
注意力机制的曲面沉浸式投影系统补偿
2022-04-24 09:53雷清桦杨婷程鹏
中国图象图形学报 2022年4期
雷清桦,杨婷,程鹏
1.四川大学视觉合成图形图像技术国家级重点实验室,成都 610000;2.四川大学计算机学院,成都 610000;3.四川大学空天科学与工程学院,成都 610000
0 引 言
随着沉浸式虚拟现实技术的发展,沉浸式投影系统在大型虚拟现实场景中得到了广泛应用,但存在一个重要且经常忽视的问题,就是光线互反射。
大多数沉浸式投影系统都存在互反射现象,互反射现象严重降低了投影图像质量和虚拟现实场景逼真度。该问题常常成为沉浸式系统推广的瓶颈,阻碍了虚拟现实项目的实施。同时,在沉浸式投影环境中,光的反射和折射非常复杂,特别是复杂的投影环境,使得利用光学方法解决这一问题变得困难。互反射补偿是指通过对投影机输入图像进行补偿,得到能够提高投影图像质量、消除互反射影响的图像。典型的沉浸式投影补偿系统包括投影仪—摄像机对和一个放置在适当距离和方向上的曲面屏幕,如图1所示。

图1 曲面投影系统的实验场景Fig.1 Inner-reflection compensation system
现行方法大多是先建立场景几何模型,然后再寻找光的反射函数,计算光线在屏幕间的互反射。虽然这些方法相对容易实现,但是主要存在3个问题。1)在沉浸式投影环境中,光的反射函数通常比较复杂,大多数方法都需要大矩阵进行求逆运算,而该矩阵的逆却可能是不存在的,无法进行求解。2)传统的互反射补偿方案由于不可避免的数学误差,难以产生高质量的视觉效果。3)以往的解决方案大多是对整幅图像进行补偿,忽略了图像亮度不同区域的补偿强度应该不同的问题。目前,还没有研究针对互反射问题的差异化提出补偿方案。Huang和Ling(2019a,b)提出了新的基于卷积神经网络(convolutional neural network,CNN)的光补偿算法CompenNet和CompenNet++,与传统方法相比,在光补偿方面具有更大优势。受此启发,本文提出一种新的基于互反射通道(inter-reflection channel,IRC)先验补偿网络Pair-Net,充分考虑了沉浸式投影环境下图像不同区域的补偿强度应该不同的特点,设计了两个结构相同的端到端的子网络分别负责对高亮度区域和低亮度区域进行补偿。通过使用注意力机制,使两个子网络能够分别学习到原图中两个区域的补偿函数。而注意力图的生成是通过IRC先验图的监督学习得到的,能够为两个网络划分出亮度不同区域。图2展示了本文的解决方案,可以看出,经过补偿的投影结果(图2(d))在视觉上明显比未经补偿的投影结果(图2(b))更接近原图。

图2 曲面投影系统互反射补偿实例Fig.2 Inner-reflection compensation for curve projection screen based on Pair-Net ((a)original image;(b)camera-captured image when original image is projected; (c)compensated image;(d)camera-captured image when compensated image is projected)
综上所述,本文方法主要有以下贡献:1)在沉浸或半沉浸式投影系统中,提出通过IRC先验获取投影图像不同区域的亮度信息;2)提出一种新型补偿网络Pair-Net,使用两个子网络分别补偿高亮区域和低亮区域,提升了补偿图像质量;3)在互反射补偿问题中使用注意力机制,可以对不同区域进行差别化补偿,提升了补偿图像视觉效果。
1 相关工作
1.1 互反射补偿
1.1.1 基于光传输矩阵的互反射补偿
基于光传输矩阵的补偿算法(Ashdown,2006;Ng 等,2003;Grundhöfer,2013;Grundhöfer和Iwai,2015;Ng等,2012;Wang等,2009)建立在相机的像素点只受投影仪对应像素点影响的假设之上。这意味着投影仪和相机对之间的像素点存在一对一的映射关系。根据这一假设,Ng等人(2003)提出一种近似求解光传输矩阵的逆的方法,采用较小的矩阵初始值模拟计算,利用小矩阵求逆和分层矩阵求逆提高精度。由于采用子矩阵模拟光传输矩阵,在精度上存在不足。实际上对于多数基于光传输矩阵的方法来说,矩阵规模较大,计算量也较大。此外,投影光线和反射光线可以影响周围区域,这意味着像素级光传输矩阵在假设本身上就存在问题。
1.1.2 基于反射模型的互反射补偿
为了避免大规模矩阵计算,提出了越来越多的无矩阵方法,将投影仪作为光源,在真实投影场景中建立光的反射模型(Li等,2013;Bimber等,2006;Takeda等,2016;Habe等,2007;Zou等,2008)。Bimber 等人(2006)提出一种直接互反射补偿方法,通过建立沉浸式投影环境下的真实反射模型,先计算环境中的互反射,然后将原图减去互反射得到补偿图像。Takeda 等人(2016)提出一种投影仪—相机对的空间反射模型,用一种在光线照射下会改变颜色的化合物制作投影屏幕,光线照射可以通过屏幕后面的光感LED(light emitting diode)阵列控制,通过LED阵列改变最终投影图像的显示效果。由于该方法需要通过LED辅助设备进行投影图像矫正,因此实用性较低。
1.2 注意力机制
注意力机制已广泛用于神经网络(Ma等,2012;Mejjati等,2018)。Kuen等人(2016)提出一种递归注意力网络,可以自动学习输入图像中的一系列子区域,用于显著性检测,将这些局部估计区域合并成一个全局估计。Li等人(2017)提出一种通过全局上下文检测目标的注意引导方法,证明了注意力机制在计算机视觉和图像处理任务中应用的优越性。Chen等人(2016)提出一种生成图像中每个像素点的注意力权重的方法,称为像素级别的注意力机制。
本文首次在互反射补偿中运用注意力机制,由于相机捕获的图像是受到互反射影响形成的图像,因此图像上面存在互反射分布信息。利用IRC先验作为注意力图生成器的监督便可以获取不同亮度区域的注意力图。
2 互反射通道
2.1 互反射通道定义
本文提出的互反射通道先验是受著名的暗通道先验的启发,暗通道先验已广泛应用于图像去雾领域(Xu等,2012)。互反射通道(IRC)基于投影图像像素点的亮度值通常高于原始图像,并且原始图像中亮度较高的图像受互反射影响较大、亮度较低的图像受互反射影响相对较少这一事实。因此,获取相机拍摄图像三通道的高值区域,能够有效描述受互反射影响更大的区域。本文将这种情况定义为互反射通道。对于相机拍摄的投影图像Icam,互反射通道S可描述为
(1)

通过上述操作,能够获取到沉浸式投影系统的高亮度区域,这就是IRC的定义。IRC不仅包含反射信息,也包含原图的高亮信息,高亮区域反射越强,对周边区域影响越大。IRC的高亮区域主要由两个因素造成,一是互反射,互反射几乎存在于投影图像的所有区域,特别是在输入图像的高亮度区域。二是输入图像中的高亮度区域和物体,如天空、海洋、雪地或白羊,也将导致IRC中的高亮度值。利用IRC得到的沉浸式投影系统的反射信息,可以监督Pair-Net的注意图的生成,使高亮和低亮区域按合适的权重进行补偿。
2.2 IRC的优势
图3是获取的投影图像的IRC先验图,可以看出,由于原图左上角的光晕影响以及互反射造成该区域的图像亮度较高。通过IRC先验,能够有效获取到原图的高光区域以及受到互反射影响的区域。在训练中,可以将IRC先验作为注意力掩膜来区分高亮度和低亮度区域,从而使用双网络进行差异化补偿。

图3 投影图像IRC例图Fig.3 The IRC prior of projection image
传统暗通道图像先验方法主要对原始图像的特征区域进行区分,并计算区域最小值,这样的区域特征信息对于互反射补偿问题是无效的。这是由于在投影系统中的互反射补偿问题中,场景中的光污染是互反射造成的,图像中的高亮区域对投影结果影响更大,而非暗通道特征区域信息。此外,IRC先验是基于投影图像的特征进行计算的,除了能够获得原图的高亮区域外,受互反射影响形成的高亮区域也可以提取出来。因此,本文提出并采用IRC先验而非暗通道作为区域特征提取的监督先验。
3 Pair-Net网络设计
3.1 曲面投影系统的数学模型
本文提出的互反射补偿系统由一个未校准的相机—投影仪对和一个固定距离和方向的曲线投影屏幕组成,如图1和图4所示,其中,E为全局光照。整个曲面投影系统可以描述为

图4 曲面投影系统的光传播Fig.4 The light transmission process of curve shaped screen
Icam=fc(fs(fp(Iin),E,s))
(2)
式中,Iin是投影仪输入图像,Icam是相机拍摄图像。
fp和fc是投影仪和相机的转换函数,fs是光线在屏幕间的反射函数。由于不同屏幕材质具有不同的光线反射率,本文使用s表示屏幕的反射率。同时,由于本文专注解决沉浸式投影系统的互反射问题,因此控制环境光照为E=0,避免环境光照的影响。为了简化公式,可以将投影仪—相机的转换函数合并成为一个函数T,式(2)可以重新表述为
Icam=T(Iin,s)
(3)

(4)
(5)
3.2 基于深度学习的公式
本文使用投影图像与相机拍摄图像作为训练集,由式(3)变形可得
Icam=T(Iin,s)→Iin=T-1(Icam,s)
(6)

Ipred=Tθ(Icam,s)
(7)

(8)

(9)

(10)
采用Loss=l1+lssim组合作为损失函数的原因在于,l1损失函数能够很好地对图像颜色进行优化,而结构相似性损失函数和l1损失函数能够优化生成图像的整体质量(Zhao等,2017)。
3.3 互反射补偿流程
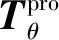

图5 Pair-Net补偿流程Fig.5 The compensation process of Pair-Net((a)project and capture images with a camera;(b)the structure of Pair-Net;(c)the process of compensating images))
在训练过程中,前景网和背景网分别以两幅几何校正后的图像作为输入。子网的两个输入和输出都是256×256×3。然后,将两个子网的输出图像根据掩膜网生成的注意力图进行融合得到生成图像。
3.3.1 前景网络和背景网络的设计
在前景和背景网络中,输入图像送入一个卷积层序列进行降采样。因为更深层的网络结构允许更为复杂的模型映射,从而有更大的潜力提高网络精度和生成高质量图像(Ronneberger等,2015)。因此,在降采样中间利用残差块序列加深网络,提高生成图像的质量。残差块通过将低层次特征与当前层特征相结合,可以有效训练更深层次的网络。同时,利用跳卷积将低层次特征信息传递给深层网络保证低层次特征不会丢失。然后,利用3个反向卷积层,逐步向上采样到256 × 256 × 3作为前景和背景网络的输出。具体子网络架构和残差块架构如表1和表2所示。

表1 子网络架构Table 1 The structure of sub network

表2 残差块架构Table 2 The structure of residual block
3.3.2 掩膜网的设计
由于在未投影前不可能获取每幅投影图像的IRC,而且互反射强弱依赖于环境。为此,本研究采用一个掩膜网S(图5(b))监督生成注意力图,该注意力图能够学习IRC的光照信息。掩膜网的架构非常简单,如表3所示,由4个卷积层和1个残差块组成,对图像特征信息进行编码。同时利用两个卷积层对特征图进行上采样,得到256 × 256 × 1的输出。由于未经投影无法直接获得一幅投影图像的IRC,因此通过学习的方式获取待补偿图像的IRC。将掩膜网络的输出与训练集输入图像(相机拍摄的受互反射影响的图像)的IRC计算一个L1+L2损失。经过训练,掩膜网络能够学习到图像中的高光部分以及可能受到投影互反射影响的部分,从而得到一个近似于IRC的掩膜。

表3 掩膜网架构Table 3 The structure of mask network
3.4 基于注意力机制的互反射补偿



(11)
(12)
(13)
4 实验及评价指标
4.1 客观评价指标
采用传统的像素级别指标峰值信噪比(peak signal to noise ratio,PSNR)、结构相似性(structural similarity index,SSIM)和均方根误差(root mean square error,RMSE)等评价图像质量。由于曲面投影屏幕的几何变形不能得到准确校正,导致评价指标结果偏低,不能很好地反映光照的消除程度,因此在采用传统图像评价指标的同时,本文提出一种新的图像指标评价方式——感兴趣区域(region of interesting,ROI)分析。通过PSNR、SSIM、RMSE和ROI分析,共同说明方法的有效性。
ROI分析的基本思想是收集不同算法的投影图像,在每幅图像中选择几个相对平滑区域,计算区域均值和标准差。区域均值表示区域光照,标准方差描述区域质量。最后,将每个区域的方差绘制在图中与均值中点垂直的直线上。具体计算为
(14)
(15)
式中,μk和δk为投影图像的第k个子区域的均值与方差,m和n是该子区域的高度和宽度。上述指标可以用来比较投影图像与原始图像的亮度差距和图像质量。
4.2 数据集
实验的投影仪—摄像系统由2 992 × 2 000像素分辨率的尼康DX VR相机和1 920 × 1 080像素分辨率的JMGO G7投影仪组成。相机与投影仪之间的距离为500 mm,投影仪前方有一个弧形屏幕,距离为800 mm。相机的白平衡模式、快门速度、感光度和对焦分别设置为自动、1/45、200和光圈值f=5.6。为了模拟真实的沉浸式系统,排除全局光的影响,实验在黑暗环境中拍摄照片。
由于沉浸式投影系统的研究没有相应的公共数据集,本文使用相机拍摄图像,构建Cam-Pro数据集,包括5 000幅用于训练的256 × 256 像素的RGB图像和800幅用于训练过程中进行网络拟合程度测试的图像。同时针对互反射补偿算法的特殊性,采集50幅色彩风格不同的图像用于算法最终补偿效果的客观指标测试。如图5(a)所示,由于曲面屏上的投影图像总是伴有几何畸变,不能直接作为数据集,因此对上述数据中相机捕获的图像都进行几何校正(Huang等,2019a)。为了便于图像预处理,将采集的摄像机图像和原始图像统一下采样到1 920 × 1 080像素。如表3,由于网络结构的输入层图像尺寸为256×256×3,因此需要将下采样图调整到256 × 256 × 3作为网络输入。
4.3 实现细节
实验在PyTorch框架下训练、20个epoch,batch-size为16,优化函数采用Adam函数,学习率由1E-3逐步提高到lE-4。
5 实验结果
5.1 对比现行方法
在ROI评价指标的基准上,与3种无注意力机制的方法,即Bimber等人(2006)方法、CompenNet方法和CompenNet++方法进行对比,视觉效果比较和ROI分析分别如图6和图7所示。

图6 不同方法的视觉效果比较Fig.6 Comparison of visualization results among different methods((a)ground truth;(b)uncompensated;(c)CompenNet;(d)CompenNet++;(e)Bimber et al.(2006);(f)Pair-Net(ours))

图7 不同方法补偿结果的ROI分析Fig.7 ROI analysis of compensation results of different methods((a)row 1 in Fig.6;(b)row 2 in Fig.6;(c)row 3 in Fig.6;(d)row 4 in Fig.6)
在比较方法中,Bimber等人(2006)的方法建立了真实投影环境的数学模型,将投影屏幕划分成n个子区域,并计算区域之间的互反射,该方法需要获得所有与环境有关的参数,如镜头畸变、表面反射和投影—相机对几何位置的细节信息,但在真实场景中,由于投影环境不同,这些参数很难保持不变,对实际使用会造成一些不便。本文提出的Pair-Net无论是视觉效果还是ROI分析,都比Bimber等人(2006)方法有明显改进。
为了说明互反射问题的难度和注意力机制的有效性,将Pair-Net与基于深度学习的端到端网络CompenNet和CompenNet++进行比较,3种模型在同一数据集上训练。CompenNet和Compennet++在不考虑不同区域不同光照强度情况下对投影图像进行全局补偿。观察这两个模型的结果,可以看到它们对输入图像进行了相同强度的补偿,可以很好地去除高亮区域的互反射,然而低亮区域太暗,图像色彩质量严重下降。从图7的ROI分析可以看出,CompenNet与CompenNet++补偿图像的标准差异较大。而Pair-Net补偿的图像在区域均值和方差上都与原图更加接近,能够在很好地消除反射光的同时,得到更好的成像质量,在评价指标和视觉效果方面均优于CompenNet和CompenNet++。
不同方法的PSNR、SSIM和RMSE如表4所示,计算方法为使用相机拍摄补偿图像的投影经几何矫正后与原图计算。从表4可以看出,4种方法的PSNR和SSIM指标较原图均有比较显著的提升,说明互反射得到了消除,投影图像质量得到了增强。本文方法的PSNR和RMSE指标均优于其他方法,SSIM指标居于第3,未经补偿的图像投影和Bimber等人(2006)方法获得的SSIM指标较高,原因在于SSIM指标更注重考量图像的结构性和清晰程度,而本文方法以及基于深度学习的方法的图像都是经过网络生成的,在图像清晰度和结构相似性方面相较于原图有一定程度的失真,因此造成了SSIM指标偏低,但是在可接受范围内。
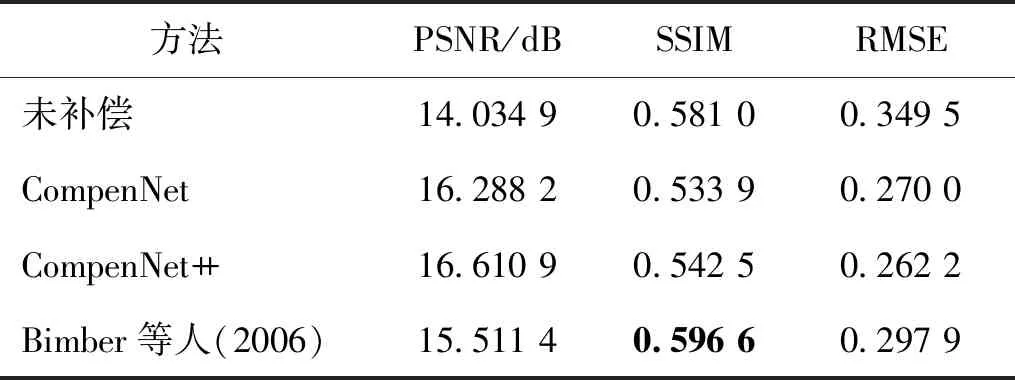
表4 不同方法的质量评价Table 4 The quantitative indexes of different methods
5.2 单网络与双网络结构对比
为了验证双子网络结构设计的有效性,设计了一个单补偿网模型进行对比,实验结果如图8所示。可以看出,单网络模型无法在不同补偿强度下对高、低亮度区域进行自适应补偿,低亮度区域在投影图像中变得亮度极低,意味着不同亮度区域进行了同一强度的补偿,同时单网的色彩失真问题比较严重,这是由于单补偿网络的算法对全局采取一致性的补偿强度,造成不同区域间存在色差。而Pair-Net对不同区域采取不同补偿强度,能够得到正确的颜色。
图8表明,双网络结构设计能有效消除沉浸式投影系统中的互反射,恢复投影图像的颜色和质量,相较于基于全局水平考虑的单网络设计,Pair-Net的双网络设计能够差异化对待不同亮度区域,提升图像质量,获得更加合适的色彩效果。单网络与双网络结构的ROI分析如图9所示,可以看出,Pair-Net取得了与原始图像最接近的均值方差。

图8 单网络结构与双网络结构投影效果对比Fig.8 Comparison of projection visualization results between single-net and Pair-Net((a)ground truth;(b)uncompensated;(c)projection visualization results of single net;(d)projection visualization results of Pair-Net(ours))
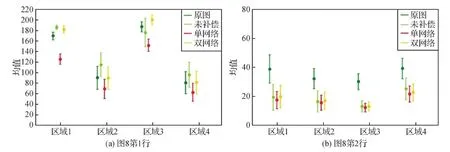
图9 单网络和双网络补偿结果的ROI分析Fig.9 ROI analysis of compensation results of single-net and Pair-Net((a)row 1 in Fig.8;(b)row 2 in Fig.8)
5.3 IRC先验的作用
注意力机制在Pair-Net中起着至关重要的作用,能够差异化补偿原图的高亮区域和低亮区域,提升最终补偿图像的质量。而IRC先验的作用是监督生成注意力图,提供有效的互反射分布信息。如果将注意力图ircback替换为全为1的掩膜,即将整幅图像标记为背景,则得到带有背景补偿强度的整幅图像补偿结果。如果ircback均为0,则Pair-Net将成为只考虑前景补偿强度的补偿结构。如果缺少IRC注意力图的监督,则暗区域会过度补偿,而高亮度区域补偿程度不够。
为了验证IRC先验监督和注意力机制的有效性,设计了一个明通道与IRC先验的对比实验。实验1采用原始投影图像的明通道作为注意力图的监督。明通道作为图像处理领域常用的算法,能够获取原始图像高亮度区域的掩膜。实验2采用IRC监督生成不同的前景和背景掩膜作为对照实验,IRC监督不仅考虑了原始图像的亮度信息,也学习沉浸式投影系统中的互反射信息。实验结果如图10所示。可以看出,使用明通道不能很好地进行前景和背景的差异化补偿,导致投影图像颜色失真。观察图10第2行可以发现,使用明通道作为监督的补偿图像的天空区域光照没有很好地消除。而Pair-Net针对高亮度的天空区域和低亮度的鹿区域进行了很好的差异化补偿,最终效果更加优秀。明通道与IRC先验的ROI分析如图11所示,可以看出,IRC监督的互反射消除效果更好,图像质量优于明通道。

图10 明通道与IRC先验投影效果对比Fig.10 Comparison of projection visualization results between bright channel and IRC prior((a)ground truth;(b)uncompensated;(c)projection visualization results of bright channel;(d)projection visualization results of IRC prior)

图11 明通道与IRC先验补偿结果的ROI分析Fig.11 ROI analysis of compensation results of bright channel and IRC prior((a)row 1 in Fig.10;(b)row 2 in Fig.10)
6 结 论
本文基于注意力机制提出一种互反射补偿网络Pair-Net,解决了投影式虚拟现实系统中由于光照冗余反射造成图像质量下降问题。同时提出IRC先验,有效获取了投影图像中的高光区域以及原始图像的高光区域用于监督注意力图的生成,能够提升补偿效果。
Pair-Net基于IRC先验监督生成的注意力图,关注强互反射区域,对互反射较强的区域增强补偿效果,对较弱的互反射区或低亮区域在投影后使其光强保持在合适水平。实验数据集通过真实投影场景收集获得,测试数据在相同实验场景进行测试从而保证算法的有效性。与现有算法相比,本文算法的PSNR和RMSE指标获得最高分值,SSIM指标位居第二,ROI分析展示了本文算法在互反射消除上的优势。在人眼视觉感受上,本文提出的算法基本不存在严重色差,具有很好的人眼视觉感受。实验结果表明,本文方法在客观指标和视觉效果上均优于传统方法和基于CNN的光度补偿算法。
然而,本文算法存在一些局限,将在后续工作中进一步研究。首先,采用端到端的CNN网络进行补偿需要对齐的图像数据集。因此,对某些无法使用照相机收集到整个投影场景图像的虚拟现实设备,该方法需要进一步改进。其次,本文算法生成的图像一定程度上存在模糊问题,与传统算法相比,SSIM指标有所下降,因此,生成图像清晰度仍然有提升的空间。
猜你喜欢
词学(2022年1期)2022-10-27
中国音乐学(2022年1期)2022-05-05
新高考·高一数学(2022年3期)2022-04-28
测绘地理信息(2022年2期)2022-04-02
客联(2021年9期)2021-11-07
红蜻蜓·中年级(2021年6期)2021-09-10
计算机与网络(2021年9期)2021-08-03
学生天地·小学低年级版(2019年5期)2019-06-05
电脑知识与技术·经验技巧(2018年2期)2018-05-21
小天使·六年级语数英综合(2017年5期)2017-05-27
