
着装场景下双分支网络的人体姿态估计
2022-04-24 09:53:42吕中正刘骊付晓东刘利军黄青松
中国图象图形学报 2022年4期
吕中正,刘骊,2*,付晓东,2,刘利军,2,黄青松,2
1.昆明理工大学信息工程与自动化学院,昆明 650500;2.云南省计算机技术应用重点实验室,昆明 650500
0 引 言
单人姿态估计(Wang等,2020)是指识别和定位出输入图像中单个人体的关节点,广泛应用于姿态追踪、人机交互、行为识别以及虚拟试衣等领域。传统的单人姿态估计主要基于图结构模型,Ramanan(2006)将人体表示为多个部件,通过提取手工设定的图像特征解决关节匹配问题。Yang和Ramanan(2011)通过部件的几何形变和外观等信息构建混合部件模型,以约束各个部件的空间关系。代钦等人(2017)定义人体部位的遮挡级别,通过部位形变模型解决人体姿态估计的遮挡干扰问题。传统方法具有较好的时间效率,但受到人工语义标注的限制,很难扩展到背景复杂和人体姿态变化大的场景。为解决以上问题,很多研究工作使用基于深度卷积神经网络方法,通过提取更为丰富的深度卷积特征,解决复杂背景下的人体姿态估计精度低的问题。Toshev和Szegedy(2014)最早将深度卷积神经网络运用于人体姿态估计,采用多阶段回归的思路设计卷积神经网络,以关节点坐标为优化目标,回归输出人体关节点坐标,最终获得准确的人体关节点坐标位置。Tompson等人(2015)改进了已有的回归网络模型,采用逐像素的关节点热图检测代替关节点坐标回归,有效提高了关节点定位的鲁棒性。这些方法极大地促进了深度卷积神经网络在人体姿态估计任务上的应用。
随着网上购物的普及,在线服装购物受到极大欢迎,许多研究者投入到服装分类、服装检索以及虚拟试衣等服装分析领域。Liu等人(2016)提出大型时尚着装数据集DeepFashion用于服装分类和检索。Ge等人(2019)在DeepFashion基础上提出DeepFashion2用于服装检测和识别、分割、检索以及姿态估计等更为全面的任务。这些任务不仅面向大量着装场景下的图像数据集,亦需关注以人为中心的着装图像区域。而着装场景下的人体姿态估计不仅可以精确估计出每个着装图像的人体姿态,同时可以为虚拟试衣、服装推荐和服装检索等服装分析领域提供人体姿态的先验信息。
已有的人体姿态估计方法侧重人体穿着简单的场景,如马克斯普朗克计算机科学研究所(Max Planck Institut Informatik,MPII)人体姿态数据集(Andriluka等,2014)中图像主要为运动、会议以及娱乐等场景,通常这些场景中服装款式单一、服装对人体关节点的遮挡较少。区别于其他场景,着装场景更关注人体穿着服饰的多样性,具有以下特点:1)着装人体图像多来源于时尚街拍,背景更具有多样性和复杂性;2)着装人体姿态多样和视角位置多变;3)人体穿着款式不一且对关节点遮挡的服饰众多、服装纹理以及颜色多样。已有的着装场景下人体姿态估计方法主要有基于着装标签的姿态重定义方法(Yamaguchi等,2012)以及深度学习方法(Marras等,2017),但仍不能有效实现着装场景下的人体姿态估计。目前,着装场景下的单人姿态估计仍然存在以下难点:1)丰富多样的图像背景内容以及人体穿着服饰纹理、颜色信息会对人体姿态估计特征提取造成严重干扰,需提高人体关节点特征提取的准确率;2)多变的人体姿态和视角位置,使人体姿态估计网络学习变得困难,需构造适合学习多变姿态和视角位置信息的姿态估计网络模型,以提高人体姿态估计的鲁棒性;3)着装人体姿态可见性受到人体穿着服饰的干扰,导致人体姿态估计时存在关节点误定位问题,需结合着装语义部位,以提高人体姿态估计的精度。
因此,本文以着装场景下的时尚街拍图像为例,提出结合姿态表示和部位分割的双分支网络,实现着装场景下高精度的单人姿态估计。本文方法流程如图1所示,主要贡献如下:1)通过在堆叠沙漏网络的基础上增加多尺度损失与特征融合,构建着装姿态表示分支网络,以学习关节点的局部和全局特征,解决着装图像多样的背景和人体穿着服饰对关节点特征提取的干扰,增强关节点的定位精度;2)基于对着装图像数据集中着装人体姿态聚类得到的姿态模板,定义姿态类别损失函数,并结合欧氏距离损失函数构造姿态表示分支的多尺度损失,提高网络对着装人体姿态变化和不同视角下人体姿态估计的鲁棒性;3)融合残差网络的深层、浅层特征构建着装部位分割分支网络,使用着装部位分割信息对人体关节点定位进行约束,最后通过姿态优化,提升人体姿态估计时关节点的定位精度。
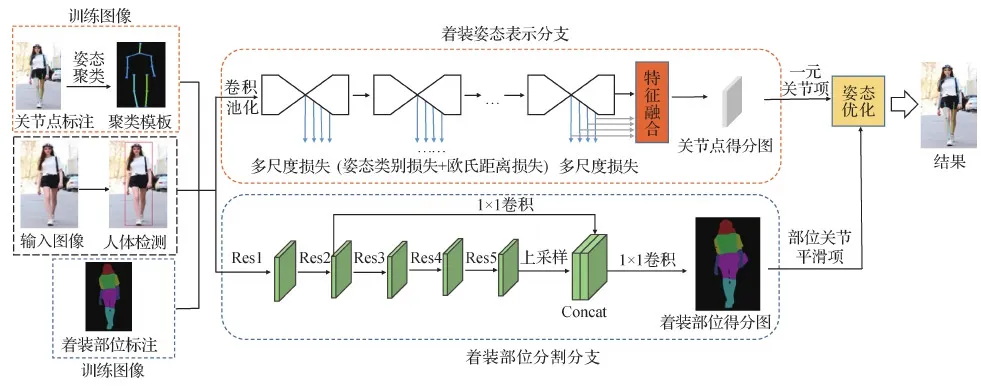
图1 着装场景下人体姿态估计方法流程图Fig.1 The whole framework of human pose estimation in dressing scene
1 相关工作
目前,基于深度卷积神经网络的单人姿态估计方法取得了较大进展。Wei等人(2016)构建多阶段级联的顺序化卷积结构学习关节点空间信息和纹理信息,通过累加所有阶段的响应图将置信度最大的点作为关节点位置实现关节点的精确定位。Newell等人(2016)提出堆叠沙漏网络,每个沙漏模块将特征进行多次下采样和上采样,并将下采样与上采样过程中大小相同的特征融合,不仅获得了不同尺度的关节点特征,同时降低了模型的计算量。后续很多研究工作将沙漏网络作为高效的基础性网络架构。Yang等人(2017)基于沙漏模块增加金字塔残差模块,采用多分支网络对输入特征进行下采样,得到大小不同的特征图,再进行上采样合并到同一尺度,提高模型的尺度不变性。Tang等人(2018)以5个沙漏模块为主干网络,通过将关节点分为低级、中级和高级的组合方式解决单人姿态估计中图像低分辨率模糊问题。
多尺度特征可同时学习丰富的空间和语义信息,有效增强人体姿态估计模型的学习能力。Chen等人(2018)将网络分为全局网络和精确网络两个阶段,全局网络采用基于特征金字塔网络获得多尺度特征并预测简单可见的关节点,精确网络融合多尺度特征预测困难的关节点。Xiao等人(2018)采用反卷积的方式从低分辨率特征图中恢复高分辨率特征图,结合网络每个尺度特征输出关节点热图。Ke等人(2018)通过多尺度特征融合加强人体关节点语义部位特征的学习。Sun等人(2019)提出保持高分辨率特征,并行连接多分辨率子网络,通过多次多尺度特征融合提高关节点定位精度。杨兴明等人(2019)构建多层模型学习不同尺度的结构特征,并通过串联初始特征解决混杂背景的干扰问题。Li等人(2020)在沙漏网络基础上增加多尺度特征并结合注意力机制生成高质量关节点热图。受该方法的启发,本文在堆叠沙漏网络的基础上提出增加多尺度损失与特征融合。与该方法不同的是,本文通过姿态聚类构建姿态类别损失函数,并与均方误差损失函数结合,以提高关节点的定位精度。
人体部位语义分割作为与人体姿态估计高度相关的任务,得到的人体语义部位不仅可以将人体关节点约束在特定的部位区域,亦能辅助人体关节点归类。Yamaguchi等人(2012)从两个不同方向分析了服装和姿态的关系,提出使用每个位置附近解析标签的归一化直方图作为精确姿态估计的附加特征。Ladicky等人(2013)通过对身体部位的语义分割获得人体关节点的外观和形状信息。Dong等人(2014)利用网格布局特征对语义部位和混合关节组模板之间的成对几何关系建模,并构造and-or图同时估计关节定位和语义标签。Nie等人(2018)通过设计解析诱导学习器学习姿态模型的动态参数,提取有用的互补解析特征以提高人体姿态估计精度。Liang等人(2019)采用联合细化网络,联合人体解析中间结果用于细化人体姿态估计结果。上述方法在利用人体部位语义分割结果促进人体姿态估计任务上取得了较好成果,但忽视了人体穿着多变对关节点可见性的影响,不能有效利用人体着装部位构建与人体关节点的位置约束关系。
Xia等人(2017)联合解决人体部位语义分割和人体姿态估计两个任务,通过人体部位语义分割限制人体姿态定位的变化。针对着装场景下的人体穿着多变导致人体姿态估计精度低问题,受Xia等人(2017)方法的启发,本文构建了包含着装姿态表示和着装部位分割的双分支网络。着装姿态表示分支引入姿态类别损失函数,通过多尺度损失与特征融合增强关节点的局部与全局特征,得到初步的人体姿态估计结果。着装部位分割分支融合残差网络的深层、浅层特征输出着装部位分割信息,基于人体关节点作为相邻着装部位的连接点思想构建部位关节平滑项,以约束人体关节点定位,最后通过姿态优化得到精确的人体姿态估计结果。
2 双分支网络
本文通过对输入的着装图像进行人体检测(He等,2017),得到着装人体区域,分别输入到着装姿态表示和着装部位分割分支。
2.1 着装姿态表示
2.1.1 姿态聚类
区别于其他场景的人体姿态,着装场景下的人体姿态具有姿态多样以及视角位置多变的特殊性,导致人体姿态估计网络学习变得困难。本文通过对着装人体姿态聚类得到姿态模板,以表示着装场景下的各类人体姿态。
将着装图像数据集中的着装人体姿态定义为一个向量列表,使用向量P=(C1,C2,…,Cm)∈Rm×3表示一个人的关节点集合。其中,Ci=(x,y,v)∈R3是一个3维向量,x,y表示一个关节点的坐标位置,v表示该关节点是否遮挡,m表示一个人的关节点总数。由于着装人体姿态包含不同视角信息,为此,参照LSP(leeds sports pose)数据集(Johnson和Everingham,2010)关节点类型设定,定义关节点总数为14,包含头顶关节、颈关节、左/右肩关节、左/右肘关节、左/右腕关节、左/右髋关节、左/右膝关节以及左/右踝关节。
首先,对训练集中已标注的姿态信息和人体边界框信息的图像进行预处理。1)利用人体边界框标注裁剪出人体感兴趣区域(region of interest,RoI),并使用姿态坐标信息将人体置于ROI的中心;2)为了便于姿态坐标归一化,将ROI的大小调整到64×64像素;3)由于包含有效关节点较少的姿态不具备代表性,并且在聚类的过程中会成为坏点,因此,仅将数据集图像中包含大于8个有效关节点的着装姿态进行聚类。
然后,采用K-means聚类方法(Zhang等,2019)进行优化。具体为
(1)
式中,S表示k个姿态类别的集合{S1,S2,…,Sk},P表示数据集中标注的姿态,Pμi表示每类姿态集合Si中的姿态平均值。Dist(·)定义了两个人体姿态的距离,计算式为
(2)
式中,m表示14类人体关节点,Cμij表示第j类关节点位置集合的平均值,Cj表示第j个关节点的位置,具体定义为
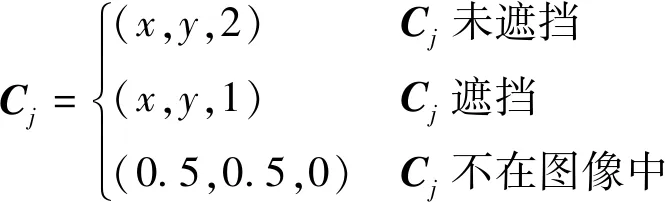
(3)
式中,x和y表示关节点在图像中的像素位置。
最后,将训练集中已标注的多个姿态信息(P1,P2,…,Pn)聚类成k(k≤n)个类别的姿态集合。
聚类后,使用每个姿态类的平均值Pμi构成姿态模板,并将Pμi中v>0.5的关节点设置为有效关节点,最后的姿态模板为Pμi中有效关节点的组合。图2给出了本文训练集中不同k值的聚类结果。其中,k=2时,聚类结果为半身和全身的姿态模板;k=3时,聚类结果为半身、全身正面以及全身背面的姿态模板;k=4时,聚类结果为半身、全身正面、全身背面、侧面的姿态模板;k=5时,引入了左、右侧面姿态模板;当k≥6时,重复增加了右侧面姿态模板,在视角位置产生冗余。因此,最终确定k=5的姿态聚类模板。姿态模板可为人体姿态估计网络提供有效的姿态结构先验信息。由于不同的姿态模板表示各类着装场景下的人体姿态,且本文最终确定的姿态模板数为5,因此通过softmax损失将姿态类别损失函数定义为

图2 着装人体姿态聚类模板Fig.2 The clustering templates of dressed human pose
(4)
式中,Pk是一个1×5的向量,该向量的大小取决于姿态模板的类别数,Sk表示该图像中的人物属于第k种姿态模板的概率。
2.1.2 多尺度损失及特征融合
单人姿态估计中由于关节点定位不准确会导致关节点的错误拼接,本文通过增加多尺度损失与特征融合学习关节点多尺度的深度特征,增强人体关节点定位精度。为此,在每个沙漏模块1/16、1/8、1/4、1/2的4个反卷积层增加损失监督,如图3所示。
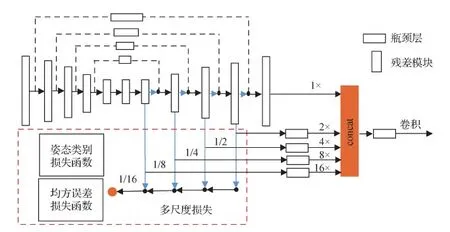
图3 多尺度损失及特征融合Fig.3 Multi-scale loss and feature fusion
为减少原始图像直接输入沙漏网络耗占的显存资源,在图像输入姿态表示分支时进行卷积和最大池化操作,将每个输入图像的分辨率调整至64×64像素;再使用1×1卷积核对4个尺度的特征图进行降维操作,在每个尺度得到与关节点数量相同的特征图维度;最后将关节点真值热图与预测的热图在对应尺度下进行误差计算,这里关节点真值热图大小调整至64×64像素,进而下采样至1/16、1/8、1/4和1/2尺度,并通过1×1卷积将对应尺度下反卷积层输出的特征预测为关节点热图。
数据集图像中关节点真值热图的生成参照堆叠沙漏网络(Newell等,2016),以关节点位置(x,y)为中心,使用2维高斯函数生成第m个关节点的真值热图Gm(x,y),标准差为1像素。为了提供有效的多尺度损失,本文将损失函数定义为每个尺度下的所有关节点热图的均方误差损失之和。因此,第i个尺度预测的所有关节点热图与对应尺度的真值热图损失函数定义为
(5)
式中,M为14,表示预测的14个人体关节点,Pm(x,y)和Gm(x,y)分别表示在像素位置(x,y)代表第m个关节的预测得分图和真值热图。
多尺度损失定义为
(6)
式中,I为4,表示为沙漏模块4个不同的尺度,i表示第i个尺度。
为了给多尺度姿态估计网络提供有效的着装人体姿态先验信息,本文将姿态模板下采样至1/16、1/8、1/4和1/2尺度,并结合姿态类别损失函数,定义最终的联合损失函数为
(7)

融合关节点多尺度特征能够更好地提高关节点定位的鲁棒性,为此基于多尺度损失在最后一个沙漏模块增加多尺度特征融合。采用上采样和concat操作,将4个尺度分别以×2、×4、×8、×16的倍率进行上采样,以融合原始特征。采用反卷积层将融合后的特征恢复到输入图像相同的尺寸,通过1×1卷积层输出像素级人体关节点得分图Pj。通过对所有尺度的特征映射学习,可以全局优化关节点定位,进一步提高人体关节点的定位精度,有效避免关节点的错误拼接。
2.2 着装部位分割
精确的着装部位分割可以为人体姿态估计提供有效的着装部位信息,以增强关节点的定位精度。
基于全卷积网络的方法通常迭代地使用卷积和池化操作,降低了特征映射的分辨率,丢失了更精细的图像信息,导致语义部位分割结果不准确。Ruan等人(2019)提出采用低层特征补偿可引入高分辨率的图像信息。受此启发,本文采用低层特征与高层特征跳跃连接的方式获得高分辨率信息,以增强着装部位分割的准确度。具体地,通过ResNet101(residual neural network)网络提取图像语义部位特征,使用网络的Res2特征捕获高分辨率信息。着装部位分割分支先采用双线性插值对残差网络的最后一层特征Res5进行上采样,并使用1×1卷积降低特征维度,然后使用1×1卷积将残差网络的第2层级特征Res2与上采样后的特征Res5进行跳跃连接操作,获得同时包含高级语义信息和高分辨率信息的特征,最后采用反卷积层将融合后的特征恢复到输入图像相同的尺寸,逐像素计算softmax分类损失,通过1×1卷积层为7个着装语义部位类型输出对应的着装部位得分图Ps。其中,softmax分类损失函数定义为
(8)
式中,wj是一个1×7的向量,si表示该像素属于第i个语义部位类型概率,向量w对应7个语义部位类型,包含上臂、下臂、腿部上半区域、腿部下半区域、头部和身体等6个着装部位以及背景。
3 姿态优化
由于人体关节点存在于相邻着装部位的交界处,以头顶关节与颈关节为例,头顶关节应定位在头部着装部位区域内以及头部着装部位的边界附近,颈关节应定位在头部着装区域或者身体着装区域内以及头部着装区与身体着装区域的相交边界附近,即每个人体关节点类型都关联着1个或者2个着装部位,如表1所示。
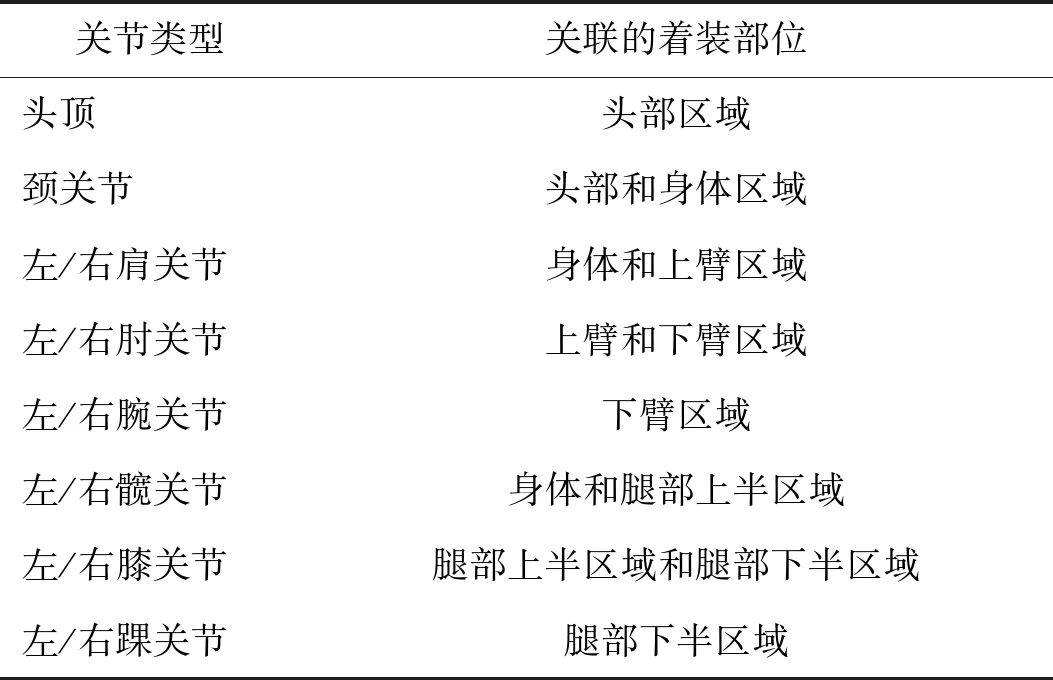
表1 人体关节点与关联的人体着装部位Table 1 Human body joint points and related dressing part/parts
此外,每相邻关节类型都关联着1个着装部位类型,如头顶关节与颈关节的连接线应在头部着装区域内,如表2所示。

表2 相邻关节点与关联的人体着装部位Table 2 Adjacent joint points and related dressing part
因此,基于着装部位与人体关节点的约束关系,设计部位关节平滑项。采用全连接条件随机场(conditional random field,CRF)进行着装人体姿态优化,以获得鲁棒性的关节点上下文关系。
将全连接CRF定义为图结构G={V,E},节点集合V={c1,c2,…,cn}表示所有候选关节点的定位,边集合E={(ci,cj)|i=1,2,…,n,j=1,2,…,n,i (9) 式中,ψi为一元项函数,表示基于关节点得分图Pj在定位ci上的对数似然函数,定义为 (10) ψi,j为二元项函数,表示基于部位得分图Ps在对应着装部位与关节点约束关系的对数似然函数,具体为 (11) (12) 式中,由部位关节平滑项f(ci,cj,lci,lcj|Ps)经逻辑回归得到,ω为权值参数,包含3个类型的特征,fu(ci,lci|Ps)表示关节类型为lci的关节点在定位ci与对应着装部位的约束关系;fu(cj,lcj|Ps)表示关节类型为lci的关节点在定位cj与对应着装部位的约束关系;fp(ci,cj,lci,lcj|Ps)表示关节类型对为(lci,lcj)分别在定位ci和cj与对应着装部位的约束关系。ci和cj表示关节点的候选位置,lci和lcj表示关节类型。 本文基于着装部位得分图Ps构建部位关节平滑项f(ci,cj,lci,lcj|Ps),假设lci为头顶关节,lcj为颈关节,则fu(ci,lci|Ps)是2维特征向量,第1个维度表示ci是否在头部着装区域内,第2个维度表示ci是否在头部着装区域的边界附近(边界的10个像素内)。fu(cj,lcj|Ps)是4维特征向量,第1个维度表示cj是否在头部着装区域内,第2个维度表示cj是否在头部着装区域的边界附近(边界的10个像素内),第3个维度表示cj是否在身体着装部位内,第4个维度表示cj是否在身体着装部位的边界附近(边界的10个像素内)。fp(ci,cj,lci,lcj|Ps)是2维特征向量,第1个维度表示ci与cj连线是否在头部着装区域内;第2个维度表示由ci与cj构造的长宽比为2.5 ∶1的矩形区域与头部着装部位的交并比(intersection-over-union,IOU)。此外,对于相邻关节则提取全部3个特征,对于非相邻关节如头顶与踝关节,将特征fp(ci,cj,lci,lcj|Ps)设置为0。 为了降低全连接CRF计算的复杂性,首先对输入图像进行人体检测并采用非极大值抑制(non-maximum suppression,NMS)筛选关节得分图Pj,为每个关节点类型生成6个候选定位。然后,基于一元关节项和部位关节平滑项,参照DeeperCut(Insafutdinov等,2016)的推理算法,将全连接CRF转换为带有L约束的整数线性规划(integer linear programming,ILP)问题,为生成的候选关节点位置c1,c2,…,cn分配关节类型标签,并组合成多个姿态配置。其中,丢失的关节点得分设定为0.2分,每个姿态的得分为一元关节项里所有可见关节点得分的总和。最后,通过非极大值抑制算法去除相似的姿态配置,并以姿态中心最接近人体检测框中心的姿态为本文最终输出的人体姿态估计结果。 实验硬件平台为Inter Core i9-9900K @3.60 GHz CPU、2080Ti GPU和32 GB DDR4 2 666 MHz Ram,集成式开发环境为PyCharm等。 由于时尚街拍图像易于获取,且包含了着装场景中背景多样复杂、人体姿态和视角位置多变、服装纹理颜色多样以及服装对关节点遮挡较多的特点,因此,本文以时尚街拍图像为例,通过爬取大型时尚街拍图像网站Chictopia,并结合在线图像搜集获得数据集原始图像,构建了一个包含7个语义部位标签和14个人体关节点标注的着装人体图像数据集。该数据集共23 875幅图像,包含男性图像9 256幅和女性图像14 619幅。使用LabelMe对数据集原始图像进行精细的语义部位标注和人体关节点标注,语义部位标注包含上臂、下臂、腿部上半区域、腿部下半区域、头部、身体等6个着装语义部位以及背景。此外,考虑到由于缺少人体姿态视角位置信息导致已有方法对着装人体侧面以及背面视角姿态估计的精度不高,本文构建的着装图像数据集还包含36%侧面姿态、25%背面姿态以及39%正面姿态的着装人体图像,如图4所示。最终选取数据集中的20 000幅图像作为训练集,2 375幅图像作为测试集,1 500幅图像作为验证集。为了更好地学习多尺度人体关节点特征以及考虑到显存大小的限制,本文将所有数据集图像分辨率设置为256×256像素,图像格式均为jpg格式,数据增强包含在[-45°,45°]内随机旋转度数,在[0.65,1.35]内选择缩放比例因子以及水平翻转。 图4 不同视角的姿态图像数量Fig.4 The number of poses with different angles of view 4.2.1 姿态聚类有效性分析 评估方式采用关节点正确估计比例(percentage of correct keypoints,PCK)机制,以检测关节点与对应真值间的归一化距离小于设定的阈值作为正确估计的关节点。参照MPII数据集设定,以头部长度作为归一化参考,阈值以头部长度乘以一个系数表示,如PCKh@0.5表示0.5倍的头部长度作为评估设定的阈值,PCKh的结果表示该阈值内模型在数据集中正确估计的关节点数占总关节点数的比例。 本文使用K均值聚类方法对数据集中已标注的姿态坐标信息进行聚类,图5展示了不同数量的姿态模板构建的姿态类别损失函数对姿态表示模型效果的影响。可以看出,姿态模板数小于等于5时,姿态估计的PCKh值不断上升,姿态模板数大于5时,姿态估计的PCKh值开始下降,这是由于姿态模板数为5时包含了人体正面、背面以及左右侧面的全部视角位置信息。姿态模板数为6时,姿态模板引入了右侧面视角,在视角位置产生冗余,所以本文将姿态类别数设置为5,以构建姿态类别损失函数,提高不同视角下着装人体姿态估计的鲁棒性,进一步提高着装人体姿态估计的精度。 图5 姿态表示模型的PCKh@0.5结果Fig.5 The PCKh@0.5 result of pose representation model 为了说明姿态类别损失函数的有效性,本文确定姿态模板数量为5,并在姿态表示模型的基础上,将有姿态类别损失函数与无姿态类别损失函数的关节点正确估计比例进行对比,结果如表3所示。可以看出,有姿态类别损失的姿态表示模型PCHh@0.5值比无姿态类别损失的提高了0.7%,说明提出的姿态类别损失能够有效提升着装人体姿态估计精度。 表3 有无姿态类别损失对姿态表示模型的影响(PCKh@0.5)Table 3 The influence of the pose category loss on the pose representation model (PCKh@0.5) /% 4.2.2 姿态优化对比实验 图6展示了姿态表示模型中最终优化构造的联合损失函数在训练过程中随着迭代次数增加的损失变化,共迭代500 000次。从图6可以看出,网络具有较快的收敛性能,最终趋于稳定的拟合。 图6 损失函数变化曲线Fig.6 Change curve of loss function 图7展示了在姿态表示模型的基础上无着装部位分割的姿态估计结果、结合着装部位分割优化后的姿态估计结果以及着装部位分割结果。可以看出,本文提出的着装部位分割具有较好的分割效果,在结合着装部位分割优化后,能有效避免人体关节点的误定位。 图7 姿态优化对比结果Fig.7 The contrastive results of pose optimization ((a)original images;(b)without dressed part segmentation;(c)dressed part segmentation;(d)with dressed part segmentation) 图8是姿态表示模型和姿态优化与堆叠沙漏网络的对比实验结果。可以看出,姿态表示模型以及姿态优化在不同归一化距离下都有较高的检测准确率。 图8 不同归一化距离的PCKh结果Fig.8 PCKh results of different normalized distance 4.2.3 姿态估计实验结果 使用PCKh@0.5评估机制分别对人体肩关节、肘关节、腕关节、髋关节、膝关节和踝关节6类关节以及整体进行评估,衡量着装图像中不同人体关节点类型的定位精度和整体的人体姿态估计性能。其中,肩关节、肘关节、腕关节、髋关节、膝关节和踝关节代表左右两侧对称关节点的平均值。表4展示了本文方法与Yang等人(2017)、Chen等人(2018)、Xiao等人(2018)和Sun等人(2019)4种人体姿态估计算法在着装图像数据集上的评估结果。结果表明,本文提出的人体姿态估计双分支网络提高了每类关节点的准确性,并在整体关节点评估取得了92.5%的效果,尤其是在最具有挑战性的肘关节和膝关节,分别较Sun等人(2019)方法提高了1.9%和2.1%。通过对比,验证了本文提出的双分支网络的人体姿态估计方法能有效提升着装图像中人体姿态估计的性能。 表4 着装人体图像数据集上的PCKh@0.5的结果Table 4 The results of PCKh@0.5 on the clothing human body image dataset /% 表5 不同人体姿态估计方法的时间复杂度与检测精度比较Table 5 Comparison of time complexity and detection accuracy among different human pose estimation methods 本文对着装图像进行人体姿态估计,图9展示了人体姿态估计网络模型在着装图像数据集的可视化结果。考虑到既要体现着装场景下人体姿态的特点,又要体现本文提出的双分支网络的人体姿态估计方法的有效性,因此图9选取了不同视角、姿态、服装款式以及背景的人体姿态估计实例,通过与原始堆叠沙漏网络、着装姿态表示模型(堆叠沙漏网络+姿态类别损失+多尺度损失及特征融合)、Sun等人(2019)的方法以及真值的对比,展示本文提出的人体姿态估计双分支网络(着装姿态表示分支+着装部位分割分支)的效果。可以看出,1)堆叠沙漏网络的结果(图9(d))在人体左、右侧面视角出现腿部关节点错误定位,人体背面视角中出现大量关节点漏定位,在背景与人体部位相似、人体着装款式颜色一致和着装服饰遮挡的情况下均呈现出不同程度的关节点误定位问题。为了克服这些问题,本文基于着装人体姿态聚类引入姿态类别损失,并通过增加多尺度损失以及特征融合构建姿态表示模型。2)姿态表示模型的结果(图9(e))有效解决了人体视角多样以及背景和服装款式干扰导致的关节点误定位和漏定位问题。3)本文提出的人体姿态估计双分支网络的结果(图9(f))通过结合着装部位分割约束人体关节点定位,有效解决了由于着装场景中人体关节点易受穿着服饰遮挡导致关节点定位失败的问题,进一步提高了着装人体姿态估计精度。 图9 着装人体姿态估计结果对比Fig.9 Qualitative results of human pose estimation in dressing scene((a)original images;(b)ground truth;(c)Sun et al.(2019); (d)stacked hourglass network;(e)dressed pose representation model;(f)ours) 4.2.4 消融分析 为了验证人体姿态估计网络模型每个部分的有效性,在构建的着装人体图像数据集的验证集上进行消融分析。首先以沙漏网络作为人体姿态估计的基础网络,然后分别在基础网络基础上增加多尺度损失、特征融合以及结合着装部位约束部分。实验结果如表6所示,其中,Base表示基础网络,Base+M表示在基础网络上增加多尺度欧氏距离损失监督,Base+M*表示在基础网络上增加多尺度联合损失监督,其中损失函数包括欧氏距离损失和姿态类别损失,Base+M*+C表示在Base+M*基础上增加特征融合,即着装姿态表示模型,Base+full表示在Base+M*+C基础上增加着装部位分割约束,即人体姿态估计双分支网络。 表6 消融实验(PCKh@0.5)Table 6 Ablation experiment (PCKh@0.5) /% 由表6可见,原始堆叠沙漏网络在着装图像数据集上验证整体的关节点正确估计比例为89.4%,本文提出的人体姿态估计网络模型PCKh整体得分为92.5%,通过结合网络的每个部分将基础得分提高了3.1%。具体地,由于多尺度损失可以较好地捕捉关节点局部特征,通过在每个沙漏模块的反卷积层增加多尺度损失,PCKh得分提高了0.8%。通过引入姿态类别损失函数,多尺度联合损失相较多尺度欧氏距离损失的PCKh得分提高了0.7%,归因于对数据集中姿态的聚类能较好地表征各类着装人体姿态。特征融合可以全局优化人体关节点多尺度特征,为难以估计的关节点提供全局上下文信息,通过在最后一个沙漏模块增加特征融合,在多尺度联合损失监督的基础上PCKh得分提高了0.8%。最后,通过使用着装部位信息约束人体关节点定位,其PCKh得分在姿态表示模型的基础上提高了0.8%。值得注意的是,在增加着装部位约束之后,人体的肘关节、腕关节、膝关节以及踝关节的PCKh得分都有了大幅提高,尤其是具有挑战性的肘关节和膝关节在姿态表示模型基础上分别提高了1.3%和2.3%,归因于着装部位的上下臂和腿部上下半区域的准确分割。总之,本文方法能够有效结合多尺度损失与特征融合以及联合着装部位信息,提升了着装人体姿态估计结果的精度。 此外,为说明提出的双分支网络对不同服饰的通用性,以简单的短袖、短裤穿着为基准,通过对数据集中穿着为长裤、短裤、连衣裙、半身裙、西装、短袖、背心、大衣、套头衫、衬衫、夹克以及其他常见服饰的人体姿态进行评估,结果如图10所示。可以看出,采用双分支网络模型的整体人体姿态估计精度约为92.4%,对穿着不同服饰的人体姿态估计具有较好的鲁棒性结果。 图10 不同服饰种类的人体姿态估计结果Fig.10 The human pose estimation results of different clothing types 针对由于服装款式多样、背景干扰和着装姿态多变导致人体姿态估计精度较低问题,本文以着装场景为例,提出一种着装场景下双分支网络的人体姿态估计方法。该模型融合全局与局部特征,提高了关节点定位精度,引入姿态类别损失提高不同视角下着装人体姿态估计的鲁棒性,再结合着装部位分割约束人体关节点定位,提高了人体姿态估计的精度。实验结果表明,本文方法在构建的着装人体图像数据集上能够提高人体姿态估计精度,关节点正确估计比例达到92.5%。 然而,本文方法还存在一些不足。一方面,针对连衣裙、大衣等对人体关节点遮挡严重的服饰,人体姿态估计精度较低,效果不理想;另一方面,当着装人体的关节点存在过多配饰遮挡时,需要提高算法的关节点定位精度。因此,本文的后续工作将着重围绕这些问题展开,以进一步提高着装场景下人体姿态估计的精度。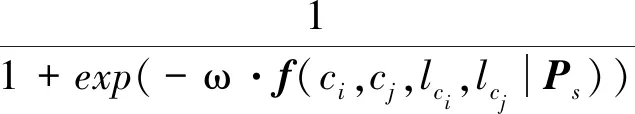
4 实验结果与分析
4.1 实验数据集

4.2 实验结果与性能分析








5 结 论
猜你喜欢
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
学生天地(2020年3期)2020-08-25 09:04:16
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
军营文化天地(2017年6期)2017-06-28 11:30:19
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
阅读(中年级)(2009年11期)2009-04-14 03:16:04
