
利用条件生成对抗网络的光场图像重聚焦
2022-04-24 09:53谢柠宇丁宇阳李明悦刘渊律睿慜晏涛
中国图象图形学报 2022年4期
谢柠宇,丁宇阳,李明悦,刘渊,律睿慜,晏涛
江南大学人工智能与计算机学院,无锡 214122
0 引 言
散焦是一种非常重要的摄影技术,通过调节光圈的大小以及对焦平面的位置,使图像中的非拍摄主体处于一种模糊状态,从而突出清晰的拍摄主体。为了获取一个较浅的景深,即具有良好散焦效果的图像,必须借助大光圈的镜头,这对相机有较高的要求。较低性能的相机往往无法获取具有理想散焦效果的图像,即使性能很好的单反相机获取的较浅景深的图像,也只能突出某一平面的主体,无法后期调整照片的主体对象和景深大小。
生成对抗网络(Goodfellow等,2014)源于博弈论,包含生成器(generator,G)和判别器(discriminator,D),G用于生成目标数据样本,D用于判断生成数据的真伪,二者互相博弈,最终得到近乎完美的生成图像。Mirza和Osindero(2014)在生成对抗网络的基础上提出了条件生成对抗网络,这是一种带条件约束的生成模型,在生成器 G和判别器D中均引入了条件变量用于指导生成目标数据。
光场图像同时具备目标场景的空间与角度信息,其应用在多个计算机视觉领域都取得了可观成果,如图像超分辨率(Tsai等,2020)、图像拼接(Guo等,2016)、光场重聚焦(Liu等,2020)、全景图生成(Overbeck等,2018)、深度估计(王程 等,2020)和图像重定向(晏涛 等,2019)等。现有的获取光场的方法主要分为两类:1)紧凑型的商业光场相机(Ren等,2005),借助一个主透镜和一系列子透镜捕获场景角度信息。然而,由于传感器的限制,商业光场相机仅能提供一个密集的角度分辨率和较低的空间分辨率。2)相机阵列,借助一系列按矩阵规则排列的相机同时拍摄对象的多个视角。早期的相机阵列庞大,不方便使用,近年来借助小型相机阵列(Lin等,2015)获取光场的技术获得了一定进展,具有广阔前景,使借助相机阵列获取光场图像愈发容易。与全光相机相比,相机阵列具有更高的分辨率和更大的基线,提高了图像质量,提供了更大的视差,为光场重聚焦算法提供了数据支持,同时也放大了传统重聚焦算法的缺陷。
传统重聚焦算法(Vaish等,2005)通过子视点叠加获取重聚焦图像,可以得到粗糙的视觉效果,但在散焦区域存在混叠等现象,这种情况在通过相机阵列获取的具有较大基线的光场图像上尤其明显。近年来,有不少基于光场重构算法用于解决这个问题。Kalantari等人(2016)通过神经网络对原有的子视点进行视点内插,利用合成的全新光场进行重聚焦。Ledig等人(2016)在Kalantari等人(2016)基础上引入生成对抗网络以提高生成子视点的质量。Wu等人(2017)为了进一步提高重构光场质量,先使用EPI(epipolar plane image)进行插值放大,然后使用神经网络修复高频细节重构光场。此类方法虽然能通过提高光场的角度分辨率缓解混叠的问题,但需要极高的计算成本,并且由于现有的光场重构算法自身存在的伪影、色差等常见问题,借助重构后的光场图像得到的重聚焦图像往往会产生新的问题。基于散焦渲染(Liu等,2016)的方法提供了一种全新的思路,使用光场图像的视差信息获取中心视点的弥散圆(circle of confusion,COC)图像,并借助各向异性滤波渲染图像,一定程度上降低了计算成本,但是该算法过分依赖COC图像的精度,一旦COC图像出现错误,就会出现同一深度平面同时出现对焦区域和散焦区域的情况,还会出现单一色块的现象,严重影响视觉效果。Ignatov等人(2020)借助深度学习提高散焦效果,虽然显著提升了视觉效果,却仅能聚焦前景,无法对景深进行调控。Busam 等人(2020)利用立体匹配图像进行重聚焦操作,可以提供更为准确的深度信息。Dansereau等人(2015)提出一种光场体积重聚焦的方法,相比于传统的平面重聚焦方法,能够获得更大的景深。
本文提出了一种可控景深的光场重聚焦方法,算法流程如图1所示。本文的贡献主要为以下3个方面:1)首次利用深度学习实现了可控景深的光场重聚焦算法,提高了算法效率。2)提出了一种条件生成对抗神经网络,能够借助光场的中心子视点以及COC图像生成对应的重聚焦图像。3)新建了一个具有光场图像、散焦图像与其对应的COC图像的数据集。

图1 本文算法总览Fig.1 Overview of our method
1 算法原理
本文算法分为两个步骤:1)首先利用光场图像计算出对应的视差图,再借助视差图计算光场子视点图像的中心视点中每个像素的COC。这一步可以调整参数得到不同大小的COC,从而完成对图像的景深的调整。2)以光场中心视点为输入、COC图像为条件输入,构建一个深度神经网络对中心视点进行散焦渲染,得到最终重聚焦后的图像。
1.1 弥散圆COC计算
设定透镜焦距为f,则图像中任意一个像素点P对应的COC的半径可表示(Liu等,2016)为
(1)
式中,Zf与Zp分别表示对焦平面与P点处的深度值,F表示所选光圈的光圈值。从光场模型(Wang等,2018)可知,深度Z=fB/d,其中B为光场图像基线,即光场图像子视点间的轴距,d表示视差值。本次实验中的视差图利用Wang等人(2019)的算法计算,最终式(1)整合为
(2)
式中,f,F,df,B均为定值,因此,图像中不同像素的COC的半径r与该点的视差值和对焦平面的视差值的差值的绝对值成线性关系。设点K为
(3)
则式(2)最终整合为
r=K|(dp-df)|
(4)
通过选择不同的df可以选择不同的对焦平面,此时对焦平面处的r数值为0。由式(4)可知,调整K值大小,可以对像素的COC的半径大小进行调整,较大的K值提供一个较大的COC的半径,产生一个比较明显的模糊效果,即一个较小的景深。为方便观察,本文对生成的单通道COC图像进行了染色处理,如图2所示,其中前4幅是合成场景,后两幅是真实场景,图2(b)右侧标尺数值表示COC的半径大小。

图2 具有不同焦平面与景深的COC图像Fig.2 COC images with different focal planes and depths of field((a)RGB images;(b)COC images)
1.2 条件生成对抗网络
COC图像体现了各深度平面的对象在成像平面的扩散程度,为了将其与原图像结合生成对应的重聚焦图像,Liu等人(2016)使用滤波器进行散焦渲染,但简单的线性叠加无法完全模拟散焦效果,并且极度依赖视差图的准度(计算出的数值和真实值的差异)。简单的端到端生成对抗网络无法有效控制最终生成的结果图像,即对于相同的输入图像,网络会根据输入的COC图像进行不同的散焦渲染,得到不同的散焦图像。对此,本文提出了一种基于COC图像的条件生成对抗网络模型,采用散焦渲染方法,并使用两个不同的编码器处理输入图像和约束条件,用于学习散焦图像与清晰图像和COC图像之间的映射关系,并在输入端通过添加约束条件的方式对结果进行控制。网络整体结构如图3所示,图中C表示concatenate操作,T/F意为True/False,即判别器的判别结果。

图3 本文提出的条件生成对抗网络结构Fig.3 Conditional generative adversarial networks structure proposed in this paper
网络生成器的输入为原光场的中心子视点图像(大小为512×512×3)和第1步计算得到的COC图像(大小为512×512×1),生成器的输出再与COC图像一起进入判别器,以保证生成的散焦图像与COC相对应。由于实际应用中往往无法获取精准的COC图像,本文将COC图像与中心视点图像分别输入网络,削弱二者的直接联系,降低不准确的COC图像对重聚焦图像的影响。生成器模型呈Y型结构,分为3段。第1段由两个编码器组成,分别对输入的COC图像和中心子视点图像进行特征提取。编码器分为4层,每层由1个卷积层、1个ReLU激活函数和1个BN(batch normalization)层组成,BN层的输出作为下一层编码器的输入。第2段的输入为第1段两个编码器的输出执行concatenate操作后的结果,由4层残差结构组成,目的是增加网络的深度以及整合两个编码器的输出。第3段是解码器部分,共4层,本文没有使用反卷积操作,而是选择了上采样后接2D卷积层,并添加了与中心视点编码器的跳级连接,最后对连接结果进行卷积核大小为1的卷积操作,解码器每层均添加了ReLU激活函数和BN层。判别器的输入为执行concatenate操作后的中心子视点图像和COC图像,再经过3层编码器(编码器结构与生成器一样),最后通过两层全连接层以及sigmoid激活函数得到判别结果。
本文提出的条件生成对抗网络的损失函数包含两部分,定义为
Losstotal=λ0LossD+LossG
(5)
式中,LossD表示判别器损失,在提出的方法中采用交叉熵损失作为判别器损失,LossG表示生成器损失,超参数λ0在本次实验中设置为10。
生成器损失LossG定义为
LossG=λ0LossL1+λ2Lossper+λ3Lossstyle
(6)


表1 不同超参数的平均PSNR和SSIMTable 1 Average PSNR and SSIM under different hyperparameters
实验表明,本文拟定的参数值可使结果达到一个理想指标。λ2和λ3参考 Liu等人(2018)方法中的取值。
L1损失LossL1定义为
(7)
式中,Vgen表示生成器的结果,Vgt表示图像的真值。本文使用预训练的VGG-16(Visual Geometry Group 16-layer network)(Simonyan和Zisserman,2015)网络对生成器的结果和真值进行特征提取,并选择pool1,pool2和pool3网络层计算特征图的损失。
感知损失Lper定义为
(8)

风格损失Lstyle定义为
(9)
式中,G代表Gram矩阵。
2 实验结果
条件生成对抗网络的训练需要大量带有条件的数据集,而本研究需要的重聚焦图像和COC图像并无公开的数据集可直接利用,因此本文借助blender仿真软件制作了一个全新的数据集。使用blender仿真软件制作数据集有3个优点:1)可以获取每个光场子视点对应的准确视差,可以计算出最精准的COC图像;2)参数透明可控,可以获取与COC图像对应的重聚焦图像;3)模型容易获取,场景多样,可以快速制作出大量数据集用于训练。该数据集包含10个不同的场景,每个场景选择了多个对焦平面,渲染了多种不同景深的光场图像,并借用了blender中的单反相机插件模拟了其对应的散焦效果。本文数据集共包含210组光场图像和对应的重聚焦图像,并从中随机抽取了180幅光场图像用于神经网络训练,3幅用于评估模型,剩下27幅以及5幅真实场景数据用于测试。本文所提算法在TitanX GPU上进行网络训练,训练次数为3 500,初始学习率设为0.000 2,训练完成约需28 h。
2.1 光场重聚焦结果对比
本文与传统重聚焦算法(Vaish等,2004)、基于光场重构优化后的重聚焦算法、包括利用神经网络进行光场重构的重聚焦算法(Kalantari等,2016)、引入对抗网络提高重构光场质量的重聚焦算法(Ledig等,2016)、利用EPI进行光场重构的重聚焦算法(Wu等,2017)以及结合COC图像使用各向异性滤波模拟散焦渲染的算法(Wang等,2019)进行对比。由于传统重聚焦算法和基于光场重构的重聚焦算法都不具备修改对焦平面和景深的功能,因此本文仅与其在单一对焦平面与景深上对比,结果如图4所示,其中,图4(b)为真值图像,其对应的COC图像如图2所示。由于Wang等人(2019)、Kalantari等人(2016)和Ledig等人(2016)的算法均无法处理图像的边缘,对图像进行了裁剪处理,为方便定性分析,对上述算法结果的边缘进行了简单的填充处理,如图4(c)(f)(g)所示。
从图4可以看出,传统重聚焦算法在散焦区域存在严重混叠现象,如图4各算法第1行中的树叶等。基于光场重构的算法通过视点内插提升子视点数量,一定程度上改善了混叠现象。但是,此类算法的最终效果极其依赖于重构的子视点质量,颜色误差、伪影等现象对最终的重聚焦图像质量会产生较大影响,上述对比实验都体现了这个问题。基于各向异性滤波的算法在大范围的散焦区域表现尚可,但存在大量单一色块的现象(图4(c)第2行),而且在散焦区域和清晰区域交界的地方存在大量错误(图4(c)第4行)。本文算法能较好地解决上述问题,在散焦区域和清晰区域交错存在的地区也能保证过渡平缓,散焦区域也较为自然,不存在混叠现象,同时,在与训练集存在较大差异的真实场景中也能得到较好的结果。与仿真数据相比,真实场景计算的COC图像存在较多错误,如位于散焦区域的像素却得到一个较小的COC数值,导致其未能进行正确的散焦渲染,Wang等人(2019)的算法就体现了这个问题。本文算法利用深度学习技术,并采用了Y型结构的生成器,削弱了COC图像与输入的中心子视点图像的直接联系,可以大幅度降低错误的COC图像对散焦渲染效果的影响。同时,本文算法在对焦平面区域存在清晰度不高、细小的纹路和材质无法恢复的问题,这可能是由于本文的网络结构主要功能是对输入的中心视点依照对应的COC图像进行散焦处理,对所有区域都会进行不同程度的模糊。

图4 光场重聚焦实验对比Fig.4 Comparison of light field refocusing by different methods((a)center images;(b)ground truth;(c)Wang et al.(2019);(d)Vaish et al.(2004);(e)Wu et al.(2017);(f)Kalantari et al.(2016);(g)Ledig et al.(2016);(h)ours)
最后,本文通过平均峰值信噪比(PSNR)和平均结构相似性(SSIM)对不同的算法结果进行定量分析,结果如表2所示,其中,对Wang等人(2019)、Kalantari等人(2016)和Ledig等人(2016)的算法仅计算裁剪后区域的数值。定量分析表明,本文算法在大多数场景都优于对比算法,而在对焦平面区域占据图像大部分区域时,Vaish等人(2004)的结果略高于本文算法,这是因为该区域具有极小的视差,传统的重聚焦算法对此不需要进行复杂处理就可以使重聚焦后的图像在该区域与输入仅有微小差距,而本文算法仍需要通过网络对该区域进行散焦渲染。即便如此,本文的结果与其差距仍然很小。值得注意的是,在此类场景中,本文算法的视觉效果明显优于Vaish等人(2004)的结果。而Kalantari等人(2016)、Ledig等人(2016)和Wu等人(2017)的方法由于重构的光场子视点存在色差、伪影等问题,在数值上表现不佳。
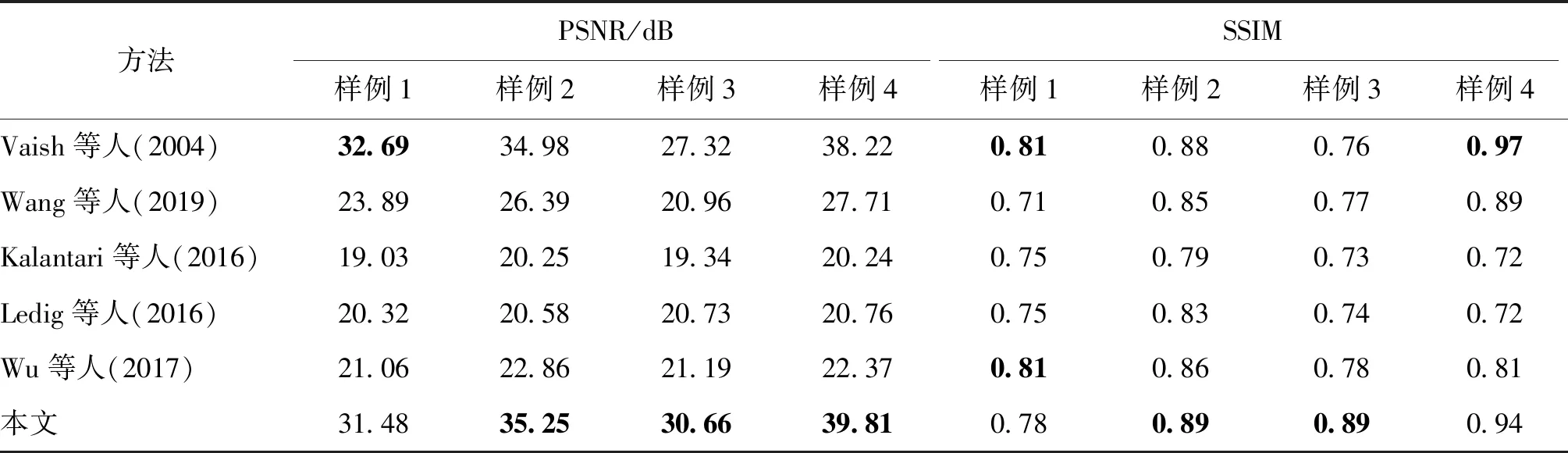
表2 光场重聚焦结果定量分析Table 2 Quantitative analysis of the light field refocus results
2.2 散焦渲染对比
Ignatov等人(2020)提出了一种利用深度学习的单幅图像散焦渲染算法,可以对输入图像的背景区域进行散焦渲染。本文算法获取了具有与之相同对焦平面与景深大小的实验结果。二者的对比实验结果如图5所示。实验结果表明,Ignatov等人(2020)的算法可以在背景区域取得较好的散焦效果,但是由于完全依赖神经网络选择散焦渲染的区域,未添加有效的约束,导致前景区域也存在不同程度的模糊。本文算法以COC图像作为约束条件,可以更好地区分散焦区域与对焦区域。同时,除了背景的散焦渲染外,本文算法还提供了调节对焦平面与景深大小的功能。

图5 Ignatov等人(2020)与本文方法散焦渲染实验对比Fig.5 Comparison of bokeh rendering between Ignatov et al.(2020)method and ours((a)center images;(b)ground truth;(c)Ignatov et al.(2020);(d)ours)
2.3 对焦平面与景深的调节
本文算法首先生成包含不同对焦平面和不同景深信息的COC图像,再通过条件生成对抗网络进行散焦渲染获取对应的重聚焦图像,能够获得单反相机拍摄的图像后期处理难以达到的效果,实验结果如图6所示。

图6 对焦平面与景深调节实验结果Fig.6 Results of focal plane and depth of field adjusting((a)refocus images;(b)dyed COC images)
3 结 论
本文提出了一种光场图像重聚焦方法。首先输入光场图像、对焦平面与景深参数,得到COC图像,再将其与光场中心视点图像输入条件生成对抗网络,输出最终的重聚焦图像。本文提出的条件生成对抗网络能够根据输入的COC图像,对输入的中心视点图像进行相应的散焦渲染。实验结果表明,提出的方法可以显著地提升图像的视觉效果。
但是,本文提出的条件生成对抗网络模型仍存在一定的不足。在实际应用中,从真实场景的光场图像中计算的COC图像往往存在大量错误,导致对焦平面区域存在一定程度的模糊,尤其是对焦平面位于前景且占据图像大部分区域时,一定程度上影响了图像质量与视觉效果。下一步将通过引入可以同时利用仿真图像和真实光场图像的半监督的领域自适应学习优化模型,并尝试加入其他损失函数进一步弱化错误的COC图像对图像结果的影响,以期在真实场景上获取更好的效果。
猜你喜欢
中国德育(2022年9期)2022-06-20
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
检察风云(2021年10期)2021-07-28
党的生活·党员电教与远程教育(2018年6期)2018-08-02
天津诗人(2017年2期)2017-11-29
环境(2016年7期)2016-05-14
数码摄影(2009年8期)2009-10-14
中国校外教育(上旬)(2009年6期)2009-08-04
电影评介(2009年9期)2009-05-13
