
北京地区空气质量影响因素分析及预测研究
2022-04-28 09:36:00金仁浩曾国静赵欣然
黑龙江科学 2022年8期
金仁浩,曾国静,赵欣然
(北京物资学院 信息学院,北京 101149)
0 引言
北京地区的空气质量一直受到人们的高度关注。近年来,北京市及其周边地区的空气质量得到了明显的改善,但空气污染治理是一个长期系统的过程[1],各级环保部门定期公布当地6种空气污染物,即PM2.5、PM10、SO2、CO、O3、NO2指标值及综合空气质量指数AQI指标值[2]。目前,研究北京地区空气质量的文献较多,主要可包括空气质量的影响因素分析和预测两方面。
相关研究主要基于北京环保部门发布的市内35个空气质量站点每日空气污染物数据。姚祎等基于2016-2020年北京市春节期间的空气质量数据,利用多元线性回归模型,得出气象因素对污染物浓度的影响占主导地位,社会经济活动水平对空气质量也存在显著性影响[3]。许昌日等基于2014-2017年北京市每日数据得出气象条件、PM2.5和O3对雾霾天气的产生有重要的影响[4]。王娟利用多元回归模型对全国各大城市空气质量数据进行分析得出,气象条件及污染物排放是影响PM2.5浓度的主要因素[5]。
国内基于统计预测模型和机器学习方法的空气质量预测研究比较丰富,譬如:王娟指出基于气象因素和污染浓度的多元回归模型对PM2.5浓度预测有着较高的精度[5];刘慧君通过逐步回归模型实现了对武汉市PM2.5指标的预测,并取得了较好的效果[6];朱晏民等对深度学习方法在空气质量预报方面的应用进展进行了总结,指出现有的机器学习方法能够实现对空气质量的有效预测,但其预测精度仍可有很大的提升,并对构建新的深度学习模型给出了展望[7];付悦等以北京市空气质量等级作为分类型目标变量,分别使用统计判别分析和机器学习分类方法进行实证研究,得出决策树模型的预测结果次于随机森林模型但优于判别分析和支持向量机模型,且能较清晰地展示分类结果[8]。总体而言,机器学习模型较一般统计模型预测精度更高,但存在模型理论较复杂、模型实现较难、解释性较差等问题。
目前,对北京空气质量影响因素和预测方面的研究尚存在一定的不足。譬如,相关文献的研究对象往往局限于一个站点或仅仅局限于北京城六区,或把北京市全域作为一个整体,并没有对北京的各个区域展开研究。另外,往往仅对北京空气质量的具体指标值进行相关因素分析和预测,并没有同时对空气质量等级进行相关因素分析和预测。针对这些不足,在现有文献的基础上,研究北京不同区域的空气质量问题,并同时考虑空气质量和空气质量等级的影响因素分析及预测研究。根据回归模型和机器学习模型的特点,对空气质量的研究主要通过回归模型进行展开,对空气质量等级的研究则通过决策树模型进行分析,研究结果可为北京地区大气污染治理提供一定的参考,具有重要的实践价值。
1 数据与方法
1.1 数据
北京市共有35个空气监测站,基于北京市2017-2020年各站点数据开展研究,由于2018年的数据质量相对较好,建模分析主要基于2018年的数据展开。每个监测站点会记录每日每小时的 PM2.5、PM10、SO2、CO、O3、NO2及AQI指标数值,各站点各指标当日均值通过当天每时均值获得,可在每日均值的基础上计算出各站点月均值和年均值。对相应站点均值进行平均计算,可得到局部区域或整个北京市域对应时间段均值。在这些空气质量指标数据中,AQI反映综合空气质量,故将该指标作为目标变量。根据AQI日均值,可将空气质量分为6个级别:优,良,轻度污染,中度污染,重度污染,严重污染。这6个级别对应的AQI区间分别为0~50、50~100、101~150、151~200、201~300、300以上[9]。
为研究北京不同区域的空气质量问题,根据北京市各区地理位置及政府相关文件,将北京市域划分为如表1中所示的5个区域。各个区域的空气质量可通过对区域内所有监测站点值取均值获得。
1.2 建模分析
对北京各区域的2017-2020年空气质量数据进行描述分析,从整体上了解北京近几年空气质量变化情况。通过相关分析研究北京空气质量与气象、社会经济因素之间的关系。通过回归模型和决策树模型分别对北京市空气质量数据和空气质量等级数据进行影响因素和预测分析。
回归模型是一种常见的统计模型,主要研究因变量和自变量之间的关系,既可以用作发现变量之间的因果关系,也可以用作对因变量的预测。回归模型具有简单易懂、统计理论完善、解释性强、容易实现等优点。决策树模型是一种简单易用的机器学习方法,是一种基本的分类与回归方法。该模型对连续性目标变量的预测精度往往较低,但由于其结果比较直观,可解释性强,比较适合对离散型目标变量建模。同时该模型具有计算速度快、容易解释、稳健性强等优点[10]。基于这两模型的特点,主要通过多元线性回归模型和分类决策树模型分别对AQI数据和AQI等级数据进行建模分析。
2 空气质量分布特征及影响因素分析
2.1 各区域空气质量分布特征
基于各个空气检测站点的日均空气质量数据可计算出表1中列出的北京市各个区域的年度空气质量指标均值。各污染物浓度值变化情况基本相似,且AQI指标是反映空气质量的综合指标,故仅列出北京市5个区域2017-2020年AQI年均值变化情况,如图1所示。
从整体上看,各个区域这4年AQI年均值都分布在70~120,且各地区年均值都呈现逐年下降的趋势,表明近年来经过政府和民众的努力,北京市空气质量得到了显著提升。在图1中横向比较各区域AQI年均值可得,东北部和西北部区域空气质量相对较好,城六区居中,而东南部和西南部区域空气质量相对较差。造成这一结果的原因可能是北京北部地区以山区居多,而中部和南部地区以平原为主,北部地区人口较少,且北部地区还处上风向。
基于北京市5个区域2018年每日AQI指标均值进行空气质量等级划分,并将2018年各区域空气质量等级分布情况列于表2中。由表2可知,各区域空气质量等级为良好的天数占比最高,达到45%左右;其次为轻度污染和优,占比分别达到25%和15%左右;重度污染和严重污染所占比重普遍较低。其中,东北部区域空气质量相对较好,等级为优的天数占比高达28%,明显高于其他区域。表2说明北京市各区域空气质量情况整体较好。
()中数据为天数占年度的百分比
2.2 气象因素对空气质量的影响
气象因素对空气质量存在着显著影响,但气象数据收集相对比较困难,仅从相关气象数据网中收集到北京市2018年每日平均气温和平均风速两个气象变量。基于2018年35个监测站点每日AQI均值可计算得北京市2018年每日AQI均值。通过相关性分析可得,北京2018年每日平均温度与AQI均值的相关系数为-0.242,呈现出显著的负相关性。平均气温高时,空气质量相对较好,这是因为气温高时会促进底层大气向高层温度低处流动,带来离地面较近的空气污染物向高空扩散。平均风速与AQI均值的相关系数为-0.359,也呈现出显著的负相关性,即风速越大空气中的污染物浓度越低,空气质量越好。风速较大,大气污染物的扩散率也就越高,进而空气污染物浓度会下降,结果与自然规律和民众的认知一致。
2.3 经济因素对空气质量的影响
社会经济因素对空气质量也存在着显著影响,但北京市经济数据主要是年度数据,因此选取了2010-2019年北京AQI年均值数据及7个年度经济数据:GDP、第二产业占比、绿地覆盖率、综合能源消费量、工业粉尘排放量、总人口、汽车保有量。相关性检验可得,AQI与GDP、综合能源消费量、汽车保有量呈现出显著的负相关性,相关性系数依次为-0.989、-0.986、-0.949;但与工业粉尘排放量呈现出显著的正相关性,相关系数为0.848;与其他3个经济因素未呈现出显著的相关性。这是因为北京市近年来在保持GDP、综合能源消费量和汽车保有量增长的同时,注重社会高质量的经济发展、大力利用绿色低碳能源、促进新能源汽车消费,使得空气质量逐年得到改善。
3 基于模型的空气质量预测分析
公众对空气质量的关注主要集中在污染物浓度和污染物等级两个角度,即从AQI数值和AQI污染等级两个角度评估空气质量,因此尝试分别以这两个指标作为目标变量建立预测模型。根据讨论的统计与机器学习模型的特点,对AQI指标建立回归模型,对AQI污染等级建立决策树模型进行预测研究。
基于北京市2018年35个空气监测站点每日数据,计算出5个区域的每日均值,并对每个区域分别建立空气质量预测模型。在对每个区域的建模分析中,因变量为区域每日AQI均值或其对应的空气质量等级值,自变量为 PM2.5、PM10、SO2、CO、O3、NO2这6个指标的区域日均值。为了消除不同量纲数值对建模的影响,对原始数据进行了正态标准化处理。由于对各区域建模过程类似,因此仅对城六区这一区域的建模过程展开分析,仅给出其他4个区域的主要模型结果。
3.1 基于线性回归模型的空气质量研究
以城六区为例,自变量 PM2.5、PM10、SO2、CO、O3、NO2之间存在着一定的相关性,但整体相关性不强,绝大多数变量之间的相关性系数在0.5左右。故在建立回归模型前需对自变量进行多重共线性检验,检验结果如表3所示。由表3可知,共线性统计量VIF值都低于10,说明各变量之间存在较弱的多重共线性,可以把这些变量一起放入回归模型进行逐步回归分析。模型结果显示,各个自变量的显著性水平都低于1‰,表明各自变量都对因变量有显著的影响。模型调整后的判定系数为0.895,该模型的拟合度良好,可以用于对AQI指数的预测。模型方程为:
AQI=0.4×PM2.5+0.3×PM10-0.9×SO2+15.2×CO+0.5×O3+0.3×NO2-14.5,
说明AQI 与SO2呈负相关外,与其他自变量都呈现出正相关关系,且 CO对空气质量指数的影响最大,SO2次之。
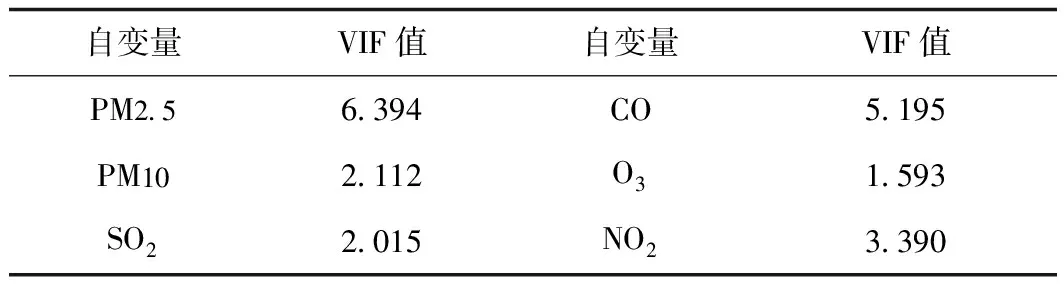
表3 自变量之间多重共线性诊断Tab.3 Multicollinearity diagnosis among independent variables
北京市其他4个区域的线性回归分析类似,模型主要结果如表4所示。由表4可知,除西南部区域的模型判定系数为0.68外,其余各区域模型判定系数均大于0.8,表明回归模型在各个区域整体拟合效果较好。同时,对北京东北部区域AQI影响最大的三个变量依次为CO、SO2、O3;对东南部区域AQI影响最大的两个变量依次为PM2.5和SO2;对西北部区域AQI影响最大的三个变量依次为CO、SO2、O3;对西南部区域影响最大的两个变量依次为O3和PM2.5。通过模型结果可知,北京市各区域模型自变量对其AQI指数的影响关系不完全相同,但综合而言,对各区域AQI影响较大的污染物主要集中在CO、SO2、PM2.5、O3。因此为了降低AQI指标值,政府部门应制定相关政策措施有效降低这4种空气污染物浓度。
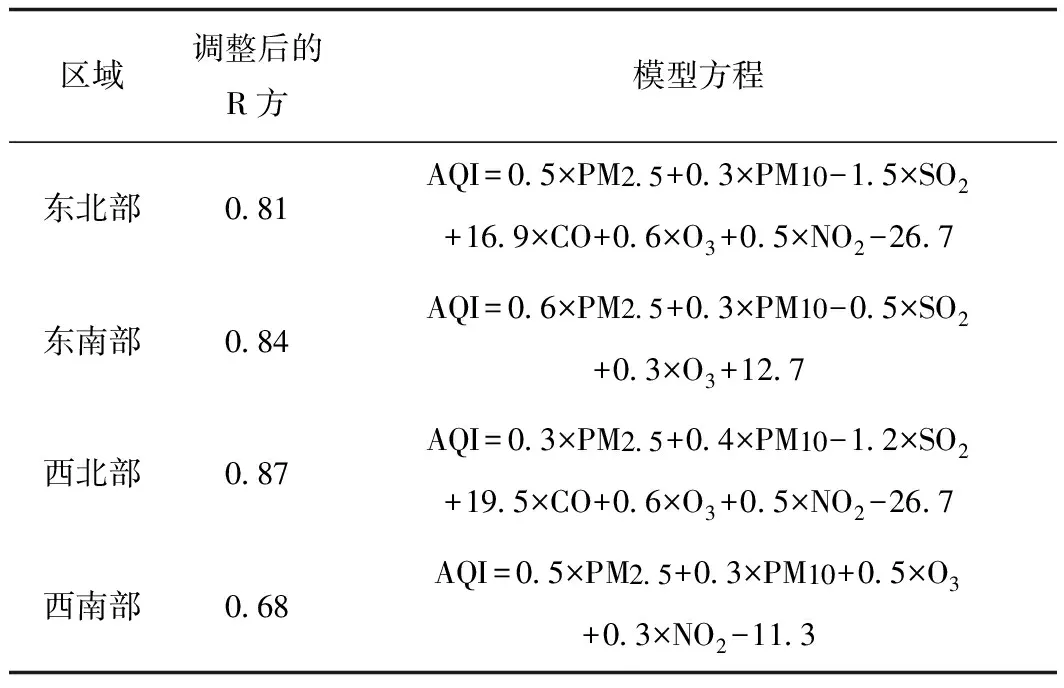
表4 各区域回归方程Tab.4 Regression equation of all regions
3.2 基于决策树模型的空气质量等级研究
以城六区为例,自变量为 PM2.5、PM10、SO2、CO、O3、NO2,因变量为空气质量等级建立决策树模型。在建模前,对样本进行随机划分,70%的数据作为训练集,30%的数据作为测试集,在训练集上创建了决策树模型,在测试集上评估模型预测效果。为防止过拟合现象出现,限制决策树的生长深度为4。决策树建模结果和生长规则如图2所示,决策树的每个子节点都包含优、良好、轻度污染、中度污染、重度污染、严重污染这6个空气质量等级,仅展示出比重最大的空气质量等级。模型筛选结果显示仅仅PM2.5和 O3这两个自变量对预测城六区空气质量等级起作用,且PM2.5的作用最为重要。在整体上,模型在训练集上的正确率达到85.9%,而在测试集上的正确率达到88.7%,表明决策树模型对城六区空气质量等级的预测精度较高。

图2 2018年城六区区域空气质量等级决策树模型结果图Fig.2 Decision-making treeresults of air quality ranks in 6 urban regions in 2018
决策树模型在其他4个区域的结果如表5所示。由表5可知,决策树模型在北京其他4个区域的预测正确率也都达到85%左右,表明模型在各个区域的预测精度较高,整体结果理想。表5同时也给出了各个区域决策树生成规则的重要性变量,PM2.5和O3是所有区域模型的关键性指标,PM10是除城六区和东北部外的模型关键性指标。因此为了提高空气质量等级,政府部门需要制定政策措施有效降低这3种空气污染物浓度。

表5 决策树模型在其他站点的预测结果Tab.5 Prediction results of other stations of decision-making model
4 结论与建议
4.1 研究总结
基于北京市2017-2020年各空气监测站点数据,计算出北京5个区域的空气质量日均值数据,在对各区域空气质量数据进行描述分析的基础上,从整体上分析北京市空气质量与气象、社会经济因素之间的关系,通过回归模型和决策树模型,分别对北京5个区域AQI指标值和空气质量等级数据进行影响因素和预测研究,相关研究结果总结如下:
近几年,北京市各个区域空气质量都得到了明显提升,全年中空气质量等级为良的天数居多,其次为轻度污染和优,其中空气质量等级为良以上的天数占比达到60%以上。北京各个区域中,东北部和西北部区域空气质量相对较好,城六区居中。
气象因素对空气质量存在着显著的影响,每日AQI均值与平均温度、平均风速都呈现出显著的负相关性。
近年来,北京市通过优化经济结构,在保持社会经济持续增长的同时提高了空气质量,AQI指标值与主要经济指标呈现出显著的负相关性。
在各个区域上,回归模型对AQI指标值的拟合效果整体较好,虽然各区域模型筛选出的自变量不完全相同,但综合而言,对AQI影响较大的污染物依次为CO、SO2、PM2.5、O3。各个区域上,决策树模型对空气质量等级的预测精度较高,各区域模型筛选出的自变量基本相同,对空气质量等级影响较大的污染物依次为 PM2.5、PM10、O3。
4.2 相关建议
根据研究内容总结,对北京市空气质量治理提出如下建议:
政府部门加大对民众环境保护工作的宣传,提高民众环保意识;鼓励民众选乘公交地铁出行;制定激励政策,鼓励民众以新能源车替代汽油车。
北京城六区和南部地区空气质量较北部地区相对较差,虽然自然因素是导致这一现象的主要因素,但政府部门仍可通过疏解人口、降低污染产业比重、提高清洁能源使用等方法提高北京中南部地区的空气质量。
从降低北京市空气质量指数和提高空气质量等级两个角度看,需要降低 CO、SO2、PM2.5、O3、PM10 这5种污染物的浓度,但从变量的重要性角度出发,CO和 PM2.5是影响空气质量较为重要的因素,因此政府部门在制定限制大气污染物排放政策时,应尤为重视对 CO和 PM2.5这两种污染物排放的限制。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
