
基于智能压实技术的高填方路基边缘压实均匀性研究
2022-04-25 12:39黄晓銮
黑龙江工程学院学报 2022年2期
黄晓銮
(福建林业职业技术学院 建筑工程系,福建 南平 353000)
高填方路基由于具有施工难度较大、易滑塌、易开裂等特点,其压实均匀性控制尤为重要。而高填方路基边缘区域是高填路基滑塌、开裂等病害的高发区域,该区域的压实均匀性评价方法更需合理准确。为此,智能压实技术逐步被应用到高填方路基压实作业中[1-2]。
徐光辉[3]将智能压实技术引用到铁路路基作业中,并提出基于“3σ”准则的压实均匀性评判方法;王龙等[4]建立了路基变形模量模型,定义了压实均匀度指标t来表征碎石土路基的碾压均匀性;王翔等[5]基于地统计学中的半变异函数模型,提出将偏基台值作为新的压实均匀性评价指标,并验证了该指标的合理性;焦倓等[6]针对目前压实评价指标未能考虑薄弱区域的问题,提出薄弱区域评价指标,通过试验验证了该指标可有效识别薄弱区域;Facas等[7]利用数理统计方法,提出利用该样本的变异系数作为指标,来评价碾压面的均匀性;Vennapusa等[8]通过建立压实特征值的指数模型,并引入地理学方法,提出了评价压实均匀性的地理统计学指标;而国内现行《铁路路基填筑工程连续压实控制技术规范》(TB10108-2011)(以下简称“现行规范”)对均匀性的评价大部分仍然是基于数理统计学方法,通过研究智能压实数据样本整体的数据分布情况来评价压实均匀性[9]。
上述研究均为智能压实均匀性评价提供了研究方向。但目前大部分研究都是以路基作为一个整体来评价压实均匀性,将全碾压面的智能压实数据作为一个大的数据样本进行分析评价。根据高填路基道路压实过程中受力模型,路基边缘区域相较路基核心区域碾压难度较大,需要的遍数可能较多。由此文中提出分区域评价的思路,将高填路基智能压实数据分为边缘区域数据样本和核心区域数据样本,引用最近邻法来重点研究边缘区域的压实均匀性,并通过现场试验验证该方法的合理性。
1 智能压实技术
目前,大部分高填方路基边缘区域的均匀性评价采用传统采样点法检测,而采样点法具有采样点少、代表性不足、费时费力、不能实时检测等明显缺陷。智能压实技术的出现解决了采样点法的缺陷,其采用数字通信、大数据分析等技术,实现了压实区域全覆盖检测,成为路基工程数字化施工的重要补充[1-2]。
智能压实技术通过将加速度计安装于振动压路机的振动轮上,采集压实过程中振动轮实时加速度信号,并根据动力学模型、信号分析技术、通讯技术等,得到全碾压面相应的压实指标,实现了路基压实过程实时、全过程控制[10-11]。
智能压实系统的工作原理如图1所示,可根据功能分为三大部分:
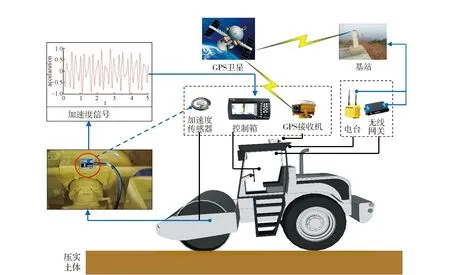
图1 智能压实系统原理
1)振动压实信号采集部分。路基压实过程中,压实土体和压路机可视作一个相互作用的动力系统,在振动轮上安装加速度计,实时采集压实过程中的竖向加速度,为智能压实系统提供数据基础。
2)压实信号处理部分。当采集到加速度数据后,通过信号分析,得到反映土体压实状态的指标,并将计算得到的指标显示于屏幕中来实时反映土体的压实状态。
3)压实位置坐标采集部分。此部分实现土体压实点的位置采集,通过结合此部分功能,可得到具体点位对应的压实指标。该部分功能由GPS接收机及卫星共同完成。
2 高填路基边缘均匀性评价方法
2.1 现有规范评价方法
国内现行智能压实规范规定:压实均匀性按整个碾压面压实值不小于振动压实值数据平均值的80%(即80%线)来控制。该规定可用图2进行描述。对于路径1,所有压实值均大于80%线,压实均匀性合格;对于路径2,有小部分的压实值低于80%线,压实均匀性不合格。
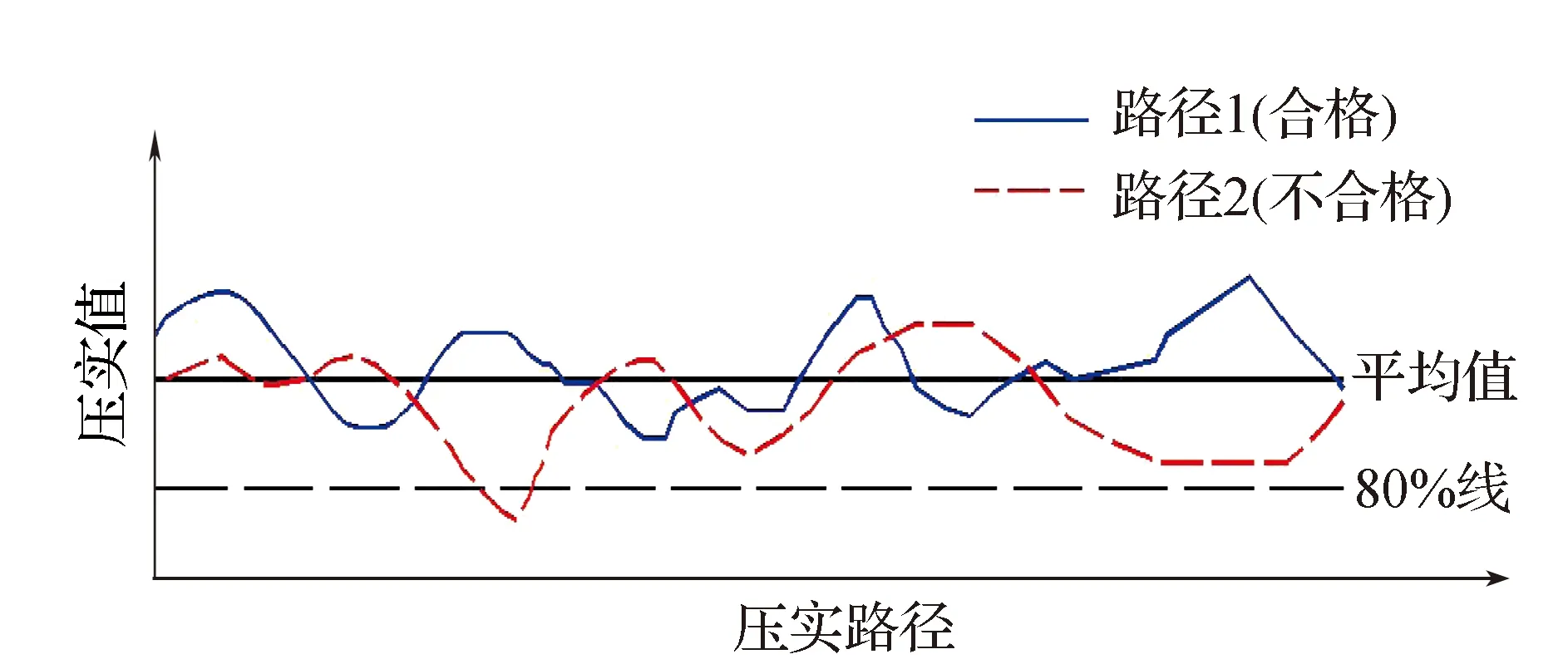
图2 现行压实均匀性评价方法
该评价方法从碾压面整个样本的数据均匀性角度来表征路基的压实均匀性,但未专门对高填路基边缘区域的均匀性评价提出规定。
2.2 基于最近邻法的均匀性评价方法
现有评价方法的不足在于:由于整个碾压面的数据样本巨大,且土体本身具有较大的变异性,所以压实完成后实际得到的智能压实数据难免会有极小部分数据小于80%的平均值。如果以此就判定压实均匀性不合格,可能会导致重复压实作业等问题。因此,当出现极小部分不合格数据时,如果能分析这些不合格数据的空间位置分布,得到其分布均匀性情况,并针对不同的分布情况,选择更加合理的措施。以图3为例,图3(a)部分不合格点的分布较为分散,对实际工程的影响相对较小;而图3(b)的不合格点分布较为集中,后续可能会产生局部工后沉降,对实际工程的影响更大,需要采取局部补强压实等措施。
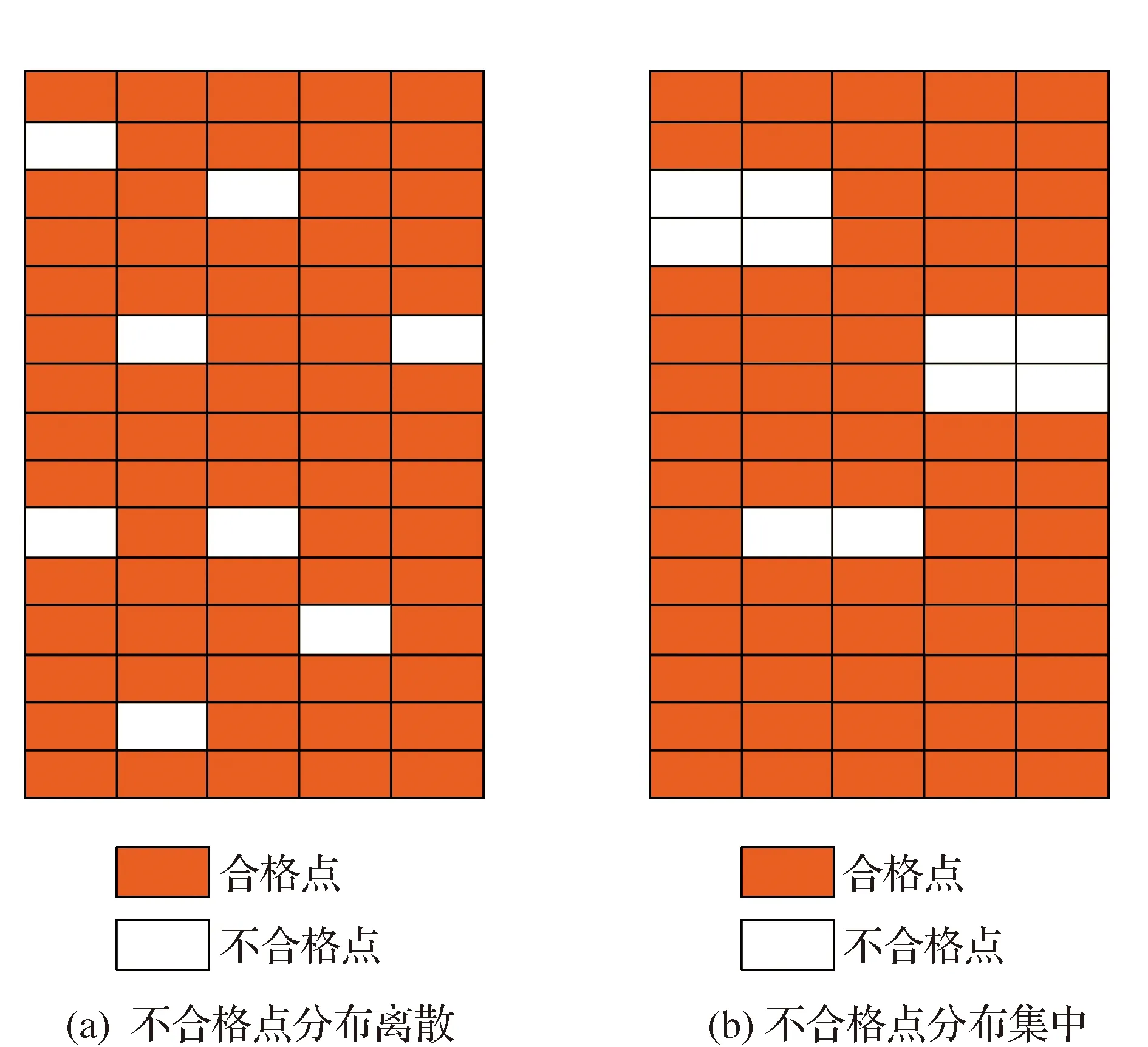
图3 点的分布情况
由以上分析可知,对不合格压实的空间分布研究是具有实际工程意义的。故文中引入可评价空间分布的最近邻法,从高填路基边缘不合格点的空间分布情况来评价高填路基边缘压实均匀性。
最近邻法以指标p来衡量点的空间分布[12-13]。具体计算为
(1)
(2)
(3)
式中:D为单位面积内的点数;ri为压实不合格点i距最近的不合格点的距离;re为理论上的标准距离,但由于不合格点的比例较小,所以需要用修正公式,具体为
(4)
式中:B为要评价的高填路基边缘的周长;n为不合格点的总数。
根据已有相关文献[14],当指标p<0.5时,点聚集分布;当p≥0.5时,点离散分布。
3 现场试验
3.1 试验概况
在某路基试验段进行智能压实试验,该试验段填料参数如表1所示。试验段长度为200 m,路基宽度为45.0 m,路基两侧5 m范围为高填路基边缘研究范围。压路机采用25 t标准振动压路机,压路机型号为YZK25,并在振动压路机上安装智能压实系统,智能压实系统采用CMV(压实计测量值)系统。压实过程中,压路机采用的振动频率为30 Hz,额定振幅为2.0 mm,行进速度为3.5 km·h-1。

表1 试验段填料参数汇总
3.2 智能压实数据网格化处理
振动压路机在实际压实过程中,速度不能保持始终一致,整个压实过程受人为因素、场地因素等影响较大,故轨迹不是理论上的一条均匀直线,而是一条沿行进方向左右突出的曲线,因此采集到的智能压实数据呈现空间不均匀分布的特点。而这会对压实评价产生一定的误差,影响评价结果的精度。
基于此,为得到精确的智能压实评价结果,首先需要对压实数据进行一定的网格化处理[8],将压实数据精确定位到合理的位置,消除位置误差对数据的干扰。文中采用半变异函数模型进行压实数据网格化处理[5]。具体思路为:首先拟合采样出数据的半变异函数通式λ(h),再根据采样间距和采样角度进行数据分组,从而得到规则的网格化数据。通式λ(h)的具体形式为
(5)
式中:C,C0,a均为常数;h为采样间距。
根据式(5)可知,当采样间距h=0时,半变异函数的值λ(0)=C0,由于采样间距为0,所以C0代表了整个智能压实采集系统的系统测量误差,较小的C0值说明采集系统的系统测量误差较小;当采样间距h趋向于无穷大时,半变异函数的值趋向于C0+C,而C值代表了智能压实数据自身的空间变异程度。
采用智能压实数据进行半变异函数拟合,求得h后,可进行数据分组,分组原理如图4所示。
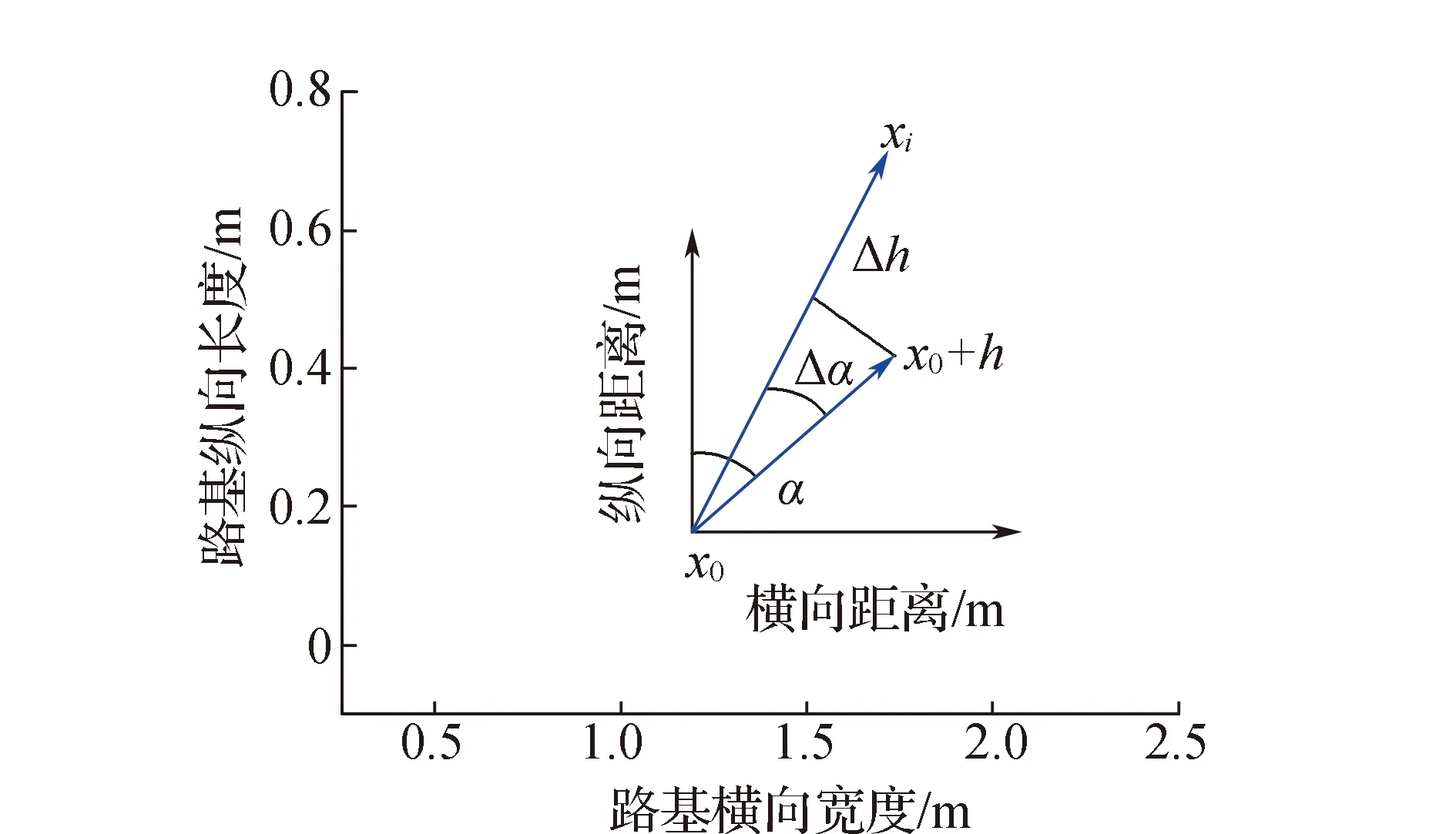
图4 半变异函数分组原理
图4中已知点x0,如果有点xi,其与点x0的关系满足以下两个条件:1)点xi与点x0的距离在x0±h之间;2)点xi与点x0连线的角度在α±Δα之间。则可认为点xi是x0在α角度采样方向上的点,可将其分为一组。全部数据分组完成后,即可得到网格化的数据,具体如图5—6所示。可以看出,网格化后的压实数据空间分布更加规整,充分排除了压实过程中由于人为因素等原因造成的数据空间变异,其数据分析结果也更加可靠。
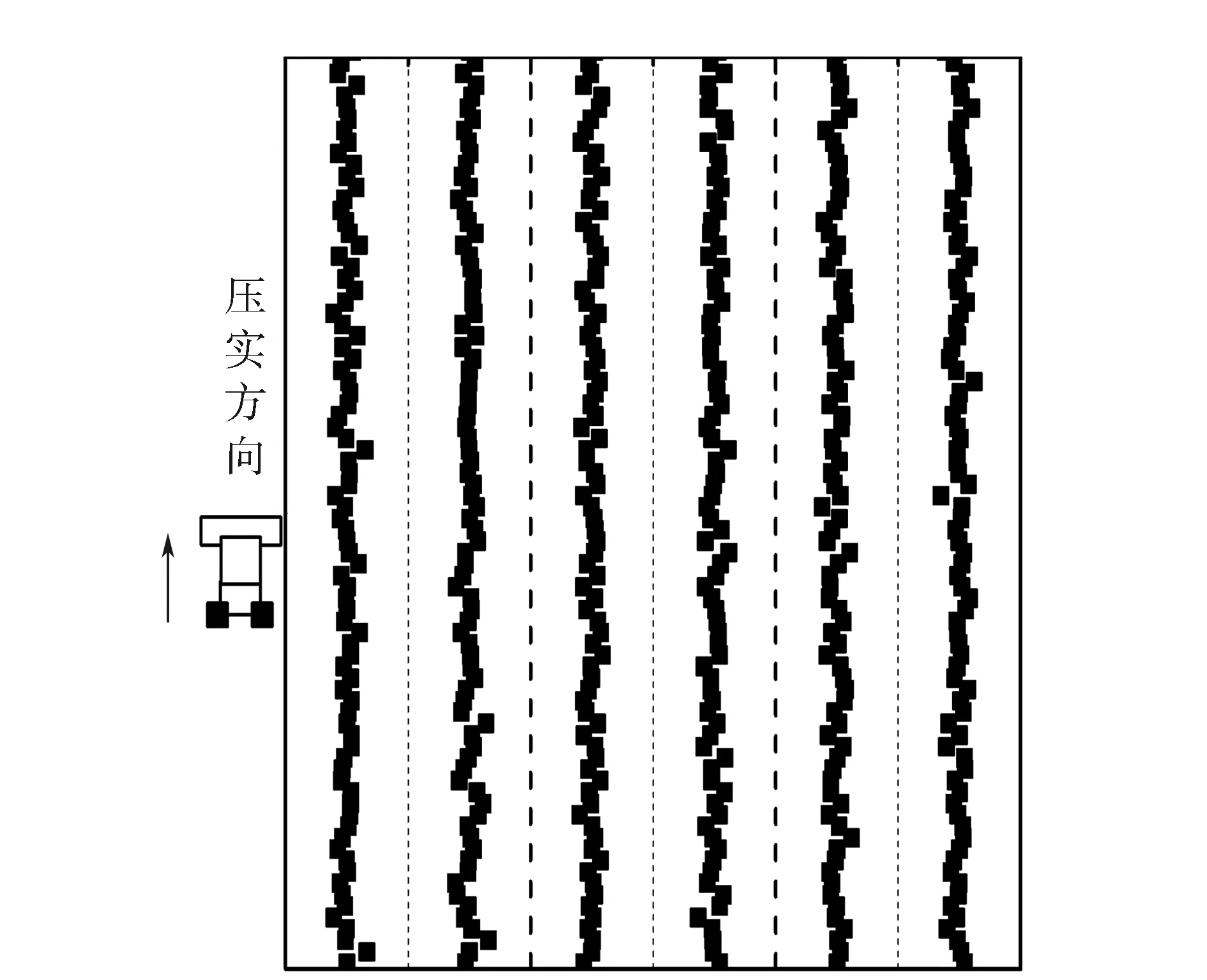
图5 压路机的压实路径
在验证了网格化的合理性后,再将现场压实得到的智能压实数据分为高填路基边缘部分、路基其他部分两大部分,并分别进行数据网格化处理,取任意压实遍数的压实数据,作出其数据云图如图7所示。
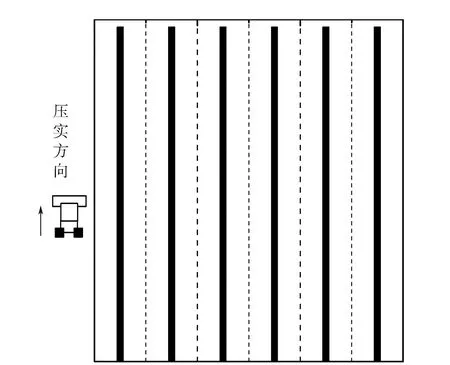
图6 压路机网格化后的压实路径
由图7可知,网格化后的数据更加直观准确地反映了碾压面的压实状况,也可以看出试验段的整体压实程度较好。此外,也可初步看出路基边缘区域的压实值整体略小于路基中心部分数据,且路基的边缘部分数据相对更加分散,说明路基边缘部分压实程度和均匀性相对稍弱,这也证明了将路基边缘部分单独进行均匀性评价的合理性和必要性。

图7 现场实际数据网格化后的云图
3.3 智能压实数据相关性校验
网格化处理解决了智能压实数据空间分布变异的问题,使智能数据能更好地对应实际的碾压面点位,但这些数据能否用于表征碾压面的实际压实状态则需进一步验证。现行规范规定,由于传统压实指标如地基系数K30、动态变形模量Evd等指标的合理性已得到验证,这些指标可用于表征碾压面真实的压实状态,故在得到智能压实数据后,需将这些数据与传统压实指标(K30、Evd)进行相关性校验,当相关性系数大于0.7时,方可认为采集到的智能压实数据可用于评价路基压实质量[6]。本试验中,传统压实指标采用K30。同时,为作对比试验,仍分别将高填路基边缘部分、路基其他部分的智能压实指标CMV与K30进行相关性校验,其结果如图8—9所示。
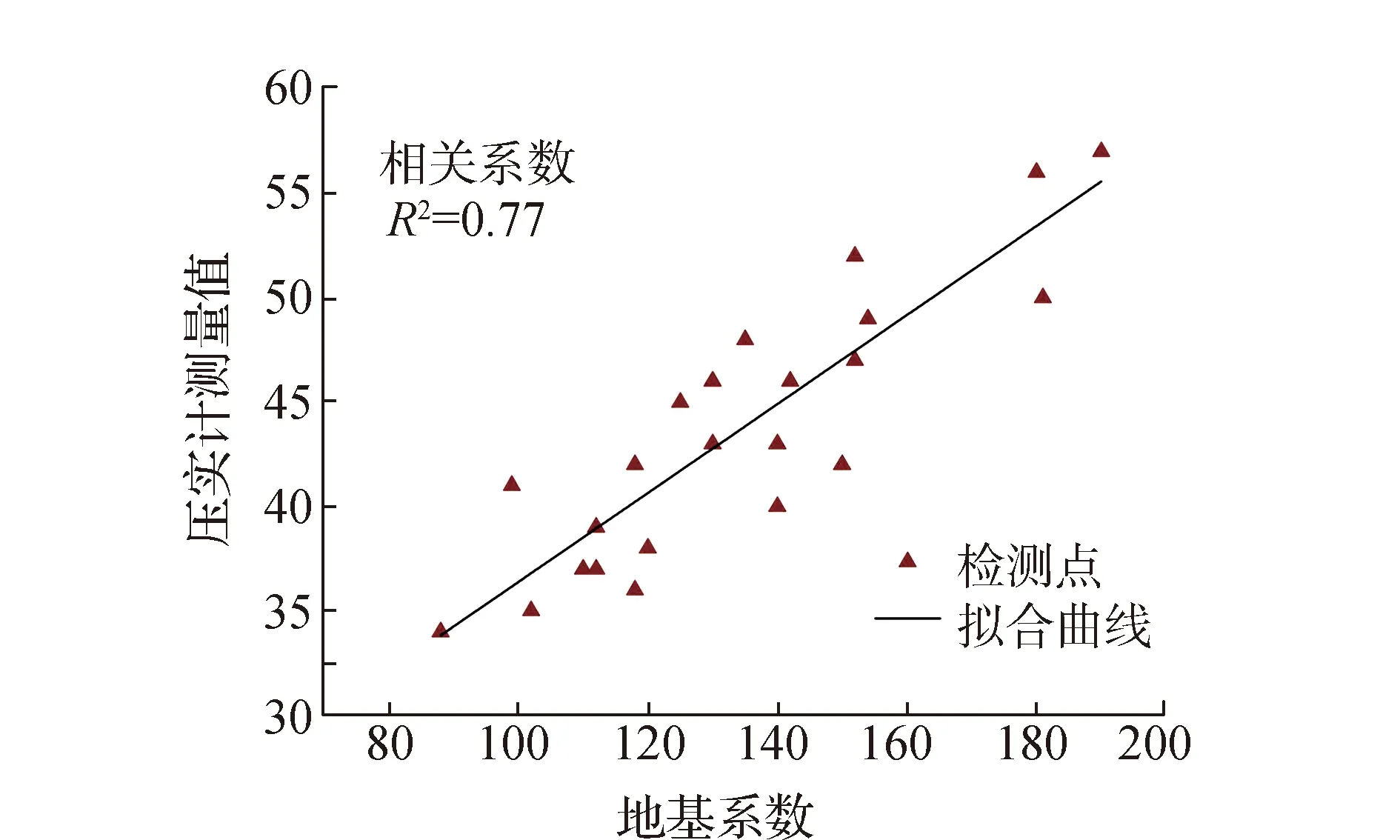
图8 高填路基边缘部分相关性校验
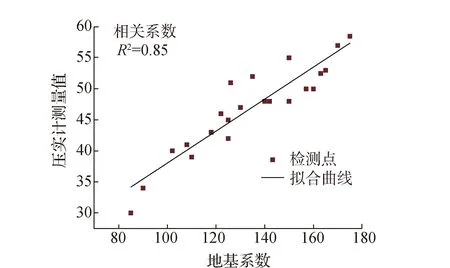
图9 高填路基其他部分相关性校验
图中对应的路基边缘部分拟合函数CMV=0.213 0×K30+15.05, 路基其他部分拟合函数CMV=0.257 8×K30+12.27。
由图8—9及拟合函数可知,路基边缘部分相关性校验的相关系数为0.77,路基其他部分相关性校验的相关系数为0.85,均大于规范中0.7的要求。表明CMV与K30有很好的相关性。
此外,从拟合结果也可以看出,路基边缘区域的拟合相关性要小于其他区域的相关性,表明边缘区域的压实值离散值相对较大,均匀性较弱,进一步证明了将路基边缘部分单独进行均匀性评价的必要性。
综上,基于半变异函数的网格化方法可有效将智能压实数据网格化,且网格化后的数据能很好地表征路基压实状态,由此可利用高填路基边缘部分的智能数据进一步评价其压实均匀性。
3.4 高填方路基边缘压实均匀性评价
由于路基压实过程中土体由松散到密实,土体松散时,智能压实数据离散型较大,且由于此时土体压实状态仍然松散,数据没有实际意义,故通常不采用前几遍的智能压实数据。为了保证试验结果的可靠性,选择试验段的三层路基填土,分别选取每一层路基边缘部分的有效智能压实数据进行均匀性评价。
首先采用现行规范中的方法,即整个碾压面压实值均不小于压实数据平均值的80%进行均匀性评价,将结果汇总如表2所示。
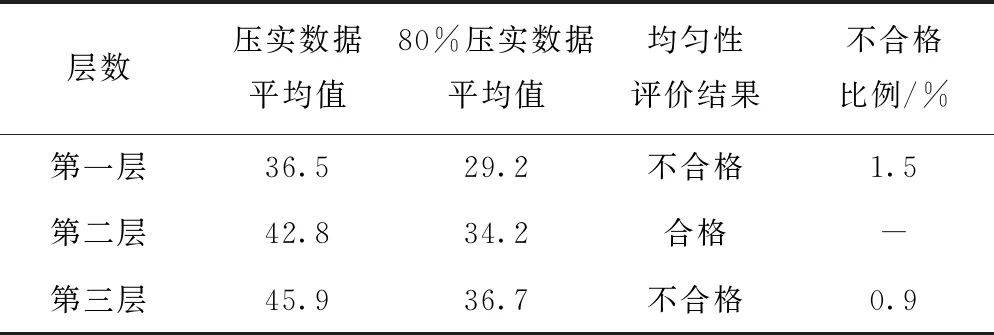
表2 现行规范评价均匀性结果
由表2可知,利用现行规范评价均匀性,三层填土中,仅有第二层的均匀性评价结果合格,即所有的压实数据均不小于压实数据平均值的80%。而第一层、第三层均存在一定比例的不合格数据,但是这个比例很低。这种情况下,如果不去考虑不合格区域的空间分布,根据空间分布特征来确定下一步措施,而是再去补充压实,可能出现的情况是:虽然不合格区域的压实值变大,但已经压实合格的区域也进一步被密实,导致压实平均值进一步提高,从而可能继续出现均匀性不合格的情况,形成补充压实负循环效应。因此,在这种情况下,采用文中提出的最近邻法来评价第一、三层中不合格区域的空间分布情况。通过计算,这层填土的最近邻指标p如表3所示。

表3 第一、三层填土不合格区域空间分布结果
由表3可知,第一层的不合格区域最近邻指标p=0.35<0.5,属于密集分布,基于最近邻法的均匀性评价结果为不合格,即这些不合格区域分布相对集中,可能会导致局部的工后沉降,需要对这些部位进行补充压实。但第三层的不合格区域最近邻指标p=1.29>0.5,属于分散分布,且属于分散程度较大的情况,故基于最近邻法的均匀性评价结果为合格,即这些不合格区域分布很分散,且占全面积的比例很小,基本不会对路基后续产生沉降影响,故可不用再进行专门补强。
综上,如果仅仅用现行规范评价均匀性,由于土体较大的变异性以及系统误差等原因,很容易产生很小比例的不合格区域。但如果不考虑不合格区域的空间分布,根据空间分布特征来确定下一步措施,会出现重复施工等问题。而引入基于最近邻法的均匀性评价后,可以描述这些小比例不合格区域的分布情况,针对不同的分布特征,采取更加合理的措施。故文中提出的基于最近邻法的均匀性评价可以为高填路基边缘区域的不均匀性评价提供补充指标。
4 结 论
1)基于半变异函数的网格化方法,通过现场实际数据分析发现,路基边缘区域的压实值要整体略小于路基其他部分的数据,证明将路基边缘部分单独进行均匀性评价的合理性和必要性。
2)现行智能压实规范均匀性评价方法未考虑不合格区域的空间分布,可能会出现重复施工等问题。而引入基于最近邻法的均匀性评价后,可以描述这些小比例不合格区域的分布情况。
3)将现行均匀性评价方法与最近邻法指数法结合后,可更合理地评价高填路基边缘部位的压实均匀性,而且可针对不合格区域不同的分布特征采取更加合理的措施。
猜你喜欢
奋斗(2021年9期)2021-10-25
当代陕西(2020年15期)2021-01-07
城市道桥与防洪(2019年5期)2019-06-26
人大建设(2019年11期)2019-05-21
西南石油大学学报(自然科学版)(2018年6期)2018-12-26
环境保护与循环经济(2017年2期)2017-09-26
通信产业报(2016年44期)2017-03-13
中国环境监察(2016年12期)2016-10-24
工业设计(2016年4期)2016-05-04
雕塑(1999年2期)1999-06-28
