
基于文本相似度的简历匹配推荐算法研究
2022-05-14 11:45施元鹏单剑峰
计算机仿真 2022年4期
施元鹏,单剑峰
(南京邮电大学电子与光学工程学院与微电子学院,江苏 南京 210046)
1 引言
随着移动互联网时代的蓬勃发展,传统的线下招聘方式正在慢慢淡出人们的视线,取而代之的是信息量巨大的互联网招聘。互联网招聘模式有着覆盖率广、处理效率较高、成本低的优势,因此受到许多招聘企业雇主的青睐。依据艾瑞咨询2020年发布的中国网络招聘市场发展研究报告可知,2019年网络招聘的企业雇主数量已经达到了486.6万家[1],招聘用户的规模更是达到2亿。因此,求职者需要浏览大量的招聘信息才能做出优质的选择。实现一个简历和岗位信息之间的相互匹配,能够更好的帮助求职者筛选出合适岗位信息。
目前,在招聘领域比较常见的推荐算法为:基于内容的推荐算法、基于协同过滤的推荐算法和混合模型的推荐算法等[2]。文献[3]是一种基于内容的推荐算法,该算法通过闵可夫斯基距离进行研究,实现人员与岗位之间的匹配。文献[4]为基于内容的个性化推荐,作者通过一种新的无监督贝叶斯多视图模型来实现人员技能和工作需求之间的匹配。文献[5]提出了一种个性化偏好的协同过滤推荐算法,根据毕业生的成绩与毕业生的个人偏好相结合,来进行职位推荐。文献[6]利用了招聘职位与简历之间的基础信息进行相似度计算然后推荐。以上文献的研究主要通过求职者的技能、成绩、学历、专业等数据来实现推荐,对于求职者的工作经验、项目经验等文本信息缺少提取,而这些信息往往又是企业招聘时所看重的,因此在实际应用中并不太适用。文献[7]提出了一种可解释的混合型就业推荐算法,利用TF-IDF的方法进行文本的信息提取,建立职位关系来实现就业推荐。由于TF-IDF的方法主要是通过词频的方式进行特征提取,缺少语义信息,因此导致简历和岗位之间相似度计算的准确率并不高。随着人工智能自然语言处理(NLP)领域的发展,研究者Tomas Mikolov在2013年提出了word2vec的方法很好的解决了词与词之间的语义特性[8]。文献[9]就是基于word2vec的方法处理简历与岗位的长文本信息,并对IT行业的简历进行个性化推荐。
本文是基于机器学习模型doc2vec来进行研究。将数据文本划分为:结构化和非结构化文本。在结构化文本中,提出了偏好权重因子α来平衡求职者和企业之间由于不同因素带来的相似度计算偏差。在非结构文本中,利用机器学习doc2vec算法来解决简历与岗位信息之间的长文本信息匹配,并利用参数χ对其相似度结果进行优化,解决doc2vec缺乏考虑文本长度的问题。相比于word2vec,doc2vec的方法能更好的处理句子及段落之间的语义相似性。
2 相似度算法相关介绍
2.1 余弦相似度
余弦相似度可以反应两个数据之间的相似性。在文本数据领域中,可以通过文本之间对应的词向量特征值集合来计算相似度[10-11]。若计算值越高,则表示两个文本越相似,余弦相似度的计算式(1)如下
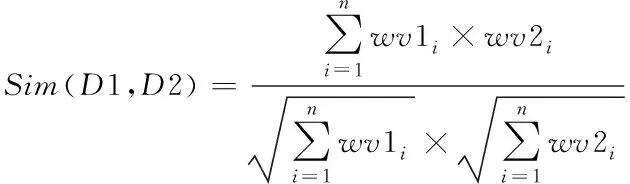
(1)
其中wv1i、wv2i分别表示文本D1、D2的特征向量分量。
2.2 Doc2vec介绍
Doc2vec(Paragraph Vector、Sentence Embeddings)是一种无监督式的神经网络算法,由Mikolov和Le基于word2vec模型的思想上提出[12]。Word2vec在预测词向量时,预测出来的词通常是具有词义的。例如,词向量‘工作’会相对于‘桌子’离‘上班’距离更近,即词向量‘工作’与‘上班’更相似。因此,这种方法克服了传统词袋模型缺乏语义的问题。
Doc2vec训练段落向量的方法和word2vec训练词向量的方法大体相同。不同之处在于,doc2vec在输入层会多添加一个可以被看作是段落主旨的段落向量(Paragraph vector),并且它会作为输入的一部分来进行训练。该模型有两种不同的训练方式,一种是PV-DM(Distributed Memory Model of paragraph vectors),即预测一个单词是通过上下文的单词来实现,另一种是PV-DBOW(Distributed Bag of Words of paragraph vector),即通过一个单词来预测上下文的单词。本文主要通过PV-DM的方法来实现文本相似度计算,下面是关于PV-DM原理的讲述。
如图1所示,在doc2vec中,每个单词被映射到唯一的向量上,表示为矩阵W中的某一列。段落也同样被映射到一个唯一的向量上,由矩阵D的某一列来表示。每次从一句话中提取若干个词,将其中的一个词作为预测词,其它词作为输入词。然后将输入词的词向量和本段话的段落向量作为输入层的输入,通过向量的加权计算得到预测词的词向量。经过这样多次滑动采样,词向量的表达会越来越准确。
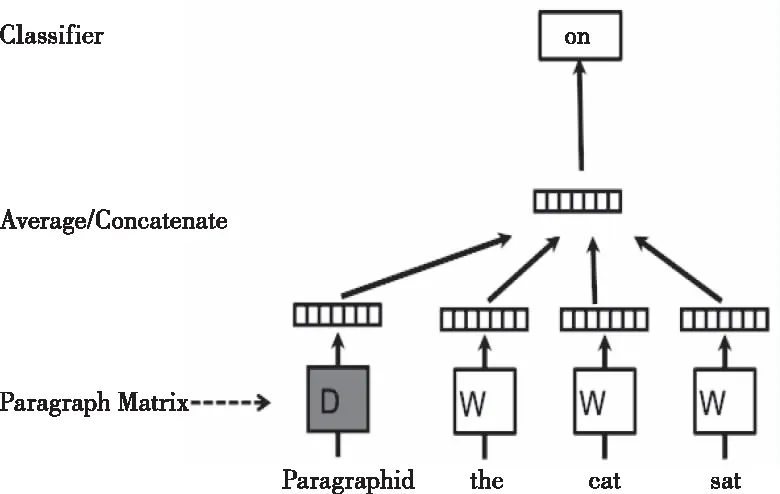
图1 PV-DM原理
通过多次对同一段落不同句子的训练,段落向量也会趋向稳定,即段落表达的主旨也会越来越明确。需要注意的是,训练出来的段落向量仅在本段落中有效,而词向量是在所有的文本中都有效的。所以在预测新的段落时,模型中的词向量以及映射层到输出层的softmax 权重参数是不变的,只需将段落向量进行随机初始化再放入模型中,并在不断迭代的过程中更新paragraph vector参数就能计算出一个稳定的段落向量。
总结以上整个doc2vec模型的过程,主要为两部分:
1)训练模型,在数据集上进行训练并得到词向量、softmax权重参数。
2)预测段落向量,首先根据新段落中的词得到相应的词向量,通过其词向量、softmax权重参数以及随机初始化的段落向量,在模型中不断迭代更新段落向量,最终得到新段落的向量。
3 简历相似度匹配方法
在电子简历中通常会包含许多的文本信息,例如个人基本信息、学历、期望薪资、工作经历等不同类型的文本数据,需要分别对其做不同的特征处理。文本数据的处理及匹配条件见表1。

表1 简历文本数据的分类及处理
简历和岗位信息中的数据主要分为结构化文本数据、非结构化文本数据。在结构化文本数据中,定类数据通过判断是否相等或包含来判断,对于定序数据,首先进行特征处理,再来判断其是否满足条件,对于定距/定比数据直接通过其大小来判断。简历文本相似度匹配推荐算法模型见图2。

图2 简历文本相似度匹配推荐算法模型
3.1 结构化文本的相似度计算
根据上面所述的数据类型,主要考虑的因素为7类:城市、职位、薪资、工作性质、学历、工作年限、专业之间的匹配,即符合匹配条件的为1,反之为0。匹配条件如(2)式
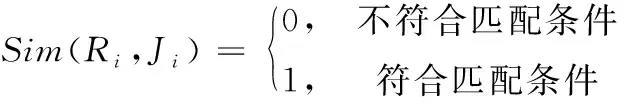
(2)
其中,i∈{1,2,3,4,5,6,7},分别对应城市、职位、薪资、工作性质、学历、工作年限、专业。
将城市、职位、薪资、工作性质划入为用户偏好型因素,将专业、工作年限、学历划入为企业偏好型因素。用λi来表示各类因素之间的权重,用户偏好型和企业偏好型的相似度计算公式分别为式(3)和式(4)
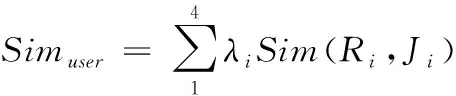
(3)
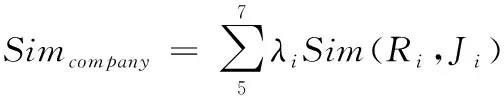
(4)
由于权重λi的不同,导致计算出来的相似度过于偏向用户或者企业问题。通过偏好权重因子α来平衡之间的关系。改进后的结构化文本相似度计算公式为
Simstructured(R,J)=αSimuser+(1-α)Simcompany
(5)
3.2 非结构化文本相似度计算
非结构化文本主要指简历中的项目经历、工作经验等长文本数据与岗位信息中的岗位要求/职责的长文本数据。通过jieba和哈工大的停用词表对其进行分词和去停词,再利用2.2章节中介绍的doc2vec训练得到段落向量,最后计算两者的相似性,相似度计算公式如式(6)所示
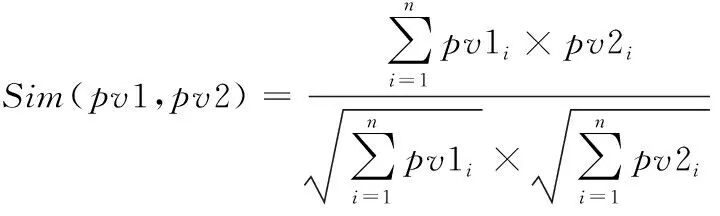
(6)
其中,pv1、pv2分别表示不同的段落向量,pv1i、pv2i表示向量pv1、pv2的分量。
由于段落向量长度是相同的,它取决于训练doc2vec模型中的vector_size参数,因此,在利用doc2vec计算相似性的情况下,缺少考虑段落长度的差异性对相似度计算的影响。文献[13]在计算句子相似度时同样考虑了句长的特性,并取得较好的结果。本文利用参数χ进行修正:
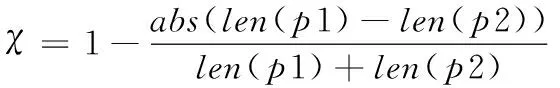
(7)
abs()为绝对值函数,用于计算段落1(p1)和段落2(p2)之间词个数的差异。当段落长度差异越大,χ就越小,段落长度十分接近时,χ接近于1。改进后,两个段落的相似度计算公式如下

(8)
综合以上结构化与非结构化数据的相似度方法,得出整个模型的相似度表达式
Sim(R,J)=Simstructured(R,J)+Simunstructured(R,J)
(9)
4 实验及分析
4.1 实验数据及评价指标
本文的实验数据来源于智联招聘联合某大厂举办的数据挖掘比赛中的脱敏数据集。一共筛选出1825个用户与42690个岗位产生的60059条行为数据,并且每条行为数据都有用人单位对其简历的满意/不满意的反馈信息,将其看做简历与岗位符合匹配的标签。按照7:3的比列将其分为训练数据集和测试数据集,并进行5折交叉验证。
在实验的评测方面,根据TOP-n推荐的匹配结果,分别计算准确率、召回率、F1值。它们的计算公式分别如下
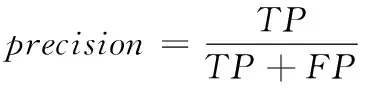
(10)
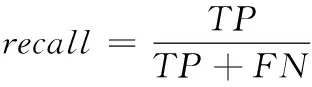
(11)
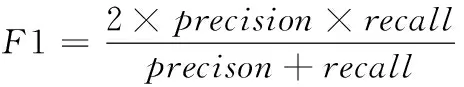
(12)
其中,TP表示TOP-n推荐中符合匹配的数目,FP表示TOP-n推荐不符合匹配的数目,FN表示没有被TOP-n推荐的符合匹配的数目。
4.2 实验步骤
Step1:对数据集的文本进行分类,并对各类数据进行特征处理,对非结构化文本进行分词、去停词。
Step2:划分数据集,对所有长文本中的词进行词向量训练。
Step3:选取合适的权重系数λi,并通过(5)式计算结构化文本的相似度。
Step4:利用doc2vec模型预测文本之间的段落向量,并通过(8)式计算之间相似度。
Step5:通过式(9)计算整体相似度,并根据其大小进行TOP排序推荐。
Step6:分别计算TOP-n的准确率、召回率、F1值及覆盖率。
Step7:改变训练集与测试集,重复5次step3-step6的过程。
Step8:统计5次实验的平均准确率、召回率及F1值。
4.3 实验结果及分析
本次实验的λi系数权重分别为[0.12,0.16,0.19,0.07,0.17,0.15,0.14],权重因子α与结构化文本相似度计算的平均准确率的关系如图3。
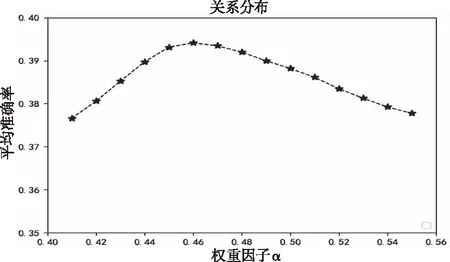
图3 α与平均准确率的关系
从图3可知,权重因子α=0.46时最佳。
为了验证doc2vec的有效性,本文与TF-IDF和word2vec的方法进行对比。抽取top-3、top-6、top-9来对比最终实验结果。
从表2可以看出无论是TOP-3、TOP-6、TOP-9进行推荐,doc2vec的各项指标都明显优于TF-IDF和word2vec的方法。
本文进行还通过参数修正后的doc2vec与word2vec(WMD)方法和原doc2vec之间的对比。其中,word2vec(WMD)是利用单词移动距离的方式来计算文本之间的相似度[14]。实验对比见表3。
从表3中可以看出,改进后的算法各项指标都优于word2vec(WMD)和doc2vec的方法。相比于dov2vec,各项指标也有一定的提升,并随着Top增加,提升更明显。特别是当Top增加到9时,F1值明显提高了2%左右。

表2 不同相似度算法的实验结果

表3 改进后doc2vec算法的实验结果对比
5 结束语
本文通过文本相似度计算的方法来实现简历与岗位之间的匹配,通过TOP-n的推荐来验证匹配的可行性,并与其它文本相似度计算方法进行比较。通过实验证明经过参数χ修正后的相似度计算方法比其它方法有更高的准确率、召回率和F1值。并且本文还通过α权重因子平衡求职者与企业之间的偏好关系,使得相似度的计算更优。同样,本文的方法有一定的局限性,词向量的训练是需要大量的样本,由于数据集中的样本数量有限,存在一些低频词的词向量精度不足的问题,对最后的匹配结果及指标也有一定影响。
猜你喜欢
小学阅读指南·低年级版(2022年5期)2022-05-09
新高考·高一数学(2022年3期)2022-04-28
课堂内外·好老师(2022年3期)2022-04-25
学习与科普(2022年17期)2022-04-23
云南教育·小学教师(2021年12期)2021-03-23
小学阅读指南·低年级版(2020年9期)2020-10-12
福建基础教育研究(2020年3期)2020-05-28
阅读(快乐英语高年级)(2020年9期)2020-01-08
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
