
基于BERT的《中图法》文本分类系统及其影响因素分析
2022-05-10 07:58:02姜鹏
图书馆研究与工作 2022年5期
姜 鹏
(上海图书馆 上海 200031)
《中国图书馆分类法》(原称《中国图书馆图书分类法》)是新中国成立后编制出版的一部具有代表性的大型综合性分类法,是当今我国图书馆使用最广泛的分类法体系,简称《中图法》[1]。长久以来,《全国报刊索引》基于《中图法》的文献分类工作主要依靠人工进行,但有限的人工标引目前已很难应对爆炸式增长的文献,迫切需要引入文本分类系统以增加文献标引量。
1 文本分类调研
文本分类一直是自然语言处理任务中的一项基础工作,是指机器按照一定的分类规则或者标准自动对文本进行类别标记的过程,其目的是对文本资源进行整理和归类[2]。文本分类一般包括传统的分类方法和基于深度学习的分类方法。典型的文本分类算法包括支持向量、循环神经网络、卷积神经网络等。侯汉清等人以《中图法》为主干体系,分类号—关键词串对应表为知识库主题,构建了基于《中图法》的文本分类系统[3];孙雄勇等人利用CNKI已人工标注的期刊数据,采用基于词典的方法,构建含有词条、分类号、权值等信息的特征短语词典,实现了基于中图法的自动分类模型[4];郭利敏利用《全国报刊索引》数据,通过TensorFlow平台上的深度学习模型,构建了基于题名、关键词的自动分类模型,其一级准确率为75.39%,四级准确率为57.61%[5]。
2018年10月,GOOGLE公司发布了一种基于双向Transformer[6]编码器的自然语言处理模型BERT(Bidirectional Encoder Representation from Transformers)[7],并刷新了11项自然语言处理任务的精度,引起了广泛的重视[8]。Adhkari A等人首次将BERT用于文本分类,通过对BERT模型进行微调以获取分类结果,并证实BERT在文本分类中依然可以取得较好的结果[9];SUN C等人在8个数据集上进行BERT在文本分类的应用,并介绍了一些调参及改进的经验,进一步挖掘了BERT的潜力[10];赵旸等人以34万篇中文医学文献摘要为预训练语料,通过构建BERT的中文基础模型(BERT-Base-Chinese)和BERT中文医学预训练模型(BERT-Re-Pretraining-Med-Chi),对R大类下16个类别的中文医学文献进行分类研究[11];吕学强等人在BERT的基础上,提出了TLA-BERT模型,用于解决多标签文本分类问题[12];罗鹏程等人通过构建基于BERT和ERINE的文献学科分类模型,实现文献的教育部一级学科自动分类[13]。
为了解基于《中图法》的文本分类系统实际应用情况,笔者在文献调研的基础上,走访了同方股份有限公司(以下简称“同方”)、北京万方数据股份有限公司(以下简称“万方”)等数据库厂商,并调研了拓尔思信息技术股份有限公司(以下简称“拓尔思”)、云孚科技(北京)有限公司(以下简称“云孚科技”)等涉及文本分类方面业务的商业公司。调研结果如下:
(1)同方、万方都有专门从事基于《中图法》的文本分类人员,且都开发出相应的文本分类系统并投入使用。其中同方采用传统的分类方式,可以做到30%以上的分类结果不需要人工校对。
(2)拓尔思、云孚科技等商业公司虽然对《中图法》不熟悉,但具有类似文本分类系统开发经验,倾向采用深度学习方法。本次调研选取了《中图法》经济类(F类)约75万条数据分别委托进行测试,测试准确率(分类层级控制在四级以内)均能达到70%以上。
(3)本次还调研了中国医学科学院信息研究所。得益于长期的数据、词表积累,中国医学科学院信息研究所采用传统分类方法对医学类文献进行分类,中文标引系统的正确率约为80%,西文标引系统的正确率大约为78%。
2 基于BERT的文本分类结果及分析
《全国报刊索引》拥有专门从事文本分类工作的队伍,在2004年和南京农业大学侯汉清教授团队合作,研发出基于《中图法》的文本分类系统并投入使用,同时不断跟进自然语言处理技术的发展,先后尝试贝叶斯、最近邻算法、Tensorflow、BERT等方法用于文本分类。本文采用BERT-Base(Chinese)为例,阐述目前所遇到的难点以及对应解决思路。
2.1 BERT原理
BERT在双向transformers的基础上,通过预训练(Pre-training)和微调(Fine-turning)两个过程来完成自然语言处理任务。其预训练阶段包括两个任务:随机掩码机制(Masked language model,MLM)和上下句预测(Next Sentence Prediction,NSP)。其中的MLM任务中,BERT会随机遮挡住15%的词语,用“[MASK]”代替,并通过不断的迭代来预测这部分词语,以此学习语义和句法信息。为了使模型更加稳定,在随机的15%的词语中,有80%的概率会用 “[MASK]”替换,有10%的概率会替换为随机的单词,有10%的概率不做任何替换。NSP任务用以判定输入的两段语句是否连续,从语料库中随机选择50%的正确语句对和50%错误语句对进行训练,这一任务可以从任何的单语料库中生成。MLM与NSP任务相结合,可以更好地刻画语句甚至篇章层面的整体信息,为微调任务提供更好的初始参数值。
BERT模型的输入如图1所示,输入层通过词向量(Token Emmbeddings)、段向量(SegmentEmbeddings)以及位置向量(Position Embeddings)三部分求和组成,且在每个句子首位加入“[CLS]”和“[SEP]”标志,其中[CLS]对应的输入向量可用于文本分类任务。

图1 BERT模型输入示意图[7]
2.2 基于BERT的中文文本分类
本文主要使用BERT-Base-Chinese进行基于《中图法》的中文文本分类。样本数据的选择方面,本文选取《全国报刊索引》篇名库所收录的2008—2019年发表并经人工标引的核心学术期刊数据,其中仅包含题名、关键词、摘要、来源、作者信息等索引信息,并没有全文。经《中图法》四、五版类号转换、错误分类号剔除等清洗工作后,训练数据总量400余万条(2008—2018年收录数据),测试数据近24万(2019年收录数据)。
分类深度方面,由于目前受限于人工标引效率、学者研究热点等客观因素的影响,各数据量分布不均匀。以《全国报刊索引》所收录的F类数据为例,涉及分类号26 202个,数据量超过500条的类目仅有20个,84%的类目(21 980个)对应数据量不到10条。更甚者,2008年至今所收录的数据,F02(前资本主义社会生产方式)及其下位类中,仅有8篇文献,且均集中在F023(封建社会)类。为保证训练数据量,本文将单类层级限定在《中图法》第四级。
为了验证BERT模型分类效果,本文首先在F类进行对比测试。将BERT与TEXT-CNN(Convolutional Neural Networks)、LSTM(long-short term memory)、百度飞桨等模型进行对比测试,除百度飞桨模型测试结果在10%至60%之间徘徊,不具有参考性,未将其列出外,其余结果如表1所示。通过对比结果可以看出,BERT模型分类测试结果要优于TEXT-CNN等模型,可进一步进行全类测试。
在进行全类标引测试前,首先根据实际工作需要,对《中图法》基本大类进行微调。《中图法》共5个基本部类,22个基本大类,目前总类目5万余个[14]。本文将D9(法律)以及T(工业技术)大类下二级类目,如TB(一般工业技术)、TD(矿业工程)等均作为一级类目处理,并去除Z大类,调整后共有38个基本大类。
具体分类思路,首先实现38个一级类目的自动分类,然后进行四级类目自动分类。输入结果方面,根据之前测试结果发现,虽然输出多个分类号(一般是前三个)时,系统准确率较高,但在实际工作中,标引人员仅给出最接近文献内容的一个分类号,为了更贴切工作需要,本文仅输出阈值最高的分类号。性能指标的选取方面,需要的是系统较高的准确率,以减轻人工工作量,经综合考虑,本文仅采用了准确率这一指标。模型主要参数设定为批训练大小(train_batch_size)为32;批预测大小(predict_batch_size)为32;学习率(learning_rate)为3e-5。一级类目测试结果如表2所示,准确率最高为97.41%,最低为52.05%。社科一级类目(A—K)平均分类准确率为88.65%,且大部分类目准确率在90%以上;而科技类目(N—X)平均分类准确率在78.12%左右,略低于社科类目。四级类目测试中,本文选取了一级类目准确率较高的四个类目:F(经济)类、J(艺术)类、R(医药、卫生)类以及TG(金属学与金属工艺)进行后续测试,测试结果如表3所示。

表2 各一级类目分类准确率
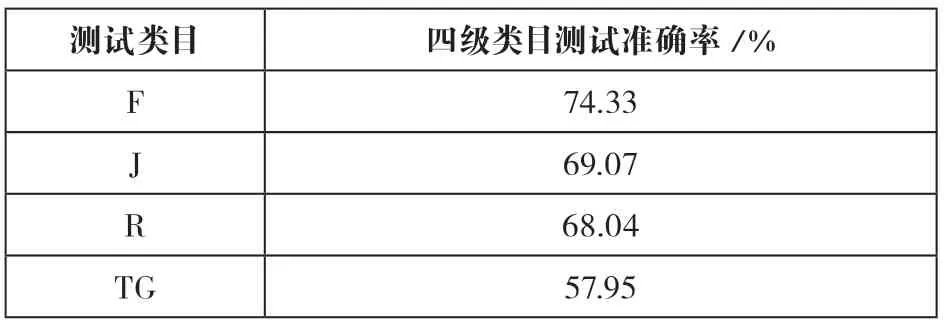
表3 F、J、R、TG类目测试结果
2.3 测试结果及难点分析
通过测试发现,一级类目准确率较高的类目主要集中在专指度较高,与其余类目交叉内容较少的类目。后经标引人员分析,此部分类目相对O(数理科学和化学)、P(天文学、地球科学)等类目而言,对标引人员专业知识背景要求相对较低。C(社会科学总论)和N(自然科学总论)在没有通览全文的情况下,很难准确入类,这点也可在表1中反映出来,实际工作中,这两类数据全部需要进行人工复验。I大类(文学)虽然主要以文学作品体裁作为主要立类依据,系统难以判定,但由于《全国报刊索引》所收录的学术文献主要属于相关文学评论,内容相对集中,系统分类准确率较高。
四级类目测试方面,通过阈值筛选可有效地将一部分标引结果设置为免检,无需再次人工标引。目前免检率最高为F类,在阈值大于0.9999的情况下,分类准确率可达到92.77%,所涉及数据占测试数据总量的38%。具体数据如表4所示。

表4 F大类测试结果分析
中文文本分类,一般包括预训练、待分类预处理、特征提取、分类等步骤[15]。影响文本分类的因素有训练数据集质量、数据分布、输入文本质量等[16]。为提高分类准确率,本文在前人基础上,分析BERT环境下影响分类质量的因素,调整测试方案,并提出解决对策。
2.4 《中图法》对分类准确率的影响
《中图法》本身是一个详尽且有巨大容纳力的类目系统,其基本类目高达四万多个。同时《中图法》广泛采用了类目复分、仿分、组配等方法增强文献的分类能力,这就造成了类号数量的不可控制性。同时这也导致同一大类不同下位类间、相近主题间区分度小,给机器分类带来极大困难。
《中图法》对类目进一步进行划分时,如涉及总分标准时,通常把类目划分为两大部分,第一部分是总论性或理论性类目,第二部分是专论性或具体性类目,遵循能入具体问题、事物的类目,不入总论性或理论性类目的原则。此外,社科一级类目(A—K)划分时,国家和时代成为这部分类目下重要分类标准,以D大类(政治、法律)为例,下设D5(世界政治)、D6(中国政治)、D73/77(各国政治),D6下又设D67(地方政治)。系统在区分总论或专论以及“世界”—“中国”—“各国”及“地方”时很容易判断错误。以“高收入者个人所得税国外征管经验及对我国的启示”为例,其侧重点在于对我国的启示,应放入F812中国财政,而系统将其划入F811世界财政。
部分类目类名相同或接近,系统难以从数据中获取区分因素。如H2(中国少数民族语言)下设“朝鲜语”(H219),而H5(阿尔泰语系)下同样含有下位类“朝鲜语”(H55),按《中国图书馆分类法第五版使用手册》(以下简称《使用手册》)中的说明“外国出版的与我国少数民族文字相同的语文著作入各语系的具体语言、文字”[17],这给机器的理解带来很大困难。另外,如J51(图案设计)下设J516(各种图案设计)、J519(其他)类目,如何准确区分这三个类目之间,尤其是“各种”和“其他”的区别,对系统而言是个考验。
类目更新缓慢,《中图法》第五版2010年9月第一次出版,截止到2021年,共发布过9次修订信息,最近一次修订为2019年8月正式发布[18],修订速度落后于技术或时代的发展。同时还存在《中图法》与《使用手册》描述不一致的情况,如“国际商务英语”《中图法》建议入“F7-43”,而《使用手册》建议入“F74-43”。
2.5 提高分类准确率对策
(1)提高训练数据质量。文献分类是一项相对主观的工作,对标引人员有较高的要求,且并没有严格的标准答案。标引人员知识背景的不同、对文章内容理解的差异、对分类规则应用角度的不同,均可能造成分类结果的不同。对测试结果进行人工抽样分析发现,由于主观性因素导致的模型分类准确率误差在±1%—4%之间。为进一步测试数据质量对分类结果的影响,本文在F类训练数据中混入部分低质量数据,这部分数据主要为仅含题名数据以及分类结果错误数据,占训练数据总量的15%。测试结果对比显示分类准确率下降约3%。
为提高训练数据质量,将导入模型的F类训练数据进行自动分类,后将机标阈值在0.5以下的数据从训练数据库中清除,重复4遍后,将清洗后的数据对模型重新进行训练,测试结果平均准确率提升至81.2%,提升幅度为2.76%。后续拟采用训练数据清洗与交叉验证并行的方法来提高训练数据质量。
(2)平衡数据分布。由于研究热点等客观因素,各类目间数据量差异较大。为测试数据量对测试结果的影响,本文在F大类上进行两组试验:一是在训练集中删除数据量在8 000以上的类目,并在测试集中删除对应类目,测试结果显示剩余类目分类准确率基本没有变化。二是在训练集中删除数据量在500以下的类目,并在测试集中删除对应类目,测试结果显示剩余类目分类准确率基本没有变化。
《中图法》为了保证实用性,根据文献分类的需要,采用多种方法对类目进行划分。最典型的在于法律类目采用双标列类(D9以及DF类),同时规定“各馆可根据各自的性质、特点,选择使用”。此外,交替类目、专类复分表、类目仿分设置、冒号组配法是否使用等,各馆所或数据提供商使用标准并不统一,这也导致不同来源的数据需要花费大量人工进行处理后才可以使用。在标引人员有限的情况下,本文无法通过引入外部数据的方式来测试小样本数据量的提升对分类准确率的影响,后续拟采用基于马氏距离的适应性过采样方法增加小样本数据量[19],以期待获取更好的分类结果。
(3)提高输入文本质量。影响标引结果的重要一方面为文中关键信息理解不当,主要表现在以下几个方面:一是一些专指度较高的词语、国名、缩略词,如“一带一路”“土耳其”等,系统无法识别。针对此情况,本文将汉语主题词表中相关术语词添加到自定义词典中,并在F大类中进行测试,测试结果并无明显的提升。二是主要因素理解错误,以“民用航空器客舱物体表面消毒效果评价”一文为例,其描述重在“消毒”,应分到R187(消毒),而非系统理解的R851(航空航天卫生学)。针对此种情况,本文拟参考N Poerner等人思路[20]引入知识图谱作为辅助信息,以增强文献主题权重。目前这项工作仅在R54(心脏、血管疾病)类中进行测试,准确率提升较为明显,但其通用性需进一步验证。
针对多主题文献,《中图法》将其划分为并列关系、从属关系、应用关系等,并说明了对应分类规则。但对错误数据分析发现系统对重点内容以及规则的判定结果不理想,如“美欧服务贸易自由化对中国经济的影响及对策”,“服务贸易”和“中国经济”是“A对B的影响”, 按规则“一个主题对另一个或多个主题影响另一主题的文献,分入受影响主题所属类目”,应入F12(中国经济),而不是机器分类的F752(中国对外贸易)。人工分析原因可能是文本预处理时将关系指示词,如“对”等作为停用词删除。为验证BERT环境下分词是否对分类结果有影响,本文以F类进行了对比实验,发现未进行预处理的情况下,模型分类准确率下降约1%。本次测试中,字长选取128,为测试输入内容对分类结果的影响,将字长分别调整为256和512,重新进行测试,测试结果略有提升,幅度不足0.3%。
(4)充分利用作者分类信息。《全国报刊索引》收录的数据中可直接用于辅助标引信息的主要有期刊分类号以及作者分类号,这两类数据可以为自动标引提供一定的助力。仍以2019年《全国报刊索引》收录数据为例,95%的文献集中在一个大类的期刊有431种;有作者分类号的文献有200 939篇,其中分类号一级类目正确的有109 235篇,占比为54.36%;扩展到刊的层面,在涉及到的4 000多种刊中,作者分类号正确率在95%以上的,有92种。由于目前尚未找出如何适当使用作者分类号的方法,本文仅使用期刊分类号用于辅助一级类目分类结果。测试结果显示,使用期刊分类号后一级类目准确率能提高0.86%。
3 结语
本实验是为了在现有技术水平下,尽可能地增加标引数据量。《全国报刊索引》编辑部根据实际情况,已在会议论文分类工作中投入使用基于BERT的文本分类系统,用以标引R类会议文献。一方面为了解决人力问题,增加标引量;另一方面在实际工作中验证系统的准确率以及可能存在的问题,以便于进一步改进。后续工作重点主要集中在以下两个方面:一是梳理人工分类经验,及时统一内部分类规则,尽量保证同一主题文献分到同一类目下,为文本分类提供高质量训练数据;二是尝试将人工分类经验引入到分类模型中,为文本分类提供一定助力。
猜你喜欢
中学生数理化·七年级数学人教版(2020年9期)2020-11-16 01:18:36
资源信息与工程(2019年2期)2019-05-09 01:29:30
温州医科大学学报(2018年8期)2018-03-03 01:41:09
温州医科大学学报(2016年2期)2016-03-16 08:16:38
图书馆学刊(2015年11期)2015-02-12 17:16:27
图书馆论坛(2015年2期)2015-01-03 01:43:00
图书馆理论与实践(2013年9期)2013-09-01 08:27:52
图书馆理论与实践(2013年3期)2013-04-27 05:39:56
温州医科大学学报(2013年10期)2013-03-18 18:13:31
图书馆理论与实践(2012年8期)2012-07-14 08:26:28
