
基于CT 影像的早期肺癌风险评估
2022-05-05 02:26何怡雯吴文浩侯学文李浩东聂生东
上海理工大学学报 2022年2期
何怡雯, 陈 阳, 吴文浩, 侯学文, 李浩东, 聂生东
(上海理工大学 健康科学与工程学院, 上海 200093)
肺癌是世界上最常见的恶性肿瘤之一,发病率和死亡率常年居高不下。由于肺癌的并发症状不易被识别、易转移等特性[1-3],绝大部分的肺癌患者直到中晚期才被确诊,导致错过了最佳的治疗时机,因而肺癌患者的5 年生存率低下。研究证明,在肺癌早期及时确诊并得到有效的治疗,可以有效地提高患者的5 年生存率[4]。因此,构建一种可靠、准确的早期肺癌风险评估模型具有重要的应用价值。多项研究表明,肺癌是环境和自身各种因素综合作用所引起的,常见的危险因素有年龄、性别、吸烟、肺部疾病史及家族恶性肿瘤史等。年龄作为肺癌的危险因素之一也已得到确认[5],相关研究显示[6]40 岁以下人群肺结节的检出率小于3 %,60 岁以上人群的肺结节检出率超过50 %。此外,研究表明,女性的肺癌患病风险比男性要高,同时长时间处于压抑状态的人群也更容易产生肺结节。吸烟作为环境中最主要的危险因素已经得到了大家的公认[7]。而自身的内在主要危险因素有患病本人的肺部疾病史和家族恶性肿瘤史。
近年来,血清肿瘤标志物在肺癌诊断方面的价值也逐渐被重视起来[8]。相关研究显示,随着肺癌患者的病情不断恶化,对应患者体内的癌胚抗原(carcinoembryonic antigen, CEA)、鳞状上皮细胞癌抗原(squamous cell carcinoma antigen, SCCA)和细胞角质蛋白19 片段(cytokeratin-19-fragment,CYFRA21-1)在血清中的表达也随之上升。因此,通过联合这3 种血清肿瘤标志物在血清中的含量情况进行分析,可以作为早期肺癌诊断的一种有效手段。CEA 与SCCA 的正常值为5.0 mg/mL,CYFRA21-1 的正常值为3.3 mg/mL。当检测值大于正常值时,可以认为该患者的肺癌患病风险较高。
计算机断层扫描(computed tomography, CT)是目前筛查肺癌最主要的技术手段。相对于支气管镜与X 线胸片检查等其他检查方式,CT 可以显示横断面的三维结构图像,能够很好地帮助医生区分病灶区域和正常组织,对于早期肺癌的筛查有着更好的检查效果。低剂量CT 技术不仅能降低患者的放射暴露时间,而且能获取足够清晰的胸部影像,从而成为早期肺癌筛查的主要方式。
由于数据的规范性、普适性等原因,国内外大部分对于肺癌的风险评估研究还属于前瞻性研究。目前国外已经有一些个人或机构建立了一些较为有效且稳定的早期肺癌风险评估模型。例如,美国德克萨斯大学安德森癌症研究中心研究的肺癌风险评估模型[9];哈佛大学公共卫生学院开发的哈佛癌症风险评估工具可以对多种恶性肿瘤进行风险评估[10];Bach 等[11]建立的肺癌预警模型主要适用于目前或既往存在吸烟史的人群;Liverpool Lung Project(LLP)模型[12]是通过研究肺炎史、肺癌家族史、石棉暴露史、年龄、性别和吸烟史来建立的肺癌风险预测模型;Spitz 等[9]建立的早期肺癌风险评估模型针对不吸烟、既往吸烟和目前正在吸烟的人群其交叉验证统计值分别为0.59,0.63 和0.65;Cassidy 等[13]建立的肺癌风险预测模型最终验证的AUC 值为0.70;王旭等[14]将与肺癌相关的有效分子生物标志物与环境因素及机体内因素结合在一起进行联合分析,研发出了相对客观的适用于东北地区的肺癌预警评估模型;同样地,张亚琛等[15]使用肺结节分布特征与其他危险因素建立了适合河北地区的肺癌早期预警模型;浙江大学团队研制出一种可以检测并分析患者呼出气标志物的仪器[16],可以对患者呼出的气体中的挥发性有机物进行定性分析,再结合其他肺癌危险因素建立肺癌的早期诊断模型,为肺癌的早期预防和诊断提供了比较成熟的技术支持。刘龙飞[17]的研究内容主要集中在对于已存在的各种模型的优化。
综上所述,现有的方法都是将重点放在对不同特征数据的处理上面,将各组学的特征数据进行融合,再选择合适的统计学方法,最后建立肺癌风险评估模型。
本文则针对于横断面数据,提出一种基于合成分析的早期肺癌风险预测模型,以克服横断面数据的不完整性。横断面数据是呈现出“倒金字塔”型的一类数据,不同病例有不同的数据缺失,从而导致具有不同因素的样本数存在区别。因此,传统的多因素回归方法无法应用到所有数据上面,而合成分析法是一种能够很好地适应于横断面型数据的统计学分析方法。
1 材料与方法
1.1 数据筛选
本文使用的数据来自上海市肺科医院,一共247 组病例。其中,200 组作为训练数据,剩余作为测试数据。每组数据包括完整的患者术前最后一套CT 影像和其他信息,并且临床医生根据每例患者的病理诊断报告给每组病例划分了危险等级,共分为5 个等级,第5 级代表危险程度最高,第1 级表示无患癌风险,以此作为建模中的结果变量。具体信息如表1 所示。从表1 可以看出,本文所使用的数据属于典型的横断面型数据,合成分析法可以在缺乏纵向队列数据时,基于横断面数据构建有效的疾病预测模型[18]。将单个因素回归模型和单个因素之间的相关性整合到一起形成一个多因素回归模型,从而克服横断面数据的不完整性。因此,本文使用合成分析法来建立最终的早期肺癌风险评估模型。

表1 肺科医院数据信息Tab.1 Data information of pulmonary hospitals
将基于CT 影像的判断结果结合其他肺癌危险因素来进行建模。首先,使用基于三维条件随机场优化的3D U-Net 分割算法[19]对所使用数据进行肺结节分割,提取完整的肺结节区域;然后,使用基于聚类辅助的随机森林分类算法[20]进行良恶性分类;最后,再使用合成分析法结合良恶性分类结果和吸烟史、家族病史等肺癌危险因素建立最终的早期肺癌风险评估模型。模型以第1~5 级的危险等级为结果变量,等级越高表示危险程度越高,模型中其他变量的类型和赋值情况如表2所示。
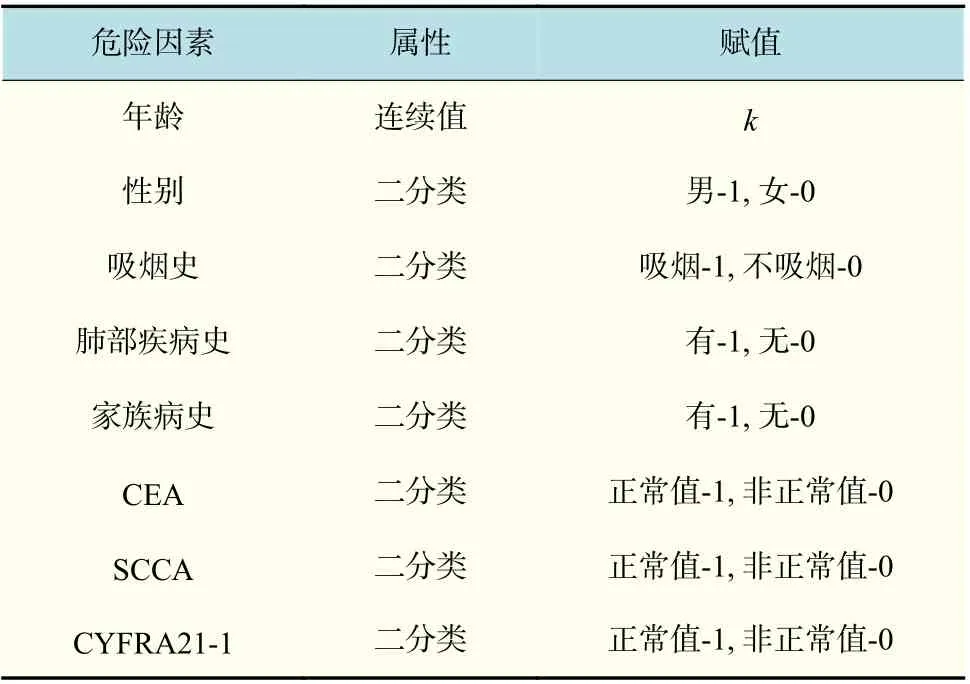
表2 肺癌风险因素及赋值Tab.2 Risk factors and assignment for lung cancer
1.2 模型建立
回归是一种从连续型统计数据中得到数学模型的方法,其中,线性回归模型的实现较为简单且快速,特别适合线性数据及较小的数据量,但对于高度复杂的非线性数据不能很好地进行拟合。另外,回归模型具有很好的可解释性,可以直接看出每个特征对结果的影响程度,有利于建模时决策分析。多因素线性回归体现了多个独立输入变量与输出因变量之间的关系,合成分析法通常有两种形式去构建多因素回归模型:一是逐步地纳入多个单因素变量,先构建第一个危险因素与结果变量直接的基础方程,再逐次将其他危险因素添加到方程里面,形成最终的多因素回归方程;二是基于现有的基础方程,直接构建多因素回归模型。本文主要研究以第一种形式来建立早期肺癌的风险评估模型。在实际肺癌风险评估模型建立过程中,单个因素(如性别、年龄、吸烟史、肺部疾病史和家族病史等)与结果变量之间的回归分析等数据主要是通过其他资料文献获得,影像学判断结果和3 种肿瘤标志物与结果变量之间的回归系数通过单因素分析获得。
现介绍使用合成分析法构建早期肺癌风险评估模型的具体步骤。
步骤1 基础方程构建。
设第一个危险因素为自变量F1,肺癌危险等级为因变量I1, 构建单因素回归模型I1=a+b1F1,b1为F1的回归系数。
步骤2 纳入第二个危险因素。
纳入第二个危险因素F2,并根据基础方程计算所对应的回归系数f2,b2为先前统计分析得到的回归系数,将b2与f2进行比较,如果差值较小,则令b2=f2; 否则,令b2=(b2-f2)。
步骤3 构建包含前2 个危险因素的回归方程。
构建新方程I2=a+b1F1+b2F2,此时,包含2 个危险因素的方程I2则反映了危险因素F1和危险因素F2与疾病之间的关系。
步骤4 重复步骤2-3,逐次纳入所有危险因素,得到最终的回归方程In=a+b1F1+···+bnFn,n为危险因素数目。
本研究使用Windows 平台的SPSS24.0 软件实现。
2 实验结果与分析
2.1 因素分析
本文将基于CT 影像的良恶性判断结果和其他危险因素相结合,建立了一个多因素回归模型,对肺癌进行风险评估。年龄、性别、吸烟等肺癌危险因素在肺癌诊断模型中的效果已经被确认,但良恶性的判断结果对于模型的影响尚未明确。因此,在建模之前,首先要分析基于CT 影像的肺结节良恶性判断结果是否适合作为肺癌危险因素之一来进行建模。由于数据类型的限制,使得本文无法使用常用的变量筛选方法来进行分析,所以,通过单因素方差分析良恶性判断结果与结果变量之间的相关性来进行确认,分析结果如表3所示。
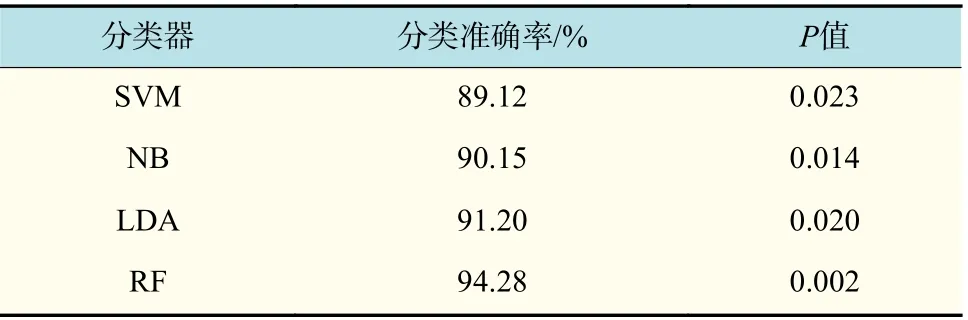
表3 不同分类器良恶性分类结果的单因素分析结果Tab.3 Univariate analysis results of benign and malignant classification results of different classifiers
整个分析在SPSS24.0 软件中进行,分别将4 组不同分类器的良恶性分类结果与风险评估的结果变量作了单因素方差分析,分别计算了各组的P值。由4 组的P<0.05 可以看出,良恶性分类结果因素对于肺癌风险评估结果变量的影响是显著的,因此,可以初步证明肺结节良恶性判断结果可以作为危险因素之一建立肺癌风险评估模型。在之后的实际建模结果评估的时候,可以进一步对此结论进行验证。
2.2 合成分析模型构建
首先统计分析了具体的肺癌单个因素和对应的回归系数,如表4 所示。将良恶性判断结果作为第一个变量来进行建模,3 种肿瘤标志物的回归系数则通过单次的单因素Logistic 回归分析得到。

表4 肺癌危险因素和对应回归系数Tab.4 Risk factors and corresponding regression coefficients of lung cancer
a. 基础方程。
以肺癌危险等级为因变量,基于CT 影像的肺结节良恶性判断结果A为第1 个危险因素作自变量,构建基础方程为
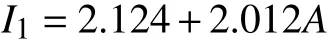
b. 加入第2 个变量:年龄B。
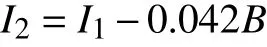
c. 加入第3 个变量:性别C。
基于方程I2,根据肺科医院整理的数据,计算每个具有年龄因素的样本的I2值,以I2为因变量、性别为自变量进行单因素线性回归分析,得到回归系数为0.005,因此,b3=(-1.36-0.005)=-1.365,构建新的方程为
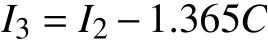
d. 加入第4 个变量:吸烟D。
基于第3 个方程I3,根据同一数据集计算每个具有吸烟因素的样本的I3值 ,再以I3为因变量、吸烟因素为自变量进行单因素线性回归分析,得到回归系数f3为 1.213,与b3相差较小,因此,包含3 个变量的方程为

e. 加入第5 个变量:肺部疾病史E。
根据数据集基于第4 个方程I4计算每一个具有肺部疾病史因素的样本的I4值,并以I4为因变量、肺部疾病史为自变量进行分析,得到回归系数f5=0.034 ,则b5=(1.269-0.034)=1.235,新的方程为
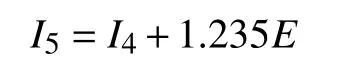
f. 加入第6 个变量:家族病史F。
根据方程I5和数据集计算每个包含家族病史的样本的I5值 ,并以I5作为因变量、以家族病史因素为自变量作回归分析,得到回归系数f6=0.107,因此b6=(1.134-0.107)=1.027,得到新的方程

g. 随后,依次分别加入第7,8,9 个变量G,H,J:肿瘤标志物CEA,SCCA 和CYFRA21-1。
重复前面的步骤加入肿瘤标志物因素,计算得出b7=1.387,b8=1.890 ,b9=1.542,构建 新 方程为
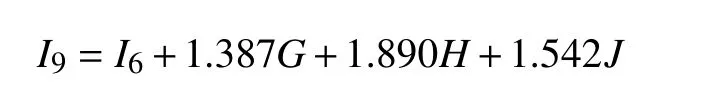
h. 构建最终模型。
为了保证最终方程对于整体数据的平均肺癌危险等级保持不变,需要在方程I9的基础上减去一个平均值2.832,得到最终的风险评估方程IF。
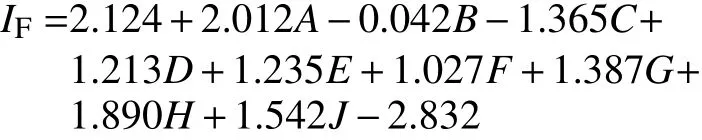
2.3 模型评价
使用组内相关系数( intraclass correlation coefficient, ICC)对医生划分的危险等级与合成分析模型得到的等级进行检验,得到的ICC 值大于0.75,表示这两组变量对同一个样本的一致性高,说明了本文得到的结果与医生给出的标准相比重复性高且可信度良好。
为进一步验证基于CT 影像的肺结节良恶性判断结果对于肺癌风险评估模型的积极影响,按照同样的方法构建了不包含影像学良恶性分类结果的合成分析模型,得到了风险评估方程IC。

分别计算了合成分析模型IF和IC在相同测试数据上表现的性能,主要指标包括准确性、敏感性、特异性。对比结果如表5 所示,图1 显示了2 个模型的ROC 曲线(接收者操作特征曲线)对比结果。
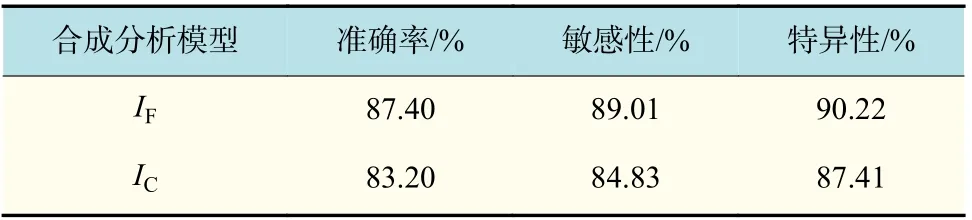
表5 模型性能对比结果Tab.5 Comparison results of model performance
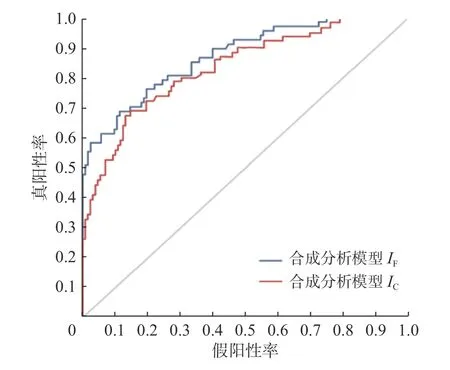
图1 模型ROC 曲线Fig. 1 ROC curve of the model
由表5 的结果可以看出,模型IF相较于模型IC具有更好的评价结果,本文提出的合成分析模型的准确率达到87.40%。同时从图1 中的ROC 曲线对比也可以证明,加入良恶性判断结果之后的肺癌风险评估模型具有更好的评估性能。
3 结 论
研究了使用合成分析方法建立基于横断面数据的早期肺癌风险评估模型。基于病人CT 影像的肺结节良恶性判断结果、年龄、性别、吸烟、家族病史、肺部疾病史和3 种肿瘤标志物为研究变量,分别构建了包含和不包含肺结节良恶性分类结果因素的模型,并在相同数据集上对比2 个模型。结果显示,包含肺结节良恶性判断结果的模型具有更好的预测性能,也进一步验证了通过单因素回归分析得出的结论,基于CT 影像的肺结节良恶性判断结果变量对于肺癌风险评估模型的构建是有益的。但本方法也存在一些不足之处。首先,对于不同因素回归系数的确定和纳入模型顺序的确定具有主观性,在整体上对模型的性能评估造成一定的影响;此外,在模型对比的过程中,由于不同模型使用的数据,涉及到的自变因素和结果变量的设定具有一定的差别,很难客观地去分析不同模型之间的差异性。希望在未来的研究中,随着研究数据的增多,更多肺癌的危险因素被确定和加入到风险评估模型当中。能够建立一个稳定、准确的早期肺癌风险评估模型。
猜你喜欢
传染病信息(2022年3期)2022-07-15
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
中国药学药品知识仓库(2022年1期)2022-03-23
昆明医科大学学报(2021年4期)2021-07-23
云南医药(2021年3期)2021-07-21
医学食疗与健康(2021年27期)2021-05-13
天津医科大学学报(2021年2期)2021-03-29
英语文摘(2020年2期)2020-08-13
饮食与健康·下旬刊(2019年10期)2019-03-09
数学学习与研究(2018年14期)2018-10-29
