
结合注意力机制的知识感知推荐算法
2022-05-15 06:35刘思远徐雁翎
计算机工程与应用 2022年9期
张 昕,刘思远,徐雁翎
辽宁大学 信息学院,沈阳110036
项目推荐是最有效的也是应用最广泛的信息过滤和信息发现的方法之一。目前为了满足用户个性化兴趣的推荐系统已经投入了大量的研究。在典型的推荐方法中,基于协同过滤[1]的方法利用用户的历史偏好,取得了显著的成效。但是推荐系统普遍面临两个问题:一是用户-项目矩阵通常是非常稀疏的,即数据稀疏性问题;二是对于新加入推荐系统的用户与项目,由于没有其历史交互信息所以无法对其进行建模与推荐,即冷启动问题。协同过滤方法在数据稀疏以及冷启动的情况下效果相对较差。解决此问题的一个常见思路是导入辅助信息,丰富推荐系统中对于用户与项目的描述,从而有效弥补用户兴趣的稀疏或缺失。在各类辅助信息(如用户概况[2]、社交网络、图像等)中,知识图谱作为一种新兴的辅助信息,其中包含大量的结构化数据[3],近年来逐渐受到研究者的关注。
知识图谱是由大量的实体和关系组成的多关系有向图。更具体地说,知识图谱中的每条边都以(头实体、关系,尾实体)的形式表示为一个三元组,也称为事实、头实体与尾实体通过关系连接。近年来,大量的知识图谱如Google 知识图谱、DBpedia 和Microsoft 的Satori 被创建并成功地应用于许多场景中,例如知识图谱补全[4]、知识问答、词嵌入[5]、文本分类等诸多领域,在推荐系统中也得到了广泛应用。图1 所示为电影推荐的典型场景,其中《霸王别姬》《建党伟业》《无问西东》三部影片为用户的观看记录,根据知识图谱可以得知影片的导演、类型和主演分别是“陈凯歌”“爱情”和“刘烨”,随后就可以向用户推荐陈凯歌导演,刘烨主演的“无极”和同样是爱情类型的电影“怦然心动”。
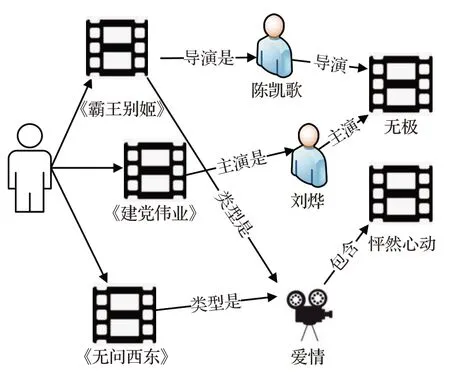
图1 知识图谱在电影推荐中的应用Fig.1 Application of knowledge graph in movie recommendation
利用知识图谱来提高推荐系统的性能,也称作知识感知推荐,在一定程度上解决了推荐系统的数据稀疏性以及冷启动问题。传统的推荐算法利用项目属性信息来缓解冷启动问题,而知识图谱可以看成是对于项目属性的拓展,具有更高维度的语义信息[6],可以更好地解决冷启动问题;对于数据稀疏性问题,引入知识图谱后所关注的不再是整个用户-项目矩阵,而是与用户交互的项目在知识图谱中通过实体传播得到的实体,从而解决数据稀疏性问题。除此之外,知识感知推荐的优势还包括:(1)知识图谱引入了项目之间的语义关联,有助于发现项目之间的潜在关系,提高推荐的准确性;(2)知识图谱包含各种类型的关系,有助于合理地扩展用户的兴趣,增加推荐的多样性;(3)知识图谱将用户的历史记录与推荐的项目连接起来,为推荐系统带来了可解释性。
一般来说,现有的知识感知推荐算法可分为两类:
一类是基于嵌入的方法,使用知识图谱嵌入(KGE)算法对一个知识图谱进行预处理,并将学到的实体嵌入到一个推荐框架中。例如,协同知识库嵌入(CKE)[7]将CF 模块与知识嵌入、文本嵌入和项目的图像嵌入结合在一个贝叶斯框架中。深度知识感知网络(deep knowledge-aware network,DKN)[8]将实体嵌入和词嵌入作为两个不同的模块,然后设计一个CNN 框架将它们组合在一起进行新闻推荐。融合循环知识图谱和协同过滤电影推荐算法[9]将协同过滤与循环知识图谱嵌入相结合进行电影推荐。但是这些方法中采用的知识图谱嵌入算法学习到的嵌入对于表示项目间的关系不太直观和有效。
另一类是基于路径的方法,通过探索知识图谱与项目之间的各种连接模式,为推荐提供额外的信息。例如,个性化实体推荐(PER)[10]将知识图谱视为异构信息网络(HIN),提取基于元路径/元图的潜在特征来表示用户与项目之间沿不同类型关系路径/图的连通性。Luo等人研究了一种基于社交网络的推荐算法Hete-CF[11],该算法通过基于元路径的相似性对用户-项目、用户-用户和项目-项目进行建模。基于路径的方法以更自然、更直观的方式使用知识图谱,但是这些方法效果的好坏很大程度上取决于人工设计的元路径的质量和数量,而这又需要领域知识。这在很大程度上限制了这些方法生成高质量推荐的能力。
针对现有推荐算法的局限性,本文提出了一种新的推荐模型——结合注意力机制的知识感知推荐算法。该算法的关键思想是应用注意力机制获取偏好传播,旨在预测用户对项目的点击率,以用户与项目的交互和知识图谱作为输入,并输出用户参与该项目(例如,点击、浏览)的概率。对于每个用户,将其历史兴趣作为知识图谱的中心,然后沿着知识图谱逐层向外扩展。对于知识图谱的每一层使用注意力机制研究每个实体的重要性,以此获取用户对不同项目的兴趣,从而更好地预测点击率。
综上所述本文的贡献如下:
(1)在知识感知推荐算法中同时结合了基于嵌入和基于路径的方法。使用知识图谱嵌入的同时无需任何人工设计,可以自动发现从用户历史记录中的项目到候选项的路径。
(2)应用了注意力机制为合并到推荐系统中的实体赋予不同的重要性。
(3)给出一个将知识图谱作为辅助信息引入到推荐系统的端到端框架。
1 相关工作
1.1 知识图谱嵌入
知识图谱嵌入是将知识图谱中的实体与关系嵌入到低维连续的向量空间中,并且保持知识图谱的固有结构。知识图谱嵌入的方法可分为两类:(1)基于平移的嵌入方法(如TransE[12]、TransH[13]、TransR 等),其中TransE是最具代表性的方法之一,将实体和关系都表示为同一空间中的向量,其基本思想是使头实体的嵌入与关系嵌入的和尽可能的接近尾实体的嵌入。(2)语义匹配模型,例如Co-mplEx[14]和RESCAL[15],通过匹配实体和关系的潜在语义来衡量知识图谱三元组的合理性。例如,RESCAL 将关系表示为满秩矩阵的形式,由于实体与关系之间都为矩阵运算,所以实体与关系的信息可以进行深层次的交互。但是这些方法更适合图文应用,例如链接预测。本文方法在推荐的同时进行了嵌入,可以看作是一种特殊设计的知识图谱嵌入方法,能够更好地服务于推荐。
1.2 注意力机制
注意力机制与人类的视觉观察具有相同的特性,即人眼在感知外界事物时并不是从头到尾观察一遍,而是根据自身的需求关注该事物特定的一部分。注意力机制对数据的不同部分赋予不同的重要性,从而使人们能够专注于最重要的数据。起初引入注意力机制[16]是为了解决基于编解码器框架处理序列到序列的转换任务,由于其能够自动地发现输入数据的重点后来被广泛应用于机器翻译、统计学习和推荐系统[17]。本文使用注意力机制来探索输入项目、用户历史记录以及知识图谱中实体之间的关系。
1.3 问题公式化
在一个典型的推荐系统中,用户集和项目集分别表示为U={u1,u2,…}和V={v1,v2,…}。用户与项目的交互矩阵Y={yuv|u∈U,v∈V},其中:

若yuv的值为1,则表示用户u与项目v之间存在交互,如点击、观看、浏览等行为。值得注意的是本文在推荐中使用的是隐式反馈,即通过用户行为间接的反应用户偏好。Y中的值为1 仅表示已观察到用户与相应项目之间的交互,尽管此类交互不能确保用户真正喜欢该项目,但它们是有关用户可能喜欢的信息的来源。同样,Y中的值为0并不表示用户对项目不感兴趣。在本文中,观察到的交互被视为模拟用户潜在兴趣的积极项目,而未观察到的交互被模拟为不感兴趣的消极项目。除了交互矩阵Y,已知内容还包括知识图谱G,它由大量的实体-关系-实体三元组(h,r,t) 组成。其中h∈E,r∈R,t∈E分别表示一个三元组的头实体、关系和尾实体,E和R表示知识图谱中实体和关系的集合。
在已知交互矩阵Y和知识图G的情况下,目标是学习一个CTR 预测模型,以预测用户u对每个输入项目v的点击概率。
2 推荐算法
2.1 整体框架
框架如图2 所示,将项目v、用户-项目交互以及知识图谱G作为输入。首先,根据用户u的历史点击项以及知识图谱根据本文的实体传播方法得到多个合并实体集。然后,将项目v和实体集中的实体进行嵌入,通过注意力机制得到基于注意力机制的用户表示。最后,使用用户u的最终表示u和项目v的嵌入v进行CTR预测。
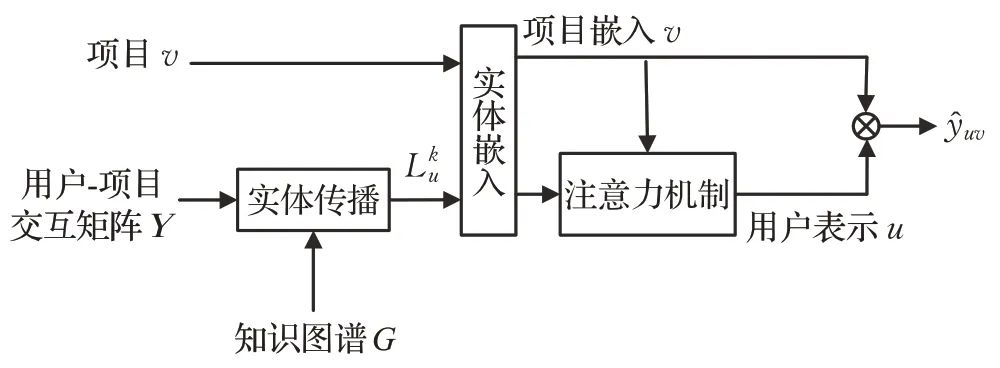
图2 框架图Fig.2 Frame diagram
2.2 实体传播
知识图谱包含各种实体以及实体之间复杂的关系,这些实体为探索用户兴趣提供了潜在的视角。然而对于特定的用户,所有的实体对于用户的偏好并不具有同等的重要性,并且有些实体与该用户是无关的(称为噪声)。为了降低噪声对于结果的影响,将用户点击历史中的实体合并到知识图谱中,使每个合并的实体都与用户相关。
实体传播过程如图3所示,将用户u点击的历史记录记为Lu={vu,1,…,vu,m,…,vu,|S|},其中vu,m代表用户u点击的第m个项目,则实体传播可以定义为:
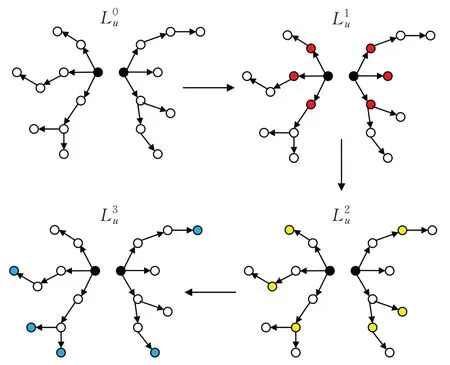
图3 实体传播Fig.3 Entity propagation
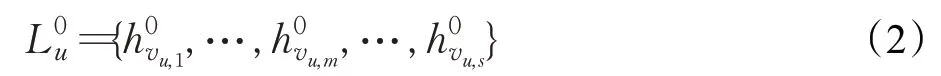
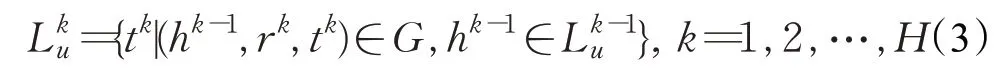
其中,H为最大传播次数,经过H次传播得到H+1 组相关实体。
实体集的大小可能随着跳数k的增加而变得越来越大,从而导致引入无关实体并且增大计算量。本文从以下几个方面解决该问题:(1)知识图谱中的大量实体它们只有传入链接但没有传出链接。(2)在诸如电影或书籍推荐的特定推荐场景中,关系可以限于与场景相关的类别,以减小实体集的大小并提高实体之间的相关性。(3)在实践中,最大跳数H通常不会太大,因为距离用户历史点击项太远的实体带来有用信息的同时也会产生更多的噪声。将在实验部分讨论H的选择。(4)在本文算法中设置固定大小的实体集,而不是使用完整的实体集,进一步减少计算开销。
2.3 基于注意力机制的用户表示
传统的推荐方法及其变体学习用户和项目的潜在表示,然后通过应用特定函数(例如内积)计算项目评分。在本文中,为了探索用户和项目之间的交互,提出了一种基于注意力机制的偏好传播方法,以获取用户的潜在兴趣。注意力机制可以描述为将query和key-value映射到输出。输出为value的加权和,其中分配给每个value的权重由query与key通过兼容性函数计算得到。
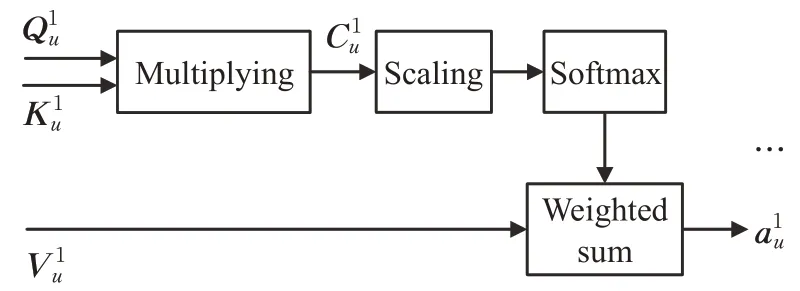
图4 基于注意力机制的用户表示Fig.4 User representation based on attention mechanism

然后通过softmax 函数对value进行加权求和得到用户对于项目v的一阶响应:
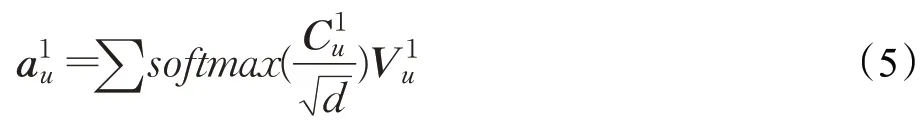
其中,softmax函数可以表示为:



2.4 学习算法
本文算法中使用知识图谱G和隐式反馈矩阵Y,学习目标是最大化模型参数Θ的后验概率:

其中,Θ包括所有实体、关系和项目的嵌入,则有:
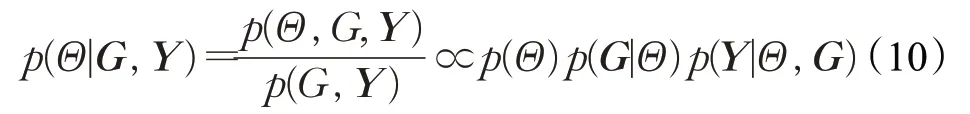
根据贝叶斯定理,在式(10)中,右侧第1项p(Θ)计算模型参数Θ的先验概率。根据文献[7],将p(Θ)设为具有零均值和对角协方差矩阵的高斯分布:

式(10)中右侧第2项是给定Θ计算知识图G的似然函数。在本文算法中,使用3阶张量分解方法来定义知识图谱嵌入的似然函数:
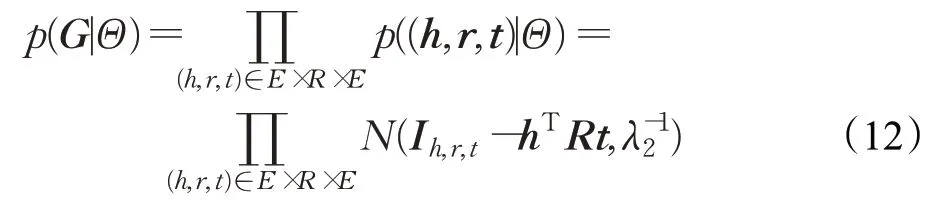
如果(h,r,t)∈G,则Ih,r,t等于1,否则为0。根据式(12),可以在同一计算模型下统一知识图谱嵌入中实体-实体对和项目-实体对在偏好传播中的得分函数。式(10)中右侧最后一项是给定Θ和知识图谱时得到的隐式反馈的似然函数,其定义为伯努利分布的乘积:
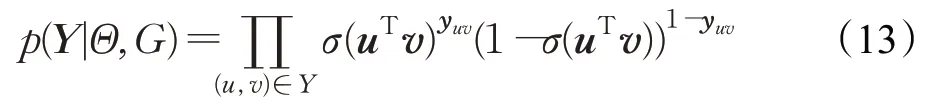
取式(10)的负对数,得到损失函数如下:
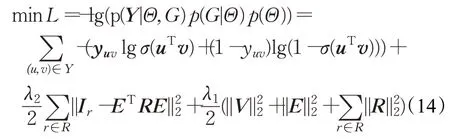
其中,V和E分别是所有项目和实体的嵌入矩阵,Ir是知识图谱中指标张量I对于关系r的切片,而R是关系r的嵌入矩阵。在式(14)中,第1项计算的是交互Y的正确标注数据和预测值之间的交叉熵损失,第2项计算知识图谱Ir的正确标注数据和重构的指标矩阵ETRE之间的平方误差,第3项计算的是用于防止过度拟合的正则化项。
本文采用随机梯度下降(SGD)算法来优化损失函数。在每次训练中,为了使计算效率更高,按照文献[18]中的负采样策略从Y中随机抽取1个小批量的正/负反馈,从G抽取1 个小批量的true/false 三元组。然后,针对模型参数Θ计算损失函数L的梯度,并基于采样的小批量数据通过反向传播更新所有参数。本文将在实验部分中讨论超参数的选择。
3 实验
本章给出算法在两个通用数据集上的实验结果,并与代表性推荐算法进行性能对比。首先介绍实验所用数据集、对比算法和相关参数设置,然后给出点击率预测以及top-K推荐在这两个推荐场景中的结果,最后讨论实验中超参数的选择。
3.1 数据集
本文选取2个通用数据集进行实验。其中MovieLens-1M数据集是电影推荐中广泛使用的数据集,由MovieLens网站上约1 000 000 个显式反馈(评级范围从1 到5)组成。Book-Crossing数据集包含了Book-Crossing社区中1 149 780个显式反馈(评级范围从0到10)组成。
由于MovieLens-1M 数据集和Book-Crossing 数据集对于电影与书籍的反馈都为显式反馈,本文将其转换为隐式反馈。对于用户已进行评级的电影或书籍(MovieLens-1M 数据集的评级阈值为4,Book-Crossing数据集考虑数据稀疏性不设置阈值)标记为1,并对相同数量的未评分电影进行采样,作为负(标记为0)的隐式反馈,然后使用用户和项目的ID嵌入作为原始输入。
本文所使用的知识图谱由文献[19]生成,MovieLens-1M 的知识图谱包含20 195 个三元组和12 种关系。Book-Crossing知识图谱表包含19 793个三元组和25种关系。由于过滤掉了知识图谱中没有相应实体的项目,因此用户,项目和交互的数量比原始数据集要少。表1为数据集预处理后的详细统计信息。
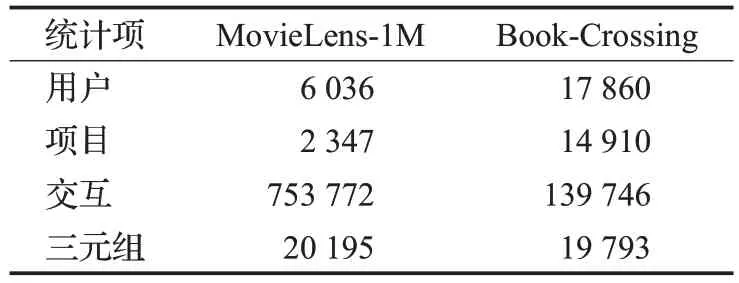
表1 数据集的详细统计数据Table 1 Detailed statistics of data set
3.2 对比算法
本文选取以下代表性算法进行对比:
(1)CKE将CF与结构知识、文本知识和图像知识结合在一个统一的贝叶斯框架中进行推荐。由于文本知识和视觉知识在本文中不可用,所以使用CKE 的CF+结构知识模块。
(2)DKN融合了实体嵌入和词嵌入,为每个输入新闻生成一个知识感知嵌入向量,然后对用户进行动态建模,其中电影和书籍的标题用于生成词嵌入,实体嵌入由TransH学习。
(3)PER 将知识图谱视为HIN(异构信息网络),并提取基于元路径的特征来表示用户和项目之间的连通性。在本文中使用PER的所有项-属性-项(例如“电影-导演-电影”)。
(4)LibFM[20]是CTR场景中广泛使用的基于特征的因式分解模型。本文将用户ID,商品ID 以及从TransR获得的实体嵌入结合起来,作为LibFM的输入。
(5)Wide&Deep[21]是一个通用的深度推荐模型,将线性通道(Wide)与非线性通道(Deep)结合使用。与LibFM类似,本文将用户ID、项目ID和TransR学到的项目嵌入结合起来作为Deep&Wide的输入。
3.3 参数设置
表2中给出了完整的超参数设置,其中d表示项目和知识图谱的嵌入维度,η表示学习率。通过优化验证集上的AUC来确定超参数。考虑到过高的跳数并不会进一步提高性能,且会产生更大的计算开销,本文实验中为MovieLens-1M 和Book-Crossing 两个数据集设置跳数分别为6 和4。为了公平考虑,所有对比算法的维度设置与表2中相同。

表2 数据集超参数设置Table 2 Data set hyperparameter settings
对于每个数据集,训练集和测试集的比例为8∶2。每个实验重复3次,并对结果取平均值。在两个实验场景中评估本文算法:(1)在点击率(CTR)预测中,将训练的模型应用于测试集中,并给出预测的点击概率。使用ACC和AUC来评估CTR预测的性能。(2)在top-K推荐中,使用训练模型为测试集中的每个用户选择具有最高点击概率的前K项,并选择Precision@K、Recall@K、F1@K这三个参数来评估推荐集。
3.4 对比结果
Top-K推荐的对比实验结果如图5 所示。其中图5(a)、(b)和(c)分别为MovieLens-1M数据集上Precision、Recall和F1的对比结果;图5(d)、(e)和(f)分别为Book-Crossing数据集上Precision、Recall和F1的对比结果。
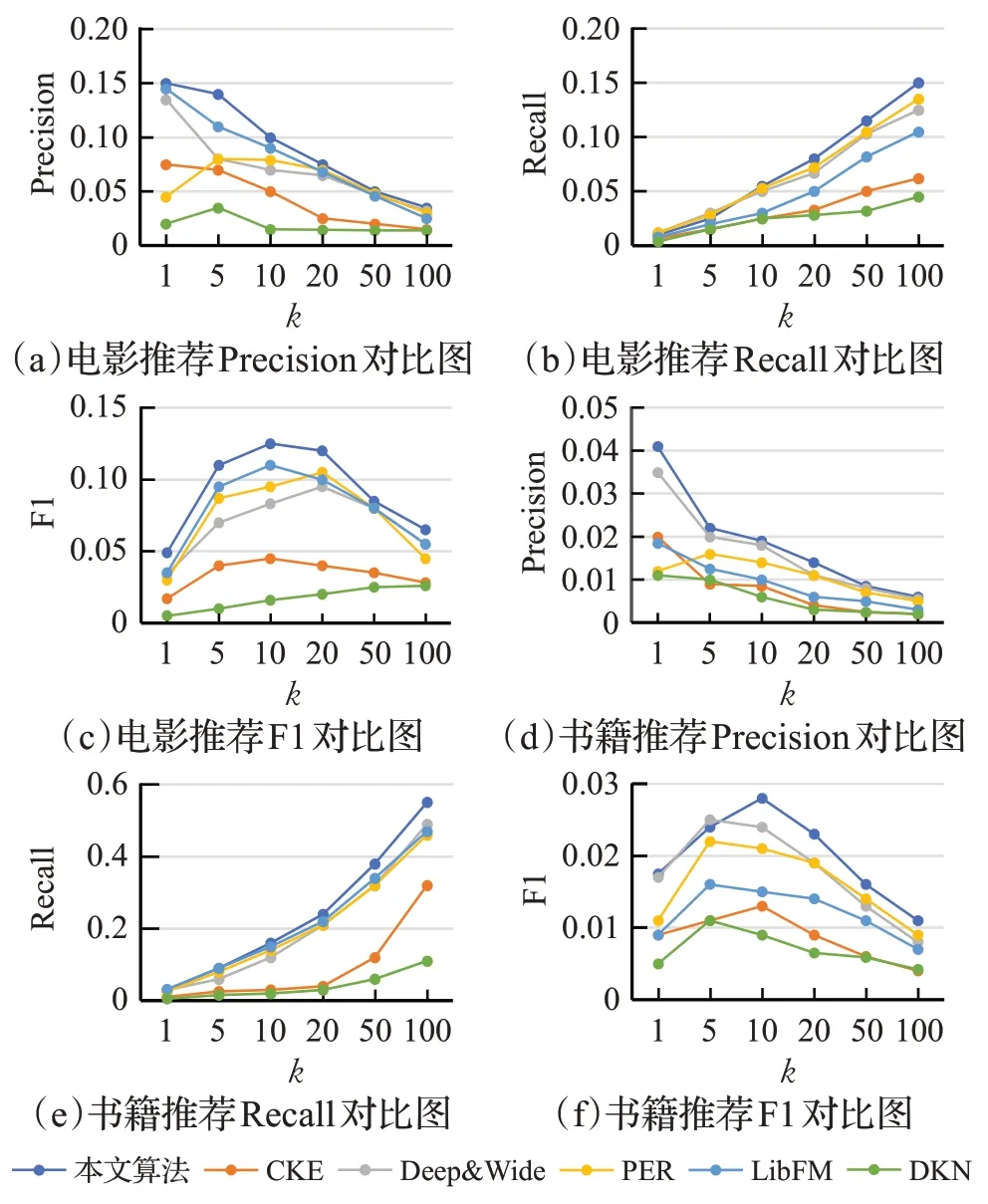
图5 Top-K推荐对比结果Fig.5 Top-K recommendation comparison results
由图5所示对比结果可以看出:
(1)CKE 的表现比其他算法差,这可能是因为只输入了结构知识,没有图像知识和文本知识输入。
(2)DKN 与其他算法相比表现最差。这是因为电影和书名太短而且不明确,无法提供有用的信息。
(3)PER 的推荐结果表现不尽如人意,因为用户定义的元路径很难达到最佳。
(4)作为两种通用推荐工具,LibFM和Wide&Deep都表现出了令人满意的性能,表明可以很好地利用知识图谱的知识来实现他们的算法。
CTR预测的对比实验结果如表3所示,本文算法在两个数据集的所有评估方法中表现最佳。具体来说,在电影推荐中,AUC 的性能比其他算法高出1.1%至27.8%,在书籍推荐中高出2.5%至13.8%。
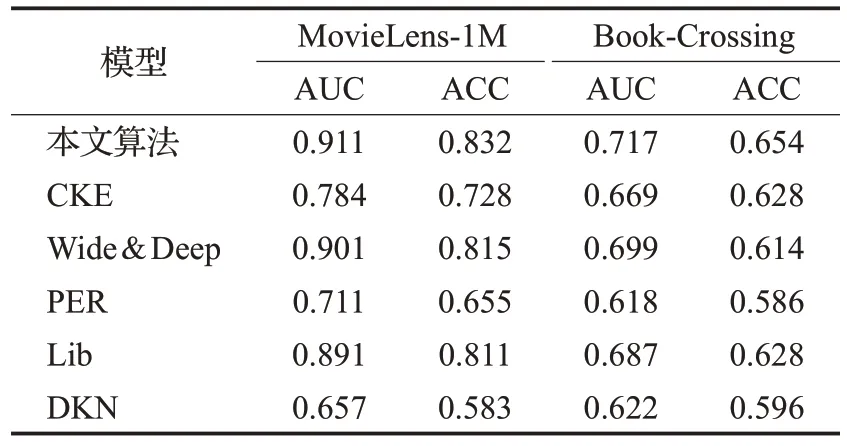
表3 CTR预测对比结果Table 3 Comparison results of CTR prediction
通过在实验中改变知识图谱中每一跳实体集数量及跳数,以进一步分析对本文算法性能的影响。在两个数据集上不同跳数下AUC 的实验结果如表4 所示。可以看出当H为4 或6 时,本文方法可以获得最佳性能。这是由于知识图谱中与用户历史点击项距离跳数越多的实体与用户的相关性越低。但是当跳数太小时则很难从知识图谱中获取额外的信息。
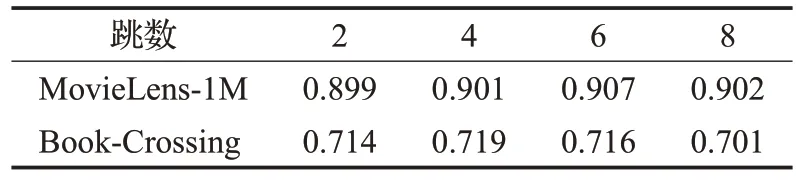
表4 跳数对AUC结果的影响Table 4 Impact of hop count on AUC results
在两个数据集上不同实体集数量下AUC的实验结果如表5 所示,可以观察到随着实体集数量的增加,算法的性能首先得到提升,因为更大的实体集可以从知识图谱中获得更多的知识。但是,当数量进一步增加时性能会下降,因为过多的实体集可能会带来无关信息。实验结果表明实体集数量为32时算法能够获得最佳性能。
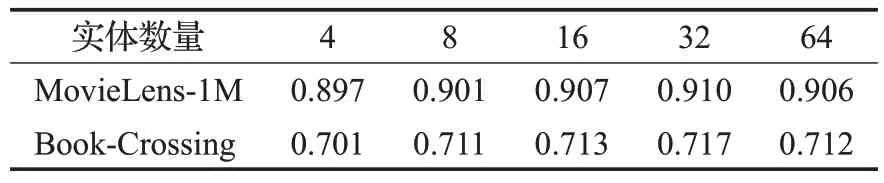
表5 每跳实体集中实体数量对AUC结果的影响Table 5 Impact of number of entities in each hop entity concentration on AUC results
3.5 参数灵敏度
在实验中改变参数d和λ2,分析其对算法性能的影响。将d从2逐渐调整到64,将λ2从0调整到0.5,同时保持其他参数不变。MovieLens-1M 上的AUC 的结果如图6 所示。由图中可以观察到,随着d的增加,性能首先得到提升,因为具有较大维度的嵌入可以编码更多有用的信息。可能由于过度拟合,在d=16 之后性能下降。由图6(b)中可以看出,当λ2=0.01 时,算法可以获得最佳性能。这是因为具有较小权重的KGE项不能提供足够的正则化约束,而较大的权重会误导目标数。

图6 超参数对于实验结果的影响Fig.6 Influence of hyperparameters on experimental results
4 总结及展望
本文提出了一种基于注意力机制的知识感知推荐算法,通过结合知识图谱中的实体来推断用户的潜在兴趣,从而解决推荐系统中的数据稀疏性和冷启动问题。算法首先通过用户的历史记录在知识图谱中扩展出的实体作为外部知识,然后通过注意力机制计算给定的用户-项目对的CTR 预测,最后形成端到端的推荐框架。通过在两个公共数据集上进行对比实验,表明本文方法相比于现有典型推荐方法,在评估指标(例如AUC、ACC 和Recall@top-K)方面取得了显著的进步。在未来,计划进一步评估模型在更多数据集上的可行性,并在改进本文嵌入方法的同时将知识图谱补全引入到模型中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少先队活动(2020年12期)2021-01-14
甘肃教育(2020年22期)2020-04-13
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
第二课堂(课外活动版)(2016年2期)2016-10-21
领导科学论坛(2016年9期)2016-06-05
