
基于随机森林算法的胰腺癌术后预测模型构建
2022-05-11 00:38:10李承圣包绮晗郝晓燕潘庆忠王素珍石福艳
吉林大学学报(医学版) 2022年2期
李承圣, 包绮晗, 郝晓燕, 潘庆忠, 王素珍, 石福艳
(1. 潍坊医学院公共卫生学院卫生统计学教研室,山东 潍坊 261053;2. 潍坊医学院护理学院内外科教研室,山东 潍坊 261053;3. 潍坊医学院公共卫生学院数学教研室,山东 潍坊 261053)
在世界范围内胰腺癌在癌症死亡原因中位居第7 位,在消化系统恶性肿瘤死亡原因中位居第2 位,每年死亡30 多万人[1]。2021年初由美国癌症学会公布的数据[2]显示:预计2021年美国新发胰腺癌病例60430 例,在男性新发恶性肿瘤中排名第10 位,女性中排名第8 位;预计死亡病例48220例,并居男性和女性恶性肿瘤死亡原因第4 位。全国肿瘤登记中心数据[3](基于2014年数据)显示:胰腺癌在我国恶性肿瘤发病率中排名第10 位,居恶性肿瘤死亡原因第6 位。胰腺导管腺癌(pancreatic ductal adenocarcinoma,PDAC)是最常见的胰腺癌类型,是一种由胰腺导管树分化而来的腺体浸润性肿瘤,占胰腺恶性肿瘤的95%以上[4],由于缺乏有效的辅助治疗手段,目前根治性手术(根治性胰十二指肠切除术等)是胰腺癌首选的治疗方案[4]。但由于胰腺癌自身的特殊解剖部位导致其发病隐匿且进程快,加之其对放化疗敏感性差,因此胰腺癌患者的预后极差,5年生存率仅为5%~10%[5]。因此,早期阶段的生存预后预测对于改善胰腺癌患者的预后生存状况极为重要。MAHAJAN 等[6]提出基于肿瘤的组织学特征对胰腺癌进行预后预测;循环肿瘤DNA 被建议作为预测和后续治疗转移性胰 腺 导 管 腺 癌 (metastatic pancreatic ductal adenocarcinoma,mPDAC)的工具[7];YU 等[8]发现基于外泌体内长链RNA 测序差异建立胰腺导管腺癌可切除阶段的诊断工具有助于改善胰腺癌患者预后;张峻烽等[9]通过加权基因共表达网络分析和单样本基因富集分析构建胰腺癌预后模型。目前,临床上用于胰腺癌诊断和预测预后的指标仍以癌抗原19-9(carbohydrate antigen 19-9,CA19-9)为主,但其灵敏度和特异度存在局限性,容易受到胆红素水平、炎症因子以及Lewis 抗原的影响[10]。因此,本研究旨在从美国国立癌症研究所监测、流行病学和结果数据库[11](Surveillance,Epidemiology,and End Results,SEER) 中获取胰腺癌的预后数据,基于随机森林算法构建胰腺癌术后预测模型,通过该模型对胰腺癌患者术后5年生存情况进行预测,以辅助临床医生改善胰腺癌患者的预后生存状况。
1 资料与方法
1.1 研究对象数据来自SEER 数据库。资料收集标准:2004—2015年被确诊为胰腺癌且5年内因癌细胞致死和随访期满5年仍存活的患者资料。纳入标准:①经病理学确诊为胰腺癌的患者;②组织学类型以国际肿瘤学疾病编码(Histologic Type ICD-O-3)为分类标准,将其限定在胰腺导管腺癌(8140、8480、8481、8490 和8500);③手术类型以原发部位手术信息[RX Summ-Surg Prim Site(1998+)]为分类标准,将其限定在根治性手术(25-90);④记录完整无空缺。排除标准:①胰腺癌并不是唯一的肿瘤;②非胰腺癌的原因死亡;③资料不完整及不明确。经过数据筛选最终纳入4020 条胰腺癌患者记录。见表1。

表1 胰腺癌患者预后变量信息Tab. 1 Prognostic variable information for pancreatic cancer patients (n=4020)
1.2 分析指标综合参考文献[12-14]和其他相关研究[15],共纳入年龄、性别、种族、肿瘤原发部位、肿瘤分化程度、是否化疗、是否放疗、淋巴结清扫数量、T 分期、N 分期、M 分期、婚姻状况、肿瘤大小和淋巴结阳性比率(淋巴结阳性比率=淋巴结阳性个数/被检淋巴结个数)14 个变量作为预后因素,其中后2 项为连续型变量,其余为离散型变量。胰腺癌患者预后变量信息见表1。
为了构建胰腺癌患者术后5年生存情况预测模型,根据5年生存状况将结局变量划分为二分类:生存时间≥60 个月者为存活编码为1,生存时间<60 个月者为死亡编码为0。
1.3 统计学分析采用R 4.0.5 软件的“caret”包的“createDataPartition”函数,按照7∶3 的比例将数据集随机划分为训练集和测试集。采用SPSS 21.0 统计软件进行数据的统计学分析,无序分类变量采用χ2检验,有序分类变量和连续型变量通过秩和检验进行2 组患者的预后因素比较。由于训练集中二分类结局变量存在明显不平衡,会降低模型的效能,故采用R4.0.5 软件的“DMwR”包的“SMOTE”函数解决结局变量不平衡问题。为提高模型的预测准确性,对训练集采用传统的统计学分析(单因素分析和多因素logistic 回归分析)同时对平衡后数据集采用随机森林变量重要性排名进行特征变量选择。 采用R 4.0.5 软件的“randomForest”包的“randomForest”函数基于平衡后的数据集构建随机森林预测模型。利用测试集评估预测模型效能,并与logistic 回归分析、支持向量机、决策树和人工神经网络算法进行比较。
2 结果
2.1 训练集和测试集患者预后因素经过数据集划分,最终纳入训练集患者2814 例,测试集患者1206 例。2 组预后因素比较差异无统计学意义(P>0.05)。见表2。
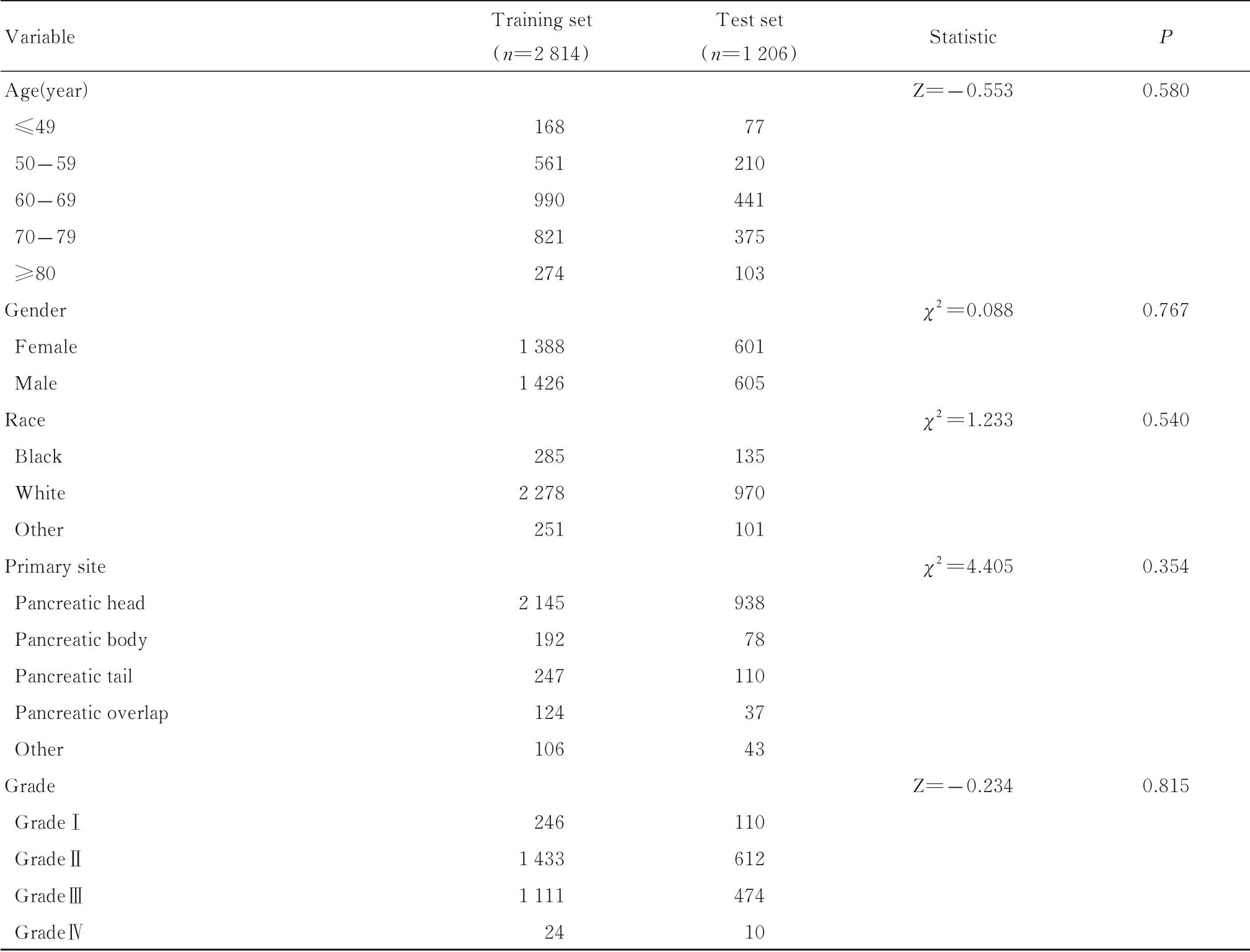
表2 训练集和测试集患者预后因素组间差异比较Tab. 2 Comparison of prognostic factors between training set and test set

续表
2.2 训练集的单因素分析训练集中的连续型变量 经 单 样 本Kolmogorov-Smirnov 检 验, 均P<0.05,不符合正态分布,因此对训练集中连续型变量采用秩和检验,而对分类变量采用χ2检验。表3为单因素分析结果。
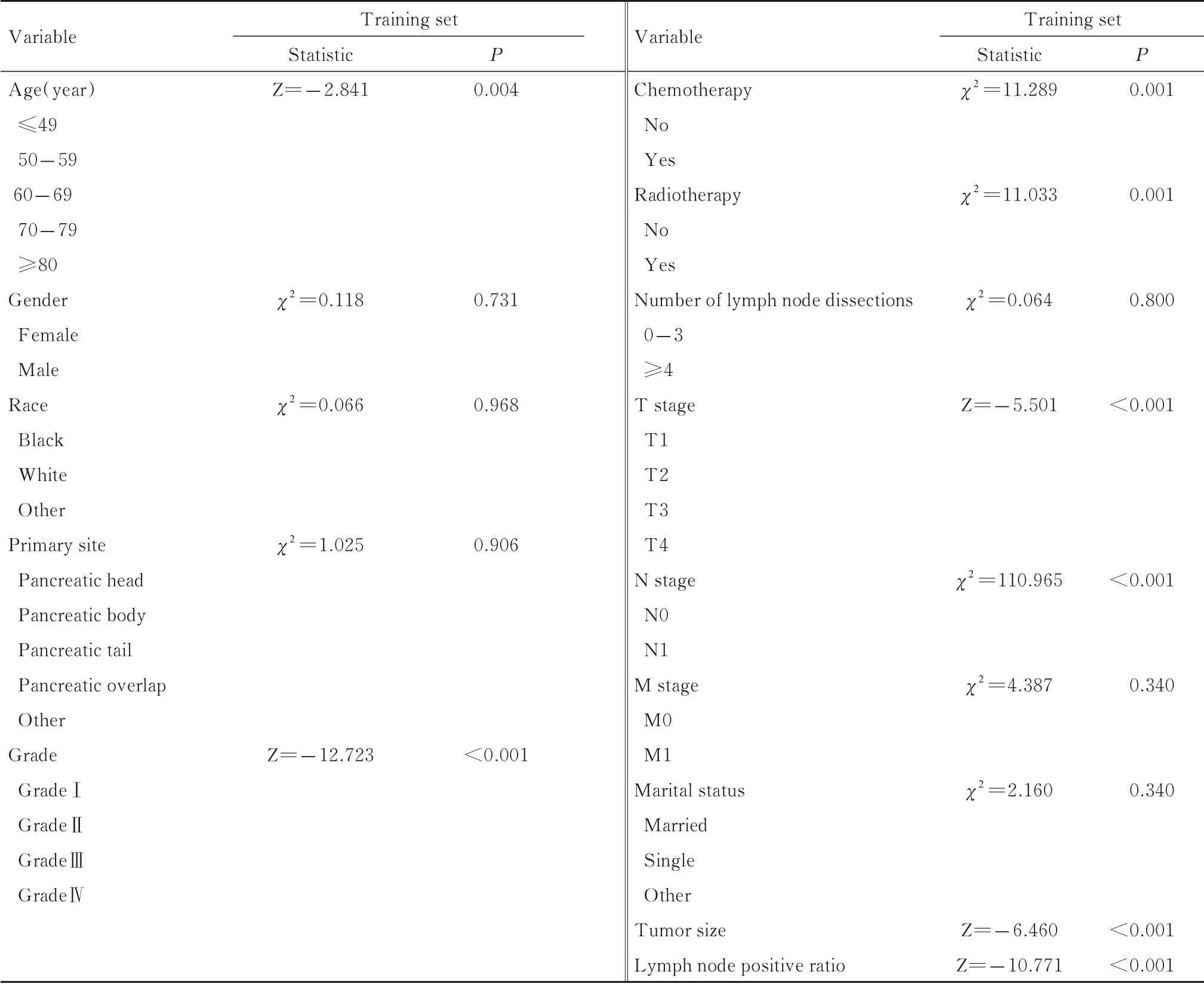
表3 训练集单因素分析结果Tab. 3 Single factor analysis results of training set
2.3 训练集的多因素分析训练集经单因素分析后,采用Logistic 回归分析进行多因素分析。纳入logistic 回归分析的变量有年龄、肿瘤分化程度、是否化疗、是否放疗、T 分期、N 分期、M 分期、肿瘤大小和淋巴结阳性比率。多因素分析结果显示:筛选出来的相关变量有肿瘤分化程度、是否化疗、是否放疗、T 分期、N 分期、肿瘤大小和淋巴结阳性比率。多因素分析结果见表4。

表4 训练集多因素Logistic 回归分析结果Tab. 4 Results of multivariate Logistic regression analysis of training set
2.4 SMOTE 数据集经过数据集划分后的训练集中有2814 个样本,其中少数类(存活=1,阳性样本)与多数类(死亡=0,阴性样本)样本的比例约为1∶13。因此,作为结局变量的生存状况存在二分类数据不平衡性,鉴于二分类数据集的不平衡性会影响机器学习建模的稳定性,本文采用合成少数样本过采样技术 (Synthetic Minority Oversampling Technique,SMOTE),以增加少数样本数量,达到数据类别间的平衡。
SMOTE 函 数 的2 个 参 数perc. over 和perc.under 会影响新生成数据集的样本量,perc.under 取值300 时会生成比例约为1∶3 的不平衡数据集,故perc. under 取 值 为100 或200[16]。为 了 尽 可 能 使 平衡数据集中多数类样本量不大于原始训练集中多数类样本量,当perc.under 取值为100 时,perc.over取值≤1300;当perc. under 取值为200 时,perc.over 取值≤600。根据上述参数取值,共生成19 个SMOTE 数据集,即平衡后数据集。
由于随机森林算法内部采用的是booststrap sample 采样方法,每次采样约有1/3 的样本不会出现在bootstrap 所采集的样本集合中,这些数据称为袋外数据(out-of-bag,OOB),OOB Error 就是随机森林泛化误差的一个无偏估计[17]。综合考虑阴性样本分类错误率、阳性样本分类错误率和袋外错误率,本研究选择SMOTE 数据集2 作为平衡后数据集进行后续随机森林算法建模。SMOTE 数据集信息见表5。
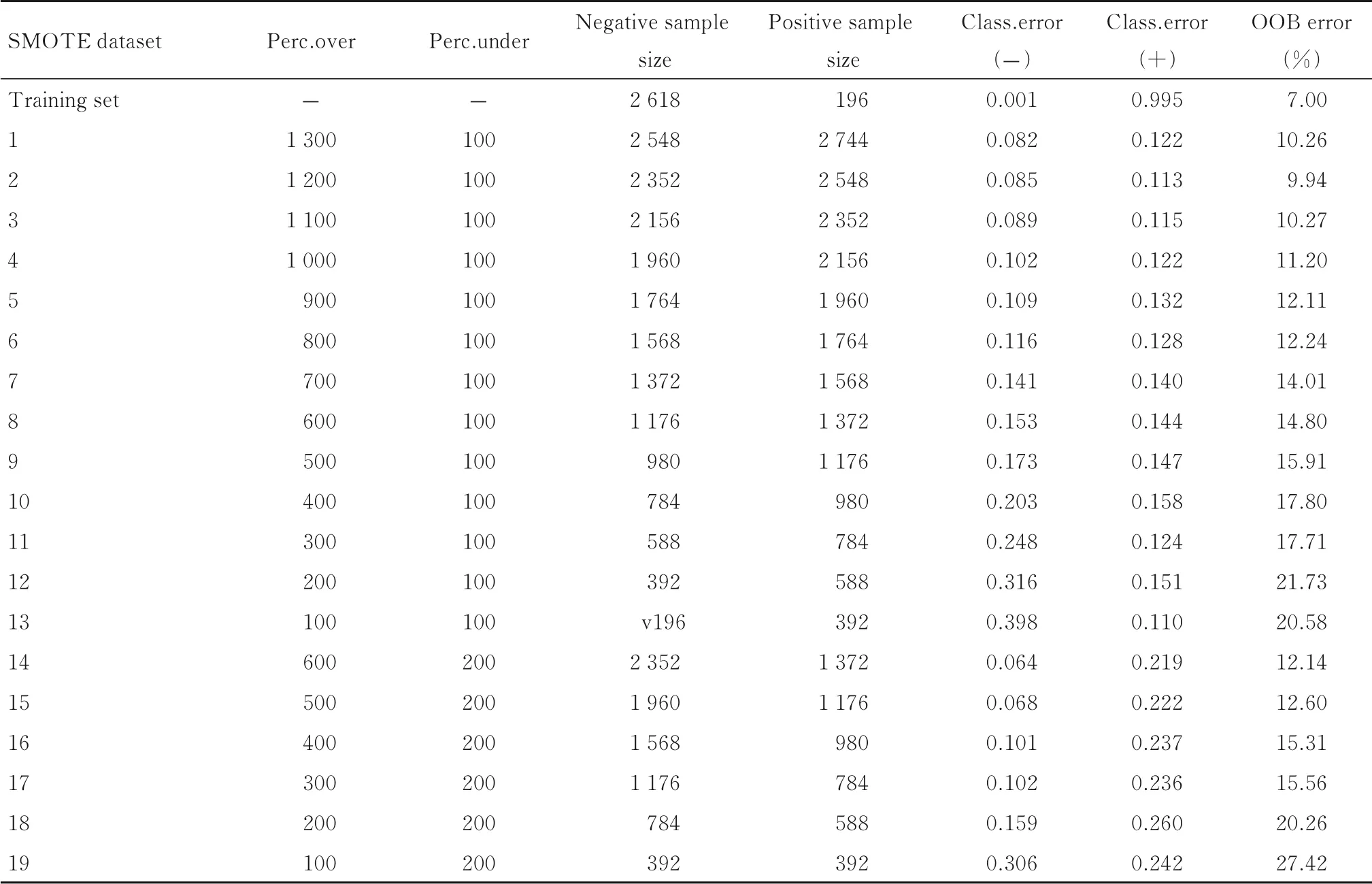
表5 SMOTE 数据集Tab. 5 SMOTE datasets
2.5 变量重要性排名基于平衡后数据集进行随机森林建模得到变量重要性排名,排序代表每个变量对模型的贡献大小。见表6。

表6 变量重要性排名Tab. 6 Ranking of importance of variables
多因素分析未纳入的变量年龄,在变量重要性排名中位次靠前,表明该变量对提升模型效能的作用较大,因此应纳入。“Mean Decrease Gini”代表使用某一个特征进行分裂时,GINI 系数下降的平均幅度,在特征类型(同时存在连续型变量和离散型变量)不一致以及特征变化范围相差较大时,结果的偏差明显,因此以基于OOB 误差的“Mean Decrease Accuracy” 为 主, 以 基 于 基 尼 系 数 的“Mean Decrease Gini”为辅,由于多因素分析结果为肿瘤分化程度、是否化疗、是否放疗、T 分期、N 分期、肿瘤大小和淋巴结阳性比率,最后选择排名在前11 位的变量作为相关变量。以此11 个变量为基础,依次减去排名最后的变量,构建不同模型,根据测试集上的模型效能确定最终高相关变量。
2.6 模型构建根据变量重要性排名在前11 位变量的基础上依次减去排名最后的变量生成4 个变量集,如下表7 所示。基于平衡后数据集,分别用4 个变量集构建随机森林模型,并用测试集对模型进行评估,评估指标为灵敏度、特异度、G-mean指数和受试者工作特征 (receiver operation characteristic, ROC) 曲 线 下 面 积(area under curve,AUC)。各模型评价指标结果见表7。

表7 各模型评价指标结果Tab. 7 Evaluation index results of each model
基于SMOTE 数据集2 构建的随机森林模型在不同数据集上的性能比较,见表8。可以看出经过SMOTE 方法处理后的平衡后数据集在建模效果方面优于原始数据集,这也从侧面印证了二分类数据集的不平衡性会影响机器学习建模的稳定性。

表8 不同数据集的随机森林模型比较Tab. 8 Comparison of random forest models with different data sets
2.7 模型比较基于变量集2 和平衡后数据集,以logistic 回归分析、支持向量机、决策树和人工神经网络4 种机器学习方法分别构建预测模型,利用测试集对4 种模型进行分类预测,结果显示:基于随机森林算法构建的预测模型各项指标均优于logistic 回归分析、支持向量机、决策树和人工神经网络。模型比较结果见表9。

表9 模型比较结果Tab. 9 Model comparison results
3 讨论
胰腺癌被称为“癌中之王”,是最具危险性的恶性肿瘤之一。近几十年来,得益于胰腺癌外科治疗和诊断技术取得的进展,胰腺癌围手术期死亡率及其术后并发症发生率均有大幅下降,但是由于胰腺癌的自身特点,胰腺癌患者术后远期生存率无明显突破[18]。早期阶段的生存预后预测对于改善胰腺癌患者的预后生存状况显得尤为重要。
随着人工智能在医学研究领域的不断应用,机器学习技术在肿瘤相关研究方面取得了巨大的进步。但肿瘤预测涉及各方面因素,复杂程度远高于传统的预测模型,基于机器学习的算法模型可以发现和识别多维因素之间的不同模式和非线性关系,从而对结果进行准确预测[13]。QIU 等[19]利用机器学习算法根据CT 检查结果预测胰腺癌病理分级;马作红等[20]基于控制营养状况评分构建晚期胰腺癌患者预后预测模型;BRADLEY 等[21]利用贝叶斯网络对胰腺癌切除术后不良预后结果进行个性化预测;吴君君[13]利用机器学习算法建立胰腺癌远处转移预测模型;邢晓蕊[22]基于机器学习算法建立胰腺癌诊断的预测模型。
在本研究中,只有6.3%的胰腺癌患者确诊时年龄小于50 岁,这与前期的研究[23-24]结果一致,年龄是导致胰腺癌预后差的重要因素。经过传统的统计学分析,肿瘤分化程度、是否化疗、是否放疗、T 分期、N 分期、肿瘤大小和淋巴结阳性比率均是影响胰腺癌患者整体存活的独立预后因素。而在随机森林变量重要性排名结果显示:淋巴结阳性比率对胰腺癌患者存活的影响最大。由于传统的肿瘤分期系统只计算阳性淋巴结的数目,这些阳性淋巴结的来源不同,因此患者在术后可能发生阶段性转移的现象[25],因此淋巴结阳性比率被提出作为新的预后因素[26],这与方向等[27]的研究结果相符,淋巴结阳性比率是影响胰腺癌患者预后的重要因素。多项研究[28-29]也证明:肿瘤分化程度、T 分期和N 分期等与胰腺癌患者总体生存的不良预后有关。
本研究基于SEER 数据库,借助SMOTE 方法,通过对特征变量进行选择,最终选择影响患者生存情况的10 项预后因素,利用随机森林方法建立胰腺癌患者术后5年生存情况预测模型,对患者术后5年的生存情况进行研究。通过与logistic 回归分析、支持向量机、决策树和人工神经网络算法进行比较,本研究结果显示:利用随机森林算法建立的胰腺癌术后预测模型在各项指标上均优于目前常用的机器学习方法。
本研究的不足之处在于未对SEER 数据库中与胰腺癌预后相关的所有变量进行研究,只根据文献提取了与预后相关的14 个变量,故本研究的模型变量具有一定的主观性与限制性。为了提高模型的准确性,在未来的研究中可以考虑对更多的变量进行研究。
猜你喜欢
保健医苑(2022年6期)2022-07-08 01:25:22
天津医科大学学报(2021年4期)2021-08-21 02:14:40
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
养生保健指南(2019年11期)2019-12-17 08:18:52
天津医药(2016年9期)2016-10-20 03:19:39
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
上海工运(2015年11期)2015-08-21 07:27:00
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:36
新高考·高二数学(2014年7期)2014-09-18 00:42:02
