
基于电子舌和电子鼻结合DenseNet-ELM的陈醋年限检测
2022-05-01 07:23王首程于雪莹高继勇王志强
食品与机械 2022年4期
王首程 于雪莹 高继勇 王志强
(山东理工大学计算机科学与技术学院,山东 淄博 255049)
陈酿可以使食醋形成独特的风味,在陈酿过程中食醋的功能成分也会随之发生变化[1]。由于不同酿造年限陈醋的价格有较大差异,伪造年限的事件时有发生。目前已有的陈醋年限检测方法主要有感官分析法[2]、荧光光谱法[3]、高效液相色谱法[1]和近红外透射光谱分析法[4]等。但感官分析法存在主观性强、易受干扰和稳定性差等缺点;荧光光谱法、高效液相色谱法、近红外透射光谱分析法等分析方法存在设备体积大、价格昂贵、检测过程复杂等问题,不适合现场快速测量。
电子鼻和电子舌是通过模仿生物的嗅觉和味觉研制的仿生检测系统,利用不同传感器间的交叉响应现象结合模式识别技术实现对样本品质及成分的分析,具有操作简单、检测高效、客观性强等优点,目前电子舌和电子鼻已被广泛应用于环境监测[5]、食品检测[6]和药物鉴别[7]等多个领域。陈醋的化学成分复杂,其品质特征都能在嗅觉和味觉上体现,但单独使用电子舌或者电子鼻难以获得完整的样本品质状态信息,导致无法获得满意的检测效果[8]。对电子舌和电子鼻的信号进行信息融合可以有效解决这一问题[9]。
信息融合的关键在于有效提取不同传感器信号的特征。Hilbert变换、快速傅里叶变换、小波分析均可用于信号特征提取。但这些方法主要基于人工设计,效率低,无法全面提取有效特征[10]。深度学习方法通过引入多个卷积层和池化层,自动地抽取数据的特征并完成分类或回归,从而实现端到端的模式识别。传统深度模型随着网络深度的加深,容易出现梯度消失和爆炸现象[11]。密集卷积网络(Dense Convolutional Network,DenseNet)是近年来提出的一种新型深度学习模型。该网络通过跨层连接、特征重用的方法,直接将特征图在通道的维度上连接起来,在保证最大程度信息传输率的前提下,实现了网络中各卷积层之间的特征传递,具有缓解梯度消失、抑制过拟合、减少参数量、增强特征传递的优点。目前DenseNet已经被广泛用于医学诊断[12]、音频检测[13]等领域。但当前尚未有研究将DenseNet应用于人工智能感官的模式识别过程。
研究拟提出基于电子舌、电子鼻结合DenseNet-ELM模型对陈醋酿造年限进行检测的方法,分别设计不同结构的DenseNet提取电子舌和电子鼻信号深层特征,并对特征进行融合,最后采用极限学习机(Extreme Learning Machine,ELM)对融合特征向量进行分类识别,以期为便捷、准确地检测不同酿造年限的陈醋提供新方法。
1 材料与仪器
1.1 试验材料
试验材料为产自山西太原的某品牌老陈醋,执行标准为GB/T 19777—2013。从本地超市购买2021年所产的一年新醋、两年陈酿、三年陈酿、五年陈酿、六年陈酿、八年陈酿、十年陈酿共7种不同年限的陈醋。每个酿造年限的陈醋取200个样本,每个样本10 mL,按照V陈醋∶V蒸馏水=1∶20的比例对样本进行稀释,每个陈醋溶液取100 mL,在(20±3) ℃环境下使用电子舌、电子鼻采集样本数据[14]。每种年限的陈醋采集电子舌和电子鼻的样本数据各200个,取其中150个样本数据按照7∶3的比例划分为训练集与验证集,剩余50个样本数据作为测试集。
1.2 电子舌与电子鼻系统
电子舌与电子鼻系统由实验室自行研制[15],其结构如图1所示。电子舌系统(Electronic tongue,ET)由传感器阵列、信号调理电路和数据采集装置组成。其中传感器阵列由三电极系统组成,包括8个工作电极(铂、金、钛、钯、银、钨、镍和玻碳)、1个银/氯化银(AgCl)电极作参比电极和1个铂辅助电极。其工作原理为:由软件控制数据采集卡产生激励信号,该信号通过信号调理模块调理后施加至传感器阵列,在激励信号的激发下,样本溶液在多个工作电极表面发生电化学反应产生微弱电流信号,该响应经I/V转换、放大和滤波后,送至数据采集卡进行数据采集,然后送至上位机进行处理。

图1 电子舌与电子鼻系统结构Figure 1 Electronic tongue and electronic nose system structure
电子鼻系统(Electronic nose,EN)由检测腔及气路、传感器阵列、信号调理电路和数据采集装置组成,传感器阵列采用6种金属氧化物半导体传感器,其型号分别为TGS2600、TGS2602、TGS2603、TGS2610、TGS2611、TGS2620。该系统工作原理为:通过采样泵将待测样品气体导入检测腔中,待测样本气体与传感器的敏感材料接触并发生氧化还原反应,从而导致气敏传感器的导电率发生变化,待测气体的化学信息转化成电信号。该电信号经信号调理电路进行放大、滤波后,送至数据采集卡进行数据采集,然后送上位机进行模式识别处理。
2 模式识别与信息融合方法
2.1 密集卷积网络
DenseNet通过建立网络中所有层之间的密集连接,可实现特征的高效复用,有利于对维度大、噪声多的复杂信号进行特征提取。DenseNet由交替串联的稠密块和过渡层共同组成,结构如图2所示。

图2 DenseNet结构图Figure 2 DenseNet structure
稠密块是DenseNet的核心结构,其结构如图3所示。稠密块包含多个由批归一化层(Batch Normalization,BN)、修正线性单元(Rectified Linear Unit,ReLu)、1×1卷积层和1×3卷积层构成的密集层。其中BN层可实现对每一层输入的标准化处理,使输入的均值趋近于0,标准差趋近于1,从而降低样本间的差异;ReLu为网络的激活函数,可将神经元的输入映射到输出端,使模型具有非线性表达能力;1×3卷积层可提取信号中的有效特征;由于稠密块中后层的输入是该层之前所有层的输出,会造成后层通道数较大,采用1×1的卷积层可减少特征图的数量并融合各个通道的特征,从而降低特征的维度。

图3 稠密块结构图Figure 3 Dense block structure
稠密块中每一层密集层与前面所有层建立连接,L层的网络中包括L(L+1)/2层连接,这种跨层连接方式增强了特征的传递,使得网络在参数和计算成本相对较少的情况下表现出更优的分类性能。每一层密集层输出的计算公式如式(1)所示。
xl=Hl([x0,x1,x2,…,xl-1]),
(1)
式中:
xl——第l层密集层输出的特征;
[x0,x1,x2,…,xl-1]——第l层到第l-1层输出特征的拼接;
H(·)——非线性变换函数的组合运算,包括卷积、BN和ReLU等操作。
过渡层由BN层、ReLU、1×1的卷积层、1×2的池化层以及Dropout层构成。其结构如图4所示。采用BN层对输入作标准化处理;1×1的卷积层可压缩特征的通道数;1×2的池化层用于降低特征的维度;加入Dropout层可减少因网络层数增加产生的计算量[16]。

图4 过渡层结构图Figure 4 Transition layer structure
2.2 极限学习机
ELM是由Huang等[17]提出的一种单隐层前馈型神经网络。与传统的机器学习算法相比,ELM通过求解方程组的方法得到输出层的权重,其输入层和隐含层之间的隐藏节点和连接权值可以随机产生,不需要在训练过程中进行调整,具有训练速度快、泛化性能强的优点。
含有L个神经节点的单隐层神经网络可表示为:
(2)
式中:
yj——单隐层网络的输出值(j=1,…,N);
xi——输入向量;
g(·)——激活函数;
w——输入权重;
b——隐含层节点的阈值;
βi——输出权重。
ELM的学习目标就是网络的实际输出值能够无限接近期望输出值。
2.3 特征信息融合
电子舌和电子鼻特征融合结合DenseNet-ELM模型的过程如图5所示。

图5 模型工作过程Figure 5 Model working process
(1) 使用电子舌和电子鼻系统对陈醋样本逐一进行检测,分别采集电子舌和电子鼻的响应信号,并对信号进行预处理。
(2) 针对电子舌和电子鼻的信号,构建不同结构的ET-DenseNet和EN-DenseNet,分析模型在训练集和验证集上准确率的变化,得到性能最佳的两个网络结构。
(3) 使用电子舌和电子鼻响应信号的训练集和验证集分别训练ET-DenseNet和EN-DenseNet,然后将训练好的模型用于提取电子舌和电子鼻信号的特征,分别得到二者的特征向量。
(4) 将ET-DenseNet和EN-DenseNet提取到的特征图进行展平操作,把多维特征转化为一维特征向量。然后将二者的一维特征向量进行拼接,得到融合特征向量,其原理如式(3)所示。融合操作,其功能是将一维电子鼻特征向量拼接在一维电子舌特征向量之后,构成融合特征向量。
F=C(ft,fn),
(3)
式中:
F——融合的特征向量;
ft——电子舌信号的特征向量;
fn——电子鼻信号的特征向量;
C(·)——融合操作。
(5) 采用ELM对融合的特征向量进行分类识别,先对其隐含层神经元个数进行优化,再采用训练集和验证集对优化的模型进行训练,并使用测试集的准确率、召回率等指标评价模型的性能。
3 结果与分析
3.1 电子舌与电子鼻响应信号
电子舌和电子鼻系统的响应信号如图6所示。图6(a)中,在电子舌不同电极的催化作用下,样本溶液在电极表面发生电化学反应,在大幅方波脉冲的激励作用下每个电极的信号呈现出不同的波形。针对每个样本,电子舌可以采集8 000个数据点(1 000×8个电极);从图6(b)可以看出,电子鼻传感器内部化学物质与样本气体接触,发生氧化还原反应,造成传感器的电导率发生变化,其两端的电压快速上升,达到各自的峰值后逐渐趋于平缓,针对每个样本,电子鼻可以采集到6 000个数据点(1 000×6个气敏传感器)。

图6 电子舌和电子鼻响应信号Figure 6 The electronic tongue and nose respond to the signal
3.2 数据预处理
针对电子舌和电子鼻的响应信号中含有大量噪声并且数值变化幅度较大的问题,采用式(4)对响应信号进行去均值和方差归一化处理。
(4)
式中:
xi——信号中的第i个响应值;
μ——信号中所有样本数据的均值;
σ——信号中所有样本数据的标准差;

3.3 DenseNet模型
3.3.1 ET-DenseNet 电子舌信号噪声多、数据量大,所以需要设置多个卷积层和池化层以提取其特征。DenseNet中稠密块的个数以及稠密块中密集层的层数直接影响DenseNet的性能,较多的卷积操作将导致模型的过拟合,较少的卷积操作则会产生特征提取不充分的问题。为了选择性能最优的模型结构,设计稠密块×密集层结构分别为2×2、2×3、2×4、3×2的模型,分析其训练过程中验证集准确率的变化。为了减小过拟合,避免偶然事件的发生,采用五折交叉验证方法分析测试集准确率。如图7所示,当稠密块×密集层结构为2×4时,验证集准确率相比于其他模型增长得更快,率先达到峰值并稳定,而且测试集准确率明显高于其他模型,且模型更加稳定。2×2、2×3两种模型由于层数较少,存在特征提取不充分的问题,结构为3×2的模型由于过拟合导致性能下降。

图7 不同结构的ET-DenseNet模型的验证集准确率和测试集准确率Figure 7 Validation set and test set accuracy of different structures of ET-DenseNet
ET-DenseNet结构如图8所示,较大的卷积核可初步降低数据维度;然后设置2个稠密块,每个稠密块中设置4层密集层;两个稠密块之间设置一层过渡层降低特征维度,并设置BN层对特征作归一化处理,采用全局均值池化降低特征维度。

图8 ET-DenseNet结构Figure 8 ET-DenseNet structure
DenseNet的增长率是指每一层网络输出的特征图在维度上的贡献量,直接关系到特征图的数量,同时,训练周期、学习率、批次尺寸等超参数对模型分类准确率的影响较大。分别对训练周期、学习率、批次尺寸进行寻优,不同参数组合在测试集的准确率如图9所示,增长率为10、训练周期为70、学习率为0.001、批次尺寸50时,测试集的准确率最高且波动较小。
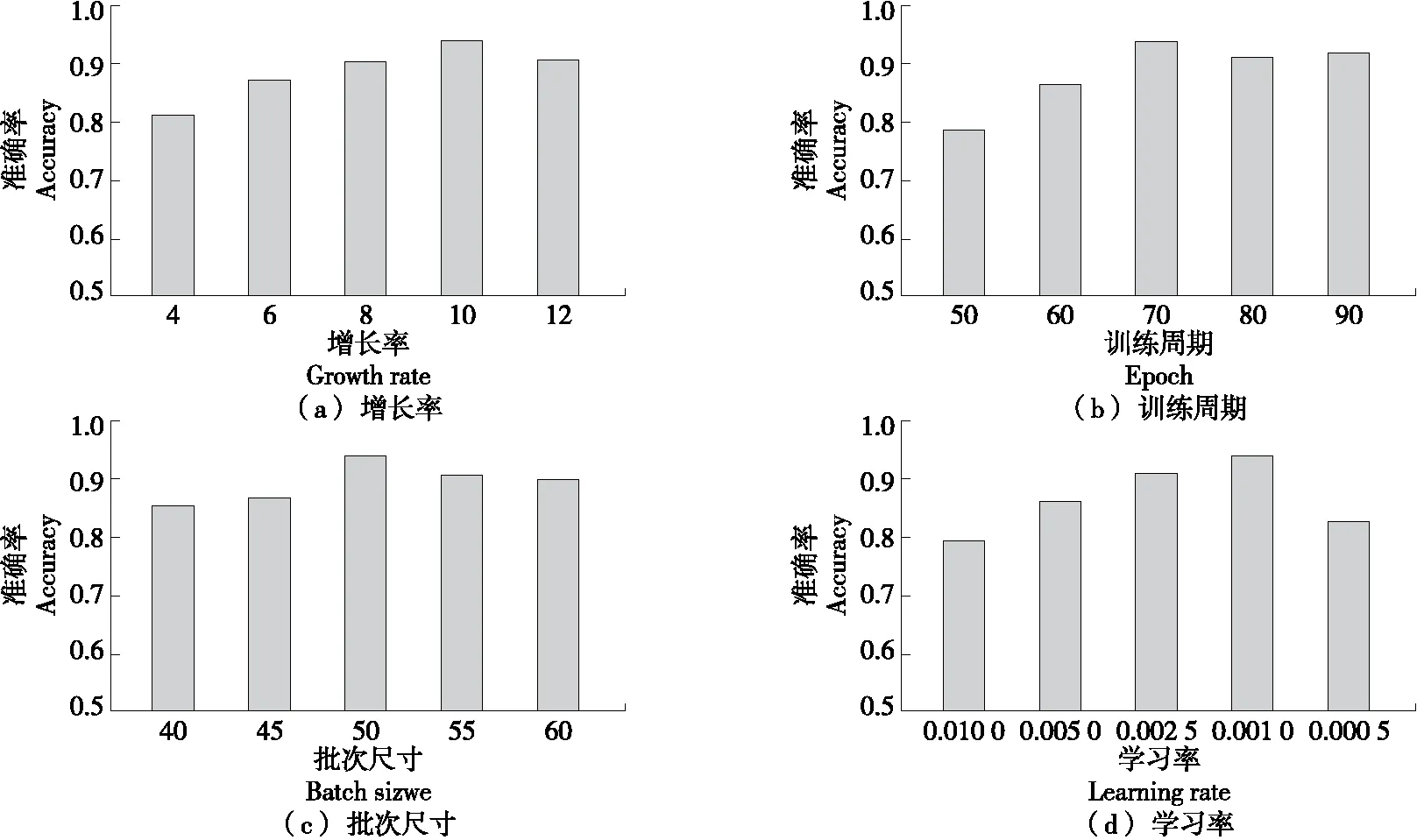
图9 不同超参数的ET-DenseNet测试集准确率Figure 9 Test set accuracy of different hyperparameters of ET-DenseNet
3.3.2 EN-DenseNet 相比于电子舌信号,电子鼻信号数据量相对较少,采用较少的卷积层和池化层就可以提取到电子鼻信号的特征信息。为了选择性能最优的EN-DenseNet,设计稠密块×密集层结构分别为1×2、1×3、1×4、2×2的模型,分析其训练过程中验证集准确率的变化,并采用五折交叉验证方法分析测试集准确率。如图10 所示,当稠密块×密集层结构为1×3的模型在训练的过程中,验证集准确率明显增长得更快,而且迅速收敛并稳定在峰值,测试集准确率明显高于其他模型,并且波动较小。

图10 不同结构的ET-DenseNet模型的验证集准确率和测试集准确率Figure 10 Validation set and test set accuracy of different structures of ET-DenseNet
EN-DenseNet结构如图11所示,设置1×16的卷积核初步降低数据维度;然后设置1个稠密块,其中设置3层密集层,使用级联的方法实现特征复用,并设置BN层对特征作归一化处理,采用全局均值池化降低特征维度。
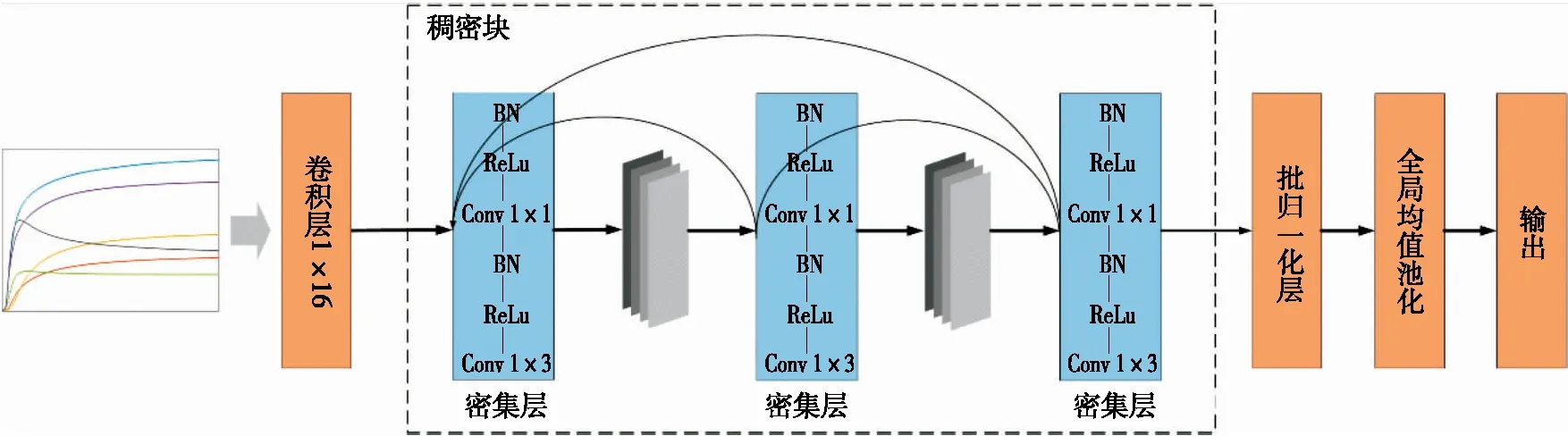
图11 EN-DenseNet的结构Figure 11 EN-DenseNet structure
采用与ET-DenseNet相同的方法对该网络的增长率、训练周期、学习率和批次尺寸进行优化。如图12所示,增长率为6、训练周期为60、学习率为0.000 5、批次尺寸为35时,测试集的准确率最高,并且波动也较小。

图12 不同超参数的ET-DenseNet测试集准确率Figure 12 Test set accuracy of different hyperparameters of ET-DenseNet
3.4 ELM模型
将ET-DenseNet和EN-DenseNet提取的特征进行融合,采用ELM对特征向量进行分类。ELM模型的输入层和隐含层之间的连接权值和阈值可以随机生成,所以只需要优化隐含层神经元个数。设置ELM隐层神经元个数的范围为[2,100],步长为2。其不同结构的ELM模型在验证集和测试集的分类准确率如图13所示,当隐藏层节点数为74时,分类效果最佳。

图13 不同隐含层神经元个数的ELM在验证集和测试集上的准确率Figure 13 The accuracy of ELM in verification set and test set with different numbers of hidden layer neurons
3.5 可视化分析
为了验证模型的特征提取效果,采用t分布随机近邻嵌入算法(Stochastic neighbor embedding,t-SNE)[18]对ET-DenseNet、EN-DenseNet提取到的特征以及融合的特征向量进行可视化分析,并建立混淆矩阵验证其分类性能,结果如图14所示。由图14可以看出,电子舌和电子鼻的每类样本特征数据点类间的差距较小,数据点基本能够汇聚成簇,但是有部分的错分点,ET-DenseNet和EN-DenseNet的分类准确率分别为95.2%,93.4%。可以看出电子舌特征可视化的效果优于电子鼻的效果,这是由于电子舌的响应信号比电子鼻的响应信号含有更多能反映不同酿造年限陈醋样本之间差异性的信息。由图14(c)和图14(f)可以看出,电子舌和电子鼻融合特征的每类样本特征的数据点完全汇聚成簇,且类与类之间分隔较大,具有明显的类间差距。DenseNet-ELM的混淆矩阵分类准确率达到99.14%,分类准确率较ET-DenseNet和EN-DenseNet有明显的提升。

图14 特征可视化和混淆矩阵Figure 14 Feature visualization and obfuscation matrices
3.6 模型性能对比分析
目前,已有研究使用离散小波变换(Discrete wavelet transform,DWT)提取电子鼻[19]和电子舌[20]信号的特征,使用支持向量机(Support Vector Machine,SVM)和CNN作为分类识别方法[21]。将以上模型进行优化后用于电子舌和电子鼻对陈醋年限的检测,优化后DWT的小波基函数为sym6、分解层数为7,SVM模型的惩罚因子C=2-5、核参数λ=25以及CNN网络结构为5个卷积层和4个池化层、学习率为0.005、批次尺寸为45、训练周期为50,并使用以上模型与文中所提方法进行对比。
为了进一步评价不同模型的性能,分别采用查准率、召回率、F1-Socre参数为评价标准对模型进行评价分析,其公式为:
(5)
(6)
(7)
式中:
P——查准率;
R——召回率;
F1——F1-Socre参数;
TP——正确分类的正样本数量;
FP——真实的负样本数量;
FN——虚假的负样本数量。
分别使用优化后的DWT-SVM、DWT-ELM、CNN作为对比模型,用于电子舌信号、电子鼻信号的分类。将以上各个模型与文中所建模型进行对比,各模型在测试集的分类结果如表1所示。
由表1可以看出,DenseNet-ELM模型的查准率、召回率和准确率分别达到0.99,0.98,0.99,性能明显高于其他对比模型。不同的特征提取方法对电子舌和电子鼻信号的特征提取能力存在较大差别。与DWT、CNN相比,由于DenseNet对特征的高效复用,具有更高的特征提取能力,其分类准确率提高3%~30%。单独使用电子舌或者电子鼻进行检测的准确率最高可达到95.2%,将电子舌和电子鼻信号的特征进行融合后,结合DenseNet-ELM模型,检测准确率达到99.1%。与其他检测方法相比,采用可见/近红外光谱透射技术结合主成分分析和神经网络鉴别陈醋品种[4]准确率为92.1%,同步荧光结合偏最小二乘法对老陈醋掺假检测[22]的偏差为3%~5%,采用近红外光谱结合主成分分析和判别分析鉴别陈醋的品牌[23]准确率为96.3%,证明文中方法性能优于以上方法。
4 结论
研究提出一种基于电子舌和电子鼻结合密集卷积网络—极限学习机模型对不同酿造年限陈醋进行检测的方法。分别设计了电子舌系统—密集卷积网络和电子鼻系统—密集卷积网络模型提取电子舌和电子鼻的信号特征,然后采用特征融合方法,将电子舌和电子鼻信号特征向量进行融合,使用极限学习机对融合特征向量进行分类识别。试验结果表明,该方法解决了单一检测设备难以获得完整的样本信息的问题,采用密集卷积网络缓解了深度学习模型由于深度增加导致的模型退化、泛化能力弱等问题,可对7种不同酿造年限的陈醋进行有效分类。研究的特征融合阶段将电子舌和电子鼻的特征向量直接进行拼接,不能体现出两者之间的重要程度,后续将研究采用自适应的特征融合方法,通过学习的方式自动获取到两种不同特征的重要程度,实现更高效的融合。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
农业工程学报(2022年7期)2022-07-09
保定学院学报(2022年2期)2022-04-07
现代仪器与医疗(2021年6期)2022-01-18
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
中医眼耳鼻喉杂志(2019年3期)2019-04-13
数学学习与研究(2018年15期)2018-11-12
