
基于部件直方图和随机文本选择的无载体信息隐藏*
2022-04-26 03:23黄华军
电讯技术 2022年4期
曾 笛,黄华军
(1.中南林业科技大学 计算机与信息工程学院,长沙 410018;2.湖南财政经济学院 信息技术与管理学院,长沙 410205)
0 引 言
随着信息科技的高速发展,信息隐藏技术已经成为当今社会研究的热点之一[1]。但在信息隐藏的过程中,只要将秘密信息嵌入在载体中,就不可避免地会导致载体信息发生改变,使其没办法抵抗OCR技术、重放攻击、统计分析等一系列基于异常检测的隐写分析技术[2]。针对上述问题,2014年专家学者们首次提出了“无载体信息隐藏”方法,其主要思想是不对载体进行任何修改,直接以秘密信息为驱动,从而生成(或者获取)含密载体[3]。该方法从本源上解决了由于载体修改引起的异常分析的隐写检测,提高了信息安全性。
目前无载体信息隐藏大致可分为搜索模型和生成模型两类。基于搜索的算法模型为:构建文本大数据为载体库,将秘密信息拆分为“标签+关键词”的形式为驱动,去数据库中搜索包含秘密信息关键词的文本以作传输载体,同时用标签定位关键词的位置,在不修改载体文本的情况下完成秘密信息的公开传输[4-8]。吉红勇[9]提出了基于单关键词的文本无载体信息隐藏方案,通过标签一一定位关键字的组合从文本库中检索到合适的自然文本来隐藏秘密信息。Long等[10]提出了一种基于web文本的无载体信息隐藏方法,通过网络爬虫技术爬取互联网上大量的web文本来隐藏秘密信息。Qin等人[11]受此启发,提出了一种基于大数据文本的无载体信息隐藏算法,通过改进的Spark平台将大数据文本进行LDA(Latent Dirichlet Allocation)主题聚类,得到词频和词语TF-IDF特征,从中搜索到包含关键词特征的文本,将其分布特征的混合索引发送给接收方。但是在这些方法中,一个载体文本只能隐藏一到两个关键字,隐藏容量也较低。
基于生成的算法模型是利用不同载体的特征对象,由秘密信息以载体对象为参照按一定的规则生成内容合理且没有异常统计信息的含密载体[12]。这种模型的核心问题是确保载体内容的逻辑合理性的同时可以正确表示秘密信息。刘明明等人[13]提出结合生成对抗网络的无载体信息隐藏方案,用秘密信息作为驱动因素替换生成对抗网络中的类别标签,以此直接生成含密图像的无载体信息隐藏方法。该方法在隐藏容量上有一定的提升,但是生成的图片质量还有待提高。陆海等人[14]提出了一种结合非直接传输和随机码本的无载体试题生成式信息隐藏算法。该方法由于生成的试题暂未考虑排序等问题,在一定程度上会存在隐写异常,导致隐藏成功率降低。
虽然无载体信息隐藏方法已经取得了很多成果,然而,隐藏容量低、成功率不理想等仍是存在的主要问题。为了克服这些问题,同时保证隐写的安全性和鲁棒性,本文提出一种基于部件直方图和随机文本选择的文本无载体信息隐藏方法。实验结果表明,该方法的隐藏成功率能达到98.33%,证明了该方法的有效性。
1 相关工作
1.1 汉字数学表达式理论
不同于英文具有字母化的特征,汉字是一种更偏重于形状的象形文字,基本单位是笔画,所以很难用类似于英文字母的形式来表示。孙星明等人[15]在对汉字进行结构化拆分之后,提出了一种用数学表达式来代表汉字的理论,把汉字常用的基本的偏旁、部首或简单字等作为部件,所有汉字均由基本的部件按一定结构关系叠加而来,每一个部件对应一个唯一的编号。而根据汉字组成特点,部件之间的关系有左右关系(lr)、上下关系(ud)、左下关系(ld)、左上关系(lu)、右上关系(ru)和全包含关系(we)六种,直观描述如图1所示。

图1 六种运算符的直观描述
因此,所有汉字的数学表达式由部件号和组织部件的位置关系组成,位置关系可以表述为运算符。这些由基本部件和运算符号构成的表达式,表示的不仅是汉字由这些部件的位置关系组成,也可以表示为组成了一个复合部件。例如A、B分别表示两个部件,那么表达式C=A lr B有两重意思:一是可以表示C是由A和B作为左右关系形成的复合部件;二是表示汉字C可以用具有上下关系的部件A和部件B表示,且A在B左边。
本文将汉字数学表达式应用到无载体信息隐藏中,相比于已有的文本无载体信息隐藏以汉字或词语为隐藏单位,本文的隐藏对象是部件,较大程度上降低了隐藏对象的细粒度,同时也较好地提高了隐藏的鲁棒性。
1.2 部件频次统计方法
文本的部件频次的统计方法首先是利用汉字数学表达式理论将文本中的汉字转换成部件和其操作数的数学表达式,再提取出其中的部件,并统计每个部件出现的次数。定义如下规则对其进行描述:
设t表示文本,Q表示文本t中出现的所有汉字集合,wi表示为集合Q中的任一汉字,Ω表示所有的部件集合,c表示Ω中的任一部件,fwi表示wi在t中出现的次数,f(c,wi)表示部件c在wi中出现的次数,则部件c在文本t中出现的次数fc为
(1)
1.3 部件直方图的相关概念
文本的部件直方图的概念是由图像的灰度直方图引申而来,部件直方图是部件级的函数,能够反映出文本中所有部件的统计分布特征。具体生成方法如下:
(1)对文本进行预处理之后,利用字符比较的方法获得文本中所有汉字的字频fwi,然后利用公式(1)统计出所有部件在文本中出现的频次fc。
(2)将文本中出现的fc按从大到小进行排序,得到部件次数的排名,结合部件的编号和部件出现的次数,按照部件出现的频次排序做出统计图,就得到了文本的部件直方图(Component-Frequency-Rank,CFR),它能直观地表示某一篇文本中出现的所有部件的次数以及排名情况。
由此可知,文本的部件直方图由部件编号、部件频次以及部件频次的排名(即部件的阶)三部分构成。
部件直方图定义为
CFR={ci,fci,rci|i=1,2,3,…,U}。
(2)
式中:U是部件总数,ci是部件编号,fci是部件ci出现的次数,rci是部件ci在文本部件直方图中的阶。
2 本文算法
本文以中文汉字为研究对象,通过借助汉字部件直方图,提出一种基于汉字部件直方图和随机文本选择的无载体信息隐藏方法。首先是对文本数据库的码本构建得到部件直方图,这一步通信双方均需完成;接着是信息隐藏部分,其中包括对秘密信息的转换、随机选择载体文本集和构建索引等流程;最后是对秘密信息的提取。算法整体框架如图2所示,包括文本库的码本构建、隐藏和提取算法设计三个部分。
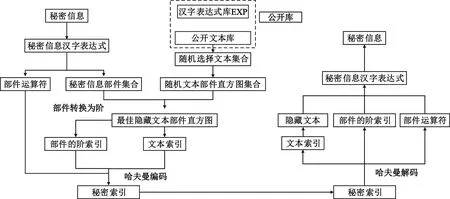
图2 算法整体框架
2.1 构建部件直方图的文本库
文本的无载体信息隐藏依托于文本数据库,本文选取搜狗实验室公开的新闻数据集作为文本数据库。通信双方在信息传递之前,需使用相同的方法对文本库建立码本库。构建码本库的过程主要包括文本预处理、统计文本的部件频次、为文本分配标签、获取文本的部件直方图以及建立全文索引。通过建立索引得到秘密信息和文本标签的映射关系。具体步骤如下:
(1)文本预处理。首先去除掉每篇文中的停用字、无用字以及标点符号,抽取文本中的中文汉字,获得每篇文本中所有的汉字集合。
(2)利用公式(2)获得每篇文本的部件直方图CFR,得到文本中每个部件编号的次数以及对应的阶排名,每篇文本的信息都被处理成“部件编号、频次、阶”的数据结构。
(3)利用哈希索引算法将对每篇文本生成一个哈希值,作为文本标签。
(4)建立文本标签与对应文本部件直方图的链接索引,使文本标签链接该文本的部件直方图。
通过构建文本库中每篇文本的部件直方图作为信息隐藏的码本,图3是一篇文本的部件直方图的一部分。

图3 文本部件直方图的一部分
2.2 信息隐藏方案
2.2.1 秘密信息转换
发送方隐藏秘密信息前,需对秘密信息进行预处理。假设秘密信息为M,其中M由n个关键字构成,不妨记作
M={m1,m2,m3,…,mn}。
(3)
利用汉字数学表达式理论,将秘密信息M的每个关键字mi转换为汉字数学表达式。由于汉字表达式中六个运算符均占用两位字节,为节约空间及便于表达,定义运算符映射规则如下:
ops={‘ud’,‘ru’,‘lr’,‘we’,‘lu’,‘ld’,‘’}⟺
{‘A’,‘B’,‘C’,‘D’,‘E’,‘F’,‘I’}。
(4)
式中:‘ud’‘ru’‘lr’‘we’‘lu’‘ld’是六个运算符,分别映射为‘A’‘B’‘C’‘D’‘E’‘F’。上述运算符均为双目运算符,考虑到部分简单的汉字的数学表达式即为单个部件,为统一表达形式,定义特殊运算符‘I’,该运算符为单目运算。为区分各个汉字数学表达式的界限,使用字符‘J’作为分隔符。则有转换之后的信息M′如公式(5)所示:
(5)
式中:EXP是汉字数学表达式转换函数,根据文献[15]可知,任何一个汉字均有唯一的汉字数学表达式与之对应。在该文献理论指导下,现已具备一套完整的汉字与汉字表达式对应库,故必存在函数EXP(M,ops),可将秘密信息每个关键字转换为秘密信息汉字数学表达式。同理,也一定存在汉字数学表达式唯一表示一个汉字,即有
M=EXP(M′,ops)。
(6)
2.2.2 基于随机文本选择的隐藏方法
为保证搜索载密文本的随机性,增加隐藏鲁棒性,同时也提高检索效率,本文提出一种随机文本选择方法实现信息进行检索载密文本,主要思想是在随机选择的公开载体文本库中与秘密信息的部件直方图进行部件集合的对比,从中获得一个包含秘密信息所有部件的载体文本。假设公开文本库包含文本总数为X,随机抽取的载体文本数量为x,则选择阈值如公式(7)所示:
(7)
遍历检索载体文本集中的文本部件直方图,如果找到包含有所有秘密信息部件集合的文本部件直方图,则将其作为载体文本,返回该文本的文本标签。
2.2.3 索引构建
当发送方获得可以隐藏秘密信息的载体文本后,可根据载体文本的部件直方图构建秘密信息索引。本文以秘密信息的部件为驱动,通过阶-部件映射规则构成秘密信息部件索引。同时将隐藏文本的文本标签作为文本索引,最终构建成“秘密信息索引+文本索引”混合结构。
阶-部件映射规则定义如下:
已知文本的部件直方图包含部件(component)、部件频次(frequency)和部件的阶(rank)三部分,部件直方图中的部件和阶存在如下特性:
性质1 在一个部件直方图内,部件号与部件的阶可唯一表示;
性质2 不同部件直方图之间,相同的部件号对应的阶不一样。
利用性质1,可在一个部件直方图内定义部件和阶的转换函数CH,即存在
rank=CH(component),
(8)
component=CH(rank)。
(9)
本文采用随机选择载体文本方法,同一秘密信息进行多次隐藏时随机选择的载体文本会大有不同,结合部件直方图部件和阶的性质2可知,构建的秘密信息索引也将不同。该方式较大程度上提高了秘密信息隐藏隐蔽性。
综上,秘密信息隐藏的大致流程为:发送方首先利用转换函数将秘密信息转换为秘密信息汉字数学表达式,在秘密信息汉字数学表达式中得到秘密信息的部件集合;然后通过在随机选择的载体文本库的部件直方图中获得的最佳隐藏秘密信息的载体文本,再根据公式(4)和公式(8)对秘密信息汉字数学表达式中的运算符进行重新表达,对秘密信息部件转换为隐藏载体文本中部件的阶作为秘密信息的部件索引,将载体文本标签作为文本索引;最后将其作为混合秘密索引传递给接收方。
考虑到秘密索引传输效率和安全性,本文将混合秘密索引的字符进行哈夫曼编码(Huffman Coding),最终形成二进制序列作为最终传递的密钥索引发送给接收方。
2.3 信息提取方案
秘密信息的提取就是信息隐藏过程的逆过程,接收方只需要将发送过来的索引按照索引构建的过程逆向拆分就能还原秘密信息。提取过程如图4所示,具体步骤如下:

图4 信息提取流程
Step1 接收发送方传递过来的二进制哈夫曼编码,并将其还原为混合秘密信息索引。
Step2 反向遍历混合秘密信息索引寻找第一个分隔符‘J’,前部分即为秘密信息索引,后部分为载密文本索引。
Step3 根据载密文本索引,接收方在文本部件直方图库中获得该文本索引的部件直方图。
Step4 根据公式(9),在载密文本部件直方图中将秘密信息索引的阶还原成部件号。
Step5 根据公式(6)的转换函数,得到秘密信息表达式M=EXP(M′,ops)。
Step6 根据分隔符‘J’,识别每个关键字,还原成秘密信息M。
Step7 由于发送方将秘密信息转换为汉字数学表达式时是逐一顺序转换,故接收方还原秘密信息就是各个汉字顺序即原始秘密信息顺序。
3 实验结果与分析
3.1 实验环境
测试环境:Windows10操作系统,CPU为Intel Xeno E5-2620 v4,主频为2.10 GHz,内存为24 GB;编程环境为Python3.6;所用到的公开库存储在远程的MySQL服务器上。
3.2 实验分析
本节分别从隐藏容量和隐藏成功率两个方面对算法进行性能分析,载体数据库来源于搜狗实验室的数据集,实验数据来源于文献[10]和文献[11]中提供的120个文本(作为秘密信息进行测试),120个文本的长度为1~6 kB。每篇测试文本的汉字数量统计如图5所示。

图5 每篇测试文本的汉字数量
3.2.1 隐藏容量
隐藏容量是指在确认秘密信息不可感知的情况下,隐写载体可隐藏秘密信息的关键词数量。隐藏容量也是评价信息隐藏算法性能的重要指标之一。
假设一条秘密信息中汉字的个数是n个,隐藏秘密信息所需载体文本的数量为s,则隐藏容量Vi的定义如下:
(10)
利用公式(10)计算实验的隐藏容量,与文献[10]和文献[11]的实验对比结果如图6所示。

图6 隐藏容量对比
从图6中可以看出,本文方法的隐藏容量远远高于其他两种方法——由于本文方法利用汉字数学表达式将秘密信息拆分为部件,极大地提高了载体文本对部件的覆盖率。故相比于其他两种方法,本文方法在隐藏容量方面的性能表现较为优越。这120个文本的平均隐藏容量的实验结果如表1所示。

表1 三种方法的平均隐藏容量
3.2.2 隐藏成功率
隐藏成功率是指秘密信息隐藏在传输载体中发送给接收方之后,接收方在传输载体中将秘密信息提取出来,和原来的秘密信息是否一致。在信息传输的过程中,为了保证能准确将秘密信息发送出去,一般需要准备一个庞大的载体数据集,使得有时候并不能精确地匹配到秘密信息,因此隐藏成功率的大小也是衡量一个信息隐藏算法的重要指标之一。假设秘密信息中汉字的个数为n,隐藏失败的汉字个数为f,则隐藏成功率σ的定义为
(11)
本次实验的文本公开库包含20万个载体文本,随机选择比率阈值取0.6,结果如图7所示。

图7 隐藏成功率对比
本文方法通过部件这种对文字结构进行拆解的形式来表示秘密信息,不受文本格式以及文体的限制,且提取时不需要用到基于自然语言处理技术来对秘密信息进行语义分析等操作,进一步提高了秘密信息的隐藏成功率。从表2可以看出,平均隐藏成功率为98.33%,相比文献[10]的94.8%的隐藏成功率有一定的提高,与文献[11]的97.89%的平均隐藏成功率相比略有提高。

表2 三种方法的平均隐藏成功率
由此可以看出,与文献[10]和文献[11]这两个算法相比,本文的平均隐藏容量相对比较高,平均隐藏成功率相差不大,有较好的性能。
3.3 安全性分析
不同于其他的中文无载体隐藏方法,本文方法使用汉字数学表达式处理秘密信息,利用自然文本的部件直方图与秘密信息之间存在的映射关系作为检索条件,最后将索引发送给接收方,整个过程没有改变过文本的任何属性,所以能够抵抗隐写分析的异常检测等。不对汉字或中文词语本身做隐藏,而是以汉字的部件为隐藏单位,通过借助部件直方图构建映射关系,实现信息隐藏。基于文本的隐写检测分析一般是分析文本属性的变化进而发现秘密信息的存在,本文方法没有改变文本的任何状态,使用的是自然文本传输信息,因此安全性高。
4 结束语
本文介绍了一种基于随机文本选择的无载体信息隐藏算法。该算法利用汉字数学表达式理论引申部件直方图,通过给定阈值随机选择一定量的载体文本部件直方图,可以提高隐藏的鲁棒性。通过构建文本的部件直方图和秘密信息的部件集合之间的映射关系得到混合秘密信息索引,同时考虑到秘密信息索引的传输效率和安全性,秘密索引采用哈夫曼编码后传输给接收方。该方法没有对载体文本进行任何修改,通过采用随机选择载体文本方式,同时充分利用了部件直方图的性质,使秘密信息每次隐藏是均生成不同的秘密信息索引,较好地实现了隐藏的安全性和隐蔽性,在隐藏容量和隐藏成功率方面的性能也较好。但该方法是将秘密信息隐藏至一个载体文本中,在寻找一个能完整包含整个秘密信息的载体文本上需要花费较大的时间开销。在下一步工作中,计划提出一种多文本选择方案解决该问题。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
河北大学学报(哲学社会科学版)(2022年1期)2022-02-17
初中生世界(2020年47期)2021-01-07
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
汽车维修与保养(2020年11期)2020-06-09
安顺学院学报(2020年1期)2020-04-05
小学语文教学·会刊(2019年2期)2019-09-10
现代计算机(2019年6期)2019-04-08
摄影之友(影像视觉)(2018年12期)2019-01-28
初中生世界·八年级(2017年3期)2017-03-24
