
基于一维卷积神经网络的加密单数据包分类*
2022-04-24 05:29周慧怡何丽华劳传媛蒙江
桂林航天工业学院学报 2022年1期
周慧怡 何丽华* 劳传媛 蒙江
(桂林航天工业学院 计算机科学与工程学院,广西 桂林 541004)
中国互联网络信息中心(CNNIC)在京发布第46次《中国互联网络发展状况统计报告》[1]中指出,截至2021年12月,我国网民规模达10.32亿,在线办公、移动支付、手机购物等多个领域得到了飞速发展,不同领域对数据的实时性、安全性、数据通信量具有不同的要求。基于移动设备的支付、通信等应用软件在交互过程中涉及个人隐私敏感信息,由此对网络安全、服务质量等都提出了新的要求[2]。随着网络应用的快速发展,如何保证网络安全和提升网络服务质量成为行业关心的重点问题,流量分类作为数据处理的关键环节之一而成为重点研究对象。
在早期的流量识别发展中,固定的服务使用的是大众所熟知的端口号,网络流量的种类相对较少,此时可以根据流量的端口号来区分不同的网络应用,此方法简单便捷、识别效果显著。随着网络动态端口技术的发展,使用端口识别的方法逐渐失效,随之而来的是基于深度包检查的方法,该方法要求对数据包载荷部分可见且特征值已知。在面临操作系统漏洞、网络安全的威胁时,越来越多的软件应用使用加密技术来加强数据传输及保存的安全,通过VPN对IP数据包的过滤、识别和封装等安全处理,可以有效实现数据的加密保护[3]。由于流加密和封装等新技术的兴起,流分类已成为一项具有挑战性的任务,经典流分类策略的性能已经下降[4]。早期网络流量分类的方法主要为基于端口识别和基于深度报检测[5],近几年,基于深度学习的分类方法被广泛应用到网络流量分类中。本文主要工作体现在以下几个方面:
1)设计提出了基于单个数据包的一维卷积神经网络模型,以单个数据包形成样本数据。由于数据样本之间具有不均衡性,结合随机欠采样和过采样的方式实现模型训练,破除了目前广泛使用数据流的限制,缩短了数据样本形成的时间,从而提升了卷积神经网络在流量分类中的实际应用。
2)将网络流量中单数据包的流量数据提取出常用的五元组信息,加上数据包的统计特征和应用层数据形成基本样本数据,将样本数据根据实际需要缩短到256到784字节之间的范围。
3)提出池化层自适应计算选择池化层的核长度和步长公式,实现了不定长样本数据均能在已训练好的一维神经网络模型的应用,从而提高模型的泛化能力。
1 相关工作研究
在流量分类发展中,主要集中在样本的数据处理和模型的改进提升方面。Yamansavascilar B在文献[6]中使用J48、随机森林、k-NN、贝叶斯网络模型对UNB ISCX的应用流量数据进行分类预测,采用数据集的111个特征作为训练特征时k-NN达到了93.94%的最高准确率,由此表明机器学习在应用流量处理的有效性。Fan Z在文献[7]中,对比了基于端口、基于负载信息的算法和机器学习(SVM和K-means)的方法,提出将负载信息进行统计后形成样本特征进行机器学习模型预测的方法,该方法达到了95%的准确度。Moore在文献[8]中提出了基于流量统计的248个特征概念,并以此形成了一套得到公开认证的流量数据集,然而提取这248个数据特征需要耗费一定的时间,需要非常高度的掌握数据的基本信息含义。深度学习的方法常常可以对数据进行自动编码,从原始的数据集中自动提取出更加包含具体意义的特征,自适应的去深度挖掘数据之间的关系,从而实现对数据的分类。
王伟在文献[9]中对加密流量数据处理成以数据会话(Session)和流(Flow)的端到端的数据形式,主要以会话数据和应用层的数据进行一维卷积神经网络(下文简称一维CNN)的分类研究,该方法在公开的加密流量数据集上取得了优异的表现。同时其在文献[10]中基于加密数据集提出了端到端的数据提取方法,发现一维CNN比二维CNN以及C4.5决策树的预测效果更好。Zou Z在文献[11]中将卷积神经网络从流中连续的三个加密数据包中提取数据,然后使用循环神经网络对数据进行训练预测,并且效果超过了使用流的前N个包作为训练样本。Wang W在文献[12]中将原始流量数据处理成基本5元组(源IP、源端口、目的IP、目的端口、传输协议)、包的大小和数据传输开始的时间,然后对其处理成流和会话的形式,卷积神经网络对恶意软件流量进行分类。郭帅在文献[13]中使用一维CNN将数据流中提取关键特征处理成529字节,对加密流量的12分类中实现了95.5%的准确度。Lotfollahi M在文献[14]中采用一维CNN对包进行分类处理,数据样本长度设置为1 500字节,将无监督的自编码算法(Stacked AutoEncoder)与神经网络进行结合,采用欠抽样的方法来处理各类之间的样本不均衡的问题,12分类的应用达到了95.4%的准确度。薛文龙在文献[15]中,将Inception与CNN模型根据数据特征进行结合,对加密流量进行处理,能够降低网络计算的复杂度,同时将准确度提升到了97.3%。在文献[16]中,Shi H提出了将深度学习与特征选择相结合的方法用于流量分类,将冗余的特征进行删除从而达到降维的目的,从而提高了模型的健壮性。Zhong W在文献[17]中解决样本不均衡的二分类P2P流量时,对比分析了三种不同的样本抽样方法(合成少数过采样技术,随机过采样,随机欠采样)来解决样本不平衡的问题,发现随机过采样是最好的采样方法。
在实际应用的过程中,网络流量的传输速度非常迅速,网络管理中心往往需要对接收到的流量进行快速的分类监察,以防止异常流量的入侵或合理的控制流量传输。对于以流或会话形式的样本数据在样本形成时具有一定延迟性,本文中数据集以单个数据包为单位进行识别提取,结合流量分类中广泛使用的一维CNN作为识别模型,进而实现流量的快速分类,辨别异常的流量。
2 数据分析及处理
2.1 数据集
本文采用Draper-Gil等(2016)提供的网络公开的“ICSX VPN-nonVPN”[18]作为数据集,该数据集以Pcap的格式存储的26GB的7中常规应用数据及对应的加密流量。在文件中包含了不同应用在交互过程实际使用到的相关协议及网络实际使用的服务协议,例如查询地址的DNS服务,因而需要对非相关的协议数据进行过滤。然而数据集未对数据包进行明确的标注分类,为了避免分类歧义,本文根据文献[9]中的数据归类方法对数据进行标记,具体的信息统计及分类如表1所示。

表1 流量分类及应用程序
根据表1的分类将数据集分为12类,可以明确地看到Skype涉及Chat、File transfer、VoIP等类别,此类综合性应用为流量准确分类带来了挑战。在文件处理过程中根据文件Pcap特定的格式提取出单个数据包,同时将数据包中的比特流转化为容易识别的字节流。根据协议的特征将字节流分割成具体含义的字段,以IPV4、TCP/UDP协议的样本数据形成本文的初步基本数据的信息。
2.2 数据预处理
本文根据改进后的一维卷积神经网络能够提高数据处理泛化能力的特点,对数据集进行预处理的过程设计如图1所示。
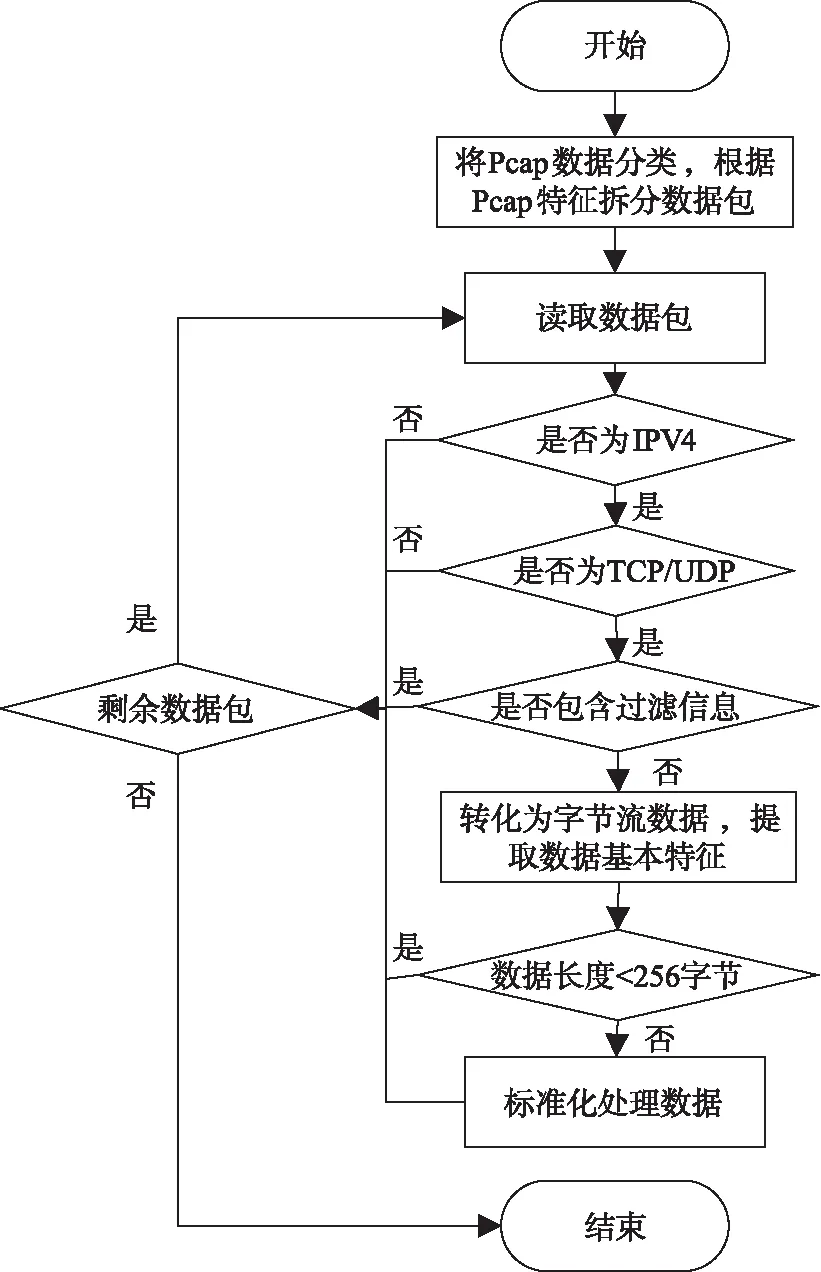
图1 数据预处理流程
数据预处理过程包含数据过滤、数据清洗、数据标准格式化三个阶段。
1)数据过滤
对数据集中包含的交互协议进行过滤,将不在表1中的应用协议的数据包进行删除,只保留包含具有应用层数据的相关数据包。根据Pcap中单个包的描述信息中包含指定关键字的信息进行过滤,例如 “Request” “Handshake” “Alert” “query” “Hello” “Discovery” “NTP”“Response” “Binding”等重点表明交互协议的特征的描述词。
2)数据清洗
针对ICSX VPN-nonVPN数据集的特点,本文选取出数据包中每条数据包中的源IP地址、源端口、目的IP地址、目的端口、数据包长度、加密协议、应用层负载信息等常用的数据内容组成数据的基本特征,对于识别异常的数据包进行丢弃,舍弃数据少于256个字节的数据;数据长度大于784字节时,对超过的数据部分进行截断处理。
3)数据标准格式化处理
将通过清洗的流量数据,进行最大最小归一化处理,并为其贴上标签,最后形成的标准数据格式为:
源端口|目的端口|数据包长度|源IP|目的IP|传输层通信协议|应用层数据长度|应用层数据长度|应用类标签。
将经过处理后的数据,称为New ICSX dataset,共736 312条数据,按照7∶3的比例分为训练集和测试集。
2.3 New ICSX dataset数据分析
经过数据预处理后的New ICSX dataset数据集的具体分布如图2所示,可以看出经过处理后的数据样本分布具有不均衡性,主要体现在各类型的数目相差较大,其中FileTransfer的流量最多,达到了436 169条。一般情况下,文件往往需要连续的传输数据包,导致传输频率较高形成较多的数据包。与之形成鲜明对比的是样本数目非常少的VPNP2P,然后P2P流量样本达到了66 200条,说明对应P2P应用而言,极少使用VPN技术进行访问。在数据类型总量上,Email的总量在5 089条,占较少的样本总数的比例。
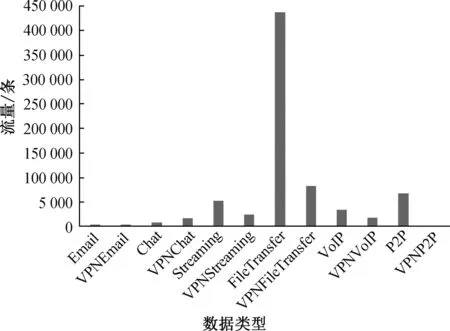
图2 样本数据分布图
从图3可知,常规流量数据总量是VPN加密数据总量的4倍,在日常上网流量中,主要以直接连接网络的方式为主,VPN为用户提供了特定场景的使用,能够通过VPN为用户提供局域网的服务。除了Chat场景外,其余类型的常规流量均大于加密的数据量。

图3 常规流量与加密流量总量对比图
经过数据量对比发现,数据总量较多的应用类型中的数据包的长度往往较大,而数据总量较小的数据包长度偏短。例如,FileTransfer类的应用类型数据的总量比例较大,每个数据包为了传输更多的数据,数据长度往往较大,而Email在实际应用中主要以文字及少量图片、文件以附件的形式传输,数据包的长度往往较小,需要的数据包也较少。为此,本文根据数据流量长度设计了样本不均衡处理,将数据根据长度进行划分成不同的长度等级,分别为ABCDEFG档位,分别对应的长度为256,324,400,484,576,676,784字节。将数据包经过标准化处理后,根据其长度与各等级长度进行对比,将其归为最接近的数据等级,为后续的训练做准备。
3 基于改进一维卷积神经网络的网络流量分类方法
3.1 一维卷积神经网络
卷积神经网络已广泛应用于生活中的多个领域,本文中将数据流量当作序列数据处理,模型结构分为输入层、卷积层、池化层、全连接层、Softmax层。其中卷积层和池化层可以进行多次堆叠构造成不同的模型,不同卷积核和池化方法对模型的训练具有不同的影响。
在一维卷积神经网络中,输入层由向量x表示,看成深度为1的序列数据。卷积层通过卷积核将上一层的抽象特征做进一步提取,从而形成更易识别的高级特征。本文中在卷积层对数据采用“same”填充方式,使得数据保持向量长度不变,深度随着卷积核数目而增加,卷积核用向量w表示,卷积核计算方法表示为:
h=g(x*w+b)
(1)
其中:g( )代表激活函数,通常采用ReLU函数;*代表卷积。
池化层通过池化核长度和步长可以缩小矩阵的尺寸,在降低网络复杂度的同时还可以进一步提取信息特征,通常使用最大池化和平均池化的方法。在池化层时数据可以使用“same”和“valid”两种方法,在使用“same”填充数据时,经过池化的输出层大小表示为:
(2)
其中:Iw表示输入数据长度;Pw表示池化核长度;S为滑动步长。
全连接层则对数据进行高度特征提取后进行模型训练,实现分类。将Softmax层的输出转化为概率分布,从而得到输入数据的分类结果。卷积神经网络数据样本为序列数据时形成了一维卷积网络,将输入样本由图片矩阵转变为向量形式,卷积核和池化层由矩阵也转化为向量,并做相应的模型修改。
3.2 改进池化层
在卷积神经网络中,需要固定样本数据的长度作为训练样本,本文中对一维卷积神经网络的池化层做了进一步改进,实现了不定长样本数据均能在训练好的模型上进行预测输出,从而提高模型的泛化能力。改进方法是保证模型中全连接层的前一层能够固定输出数据的长度,将第二个池化层的数据填充方式设置为“valid”,自适应的计算出对应的池化核长度(Pw)和滑动步长(S),从而保证了模型的稳定性。具体公式表示为:
(3)
Pw=Iw-(Ow-1)*S
(4)
其中:Iw表示池化层的输入数据长度;Ow为输出长度。
3.3 改进的一维卷积神经网络
改进后的一维卷积神经网络模型如图4所示,分别由卷积层、一般池化层、卷积层、自适应池化层和全连接层组成,可以实现自动调整滑动步长和池化核的大小。将通过本文给出的数据预处理方法获得的New ICSX dataset数据作为训练数据,实现对不同长度流量数据的分类,从而提高模型的泛化能力。
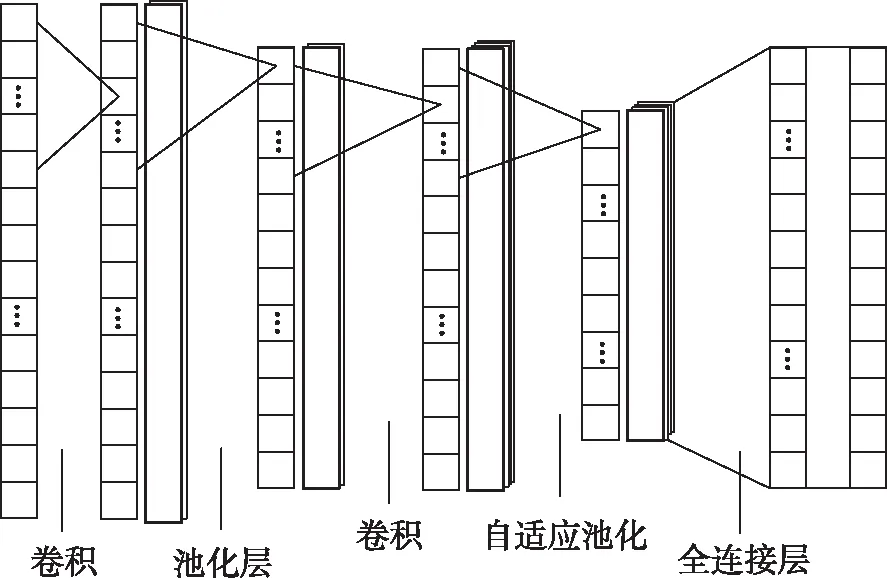
图4 改进一维卷积神经网络模型
改进后的一维卷积神经网络模型中的参数主要参考文献[9],改进池化层的参数通过公式3和公式4进行自动调整,从而实现对不同长度流量数据的处理,具体如表2所示。

表2 一维卷积神经网络参数
模型参数设置初始学习率为0.05,学习衰减率为0.99(用于设置学习率会随着训练次数而变化),添加L2正则化来防止过拟合问题,为TensorFlow中训练的参数设置平滑参数因子为0.99,模型训练迭代次数为100。
4 实验测试与结果分析
4.1 实验环境及评价标准
为了验证提出的数据处理方法在流量分类中的有效性,采用一维卷积神经网络对其进行验证,本文采用TensorFlow作为实验平台,部署在64位Windows Server2016操作系统,64GB内存,Intel Xeon Silver的cpu上。
在评估模型分类的结果时,采用准确率(accuracy)作为首要的评价标准,准确率主要衡量模型在评估分类时候的综合性能,精确度(precision)和召回率(recall)则可以对具体的类预测结果进行评价,如公式5,公式6和公式7所示。
(5)
(6)
(7)
其中:TP,TN,FP,FN来自表3中的混淆矩阵。假设只有False,True两种分类时,TN、TP均表示预测正确的数量,FP表示原本是False类被预测为True类的数量,FN则与之相反。

表3 混淆矩阵
4.2 实验结果分析
为了考查本文提出流量分类模型中关于数据长度对预测结果的影响,为此将数据分为不同的数据长度分别为256,324,400,484,576,676,784字节形成七组对比实验,当数据的实际长度小于设定流量长度时,则做补0处理。由于数据之间存在样本不均衡问题,在章节2.3中已经将样本分为多个等级,在实验中将数据按照A到G的顺序进行批量训练,在训练的过程中对样本采用过采样技术和随机欠采样的技术。将数据较少的样本重复多次采样达到增加样本的目的,而将数据较多的样本每次训练时采取随机采取部分样本进行训练,从而使得不同长度的训练样本达到均衡。
图5为七组数据的对比实验结果,从中可以看到,本文的数据处理方法中关于不同长度的预测准确度均较高,其中长度为676字节的准确度最高达到了98.82%。不同长度的样本数据对模型的预测准确度波动较小,说明当数据样本长度达到256字节后,应用层数据对模型预测准确度的影响较小。在实际应用中为了降低模型的复杂度,则可以选取256字节作为训练样本长度。

图5 模型预测准确度图
从表格4中可以看出,在对比的几篇论文中使用的方法类似,均使用了卷积神经网络,数据长度不一,文献[9]中使用数据流格式作为数据处理方式时,数据长度为784字节,效果最差;文献[13]中改进了数据流格式的处理方式,使得数据的输入长度降低到了529字节,同时准确率也得到了较明显的提升;文献[14]中使用数据包作为模型输入,数据长度达到了1 500字节,数据格式为IP层的首个20字节字段加上其负载的前1 480字节,从模型上进行改进突破,将自编码算法与卷积神经网络进行结合,效果达到了95.40%。在本文中以单个数据包为基础提取出样本数据,将数据长度处理为676字节,实现了最高的98.82%的准确率。

表4 数据预测对比表
从图6中可以看出,不同长度的数据集在模型预测各个类别的精确度趋势像基本保持一致,需要特别注意的是VPNP2P的精确度值为0,意味着对此类的预测分类结果都是错误的,主要原因是该类别的总共样本较少,形成了严重的样本不均衡问题所致。在样本分类中,FileTransfer、VPNFileTransfer的精确率和召回率最高,样本中其所占比例较大,在训练时进行的随机欠采样方法对其几乎没有影响,从而表明该训练方法的有效性。Email、Chat和VoIP的精确度和召回率稍微低一些,通过对比图7可知,预测错误的类型中,这几类所占的比例最大。VPN和非VPN的样本在预测时具有明显的分界线,即当一个VPN样本被错误分类时,其往往会被预测为与之类型接近的VPN类中,反之亦然。

图6 各类之间的精确度对比图

图7 预测混淆矩阵图
在图6和图7中可以明显地看出,模型预测的精确度和召回率在形态上形成了高度的一致性,直接说明类之间存在一定的关联。在精确度最低的Chat类型中,从图7中可以看到错误评估的样本数据主要来源于VoIP、FileTransfer、Streaming和Email,其中VoIP所占比例最大,从中可以分析出,这几类数据与Chat类比较相似,而VoIP类关系最为密切。从预测结果的表现形式看,总体上比较符合现实中Chat的应用场景,因为Chat类中往往会包含了文字传输、文件、视频等传统的数据传输形式。与之类似的是Chat类的部分样本数据转化到了Streaming、VoIP,从而导致其召回率相对较低。

图8 各类之间的召回率对比图
4.3 模型泛化能力
设计了基于不同长度训练得到的最佳模型分别对256~784字节长度的测试数据集进行了预测,得到的实验结果如表5所示,第一列分别表示基于256到784字节的训练集上得到的最佳模型。

表5 模型在不定长数据的准确度
从表5中可以看到,训练集和测试集长度一致时得到的准确率最高,基于不同训练长度分别得到的模型在不定长的测试集上依然获得了比较高的准确度。当训练集长度为784字节时,模型的泛化效果最好,其在长度为676字节的测试集上得到了98.54%的准确度,在长度较短的256字节上依然获得了97.59%的准确度。当训练集在484~784字节的长度范围时,均能找到相对其较短并且预测准确度较高的测试集长度。意味着模型遇到长度比训练集短时,在不做补0处理时依然可以得到较高的准确预测,从而可知模型对输入样本具有一定的泛化能力。
5 结语
本文主要研究了基于单数据包为数据样本的一维卷积神经网络模型在加密流量中的应用,并与现存方法做了对比分析。结果证明,单个数据包能够直接进行模型训练和预测,虽然产生的数据比流、会话的数量大,但是在预测时能够对数据进行快速检测,并且预测精度更高,从而更具有实际应用价值。本文的不足是没有充分考虑到VPNP2P数据样本对预测结果的影响,缺乏对比分析不同的网络模型对数据预测的影响。还有待继续深入研究如何提高其泛化能力,下一步计划是继续探索不同的流量数据处理方式,深入研究多种模型在加密流量数据预测的分析对比。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
销售与市场(营销版)(2021年10期)2021-11-21
北京航空航天大学学报(2021年9期)2021-11-02
民用飞机设计与研究(2020年4期)2021-01-21
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
销售与市场(营销版)(2019年6期)2019-06-21
物联网技术(2018年8期)2018-12-06
中小企业管理与科技(2018年11期)2018-11-06
北京航空航天大学学报(2018年1期)2018-04-20
