
智慧炼油厂生产数据处理算法及其在催化重整数据处理上的应用
2022-05-05 10:55王鑫磊
石油炼制与化工 2022年5期
苗 准,王鑫磊,张 蕾
(中国石化石油化工科学研究院,北京 100083)
随着信息技术的发展应用,现代炼油化工企业基本实现了生产装置运行数据的实时采集、记录与监控,积累了海量数据。如何充分处理好、利用好生产大数据,对优化生产、提质增效、建设智慧炼油厂具有重大意义,但也面临不小的挑战。每个炼油厂的生产数据采集位点数量各不相同,少则数千,多则数万乃至数十万;数据采集时间间隔也随炼油厂、装置和采集位点有所不同,多在数秒至数分钟,对同一位点,其采集间隔有时也会有所波动;炼油厂生产装置年均运行时间在8 000 h以上,总体上炼油厂生产大数据具有多位点、高频率、长时间的特点,具备一定的复杂性。
因此,工业数据处理是一项高度专业化、流程化、自动化的系统工程,面对如此海量的炼油厂生产大数据,必须形成一套高效、专业、各装置通用的处理方法。本课题针对炼油厂生产数据特点,研发设计智慧炼油厂生产数据处理分析通用标准流程,并将其形成SmartPec软件工具包。通过其在催化重整装置生产数据上的应用,解决目前生产数据模型准确性低、影响收率的关键要素难以确定、最优化目标难以实现等难题。
1 数据处理分析总流程简介
针对炼油厂特点研发设计的数据处理分析通用标准流程,并形成SmartPec软件工具包,如图1所示。主要包括数据预处理、数据分析、数据仿真、数据建模4大模块。数据预处理模块依次对炼油厂生产数据进行数据校验、缺失值填补(可选)、数据清洗、离群点识别与去除。预处理后的数据可在数据分析模块进行数据挖掘,该模块集成了包括相关性分析、降维与可视化分析、聚类分析、差异特征分析等在内的数据分析方法,既可以独立运行,又可以按次序依次运行。此外,软件包还具备数据仿真功能,当数据样本量不足时,该模块可对差异特征分析的输出结果进行数据分组仿真,实现数据的补充。另外,在数据建模模块,SmartPec提供了广义线性(GLM)模型和神经网络(NN)模型的构建方法供选择,并囊括了两种模型的比较及应用。
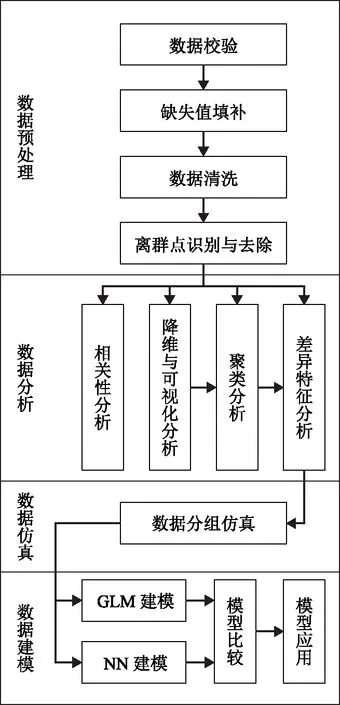
图1 SmartPec数据处理流程
2 SmartPec各模块介绍
2.1 数据预处理
SmartPec采用数据矩阵作为输入,行是特征,即各数据采集位点或各种物化性质;列是样本,一般是采集数据的时间点,各时间点可等间隔也可不等间隔。由于各炼油厂所用数据库不同、数据格式各异,准备工作难以编写统一的处理程序,但其基本步骤都包括读入数据、对齐(或平滑)时间点、统一缺失值格式。其目的是按照SmartPec对输入数据的要求将数据规范化,建立统一的数据格式。
2.1.1数据校验
数据校验主要包括校验数据中的常数行数与列数、缺失值数量、负数值数量等。该模块的目的是在数据处理前,及时发现数据中的冗余数据、缺失数据与异常数据,并提前进行处理。
2.1.2缺失值填补
处理缺失值的一种方法是缺失值填补,即依据已有数据,按一定规则对缺失值进行预测和插补。其优点是保持矩阵行列数不变,不会带来额外的数据和信息损失;缺点是填补数据质量存在未知性。SmartPec根据数据是否是等间隔时间序列数据,采取线性插值法或链式方程多元插补法[1]两种策略进行缺失值填补。
2.1.3数据清洗
处理缺失值的另一种方法是数据清洗,即按一定准则删除包含缺失值的行或列,从而达到消除缺失值的目的。其优点是简单快捷,且不会引入错误数据给后续分析带来不利影响;缺点是需删除整行整列数据,会带来额外的数据和信息损失。SmartPec包含一套专门设计的数据清洗算法,以穷举打分的方式确定最优的行列删除方式,从而在删除所有缺失值的同时尽可能多地保留矩阵中的数据。
2.1.4离群点识别与去除
离群点又叫歧异值或野值,是指显著偏离总体均值的数据点。采样误差、记录错误等原因都会产生离群点,它不仅直接影响模型拟合精度,甚至会使分析得出错误结论。SmartPec包含一套专门设计的算法,通过计算每个样本与其他样本间距离来识别和去除数据中的离群点,并经过多个炼油厂多套装置的数据校合,有力保障了数据的正确性和后续分析的准确性。
2.2 数据分析
2.2.1相关性分析
特征间相关系数是相关性分析中最常用的量,SmartPec可计算所有特征对间相关系数,并筛选出相关系数大于0.5和小于-0.5的强相关特征对,然后画出相关系数热图。
2.2.2降维与可视化分析
炼油厂数据特征多、维度高,需降维以进行可视化和下游分析。SmartPec集成了常用的降维与可视化方法PCA[2](Principal Component Analysis,主成分分析)和t-SNE[3](t-distributed Stochastic Neighbor Embedding,t-分布随机邻域嵌入算法)。t-SNE是采用非线性随机邻域嵌入的一种机器学习算法,其主要思想是通过将高维空间中点与点间的欧氏距离转换为条件概率来表征其相似性,进而使用这些概率分布在低维空间中进行点重构,因而更适合数据分类可视化,而PCA更多作为下游分析的输入。
2.2.3聚类分析
SmartPec采用Elbow法确定聚类数,以类内平方和随聚类数变化曲线的拐点作为最优聚类数。为去除无关成分的干扰,SmartPec采用PCA主成分作为层次聚类法的输入,并将t-SNE图按聚类结果染色作为可视化输出。聚类结果可用于对数据进行分类建模,有助于提高模型的拟合度和准确性。
2.2.4差异特征分析
刻画聚类结果各子类间差异的本质是探测在各类间存在差异的特征,可定义为差异特征分析问题。SmartPec采用ANOVA[4](Analysis of Variance,方差分析)对每个特征进行多类样本均值检验,当结果显著时,再多次使用T检验刻画该特征在每对子类间均值的差异情况。最后,输出差异特征分析汇总表,按差异由强到弱给出所有特征及其显著性,并给出所有显著差异特征的箱线图。
2.3 数据仿真
数据建模一般需要较多样本量,当原始数据或子类样本数较少时,建模效果难以保证。为解决这一问题,需依据已有样本进行数据仿真产生更多样本。整体来讲,同类数据具有同一性,不同类数据具有差异性。进行仿真的前提是被仿真数据具有相似性或同一性,即一次仿真只能针对一个子类进行。在该前提下,可假设同类数据的同一特征在大量样本中近似服从正态分布,不同特征服从不同参数的正态分布。此外,针对炼油厂数据可能存在的约束,例如百分比特征取值在0~100%之间、族组成数据(PONA)之和为100%等,SmartPec采用了截尾正态分布来控制每个特征的上下限,并设计了归一化方法来确保多个特征之和为指定常数。
2.4 数据建模
数据建模广泛用于目标特征预测,例如,根据原料性质、操作条件预测产品性质。通常,先用训练数据建模和训练模型,再用测试数据测试准确率达标后,所建模型即可用于实际数据。广义线性模型[5](Generalized Linear Model,GLM)是指用自变量对因变量进行广义线性回归训练出的预测模型。神经网络[6-7](Neural Networks,NN)模型是人工智能领域近年来的研究热点。SmartPec实现了两种方法在生产数据上的建模、训练、测试与应用,并集成了模型比较功能。由于一次随机划分训练、测试样本其结果难免有一定随机性,为减小随机性、反映真实情况,SmartPec中的模型比较功能采用K折交叉验证。K折交叉验证是指将所有样本随机等分为K份,用其中K-1份样本作训练集、1份样本作测试集得出预测结果和真实值的均方误差(Mean-Square Error,MSE),循环K次,每次依次将1份样本作测试集,其余K-1份样本作训练集,最终MSE等于K个MSE的平均值,MSE均值越小代表模型准确性越好。
3 SmartPec在催化重整数据处理上的应用
3.1 大幅提高重整装置数据建模预测准确性
芳烃收率是催化重整装置的关键优化目标之一,要最大化芳烃收率,首先要对重整生产数据进行建模。使用某炼油厂2016—2019年催化重整装置的运行数据,用SmartPec数据处理流程对其进行数据预处理、降维和聚类分析,并分类建模。以重整进料性质和操作条件为自变量、产品芳烃收率为因变量,SmartPec对聚类各子类随机抽取90%样本作为训练数据分别训练GLM和NN模型,其余10%样本作为测试数据,计算芳烃收率的建模预测结果和真实值的MSE,并进行10折交叉验证来减小样本抽取的随机性,10折交叉验证可参考2.4节中K折交叉验证的定义。在不使用SmartPec流程进行数据预处理,直接全样本建模时,GLM模型和NN模型的10折交叉验证MSE分别为3.887和4.168,如图2中实线所示。使用SmartPec流程进行数据预处理后,GLM模型的10折交叉验证MSE均值为0.897,NN模型的10折交叉验证MSE均值为0.489,如图2中虚线所示。结果证明使用SmartPec流程建模可将GLM模型的MSE减小76.9%、NN模型的MSE减小88.3%,大幅提高了数据建模的准确性。
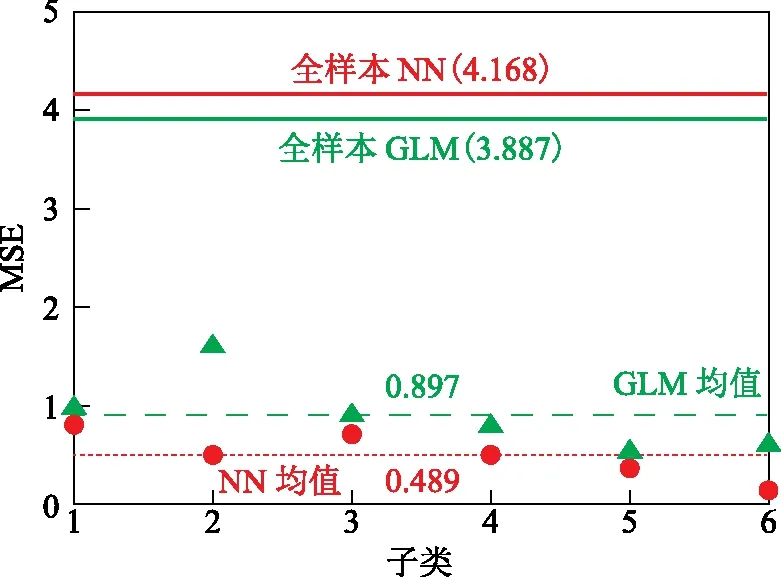
图2 使用NN模型和GLM模型对催化重整数据建模的10折交叉验证MSE●—NN; ▲—GLM
此外,由于SmartPec的开发不针对单一装置或炼油厂,这使得它的适用范围非常广,对于不同的数据类型及装置类型,都可用SmartPec建立的标准流程处理分析进而提高数据建模准确性。因此SmartPec不仅可以对催化重整装置进行建模,还可以对其他各类炼化装置具有广泛的适用性与非常好的建模效果。
3.2 准确识别影响重整芳烃收率的关键要素
催化重整装置的芳烃收率与重整进料性质和装置操作条件密切相关,找出影响重整芳烃收率的关键要素并按其重要性进行排序,不仅可以方便装置操作人员对装置整体运行状况进行监测,也可以通过对各项主要影响参数的分析和调节,实现装置的故障清除或优化运行。图3是某炼油厂2016—2019年催化重整装置运行数据中芳烃收率的直方图,为了划分高低收率样本,图中给出了25%和75%分位数线,如图3中红色虚线所示,25%分位数线左侧的305个样本是低收率样本,75%分位数线右侧的305个样本是高收率样本。使用SmartPec的差异特征分析功能,对低收率样本和高收率样本进行分析,识别并给出了校正后p值小于0.01的差异特征排序,即为影响重整芳烃收率的关键要素。通过对数据进行分析,给出了影响芳烃收率的4个关键要素,分别是重整进料终馏点、平均相对分子质量、C8环烷烃(C8N)含量以及脱丁烷塔回流量。图4为芳烃收率和4个关键要素的关系,由图4可见,重整进料终馏点、平均相对分子质量、脱丁烷塔回流量与芳烃收率呈现负相关,C8N含量与芳烃收率呈现正相关,由此可指导工艺人员对重整芳烃收率进行优化。
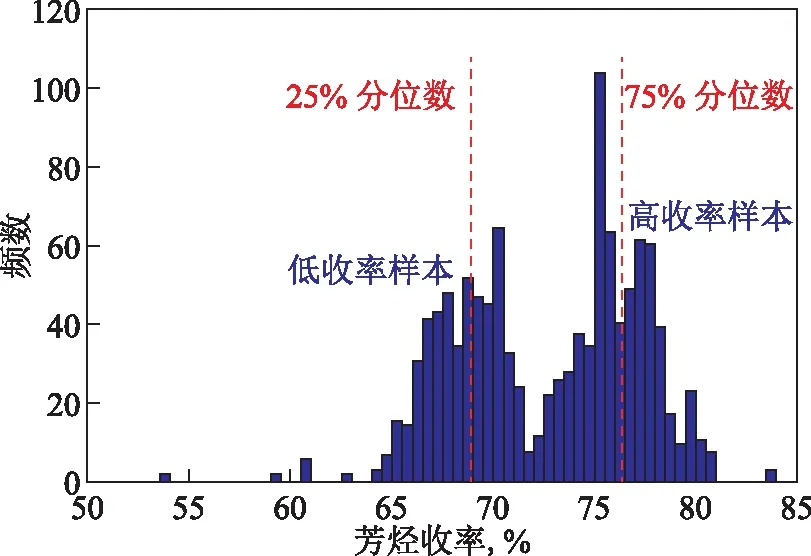
图3 某炼油厂催化重整装置运行数据中芳烃收率
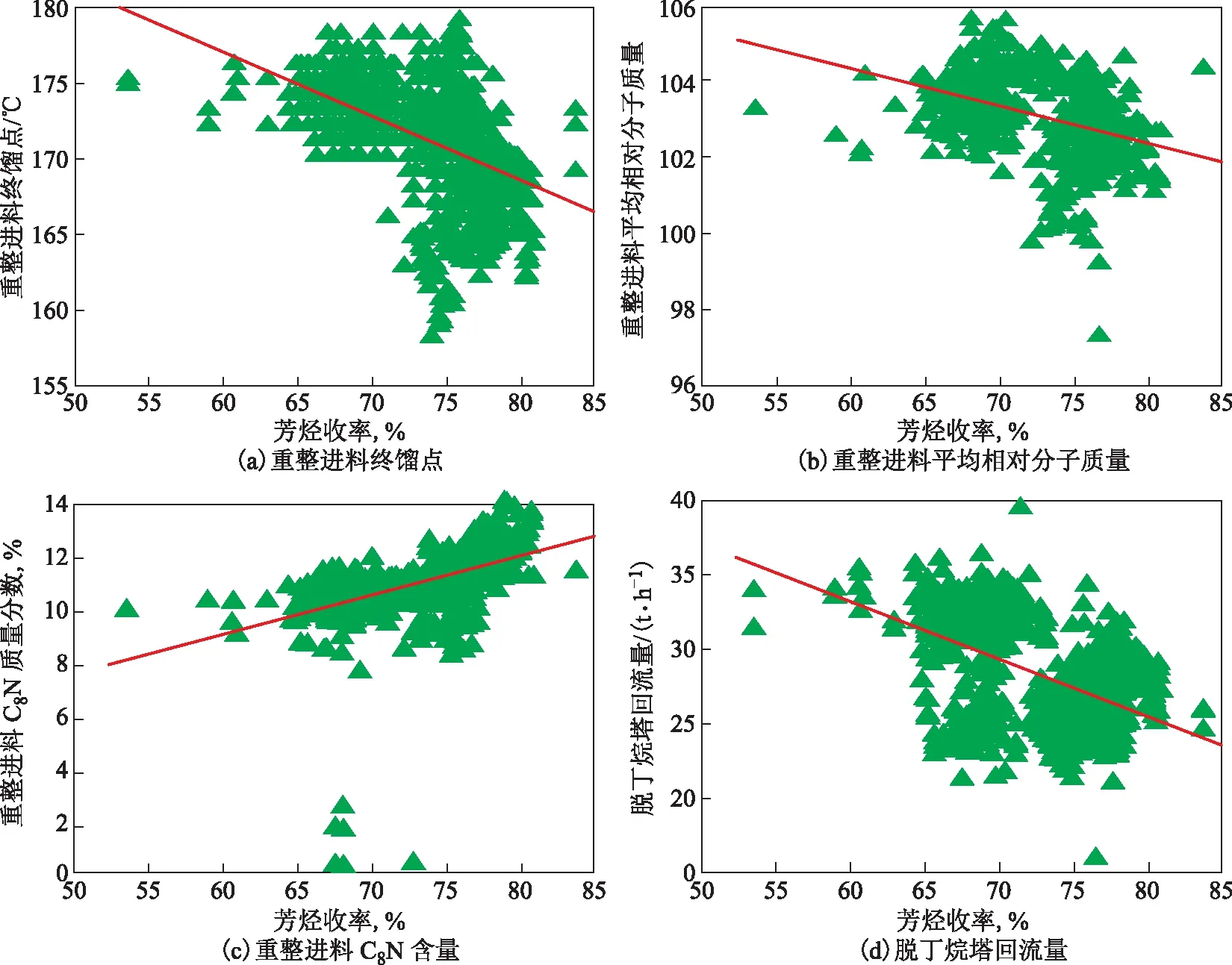
图4 SmartPec识别出的影响催化重整芳烃收率的4个关键要素
此外,SmartPec不仅可以识别两类样本间的关键差异特征,更可以准确识别多类样本间的关键差异特征,应用方式灵活多变;SmartPec在开发时充分考虑到各种异常输入与提示,且在做好输入控制的同时尽量包容各种可能的数据情况,能够适应炼油厂数据特点,稳定性强。
3.3 最大化重整芳烃收率
SmartPec的数据仿真功能提供了最大化重整芳烃收率的计算方案。将本文3.2小节中,差异特征分析结果高芳烃收率组的参数作为输入变量,使用SmartPec对高芳烃收率样本进行仿真,仿真样本量为10 000个;再将10 000个仿真样本作为3.1小节中所建立的NN模型的输入变量进行计算,结果表明,10 000个仿真样本中最大预测芳烃收率为83.61%。此样本对应的原料性质与主要操作条件参数即为重整最优芳烃收率工况。
研究结果表明,将数据仿真功能与数据建模功能相结合,实现了建模数据的快速获取,提高了数据模型的适用性和准确性。随后利用所建立的模型筛选最优化目标变量或目标函数的样本参数,给出的最优化结果可作为炼油厂实际运行调参的依据之一。SmartPec软件工具包对复杂的数据处理分析过程进行模块化设计和实现,用户只需根据需求“搭积木”进行组合,简单易用。此外,SmartPec还专门开发了对多线程并行计算的支持系统,且支持Windows,Mac,Linux等多个平台,方便快捷。
4 结 论
介绍了专用于处理炼油厂生产数据的通用标准流程程序包SmartPec,并测试了该软件工具在催化重整数据处理上的应用。SmartPec可将基于重整装置运行数据建立的GLM模型的MSE减小76.9%、NN模型的MSE减小88.3%,大幅提高了重整装置及炼油厂各类装置数据建模预测准确性,且具有适用范围广,通用性强的特点;SmartPec还具备一系列适用于炼油厂数据特点的数据挖掘和分析功能,准确识别出了影响催化重整芳烃收率的4个关键要素,并可用于探测多类样本间差异特征,应用方式灵活,稳定性强;SmartPec通过对某炼油厂催化重整装置运行数据的数据分析、数据处理、模型训练和模拟计算,提供了芳烃收率最大化方案;最后,SmartPec软件包可用于多种优化任务,简单易用,方便快捷。
猜你喜欢
炼油技术与工程(2022年9期)2023-01-07
石油炼制与化工(2022年11期)2022-12-24
银行家(2022年5期)2022-05-24
福建农林大学学报(哲学社会科学版)(2021年5期)2021-12-04
法制博览(2021年14期)2021-11-25
市场周刊(2021年8期)2021-11-22
科学家(2021年24期)2021-04-25
化工管理(2021年5期)2021-04-23
石油炼制与化工(2020年8期)2020-08-06
当代化工(2020年2期)2020-03-18
