
注意力机制改进轻量SSD模型的海面小目标检测
2022-04-24 09:53贾可心马正华朱蓉李永刚
中国图象图形学报 2022年4期
贾可心,马正华,朱蓉,李永刚
1.常州大学计算机与人工智能学院,阿里云大数据学院,常州 213000;2.嘉兴学院数理与信息工程学院,嘉兴 314001
0 引 言
中国拥有广阔的水域面积和大量海洋资源,随着对海洋开发需求的不断增长,无论对海洋资源勘探、无人艇避障还是目标攻击等应用,海面目标检测都是重要的研究课题(Zhao等,2014)。然而,海面复杂多变的环境和种类繁多的目标,对精确检测海面目标提出了更高要求,特别是海面小目标检测。进入21世纪以来,以大数据、人工智能为代表的新一代信息技术快速发展,为推动海洋事业发展做出了重要贡献。深度学习模型强大的特征提取能力,使其在目标检测技术中得到广泛应用,使用深度学习模型进行海面目标检测,可为海洋搜救、无人艇业务和智能船舶等提供技术支持。
目标检测技术主要包括基于图像处理并结合机器学习算法的传统目标检测方法和基于深度学习的目标检测方法,如图1所示。

图1 目标检测技术的主要研究方向Fig.1 Main research directions of object detection technology
传统的目标检测方法主要有特征匹配法、背景差分法、帧差法和光流法。背景差分法、帧差法和光流法多用于运动目标检测,特征匹配法适用于图像目标检测,主要分为区域选择、特征提取和图像分类3部分。虽然有一些检测效果较好的传统目标检测方法,但面临检测精度低和检测速度慢等问题。相比传统目标检测方法,基于深度学习的目标检测方法在速度和准确率方面均有明显优势。基于深度学习的目标检测方法大致分为两个研究方向:基于目标候选框检测与卷积神经网络结合的two-stage目标检测系列和基于回归的一体化卷积网络one-stage目标检测系列。在two-stage系列中,以区域卷积神经网络(region convolutional neural network,R-CNN)的系列算法为代表算法,逐步实现端到端的目标检测,检测精度得到大幅提升,但网络参数庞大,检测速度较慢(Ren等,2017)。以单次检测器YOLO(you only look once)(Redmon等,2016)和单网多尺度检测器SSD(single shot multiBox detector)(Liu等,2016)为代表算法的one-stage系列算法,相比two-stage检测器,检测速度得到一定幅度提升,但定位精度有所下降,且仍有模型参数过大问题。
基于深度学习的目标检测方法通常是针对通用目标数据集设计的检测模型,对于图像中的小目标来说,检测效果并不是很理想。定义小目标一般有根据绝对尺寸进行定义和根据相对尺寸进行定义两种方式。根据绝对尺寸进行定义时,以COCO(common objects in context)数据集为例,尺寸小于32 × 32像素的目标即为小目标;根据相对尺寸进行定义时,国际光学工程学会(International Society of Photo-Optical Instrumentation Engineers,SPIE)将小目标定义为在256 × 256像素的图像中目标面积小于80像素的目标,即目标面积小于图像面积的0.12%。针对图像中的小目标检测,部分研究在现有检测模型基础上提出了一些改进方法。特征金字塔网络(feature pyramid network,FPN)(Lin等,2017)采用多尺度特征融合方式,通过融合高层语义信息和低层位置信息后的结果来检测目标,该方法是针对通用目标的检测方法,在小目标检测中起到了关键作用,但结果不可控。Bell等人(2016)提出利用上下文信息和多尺度特征改善小目标检测效果。Yang等人(2016)提出根据候选区域尺寸大小提取不同卷积层特征,并使用级联分类器快速提取不含目标的候选区域,提高了小目标的检测精度和速度。检测小目标可以通过使用高层特征图来加强低层特征图的语义信息(Cao等,2018)、增加图像分辨率或融合高分辨率特征与低分辨率图像的高维特征来解决(Menikdiwela等,2017),然而使用较高分辨率的图像会增加计算开销,对设备要求较高。Singh等人(2018)提出一种新的训练思路,利用类似滑动窗口的碎片chips,先粗略定位正负样本的所在区域,然后将该区域作为卷积网络的输入,进行精确检测。该方法摆脱了模型训练时对较高分辨率图像的依赖,对小目标的检测效果也有所提升,但实现过程相对复杂。感知生成对抗网络(perceptual generative adversarial network,PGAN)(Li等,2017)使用生成对抗网络(generative adversarial network,GAN)在卷积网络中构建特征,其中生成器生成小目标的超分表达,判别器能从生成的超分图形中的检测获益量来计算损失值,然后交替执行生成器和判别器网络对抗训练过程,利用大小目标的结构相关性来增强小目标的表达,使其与对应大目标的表达相似,从而提高小目标检测性能,但网络构建的特征在交通标志和行人检测上下文中难以区分大小目标。Chen等人(2016)改进候选区域生成网络,并结合上下文信息采用上采样策略用于小目标检测。Cheng等人(2018)和Ren等人(2018)通过添加上下文信息提高小目标检测的检测效果。Hu和Ramanan(2017)提出一种无约束条件下的低分辨率人脸检测方法,通过在不同大小的模板上分别寻找对应大小的目标,采用超分辨率和细化网络生成真实清晰的高分辨率图像,并引入判别网络对人脸与非人脸进行分类,从而增强人脸检测算法的鲁棒性,但对其他小目标的检测效果有待验证。另外,Kisantal等人(2019)通过对数据集进行预处理,利用过采样和增强的方法提高小目标的检测性能,但大目标的检测效果会受到影响。
目前,基于深度学习的目标检测方法的研究更多集中于构建更深的网络,以达到提高检测精度的目的,网络模型一般存在参数量过于庞大,从而导致检测速度过慢等问题,且大部分检测效果优秀的网络仅能在高性能的图形处理器(graphics processing unit,GPU)上运行,对设备计算能力要求较高,而压缩模型又会影响模型的检测精度。同时,海面图像中目标复杂多样,其中小目标相对较多,通用目标检测模型和一些特定的小目标检测模型对海面目标的检测效果还有待验证。因此,本文在标准的SSD目标检测模型基础上,结合Xception深度可分卷积神经网络结构,在保证一定检测精度的情况下,提出了轻量化的SSD海面目标检测模型。同时,基于提出的轻量化SSD海面目标检测模型,引入轻量级注意力机制模块,在压缩模型的同时保证了目标检测精度,并可有效实现对海面小目标的检测,降低了小目标漏检率。
1 理论基础
1.1 标准的SSD目标检测算法
SSD目标检测算法是Liu等人(2016)提出的一种one-stage深度学习目标检测算法。标准的SSD目标检测算法基于VGG-16(Visual Geometry Group network-16)网络模型,删除末端全连接层,添加辅助卷积层和池化层,提取特征的同时减小特征图的尺寸,并在6个不同尺寸的特征图上进行预测。标准的SSD目标检测算法架构细节如图2所示。

图2 标准的SSD目标检测算法架构细节Fig.2 Architecture details of the standard SSD object detection algorithm
SSD目标检测算法结合了YOLO算法检测速度快和区域候选网络(region proposal network,RPN)定位精准的优点,采用RPN中的多参考窗口技术,进一步提出在多个分辨率的特征图上进行检测,训练过程中融入难分样本挖掘操作,对图像中难分样本进行聚焦,针对具有多种尺度的目标检测效果较好,但对小目标的检测通常效果不佳。
1.2 Xception网络结构
Xception(Chollet,2017)是谷歌公司继inception后提出的inceptionV3的一种改进模型,采用深度可分卷积替换inceptionV3中的多尺寸卷积核。简化的inception模块如图3所示。

图3 简化版inception模块Fig.3 Simplified inception module
深度可分卷积是轻量化网络的主要结构,由3 × 3和1 × 1卷积核组成,将标准卷积分为深度卷积和逐点卷积,即在输入的每个通道独立执行空间卷积,再进行逐点卷积,将深度卷积的通道输出映射到新的通道空间,简化结构如图4所示,其主要作用是减少网络参数,加快网络运行速度。
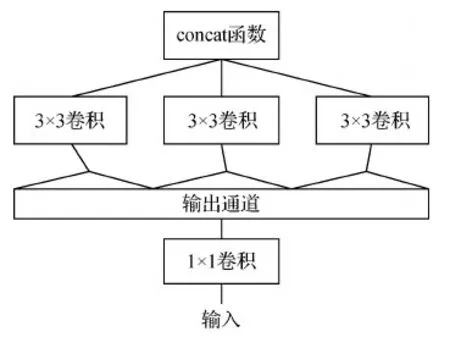
图4 简化版Xception模块Fig.4 Simplified Xception module
Xception网络是带有残差连接的深度可分卷积层的线性堆叠。基于深度可分卷积,搭配线性残差卷积网络实现内部结构的每个块,使得该结构非常容易定义和修改,主要块结构有两种,如图5所示。
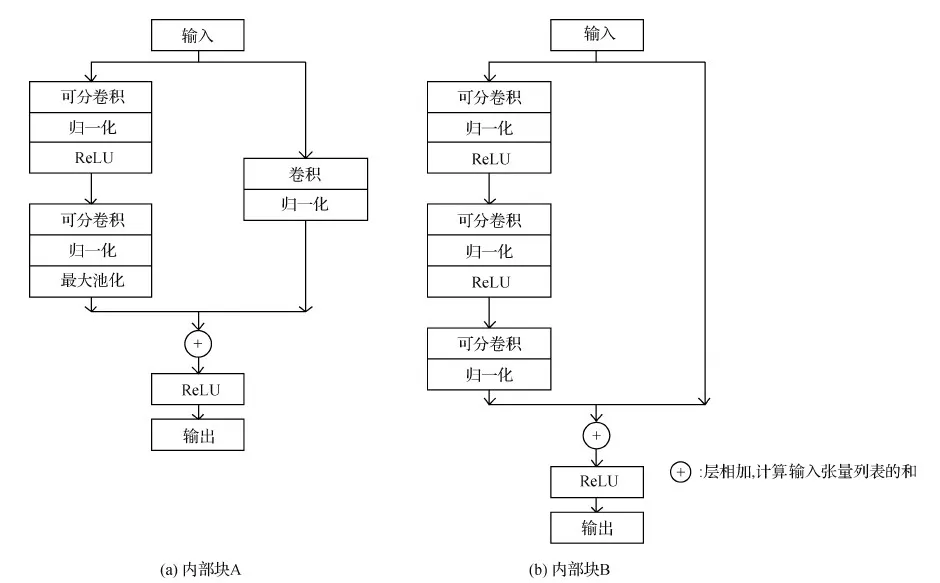
图5 Xception内部块结构Fig.5 Internal block structure of Xception ((a)internal block A;(b)internal block B)
1.3 注意力机制
深度学习中的注意力机制借鉴了人类的视觉注意力机制,在快速扫描全局图像的同时,获得需要重点关注的目标区域,并对此区域投入更多的注意力资源,以获取关注目标的细节信息,从而抑制其他无用信息。在计算能力有限的情况下,注意力机制是解决信息超载问题的一种分配方案,可将计算资源更多地分配给表征中较有价值的部分。
近年来,在计算机视觉领域中注意力机制的应用逐渐增加,Wang等人(2017)提出使用一种基于注意力的可堆叠的残差学习网络结构,在前向过程中提取模型的注意力,使模型训练更加简单,且易优化和学习,具有较好的性能。Hu等人(2018)通过显式地建立通道间的依赖关系,使网络能够执行动态通道特征,重新自适应地校准通道式的特征响应,提高了网络的表征能力。受此启发,结合SSD目标检测算法的特点,本文引入了轻量级注意力机制模块进行进一步研究。
2 本文模型
本文在标准的SSD目标检测模型基础上,结合Xception深度可分卷积,提出了轻量SSD模型用于海面目标检测,减少了网络模型的参数,使网络模型轻量化得到体现。同时,为保证检测精度,引入轻量级注意力机制模块,降低了小目标的漏检率,可有效检测出图像中的小目标。模型总体网络结构如图6所示,架构细节如图7所示。
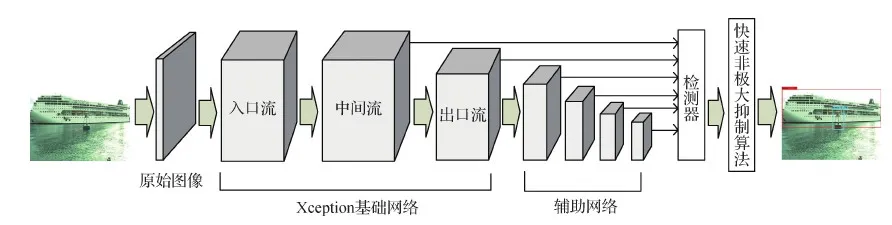
图6 本文模型总体网络结构Fig.6 The network structure of this model

图7 本文模型网络架构细节Fig.7 Network architecture details of this model
2.1 基于Xception网络的深度可分卷积特征提取网络
标准的SSD目标检测模型采用VGG-16作为特征提取网络,其中使用标准的卷积方式进行密集链接,参数量相对较大。而Xception网络采用深度可分卷积,对过参数化的标准卷积进行压缩,使网络轻量化得到体现。基于Xception网络的深度可分卷积特征提取网络分为入口流(entry flow)、中间流(middle flow)和出口流(exit flow)3部分,共13个块,其中entry flow有4个,exit flow有1个,主要由Xception内部块结构A组成;middle flow有8个,主要由Xception内部块结构B组成,结构如图8所示。

图8 特征提取网络结构Fig.8 Structure of the feature extraction network ((a)entry flow;(b)middle flow;(c)exit flow)
本文模型使用深度可分卷积层替代标准卷积层,其中Xception网络的entry flow替代VGG-16中的前4个块,middle flow和exit flow替代VGG-16中的第5个块,后接4个标准卷积层,作为整体特征提取网络。同时,将其中6个卷积层生成的特征图输入到检测模块中进行回归和分类,包括middle flow生成的特征图、exit flow生成的特征图以及后4个标准卷积层生成的特征图。
2.2 轻量级注意力机制模块
使用深度可分卷积可以减少参数量,但由于失去了大部分可调参数,在一定程度上牺牲了检测精度。为保证轻量化后的SSD目标检测模型的检测精度,本文引入轻量级注意力机制模块(lightweight attention modules,LAM)来提升目标的检测效果。
轻量级注意力机制模块对输入的特征层进行全局平均池化,再分别采用线性整流函数ReLU(rectified linear unit)和hard-swish激活函数进行两次全连接,通过调整通道的权重,达到选择更具有价值的特征信息的目的。LAM结构中使用的激活函数ReLU和hard-swish为
relu(x)=min(max(x,0),6)∈[0,6]
(1)

(2)
式中,变量x为输入图像,relu表示激活函数ReLU,h-swish表示激活函数hard-swish,该函数类似于sigmoid激活函数,可以减少运算量,提高性能。LAM结构如图9所示。

图9 轻量级注意力机制模块结构Fig.9 Structure of lightweight attention mechanism module
3 实验与分析
3.1 实验平台
在Windows10 64位操作系统上搭建深度学习开发环境,选用PyCharm作为集成开发环境,实验框架基于Python语言实现。主要配置为16.0 GB内存,Intel Core i7-9750H @ 2.60 GHz CPU,显卡(GPU)型号为NVIDIA GeForce RTX 2060,显存6 GB,显卡计算能力为7.5。深度学习开发环境为JetBrains PyCharm Community Edition 2017.2.4 x64,Python 3.6.5,CUDA 9.0,cuDNN7.6.4.38,tensorflow-GPU 1.9.0和Keras 2.2.0。
3.2 实验数据
实验原始数据来源于海洋障碍检测数据集MODD 2(marine obstacle detection dataset 2)(Bovcon等,2018)。该数据集图像由船(boat)和浮标(buoy)等海面物体组成,原始图像大小为1 278 × 958像素,本文实验采用其中5 050幅图像,检测目标设定为船(boat)和浮标(buoy)两类,并将图像直接缩小到300 × 300像素,如图10所示,其中包含目标的图像共3 823幅,包含船的图像2 571幅,包含浮标的图像2 041幅,随机选取2 140幅图像用于训练,1 147幅图像用于测试,通过标注软件(LabelImg)对船和浮标进行标定,按照VOC2007(visual object class 2007)数据集格式进行处理,包含目标总数为5 019,其中标签boat的数量为2 840,标签buoy的数量为2 179,构建海面目标检测数据集,并定义本数据集中所占像素面积小于32 × 32像素的目标为小目标。据实验统计,本数据集标签boat的小目标数量为1 150,标签buoy的小目标数量为1 408。

图10 原始数据集Fig.10 Original dataset
由于本文选取的海面目标检测的数据集样本量不大,若直接使用该数据集从零开始进行训练会导致网络收敛速度慢,检测效果也会受到一定影响。因此,采用迁移学习的方法,利用预训练的模型,对本文数据集进行微调训练。同时,在对海面图像采集设备不做高要求的基础上,一般采集到的海面图像分辨率相对较低,为使本文模型在此情况下也有较好的检测效果,在训练模型前,将图像直接缩小至300 × 300像素。图像缩小后对原始图像中的小目标的分辨率会有一定的影响,后续工作中将考虑直接使用原始图像进行实验,并将图像缩小后的实验结果与直接使用原始图像的实验结果进行对比,为得到检测效果更好的网络模型做准备。
3.3 实验分析
训练过程中,对输入图像进行归一化处理,缩小为300 × 300像素的RGB图像,基于Xception在COCO数据集上预训练的模型进行训练,使用模型参数量(model parameters,params)、浮点计算量(floating-point operations per second,FLOPs)、每秒内可处理的图像数量(frames per second,FPS)、检测精度(precision rate)和漏检率(miss rate)对模型进行评估,并采用平均精度均值(mean average precision,mAP)评估模型在本文数据集上的各类别的性能。检测精度和漏检率的计算公式为
(3)
(4)
式中,fprce表示检测精度,fmiss表示漏检率,TP(true positives)为真正例,即同一真实标签只计算一次情况下,交并比 (intersection-over-union,IoU)>0.5的检测框数量;FP(false positives)为假正例,即IoU≤ 0.5的检测框或检测到同一真实标签的多余检测框数量;FN(false negatives)为假负例,即未检测到的真实标签数量。
3.3.1 实验1
实验使用基于Xception网络的深度可分卷积特征提取网络替换VGG-16骨干网络,并通过控制变量,对比不同网络模型的检测效果,包括基于VGG-16的SSD网络(SSD + VGG-16模型)、基于Mobilenet的SSD网络(SSD + Mobilenet模型)以及基于Xception的SSD网络(SSD + Xception模型)。
4种模型的浮点运算量如表1所示,标准的SSD目标检测模型的浮点运算集中于乘(Mul)和加(Add)运算,计算量较大,内存访问成本较高;其他模型则通过减少Mul和Add运算,提高内存的读写速度,从而达到网络轻量化的效果。

表1 4种模型的浮点运算量Table 1 Floating-point operations of four models
4种模型的轻量化评价指标的实验结果如表2所示。对比第1行和第2行结果可以看出,Mul和Add运算的大量减少使得以Mobilenet为特征提取网络的目标检测模型的参数量和浮点运算量均有所降低,同时每秒内可处理图像的数量有所增加,但检测模型的轻量化导致其特征表达能力降低,从而影响了检测精度,mAP降低了2.28%。对比第1行和第3行结果可以看出,以Xception为特征提取网络的SSD + Xception目标检测模型转化一定量的Mul和Add运算,使其参数量降低了19.01%,浮点运算量降低了18.40%,保证了模型的特征表达能力,在减少参数量和浮点运算量的同时,保持每秒内处理图像数量基本不变,检测精度降低较少,达到了在保证一定的检测精度情况下,对网络轻量化的效果。

表2 4种模型的轻量化评价指标的实验结果Table 2 Experimental results of lightweight evaluation indexes of four models
3.3.2 实验2
实验以基于Xception特征提取网络的SSD+ Xception目标检测模型为轻量化SSD模型,分别在不同输出层引入轻量级注意力机制模块来提高模型的检测精度,并进行检测效果对比,实验结果如表3所示。

表3 不同输出层引入轻量化注意力机制对实验结果的影响Table 3 Effects of different output layers on experimental results by introducing lightweight attention mechanism /%
虽然网络高层的特征语义信息比较丰富,但随着网络逐层升高,图像中的小目标的特征语义信息逐渐淡化,使得检测过程中小目标易漏检。网络低层的特征语义信息较少,但小目标的特征语义信息明确,且目标位置准确,在低层引入注意力机制模块可以将注意力集中在部分显著或感兴趣的信息上,对小目标的特征语义信息表达起到一定积极作用。
从表3可以看出,在不同输出层引入LAM得到的mAP也不同。在6个特征层均引入LAM的情况下,mAP反而有所下降,随着LAM在特征层的引入逐渐趋于低层化,mAP逐渐增加,在中间流、出口流和卷积层1分别引入LAM时,mAP达到局部最大值。单独在出口流引入LAM时,与未引入LAM的轻量化SSD模型相比,mAP提高了0.11%。在出口流和卷积层1分别引入LAM时,检测效果最好,与未引入LAM的轻量化SSD模型相比,mAP提高了1.22%。
本文模型为在出口流和卷积层1分别引入LAM的轻量化SSD目标检测模型,与其他改进SSD模型的目标检测效果评价指标进行对比,实验结果如表4和图11—图15所示。综合表2的实验结果,对比本文模型和其他3种模型的目标检测效果,与SSD+Mobilenet和SSD + Xception两种模型相比,虽然本文模型的参数量和浮点计算量有所增加,但检测效果也有所增强,甚至部分指标超过了标准SSD目标检测模型;与标准SSD目标检测模型相比,本文模型每秒处理图像的数量基本不变,并且在参数量降低16.26%、浮点运算量降低15.65%的情况下,buoy的平均精度提高了1.1%,漏检率减小了3%,mAP提高了0.51%,同时保证了boat的平均检测精度,提高了检测准确率。

表4 4种模型的目标检测效果评价指标的实验结果Table 4 Experimental results of object detection effect evaluation indexes of four models /%

图11 mAP及两类目标AP的实验结果Fig.11 Experiment results of mAP and two kinds of objects AP

图12 boat类精确率—召回率曲线Fig.12 Precision-recoll(P-R)curves of boat class

图13 buoy类精确率—召回率曲线Fig.13 Precision-recoll(P-R)curves of buoy class

图14 FP与TP检测结果Fig.14 Detection results of FP and TP

图15 漏检率实验结果Fig.15 Experimental results of missing rate
使用本文模型和其他模型分别对图像中的小目标和非小目标进行测试,效果如图16和图17所示。可以看出,对图像中的小目标测试时,本文模型优于其他模型,但是对图像中非小目标测试时。同时,由图17可以看出,在对图像中的重叠目标测试时,本文模型的检测效果并不明显。对此,本文从构建的数据集中选取457幅含重叠目标的图像作为测试集对重叠目标进行检测实验,结果如表5所示,本文模型在对重叠目标进行检测时,mAP值均高于其他3种模型,但是浮标漏检率略高于标准的SSD模型。

表5 4种模型对重叠目标的检测效果评价指标的实验结果Table 5 Experimental results of overlapping object detection effect evaluation indexes of four models /%

图16 小目标测试效果Fig.16 Test effect of small objects ((a)SSD + VGG-16;(b)SSD + Mobilenet;(c)SSD + Xception;(d)ours)

图17 非小目标测试效果Fig.17 Test effect of non small objects ((a)SSD+VGG-16;(b)SSD + Mobilenet;(c)SSD + Xception;(d)ours)
由此可见,由于较低层的特征图蕴含更多小目标的信息,本文模型在较低的特征层中引入轻量级注意力机制,能有效提升小目标检测性能,同时能有效提升重叠目标的检测效果。
使用本文模型与其他目前流行的轻量化目标检测模型进行对比实验,选择在PASCAL VOC2007(pattern analysis,statistical modeling and computational learning visual object classes 2007)数据集上对模型进行训练,并在VOC2007测试集上进行测试。实验结果如表6所示,虽然Tiny SSD模型最小,但其检测精度相对较低;本文模型比Tiny YOLOv2、Tiny YOLOv3和PeleeNet更轻量化,但在检测精度上优于以上模型。权衡两个检测标准,本文模型取得了较好的检测效果。
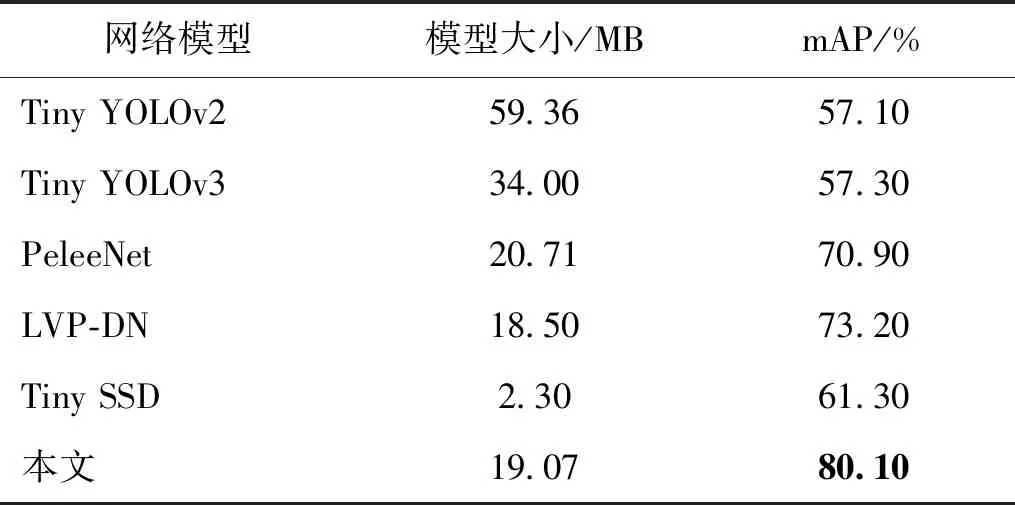
表6 本文模型与其他轻量化目标检测模型的对比实验结果Table 6 The comparison experimental results between the proposed model and other popular lightweight object detection models
4 结 论
本文提出一种注意力机制改进的轻量SSD模型用于海面小目标检测,针对标准的SSD目标检测模型参数量较大、对设备计算能力要求较高等特点,在保证一定的检测精度的情况下,以Xception网络作为特征提取模块对其进行轻量化操作,基于轻量化的SSD目标检测网络,引入轻量级注意力机制模块,对轻量化后的网络进行优化,弥补由于参数量降低带来的检测精度损失,同时提高了对小目标的检测效果。
目前,本文实验只针对船和浮标两类海面目标进行检测,后续考虑增加检测目标种类,统计数据集中的大小目标检测情况,对在不同层引入注意力机制时大小目标的检测精度进行量化对比分析。本文模型将注意力集中于较低特征层,使得高层的特征语义信息相对忽略,从而对图像中部分重叠目标的检测效果有一定的影响,后续考虑利用高层语义特征增加经验知识,继续对网络进行优化,并对海面目标与岸边目标重叠的检测情况进行实验对比分析,以寻求效果更好的网络模型用于海面目标检测。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年15期)2022-08-19
汽车实用技术(2022年11期)2022-06-20
汽车实用技术(2022年9期)2022-05-20
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
初中生世界·九年级(2018年12期)2018-12-22
中国新通信(2017年9期)2017-05-27
