
融合相似性判断的网络新词发现算法
2022-04-20 04:06张爽,陈莉,李铮
西北大学学报(自然科学版) 2022年2期
张 爽,陈 莉,李 铮
(西北大学 信息科学与技术学院,陕西 西安 710127)
近年来,微博、短视频等各类社交媒体对人们日常生活中的信息传播起着很大作用,人们倾向于从这些社交软件上获取新闻资讯、关注热点事件,大量网络新词也借助着这些社交媒体被广泛传播。已有研究表明,由于新词没有被完全发现会导致60%的分词错误,而且分词效果的好坏会直接影响中文文本情感分析过程中情感词典的构建以及情感倾向性判断[1]。
新词发现通常指的是未登录词的发现,这些词大多来自于微博文本、短视频评论以及长视频弹幕,具有构词模式简单自由且构词方式多样等特点。目前新词发现方法主要分为3种:①基于规则的方法、基于统计的方法以及基于统计与规则相结合的方法。基于规则的方法[2]主要利用语言学中的构词规则、词性以及语义信息设计出可以进行词语匹配的规则模板,然后,通过设计好的模板对语料进行匹配发现新词,在特定领域使用这种方法进行新词发现的准确率较高,但可移植性较差,需要耗费大量的人力物力。②基于统计的方法是通过词频、互信息及邻接熵等统计信息量识别新词,基于统计的方法更灵活,可移植性强且易于扩展。Zhang等人针对互信息的不对称共现问题,首次提出了增强互信息用于计算词语的内部凝聚度,有效识别多字表达式,但其忽略了语言特征对于新词识别的影响[3];李文坤等人提出一种基于词内部结合度和边界自由度的新词发现方法,从没有成功分词的“散串”中发现新词,该方法对数据稀疏性很敏感,无法有效识别低频新词[4];夭荣朋等人提出了一种基于改进互信息和邻接熵的微博新词发现算法,针对传统互信息难以识别大于两个字的多字词问题,证明了多字串互信息公式的有效性,但该算法采用N-Gram模型,导致新词发现过程中候选词串数量过多[5];刘伟童等人针对N-Gram产生大量词串导致新词发现效率较低的问题,提出从左到右逐字扩展候选词串的切分方法,该算法有效提高了发现新词的效率,但未考虑上下文语义对新词识别的影响[6]。③融合规则和统计的方法成为目前新词发现的主流方法,该方法综合了两种方法的优点。张海军等人提出利用逐层剪枝的方法过滤低频重复串,再利用统计量计算得到字串的牢固程度,最后,加入偏旁的词性猜测特征用于海量语料文本中的新词发现,但该方法对于长词以及单字词的识别效果不佳[7];赵志滨等人针对领域新词的发现,提出基于依存句法分析和词向量结合的方法,首先,以依存句法分析为基础构建句法词典,再结合词向量技术可以有效识别领域新词,但该方法对于开放领域的新词识别具有局限性[8];Shang等人通过word2vec模型训练得到候选词与旧词相似值,在传统互信息公式中加入相似性增强值的计算,过滤非新词的固定表达,该算法在小规模语料库上取得了不错的效果,但忽略了句子结构以及停用词对识别结果的影响[9];王煜等人通过分析热点新词的特性,利用改进的FP-tree找到频繁候选新词串,在点互信息的基础上加入时间特征值判断候选词的内部结合强度,使得热点新词的识别率大幅度提升,但该方法无法适用于大量网络文本的新词发现[10]。
综上,现有的新词发现方法已取得了较好的识别结果,但仍存在两个主要问题:①大多方法默认新词为二字词或多字词,未考虑单字词作为新词的情况,导致单字新词无法识别;②忽略了句子结构信息和上下文语义信息对于新词识别的影响,导致新词识别的准确率不高。针对上述问题,本文在新词发现过程中,基于字的粒度进行统计量的计算,获取候选新词集;并基于CNN模型,提出一种依存句法与语义信息结合的相似性计算模型(similarity computing model based on dependency syntax and semantics,DSSCNN)计算候选词和旧词所在句子相似性值,得到最终新词集合。实验结果表明,该算法能够有效提高新词识别的精度。
1 相关统计量
1.1 最大增强互信息
通常将互信息作为词串成词概率的内部统计量,如果计算得到的互信息值越大,代表词串内部凝聚度越大,相互依赖性越强,即更容易组成词语。互信息[11]的计算如式(1)所示。
(1)
其中:p(x),p(y)表示词或单个字x、y单独出现在语料中的概率;p(x,y)表示x、y共同出现在语料中的概率;MI(x,y)表示x,y的凝聚程度。
互信息在衡量词语关联性方面存在非对称共现问题,即对于一个词对来说,仅考虑两个词的共现概率,忽略了某词单独出现而其他词没有单独出现的情况。比如:词语A出现次数为100,词语B出现次数为300,A和B共同出现次数为100,也就是说,A仅仅与B一块出现了,但B可能与其他词共同出现次数更多,在这种情况下,A中包含B的信息比B中包含A的信息更多,互信息就无法正确衡量A和B的内部凝聚度。针对此不足,文献[3]提出增强互信息(enhanced mutual information,EMI)的定义,如式(2)所示。
(2)
其中:多字候选词w=w1,w2,…,wS;nw为候选词w的出现次数;nwi是wi的出现次数;N是文本总数;f是平滑因子,保证nw=nwi时分母不为0。
通常同一新词可能由3字及以上短语的不同模式组合而成[12],比如“华语LIVE王”具有“华语/LIVE/王”“华语LIVE/王”“华语/LIVE王”等多种不同的组成模式,若对不同的模式分开计算,会导致识别结果存在冗余。因此,本文对组合成同一新词不同模式的EMI值取最大值。若同一候选词共有m种不同的组成模式,只保留该候选词的最大EMI值(MEMI),如式(3)所示。
MEMI(w)=max(EMI(wi)),
i=1,2,…,m。
(3)
1.2 加权左右邻接熵
邻接熵(branch entropy,BE)是HUANG等人提出用来衡量词串左右相邻词串对成词概率的影响的外部统计量[13],通过计算信息熵得到候选词左右邻接词串的可变性。通常候选词的左右邻接串可搭配的字词越丰富,BE越大。故一般取HL和HR中的较小值,左右邻接熵的计算分别如式(4)和式(5)所示。
(4)
(5)
其中:Wl是候选词x的左邻接字集合;Wr是候选词x的右邻接字集合;p(xl|x)表示xl为候选词x左邻接字时的概率;p(xr|x)为xr候选词x右邻接字时的概率。
若使用传统邻接熵计算得到的左右邻接熵值相等,会默认左右邻接字xl和xr对于候选词x贡献的信息量相同。但在实际文本中,若候选词的邻接字为停用词时,比如标点符号、特殊符号、常见字等,候选词更容易被切分为新词[14],即左右邻接字对候选词能否成词的贡献量存在差异。由于网络文本口语化严重,存在大量的停用词,因此,本文在式(4)和式(5)的基础上赋予邻接字符权值,用于区分邻接字为停用词或普通词时的贡献程度,加权后的邻接熵(weighted branch entropy,WBE)计算如式(6)和式(7)所示。
(6)

(7)
其中,权值wxl和wxr分别表示左右邻接字符对于新词划分边界的贡献大小。
2 融合相似性判断的网络新词发现算法
本文面向微博和短视频评论等网络文本进行新词发现,针对传统基于统计量的新词发现算法忽略了新词与旧词具有高度相似的句法和语义信息的问题,提出一种改进的相似性计算模型过滤无用新词。
2.1 改进的相似性计算模型
在实际文本中,某些满足统计量识别出来的新词只是一些固定表达,比如“在过程中”“年以来”等,容易被误判为新词[9]。并且只基于统计量无法正确识别旧词新义的网络新词,比如“真香”“塌房”等。因此,本文提出一种相似性判断原则,即新词与某些历史表达具有较强的关联性,若词语A与词语B具有相似的上下文语义信息,并且担当相同的句子成分或具有相同的依存关系时,词语A是一个旧词,词语B成为新词的可能性更大。
通常使用余弦距离等方法直接计算句子相似度会导致语义信息的丢失, 而且网络文本大多内容简短且数据量较大。 为了获取局部特征且保证较高的执行效率, 本文基于CNN模型, 提出DSSCNN相似性计算模型,DSSCNN模型结构如图1所示。

图1 相似性计算模型图Fig.1 Similarity calculation model
在模型输入层使用word2vec训练词向量,生成候选新词与旧词所对应句子的句子矩阵向量作为输入。
在句法结构相似性特征表示层,对中心词分别为候选新词和旧词的句子S1和S2进行依存句法分析,提取句法分析结果的依存词对,表示为三元组WordPair(wi,wj)=(wi,wj,relation),wi为中心词,wj为从属词,relation表示依存关系。分析文本结构,新词在句中大多充当主、谓、宾、定,依存关系以主谓、动宾、定中、状中关系为主,所以句法分析结果保留以上依存对。在句法结构相似性特征表示层,计算对应词向量w1和w2的相似度,形成句法相似性向量矩阵DM×N,M和N表示两个句子的中心词个数,相似度计算公式如式(8)所示。
(8)
其中,n表示词向量的维度。
两个句子的依存词对集合分别为DSetS1和DSetS2,基于依存句法分析结果,对relation相同的依存对计算余弦相似值,根据式(9)生成句子的句法结构相似性特征fdep。
Simdep(S1,S2)=
(9)
其中,α是计算余弦相似度的调整系数,由于不同数据集训练生成的词向量模型不同,得到的相似度值也会存在不同程度的差异,α主要用于放大相似度值,调整误差。设置门限值1,防止调整后的相似度值超出实际范围[-1,1]。max(cos(w,DSetS2))表示在依存词对集合DSetS2中词向量与中心词向量w的最大余弦相似度值。
在卷积和池化层,选择特定卷积核大小和最大池化方法,获得句子的特征输出表示向量o1和o2。在语义相似性计算层,依据余弦距离计算得出语义相似性特征表示fsem。在全连接层将o1、o2与获取的相似性特征向量fdep、fsem结合,形成新的特征向量f。最后使用log-softmax计算相似度值Sim(S1,S2)。
2.2 新词发现算法
现有的新词识别方法大多基于词的粒度,默认新词为二字词或多字词,而使用互信息无法计算单字新词的成词概率。针对此问题,本文基于字的粒度识别新词。
若使用现有分词工具分词后,将散串作为候选词会导致新词无法被正确识别;若采用N-Gram模型获取初始候选词,会导致候选词数量过于庞大,算法执行效率大大降低。因此,本文采用从左向右逐字扩展的方法计算相关统计量获得候选新词。
综上,融合相似性判断的网络新词发现算法先对原始文本数据进行预处理;再基于字的粒度,分别计算单字词频、最大增强互信息和加权左右邻接熵获取候选新词集;最后,基于DSSCNN计算新词与旧词所在句子相似度,过滤候选新词。算法的具体步骤如下。
输入: 原始文本数据集text, 词频阈值p,MEMI阈值t,WBE阈值k,相似度阈值s
输出:新词集合newWords
1)数据预处理。将获得的文本字符全部转为UTF-8编码格式;去除掉转发文本中的标识符、主题内容及一些特殊字符串,如“@人民日报”等;进行断句操作,保留断句结果;将文本中的停用词使用符号“-”代替。
2)获取候选单字新词集。将1)中的句子切分为单字集合,依次计算单字词频,若大于词频阈值p,将其加入候选单字新词集合中。
3)获取候选多字词。选择2)中单字与右邻接字结合为候选多字词。
4)判断最大增强互信息。使用式(3)计算候选多字词的MEMI值。若大于阈值t,执行5);若小于阈值t,将候选多字词加入候选新词集。
5)判断加权左右邻接熵。使用式(6)、(7)计算候选多字词的WHL和WHR值,若均大于阈值k,则向右继续扩展,执行4);若小于阈值k,则返回执行3)。
6)获取候选新词集。将2)的候选单字新词集合并到候选新词集合中。
7)获取旧词集合。使用pyltp的cws.model对中文维基百科语料进行分词,使用哈工大停用词典去停用词,得到旧词集合。
8)获取依存词对。使用pyltp的parse.model对候选新词和旧词所在句子进行依存句法分析。获取以候选新词和旧词作为中心词的依存词对集合。
9)判断相似性获取新词集合。使用DSSCNN计算候选新词与旧词所在句子的相似度。若大于阈值s,则将候选新词加入新词集合;若小于阈值s,去除候选新词。
3 实验结果与分析
3.1 实验数据集
本文爬取部分微博文本和短视频评论作为数据集,时间集中在2019年12月至2020年9月,包括基于关键字的微博内容、部分微博及短视频的评论信息。共采集数据8万条,该时间段内实时热搜前十的部分话题微博6万条,人民日报相关微博和热门短视频的评论文本2万条。将数据集按照4∶1的比例随机划分为训练集和测试集,本文实验部分所有对比方法均使用此数据集。
3.2 实验评价指标
本文利用N-Gram模型将原始文本划分为多个候选词串,因新词大多由1到6个字符构成,故N取值为1~6;再进行去重、去停用词等过滤操作;最后,根据搜狗新词细胞库等网络资源进行人工比对,共选取900个新词作为标准新词集。通过正确识别出来的新词个数与标准新词集对比,评价新词发现算法的优劣。采用的算法评价指标有准确率P(precision)、召回率R(recall)和F值(F-measure)。计算公式分别为

(10)
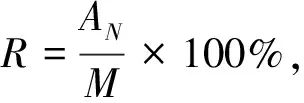
(11)

(12)
其中:AN表示正确识别出的新词数;N表示识别出的词语总数;M表示标准新词集中新词个数。
3.3 实验环境与参数设置
本文使用实验环境设置见表1。确定参数取值是利用贪心算法的思想,先选择一个随机值,再在一定范围内根据步长的大小进行多次实验,分析实验结果,选取F值最大时的参数值作为最终取值。

表1 实验环境配置参数表Tab.1 Experimental environment configuration parameters
对于调整参数α,初始取值为1,在范围[1,2]内,设置步长为0.1,进行多次实验得出F值随α取值的变化过程如图2所示,故最终确定α值为1.5。
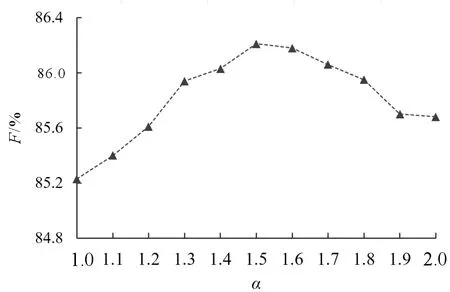
图2 调整参数α对F值的影响变化图Fig.2 The influence of adjustment parameter α on F
在确定统计量阈值时,若取值过大,会导致部分有效候选新词被过滤;若取值过小,划分的候选词串数量较大,导致新词识别的准确率较低。因此,先随机设置初始值,再进行反复实验不断调整。确定词频阈值时,初始值设为5,以步长5在范围[5,40]内进行多次实验,当F值最大时,阈值为20;再在范围[10,30]内,以步长2进行多次实验,当F值最大时,阈值为20,故最终确定词频阈值为20。其他阈值的确定思想同上述过程。经反复实验对比后,最终设置词频阈值为20,MEMI阈值为10,WBE阈值为5,相似性阈值为0.55。WBE中权值的设定主要为了区分停用词和普通词对于划分边界的贡献,故当邻接字符为停用词时,权值设置为1.5,相反,邻接字符为普通词时,权值设置为1。
使用Skip-gram[15]对中文维基百科和训练集数据进行训练,设置上下文窗口值为5,向量维度为50,训练完成后获得词向量表。然后对DSSCNN模型进行训练,设置卷积映射个数为100,卷积核大小为5,迭代次数为20。
3.4 实验结果分析
为验证本文提出算法的有效性,共设置两组对比实验,实验1为基于统计量的新词发现对比实验,实验2为融合相似性判断的新词发现对比实验。
3.4.1 实验1的结果与分析 第1组对比实验是基于统计量的方法,分别选取传统互信息与左右邻接熵结合MI-BE[6]、互信息和加权左右邻接熵MI-WBE结合[14]作为基准方法,同时和增强互信息与左右邻接熵组合EMI-BE、最大增强互信息与左右邻接熵组合MEMI-BE、增强互信息与加权左右邻接熵组合EMI-WBE、最大增强互信息与加权左右邻接熵组合MEMI-WBE共6种基于统计量的方法进行对比实验,结果如表2所示。

表2 基于统计量的实验结果对比表Tab.2 Comparison of experimental results based on statistics %
MI-BE采用文献[6]提出的新词发现方法,在进行新词识别的过程中,出现了大量满足阈值且具有近似含义的重复词串,比如“电影院”和“影院”、“饭圈文化”和“文化”等,这些重复词串的出现使得新词识别的准确率较低。EMI-BE和MEMI-BE可以有效识别共现不均衡的词语,准确率和召回率都有一定的提高。
MI-WBE在互信息的基础上使用加权左右邻接熵,对于口语化的微博文本中存在更多的停用词以及特殊符号,即使出现HL和HR相等的词,也能够有效识别新词边界。EMI-WBE和MEMI-WBE与之前的实验相比,实验结果值更高。但从图3可以看出这两个实验结果相差不大,所以,MEMI只针对那些具有多种组成模式的新词有效果,而且WBE的使用弱化了具有多种模式组合的新词识别。
MI-BE和MI-WBE均未考虑单字新词的识别,其余4个实验基于字的粒度识别出部分单字新词,如:“卷”“凎”“害”“可”“晕”等,相比MI-BE和MI-WBE,召回率都有了较大的提升,表明本文提出基于字的粒度识别新词是有效的。
3.4.2 实验2的结果与分析 为验证本文提出的相似性计算模型DSSCNN对于新词识别有效,以相似性增强互信息与左右邻接熵结合(SEMI-BE)[9]为基准方法,使用文献[16]提出的语义相似性计算模型SSCNN与本文提出的DSSCNN进行相似性判断,分别与基于统计量的6种方法结合进行对比实验,结果如表3所示。
表3 统计量与相似性判断结合的实验结果对比表
Tab.3 Comparison of experimental results based on statistics and similarity judgment

方法P/%R/%F/% Baseline[9]SEMI-BE76.2775.6875.97 MI-BE73.3174.2073.75 EMI-BE75.6774.5575.11 SSCNN[16]MEMI-BE76.1675.5875.87 MI-WBE74.1074.6074.35 EMI-WBE76.2078.5977.38 MEMI-WBE78.5080.6879.58 MI-BE77.1078.7277.90 EMI-BE80.9079.4080.14 DSSCNN(本文模型)MEMI-BE81.9782.1082.03 MI-WBE80.3281.1080.71 EMI-WBE84.9685.1585.05 MEMI-WBE85.93 86.49 86.21
实验2采用的基准方法是文献[9]提出基于相似性增强互信息的新词发现算法,在MI-BE的基础上,使用相似性增强互信息公式过滤候选新词,可以看出识别效果较好。第2组实验是加入SSCNN模型判断句子语义相似性进行候选新词的过滤,从实验结果可以看出,相比于单独使用统计量的方法,加入SSCNN进行句子上下文语义信息的判断使得新词识别结果有了较明显的提升,但总体效果比基准方法稍差,只有SSCNN-EMI-WBE的召回率和SSCNN-MEMI-WBE方法的结果略好于基准方法。主要原因在于,基准方法通过训练词向量模型,计算候选词与旧词的词语相似性值,将其加入到MI计算公式中,而SSCNN模型得到的只是候选新词与历史表达句子语义相似。以上方法虽可以有效识别词义相近的新词,但对于具有相似句法结构、词义相差较大的新词无法正确识别。
本文提出的DSSCNN模型在SSCNN进行句子语义相似的基础上加入句法结构相似性特征。从图3可以看出,加入DSSCNN的识别效果明显优于仅使用统计量和仅考虑语义相似的方法。通过分析新词集合,在加入句法和语义结合的相似性判断后,不仅能有效过滤掉经常出现但不能被认为是新词的固定表达,比如“年以来”等,也能有效识别出部分旧词新义和中英文结合的新词表达,比如“真香”“路人”“slay全场”“duck不必”“打call”等,使得新词识别的准确率、召回率及F值都有了较大的提升。表明本文提出的相似性判断模型DSSCNN对新词识别是有效的。

图3 加入相似性判断前后实验结果对比图Fig.3 Comparison of experimental results before and after adding semantic similarity judgment
本文对获取到的有效网络新词进行分析归纳,将网络新词主要分为缩略词、新造词等5个类别,具体描述如表4所示。从表4可以看出,不同于传统新闻文本,在网络文本内容中,命名实体所占比例较少,而由缩略词和谐音所衍生出的新词所占比例较大。
4 结语
本文对新词发现方法进行研究,提出了一种在统计量计算基础上,融合句法与语义相似性判断的网络新词发现方法。该方法基于字的粒度,计算词频、最大增强互信息以及加权左右邻接熵等统计量得到候选新词集,和传统的统计量计算结果相比,本文选用的统计量可有效过滤部分重复含义的词串,也解决了字词出现次数、邻接字符贡献不对称以及多模式组合等问题。根据新词与历史表达的句法结构与上下文语义相似性原则,本文提出改进的相似性计算模型DSSCNN,过滤无效新词。对比实验结果表明,加入相似性判断

表4 网络新词描述表Tab.4 Description of internet new words
的新词识别效果有了明显提升。但使用CNN模型进行相似性判断时,会丢失词汇的位置顺序信息,更适用于短句的相似性计算。在下一步工作中,将主要针对相似性判断进行改进,希望在提高新词识别准确率的同时降低计算复杂度。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
中学生天地(B版)(2022年4期)2022-05-17
建材发展导向(2021年19期)2021-12-06
现代英语(2021年18期)2021-11-22
现代计算机(2021年10期)2021-05-28
现代计算机(2021年3期)2021-03-24
周末·校园文学(2017年35期)2018-02-06
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
疯狂英语·原声版(2013年6期)2013-07-16
