
流形正则化约束的图像语义分割
2022-04-24 10:49:06肖振久宗佳旭兰海魏宪唐晓亮
中国图象图形学报 2022年4期
肖振久,宗佳旭*,兰海,魏宪,唐晓亮
1.辽宁工程技术大学软件学院,葫芦岛 125105;2.泉州装备制造研究所,泉州 362000
0 引 言
图像的语义分割是机器视觉领域一项必不可少的核心任务。语义分割可以广泛用于场景信息理解、自动驾驶和医疗辅助诊断等领域,且具有重要作用。目前,尽管对图像的语义分割展开了积极研究,但仍需重点解决精准区分不同尺寸的相同物体和克服遮挡、光照等问题(青晨 等,2020)。为了解决上述问题,有效完成不同场景的分割任务,有必要增强像素级别的识别能力,特别是全卷积神经网络(fully convolutional networks,FCN)(Long等,2015)。但是受限于卷积操作的局域性,分割结果仅受限于局部的感受野中,无法融合长距离的上下文信息,从而限制了FCN类方法的发展。另外,在图像数据下采样过程中,会造成细节本征信息损失,尤其在U型网络结构中(韩慧慧 等,2020)。
为利用像素间的上下文信息,利用条件随机场(Zheng等,2015)或注意力机制(Zhao等,2018)使任意位置的单个特征可以感知其他位置的所有特征,从而使输出结果能够融合各像素点之间的关系。但是在条件随机场以及注意力机制中,仅利用单个像素点间的相似度建立势函数(Krähenbühl和Koltun,2012)或权重矩阵,难以在低对比度的图像中取得较好效果,另外需要生成巨大的注意力图来计算每个像素之间的关系,计算复杂度高且占用显存资源,从而限制了其在图像语义分割中的表现。基于以上问题,本文提出一种流形正则化约束的图像语义分割算法,通过将图像分割中的输入数据和输出结果视为两个不同流形并维持这两个流形之间对应关系来获取像素间的本征结构,有效利用了上下文的信息并提升了算法的分割精度。本文的主要贡献有:1)提出一种基于几何优化的流形正则化方法,通过将高维空间中相邻的输入数据点与输出结果维持在同样的流形结构上,引入了像素点间的上下文关系,提高了分割精度。2)与现有主流的图像分割算法相结合,本文提出的流形正则化算法能够很好地嵌入各类分割算法,并且提升分割精度,在多个数据集上的性能处于领先位置。本文算法代码已上传至Github,共享网址为https://github.com/jiaxu0017/Manifold_Segmentation。
1 相关工作
1.1 语义分割
近几年,针对语义分割的研究取得了新的进展,吸引了大量研究人员的关注。FCN对语义分割进行了开拓性尝试,基于FCN思想的语义分割技术得到长足进展。然而开始的FCN由于多层的池化操作导致提取的特征信息在图像细节处丢失严重,从而影响了算法在细节处的表现。为解决这一问题,Chen等人(2016)、Yu和Koltun(2016)通过较少的降采样操作以获得更精细的特征并利用膨胀卷积来增强感受野,DeepLabV2(Chen等,2018)提出ASPP(atrous spatial pyramid pooling)模块,利用不同的膨胀卷积捕获图像上下文中的信息,DeepLabV3(Chen等,2017)设计则采用级联或并行的空洞卷积,通过不同速率的空洞卷积获取上下文信息,PSPnet(pyramid scene parsing network)(Zhao等,2017)利用金字塔模型聚合上下文信息。此外,通过优化编码器—解码器结构,如U-Net(Ronneberger等,2015)、RefineNet(Lin等,2017)和SegNet(Badrinarayanan等,2017)等,将信息融合在低层和高层结构中,获得不同尺寸的特征信息,预测分割后的图像,亦能够提升分割精度。另外,在分割结果上进行后处理,利用预测结果自身的上下文信息来优化分类结果也是一种提升精度的有效方法。常见的后处理方法包括利用条件随机场(conditional random field,CRF)(Chandra等,2017)和马尔可夫随机场(Markov random field,MRF)(Liu等,2015)等建立各像素间的图模型,进一步精确定位像素边界和分割结果。
1.2 上下文信息捕捉
利用上下文信息来增强图像语义分割在细节上的表现是目前的热门研究方向。自FCN类方法提出之后,研究人员也聚焦于上下文信息的捕捉上,利用概率图模型中的条件随机场和马尔可夫随机场捕获预测结果中的上下文依赖关系。和超等人(2020)通过不同的膨胀卷积和池化等操作生成的特征图来聚合多尺度上下文信息,实现多尺度的上下文信息融合。Byeon等人(2015)采用递归神经网络,通过捕获标签上的空间信息或局部特征丰富上下文的依赖关系。尽管采用上下文融合的方式有助于获取不同比例的对象,但是无法利用全局视图中对象或事物之间的关系。而基于图模型的方法又难以与现有图像处理的卷积神经网络模型完美融合,实现端到端学习。另外,通过递归神经网络隐式捕获全局关系,其有效性很大程度取决于长期记忆的结果。上述两种方法并不能满足不同像素对不同上下文信息的要求。
获取上下文之间的关系,对远程依赖进行建模仅靠上述技术还远远不够,注意力模块的引入为建立信息间的远程依赖提供了新的思路,并且在许多应用中取得了成功。Vaswani等人(2017)利用注意力机制建立Transformer模型并用其替代循环神经网络,通过绘制全局依存关系用于机器翻译,效果得到大幅提升。目前,注意力机制越来越多地应用于计算机视觉领域。Wang等人(2018b)利用一种非局部模块,通过计算特征图中每个空间点之间的相关矩阵生成巨大的注意力图,然后引导密集的上下文信息进行聚合。DANet(dual attention network)(Fu等,2019)通过结合像素间的上下文信息和通道空间内的上下文信息来提高分割精度。CCNet(criss-cross attention network)(Huang等,2019)通过新颖的交叉注意力模块在交叉路径上收集周围像素的上下文信息,并通过循环操作,使每一个像素最终可以捕获所有像素的远程依赖关系。
1.3 流形正则化
正则化约束思想有着丰富的数学历史,可回溯至Tikhonov求解不适定逆问题,其作为样条理论的核心思想已广泛用于机器学习领域(Evgeniou等,2000),许多机器学习算法,如支持向量机均可视为正则化的特例。而流形正则化则利用数据分布的几何结构对具体学习任务的损失函数进行约束。假定数据的相关子集来自某种拓扑流形:带有不同标签的数据在流形曲面上距离较远。基于该假设,流形正则化广泛应用于半监督学习(Belkin等,2006)。
在神经网络中,由于连续的合并操作或卷积步幅导致特征的分辨率下降,使得神经网络学习到越来越抽象的特征表示,即本征结构。但是,这种局部图像转化为固定的特征表示,往往会造成关键信息的损失。为解决本征结构的损失,控制复杂的几何分布,研究人员针对流形约束做了大量工作,提出多种应用流形正则化的半监督学习框架。Belkin等人(2016)利用边际分布的几何形状,提出一种基于流形的正则化学习框架,主要针对半监督学习能够有效地使用未标记数据。另外,针对半监督学习,Geng等人(2009)提出内在流形自动近似的算法,并开发了一个集合流形正则化的框架,结合一些初始的猜测来近似本征流形。为了更深一步地解释流形在半监督学习中的作用,Niyogi(2013)通过建立minmax框架,调查了多种学习的方式,通过对流形在半监督学习中的潜在用途来解释流形正则化及相关的几何算法。除了建立流形正则化的半监督学习中的框架,研究人员也将流形学习应用于图像分割领域中。Quispe和 Petitjean(2015)利用先验对象的几何形状指导分割,该算法依赖扩散图来编码训练集的形状变化,并用对象分割提供相应的帮助。Luo和Huang(2014)提出一种针对刚性物体和非刚性物体运动分割的自适应流形降噪技术,通过流形约束的方式降低分割中的偏差。基于这一思路,本文利用流形正则化约束对图像语义分割模型参数进行优化,通过维持图像分割中的输入数据和输出结果两个流形之间对应关系,获取数据间的本征结构,从而提升算法模型的性能。
2 算法原理及实现
2.1 损失函数
深度学习算法通常使用随机梯度下降作为任务求解工具,为能保证求解结果快速而准确地收敛,需要保证类别信息的数学表达(损失函数)能够涵括各类情况,通常的多分类问题使用交叉熵作为类别间的损失函数,其损失函数Lcla定义为
(1)
由于图像分割可以定义为像素级别的分类任务,因此,分割任务中损失函数即对所有像素点的交叉熵损失函数Lseg进行求和,即
(2)
通过式(2)可以看出,这类损失函数的缺点在于仅计算单个像素点的预测结果与真实值之间的惩罚值,没有考虑邻近像素点分类结果的影响。从直观上看,在邻近像素点预测为某个分类的情况下,该像素点预测为其他分类的损失惩罚应该增大。这类思想是多数上下文信息捕捉方法的前提假设,为解决这一问题,本文通过在损失函数中引入流形正则约束项来实现相邻像素间上下文信息的捕捉。
2.2 流形正则化
在本文中,假定输入数据与其对应的预测结果在高维原始数据空间内的低维流形曲面上有着相同的几何结构。基于这一假设,利用数据的几何结构构建正则化约束项是本文的主要创新点。在式(2)中加入流形正则约束项,总体损失Ltot为
(3)

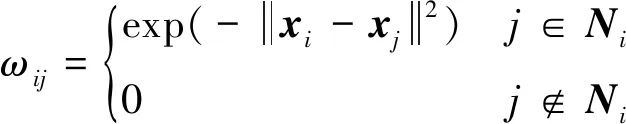
(4)
式中,Ni表示xi的近邻数据点集合,j为范围Ni内的任意一点。当xj不处于xi的邻域内时,ωij为0,即不考虑非近邻点之间的相互影响,仅考虑邻域内的流形结构。
通过ωij建立输入数据xi之间的相似度,为保证相邻的x输入数据对应的预测结果y也具有高相关性,给出流形正则项的定义,具体为
(5)

图1 几何结构示意图Fig.1 Geometric structure diagram


(6)
式中,N表示所有图像点,Np表示图像中所有不相交的子集。θ为模型所有参数,代表了损失函数Ltot的解空间。
2.3 子图像块划分

(7)
从式(7)可以看出,当分割的子图像块取最小值1×1时,其形式与CRFasRNN(conditional random fields as recurrent neural networks)(Zheng等,2015)中的势函数十分接近,核心思想均为给具有相同RGB取值的像素点分配相同的预测结果,在概率图模型中,即增大P(y|x),从几何结构的角度看,即减小高相似度的输入数据对应的输出结果在高维空间中的欧氏距离。当所选子图像块逐渐增大,可视为在高维数据空间中相邻近的子图像块对应的分割结果在其高维空间中亦十分接近。当子图像块的大小等于输入图像尺寸h×w时,此时可在训练批数据之间建立关联,从而将本文算法用于流行正则约束常见的半监督学习(Belkin等,2006)。
2.4 算法实现
将流行正则约束项加入到现有的深度学习网络模型,可实现端对端的图像语义分割模型的训练。
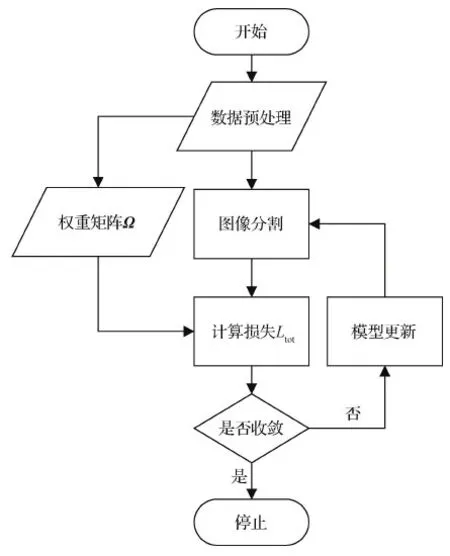
图2 算法流程图Fig.2 Algorithm flow chart
1)将原始图像分割为s×s个子图像块作为xi;
2)利用式(4)计算各子图像块之间的权重矩阵Ω;
4)根据式(6)计算包含流形正则项约束的总体损失函数Ltot;
5)利用随机梯度下降法对模型参数进行更新;
6)重复步骤3)—5),直至结果收敛。
上述步骤中,确定子图像块的数目N后,步骤2)与训练过程无关,可在训练前完成所有子图像块间权重矩阵Ω的计算,从而大幅减少运算时间。
3 实验分析
为了验证本文算法的有效性,通过实验比较了算法在Cityscapes(Cordts等,2016)和PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes)(Everingham等,2012)两个数据集上的准确性,并与当前先进算法进行比较。实验结果表明,本文算法在Cityscapes和PASCAL VOC 2012两个数据集上均达到了最佳效果。
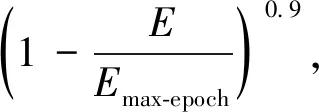
本文算法采用基于ImageNet上的ResNet(residual network)预训练网络模型(He等,2016),并使用DeepLab v3作为图像分割骨架网络,并在骨架网络基础上加入子图像块的提取以及流形正则约束项作为本文算法的最终实现。
3.1 评价标准和数据集
采用平均交并比(mean intersection over union,mIoU)作为语义分割的评价标准,其计算为
(8)
式中,tp表示某一类别中正确的正样本分类结果,fp表示错误的正样本分类结果,fn表示错误的负样本分类结果,对所有类别的交并比求平均,即为平均交并比mIoU。
实验比较了不同分割算法在Cityscapes和PASCAL VOC 2012两个数据集上的平均交并比。
Cityscapes数据集用于城市语义分割任务,该数据集中包含来自50个城市的5 000幅高质量像素级精细标注的图像和20 000幅粗略标注的图像,并且在分割图像中存在大量的遮挡、目标尺寸大小不一及光照不均的情况,如图3所示。每一幅图像的分辨率都为1 024 × 2 048像素,共分为35个类,其中19类用于语义分割的评估,实验仅采用5 000幅精细标注的图像。PASCAL VOC 2012数据集主要针对目标对象进行分割,非目标对象视为背景。共包含10 582幅图像,涉及20个前景对象和1个背景类的分割。

图3 Cityscapes分割示意图Fig.3 Cityscapes segmentation example diagram
3.2 与骨架网络的对比实验
本文通过引入流形正则化约束项对图像中的上下文信息进行捕获,同时维持语义分割过程中数据的几何结构一致性。本文算法中分割尺度s为实验中一项关键的超参数,将直接影响实验结果。为确定分割尺度s的大小,基于ResNet101网络对分割尺度进行快速实验,对比了平均交并比(mIoU)和运行时间(time),超参数λa设为0.01,实验结果如表1所示。可以看出,随着分割尺度s的逐渐增大,模型效果也得到提升,当s增大到10之后,继续增大s对模型的提升效果已趋于饱和。同时,随着s的增大,训练时长成倍增加。为平衡实验精度和训练时长,后续实验中的s均设为经验值10,即将原始图像平均分割为100个子图像块。

表1 本文算法在不同分割尺度的平均交并比和运行时间Table 1 The mIoU and time by proposed algorithm with different segmentation scales
为进一步验证本文算法的有效性,将本文算法与基础骨架网络进行实验对比。设置不同的约束权重λa作为超参数,对流形正则项的影响进行经验性分析,实验结果如表2所示。可以看出,流形正则化约束的图像语义分割算法显著提升了模型性能。λa取值在[0,0.001]时,模型精度逐步提高,λa=0.001时模型精度最高;λa取值在[0.001,0.01]时,模型精度逐步下降,但仍优于骨架网络;λa>0.01时,模型精度持续下降并且性能弱于骨架网络。故参数λa应控制在[0,0.01],选取0.001时,模型取得最优值。针对这一实验结果,本文认为这一数值与模型训练数据的内在维度(intrinsic dimension)有关,当网络模型将数据从输入数据的流形形状转换至输出结果的流形形状时,两者的流形维度即各自内在维度的差异会对超参数的选取造成一定影响。当两者流形维度相差较大时,过强的形状约束会对模型的网络性能造成影响,此时应该减小流形约束项的影响,即减小λa,反之亦然。与骨架网络相比,采用流形正则化约束算法的mIoU最高为78.0%,在对网络模型推理过程不引入额外计算量的前提下,最终结果提高了0.5%。

表2 本文算法与基础骨架网络在不同权重下的mIoU对比Table 2 Comparison of mIoU by bone network and our algorithm among different weights
3.3 ResNet50和ResNet101模型泛化实验
为验证本文算法的泛化性,在不同数据集上分别以ResNet50和ResNet101为基础网络,与骨架网络BoneNet(bone network)进行对比实验,结果如表3所示。可以看出,与采用骨架网络的分割结果相比,本文算法在Cityscapes数据集上以ResNet50和ResNet101为基础网络的mIoU分别提升了0.3%和0.5%,在PASCAL VOC 2012数据集上以ResNet50和ResNet101为基础网络的mIoU分别提升了0.8%和2.1%。通过实验对比可以发现,与参数量较少的ResNet50网络相比,本文提出的流形正则约束项在ResNet101骨架网络上的精度提升幅度更多,原因在于流形正则化主要对模型参数的优化过程起约束作用,因此在模型参数量更大的网络模型中能取得更好的效果。

表3 本文算法与骨架网络在不同数据集和不同基础网络上的mIoU对比Table 3 Comparison of mIoU with different base networks between BoneNet and our algorithm on different datasets /%
3.4 各项分类结果及可视化
为验证流形正则化约束的图像语义分割算法对网络的影响,对Cityscapes数据集中每个单独的语义类别,在以ResNet101为基础的骨架网络和本文算法上进行定量和定性实验对比,结果如表4所示。
从表4可以发现,本文算法对大多数语义类别的精度均有所提升,主要原因有:1)采用流形正则化约束的图像语义分割算法增加了图像分割过程中的上下文信息,使分割模型在学习过程中不再局限于局部信息;2)采用本文算法使得图像在源域和目标域之间保留了更多的本征结构,使得目标图像更加贴近原始图像中的几何形态;3)通过添加约束项,提高了网络的学习能力,优化了模型性能。

表4 模型语义类别实验精度对比表Table 4 Comparison of experimental accuracy of model semantic categories /%
本文提出的流形正则化约束的图像语义分割算法和骨架网络在Cityscapes数据集上的分割效果如图4所示,不同颜色表示不同的分割目标,标准分割图像中的黑色区域为未标记区域,对比部分采用不同色彩的窗口标出,并对第4行和第5行的细节部分进行了放大展示。可以发现,本文算法的精度较骨架网络有了较大提升,可以纠正一些误分类别,如第1行的人行道和第3行的巴士。对未标记部分分类更加平滑,分割图像整洁连续,如第2行的道路,虽然在标准分割图像中未进行标记,但是通过本文算法依旧取得了良好效果,分类正确且边缘平滑。原因是采用流形正则化约束的图像分割算法摆脱了局部信息的限制,可以利用图像中的上下文信息进行学习,在边缘处理和像素点分类时可以获得更加优异的效果。另外,采用本文算法可以加强局部特征中细节方面的描述,如第4行和第5行橙色部分,图中的信号灯等细节信息成功标记出来。因为采用本文算法减少了图像分割过程中本征结构的损失,使得图像中的细节信息得到更好展示。综上所述,本文算法无论对图像中边界及区域信息的描述还是对局部信息细节的区分都是有帮助的,分割图像的语义一致性得到明显改善。

图4 本文算法与骨架网络在Cityscapes数据集上的分割效果对比Fig.4 Comparison of segmentation results between backbone network and ours on Cityscapes dataset((a)original images;(b)ground truth;(c)segmentation results by backbone network;(d)segmentation results by ours)
为了进一步评估本文算法的有效性,在PASCAL VOC 2012数据集上进行测试,结果如图5和表3所示。可以看出,本文算法在PASCAL VOC 2012数据集上的精度明显提高,与在Cityscapes数据集上的实验结果相似,本文算法减少了误分和漏分现象,如图5第1、2、4行所示,并且分割图像的边缘更加平滑,如图5第3行和第4行所示。通过在不同数据集上的实验,不仅证明了算法可以提高模型分割的精度,也证明了算法具有良好的泛化性,表明本文算法可以广泛用于不同的应用场景,具有一定的实用价值。

图5 本文算法与骨架网络在PASCAL VOC 2012数据集上的分割效果对比Fig.5 Comparison of segmentation results between backbone network and ours on PASCAL VOC 2012 dataset((a)original images;(b)ground truth;(c)segmentation results by backbone network;(d)segmentation results by ours)
3.5 与先进算法模型的对比实验
将本文算法在Cityscapes和PASCAL VOC 2012数据集上与目前先进算法进行横向比较。
在Cityscapes数据集上,对比方法有FCN 8s(Long等,2015)、DeepLab-V2(Chen等,2018)、RefineNet(Lin等,2017)、SSED(semantic segmentation of encoder-decoder structure)(韩慧慧 等,2020)、HarDNet(harmonic DenseNet)(Chao等,2019)和DUC(dense upsampling convolution)(Wang等,2018a),结果如表5所示。可以看出,在数据集Cityscapes上,本文算法的精度较FCN 8s等基础模型有了显著提升,并且优于DeepLab-V2、RefineNet、SSED、HarDNet和DUC等先进模型。
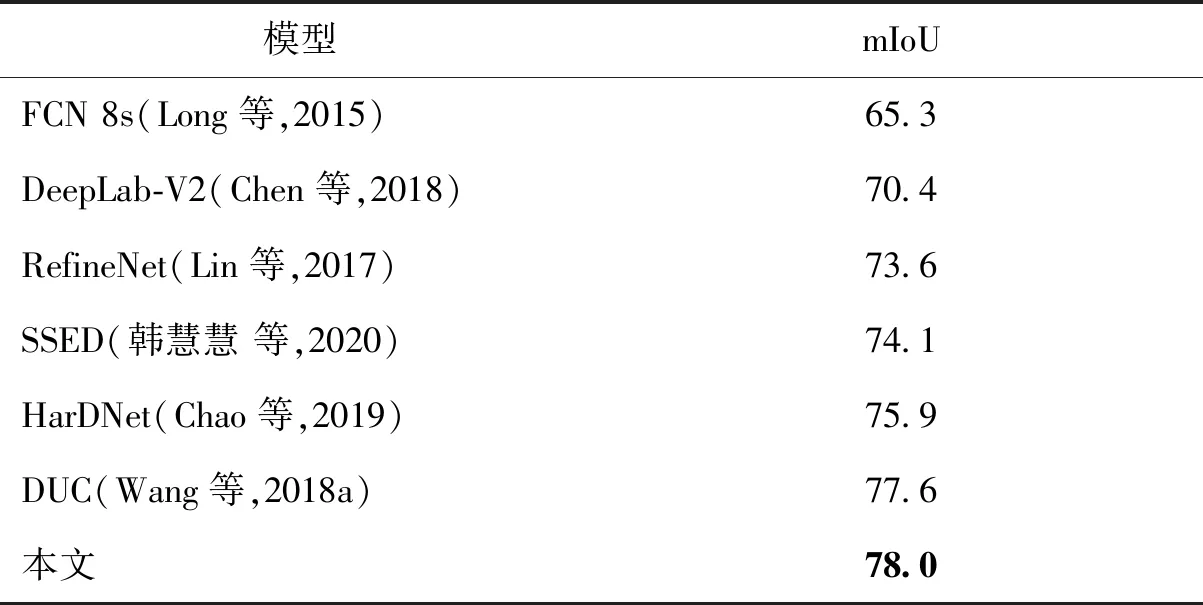
表5 不同模型在Cityscapes数据集上的横向实验对比Table 5 Comparison of accuracy experiments of different models on Cityscapes dataset /%
在PASCAL VOC 2012数据集上,与SegNet(Badrinarayanan等,2017)、FCN 8s(Long等,2015)、Hypercolumn(Hariharan等,2015)和ESPNetv2(efficient spatial pyramid network v2)(Mehta等,2019)等方法进行对比,结果如表6所示。可以看出,在PASCAL VOC 2012数据集上,本文算法的精度优于SegNet、FCN 8s、Hypercolumn和ESPNetv2等模型。

表6 不同模型在PASCAL VOC 2012数据集上的横向实验对比Table 6 Comparison of accuracy experiments of different models on PASCAL VOC 2012 dataset /%
通过以上两个对比实验可以看出,本文算法适用于多种不同场景,并取得了较好结果,在一定程度上解决了误分、漏分问题,并使得分割图像的边缘更加光滑。上述实验结果表明,本文算法在图像分割问题上优于对比方法。
4 结 论
本文提出一种流形正则化约束的图像语义分割算法,假定输入图像与预测结果在低维流形空间上存在相同几何结构并以此作为约束,促使网络自适应地捕获数据间的上下文信息。在无需生成巨大特征矩阵并不引入任何推理过程中的额外计算量的前提下,建立了图像分割网络中像素点间的依赖关系。实验结果表明,本文算法十分有效并且适用于不同的骨架网络,尤其在参数量更大的网络模型上表现更为出色,在Cityscapes和PASCAL VOC 2012两个图像语义分割数据集上的分割性能均优于其他模型。但是,本文算法仅引入了权重系数λa和分割尺度s作为超参数,在下一步工作中,将探求验证各超参数和算法模型之间的关系,并引入模型训练中的其他变量,如像素点的位置信息等,进一步优化算法。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2020年2期)2020-06-02 11:28:48
数学物理学报(2019年6期)2020-01-13 06:08:16
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
数学物理学报(2019年1期)2019-03-21 05:26:18
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
数学杂志(2018年5期)2018-09-19 08:13:48
数学物理学报(2017年5期)2017-11-23 07:51:31
振动工程学报(2015年2期)2015-03-01 01:16:13
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
