
MTMS300:面向显著物体检测的多目标多尺度基准数据集
2022-04-24 10:49:48李楚为张志龙李树新
中国图象图形学报 2022年4期
李楚为,张志龙*,李树新
1.国防科技大学电子科学学院自动目标识别重点实验室,长沙 410073;2.国防科技大学信息通信学院,西安 710106
0 引 言
视觉注意是人类视觉系统有选择性地处理显著视觉刺激的一种特殊机制。在计算机视觉领域,视觉显著性的典型应用包括目标检测识别、图像和视频压缩、图像分割以及视觉跟踪等(Borji等,2015)。视觉显著性算法大致可以分为3类,即启发式的方法、基于超像素分割的方法和基于卷积神经网络(convolutional neural network,CNN)或全卷积网络(fully convolutional networks,FCN)的方法。启发式的方法通常直接或间接利用心理学和视觉理论研究成果,此类方法的研究始于1998年左右,典型的有基于认知的Itti模型(Itti等,1998)、基于信息论的AIM(attention based on information maximization)模型(Bruce和Tsotsos,2005)、基于图的GBVS(graph-based visual saliency)模型(Harel等,2006)和基于布尔图理论的BMS(Boolean map saliency)模型(Zhang和Sclaroff,2013)等。基于超像素分割的方法首先利用超像素分割算法将图像划分为超像素,再计算显著性。此类方法的研究始于2011年左右,典型的有RC(region-based contrast)模型(Cheng等,2011)和DRFI(discriminative regional feature integration)模型(Jiang等,2013b)等。在Borji等人(2015)的评估实验中,表现最好的6个视觉显著性模型中有5个是基于超像素分割的方法。基于卷积神经网络(CNN)或全卷积网络(FCN)(Shelhamer等,2017)的方法一般用预训练的VGGNet(Visual Geometry Group network)或ResNet(residual neural network)作为基础网络架构,然后构建特定的卷积层或全连接层,再在MSRA-B(Microsoft Research Asia)(Liu等,2011)、MSRA10K(Cheng等,2015)等显著性基准数据集上进行微调。此类方法的研究始于2015年左右,典型的有MDF(multiscale deep features)(Li和Yu,2016)、ELD(encoded low level distance)(Lee等,2016)和AFNet(attentive feedback network)(Feng等,2019)等。
在视觉显著性模型发展过程中,基准数据集起到了至关重要的作用。在基准数据集上的测试可以使研究者对各种视觉显著性模型进行定量评估和分析,为模型改进与发展提供助力;此外,基准数据集可以训练基于CNN或FCN的视觉显著性模型。
基准数据集经历了从边框标注到像素级标注、从单目标到多目标、从简单背景到复杂背景以及从几百幅图像到上万幅图像的发展历程,公开的基准数据集也越来越多,如表1所示。然而,并非所有关于数据集的文献都详细介绍数据集的构建方法和制备过程,对不同数据集的定量分析和对比也甚少,随着基准数据集的规模和种类不断扩大,这些问题不利于视觉显著性模型的发展。

表1 显著性检测基准数据集Table 1 Saliency detection benchmark dataset
现有的基准数据集大多存在一些偏差,常见的有中心偏差、选择偏差和类别偏差等。中心偏差指在拍摄过程中,拍摄者往往倾向于将目标置于相机视野的中央,这类偏差也称为相机拍摄偏差;选择偏差指在数据集构建过程中,设计者选择图像时带有特定倾向,如只选择背景简单的或只选择目标较大的;类别偏差指数据集中的类别不均衡,此类问题在深度卷积神经网络训练过程中经常遇到。图1是两幅MSRA10K数据集的典型偏差图像。图1(a)具有严重的中心偏差;图1(b)则选择偏差过强(背景极其简单)。

图1 基准数据集中的偏差问题Fig.1 Bias in benchmark datasets((a)center bias;(b)selection bias)
基准数据集偏差问题很大程度上已将显著性模型发展带入歧途,使人们对显著性的概念产生了只要目标够大且位于图像中央就具有显著性的固化印象。在消除数据集偏差方面,已有学者做了一些工作。Shi等人(2016)认为前景和背景相似的图像对显著性检测来说更具挑战性,建立了ECSSD数据集(extended complex scene saliency dataset),包含语义上有意义、结构上复杂的自然图像,并与MSRA-1000数据集(Achanta等,2009)进行对比,在CIELab(commission international eclairage)色彩空间的3个通道上比较前景和背景的差异。Li等人(2014)指出现有显著性基准数据集存在严重设计缺陷,将误导模型发展,认为数据集偏差来源于图像采集和标注过程,提出如果将图像采集和图像标注分开就可以避免设计偏差,并基于这一思想建立了PASCAL-S(pattern analysis,statistical modeling and computational learning)数据集。另一方面,尽管现有数据集存在偏差,但并不意味要否定它们,而是应该对数据集偏差进行正确理解和分析,从而合理利用现有数据集,或避开既有偏差去创建新的数据集。Bylinskii等人(2019)指出需要研究特定任务的基准数据集并妥善处理数据集偏差。以侦察和监视任务为例,图像中往往包含多个小目标并且背景复杂。
此种情形下,目标的显著性通常体现为目标和环境差异蕴含的显著性,而不是目标尺寸或位置带来的显著性(如图1所示)。在缺少相应数据集作为支撑的前提下,通用的视觉显著性算法往往难以直接应用于这类任务。
如上所述,现有基准数据集普遍存在偏差,因此难以充分体现不同模型的性能,不能完全反映某些典型应用(如侦察监视)的技术特点。为此,本文通过定量分析目前常用的9个基准数据集的统计学差异,提出两个新的基准数据集。本文的贡献主要有3个方面:1)设计了一个能体现侦察监视应用特点的新基准数据集MTMS300(multiple targets and multiple scales)。数据集包含300幅来自海陆空场景的彩色可见光图像,具有中心偏差小、目标面积比分布均衡、图像尺寸多样及图像中包含多个目标等特点;2)利用MTMS300数据集和公开基准数据集对典型的视觉显著性算法展开性能评估,从公开基准数据集中找出对多数非深度学习算法而言都较为困难(指标得分低)的图像,构成了一个新的基准数据集DSC(difficult scenes in common);3)讨论了基准数据集的定量评估方法,从复杂度和中心偏差的角度对9个公开基准数据集和本文提出的两个数据集进行分析和对比。
本文提出的两个数据集的在线发布地址为:https://github.com/iammusili/MTMS300_SOD_dataset/。
1 数据集属性
1.1 MTMS300数据集
MTMS300数据集包含600幅图像,彩色可见光图像和像素级标注图各300幅,可见光图像与标注图一一对应。图像具体信息如下:1)图像名称从001开始递增编号,最大为300;2)图像分辨率不固定;3)可见光图像以jpg格式保存,位深度为24位;标注图以bmp格式保存,位深度为8位。
1.2 DSC数据集
DSC数据集包含638幅图像,319幅彩色可见光图像和319幅像素级标注图,可见光图像与标注图一一对应。图像具体信息如下:1)图像名称为数据集名称_数据集图像编号,例如ImgSal数据集编号107的图像在DSC数据集的名称为ImgSal_107;2)图像分辨率不固定;3)可见光图像以jpg格式保存,位深度为24位;标注图以png格式保存,位深度为8位。
2 数据集描述
显著性检测基准数据集的构建通常包括图像采集、图像标注和显著物体筛选。图像标注和显著物体筛选也可同时进行。Li等人(2014)提出将图像采集和图像标注分开以避免数据集的设计偏差,同时为确保显著物体的标注一致性,避免带歧义的标注,一种典型做法是多名参与者分别标注,然后投票保留票数高的区域(Borji等,2013a)。也可以将参与者分为测试组和真值组,对测试组计算AUC(area under roc curve)值或F值,并用该值表征标注的一致性(Li等,2014;Shi等,2016)。Borji等人(2012)和Fan等人(2018)利用交并比(intersection over union,IoU)定义图像的标注一致性,IoU越接近1,一致性越大。
为避免数据集设计偏差,提高标注一致性,本文将图像采集和图像标注分开,分两步构建数据集。首先6名参与者分别采集图像,再进行筛选和汇总;然后另外5名参与者对采集的图像手工标注。在标注阶段,使用IoU确保标注的一致性。
2.1 图像采集
图像采集分两阶段进行以保证图像质量。第1阶段是图像收集,首先明确需要收集的图像为侦察和监视场景下常见的多目标、复杂背景图像,然后6名参与者通过关键词搜索、在相关网站浏览的方式,下载公开的可见光图像,最终得到约400幅图像。第2阶段是图像筛选,本文结合HSV(hue saturation value)色彩特征和LBP(local binary pattern)纹理特征,通过计算图像特征直方图的差异进行相似度判断,排除过于相似甚至重复的图像,保留324幅图像,然后选择海陆空场景各100幅,最终确定300幅图像用于标注。
同时,本文对已有基准数据集进行相似度判断,DUT-OMRON、ImgSal、MSRA10K和THUR15K数据集分别有42、28、26和106幅重复图像,ECSSD、Judd-A、PASCAL-S、SED1和SED2数据集没有重复图像。
2.2 图像标注
图像标注也分两阶段进行,以保证标注的一致性,第1阶段是粗略的边框式标注,第2阶段是精细的像素级标注,如图2所示。在第1阶段,5名参与者先用矩形边框标注图像的显著物体,然后用IoU判定物体是否具有显著性。本文参考Fan等人(2018)方法,仅考虑至少3个人标注的区域,同时参考Borji等人(2012)的统计结果,将IoU阈值设为0.6。以图2(b)为例,图中有3个区域标注框(红色矩形框),但仅两个区域满足阈值条件,判定为显著性区域,另一区域则丢弃。在第2阶段,2名参与者对包含显著物体的矩形边框进行精细的像素级标注,如图2(c)所示。最终,本文建立了一个包含海面、陆地和天空3种场景各100幅图像的基准数据集MTMS300,图3给出了这个数据集中的一些图像和对应的标注图。像素级标注的原则是:1)只标注显著物体未遮挡区域(图3(a));2)尽可能地将物体独立分割,但不强行分割具有重叠区域的物体(图3(b));3)尽可能地使图像使用者能仅通过轮廓就辨识出物体(图3(c))。

图2 从粗到细的图像标注过程Fig.2 Image annotation process from coarse to fine ((a)original image;(b)bounding-box annotation;(c)pixel-wise annotation)

图3 MTMS300数据集中的例图和对应的标注图Fig.3 Examples from MTMS300 dataset and the corresponding annotation maps((a)occluded objects;(b)overlapped objects;(c)discernable contours;(d)multiple objects)
3 数据集验证与评估
3.1 公开基准数据集
Borji和Itti(2013)和Borji(2015)详细介绍了多种数据集的图像数量和图像分辨率。Borji和Itti(2013)介绍的主要是眼动(eye movement)数据集;Borji(2015)介绍的是显著物体数据集,既有边框级标注,也有像素级标注。
本文基于3个原则选择公开基准数据集:1)具有像素级标注;2)广泛使用;3)尽可能地包含多个目标。最终确定9个公开数据集,如表1所示。由于图像包含的目标数量一定程度上代表了图像的复杂度,本文通过计算标注图中连通区域数量的方式,统计数据集包含的最大目标个数和多目标图像的比例,结果如表2所示。可以看出,无论多目标最大数量还是图像比例,本文提出的MTMS300数据集都远超其他数据集,随后是ImgSal、PASCAL-S、DUT-OMRON和ECSSD数据集。Judd-A、THUR15K、MSRA10K和DSC是单目标图像比例最大的4个数据集。

表2 基准数据集中多目标图像比例Table 2 The percentage of multi-objects images in benchmark datasets
3.2 基准数据集定量分析
数据集的中心偏差和复杂度是设计和评价数据集时必须考虑的问题。Alpert等人(2007)、Achanta等人(2009)、Li等人(2011)、Yang等人(2013)和Cheng等人(2015)都提出了新的基准数据集,但是缺乏对数据集的定量分析。
3.2.1 中心偏差


图4 基准数据集的NOD概率密度分布Fig.4 Distributions of normalized object distances of benchmark datasets

图5 不同基准数据集的AAM对比Fig.5 Comparison of AAM among different benchmark datasets
3.2.2 复杂度
Shi等人(2016)、Li等人(2014)和Fan等人(2018)用颜色直方图对比方法分析数据集的复杂度。Shi等人(2016)通过在CIELab色彩空间的3个通道上计算前景和背景的直方图卡方距离比较目标和背景的差异,并用ECSSD和MSRA-1000作为对比数据集进行评价实验,认为直方图卡方距离小的图像对显著物体检测更具挑战性(因为背景和前景更相似)。Li等人(2014)通过局部颜色对比、全局颜色对比、局部gPB边界强度和目标尺寸4种方法分析数据集的复杂度。Cheng等人(2014)、Borji(2015)和Li等人(2017)用超像素判断数据集的复杂度。Borji(2015)使用基于图的超像素分割算法(Felzenszwalb和Huttenlocher,2004)计算图像的超像素,认为超像素越多,图像越复杂,同时认为Bruce-A数据集的超像素较少是由显著物体小造成的。说明对显著物体小的图像,超像素数量不能完全代表其复杂度。Borji等人(2012)和Judd等人(2009)认为熵值高的图像包含更强的干扰,通常有不同的纹理细节;Borji等人(2012)、Borji等人(2013a)、Borji(2015)和Li等人(2017)通过目标占图像比例(归一化目标尺寸)分析复杂度,认为比例越小,图像越复杂;Borji(2015)和Fan等人(2018)用图像中目标的数量判断复杂度,认为目标越多,图像越复杂。
本文采用归一化目标尺寸、前景/背景直方图卡方距离、超像素数量和图像熵等度量方式分析数据集的复杂度。

表3 基准数据集归一化目标尺寸Table 3 Normalized object sizes of benchmark datasets
前景/背景直方图卡方距离的计算方法为:根据标注图的真值掩膜将彩色图像分为前景和背景,然后分别计算CIELab色彩空间中L、a、b等3个通道的前景/背景直方图卡方距离,再取平均值。表4以0.2、0.4、0.6和0.8为分界线给出了前景/背景直方图卡方距离的统计结果。图像的直方图卡方距离越小,说明前景和背景越接近,对显著性检测更具挑战性。事实上,Li和Yu(2016)构建数据集时,选择的都是直方图卡方距离小于0.7的图像。

表4 前景/背景直方图卡方距离统计结果Table 4 Statistical results of Chi-square distance of histograms
超像素数量的计算方法为:先将图像缩放至400 × 400像素,再计算超像素数量。在此,使用基于图的超像素分割算法(Felzenszwalb和Huttenlocher,2004),算法参数为σ=1,K=500,min =50。超像素数量统计结果如表5所示。可以看出,MTMS300数据集的超像素数目最少,该结果与Borji(2015)的结论吻合,因为MTMS300数据集包含的主要是小目标。SED1和SED2数据集的超像素也较少,DSC数据集的超像素数目最多,然后是ECSSD、DUT-OMRON、Judd-A和PASCAL-S数据集。

表5 超像素数量统计结果Table 5 Statistical results of the number of superpixels
图像的熵值越大,图像包含的信息越多,图像越复杂。表6是5,7,7.5和7.8为分界线的图像熵统计结果。可以看出,DSC数据集的熵值最大,这也侧面印证了图像熵在一定程度上代表了数据集的复杂度(DSC数据集由多数模型得分都低的困难图像组成)。此外,DUT-OMRON、ECSSD、ImgSal、Judd-A和PASCAL-S的熵值都较大,MTMS300数据集的熵值分布比较平均。综合而言,SED2的熵最小,其次是MSRA10K和SED1。

表6 图像熵的统计结果Table 6 Statistical results of the image entropy
3.2.3 小结
结合表1—表6、图4和图5可以得出以下结论:1)基准数据集的侧重点不同。例如,Judd-A的图像场景较为杂乱且视野较大;MSRA10K通常只有1个无歧义的显著目标;SED1和SED2分别只包含1个和2个目标但类别多样化;THUR15K只包含5种特定类别目标;ECSSD包含语义丰富但结构复杂的自然图像。2)通用数据集中,MSRA10K、SED1和SED2是最简单的3个数据集,ImgSal、DSC、Judd-A和PASCAL-S是最复杂的4个数据集,DSC数据集在前景/背景差异、超像素数量和图像熵上较为突出,暗示包含的图像很复杂。3)与其他数据集相比,MTMS300数据集在目标数量、中心偏差和目标大小等方面比较突出,能够较好地满足侦察监视场景的需求。4)不同度量指标之间没有必然的相关性。例如,ECSSD、DUT-OMRON和Judd-A等前景/背景差异较大的数据集,超像素数目都较多。但是同样前景/背景差异较大的MTMS300数据集,却因为包含了很多小目标,导致超像素数目不多。综上所述,在用数据集进行视觉显著性模型的性能评估或训练时,需要综合考虑数据集的特性。
3.3 视觉显著性模型的性能评估
实验通过在数据集上定量测试多种算法模型,对数据集的复杂度和难度进行定性对比分析。
3.3.1 实验设计
视觉显著性模型包括启发式方法、基于超像素分割的方法和基于深度学习的方法3大类。实验时每类模型选取6种共18种具有代表性的视觉显著性模型进行评估,如表7所示。
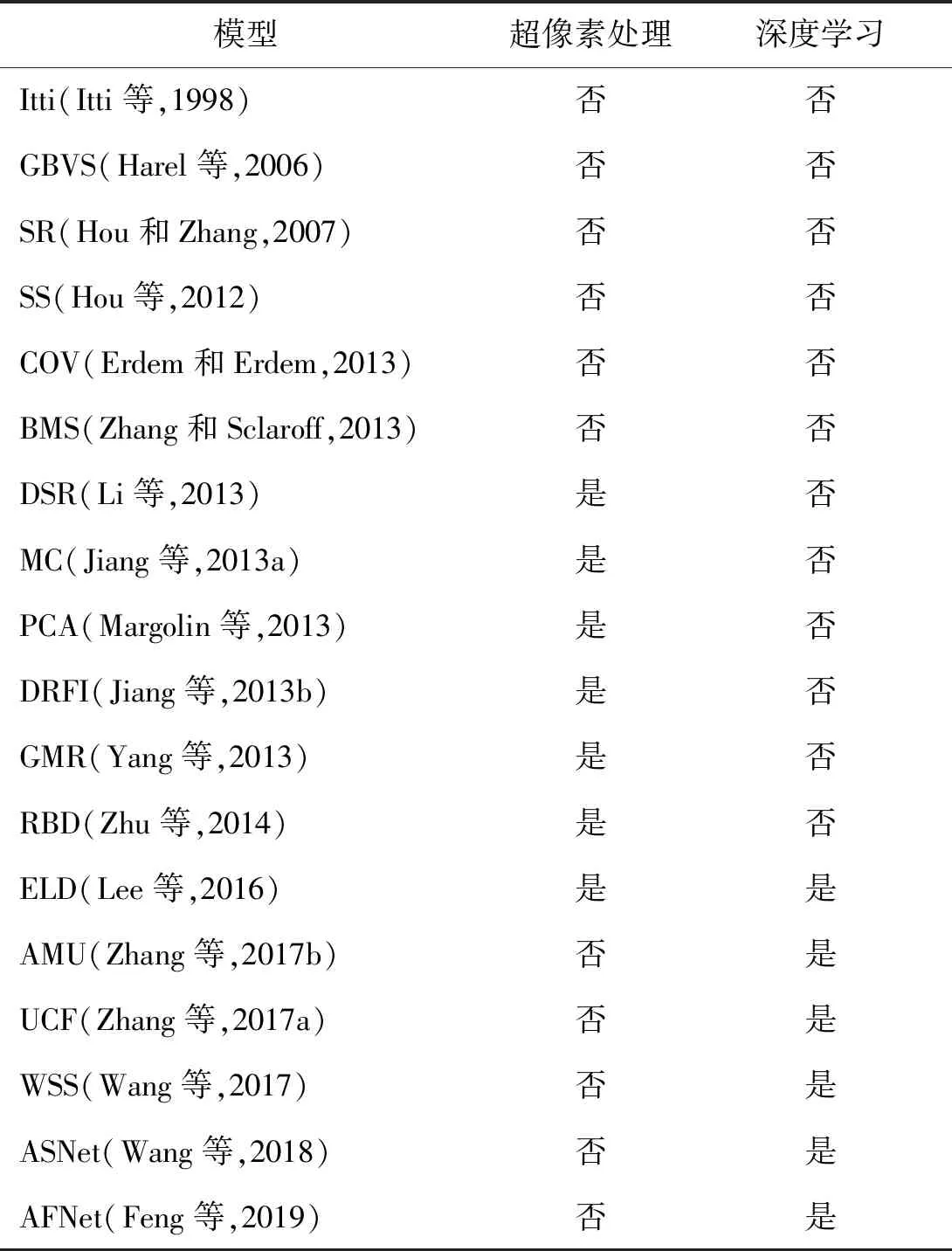
表7 视觉显著性模型Table 7 Visual saliency models
3.3.2 性能评价指标
(1)
(2)
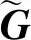
TPR和FPR构成受试者工作特征(receiver operating characteristic,ROC)曲线,对ROC曲线积分即求得AUC值。AUC值的取值范围为[0,1],值越大,说明模型性能越好。
F值(也称Fβ)的计算方法为
(3)
F值同时考虑了精度P和召回R,可以更全面地评价显著图的质量。本文参照Achanta等人(2009)的方法,将β2设为0.3,以增加精度的权重,并只使用F值的最大值描述模型性能。
3.3.3 实验结果
表8和表9分别是视觉显著性模型在不同基准数据集上的AUC值和F值。由表8和表9可以得出以下结论:1)经过多年发展,视觉显著性模型的性能在简单数据集上已趋于饱和,但在复杂数据集上还远远不够。以MSRA10K数据集为例,1998年Itti模型的AUC和F值仅为0.87和0.66;2013年MC模型的AUC和F值提高到0.95和0.90;2018年ASNet模型的AUC和F值达到0.99和0.96。然而,在Judd-A这样的复杂数据集上,表现最好的ASNet算法的F值也仅为0.6,不能令人满意。2)数据集质量与模型性能有紧密联系。以DUT-OMRON数据集为例,其图像数量只有MSRA10K的一半,但用DUT-OMRON训练的ASNet模型与用MSRA10K训练的ELD和AMU模型相比,在多个复杂数据集上的指标得分都更高。3)模型在数据集上的指标得分与数据集复杂度成反比。MSRA10K、SED1和SED2数据集最为简单,ImgSal、DSC、Judd-A、PASCAL-S和MTMS300数据集最为复杂,模型在这些数据集上的F值和AUC值印证了这一结论。4)在公开基准数据集上训练的算法模型难以直接应用到特定场景的视觉显著性任务中。以DRFI和ASNet等模型为例,它们在公开数据集上的F值高达0.9,但是在MTMS300数据集上的F值仅为0.66,这也表明针对侦察监视任务等特定场景,设计新的视觉显著性算法很有必要。

表8 不同模型在不同数据集上的AUC值Table 8 AUC values of different models on different datasets
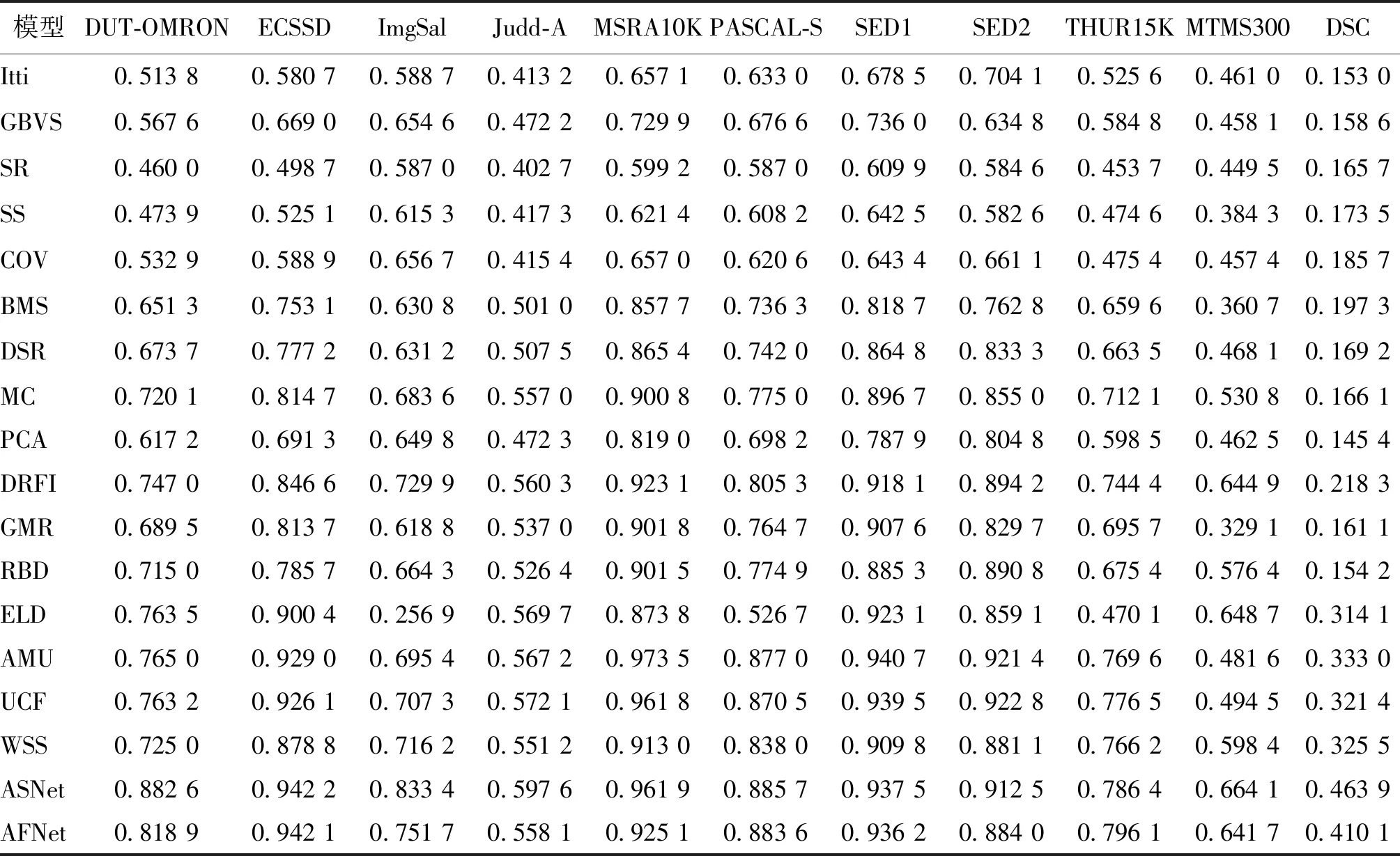
表9 不同模型在不同数据集上的F值Table 9 F values of different models on different datasets
3.4 DSC数据集的构建
基于3.3节的实验,本文从9个公开数据集中找出“共同困难”图像,构建DSC数据集。“共同困难”图像的定义为:如果12个非深度学习模型中有至少8个模型都在同一幅图像上指标得分低,就认为这幅图像是“共同困难”图像。
具体来说,本文分3步构建DSC数据集:第1步,找出AUC低于0.7的“共同困难”图像;第2步,找出F值低于0.3的“共同困难”图像;第3步,两部分图像取交集。将AUC阈值设为0.7的原因是:0.5是随机猜测的得分,如果低于0.7,说明不比随机猜测好多少,那么必然是困难的图像;根据经验将F值的阈值设为0.3。从各公开基准数据集中找出的“共同困难”图像的数量如表10所示。

表10 来自公开基准数据集的“共同困难”图像数量Table 10 The number of difficult images in common from public benchmark datasets /幅
图6给出了DSC数据集的例图和模型的显著图。可以看出,对传统算法而言,“共同困难”的图像对一些最新的算法模型仍具有挑战性。

图6 DSC数据集的例图和对应的显著图Fig.6 Examples from DSC dataset and the corresponding saliency maps((a)original images;(b)annotation maps;(c)ELD;(d)AMD;(e)UCF;(f)WSS)
4 数据集使用说明
4.1 数据使用方法
数据集的推荐使用方法如下:1)使用者利用自己编写的视觉显著性算法或软件读取1幅或多幅彩色可见光图像,根据算法进行显著性判别,输出与可见光图像尺寸一致的显著图。2)同时读取显著图和相应的标注图,计算显著图对应的AUC值和F值等指标得分;也可根据实际需求,自行设计新的评估指标并计算。本文数据集提供上述评估指标的程序代码。
4.2 应用场景
本文数据集适用于视觉显著性模型的性能评测和模型训练。
5 讨 论
5.1 模型在公开数据集上的失败原因

图7 低质量标注的例图Fig.7 Examples of low-quality annotation((a)original images;(b)annotation maps)
5.2 模型在MTMS300数据集上的失败原因
MTMS300数据集制备过程中,将图像采集和图像标注分开,用IoU判定标注一致性,尽可能避免了数据集的设计偏差,提高了数据集的标注一致性。因此,模型在MTMS300数据集上得分不高的原因,主要有:1)模型只突出主要目标,抑制了小目标(图8第1行),甚至完全无法检测到图像中的小目标(图8第2、3行)。2)对图像存在多个目标的情形,不能全部检测出来(图8第4、5行)。3)模型参数固定,难以自适应图像尺寸。以RBD模型为例,其超像素大小固定为600像素,对大图像而言,该参数会使RBD模型容易检测出所有目标,但这将导致小图像只包含几十个超像素。并且对于图像中的小目标(如10 × 10像素大小的目标)而言,其面积甚至不如一个超像素大,因而容易被漏检。
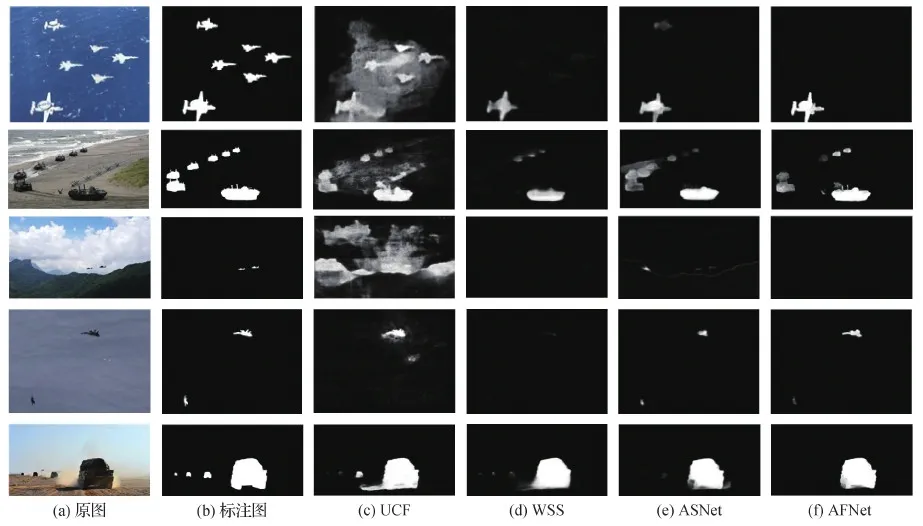
图8 模型在MTMS300数据集的失败例子Fig.8 Failure cases of models over MTMS300 dataset((a)original images;(b)annotation maps;(c)UCF;(d)WSS;(e)ASNet;(f)AFNet)
6 结 论
本文提出一个面向侦察监视应用的显著性检测基准数据集MTMS300,主要特点是:中心偏差小、目标面积比分布均衡、图像分辨率多样以及场景中包含多个目标。
本文利用6个度量指标对基准数据集展开定量分析,统计了数据集的中心偏差和复杂度等特性,并评估了数据集的难度系数。此外,通过18个模型在11个数据集上的实验和评估,证明了模型的得分和数据集的难度系数是有相关性的。但是也有一些难度系数低的数据集(如THUR15K),模型的得分不高,本文认为这主要与标注质量有关。
本文分析了模型在基准数据集上失败的原因,并找出了公开数据集中令多数传统模型都觉得困难(指标得分低)的图像,构成了一个“共同困难”数据集DSC。
结合实验和分析,本文发现仍有一些值得关注的问题:1)构建数据集时,必须严格把控数据集的质量。例如,DUT-OMRON数据集的图像数量只有MSRA10K的一半,但是用DUT-OMRON训练的模型比用MSRA10K训练的模型效果显然要好,这表明数据集的质量对模型有直接影响。2)本文使用 6种度量指标对数据集展开了定量分析,如何在此基础上充分利用数据集的特性,将不同的数据集融合,提升基于深度学习的视觉显著性模型的性能,是一个值得研究的问题。3)现有显著性检测模型的评估指标无法适用于特定任务下的数据集。例如,对于同时包含大、小目标的图像,如果模型只检测出了大目标(如图8第1行)也能获得不低的指标得分,相当于评估指标忽视了小目标漏检,这显然是不理想的。而且,现有评估指标无法体现显著图中的目标个数和实际目标个数的差异。因此,如何设计一个指标表征此类场景下显著物体检测模型的性能是一个值得考虑的方向。
致 谢MTMS300数据集的构建得到了新浪军事、中国军事图片中心和铁血社区的支持,在此表示感谢。
猜你喜欢
学生天地(2020年6期)2020-08-25 09:10:50
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:36
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
公民与法治(2016年19期)2016-05-17 04:18:15
系统医学(2016年8期)2016-02-20 02:55:08
读者·校园版(2015年7期)2015-05-14 13:11:40
河南科技(2014年15期)2014-02-27 14:12:35
电子设计工程(2014年6期)2014-02-27 11:56:56
