业领域得到广泛应用。如人脸识别、交通灯识别等。在建筑和矿产等行业,为保证工人生产安全,要求工人生产期间必须佩戴安全帽,安全帽的佩戴检查成了生产安全管理的一项重要的工作[1]。由于工地上作业环境危险,不适合用人力在现场进行实时监控,安全帽的正确佩戴情况的实时监测,成为了智能化嵌入式设备应用开发研究的一个重要应用场景。
国内有少部分学者提出基于深度学习的安全帽检测方法。施辉等[2]在YOLOv3中添加特征金字塔进行多尺度的特征提取,获得不同尺度的特征图,以此实现安全帽的检测。肖体刚等[3]在YOLOv3 算法的基础上,改进网络结构,增大输入图像的尺度,使用深度可分离卷积结构替换Darknet-53 传统卷积,使用多尺度特征检测,增加浅层检测尺度,添加4倍上采样特征融合结构,缩减模型参数,提高安全帽佩戴检测准确率。张锦等[4]在YOLOv5 的基础上使用K-means++算法重新设计先验框尺寸并将其匹配到相应的特征层;在特征提取网络中引入多光谱通道注意力模块,使网络能够自主学习每个通道的权重,增强特征间的信息传播,从而加强网络对前景和背景的辨别能力,并在训练迭代过程中随机输入不同尺寸的图像,以此增强模型的泛化能力。
上述方法虽然对算法进行了优化改进,但其参数量和计算量较大,不利于终端设备的部署,且对遮挡目标辨别度差,针对现有技术的缺点、不足之处,本文提出了一种轻量级的安全帽佩戴检测模型YOLO-M3,将YOLOv5s 主干网络替换为MobileNetV3 来进行特征提取,由深度可分离卷积代替原始卷积层提取特征,大幅度减少网络计算量;其次,使用DIoU-NMS 替换NMS,改善目标遮挡时的漏检问题,为了在减少参数量和计算量的同时保持较高的检测精度,添加CBAM 注意力机制加强对检测目标的关注,再对模型进行知识蒸馏,使轻量级的模型具有复杂网络模型的学习能力,来增加模型检测的召回率和准确度。通过实验验证了YOLO-M3模型的有效性,提高了对遮挡目标的辨识度,降低了硬件成本,满足在低算力平台上部署的需求。
1 相关理论
1.1 MobileNetv3
MobileNet 系列网络作为轻量级网络的代表,被广泛应用到嵌入式端和移动端,MobileNetv3[5]作为MobileNet系列的最新版,它综合了以下四个特点。
1.1.1 MobileNetV1的深度可分离卷积
引入深度可分离卷积,将普通卷积替换为深度卷积和点卷积,深度卷积针对每个输入通道采用不同的卷积核,即网络的分组数与网络的channel数量相等,使网络的计算量减到最低,再使用点卷积进行channel 之间的融合[6]。标准卷积分解为深度卷积与逐点卷积的过程如图1所示。
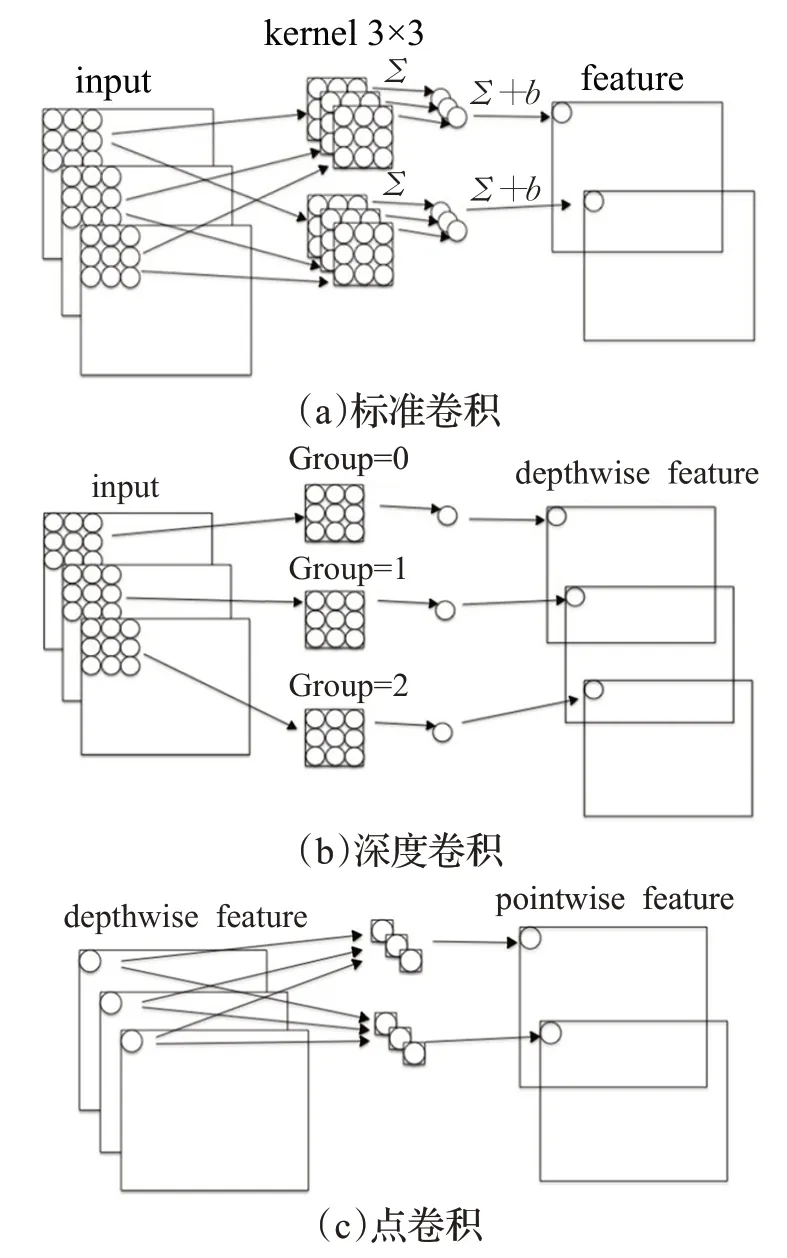
图1 标准卷积分解过程Fig.1 Standard convolution decomposition process
假设Dk×Dk为卷积核的尺寸,M为输入通道数,N为输出通道数,DF×DF为输出特征图的尺寸,那么普通卷积的计算量如式(1)所示:
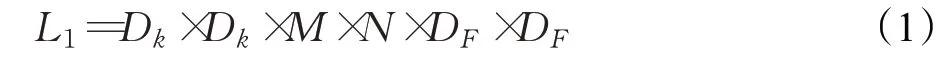
深度可分离卷积的计算量如式(2)所示:
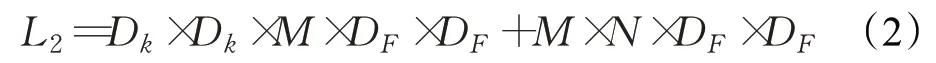
如式(3)所示,通过深度可分离卷积,相当于将普通卷积的计算量压缩为:
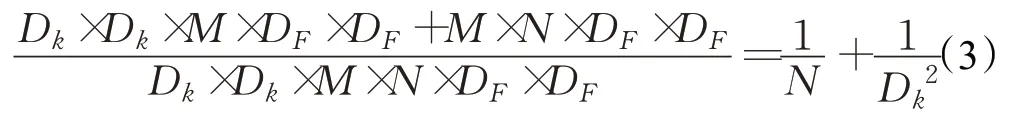
通过深度可分离卷积,在保持较好的精度的同时,计算量大幅度降低[7]。
1.1.2 MobileNetV2具有的线性瓶颈的逆残差结构
MobileNetV2[8]的线性瓶颈的逆残差结构与原始的残差结构不同,原始的残差结构采用先降维、再升维的方法,深度卷积因其参数少,提取的特征相对较少,先进行压缩,提取的特征会更少,因此先扩张来进行特征提取再压缩,此外,深度可分离卷积得到的特征对应于低维空间,如果后续接线性映射则能够保留大部分特征,而如果接非线性映射则会破坏特征,使得模型效果变差。因此把每一个Block 中最后的ReLU6 层换成了线性映射Linear,来减少特征的损耗,获得更好的检测效果。如图2所示。
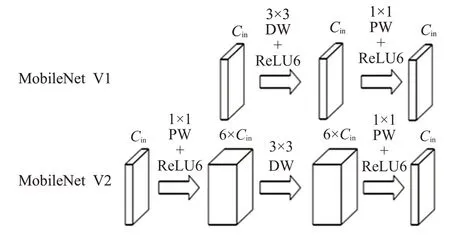
图2 反向残差模块结构Fig.2 Reverse residual module structure
1.1.3 轻量级的注意力模型
引入轻量级注意力机制SENet[9]网络,注意力网络SENet是通过对每个通道进行全局平均池化,使其具有全局的感受野,进而使浅层网络也具有了全局信息;再通过FC→Relu→FC→h-swish 为每个通道生成相应的权重,来提升重要的特征并抑制不重要的特征,SENet注意力机制结构如图3所示。
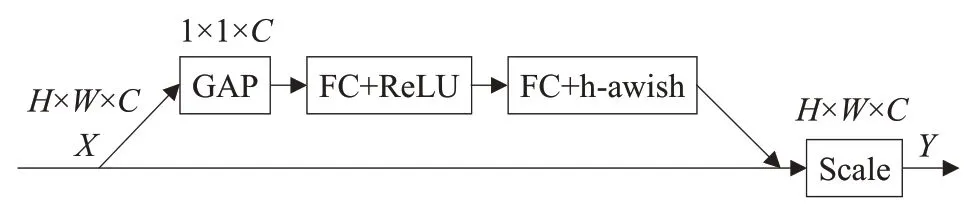
图3 SENet注意力机制结构Fig.3 SENet attention mechanism structure
其中输入X的大小为H×W×C,GAP 表示全局平均池化,FC表示全连接层,ReLU和h-swish为激活函数,Scale 将生成的各个通道的权重系数与对应通道所有元素相乘实现重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
1.1.4 利用h-swish代替swish函数
h-swish是基于swish[10]的改进,swish函数具有无上界、有下界、平滑和非单调的特点,并且在深层模型上的效果优于ReLU,但其sigmoid 函数σ(x)在移动端非常消耗计算资源,为了能够在移动设备上应用swish 并降低它的计算资源的消耗,h-swish改用sigmoid函数σ(x)的近似函数ReLU6来逼近Swish,使用ReLU6在量化模式下能提高大约15%的效率,且ReLU6函数在许多软硬件框架中都已实现,易于量化部署,计算推理速度快。swish和h-swish函数的公式分别如式(4)、(5)所示:
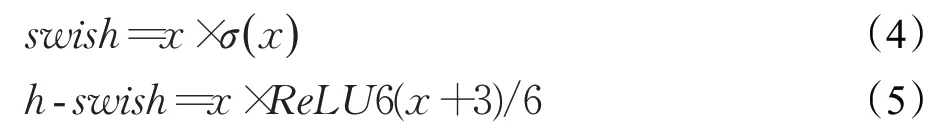
1.2 YOLOv5s
YOLOv5s的结构由四部分组成,输入端、Backbone主干网络、Neck 网络、Prediction 输出端,如图4 所示。YOLOv5s 在数据输入部分加入了自适应图像填充、自适应锚框计算、Mosaic 数据增强来对数据进行处理,增加了检测的辨识度和准确度;在Backbone 中主要采用Focus结构和CSP1_X结构,Focus结构主要用来进行切片操作,在不损失任何信息的情况下通过增加特征图的维度来缩小特征图的尺寸,得到二倍下采样特征图,CSP1_X中加入残差结构使得层和层之间进行反向传播时,梯度值得到增强,有效防止网络加深时所引起的梯度消失,得到的特征粒度更细。Neck中采用CSP2_X结构,降低计算量的同时使网络对特征的融合能力得到加强,保留了更丰富的特征信息。Neck 层还设计了特征金字塔在网络中从上向下的传递语义信息和路径聚合结构来传递定位信息。Prediction中将边界锚框的损失函数CIOU_Loss改为GIOU_Loss,采用加权nms运算对多个目标锚框进行筛选来提高对目标识别的准确度。
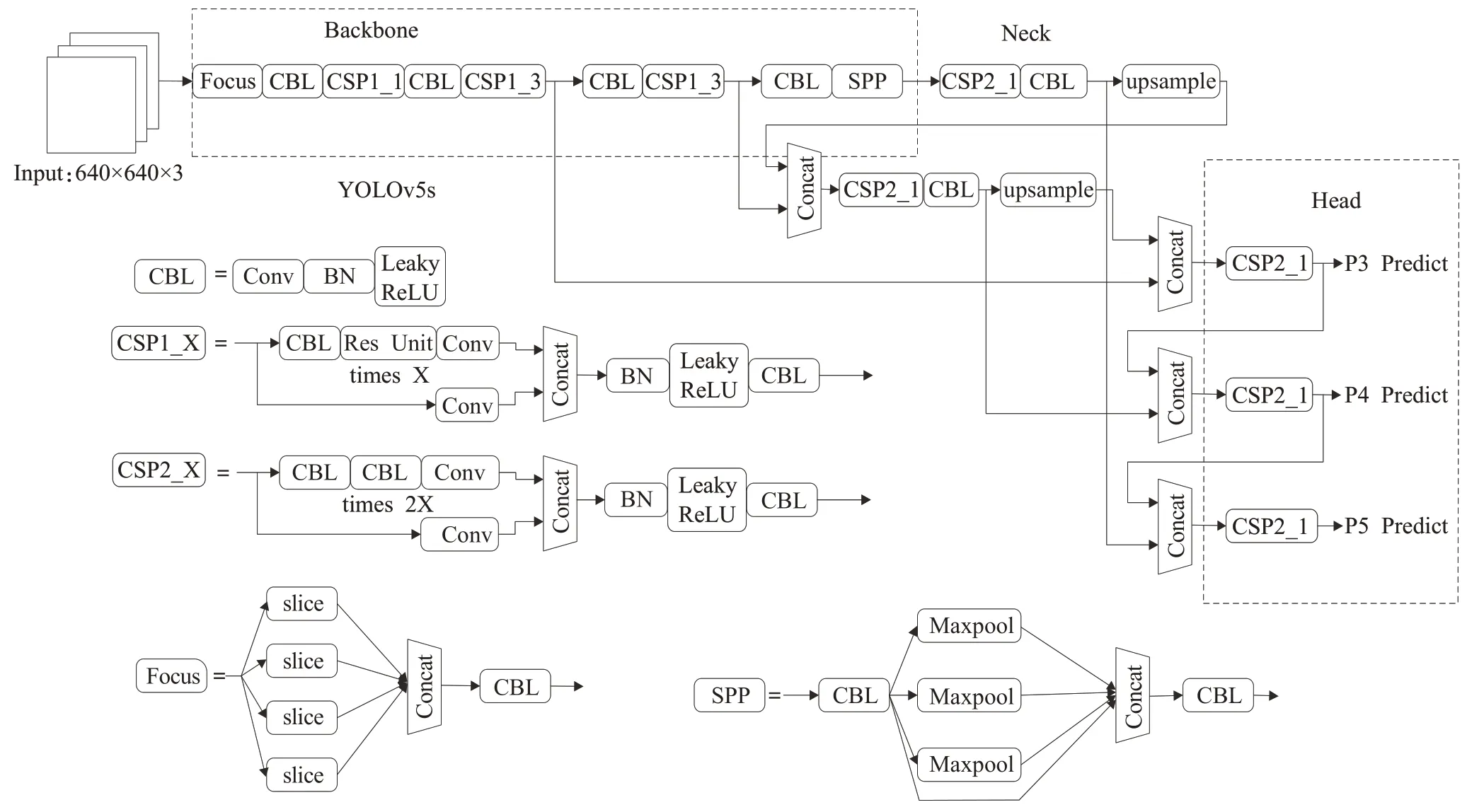
图4 YOLOv5s结构图Fig.4 YOLOv5s structure diagram
2 YOLO-M3改进算法
2.1 主干提取网络的改进
将YOLOv5s 的Backbone 主干网络替换为Mobilenetv3的主干网络,来进行特征提取,Mobilenetv3是一种轻量神经网络,特点是参数少、速度快、占用显存低,由深度可分离卷积代替原始卷积层提取特征,在减少参数量的同时,提高了运算速度,也大幅度降低了对算力的需求。YOLO-M3提取网络结构如表1所示。
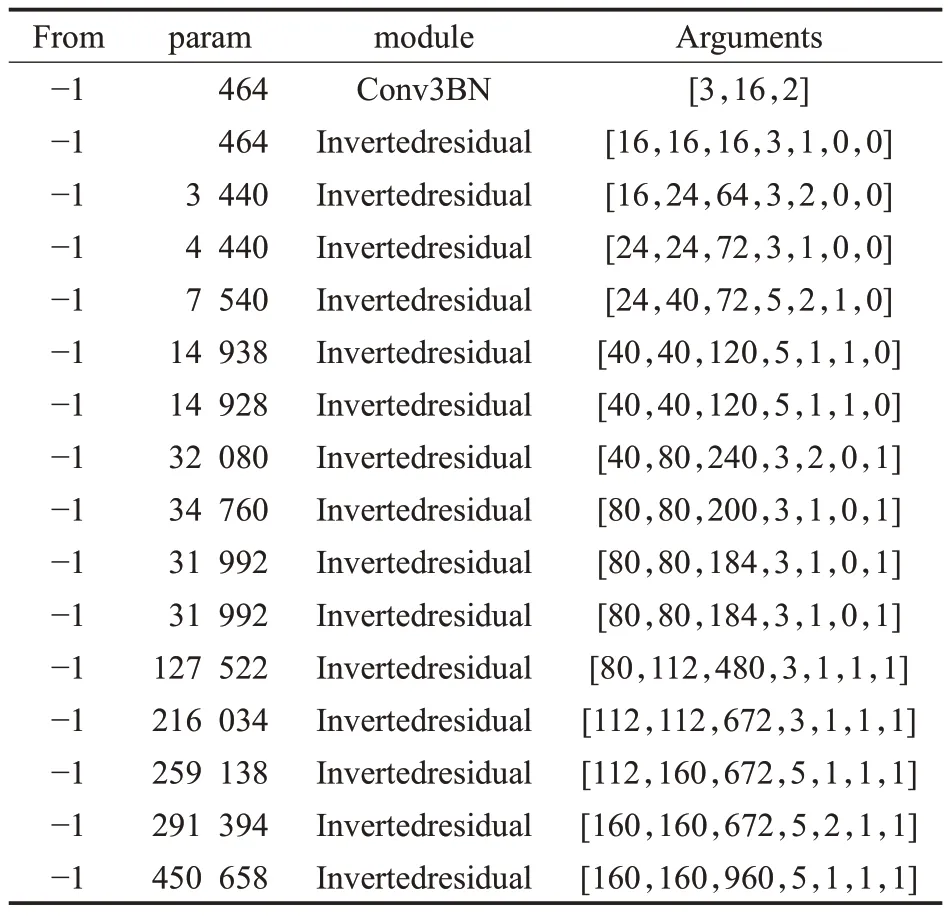
表1 YOLO-M3提取网络结构Table 1 YOLO-M3 extract network structure
表1 中From 列的-1 表示输入来自上一层输出,Con3BN后Arguments列的值分别表示该模块的输入通道数、输出通道数和步长信息,Invertedresidual 后Arguments 列的值分别表示该模块的输入通道数、输出通道数、1×1 卷积升维后的通道数、卷积核大小、步长、是否加入SE注意力机制和是否使用h-swish激活函数,经计算,提取网络替换后的模型共计5 102 109 个parameters,计算量为1.0×1010,YOLOv5s模型共计7 056 607个parameters,计算量为1.6×1010,由此得知,优化后模型参数量减少了27.6%,计算量减少了38%,实现了对模型的初步压缩。
2.2 注意力机制的改进
在网络模型中用CBAM[11]注意力机制替换SENet模块来优化目标检测精度,加强对检测目标的关注,从而降低由于环境复杂造成的检测精度下降的问题。
CBAM 包含2 个独立的子模块,通道注意力模块和空间注意力模块,分别在通道和空间维度上进行Attention,给定一个特征图,CBAM 模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图与输入特征图相乘以进行自适应特征优化。引入CBAM 后,特征覆盖到了待识别物体的更多部位,而且最终判别物体的几率也更高。CBAM 注意力机制结构如图5所示。
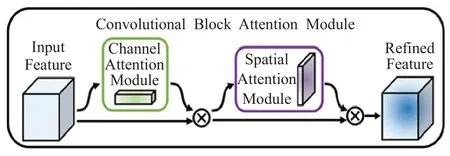
图5 CBAM注意力机制结构Fig.5 CBAM attention mechanism structure
具体方法:先通过通道注意力机制,在空间维度上分别进行最大值池化与平均值池化,得到两个只有通道维度的向量,然后将这两个向量分别通过一个共享全连接层,两特征相加后经过sigmoid 函数。得到通道注意力向量,通道注意力机制表达式如式(6)所示:
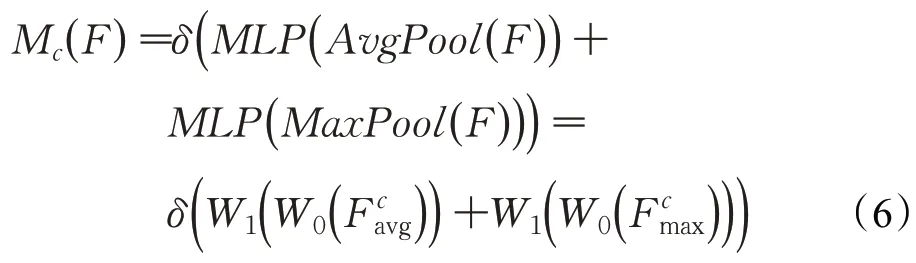
通道注意力机制如图6所示。
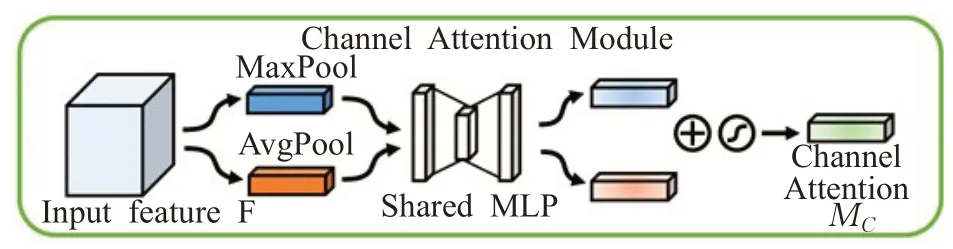
图6 通道注意力机制Fig.6 Channel attention mechanism
再通过空间注意力机制,在通道维度上进行最大值池化和平均值池化,然后将这两个结果基于通道做连接操作。然后经过一个卷积操作,降维为1个通道。再经过sigmoid生成空间注意力向量。空间注意力机制表达式如式(7)所示:
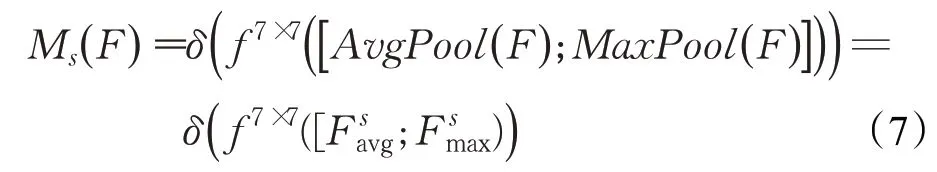
空间注意力机制如图7所示。
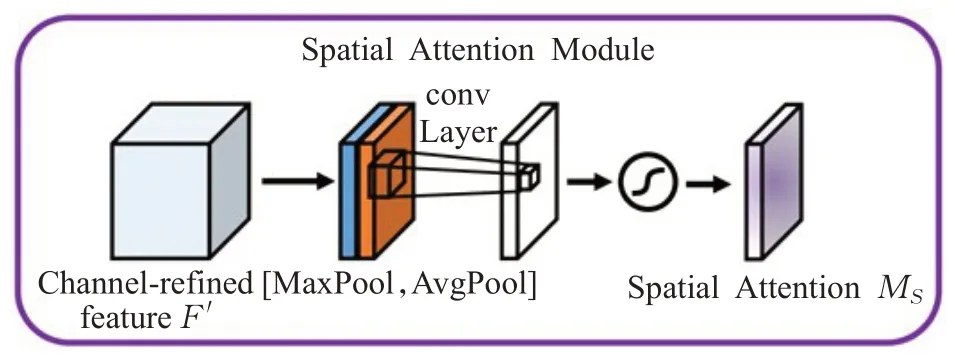
图7 空间注意力机制Fig.7 Spatial attention mechanism
2.3 NMS非极大值抑制改进
使用DIoU-NMS[12]替换NMS,改善目标拥挤时的漏检问题,增加检测的召回率和准确率。在使用NMS 移除多余的检测框时,评判的标准是某个检测框与预测得分最高的检测框的交并比IoU,当IoU 大于设定的阈值时,预测的检测框将被移除。但在目标密集的情况下,由于目标的相互遮挡检测框的重叠面积较大,经常会被NMS 错误的移除,造成目标漏检。考虑到工作场地人员的密集性,使用DIOU 和NMS 相结合的方法来改善漏检情况,DIoU-NMS 不仅考虑了交并比IoU 的值,还考虑了预测边界框和真实边界框两个Box 中心点之间的距离,DIoU-NMS公式如式(8)所示:
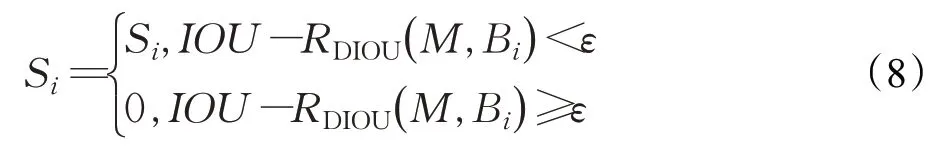
其中,M表示预测分数最高的一个预测框,Bi用来判断预测框是否需要被移除,Si表示分类分数,ε表示NMS 的阈值,RDIOU是两个Box 中心点之间的距离,公式如式(9)所示:

其中,ρ2(·)是欧式距离,b和bgt是预测边界框和真实边界框的中心点,c表示两个Box的最小包围框的最短对角线长度。
DIoU-NMS的与NMS的最大不同之处在于当两个中心点较远的box,DIoU-NMS 认为可能位于不同的对象上,不应将其删除,从而改善漏检情况。
针对上述问题,建筑企业需在公司内部建立起相关规章制度,严格规范整个核算过程,让整个环节更加严谨[4-6]。同时,在企业内部可以建立起专门的监督部门,对会计核算人员和工作进行实时动态监督,还要加强外部监督。除此之外,还要培养一批专业的会计核算工作人员,树立起他们的规范意识,提高专业素养,从而更好地进行建筑企业项目管理的会计核算工作,促进企业的发展。
2.4 知识蒸馏
知识蒸馏(knowledge distillation)是模型压缩的一种常用的方法[13],不同于模型压缩中的剪枝和量化,知识蒸馏的主要思想是训练一个小的网络模型来模仿一个预先训练好的大型网络。这种训练模式又被称为“teacher-student”,大型的网络是“教师网络”,小型的网络是“学生网络”。知识蒸馏期望让学生网络在拥有更少参数量,更小规模的情况下,达到与教师网络相似甚至超越教师网络的精度。因此,对模型进行蒸馏,解决了速度较慢,占用显存高的问题,并且增加了模型的准确度。蒸馏过程如图8所示。
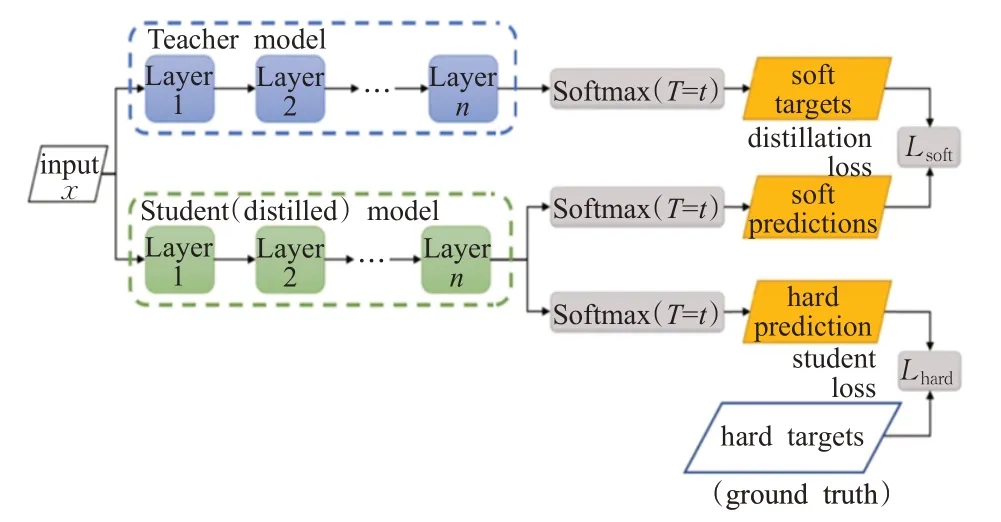
图8 蒸馏过程Fig.8 Distillation process
首先利用数据训练一个层数更深,提取能力更强的教师网络,得到logits,然后,将教师网络输出logits进行温度为T的蒸馏,经过softmax层得到类别预测概率分布作为soft targets,同时,学生网络输出logits经过相同温度T进行蒸馏,经过softmax层之后得到类别预测概率,作为soft predictions,进一步得到损失函数Lsoft,Lsoft公式如式(10)所示:

教师网络也有一定的错误率,使用真实标签作为hard targets,和学生网络原始softmax 进一步得出损失函数Lhard,Lhard的公式如式(11)所示:cj为第j类真实标签值。

损失函数Lhard和Lsoft加权相加作为最终的损失函数L。使得学生模型学习教师模型的同时,也在和真实标签进行比对学习,可有效阻止教师网络中的错误信息被蒸馏到学生网络中。本文采用YOLOv5m 模型作为教师模型,以经过以上步骤改进的YOLOv5s 作为学生模型进行蒸馏,提高学生模型的性能。
3 实验结果及对比分析
3.1 实验数据处理与实验环境
本实验是在Windows 10 操作系统,NVIDIARTX A5000 显卡下,通过Pytorch 深度学习框架实现的模型的搭建、训练和验证,使用CUDA 11.1 计算架构,同时将cudnn 添加到环境中加速计算机的计算能力。所用的数据集是Safety Helmet Wearing[14],并对其中不符合本实验的图片进行剔除,同时又从互联网上筛选一些具有复杂的施工环境和目标密集的图片来做补充,进而提高检验难度,来满足在移动端或嵌入式端的实际应用,用PASCALVOC 对数据进行标记。实验数据集包含7 851张图片,以8∶2 的比例划分数据集和验证集,并将格式从XML转换为txt格式,图片分辨率大小为640×640,训练批次设置为16,初始学习率为0.003,IoU阈值设置为0.5,mixup 为0.5,所有参照模型均按照此参数训练300个epoch。
3.2 改进过程的对比实验及结果分析
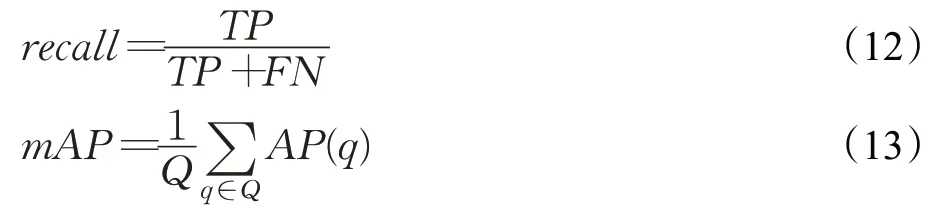
TP是指人佩戴了安全帽同时检测正确的数量,FN是指人佩戴了安全帽但是检测错误的数量,AP是平均准确度,是指在所有召回率的可能取值情况下,得到的所有准确度的平均值,平均精度(mAP)是指AP 值在所有类别下取的平均。平均准确度AP的计算公式如式(14)所示:

TN是指人未佩戴安全帽同时检测正确的数量,FP是指人未佩戴安全帽但检测错误的数量。具体实验结果如表2所示。
由表2 可以看出,YOLOv5s 的模型大小13.7 MB,计算量为1.6×1010,特征提取网络换深度可分离卷积后模型大小下降为10.2 MB,计算量为1.0×1010,添加CBAM注意力机制和DIoU-NMS替换NMS进行优化后模型大小为8.4 MB,计算量为9.6×109,模型大小为YOLOv5s的60%,计算量为YOLOv5s的58%,mAP仅下降了1个百分点,仅通过跟教师模型学习mAP和YOLOv5s相差0.5 个百分点,但再加上和真实标签比对学习后获得的最终模型YOLO-M3 的mAP 仅比YOLOv5s 相差了0.1个百分点,召回率和YOLOv5s 相等,由此可知,通过改进,在大幅度减少计算量、参数量和模型大小的情况下也保证了较高的mAP。
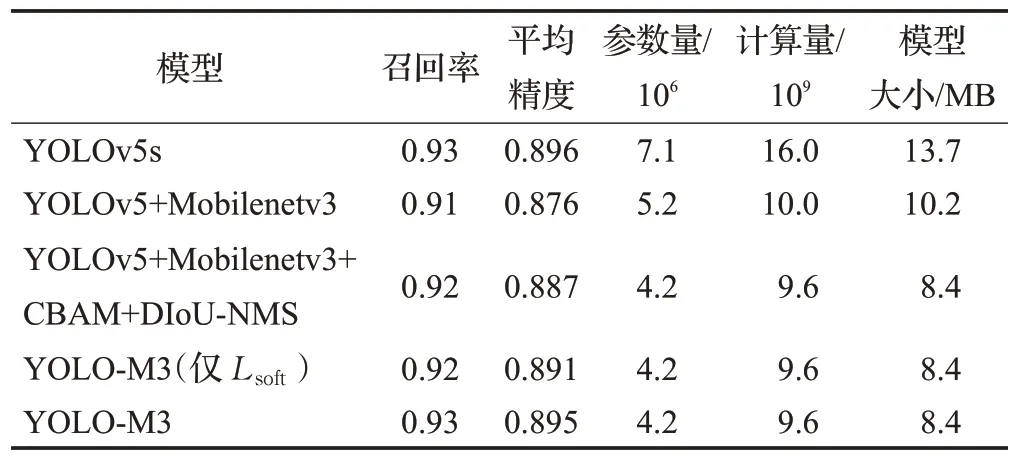
表2 改进过程的对比实验结果Table 2 Comparative experimental results of improvement process
YOLO-M3 和YOLOv5s 对安全帽数据集训练结果的平均精度和召回率的曲线图如图9所示。
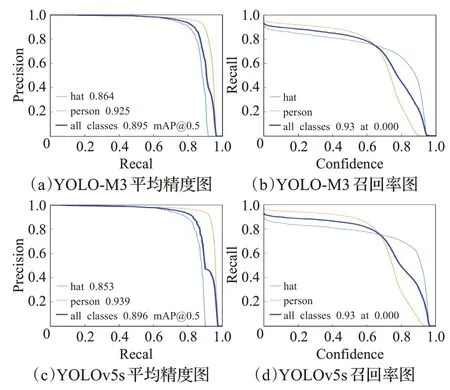
图9 YOLO-M3和YOLOv5s的训练结果Fig.9 Training results of YOLO-M3 and YOLOv5s
另外,为了更直观地感受改进算法和YOLOv5s 的检测区别,选取了密集目标和光线不好的情况图像来进行检测对比,结果如图10和图11所示。

图10 YOLO-M3检测结果Fig.10 YOLO-M3 test results

图11 YOLOv5s检测结果Fig.11 YOLOv5s test results
由检测结果可知,YOLO-M3 对于遮挡目标有较好的检测精度,且多数目标识别的准确度高于YOLOv5s,且在光线不佳的情况下,YOLO-M 的识别精度优于YOLOv5s,由此可知,本文改进的YOLO-M算法在大幅度降低参数量和计算量的同时,保持了较高的精度,且对遮挡目标有较高的辨别度,达到了需要的效果。
3.3 YOLO-M3与其他算法的对比
将YOLO-M3与其他主流算法相比较,来对YOLOM3 的性能进行分析,进一步证明检验YOLO-M3 的优越性和可行性,实验结果如表3所示。
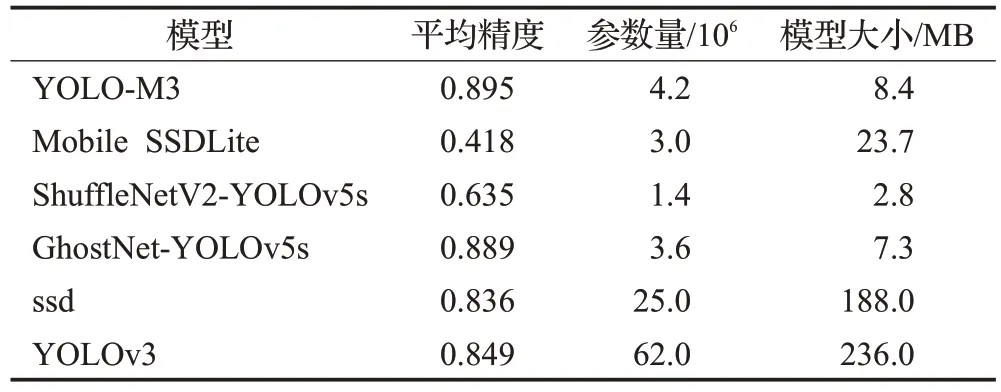
表3 YOLO-M3与其他算法对比实验结果Table 3 Comparitive experimental results between YOLO-M3 and other algorithms
由实验结果知,与Mobile SSDLite[15]相比,YOLOM3大幅度降低模型大小的情况下,平均精度提升了47.7个百分点;相较于ShuffleNetV2-YOLOv5s 和GhostNet-YOLOv5s,YOLO-M3 模型大小和参数量稍大,但平均精度分别提高了24.3 个百分点和0.6 个百分点;与主流检测网络模型SSD 和YOLOv3 相比,YOLO-M3 的模型大小和参数量都有大幅度的降低,平均精度显著提高,相较于现阶段基于轻量级改进算法和主流检测算法,YOLO-M3 具有较好的性能,达到了减小参数量和模型大小的同时,保持较好的平均精度的效果。
4 结束语
由于现有的对安全帽佩戴检测算法的参数量和计算量较大,不利于在嵌入式等设备进行部署,且对遮挡目标辨别度差,针对现有技术的缺点、不足之处,本文对YOLOv5 网络进行了轻量化的改进,首次将Mobile-NetV3 和YOLOv5s 相结合进行轻量化的方法运用到安全帽佩戴的检测,且添加CBAM 注意力机制和DIoUNMS 来优化提取效果和提高对遮挡目标的辨识度,并在对模型知识蒸馏的过程中,除了与复杂教师网络模型学习外,还与真实标签做对比,有效阻止了教师网络中的错误信息被蒸馏到轻量级网络中,使轻量级模型具有更强的学习能力。实验结果表明,改进后的模型提高了对遮挡目标的辨识度,且在保持了较高的平均精度的同时,模型大小、参数量和计算量大幅度的降低,满足了在嵌入式端等设备部署的要求。
猜你喜欢
机电安全(2022年4期)2022-08-27
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
课外生活·趣知识(2019年4期)2019-09-10
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
今古传奇·故事版(2017年5期)2017-04-08
第二课堂(课外活动版)(2016年2期)2016-10-21
