
基于改进Bi-LSTM 和XGBoost 的电力负荷组合预测方法
2022-05-05 02:26代业明
上海理工大学学报 2022年2期
代业明, 周 琼
(青岛大学 商学院,青岛 266071)
随着电力需求日益增加,传统电网在集中配电、人工监控和恢复、双向通信等方面开始遇到挑战[1-2],智能电网的出现为解决上述困难提供技术可能,有助于监控电力生产、传输和消耗,并平衡三者关系[3]。但由于气候、经济、环境等不确定因素的影响,电力负荷波动较大[4],难以简单对其进行预测。为了确保电力系统安全运行,减少电力消耗,满足市场需求,平衡电力负荷的供需关系,最大化经济效益,对电力负荷进行精准预测十分必要。
现有电力负荷预测方法主要分为4 类:传统预测、现代预测、混合预测和组合预测。其中,传统预测方法包括时间序列分析[5]、回归分析[6]和其他统计方法,能较好处理简单线性问题和估计未来电力负荷,但在处理非线性问题时效果不佳。于是,基于非线性映射的现代预测技术逐渐用来预测非线性问题,主要包括模糊逻辑、灰色系统、人工神经网络、支持向量回归。但这些方法依然存在计算复杂[7-8]、泛化能力差[9]和过拟合[10]等固有局限,对电力负荷精准预测带来新的挑战。
针对上述不足,通过粒子群[11]、贝叶斯[12]等参数优化算法以及对数据进行预处理,提出了混合预测模型。从参数优化角度,Wang 等[13]使用混合支持向量回归方法预测中长期负荷,并使用基于嵌套策略和状态转移算法的分层方法优化预测模型的参数;Barman 等[14]使用灰狼优化器优化支持向量机参数并预测了受文化或宗教仪式等社会因素显著影响的电力需求。通过数据分解[15]和特征选择技术[16]对数据进行预处理,有助于消除异常值,纠正数据错误和提高数据质量。因此,混合预测方法比前两种预测方法表现更佳。
为进一步改进和优化预测模型,克服传统、现代和混合预测方法中单一预测模型的固有缺陷,将两个以上的不同预测模型以特定加权方法组合,从而得到组合预测方法。如Xiao 等[17]采用布谷鸟搜索算法来优化组合模型的权重系数,实验结果表明所提出的组合预测模型可以产生更低的误差,能够提供稳定、高精度的负荷预测;林锦顺等[18]、邓带雨等[19]和Chu 等[20]也证明了组合预测模型的性能优于单一模型;陈振宇等[21]使用长短期记忆网络(long short-term memory, LSTM)和极端梯度提升(eXtreme gradient boosting, XGBoost)模型预测电力负荷,然后根据误差倒数法为两个模型分配权重,从而尽可能减小误差和提高预测精度;庄家懿等[22]结合MAPE-RW 算法进行模型组合初始权重设置,对最佳权重进行搜索,构建了CNN-LSTM-XGBoost 组合预测模型,比单一预测模型误差显著降低;Nie 等[23]则使用多目标灰狼算法(multi-objective grey wolf algorithm, MOGWO)分别对径向基函数网络(radial basis function network,RBF)、广义回归神经网络(generalized regression neural network, GRNN)和极限学习机(extreme learning machine, ELM)赋予权重,建立了一种基于群智能优化的组合预测模型,有效降低了单一模型适应性弱的不利影响,使准确性和适应性得到迅速提高。
从以上文献可知,组合预测方法对预测的改进不仅需要多个预测模型,还需要计算每个模型所占权重,并没有强调数据预处理的重要性,并且通常组合现有成熟预测模型。在此背景下,本文首先使用加权灰色关联投影算法(weighted grey relational projection, WGRP)对数据进行预处理,消除节假日的不利影响;其次,在被广泛认为是一种能够充分隐藏信息并获得良好预测效果的Bi-LSTM 预测模型基础上,将具有大规模并行处理、分布式信息存储、可接受的自组织和自学习能力等优点的注意力机制添加到Bi-LSTM 模型中,消除不合理的影响,并强调关键输入数据影响,得到了“Attention-Bi-LSTM”模型;最后,为了避免单一预测模型缺陷,再将通过添加正则项来控制模型复杂性和防止过度拟合、提高模型泛化能力的XGBoost[21]模型与Attention-Bi-LSTM模型组合,得到“Attention-Bi-LSTM + XGBoost”电力负荷组合预测模型,并运用新加坡电力市场数据进行评估。
1 基本理论
1.1 加权灰色关联投影算法
加权灰色关联投影算法[16]是一种将各因素之间发展趋势的相似或相异程度,即“灰色关联度”作为衡量各因素关联程度的一种方法。该方法不受样本量多少的限制,可以全面分析指标间相互关系,反映各决策方案与理想方案之间接近程度,并对有无规律的样本量都同样适用,结果具有一般性、计算量小的特点。
首先,选择n1个样本的数据和待预测样本的数据,计算它们之间的关系系数,并构造以下灰色关联矩阵。

式中,An1m1表示第n1个样本中第m1个因子的灰色关联系数。
然后,使用熵权法计算各影响因素的权重,并对灰色关联矩阵进行加权,得到加权灰色关联矩阵,如下所示:

因此,每个历史样本和待预测样本之间的加权灰关联投影值Bi为

最后,将得到的投影值从大到小排序,选择投影值较大的样本作为相似样本进行替换。
1.2 Attention-Bi-LSTM 电力负荷预测模型
1.2.1 Bi-LSTM 模型
为了改善循环神经网络中的梯度爆炸和消失的问题,LSTM 用门控机制来控制信息的更新或丢弃,引入了输入门、遗忘门、输出门[24],以此去除一些对当下情况不重要的内容,使得信息保存时间延长,可以保存一些时间较为久远的信息。LSTM 门的输入均为当前时间步输入Xt与上一时间步隐藏状态Ht-1,输出由激活函数sigmoid 函数(σ)的全连接层计算得到。其总体框架为

与LSTM 不同,Bi-LSTM 方法由前向LSTM和后向LSTM 组合而成,在对数据特征提取的时候会考虑到隐藏在数据中的整体信息,通过正向和反向两个角度来进行特征提取,然后将双向提取的结果按照特定方式进行结合。从两个维度进行总结,在一定程度上消除单一LSTM 中输入数据顺序对最终结果的不利影响,使结果更全面。
1.2.2 Attention 机制
目前,Attention 机制在计算机视觉、手写识别等领域已被广泛使用。应用于深度学习中的Attention 机制可以理解为如何从输入数据中过滤出关键信息,并对这些关键信息赋予更高的权重以作出有效决策。为了强调输入数据对输出数据的不同影响力,优化数据的特征提取,提高预测性能,本文在Bi-LSTM 的基础上引入Attention 机制,可以计算出注意力的概率分布,消除输入数据对输出数据不合理的影响,从而提高关键输入数据的影响力。其结构如图1 所示,相关计算见文献[25]。

图1 注意力机制结构Fig. 1 Structure of Attention mechanism
1.3 XGBoost 电力负荷预测模型
XGBoost 通过不断添加树,不断进行特征分裂来生长一棵树,每添加一个树,就是学习一个新函数,去拟合上次预测的残差。当训练完成得到k棵树,每棵树中包含若干叶子结点,每个叶子结点就对应一个分数。最后只需要将每棵树对应的分数加起来就是该样本的预测值,即各样本和它们对应的权值乘积累加[21]。因此,随着迭代次数的增加,预测精度也不断提高。XGBoost 模型如下:

每一次迭代,都在现有树的基础上,增加一棵树去拟合前面树的预测结果与真实值之间的残差,其迭代过程如下:

XGBoost 的目标函数如下所示:


式(16)将每个样本的损失函数值叠加起来,将所有以同一个叶子结点的样本进行重组,过程如下:

为了方便计算,符合数据输入的要求,数据要预先被归一化处理,具体方法如式(20)所示,使数据被限制在 [0,1]的范围内。

式中:xmin为电力负荷数据中的最小值;xmax为电力负荷数据中的最大值;x为需要归一化处理的数据。
2 Attention-Bi-LSTM+XGBoost 电力负荷组合预测模型
2.1 权重赋予方式
在误差倒数法中,误差较小的预测模型被赋予较大权重,于是组合预测模型的总体误差可以显著降低。为确定权重系数,本文采用误差倒数法为模型分配权重,公式如下:

式 中: ωi为 权 重 值;fit为Attention-Bi-LSTM 和XGBoost 所得出的预测值; ε1, ε2分别为预测模型Attention-Bi-LSTM 和XGBoost 的误差值。
2.2 Attention-Bi-LSTM+XGBoost 电力负荷组合预测模型
与现有预测模型不同,Attention-Bi-LSTM 模型不仅可以充分考虑隐藏在输入数据中的整体信息,而且可以从两个维度获得更全面的结果,同时也强调了关键输入数据的影响。因此,使用Attention-Bi-LSTM 模型可以提高预测结果的准确性;此外,XGBoost 作为一种新兴的预测模型,具有较低复杂度,可以防止过度拟合,并具有良好的预测性能。本文首先使用Attention-Bi-LSTM和XGBoost 方法预测电力负荷,并获得相应的误差;然后根据误差结果,采用误差倒数法计算上述两种模型的权重;最终将上述两种模型的不同预测结果组合起来,从而克服单一预测模型各种固有缺陷。该预测模型框架如图2 所示。

图2 Attention-Bi-LSTM + XGBoost 组合预测模型框架Fig.2 Framework of Attention-Bi-LSTM + XGBoost combined prediction model
3 Attention-Bi-LSTM+XGBoost 电力负荷组合预测方法
本文所提出的组合预测方法预测过程如图3所示,预测步骤主要分为以下4 个阶段:

图3 组合预测模型框架图Fig.3 Frame diagram of combined forecasting model
第一阶段,预处理数据。首先,本文选择了几个影响最大的特征,如时间、日类型、假日类型、实时价格,然后利用WGRP 算法对节假日数据进行处理,使数据更具一般性,最后将数据标准化。
第二阶段,单一模型预测。使用注意力机制对LSTM 模型进行优化,消除不合理因素的影响,突出关键输入数据的影响,使结果更加全面。Attention-Bi-LSTM 和XGBoost 模型都用于预测同一数据集,并根据预测结果为两个模型组合作准备。
第三阶段,权重赋予。在用Bi-LSTM和XGBoost方法对电力负荷数据进行预测后,根据预测的误差使用误差倒数法获得权重,并对单个模型进行加权,形成了Attention-Bi-LSTM + XGBoost 组合预测模型。
第四阶段,预测评估。通过比较6 个基准模型和新加坡电力市场实际数据的预测误差,评估该方法能否提高电力负荷预测的准确性。
4 模型评价
本节基于新加坡电力市场数据集评估和讨论所提出的预测方法性能。由于LSTM,Bi-LSTM,Attention-Bi-LSTM,Attention-LSTM ,Attention-RNN 和XGBoost 与本文的模型具有很高的相关性,因此作为基准模型与本文提出的方法进行比较。
4.1 数据集和实验环境
本文选取新加坡电力市场2019 年1 月1 日至2021 年1 月7 日的数据,并考虑了日类型、时刻、节假日类型、实时电价等因素,历史电力负荷数据的采样周期为1 h,2019 年1 月1 日至2020 年12 月31 日的数据为训练数据,2021 年1 月1 日至2021 年1 月7 日的数据为测试数据,预测出2021 年1 月1 日至2021 年1 月7 日的电力负荷情况,最后进行结果比较和误差分析。
本次实验硬件平台为装有Intel i5-1035G1 处理器的台式电脑,内存为8 GB,固态硬盘容量为477 GB,CPU 显卡为MX230。基于Python 语言实现本文所提出的方法,Attention-Bi-LSTM 模型使用Keras 深度学习框架,XGBoost 使用py-xgboost框架。
4.2 评价标准
本文选取平均相对误差绝对值(mean absolute percent error, MAPE)作为各个预测模型的主要评判指标,并选取平均绝对误差(mean absolute error,MAE)和均方根误差(root mean squared error, RMSE)作为辅助评判指标。MAPE,MAE 和RMSE 的计算公式分别如下所示。

式中:n为 电力负荷数据的数量;yt为实际的电力负荷数据;yˆt为预测出的电力负荷数据。
4.3 数据预处理对预测结果的影响
首先对新加坡电力负荷数据使用加权灰色关联投影算法进行处理,选取与五一劳动节关联度较大的历史数据,使数据更加具有一般性。为了验证WGRP 算法的重要性,分别使用Attention-Bi-LSTM 和经过加权灰色关联投影算法处理的Attention-Bi-LSTM,以及XGBoost 和经过加权灰色关联投影算法处理的XGBoost,对五一假期的数据进行预测。最后将上述4 种模型的结果与真实值进行比较,并进行误差分析。
图4 比较了引入WGRP 算法前后Attention-Bi-LSTM 预测结果与真实值变化趋势,可以发现经过处理的模型比未经处理的模型更接近实际值。表1 显示了WGRP 算法处理的Attention-Bi-LSTM的MAPE,MAE 和RMSE 值分别为0.639,67.147和96.232,意味着经过WGRP 处理的Attention-Bi-LSTM 预测模型具有更高的预测精度。因此,对于Attention-Bi-LSTM,在选择2020 年5 月1 日的历史假日数据后,可以使用WGRP 算法来提高模型的精度,表明了WGRP 算法预处理的有效性。

图4 加权灰色关联投影算法预处理前后的Attention-Bi-LSTM 预测结果与真实值对比Fig. 4 Comparison between real values and prediction results of Attention-Bi-LSTM model before and after processing by WGRP algorithm

表1 加权灰色关联投影算法预处理前后的Attention-Bi-LSTM 预测误差分析Tab.1 Error analysis of Attention-Bi-LSTM model before and after processing by WGRP algorithm
图5 比较了引入WGRP 算法前后的XGBoost 预测结果与真实值关系,WGRP 算法处理的XGBoost线条趋势与实际值基本一致,从表2 也可以看出,WGRP 算法处理的XGBoost 的MAPE,MAE和RMSE 值分别为0.409,42.976 和43.817,意味着经过WGRP 处理的XGBoost 模型具有更高的预测精度。因此,对于XGBoost,WGRP 算法同样有助于提高模型的预测精度。

图5 加权灰色关联投影算法预处理前后的XGBoost 预测结果与真实值对比Fig. 5 Comparison between real values and prediction results of XGBoost model before and after processing by WGRP algorithm

表2 XGBoost 及加权灰色关联投影算法处理的XGBoost 误差分析Tab.2 Error analysis of XGBoost model before and after processing by WGRP algorithm
当不考虑WGRP 算法时,虽然预测结果与实际值的变化趋势基本一致,但是差异很大。使用WGRP 算法后,减少了预测结果与实际值之间的差距。因此,为了减少预测误差,首先使用WGRP算法处理历史数据中的假日数据。然后,为了验证该算法在提高预测精度和减少误差方面的优势,使用相同的模型对处理后和未处理的数据进行预测。结果发现,数据处理的预测结果更接近真实值,预测精度可以进一步提高。因此,采用WGRP 算法对假日数据进行处理,使数据更加通用,提高了预测精度。
4.4 预测结果分析
接下来以预处理后的电力负荷数据来验证提出的电力负荷预测方法的适用性。首先,使用Attention-Bi-LSTM 和XGBoost 模型对同一组数据进行预测,并得出两个模型的预测误差;其次,根据误差对上述两种预测模型进行加权,并将其与误差倒数法相结合,误差较小的模型被赋予更高的权重;第三,为了验证本文提出的组合预测模型的有效性,使用LSTM,Bi-LSTM,Attention-RNN,Attention-LSTM,Attention-Bi-LSTM,XGBoost和“Attention-Bi-LSTM + XGBoost”组合预测模型分别进行预测,并对预测结果进行比较。
4.4.1 预测结果和实际数据比较
a. 图6 显示LSTM,Bi-LSTM,Attention-RNN,Attention-LSTM,Attention-Bi-LSTM,XGBoost模型和“Attention-Bi-LSTM + XGBoost”组合预测模型的预测结果与实际值之间的比较,易知“Attention-Bi-LSTM + XGBoost”组合预测模型的预测精度最高,而Bi-LSTM 模型的预测精度最低。
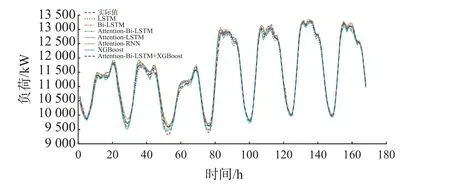
图6 预测结果和实际数据的趋势比较图Fig. 6 Trend comparison chart of prediction results and actual values
b. 新加坡2020 年1 月7 日24 h 预测结果的局部放大图如图7 所示,从图7 中可以看出,“Attention-Bi-LSTM + XGBoost”组合预测模型的预测值曲线与实际值曲线最接近,即本文提出的模型拟合效果最好。
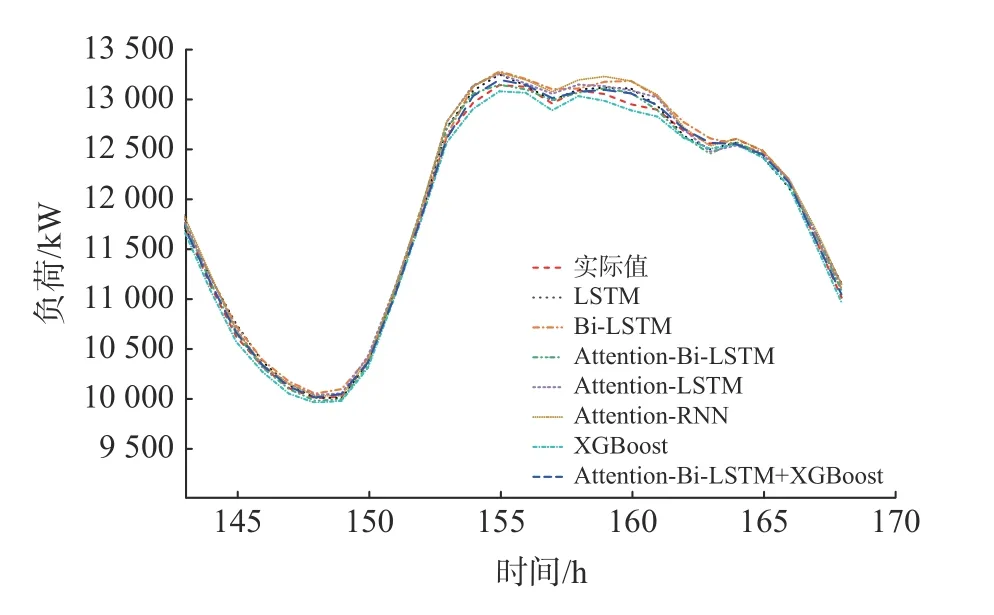
图7 新加坡2020 年1 月7 日预测结果的局部放大图Fig. 7 Local enlarged drawing of Singapore’s prediction results on January 7, 2020 (24 hours)
4.4.2 误差比较分析
上述6 种模型的MAPE,MAE 和RMSE 值如表3 所示,通过比较表3 中误差值可知:
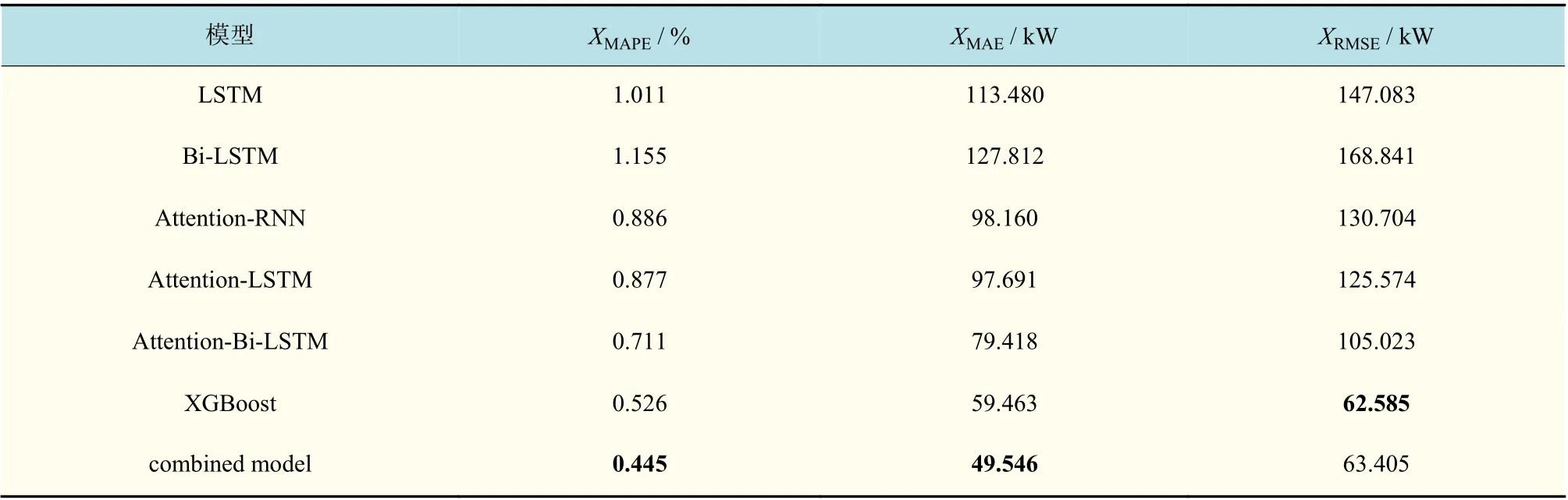
表3 新加坡电力市场的误差分析Tab.3 Error analysis in Singapore power market
a. 由于LSTM 是循环神经网络(recurrent neural network, RNN)的改进,因此Attention-LSTM 的误差小于Attention-RNN,说明本文选择LSTM 作为基础预测模型的必要性。
b. 根据LSTM,Attention-LSTM 和Attention-RNN 模型3 种预测模型综合比较,可知注意力机制对预测精度有显著影响。
c. 在所有基准模型的精度测试标准中,XGBoost的误差值最小,这意味着XGBoost 具有极其优异的预测性能,因此本文使用XGBoost 来组合提高Attention-Bi-LSTM 预测模型的精准性。
d. 表3 显示,“Attention-Bi-LSTM + XGBoost”组合预测模型的MAPE 和MAE 值分别为0.445 和49.546,从整体角度来看最小。尽管XGBoost 的RMSE 值最小为62.585,但所提出的组合预测模型的值仅略高于最小值,显然可以接受。因此,两种预测模型的组合可以从整体上降低预测误差,从而优于单一预测模型,提高现有模型的预测精度。
e. 与文献[21] 不同的是,本文首先对数据进行了处理,并且将双向和注意力机制添加到LSTM模型进行改进,以提高预测精度。通过误差对比,可以发现本文所用方法相较文献[21]在精确度上可以提高12%左右,因此证明本文使用各种改进方法的必要性和有效性。
5 结 论
为了提高电力负荷预测的准确性和稳定性,本文提出了一种基于WGRP 算法的Attention-Bi-LSTM + XGBoost 电力负荷组合预测方法。在数据预处理阶段,采用WGRP 算法选择节假日历史负荷序列,在预测阶段则采用Attention-Bi-LSTM +XGBoost 电力负荷组合预测模型进行预测并得到了较好的预测结果。使用新加坡电力市场的数据集对比评估后,可以得出以下结论:
a. 利用WGRP 算法对假日数据进行预处理,可以有效提高模型的预测精度;
b. 注意力机制允许Bi-LSTM 模型强调重要因素的影响,从而消除冗余,提高预测性能;
c. 在XGBoost 中加入正则项可以降低模型复杂性,有效防止过度拟合,减少计算量,从而大大提高算法的效率,因此使用XGBoost 模型进行组合优化可以极大减少模型误差;
d. 与所有基准模型预测结果相比,“Attention-Bi-LSTM + XGBoost”组合模型的预测结果误差最小,与实际值最接近,表明了本文预测方法的优越性。
综上所述,本文提出的组合预测方法比单一的传统和现代预测方法、混合预测方法,以及其他现有的组合预测方法更有效,获得更高的电力负荷预测精度,从而减少电力市场中不必要的浪费,提高电力系统运行的可靠性和安全性。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
纺织标准与质量(2022年2期)2022-07-12
温州大学学报(自然科学版)(2022年2期)2022-05-30
煤气与热力(2022年4期)2022-05-23
今日农业(2021年17期)2021-11-26
粉末冶金技术(2021年3期)2021-07-28
建材发展导向(2021年23期)2021-03-08
长江大学学报(自科版)(2021年6期)2021-02-16
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
