
基于改进训练策略的高光谱图像分类
2022-04-14 06:40吴少乔
哈尔滨商业大学学报(自然科学版) 2022年2期
吴 少 乔
(哈尔滨工程大学 信息与通信工程学院, 哈尔滨 150001)
高光谱成像是遥感技术中的一项重要技术,可收集可见光到近红外波段的电磁光谱.高光谱成像传感器通常提供来自地球表面同一区域的数百个窄光谱带.高光谱图像由诸多一维多谱带像元组成,每个像元对应于特定波长的光谱反射率.高光谱图像分类通过区分细微光谱差异以区分不同类别像元,在许多领域得到了广泛的应用[1-5].
高光谱遥感可以用于城市规划,对于真彩色的图像,人眼难以分辨真草坪和人造塑料草坪,但对于高光谱图像及分类技术却可以通过特征分析区分开,因为在光谱特征上,真草皮和人造草坪具有本质性差异,同理,在军事领域,战场上真实地物和伪装地物目标也可以获得很好的区分,自然地块、陆军行进扰动的地块之间的差异也可以利用高光谱图像技术提取出来,从而对敌军路线进行还原.
在文献[6]中,Zhao等人中首次在高光谱图像分类中提出基于框的卷积神经网络,输入像素及其周围的正方形区域作为训练样本,标签作为其输出.该模型学习获得识别中心像素的能力,然后在测试集上利用这种能力实现像元分类.卷积神经网络自然地利用了空间信息,实现了空间和光谱信息的组合.文献[7]中,Chen等人提出了基于三种特征提取结构的卷积神经网络,用于获取高光谱图像的多种特征,并首次提出了将3DCNN应用在高光谱图像分类中.
人工智能的突破已经融入到高光谱图像分类领域.文献[8]中,Zhong等人首先利用3DCNN的原始波段信息,然后提取空间特征,在此过程中使用残差网络[9]来防止梯度的消失,保持模型的深度.文献[10]中,Wang等人引入了密集卷积网络[11](DenseNet)的快速密集谱空间卷积网络.文献[12]中,受卷积块注意模块[13]的启发,Ma等人提出了一种双分支多注意机制网络.文献[14]中,Li等人提出让光谱分支和空间分支分别捕获光谱和空间特征,然后将两个分支的输出连接起来的网络.
文献[15]中,Chen等人提出了一种卷积神经网络的自动设计方法,该方法具有搜索过程和正则化技术cutout.文献[16]中,Mou等人提出了光谱注意机制,利用全局卷积得到的门限来选择有效波段,抑制信息量较小的波段.
卷积神经网络应用在高光谱图像分类是目前高光谱图像分类的主流研究方向之一,各种在深度学习中取得有效的方法、模块、构建网络方式不断地应用在高光谱图像分类以期望在尽可能少的训练样本下取得尽可能高的识别精度.在卷积神经网络中在高光谱图像中的多项模型优化研究中,可以发现,除了训练集,另外一部分有标签样本同样参与了模型训练,一般的思路是利用早停训练策略,这部分有标签样本被称作验证集,模型每更新一次同时计算验证集输出值与真实标签之间的损失,记为验证集损失,当验证集损失在若干周期次迭代下不再下降时,提前停止训练,取验证集损失的全局最小值对应的权重作为最终输出的权重,模型相当于在验证集损失取得全局最小值时训练完毕.
基于验证集损失的早停训练策略使用了额外的有标签样本,同时在实验中也可以发现,这种训练策略会带来额外的训练过程中产生的误差.训练误差表达的意思是对于同样的训练环境,包括训练集、模型、初始权重、训练优化器、超参数,在这些不变条件并重复训练下,实验结果有差别,经过实验,可以发现重复训练下有些实验的识别精度较大地偏离这些重复训练结果的平均识别精度.
这项研究提出了一种新的训练策略以替代基于验证集损失的训练策略,这种训练策略相比于目前的训练策略,不需要验证集,可以节省验证集样本的标签成本,在对比实验中,仅使用了一半的有标签样本,实现了更高的多次重复实现条件下的平均识别精度.
1 改进的训练策略及对比实验
1.1 改进的训练策略与早停策略的对比
此研究提出了基于训练集损失的训练策略,不使用验证集,仅使用训练集,将训练周期后半段中训练集损失取得最小时的模型作为最终的参加测试的模型.
算法的工程实现为:假如训练周期为200,当训练进行到100周期时,保存此时的训练集损失为最小损失以及此时的模型权重,此后,只要训练集损失小于这个值,用此时的训练集损失代替最小损失同时保存模型权重,训练进行到200周期结束时,读取最小损失对应的权重参与测试.
为了验证方法的有效性,使用了SSRN[8]、FDSSC[10]、DBMA[12]、DBDA[14]模型进行对比实验,这些模型较深,参数较多.这些模型使用了很多有效方法,比如残差网络[9]、稠密连接网络[11](DenseNet)、批归一化[17]以及注意力机制,或具有代表性或最近提出.这些模型源码、改进训练策略代码可以公开获取.
实验中使用了高光谱公开标准集,分别是Indian Pines数据集、Pavia University数据集、Salinas Valley数据集,分别简称为IP数据集、PU数据集、SV数据集.这些数据集在网站上公开获取,使用的版本为修正后(Corrected)版本,比如在IP数据集上,去除了覆盖吸水区域的20条谱带.
使用的评价指标有OA,AA以及Kappa系数,其中OA评价识别正确像元占所有像元的比重,AA是每类像元识别正确率的平均,Kappa系数反映了地面真实性与分类结果的一致性.
随机生成10个随机种子用于随机生成训练集与验证集.对于SSRN、FDSSC,窗大小为7,DBMA、DBDA窗大小为9.对于SSRN、FDSSC、DBMA,批量大小为16,对于DBDA,批量大小为24,优化器为Adam,学习率为0.000 5.使用基于验证集损失的早停策略,早停周期为30,即当模型在120周期训练完毕时,可以发现在90周期,验证集的损失取得全局最小值,最终的模型取90周期时的模型;使用改进的训练策略.
在一个数据集下,不同模型在早停策略下的训练集、验证集、测试集完全一致,改进的训练策略仅使用训练集,与早停策略下的训练集,测试集完全一致,测试集不使用但划分出来,与早停策略一致,但不起任何作用,不同模型在改进训练策略下训练集、测试集完全一致.表1~3为不同数据下训练集、验证集、测试集的数目.
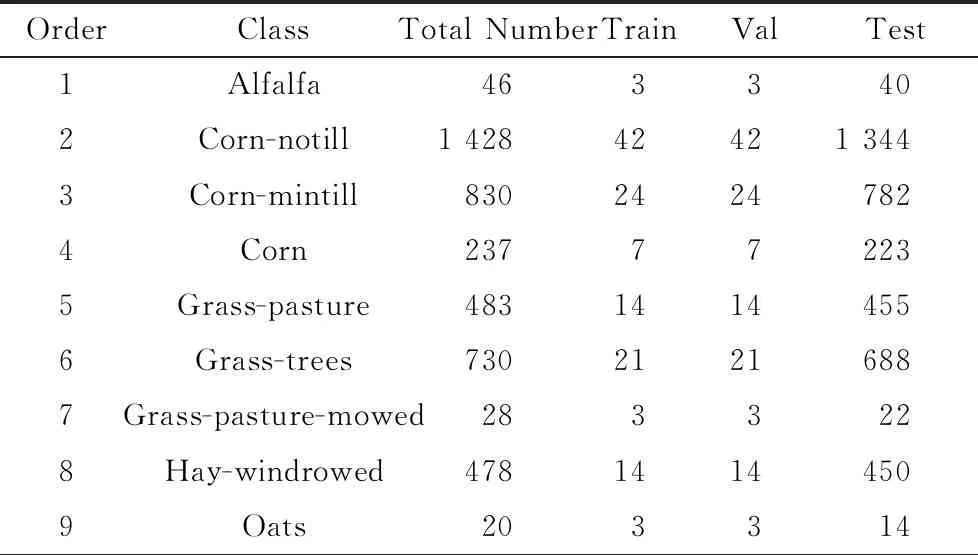
表1 IP数据集上使用的训练集、验证集、测试集数目
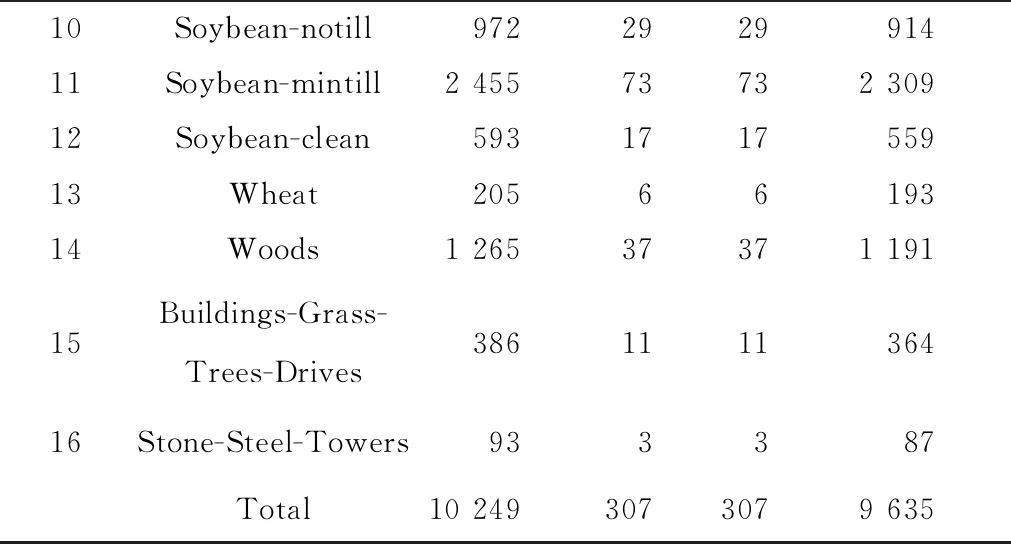
10Soybean-notill972292991411Soybean-mintill2 45573732 30912Soybean-clean593171755913Wheat2056619314Woods1 26537371 19115Buildings-Grass-Trees-Drives386111136416Stone-Steel-Towers933387Total10 2493073079 635
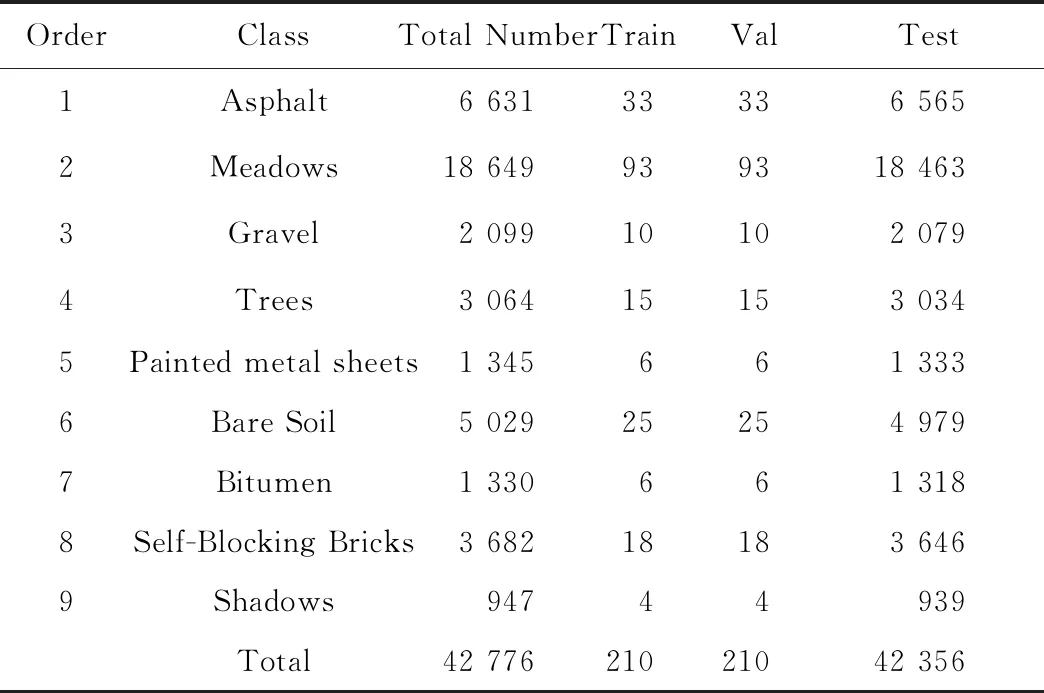
表2 PU数据集上使用的训练集、验证集、测试集数目

表3 SV数据集上使用的训练集、验证集、测试集数目
实验设置如下:在IP、PU、SV数据集下,使用SSRN、FDSSC、DBMA、DBDA模型,使用两种训练策略,其中早停策略中的早停周期为30,提出的训练策略在不使用验证集,也就是仅使用与前文相比一半的有标签样本条件下进行实验,两种训练策略在一致的测试集上测试.见表4~6.

表4 在IP数据集使用两种训练策略随机训练集选取方式重复10次训练实验结果
在文献[14]中,Li等人提出了DBDA模型,在三个数据集上,文献中仅列出了一次实验的结果,其结果如表7所示,其中参照了文献中数据集各类数目,使用了相同的训练环境,在更加客观的10次不同随机训练集下对本文中的识别精度进行了复现.文献中DBDA模型,OA值的实验结果为95.38%,没有标准差,仅为一次实验结果,在改进训练策略下,10次随机训练集的平均OA为93.44%,最大OA值为95.59%,最大OA值符合一次实验表现,但本文中AA值为96.47%,随机10次实验结果无一接近,本文中的训练集验证集无法复现是AA值无法复现的原因,完全相同训练环境下更加客观的10次随机训练集都没有取得接近的结果,可能仅有还原作者训练时的训练集于验证集才可能出现对应的结果.此外,对于SSRN模型,10次随机训练集无一AA值降到79.40%.说明训练集的选取对识别精度也存在较大的影响.
回到改进的训练策略,使用新的训练策略后,DBDA模型10次随机训练集平均OA从93.44%提升到了95.38%,其中93.44%就是文献中实验环境还原后10次随机训练集的平均OA,使用新的训练策略后的平均OA几乎成为旧策略下的最大OA.
新的训练策略下有标记样本数目仅为旧策略的一半,307个有标记样本在IP数据集以及DBDA模型上实现了10次不同训练集95.38%的平均OA值.
在多个模型下,新的训练策略和提出的样本预选方法普遍展现了其优势,在IP数据集下的实验表格中,识别精度的提升以及标准差的降低都用黑体进行标注.表4中,在随机训练集下,两种训练策略共计24个评价指标(OA,AA,Kappa系数及其标准差)中获得提升的有17个,对于FDSSC模型以及DBDA模型,评价指标都获得了提升.表5中,在PU数据集下,两种训练策略共计24个评价指标中获得提升的有23个.表6中,在SV数据集下,两种训练策略共计24个评价指标中获得提升的有19个.就OA平均值而言,4个模型在4个数据集上都获得了提升.
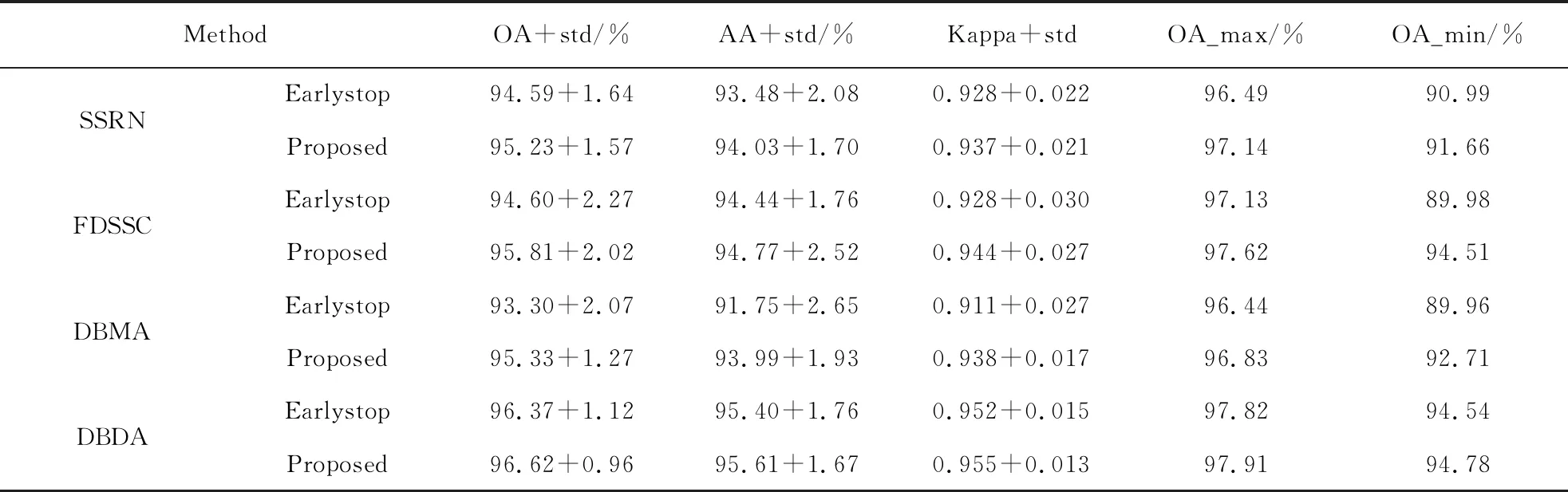
表5 在PU数据集使用两种训练策略随机训练集选取方式重复10次训练实验结果

表6 在SV数据集使用两种训练策略随机训练集选取方式重复10次训练实验结果
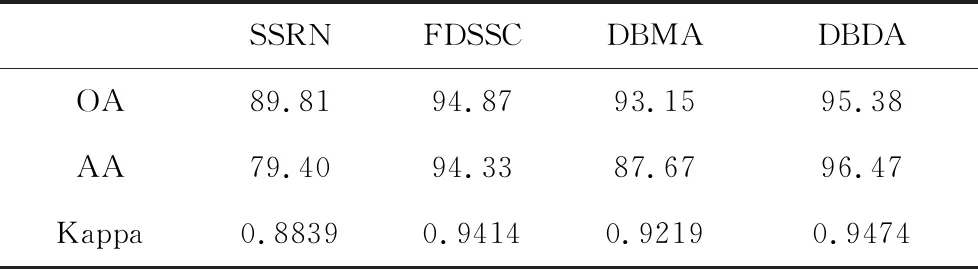
表7 文献中展示的四个模型在IP数据集上同样实验环境下的识别精度
1.2 早停策略训练误差验证
接下来通过实验展示基于验证集损失早停策略额外产生的训练误差.在上述实验过程中,先随机生成随机整数,再将这10个随机整数作为随机种子生成随机训练集以及验证集,余下作为测试集.关于随机种子的描述为通过确定随机种子让随机的结果确定化.于是对于10次不同随机训练集的结果,记录取得最小总体识别精度训练集的随机种子,再固定随机种子为这个整数,在相同实验条件下重复10次训练,记录平均AA、OA、Kappa.
表8记录了SV数据集早停策略下OA最小值对应训练集、验证集重复10次训练结果,可以发现最小的那次OA值对应的一次结果全部小于同样环境下10次重复训练结果, 要知道所谓的同样环境包含训练集验证集,平均结果能更加真实地反映这组训练集验证集下的识别精度,而取得的最小OA值那一次实验是训练误差较大导致.其中比如FDSSC,最小OA值为91.78%,平均OA值及其标准差为96.06%以及1.19%,最小OA值严重偏离了平均值.表4~6中,在12次对比实验中,使用新训练策略下的最小OA值有10次超过了早停策略下的最小OA值,训练误差来源于两个部分,训练模型本身的误差,来自于验证集选取的误差,新训练策略由于没有使用验证集,训练误差的降低使得最小OA值在新训练策略上多次领先,但无论对于那种误差来源,都存在识别精度大幅度下降的现象,在表6中SSRN在新训练策略下的最小OA值仅为87.95%,远低于10次平均93.45%,在表8中,DBMA模型在早停策略训练方式下OA的标准差为3.01%,说明其中一次实验也出现了识别精度大幅度下降的结果.
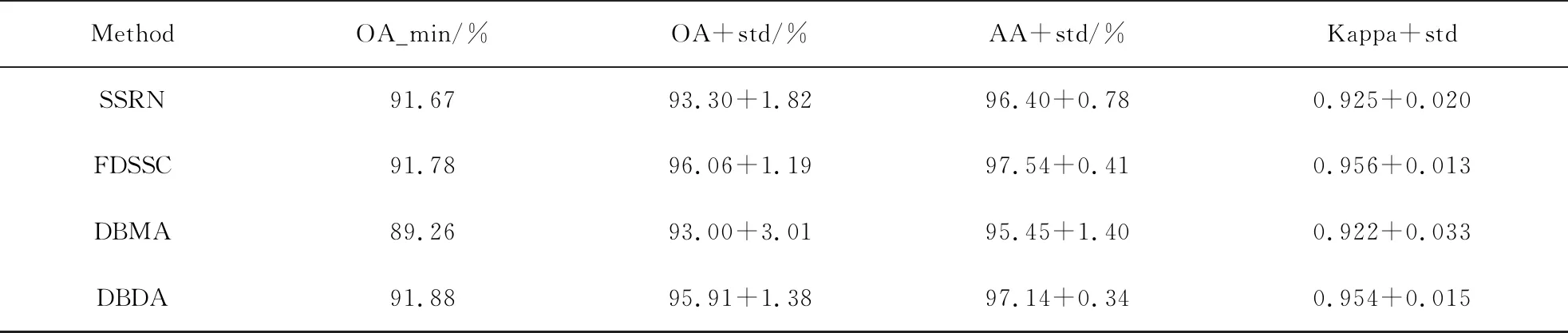
表8 SV数据集上使用早停策略OA最小值训练集重复10次训练结果
当使用早停策略取得较小识别精度时,实验过程存在三种情况,验证集损失非常小的情况下验证集总体正确率却很低;验证集损失非常小,验证集总体正确率也很高,但测试集识别精度依然很低;模型过早地结束训练,验证集损失非常大.对于第一点,其可能是单独基于验证集损失而不是总体考量验证集损失以及验证集正确率造成的,也可以发现,在训练集上会同样出现损失小而总体正确率低的现象;对于第二点,其可能是所划分出来的验证集相对于更大体量的测试集来说不具备代表性造成的;对于第三点,使用更大的早停结束周期可以解决问题,但也意味着将花更多的时间进行训练.
1.3 方法有效性探究
上述早停训练策略是在早停周期为30的基础上训练下,下面改变早停周期并观察结果.
在IP数据集DBDA模型上,使用10组随机训练集、验证集,分别使用早停周期为40、50、60进行训练,10组训练集、验证集保持不变,其他条件与前述相同.实验结果记录见表9,其中,早停数代表早停周期,周期代表10次重复训练的平均周期,次数代表10次中达到训练周期上限200而结束训练的次数.
从表9中可以看出随着早停周期的增长,模型的识别精度及其稳定性获得了提升,在早停周期较小时,早停策略更大概率过早结束训练,此时模型是欠拟合的.早停周期越高,训练周期越长,早停数40相当于在早停数为30结束训练后继续训练,如果接下来10周期验证集损失没有取得新的全局最小值,训练完毕,如果出现了,需要在这个最小值之后40周期没有出现更小验证集损失而训练完毕.
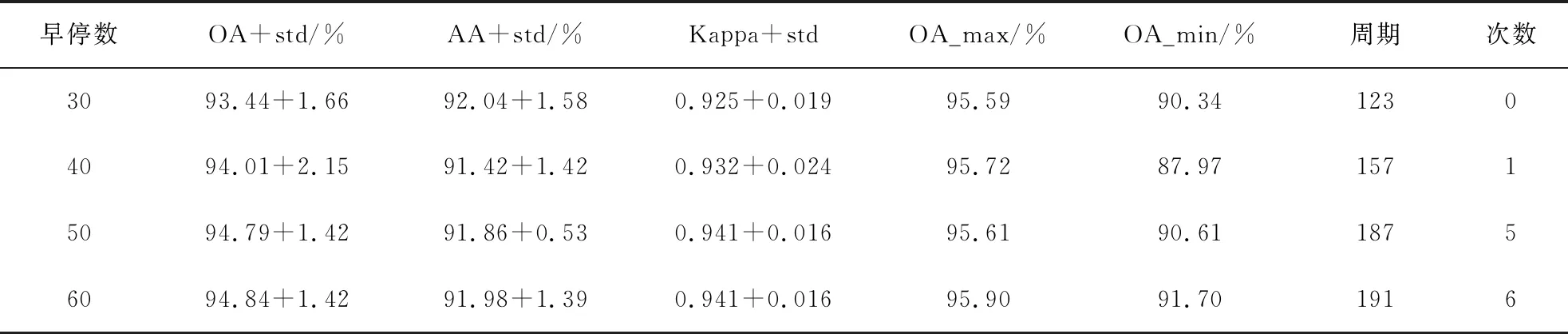
表9 DBDA模型在IP数据集上更改早停周期的实验结果
早停策略的目的是防止模型训练出现过拟合,而目前的情况是,随着继续训练,模型没有因为过拟合而出现识别精度的下降,反而提升了,还没有达到过拟合的程度,随着早停周期的提升,模型越来越多次数达到模型训练周期上限而停止训练,当早停周期为60时,平均训练周期已经十分接近于200周期训练上限,可以猜想随着早停周期的继续上升,当每次都达到训练周期上限时,再提升早停周期时对模型的训练不再产生影响,此时早停策略已经“名存实亡”.
早停周期为60时,10次实验平均在191周期结束训练,在新的训练策略下,模型固定在200周期训练完毕,两者训练周期比较接近,但早停策略下,每个周期训练完毕额外需要将验证集正向通过模型以计算验证集损失,总体时间相比差别不大.在早停策略下,早停周期为60时早停训练策略取得了最好结果,在同样训练集下,新训练策略OA平均值为95.38%,高于早停训练策略下94.84%最好结果,此外新训练策略仅使用一半有标签样本.总体来说,从训练时间、使用有标记样本、识别精度等方面,新训练策略都展现了其有效性.新训练策略的提升一部分来源于早停训练策略的欠拟合,一部分来源于其舍弃了验证集.下一步使用新训练策略,将训练周期上限提高.
早停周期为60时,模型训练以及十分接近周期上限,识别精度稳步上升,但仍然无法确定期间有没有过拟合,为了进一步验证模型的过拟合风险,将模型训练进一步拟合到训练集上.早停策略具有防止过拟合的作用,实验改用改进的训练策略:在原本实验环境下,在IP数据集DBDA模型上,将训练周期上限分别提升到300以及400进行实验,使用新训练策略实验重复10次,在三个训练周期上限下使用的10组不同随机训练集与上述实验完全一致,对于周期上限为300,训练完毕的模型存在于150~300周期,周期为400时同理.表10记录了实验结果.

表10 DBDA模型在IP数据集上提高训练周期上限后使用新训练策略的实验结果
从表10可以看出训练周期在200时,模型识别精度最佳,300周期和400周期训练结果相差无几,而相对于200周期训练识别精度有少量下降,此外,300周期和400周期训练识别精度较200周期更加稳定.
这个实验以及改进训练策略相对于早停策略的提升,说明在高光谱数据集上,使用早停策略防止模型过拟合是不必要的,因为模型过拟合风险不大.
2 结 语
改进的训练策略舍弃了验证集,使用了一半的有标记样本,在作为对比的四个卷积网络模型上实现了识别精度上的提升,其展现的有效性可以使提出的训练策略推广到其他使用了验证集的模型训练过程中,进一步提升模型的识别精度.实验过程中新训练策略的实验结果以及对DBDA模型过拟合风险的测试说明上述模型过拟合风险较小,使用额外的有标记样本建立验证集是不必要的.在较新的卷积网络中,使用了新的深度学习方法,比如批归一化以及稠密连接网络,这些方法设计的初衷不是专一地用于防止模型过拟合,但在使用中却证实具有避免模型过拟合的作用,早停策略的提出比这些方法早,为一种延续下来的方法,但具体模型在新方法的加持下是否还存在较大过拟合风险没有具体实验过,这是所提出训练策略简单有效的原因,此外,不使用验证集而进行训练在深度模型上具有一定的难度,这是提出训练策略的创新之处.如图1所示,其展现FDSSC模型在PU数据集上一次实验训练集正确率,验证集正确率,训练集损失以及验证集损失,可以发现验证集损失的波动较训练集损失波动小,基于验证集损失,而非基于训练集损失构建一个训练策略较为容易,早停策略基于验证集,其作为一个成熟有效的训练策略在训练集损失波动巨大的情况下被自然地使用了.总体来说,这项研究在高光谱图像分类下,验证了在一些或新或代表性地模型上过拟合风险较小的事实,并提出了一项不基于验证集的训练策略,发现提出的训练策略在识别精度上具有较大的提升,且伴随的训练误差较小.
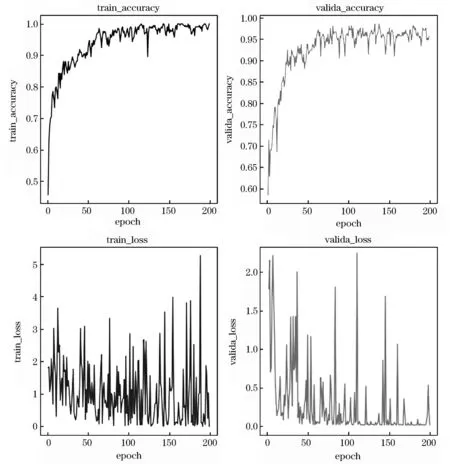
图1 FDSSC模型在PU数据集上一次实验过程
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年8期)2022-08-08
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机研究与发展(2022年1期)2022-01-19
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
职业·中旬(2009年12期)2009-06-01
