
博物馆智慧化背景下文物知识图谱构建的实践探索
2022-05-07 09:13戴畋
科学教育与博物馆 2022年1期





摘要随着网络化、数字化的发展,博物馆在知识分享以及知识传播方面的贡献越发突出。文物知识图谱就是为了适应这种新的网络环境而产生的一种语义知识组织和服务的方法。文章试图回归知识图谱构建的本质,通过介绍目前知识图谱构建领域的一些新思路与新形式,结合文物数据库的特点,对博物馆如何利用知识图谱构建文物藏品知识库进行深入思考,以期挖掘文物知识图谱更大利用价值。
关键词智慧博物馆知识图谱数据挖掘
0 引言
随着博物馆信息化、智慧化的不断提高,博物馆在知识领域发挥的作用正在不断深化,尤其在知识分享以及知识传播方面的贡献正变得日益重要,广大观众及用户对于全球性知识获取的需求也在不断增长。但由于博物馆本身是一个发展历史较长的实体保存单位,对于知识和信息的获取和利用方式還未能完全满足数字化网络化时代的发展,许多历史知识与文物信息也都未能得到很好的挖掘。因此,就需要进行文物知识图谱的构建,以高效准确、简明易懂的方式和实现技术将博物馆内的众多文物历史知识进行整合和梳理,找出内在逻辑,从而满足日益增长的广大观众与用户的需求,讲好文物背后的故事,更好地完成博物馆在文化历史宣传方面的积极作用。
1 知识图谱的概念及相关研究
作为一种智能高效的知识组织方式,自2012年 Google 公司提出“知识图谱(Knowledge Graph)”至今,知识图谱技术得到了飞速发展,但实际上目前业界并没有一个公认的定义。
维基百科上知识图谱的词条实际上是对 Google 公司搜索引擎使用的知识库功能的描述,即知识图谱是Google 公司使用的一个知识库及服务,它利用从多种来源收集到的信息提升搜索引擎返回的结果的质量[1]。
在《知识图谱:方法、实践与应用》中,将知识图谱表述为“是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。”知识图谱由节点和边组成,节点可以是实体,也可以是抽象的概念;边可以是实体的属性,或者是实体之间的关系。知识图谱的早期理念来自 Semantic Web(语义网)[2],其最初理想是把基于文本链接的万维网转化成基于实体链接的语义网。
国内外围绕知识图谱也进行了大量研究,比如 I. Rafols 等人提出“知识图谱是科学领域或科学团体的符号表征,图中的元素与研究主题对应。而元素按照相似性进行布局,相关元素距离较近,不相关元素距离较远(图1,2)。图谱上的元素可以是作者、出版物、研究机构、科学主题或仪器工具等,其目的在于使用户能够分析元素之间的关系。大部分知识图谱使用的是文献数据库中的数据,不过也有使用其他数据源的。”[3]近年来我国一些学者也对知识图谱的概念做出了比较完整和全面的定义。比如肖仰华等将知识图谱概念分为狭义和广义。其中狭义的知识图谱特指一类知识表示,本质上是一种大规模语义网络。而广义的知识图谱是大数据时代知识工程一系列技术的总称,在一定程度上指代大数据知识工程这一新兴学科[4]。而刘则渊等人则将知识图谱定义为“显示科学知识的发展进程与结构关系的一种图形,可视化地描述人类随时间拥有的知识资源及其载体,绘制、挖掘、分析和显示科学技术知识以及它们之间的相互联系,在组织内创造知识共享的环境以促进科学技术研究的合作和深入。科学知识图谱具有‘图’和‘谱’的双重性质与特征:既是可视化的知识图形,又是序列化的知识谱系,显示了知识元或知识群之间网络、结构、互动、交叉、演化或衍生等诸多复杂的关系。”[4]
可以看出,知识图谱汇集了众多学科的理论和框架,本质上是一种语义网络,通过定量与定性相结合的研究方法,动态性地呈现科学知识的基本情况,同时揭示其背后隐含的规律、关系和趋势,从而产生新的知识。
近年来,随着互联网的日益普及,越来越多的知识图谱应运而生。根据 LOD(Linked Open Data 开放互联数据联盟)公布的数据,截至2019年3月,已有1239个开放互联的知识图谱加入,供全球用户使用[5]。表1为一些常见的知识图谱及其特点和规模。
其中,Cyc 是持续时间最久、影响范围最广、争议也较多的知识库项目。Cyc 最初的目标是要建立人类最大的常识知识库。它的主要特点是基于形式化的知识表示方式刻画知识,这样的优势是可以支持复杂的推理,但过于形式化也导致知识库的扩展性和灵活性不够。相比之下,ConceptNet采用了非形式化、更加接近自然语言的表述。而与 Google 知识图谱相比,则侧重于词与词之间的关系。WikiData的目标是构建一个免费开放、多语言、任何人或机器都可以编辑修改的大规模链接知识库,支持以三元组为基础的知识条目的自由编辑。截至目前,WikiData已经包含超过5000万个知识条目。
2 利用知识图谱构建文物藏品知识库
在文博领域,近些年国内外有许多科研机构和个人尝试利用知识图谱的方式构建各类文物主题库,知识图谱的应用逐渐受到研究人员和相关工作人员的关注,在各个领域均有涉及,比如智慧导览、智能问答、智慧展陈与可视化等,成为博物馆智慧化的重要研究和应用领域之一。但由于文物资料来源广泛,数量巨大,标准化程度极低,因此资料的知识点提取难度极大。同时,文物研究人员通常专攻某一类型或某一段历史,文物之间的内在联系很难获得,因此,文物知识图谱的构建难度较大,且在构建时自动化程度较低,多为人工提取和处理知识点,远远无法达到计算机自动处理和识别,这样就大大降低了文物知识图谱的检索效率和应用前景。而身处文博知识体系下,通过系统性梳理知识图谱的构建逻辑和构建方法,希望可以探索出一条针对文物藏品的知识图谱的构建方法。
一般来说,知识图谱的构建主要包含三个方面,即:知识抽取、知识加工和知识融合,而一套完整的知识图谱构建方法,还需要考虑图谱的存储和可视化等问题(图3)。由于文物的情况比较复杂,对于文物名称、描述、年代等方面的元数据规范程度较低,因此,在实际构建中,还需要考虑对于来源数据库的预处理工作,从而最大程度上实现知识图谱的自动化与准确性。
2.1 数据库预处理环节
数据库的预处理是指建立文物知识图谱来源数据库的元数据体系规范,以解决数据库互操作的问题,并为之后的文物知识图谱的构建打下良好基础。在许多知识图谱构建工具中,已包含预处理工序,但由于文博领域各类文物藏品的复杂性与多样性,数据库规范程度较低且元数据体系不统一,软件的自动预处理模块效果较差,因此需要人工干预,选择一种逻辑清晰、可扩展性强、且能够从语义层面解决数据之间异构性的元数据标准,将来源数据库与该元数据标准进行映射,以完成数据库的预处理环节。
CIDOC 概念参考模型(CIDOC Conceptual Ref- erence Model,简称 CIDOC CRM)是由国际博物馆理事会(International Council ofMuseums,简称 I- COM)下属的国际文献理事会(International Com-mittee for Documentation,简称 CIDOC)开发的一套应用于文化遗产的信息集成概念参考模型。它通过提供定义和形式化结构来描述文化遗产中所使用的隐形概念和显性概念以及它们之间的关系,从而帮助相关领域的研究者、管理者和公众在多源、异构、数量庞杂的数据中对特定信息进行定义和表达,并且通过提供通用和可扩展的语义框架,促进公众对文化遗产信息的共建共享[8]。
目前,最新的版本为 Version 5.0.4,于2011年12月发布[9]。本版本定义了90个类,147个属性,涵盖了围绕指定文物的时间跨度信息、分类学信息、主题描述信息、时空关系信息、复制权及版权信息、采集信息、计划使用信息、所有人信息等34类著录信息,随着模型的不断完善,类和属性都可以进行扩展。所有类别均以 E 开头,如 E1 CRM Entity(CRM 实体),E4 Period(时期);所有属性均以 P 开头,如 P1 is identified by(由…确定),P9 consists of(包括)。属性两端分别连接着代表“域”和“范围”的类,定义类与类之间的特定关系。通过如此规范化的描述,基本可以满足某一领域知识的基本体系结构,便于数据信息的存储利用和共享。
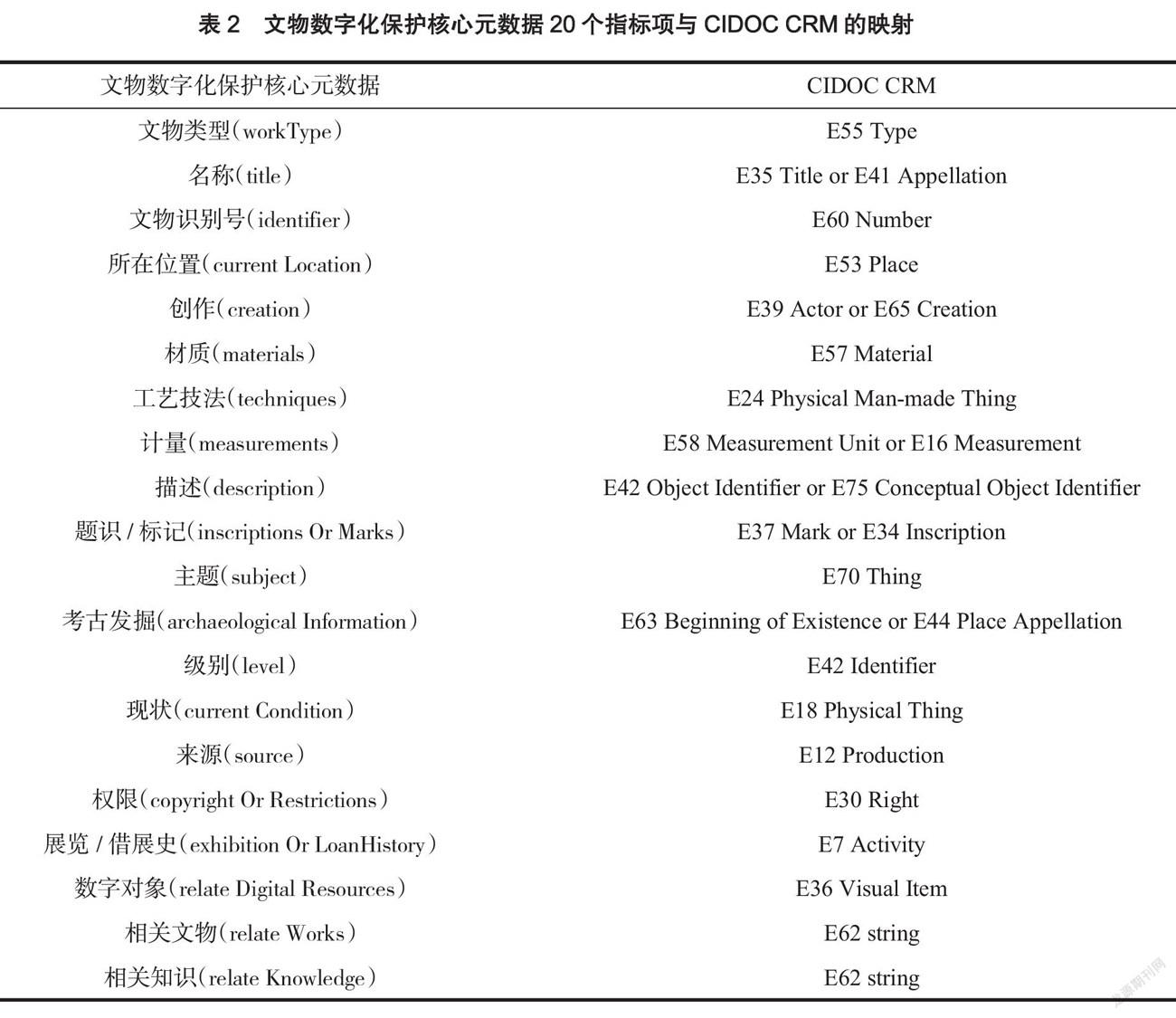
国家文物局在2017年发布的《中华人民共和国文物保护行业标准(征求意见稿)》中的《文物数字化保护核心元数据》,是针对文物数字化保护中不同类型文物资源基本特征进行描述的元数据标准,是根据文物资源的共同特点确定的元数据集合。该标准仅定义文物元数据的核心元素集,作为各领域元数据互操作的一个基础元素集,适用于各类文物信息资源的基本特征描述。在基于特定需求的具体项目或应用中可以增加额外的限制、规则和解释[10]。该核心元数据由20个元素组成,可以描述所有文物藏品的基础信息,并可以通过增加元素集来针对不同文物进行描述。表2为文物数字化保护核心元数据的20个指标项与 CIDOC CRM 的映射,通过映射来完成文物知识图谱来源数据库的预处理工作。
2.2 知识抽取
在知识抽取环节,不同主题的数据来源于各现成的数据库,且数据库本身较为规范,可以通过分析软件自动抽取,而在文物藏品领域,目前为止并未有足够支持文物知识图谱的数据库,且数据库来源复杂,标准众多,因此博物馆的知识图谱的构建一般都利用各自的馆藏文物数据库加上领域专家,针对某个主题进行构建,相对来说人工干预较多,自动化程度较低。这是一直以来未能解决的问题。
浙江大学的张娜在毕业论文中提出了一种基于半监督学习的三元组文物关系自动抽取算法,通过改进 Tri-training 模型来抑制半监督学习中的语义漂移问题。若能够结合文物数据库元数据预处理环节,则可进一步控制自动抽取环节的语义偏差,产生较好的知识抽取效果,更加适合文物数据库的关系抽取工作。
2.3 知识加工与融合
一般来说,文物知识图谱的知识加工与融合方法主要包括两类,即:基于多个知识图谱的融合方法、基于多源异构数据的融合方法(图4)。
其中,在基于多个知识图谱的融合方法中,首先每个知识图谱都是由一个独立的文物数据库构建而得,然后再将各个知识图谱融合为一个知识图谱,主要包括四个步骤,即:概念融合、实体对齐、属性对齐以及属性值融合。
在概念融合步骤中,由于文物数据库的特殊性,主要采取人工方法进行匹配以保证融合质量。在实体对齐步骤中,主要采取集体对齐的方式,即考虑整个文物知识图谱的信息进行匹配。之后再进行属性对齐以及属性值的融合,包括删除重复知识和去除错误知识。
而基于多源异构数据的融合方法是输入多源异构的数据库,比如互联网页面或者其他知识图谱等,最终输出一个融合后的文物知识图谱,这一类的典型代表是谷歌公司的 Knowledge Vault[11]。它采用全自动的信息搜集整合机制,没有任何人工干预,通过相关算法从互联网自动搜集信息,之后将信息整编为可用内容并入库。目前,Knowlegde Vault 的入库信息已达16亿条,其中2.7亿条内容被认定为“事实”(即谷歌公司通过大数据分析所得结果真实性在90%以上的内容)。
Knowlegde Vault 主要由三部分组件构成:知识抽取器,主要以互联网页面作为数据源进行知识抽取;知识推理器从知识图谱自身推理出新知识,并计算相应三元组成立的概率;知识融合器训练一个回归模型,从知识抽取器和知识推理器中得到每条信息的最终可信度[12]。
2.4 常用知识图谱的构建工具
目前文物类知识图谱的构建一般采用建模+系统开发的方法,选取典型文物,借助大量的专家资源完成知识图谱的规则设置和模型建构,可扩展性、可复制性较差。如果能够在规范文物元数据体系的基礎上,应用现成的知识图谱构建工具,根据实际情况对工具的模块和算法进行更改和调整,则可能会给文物知识图谱的构建带来新的思路。
国内常用的构建工具有Pajek、CiteSpace,国外常用的工具有 UCINET、Gephi、VOSviewer、Van- tagePoint、Sci2等。下面选取几个具有代表性的工具进行介绍,以探讨针对文物进行知识图谱构建的可能性。
2.4.1 CiteSpace简介[13]
CiteSpace是美国雷德赛尔大学信息科学与技术学院的陈超美博士于2004年开发的一款信息可视化分析软件。可以分析某个领域具有开创性和标志性的作品,分析某个领域起关键作用的知识拐点标志物,可以找出某个领域中主流地位的主题以及不同领域之间的关联。它可以通过分析某个领域中的潜在知识,以可视化的手段呈现其体系结构、规律和分布情况,并且显示该领域可能的发展新趋势和新动态。
CiteSpace以动态追踪、可视化与序列化兼具以及知识图谱构建功能完整为最大特点。其中,CiteSpace可以通过对特定领域文献的相关数据的计量,对该学科领域或研究方向的文献数据进行动态追踪,以探索该领域的演化路径和知识拐点。
CiteSpace展示的既是可视化的知识图形,又是序列化的知识谱系,它可以显示知识单元或知识群之间的网络、结构、互动、交叉、演化或衍生等诸多复杂的关系。利用CiteSpace可以帮助刚进入某一科学领域的研究者对该领域建立全面完整的认识,识别领域的研究热点以及预测学科的发展趋势。 2.4.2 Gephi 简介[14]
Gephi 是一款跨平台的基于 JVM 的复杂网络分析软件,主要用于各种网络和复杂系统,可以实现动态和分层图的交互可视化与探索开源工具。它可以处理巨大规模的数据量,支持100,000个节点和1,000,000条边,适合搭建大型的知识图谱。Gephi 界面优美,允许开发者扩展及编写插件,具有很强的可扩展性。
作为知识图谱的分析与构建工具,Gephi 可提供类似 Excel 的界面來操作数据列以及搜索和转换数据。同时,Gephi 提供中间中心性、紧密性、直径、聚类系数、社区检测(模块化)等多种分析方法,以用于知识图谱网络的构建。
Gephi 以可扩展性强、实时可视化、探索性强以及动态过滤等功能作为最大特点。其中,Gephi 一直以来致力于研究如何进行交互式和高效的网络探索,是动态图形分析创新的先锋。它提供丰富的图像处理工具,能够直观地显示知识图谱的复杂联系。2.4.3 VOSviewer简介[15]
VOSviewer是由荷兰莱顿大学的NeesJanvan Eck 与Ludo Waltman 共同开发的,用于构建可视化网络知识图谱计量分析软件。它以智能可视化、傻瓜化操作以及基于关联强度的数据处理为最大特点。VOSviewer使用类似谷歌地图的缩放和滚动功能,可以详细探索知识图谱。同时提供图谱关键部分的快速概述和随时间变化的演变轨迹。
VOSviewer的结果试图使用标签来呈现,即每一个节点用一个圆圈表示,圆圈大小表示节点的重要程度,若节点被划分为不同的聚类,则圆圈颜色不同。另外,知识图谱上的每个节点都可根据其密度进行颜色填充,两极颜色为红色和蓝色,节点越大,权重越大,颜色越接近红色;反之,若节点越小,权重越小,颜色越接近蓝色。
3 文物知识图谱构建的尝试与实践
在文物知识图谱构建的尝试与实践方面,国内高校及文博行业一直在进行积极有益的探索。
3.1 文物知识图谱构建
比如西北大学计算机应用技术学院的邱超[16],提出了一种基于 web 文本的文物知识图谱自动生成方法。该方法将特征词集的思路融合到文物知识点抽取规则生成算法中,以减少生成部分的人工干预成分,极大提高了工作效率和准确性。采用规则和极限学习机(Extreme Learning Machine, ELM)相结合的文物知识点抽取算法以及基于联合索引的资源描述框架(Resource Description Framework, RDF)的文物知识点存储方法,实现了文物知识点的快速检索。
浙江大学计算机科学与技术专业的张娜[17]提出了一种基于半监督学习的文物关系抽取算法,在算法中使用经过改进的三分类器协同训练模型(Tri- training Model),用于文物关系的自动抽取工作。
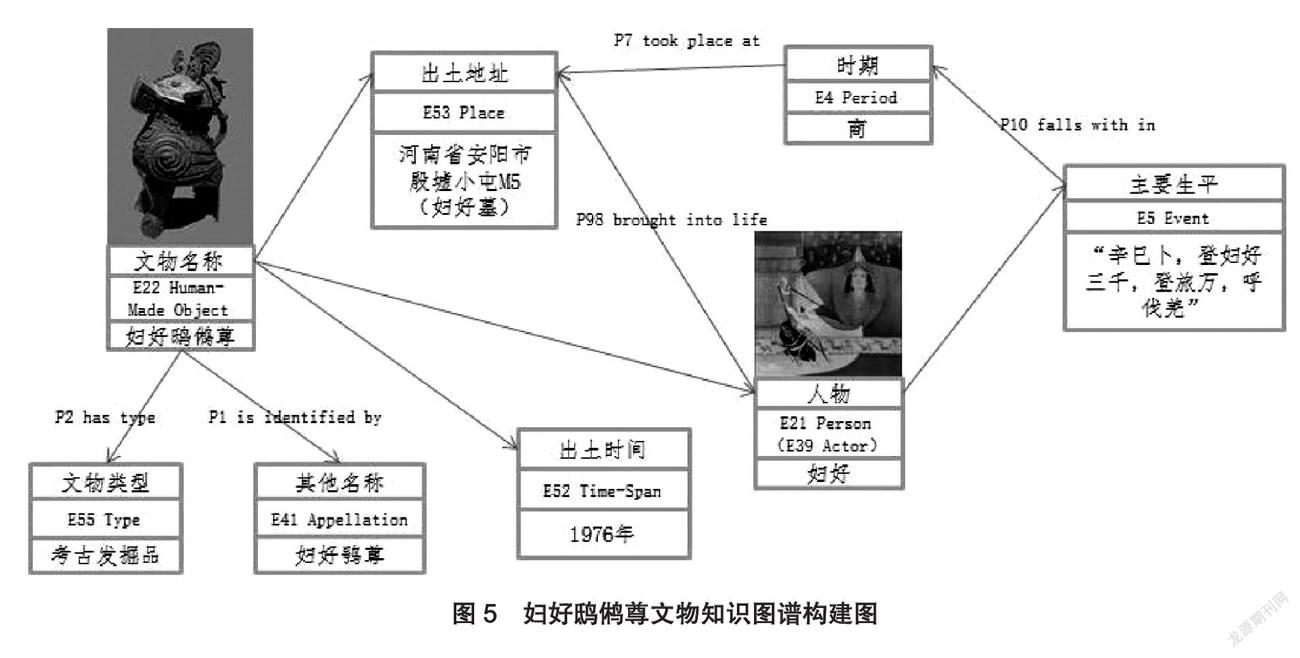
中国国家博物馆在2019年针对馆藏文物开始进行文物知识图谱的构建工作,目前已初步完成馆藏文物影像元数据体系的搭建,以 CIDOC CRM 模型为基础,并可与该模型进行一一映射,简单易行,方便扩展。其中,以对青铜器类中妇好鸱鸺尊[18]的文物知识图谱构建为例,如图5所示。
将文物与相关人物通过事件、地址、时期等属性进行关联,绘制出一幅典型的可扩展可描述的文物知识图谱模型。但由于国家博物馆馆藏文物数量较大,相关信息较多,且对于各类文物的研究内容进展不同、丰富程度不同,因此,在制作文物知识图谱的过程中,耗时较长,且只能分类处理,进行专题描述,暂时无法形成覆盖全馆所有文物类型的文物知识图谱模型。
3.2 藏品文物知识问答
天津大学软件工程专业的杨伟强[19]则通过与山西博物院的专家合作,共同完成馆内100件具有代表性的馆藏文物的文物知识图谱构建,提出了一种用于知识表达的本体模型和标准规范,并通过设计包括基于图数据库的数据存储、数据模型转换和知识融合等的基础模块,实现了山西博物院馆藏文物的知识图谱构建,在藏品文物检索、文物知识问答等方面初步实现人机交互,同时可以进一步支撑诸如文物陈列展览、文献研究等内容的辅助决策功能。但由于只是围绕着100件文物展开的研究与尝试,在文物规模上不够庞大,在文物类型覆盖面上也不够广泛。且因为大量的文物知识信息是以自然语言形式存在,在前期的自然语言规范形式上受到较多的限制,可能出现文物知识问答偏差等问题。
3.3 文物知识图谱可视化展示
万达信息承建的上海博物馆“董其昌数字人文”专题书画知识图谱,则是针对董其昌书画作品及对其书画生涯产生重要影像的鉴藏、交游、教育、传承等人文脉络,采用机器学习 CNN 深度模型卷积网络研发了图像关联 AI 引擎,对董其昌书画作品的数字图像及绘画元素进行分析,以可视化的形态为董其昌研究设计了一个“主体—表达—时代”的综合维度,逐步形成绘画元素标准样本国际平台。同时,通过机器学习建立社会网络关系图,为更好地理解其交游圈,对他的多方位影像给出了立体图景。
同时,利用 python、Gephi 等可视化方式绘制了董其昌的大事作品年表、作品可视化、书画船栏目、社会网络关系图等,并预留了与中国历史人物传记资料库、中国历史地图集等数据库的接口,为未来的进一步丰富打下了基础。但作为文物知识图谱而言,数据量和覆盖范围偏小,且大量工作是由人工方式完成,如何实现知识图谱中数据自动化导入和更新并且保证准确性、有效性,将是未来重点需要研究的工作。
這些在文物知识图谱领域进行的尝试和研究,对于让博物馆的文物真正“活”起来,让博物馆更好地讲好文物背后的故事有着非常重要的意义。因为这让越来越多的文物工作者看到了在“智能+”时代博物馆的更多可能性,同时也让更多的观众更加体会到文物的魅力以及中国文化的博大精深。
3.4 文物知识图谱辅助决策
天津大学张加万团队为故宫92周年“发现·养心殿—主题数字体验展”而构建的“养心殿知识图谱”,打通了文物之间的界限,让资源无限共享,进而从文物角度关联整个中国历史文化。不仅如此,通过充分运用云计算、大数据、物联网、移动通信等新一代信息技术成果,感知、分析、处理博物馆(群)运行的各项关键信息,实现博物馆智慧管理、智慧保护、智慧服务三大能力,从而真正实现“智慧博物馆”概念,让文物真正“活”起来。
4 结论
随着社会信息化程度的不断提高与深入发展,如何更好地利用文物大数据开展工作,一直以来是博物馆行业思考的方向。当前大量的文物知识图谱管理与应用方法仍是将知识图谱当作普通的图数据或是辅助展览的可视化工具,缺乏对于知识图谱语义信息与减少人工干预等方面的深入考虑。因此,本文试图回归知识图谱构建的本质,通过介绍目前知识图谱构建领域的一些新思路与新形式,结合文物数据库的特点,在文物知识图谱构建的三个环节中,增加数据预处理环节,选择最适合文物知识图谱构建的知识抽取与知识融合方式。另外,在知识融合方面,通过增加文物规模和覆盖面,进一步准确地将抽取的实体和知识图谱中对应的实体进行链接。
当然,文物数据库的数据量比之其他领域或者整个网络世界而言,并不算是规模巨大,那些关于文物知识图谱构建工作的尝试,虽然可能还处于探索阶段,但非常值得关注。而复杂网络领域积累的大量的真实网络分析方法,如果能够将这些丰富的方法用于文物知识图谱的实证研究,对于文物知识图谱的新的认知机制的发现,也有着巨大的价值。
参考文献
[1]闫树,魏凯,洪万福,等.知识图谱技术与应用[M].北京:人民邮电出版社,2019:2-3.
[2]N. Shadbolt, T. Berners-Lee, W. Hall. The Semantic Web Re- visited[J]. IEEE Intelligent Systems, 2006, 21(3):96-101
[3]Rafols I, Porter A L, Leydesdorff L. Science overlay maps: A new tool for research policy and library management[J]. Journal of the American Society for Information Science and Technology, 2010, 61(9):1871-1887.
[4]肖仰华,徐波,林欣,等.知识图谱:概念与技术[M].北京:电子工业出版社,2020:2-3.
[5]刘则渊,陈悦,侯海燕.科学知识图谱:方法与应用[M].北京:人民出版社,2008:385.
[6]Linked Open Data. About the diagram [EB/OL].[2020-03-18].https://lod-cloud.net/.
[7]肖仰华,徐波,林欣,等.知识图谱:概念与技术[M].北京:电子工业出版社,2020:31-32.
[8]ICOM/CIDOC CRM Special Interest Group. Short Intro of CIDOC CRM[EB/OL].[2020-01-08]. http://www.cidoc-crm. org/node/202.
[9]ICOM/CIDOC CRM Special Interest Group. Functional Overview of CIDOC CRM [EB/OL].[2020-01-08]. http://www.cidoc-crm.org/functional-units.
[10]中华人民共和国国家文物局.文物数字化保护核心元数据[S/EB].中华人民共和国文物保护行业标准(征求意见稿).(2017-03-10)[2020-01-13].
[11]Xin Dong, Evgeniy Gabrilovich, GeremyHeitz,etc. Knowledge vault: A web-scale approach to probabilistic knowledge fusion [C]. The 20th ACM SIGKDD interna- tional conference on Knowledge discovery and data min- ing, New York, America:2014.
[12]Hal Hodson. Google's fact-checking bots build vast knowl- edge bank[EB/OL].[2020-03-24]. https://www.newscientist. com/article/mg22329832-700-googles-fact-checking-bots- build-vast-knowledge-bank/#.U_rpfKN0Nc4.
[13]陈悦,陈超美,刘则渊,等.CiteSpace知识图谱的方法论功能[J].科学学研究,2015,33(2):242-253.
[14]Gephi. The Open Gragh Viz Platform [EB/OL].[2020-03-22].https://gephi.org/.
[15]VOSviewer. Welcome to VOSviewer [EB/OL].[2020-03-22].https://www.vosviewer.com/.
[16]邱超.基于Web 文本的文物知識图谱自动生成方法研究[D].西安:西北大学,2016.
[17]张娜.文物知识图谱构建关键技术研究与应用[D].杭州:浙江大学,2019.
[18]中国国家博物馆.中国国家博物馆馆藏文物研究丛书.青铜器卷(商)[M].上海:上海古籍出版社,2020:139.
[19]杨伟强.文物知识图谱的构建与应用[D].天津:天津大学, 2018.
(2020-09-25收稿,2021-12-08修回)
作者简介:戴畋(1987—),女,馆员,主要研究方向:智慧博物馆标准化体系研究、智慧博物馆知识图谱与智能问答研究, E-mail:daitian5049@163.com。
Practice and Research on the Cultural Relics Knowledge Graph Construction in the context of Museum Intelligence// DAI Tian
Author's Address The National Museum of China, E-mail:daitian5049@163.com .
Abstract The museum has been shouldered the task of spreading and sharing cultural knowledge andpreserving cultural heritage . With the development of network digitalization, the needs of the audience and users for cultural knowledge continue to develop, as well as the appreciation level of historical and cultural knowledge is also improved . Therefore, it is necessary for museums to fully explore the internal information of cultural relics and relations between cultural relics and history . As a means of data mining, knowledge graph has been paid more and more attention by the culture and museum industry which is characterized by large amount of data processing, high degree of processing automation, strong ability of learning and expansion, and visualization of processing results . More and more museums begin to use the cultural relic knowledge graph to excavate the cultural relic information that make positive and beneficial attempts in the cultural relic knowledge graph construction.
Keywords Smart Museum, knowledge graph, data mining
猜你喜欢
工业设计(2022年4期)2022-05-17
国际传播(2022年1期)2022-05-10
师道·教研(2022年1期)2022-03-12
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
意林·少年版(2018年13期)2018-08-14
新城乡(2018年6期)2018-07-09
布达拉(2018年5期)2018-05-14
