
改进支持向量机的齿轮故障诊断研究
2022-04-28 04:34任竹鹏黄海松
机械设计与制造 2022年4期
任竹鹏,黄海松,胡 耀,2
(1.贵州大学现代制造技术教育部重点实验室,贵州 贵阳 550025;2.贵州人和致远数据服务有限责任公司,贵州 贵阳 550081)
1 引言
齿轮作为基础旋转部件,在机械设备的运转中发挥着不可替代的作用。但是在长时间的工作中,齿轮发生故障的概率非常高,故对齿轮进行故障诊断及其预测性维护有着非常重要的意义。
文献[1]根据齿轮特征故障提取困难的问题提出了一种支持向量机和多维度特征表征相结合的办法,对齿轮箱进行了故障诊断。文献[2−3]提出了一种依据齿轮加速度信号来提取特征进行故障诊断的方法。文献[4−5]提出了基于深度学习和利用深度融合的方法对多样特征进行提取的,从而进行多目标优化,最后应用于齿轮箱的故障诊断。
齿轮工况下常见的几种失效形式分别为:齿面点蚀、齿面胶合、齿面磨损、轮齿折断、齿面塑性变形[6−9]。轮齿折断对设备的危害很大,研究轮齿折断有着重要的实际意义。由此,首先对轮齿折断进行正常和故障声音信号的采集,后用主成成分分析法和改进的支持向量机算法对数据进行建模训练及其预测,取得了很好的分类效果,在故障诊断中得到很好的应用。
2 支持向量机相关原理及优化
支持向量机[10]是一种在有线的小样本中,寻求获得复杂模型与学习之间平衡的一种机器学习的方法,它在二分类中比较常见。假设给定的训练集为(X,Y)={(xi,yi)},yi∈{−1,1},i∈1,2,3 ⋅⋅⋅,n,式中的xi,yi分别代表的是训练集的第i个样本和它的样本标签。在支持向量机算法中利用引入的核函数(K′)是将原始低维特征空间中线性不可分的样本映射到高维特征空间之中,从而使得其在高维空间中变得线性可分;在此基础上同时引入松弛变量ξi≥0,i=1,2,3,⋅⋅⋅,n与惩罚因子C,综上,该情况下SVM的代价函数,如式(1)所示,并使其最小:
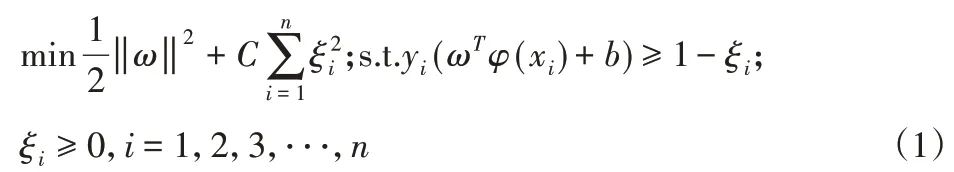
对于式(1)的优化求解,可引入拉格朗日乘子法转化为对偶形式,即:
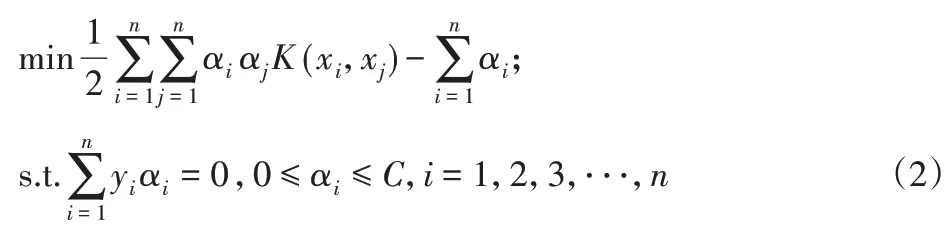
Pca是主成成分分析法[11−12],它具有以下几个优点:(1)降低算法的计算开销;(2)可以使数据及更容易使用;(3)去除噪声等。
Ga是遗传算法[13],是通过模拟达尔文生物进化论的自然选择机理的计算模型。它是通过在自然进化过程中来搜索最优解。其主要过程是复制、交叉、变异。通过编码染色体后进行代代进化,最终达到收敛到最适合的种群,因此求得满意解或者是最优解。
因支持向量机中容易出现过拟合等问题,所以需要对参数进行优化,对数据集进行处理,依次引入了主成成分分析法和遗传算法。
3 实验
齿轮故障诊断实验在半消声中进行房间。我们建造的实验系统由两级变速箱,变频电机,变频器,可编程磁制动器组件,张力控制器和测量系统。测量系统由来自丹麦的四个4189−A−021自由场麦克风组成B&K公司,德国HEAD公司的数据采集工具,以及Artemis数据录音软件。麦克风和数据采集仪器通过Bayonet连接用于数据传输和数据的螺母连接器(BNC)接口由Artemis软件记录。
3.1 实验设备环境
整个实验系统,如图1所示。图1显示了测试结果工作台和图2显示数据采集系统。两级变速箱减速比率为23.34,高速轴减速比为18/81,低速轴减速比率为16/83。在这项研究中,齿轮故障选择低速轴进行研究,并从正常情况收集声学信号齿轮断裂。

图1 实验系统Fig.1 Experiment System

图2 数据采集系统Fig.2 Data Collection System
故障模式,如图4所示。

图3 整体图Fig.3 Overall Picture

图4 齿轮故障图Fig.4 Gear Failure Diagram
3.2 实验数据的获取
在采集声音信号后,经MATLA 软件处理得到原始信号波形、幅值、相位,如图5~图7所示。

图5 原始信号波形Fig.5 Original Signal Waveform

图6 原始信号幅值Fig.6 Original Signal Amplitude

图7 原始信号相位Fig.7 Original Signal Phase
4 数据处理
在采集一分钟的声音信号后,经实验发现一秒的诊断效果最佳,所以将数据分成60份进行实验验证。
(1):将声音信号在matlab中打开,进行转换,将一分钟的数据分成60份,每份一秒钟。
(2):将数据在[−1,1]区间进行归一化,后进行pca降维处理。
(3):利用Ga算法对c、g进行参数优化,以期待获得更好的训练模型。
(4):在模型训练好后导入测试集进行实验验证,训练集与测试集的比例为2:1。具体数据如表一所示,其中括号中前面一个数据为准确的个数后面一个为样本数。
适应度的曲线,如图8所示。

图8 适应度曲线Fig.8 Fitness Curve

表1 实验具体数据Tab.1 Experimental Specific Data
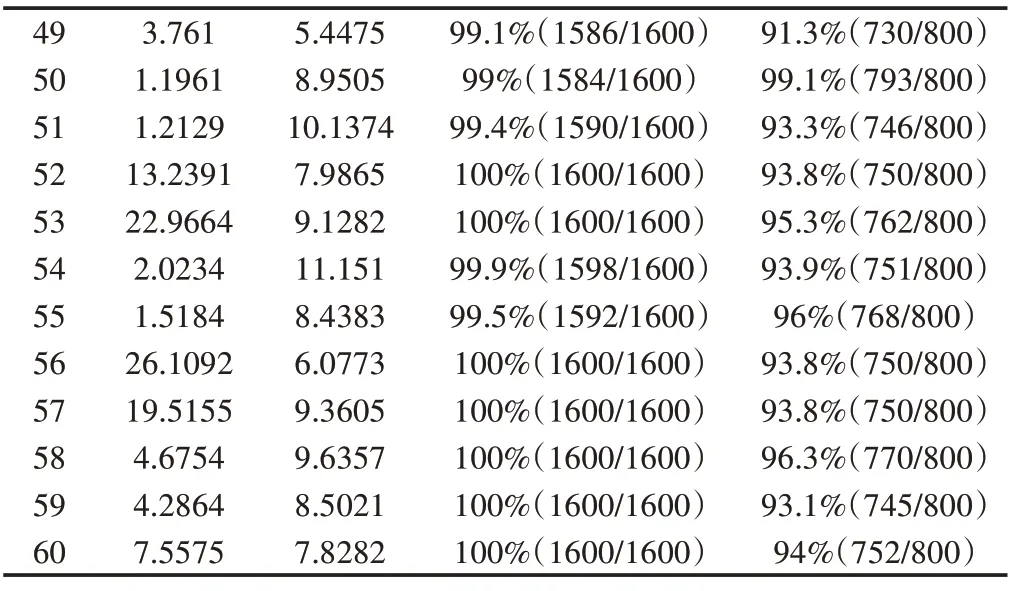
91.3%(730/800)99.1%(793/800)93.3%(746/800)93.8%(750/800)95.3%(762/800)93.9%(751/800)96%(768/800)93.8%(750/800)93.8%(750/800)96.3%(770/800)93.1%(745/800)94%(752/800)49 50 51 52 53 54 55 56 57 58 59 60 3.761 1.1961 1.2129 13.2391 22.9664 2.0234 1.5184 26.1092 19.5155 4.6754 4.2864 7.5575 5.4475 8.9505 10.1374 7.9865 9.1282 11.151 8.4383 6.0773 9.3605 9.6357 8.5021 7.8282 99.1%(1586/1600)99%(1584/1600)99.4%(1590/1600)100%(1600/1600)100%(1600/1600)99.9%(1598/1600)99.5%(1592/1600)100%(1600/1600)100%(1600/1600)100%(1600/1600)100%(1600/1600)100%(1600/1600)
在主成成分分析法的基础上,分别使用支持向量机、粒子群算法优化的支持向量机重新进行建模,进行60组试验计算平均值,比较结果,如表2所示。

表2 实验对比Tab.2 Experimental Comparison
在模型的训练过程中,迭代次数如果过少,拟合效果并不理想,容易出现欠拟合;反之迭代次数过多,则会出现在训练集时模型表现良好,而测试集表现不佳的过拟合现象,使得模型的泛化能力差。故通过控制迭代次数来提高故障识别准确率,如图9所示。

图9 故障识别准确率随迭代次数的变化Fig.9 Fault Identification Accuracy Changes with the Number of Iterations
5 结论
鉴于齿轮的故障变化实际上表现为齿轮工作产生声音的变化,所以采集了一分钟的声音信号。基于支持向量机在小样本训练预测的优势条件,运用主成成分分析法和遗传算法对支持向量机过拟合等问题进行优化,提高了分类效果从而对齿轮断齿这一故障诊断问题进行研究。提出并分析了改进支持向量机算法在齿轮断裂故障数据分类诊断的应用,并通过实例验证了算法的可行性。今后将对齿轮的其他几种失效形式进一步研究。
猜你喜欢
中国重型装备(2022年2期)2022-04-19
一重技术(2021年5期)2022-01-18
内燃机工程(2021年6期)2021-12-10
矿山机械(2020年8期)2020-08-19
少儿科学周刊·少年版(2020年9期)2020-03-04
少儿科学周刊·少年版(2020年9期)2020-03-04
疯狂英语·读写版(2019年5期)2019-09-10
电子制作(2018年10期)2018-08-04
北京航空航天大学学报(2016年6期)2016-11-16
汽车电器(2014年5期)2014-02-28
